Caching algorithm for a GridSearchCV#
Ideas#
The goal is to measure the impact of using a cache while optimizing a pipeline:
[
('scale', MinMaxScaler()),
('pca', PCA(2)),
('poly', PolynomialFeatures()),
('bins', KBinsDiscretizer()),
('lr', LogisticRegression(solver='liblinear'))
]
With the following parameters:
params_grid = {
'scale__feature_range': [(0, 1), (-1, 1)],
'pca__n_components': [2, 4],
'poly__degree': [2, 3],
'bins__n_bins': [5],
'bins__encode': ["onehot-dense", "ordinal"],
'lr__penalty': ['l1', 'l2'],
}
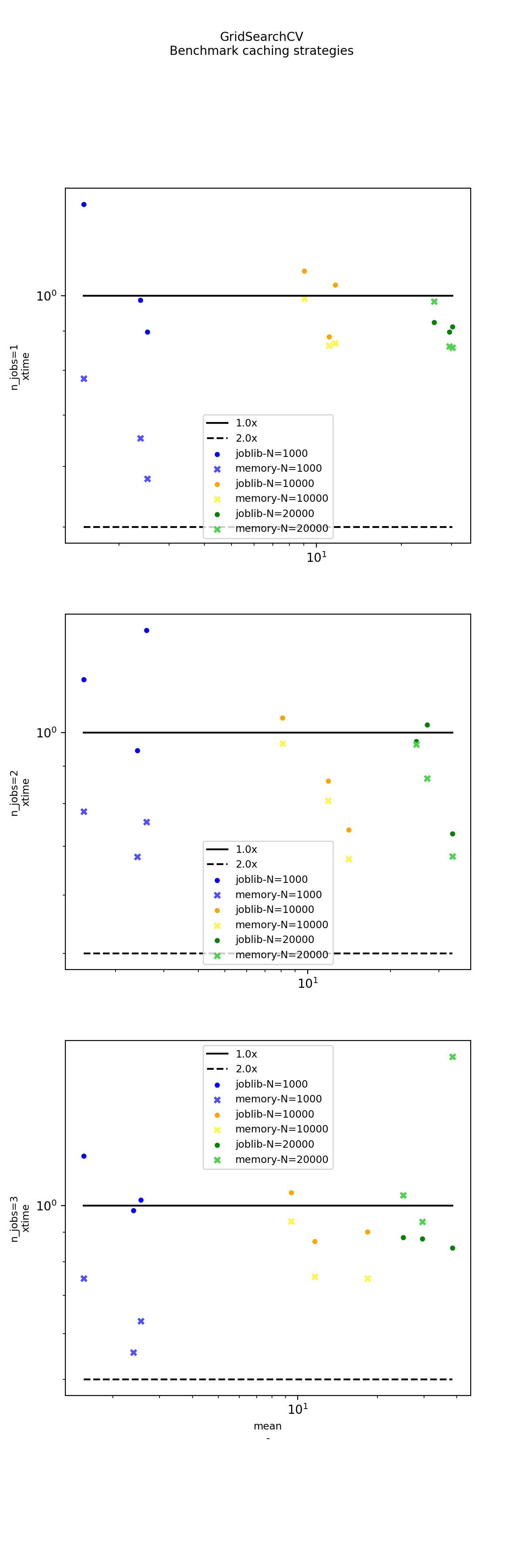
It looks into different ways to speed up the optimization by caching. One option is not implemented in scikit-learn: PipelineCache, it implements a cache in memory as opposed of joblib which stores everything on disk. This implementation is faster when the training runs with one process, joblib does a better job if the number of jobs and processes is higher even if it may store a huge load of data.
