Note
Click here to download the full example code
Profling functions while using ONNX to extend pytorch#
The example creates a simple graph with many inputs so that the graph computing the gradient has many outputs. As the training of the whole model is done by torch, some time is spent just to exchange information between torch and onnxruntime. This time is minimized because the data is exchanged through DLPack protocol. That leaves the copy of the structures describing the data.
ONNX graph#
import os
import numpy
from pandas import DataFrame
import matplotlib.pyplot as plt
from pyquickhelper.pycode.profiling import profile, profile2graph, profile2df
import torch
from onnxruntime.training.ortmodule import ORTModule
def from_numpy(v, device=None, requires_grad=False):
"""
Convers a numpy array into a torch array and
sets *device* and *requires_grad*.
"""
v = torch.from_numpy(v)
if device is not None:
v = v.to(device)
v.requires_grad_(requires_grad)
return v
class NLayerNet(torch.nn.Module):
def __init__(self, D_in, D_out, lay=200):
super(NLayerNet, self).__init__()
H = 2
self.linears = [torch.nn.Linear(D_in, H)
for n in range(lay)]
self.linear2 = torch.nn.Linear(H * lay, D_out)
def forward(self, x):
xs = [torch.sigmoid((x)) for lay in self.linears]
conc = torch.cat(xs, dim=1)
y_pred = self.linear2(conc)
return y_pred
Training#
The training happens on cpu or gpu depending on what is available. We try first a few iteation to see how it goes.
def train_model(model, device, x, y, n_iter=100, learning_rate=1e-5,
profiler=None):
model = model.to(device)
x = from_numpy(x, requires_grad=True, device=device)
y = from_numpy(y, requires_grad=True, device=device)
criterion = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
losses = []
for t in range(n_iter):
def step_train():
y_pred = model(x)
loss = criterion(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss
loss = step_train()
losses.append(loss)
if profiler is not None:
profiler.step()
return losses
device_name = "cuda:0" if torch.cuda.is_available() else "cpu"
device = torch.device(device_name)
print("device:", device)
d_in, d_out, N = 2, 1, 100
x = numpy.random.randn(N, d_in).astype(numpy.float32)
y = numpy.random.randn(N, d_out).astype(numpy.float32)
model = ORTModule(NLayerNet(d_in, d_out))
train_losses = train_model(model, device, x, y, n_iter=10)
train_losses = numpy.array([t.cpu().detach().numpy().ravel()
for t in train_losses])
df = DataFrame(data=train_losses, columns=['train_loss'])
df['iter'] = df.index + 1
fig, ax = plt.subplots(1, 1, figsize=(8, 4))
df.plot(x="iter", y="train_loss", title="Training loss", ax=ax)
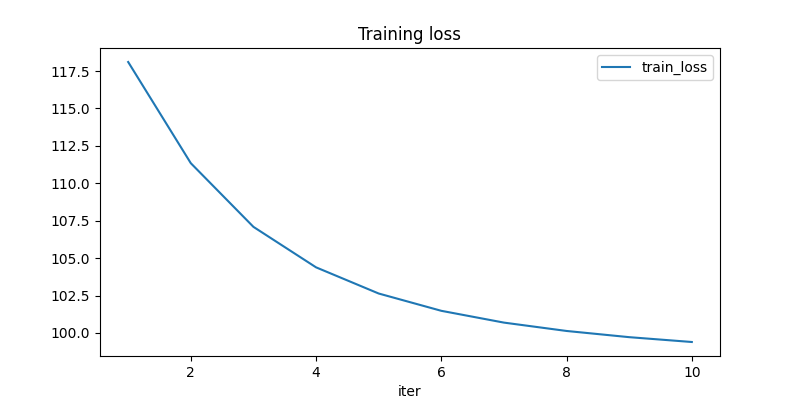
Out:
device: cpu
somewhere/workspace/deeponnxcustom/deeponnxcustom_UT_39_std/_venv/lib/python3.9/site-packages/onnxruntime/training/ortmodule/_training_manager.py:190: UserWarning: Fast path enabled - skipping checks. Rebuild graph: True, Execution agent: True, Device check: True
warnings.warn(
<AxesSubplot:title={'center':'Training loss'}, xlabel='iter'>
- Profiling
folder = os.path.abspath(os.getcwd()).split('deeponnxcustom')[0]
folder2 = os.path.abspath(os.path.split(