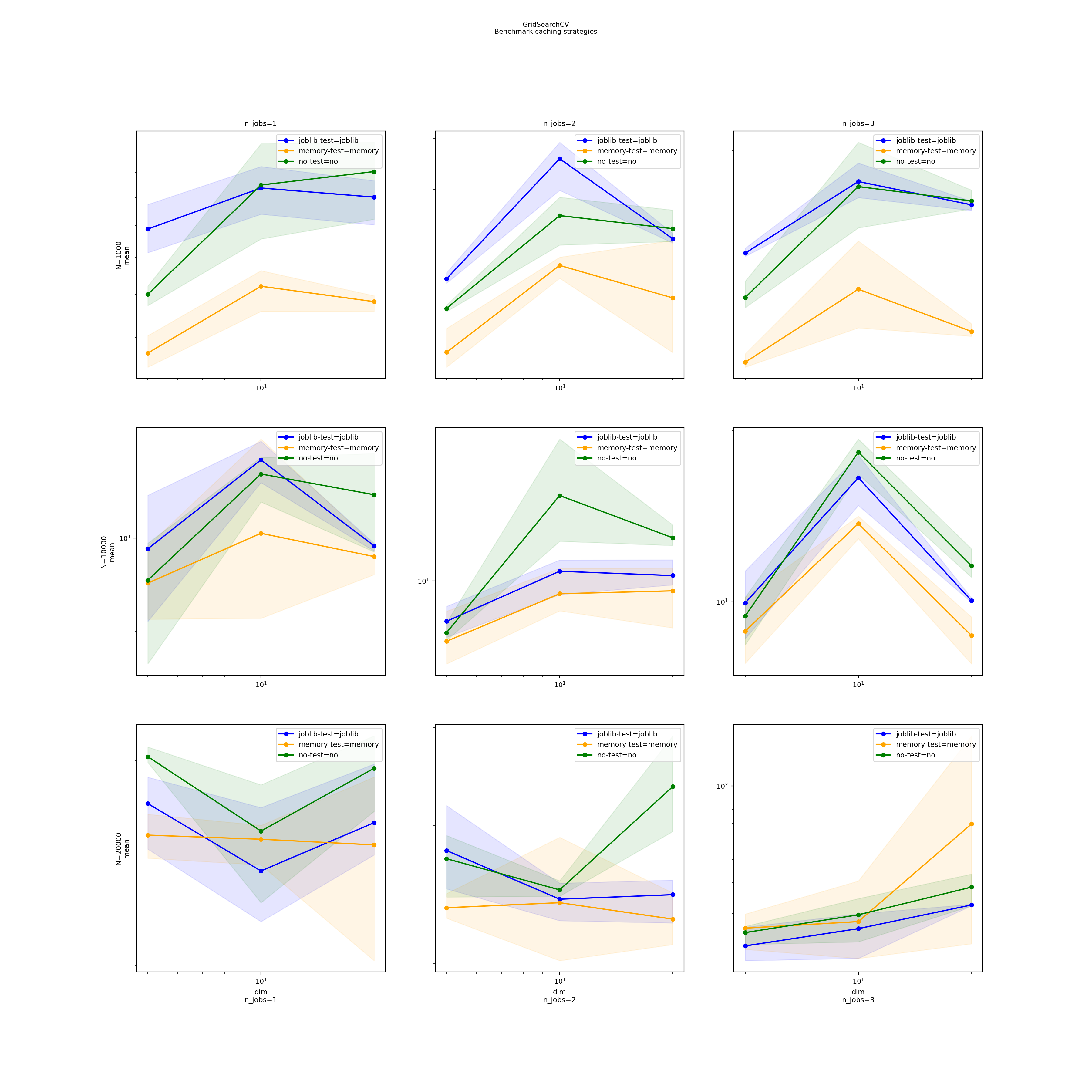
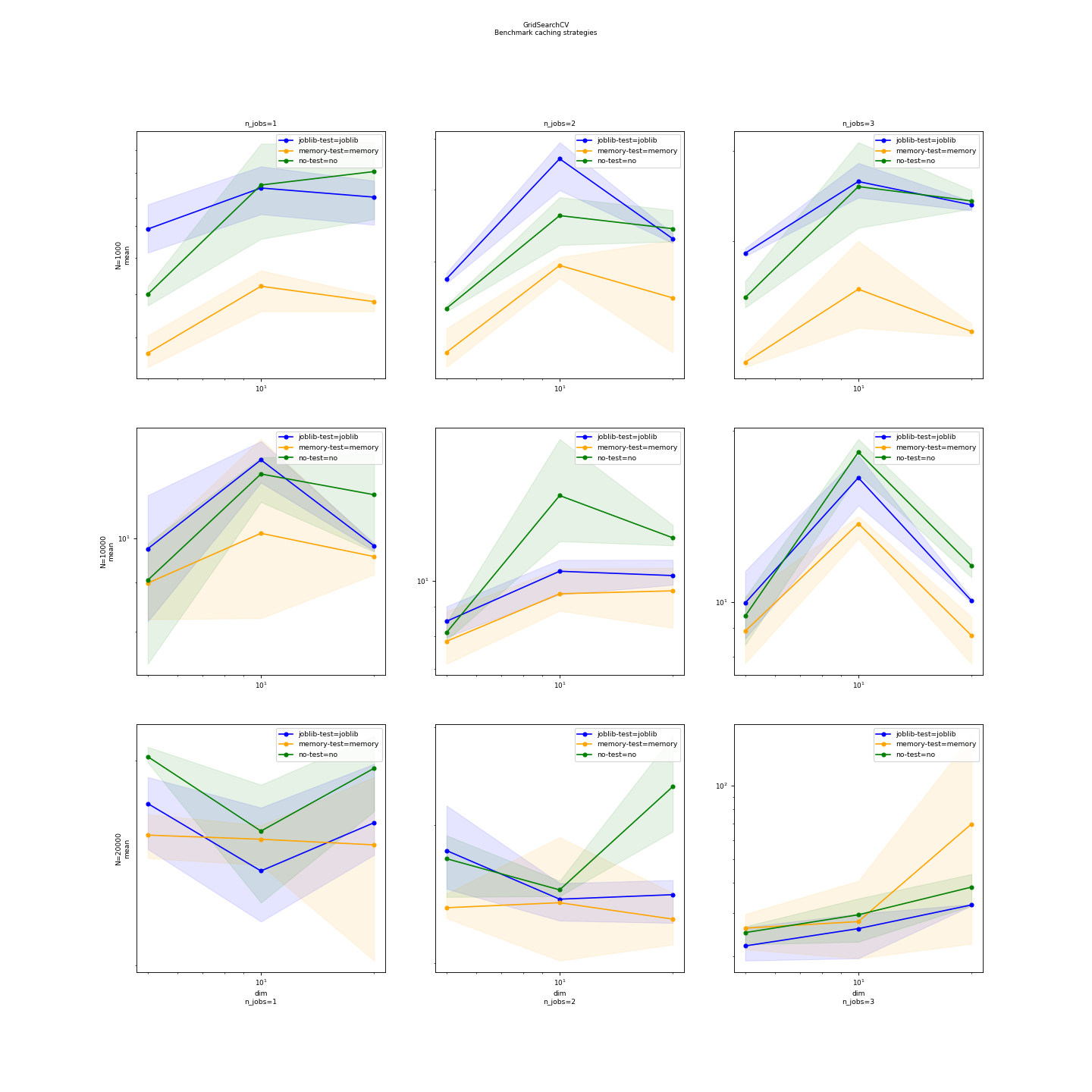
Graphs#
(Source code, png, hires.png, pdf)
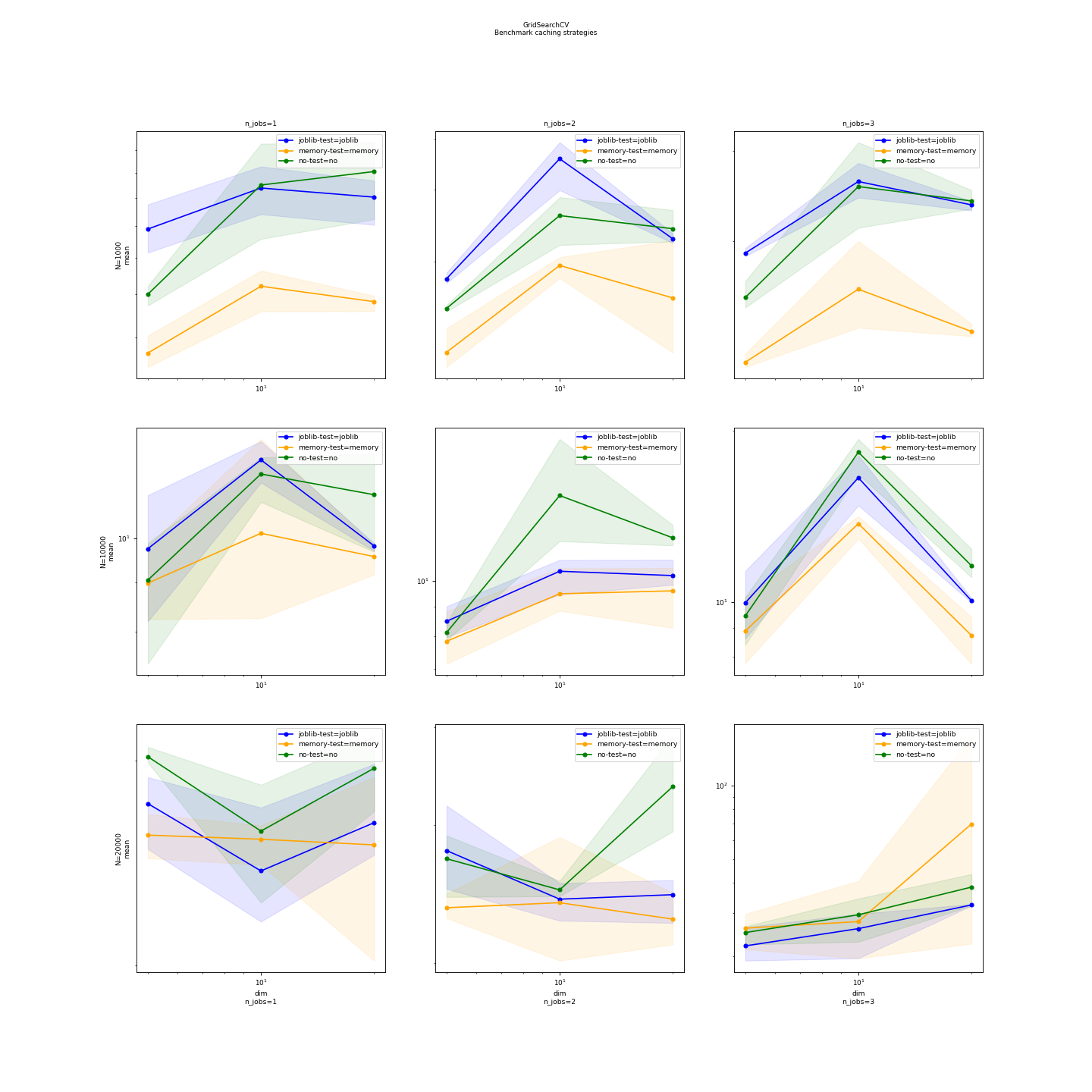{kind=link}
{kind=link}
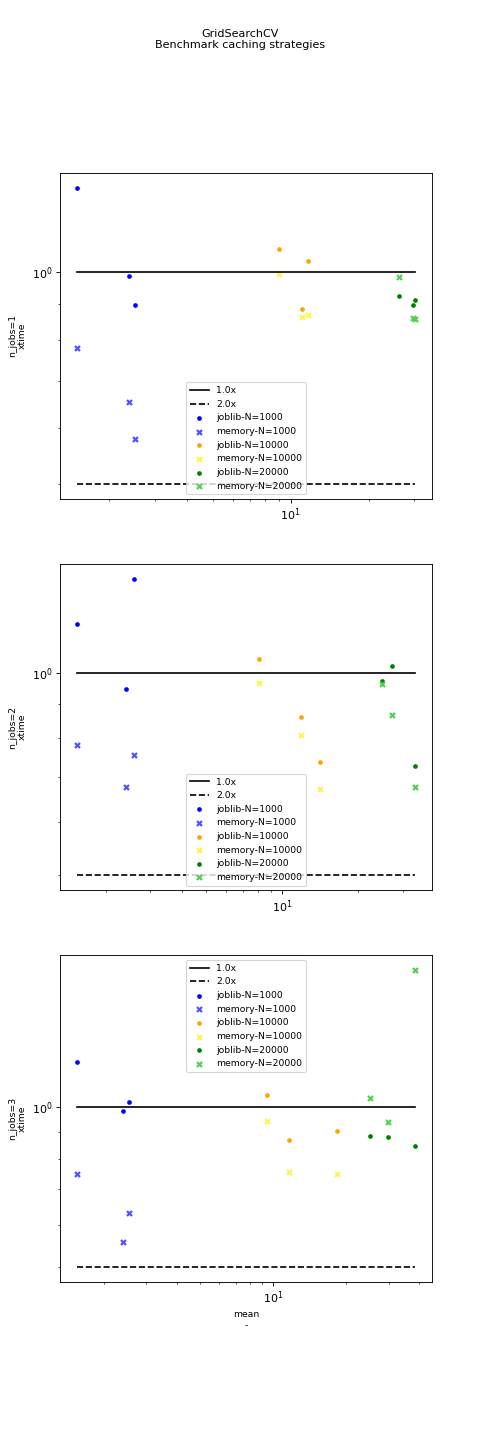
(Source code, png, hires.png, pdf)
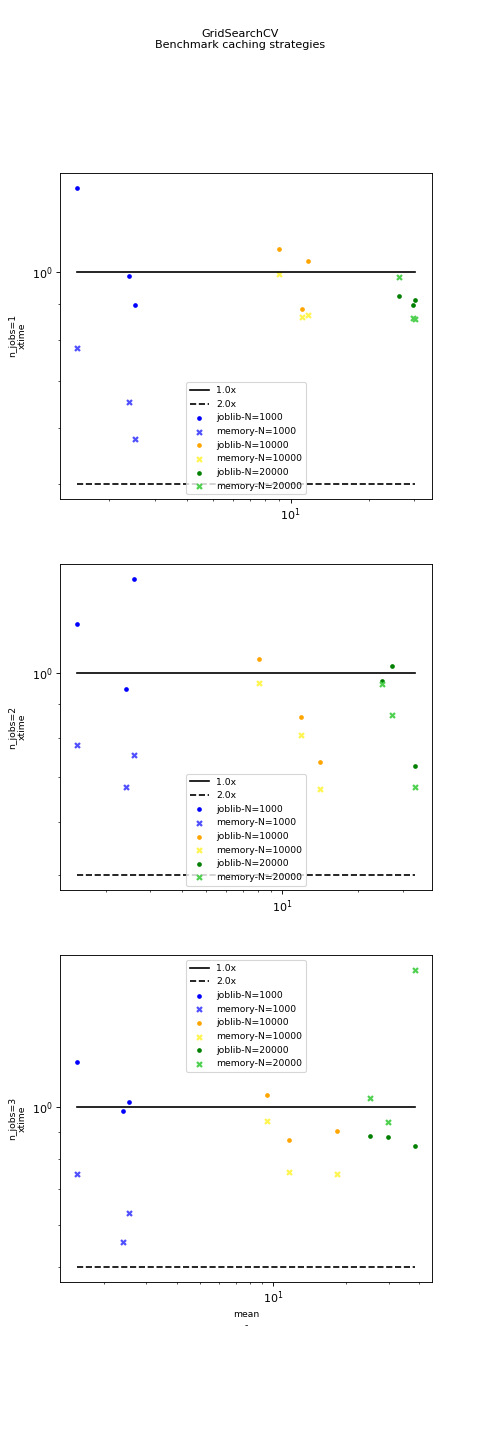{kind=link}
{kind=link}
Machine used to run the test#
<<<
from pyquickhelper.pandashelper import df2rst
import pandas
name = os.path.join(
__WD__, "../../scikit-learn/results/bench_plot_gridsearch_cache.time.csv")
df = pandas.read_csv(name)
print(df2rst(df, number_format=4))
>>>
name |
version |
value |
|---|---|---|
date |
2019-12-11 |
|
python |
3.7.2 (default, Mar 1 2019, 18:34:21) [GCC 6.3.0 20170516] |
|
platform |
linux |
|
OS |
Linux-4.9.0-8-amd64-x86_64-with-debian-9.6 |
|
machine |
x86_64 |
|
processor |
||
release |
4.9.0-8-amd64 |
|
architecture |
(‘64bit’, ‘’) |
|
numpy |
1.17.4 |
openblas, language=c |
pandas |
0.25.3 |
|
sklearn |
0.22 |
Raw results#
<<<
from pyquickhelper.pandashelper import df2rst
import pandas
name = os.path.join(
__WD__, "../../scikit-learn/results/bench_plot_gridsearch_cache.csv")
df = pandas.read_csv(name)
print(df2rst(df, number_format=4))
>>>
test |
N |
n_jobs |
dim |
repeat |
number |
min |
max |
mean |
lower |
upper |
count |
median |
error_c |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
joblib |
1000 |
1 |
5 |
3 |
1 |
1.786 |
2.188 |
1.972 |
1.786 |
2.188 |
3 |
1.944 |
0 |
memory |
1000 |
1 |
5 |
3 |
1 |
1.103 |
1.26 |
1.17 |
1.103 |
1.26 |
3 |
1.148 |
0 |
no |
1000 |
1 |
5 |
3 |
1 |
1.43 |
1.552 |
1.499 |
1.43 |
1.552 |
3 |
1.515 |
0 |
joblib |
1000 |
2 |
5 |
3 |
1 |
1.768 |
1.876 |
1.812 |
1.768 |
1.876 |
3 |
1.793 |
0 |
memory |
1000 |
2 |
5 |
3 |
1 |
1.101 |
1.369 |
1.197 |
1.101 |
1.369 |
3 |
1.121 |
0 |
no |
1000 |
2 |
5 |
3 |
1 |
1.506 |
1.562 |
1.534 |
1.506 |
1.562 |
3 |
1.532 |
0 |
joblib |
1000 |
3 |
5 |
3 |
1 |
1.867 |
1.937 |
1.894 |
1.867 |
1.937 |
3 |
1.878 |
0 |
memory |
1000 |
3 |
5 |
3 |
1 |
1.136 |
1.206 |
1.161 |
1.136 |
1.206 |
3 |
1.14 |
0 |
no |
1000 |
3 |
5 |
3 |
1 |
1.483 |
1.67 |
1.552 |
1.483 |
1.67 |
3 |
1.501 |
0 |
joblib |
10000 |
1 |
5 |
3 |
1 |
8.196 |
11.08 |
9.748 |
8.196 |
11.08 |
3 |
9.971 |
0 |
memory |
10000 |
1 |
5 |
3 |
1 |
8.239 |
9.818 |
8.98 |
8.239 |
9.818 |
3 |
8.881 |
0 |
no |
10000 |
1 |
5 |
3 |
1 |
7.404 |
9.878 |
9.044 |
7.404 |
9.878 |
3 |
9.849 |
0 |
joblib |
10000 |
2 |
5 |
3 |
1 |
7.962 |
9.023 |
8.493 |
7.962 |
9.023 |
3 |
8.495 |
0 |
memory |
10000 |
2 |
5 |
3 |
1 |
7.151 |
8.844 |
7.834 |
7.151 |
8.844 |
3 |
7.507 |
0 |
no |
10000 |
2 |
5 |
3 |
1 |
7.863 |
8.447 |
8.113 |
7.863 |
8.447 |
3 |
8.028 |
0 |
joblib |
10000 |
3 |
5 |
3 |
1 |
8.618 |
11.33 |
9.953 |
8.618 |
11.33 |
3 |
9.912 |
0 |
memory |
10000 |
3 |
5 |
3 |
1 |
7.799 |
10.2 |
8.881 |
7.799 |
10.2 |
3 |
8.65 |
0 |