os.path.dirname(torch.__file__))[0])[:-6]
ps, text = profile(
lambda: train_model(model, device, x, y, n_iter=200))
print(type(ps))
print(text.replace(folder, "").replace(folder2, ""))
Out:
<class 'pstats.Stats'>
47085 function calls (45881 primitive calls) in 0.720 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.720 0.720 deeponnxcustom/deeponnxcustom_UT_39_std/_doc/examples/plot_profile_ortmodule.py:123(<lambda>)
1 0.004 0.004 0.720 0.720 deeponnxcustom/deeponnxcustom_UT_39_std/_doc/examples/plot_profile_ortmodule.py:66(train_model)
200 0.005 0.000 0.715 0.004 deeponnxcustom/deeponnxcustom_UT_39_std/_doc/examples/plot_profile_ortmodule.py:77(step_train)
200 0.002 0.000 0.329 0.002 site-packages/torch/_tensor.py:307(backward)
200 0.003 0.000 0.326 0.002 site-packages/torch/autograd/__init__.py:85(backward)
200 0.066 0.000 0.313 0.002 {method 'run_backward' of 'torch._C._EngineBase' objects}
400 0.006 0.000 0.276 0.001 site-packages/torch/nn/modules/module.py:1104(_call_impl)
200 0.003 0.000 0.247 0.001 site-packages/torch/autograd/function.py:243(apply)
200 0.027 0.000 0.244 0.001 site-packages/onnxruntime/training/ortmodule/_training_manager.py:113(backward)
200 0.001 0.000 0.232 0.001 site-packages/onnxruntime/training/ortmodule/_utils.py:390(_forward)
200 0.002 0.000 0.231 0.001 site-packages/onnxruntime/training/ortmodule/_utils.py:370(_forward)
200 0.011 0.000 0.227 0.001 site-packages/onnxruntime/training/ortmodule/_training_manager.py:169(forward)
200 0.192 0.001 0.192 0.001 site-packages/onnxruntime/training/ortmodule/_execution_agent.py:144(run_backward)
200 0.013 0.000 0.182 0.001 {built-in method apply}
200 0.007 0.000 0.169 0.001 site-packages/onnxruntime/training/ortmodule/_training_manager.py:67(forward)
200 0.026 0.000 0.159 0.001 site-packages/onnxruntime/training/ortmodule/_training_manager.py:30(execution_session_run_forward)
200 0.113 0.001 0.113 0.001 site-packages/onnxruntime/training/ortmodule/_execution_agent.py:134(run_forward)
200 0.007 0.000 0.067 0.000 site-packages/torch/optim/optimizer.py:83(wrapper)
200 0.010 0.000 0.038 0.000 site-packages/torch/optim/optimizer.py:189(zero_grad)
200 0.002 0.000 0.037 0.000 site-packages/torch/autograd/grad_mode.py:24(decorate_context)
200 0.001 0.000 0.036 0.000 site-packages/torch/nn/modules/loss.py:528(forward)
200 0.004 0.000 0.035 0.000 site-packages/torch/nn/functional.py:3234(mse_loss)
400 0.023 0.000 0.027 0.000 site-packages/onnxruntime/training/ortmodule/_utils.py:67(_ortvalues_to_torch_tensor)
200 0.004 0.000 0.027 0.000 site-packages/onnxruntime/training/ortmodule/_io.py:152(_combine_input_buffers_initializers)
200 0.009 0.000 0.025 0.000 site-packages/torch/optim/sgd.py:109(step)
400 0.005 0.000 0.021 0.000 site-packages/torch/autograd/profiler.py:435(__enter__)
200 0.020 0.000 0.020 0.000 {built-in method torch._C._nn.mse_loss}
400 0.015 0.000 0.015 0.000 {built-in method torch._ops.profiler._record_function_enter}
200 0.000 0.000 0.014 0.000 site-packages/onnxruntime/training/ortmodule/_io.py:184(<dictcomp>)
400 0.003 0.000 0.014 0.000 site-packages/torch/autograd/profiler.py:426(__init__)