no |
10000 |
3 |
5 |
3 |
1 |
8.4 |
10.19 |
9.442 |
8.4 |
10.19 |
3 |
9.734 |
0 |
joblib |
20000 |
1 |
5 |
3 |
1 |
25.18 |
29.03 |
27.56 |
25.18 |
29.03 |
3 |
28.45 |
0 |
memory |
20000 |
1 |
5 |
3 |
1 |
24.73 |
26.98 |
25.89 |
24.73 |
26.98 |
3 |
25.95 |
0 |
no |
20000 |
1 |
5 |
3 |
1 |
29.89 |
30.82 |
30.23 |
29.89 |
30.82 |
3 |
29.99 |
0 |
joblib |
20000 |
2 |
5 |
3 |
1 |
24.89 |
31.79 |
27.85 |
24.89 |
31.79 |
3 |
26.87 |
0 |
memory |
20000 |
2 |
5 |
3 |
1 |
22.84 |
24.54 |
23.55 |
22.84 |
24.54 |
3 |
23.26 |
0 |
no |
20000 |
2 |
5 |
3 |
1 |
24.3 |
29.11 |
27.19 |
24.3 |
29.11 |
3 |
28.16 |
0 |
joblib |
20000 |
3 |
5 |
3 |
1 |
19.18 |
26.3 |
22.04 |
19.18 |
26.3 |
3 |
20.64 |
0 |
memory |
20000 |
3 |
5 |
3 |
1 |
21.35 |
29.79 |
26.07 |
21.35 |
29.79 |
3 |
27.07 |
0 |
no |
20000 |
3 |
5 |
3 |
1 |
22.34 |
26.51 |
25 |
22.34 |
26.51 |
3 |
26.15 |
0 |
joblib |
1000 |
1 |
10 |
3 |
1 |
2.099 |
2.566 |
2.344 |
2.099 |
2.566 |
3 |
2.367 |
0 |
memory |
1000 |
1 |
10 |
3 |
1 |
1.395 |
1.656 |
1.55 |
1.395 |
1.656 |
3 |
1.6 |
0 |
no |
1000 |
1 |
10 |
3 |
1 |
1.892 |
2.824 |
2.374 |
1.892 |
2.824 |
3 |
2.406 |
0 |
joblib |
1000 |
2 |
10 |
3 |
1 |
2.986 |
3.915 |
3.567 |
2.986 |
3.915 |
3 |
3.799 |
0 |
memory |
1000 |
2 |
10 |
3 |
1 |
1.818 |
2.047 |
1.954 |
1.818 |
2.047 |
3 |
1.998 |
0 |
no |
1000 |
2 |
10 |
3 |
1 |
2.193 |
2.872 |
2.589 |
2.193 |
2.872 |
3 |
2.701 |
0 |
joblib |
1000 |
3 |
10 |
3 |
1 |
2.43 |
2.837 |
2.611 |
2.43 |
2.837 |
3 |
2.566 |
0 |
memory |
1000 |
3 |
10 |
3 |
1 |
1.355 |
1.999 |
1.611 |
1.355 |
1.999 |
3 |
1.478 |
0 |
no |
1000 |
3 |
10 |
3 |
1 |
2.121 |
3.114 |
2.553 |
2.121 |
3.114 |
3 |
2.423 |
0 |
joblib |
10000 |
1 |
10 |
3 |
1 |
11.42 |
12.6 |
12.05 |
11.42 |
12.6 |
3 |
12.14 |
0 |
memory |
10000 |
1 |
10 |
3 |
1 |
8.256 |
12.67 |
10.11 |
8.256 |
12.67 |
3 |
9.419 |
0 |
no |
10000 |
1 |
10 |
3 |
1 |
10.9 |
12.12 |
11.65 |
10.9 |
12.12 |
3 |
11.94 |
0 |
joblib |
10000 |
2 |
10 |
3 |
1 |
9.461 |
10.88 |
10.4 |
9.461 |
10.88 |
3 |
10.85 |
0 |
memory |
10000 |
2 |
10 |
3 |
1 |
8.861 |
10.52 |
9.494 |
8.861 |
10.52 |
3 |
9.1 |
0 |
no |
10000 |
2 |
10 |
3 |
1 |
11.74 |
17.74 |
14.12 |
11.74 |
17.74 |
3 |
12.88 |
0 |
joblib |
10000 |
3 |
10 |
3 |
1 |
14.77 |
18.09 |
16.53 |
14.77 |
18.09 |
3 |
16.71 |
0 |
memory |
10000 |
3 |
10 |
3 |
1 |
12.91 |
14.14 |
13.72 |
12.91 |
14.14 |
3 |
14.11 |
0 |
no |
10000 |
3 |
10 |
3 |
1 |
16.75 |
19.33 |
18.33 |
16.75 |
19.33 |
3 |
18.9 |
0 |
joblib |
20000 |
1 |
10 |
3 |
1 |
21.82 |
27.33 |
24.12 |
21.82 |
27.33 |
3 |
23.2 |
0 |
memory |
20000 |
1 |
10 |
3 |
1 |
24.41 |
26.39 |
25.68 |
24.41 |
26.39 |
3 |
26.24 |
0 |
no |
20000 |
1 |
10 |
3 |
1 |
22.65 |
28.6 |
26.1 |
22.65 |
28.6 |
3 |
27.04 |
0 |
joblib |
20000 |
2 |
10 |
3 |
1 |
22.67 |
25.3 |
24.15 |
22.67 |
25.3 |
3 |
24.46 |
0 |
memory |
20000 |
2 |
10 |
3 |
1 |
20.16 |
28.96 |
23.9 |
20.16 |
28.96 |
3 |
22.57 |
0 |
no |
20000 |
2 |
10 |
3 |
1 |
24.36 |
25.48 |
24.81 |
24.36 |
25.48 |
3 |
24.61 |
0 |
joblib |
20000 |
3 |
10 |
3 |
1 |
19.6 |
29.83 |
25.95 |
19.6 |
29.83 |
3 |
28.42 |
0 |
memory |
20000 |
3 |
10 |
3 |
1 |
19.58 |
40.71 |
27.74 |
19.58 |
40.71 |
3 |
22.92 |
0 |
no |
20000 |
3 |
10 |
3 |
1 |
22.91 |
34.48 |
29.58 |
22.91 |
34.48 |
3 |
31.34 |
0 |
joblib |
1000 |
1 |
20 |
3 |
1 |
2.007 |
2.417 |
2.256 |
2.007 |
2.417 |
3 |
2.343 |
0 |
memory |
1000 |
1 |
20 |
3 |
1 |
1.396 |
1.49 |
1.453 |
1.396 |
1.49 |
3 |
1.474 |
0 |
no |
1000 |
1 |
20 |
3 |
1 |
2.056 |
2.842 |
2.512 |
2.056 |
2.842 |
3 |
2.639 |
0 |
joblib |
1000 |
2 |
20 |
3 |
1 |
2.218 |
2.34 |
2.271 |
2.218 |
2.34 |
3 |
2.256 |
0 |
memory |
1000 |
2 |
20 |
3 |
1 |
1.196 |
2.251 |
1.627 |
1.196 |
2.251 |
3 |
1.434 |
0 |
no |
1000 |
2 |
20 |
3 |
1 |
2.237 |
2.67 |
2.404 |
2.237 |
2.67 |
3 |
2.306 |
0 |
joblib |
1000 |
3 |
20 |
3 |
1 |
2.293 |
2.39 |
2.352 |
2.293 |
2.39 |
3 |
2.372 |
0 |
memory |
1000 |
3 |
20 |
3 |
1 |
1.304 |
1.38 |
1.333 |
1.304 |
1.38 |
3 |
1.314 |
0 |
no |
1000 |
3 |
20 |
3 |
1 |
2.309 |
2.512 |
2.393 |
2.309 |
2.512 |
3 |
2.358 |
0 |
joblib |
10000 |
1 |
20 |
3 |
1 |
9.696 |
9.876 |
9.815 |
9.696 |
9.876 |
3 |
9.873 |
0 |
memory |
10000 |
1 |
20 |
3 |
1 |
9.165 |
9.837 |
9.567 |
9.165 |
9.837 |
3 |
9.699 |
0 |
no |
10000 |
1 |
20 |
3 |
1 |
9.676 |
12.24 |
11.09 |
9.676 |
12.24 |
3 |
11.36 |
0 |
joblib |
10000 |
2 |
20 |
3 |
1 |
9.842 |
10.89 |
10.22 |
9.842 |
10.89 |
3 |
9.922 |
0 |
memory |
10000 |
2 |
20 |
3 |
1 |
8.27 |
10.54 |
9.606 |
8.27 |
10.54 |
3 |
10.01 |
0 |
no |
10000 |
2 |
20 |
3 |
1 |
11.54 |
12.53 |
11.9 |
11.54 |
12.53 |
3 |
11.63 |
0 |
joblib |
10000 |
3 |
20 |
3 |
1 |
9.975 |
10.16 |
10.05 |
9.975 |
10.16 |
3 |
10 |
0 |
memory |
10000 |
3 |
20 |
3 |
1 |
7.778 |
9.401 |
8.725 |
7.778 |
9.401 |
3 |
8.994 |
0 |
no |
10000 |
3 |
20 |
3 |
1 |
11.04 |
12.39 |
11.57 |
11.04 |
12.39 |
3 |
11.28 |
0 |
joblib |
20000 |
1 |
20 |
3 |
1 |
24.89 |
29.8 |
26.53 |
24.89 |
29.8 |
3 |
24.9 |
0 |
memory |
20000 |
1 |
20 |
3 |
1 |
20.2 |
29.04 |
25.39 |
20.2 |
29.04 |
3 |
26.94 |
0 |
no |
20000 |
1 |
20 |
3 |
1 |
27.14 |
31.51 |
29.55 |
27.14 |
31.51 |
3 |
30.01 |
0 |
joblib |
20000 |
2 |
20 |
3 |
1 |
22.52 |
25.54 |
24.47 |
22.52 |
25.54 |
3 |
25.34 |
0 |
memory |
20000 |
2 |
20 |
3 |
1 |
21.14 |
24.59 |
22.77 |
21.14 |
24.59 |
3 |
22.59 |
0 |
no |
20000 |
2 |
20 |
3 |
1 |
29.46 |
39.01 |
33.61 |
29.46 |
39.01 |
3 |
32.36 |
0 |
joblib |
20000 |
3 |
20 |
3 |
1 |
32.22 |
32.69 |
32.46 |
32.22 |
32.69 |
3 |
32.48 |
0 |
memory |
20000 |
3 |
20 |
3 |
1 |
22.5 |
160.4 |
69.74 |
22.5 |
160.4 |
3 |
26.38 |
0 |
no |
20000 |
3 |
20 |
3 |
1 |
32.19 |
43.45 |
38.42 |
32.19 |
43.45 |
3 |
39.62 |
0 |
Benchmark code#
# coding: utf-8
"""
Benchmark of grid search using caching.
"""
# Authors: Xavier Dupré (benchmark)
# License: MIT
from time import time
from itertools import combinations, chain
from itertools import combinations_with_replacement as combinations_w_r
import numpy as np
from numpy.random import rand
from numpy.testing import assert_almost_equal
import matplotlib.pyplot as plt
import pandas
import sklearn
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler, KBinsDiscretizer, PolynomialFeatures
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.utils._testing import ignore_warnings
import sklearn.utils
from mlinsights.mlbatch import PipelineCache, MLCache
##############################
# Starts a dask cluster
# +++++++++++++++++++++
has_dask = False
"""
# Does work yet.
from distributed import Client, LocalCluster
try:
cluster = LocalCluster()
print(cluster)
client = Client(cluster)
print(client)
has_dask = True
except Exception as e:
print("Cannot use dask due to {0}.".format(e))
has_dask = False
"""
##############################
# Implementations to benchmark
# ++++++++++++++++++++++++++++
from pymlbenchmark.benchmark import BenchPerf, BenchPerfTest
from pymlbenchmark.datasets import random_binary_classification
class GridSearchBenchPerfTest(BenchPerfTest):
def __init__(self, dim=None, n_jobs=1, **opts):
assert dim is not None
BenchPerfTest.__init__(self, **opts)
self.n_jobs = n_jobs
def _make_model(self, dim, cache, n_jobs):
if cache in (None, 'no'):
cl = Pipeline
ps = dict()
elif cache == 'joblib':
cl = Pipeline
ps = dict(memory='jb-%d-%d' % (dim, n_jobs))
elif cache == 'dask':
cl = Pipeline
ps = dict(memory='dk-%d-%d' % (dim, n_jobs))
elif cache == "memory":
cl = PipelineCache
ps = dict(cache_name='memory-%d-%d' % (dim, n_jobs))
else:
raise ValueError("Unknown cache value: '{0}'.".format(cache))
model = cl([
('scale', MinMaxScaler()),
('pca', PCA(2)),
('poly', PolynomialFeatures()),
('bins', KBinsDiscretizer()),
('lr', LogisticRegression(solver='liblinear'))],
**ps)
params_grid = {
'scale__feature_range': [(0, 1)],
'pca__n_components': [2, 4],
'poly__degree': [2, 3],
'bins__n_bins': [5],
'bins__encode': ["onehot-dense", "ordinal"],
'lr__penalty': ['l1', 'l2'],
}
return GridSearchCV(model, params_grid, n_jobs=n_jobs, verbose=0)
def data(self, N=None, dim=None, **opts):
# The benchmark requires a new datasets each time.
assert N is not None
assert dim is not None
return random_binary_classification(N, dim)
def fcts(self, dim=None, **kwargs):
# The function returns the prediction functions to tests.
global has_dask
options = ['no', 'joblib', 'memory']
if has_dask:
options.append('dask')
models = {}
for cache in options:
models[cache] = self._make_model(dim, cache, self.n_jobs)
def fit_model(X, y, cache):
if cache == "joblib":
sklearn.utils.parallel_backend("loky", self.n_jobs)
elif cache == "dask":
sklearn.utils.parallel_backend("dask", self.n_jobs)
else:
sklearn.utils.parallel_backend("threading", self.n_jobs)
model = models[cache]
model.fit(X, y)
if cache == 'memory':
MLCache.remove_cache(model.best_estimator_.cache_name)
res = []
for cache in sorted(models):
res.append({'test': cache, 'fct': lambda X,
y, c=cache: fit_model(X, y, c)})
return res
##############################
# Benchmark
# +++++++++
@ignore_warnings(category=(FutureWarning, UserWarning, DeprecationWarning))
def run_bench(repeat=3, verbose=False, number=1):
pbefore = dict(dim=[10, 15])
pafter = dict(N=[100, 1000, 10000], n_jobs=[1, 3])
bp = BenchPerf(pbefore, pafter, GridSearchBenchPerfTest)
with sklearn.config_context(assume_finite=True):
start = time()
results = list(bp.enumerate_run_benchs(repeat=repeat, verbose=verbose))
end = time()
results_df = pandas.DataFrame(results)
print("Total time = %0.3f sec\n" % (end - start))
return results_df
##############################
# Run the benchmark
# +++++++++++++++++
filename = "bench_plot_gridsearch_cache"
df = run_bench(verbose=True)
df.to_csv("%s.csv" % filename, index=False)
print(df.head())
if has_dask:
cluster.close()
#########################
# Extract information about the machine used
# ++++++++++++++++++++++++++++++++++++++++++
from pymlbenchmark.context import machine_information
pkgs = ['numpy', 'pandas', 'sklearn']
dfi = pandas.DataFrame(machine_information(pkgs))
dfi.to_csv("%s.time.csv" % filename, index=False)
print(dfi)
#############################
# Plot the results
# ++++++++++++++++
from pymlbenchmark.plotting import plot_bench_results
print(df.columns)
plot_bench_results(df, row_cols=['N'],
col_cols=['n_jobs'], x_value='dim',
hue_cols=['test'],
cmp_col_values='test',
title="GridSearchCV\nBenchmark caching strategies")
import sys
if "--quiet" not in sys.argv:
plt.show()