200 0.001 0.000 0.013 0.000 site-packages/torch/nn/modules/module.py:1586(named_buffers)
203 0.003 0.000 0.012 0.000 site-packages/torch/nn/modules/module.py:1501(_named_members)
200 0.001 0.000 0.011 0.000 site-packages/onnxruntime/training/ortmodule/_gradient_accumulation_manager.py:50(extract_outputs_and_maybe_update_cache)
200 0.002 0.000 0.011 0.000 site-packages/torch/optim/_functional.py:158(sgd)
800 0.003 0.000 0.010 0.000 site-packages/onnxruntime/training/ortmodule/_graph_execution_manager.py:61(is_set)
400 0.010 0.000 0.010 0.000 {built-in method zeros}
200 0.004 0.000 0.010 0.000 site-packages/torch/functional.py:46(broadcast_tensors)
200 0.003 0.000 0.009 0.000 site-packages/torch/autograd/__init__.py:30(_make_grads)
400/200 0.002 0.000 0.008 0.000 site-packages/onnxruntime/training/ortmodule/_io.py:160(_expand_inputs)
400 0.008 0.000 0.008 0.000 {method 'add_' of 'torch._C._TensorBase' objects}
800 0.004 0.000 0.008 0.000 site-packages/onnxruntime/training/ortmodule/_utils.py:127(_torch_tensor_to_dlpack)
3831 0.004 0.000 0.008 0.000 {built-in method builtins.isinstance}
2408 0.006 0.000 0.007 0.000 site-packages/torch/_tensor.py:1092(grad)
1805/803 0.007 0.000 0.007 0.000 site-packages/torch/nn/modules/module.py:1668(named_modules)
400 0.003 0.000 0.007 0.000 site-packages/torch/autograd/profiler.py:439(__exit__)
800 0.002 0.000 0.006 0.000 site-packages/onnxruntime/training/ortmodule/_graph_execution_manager.py:69(is_disabled)
1600 0.004 0.000 0.005 0.000 /usr/local/lib/python3.9/enum.py:748(__contains__)
200 0.005 0.000 0.005 0.000 {built-in method ones_like}
400 0.005 0.000 0.005 0.000 {built-in method torch._ops.profiler._record_function_exit}
200 0.004 0.000 0.004 0.000 {built-in method broadcast_tensors}
600 0.001 0.000 0.004 0.000 /usr/local/lib/python3.9/abc.py:96(__instancecheck__)
204 0.002 0.000 0.004 0.000 site-packages/torch/autograd/grad_mode.py:126(__enter__)
1403 0.004 0.000 0.004 0.000 {built-in method builtins.len}
600 0.002 0.000 0.004 0.000 {built-in method _abc._abc_instancecheck}
200 0.001 0.000 0.004 0.000 site-packages/torch/autograd/grad_mode.py:82(clone)
1600 0.003 0.000 0.003 0.000 {method 'is_contiguous' of 'torch._C._TensorBase' objects}
408 0.002 0.000 0.003 0.000 site-packages/torch/autograd/grad_mode.py:215(__init__)
400 0.003 0.000 0.003 0.000 {method 'zero_' of 'torch._C._TensorBase' objects}
204 0.003 0.000 0.003 0.000 site-packages/torch/autograd/grad_mode.py:121(__init__)
800 0.003 0.000 0.003 0.000 {built-in method torch._C._to_dlpack}
400 0.003 0.000 0.003 0.000 {built-in method torch._C._get_tracing_state}
810 0.001 0.000 0.002 0.000 site-packages/torch/_tensor.py:706(__hash__)
200 0.001 0.000 0.002 0.000 site-packages/onnxruntime/training/ortmodule/_io.py:296(unflatten_user_output)
204 0.001 0.000 0.002 0.000 site-packages/torch/autograd/grad_mode.py:130(__exit__)
200 0.000 0.000 0.002 0.000 /usr/local/lib/python3.9/abc.py:100(__subclasscheck__)
600 0.001 0.000 0.002 0.000 site-packages/torch/nn/modules/module.py:1607(<lambda>)
200 0.002 0.000 0.002 0.000 site-packages/onnxruntime/training/ortmodule/_training_manager.py:57(<listcomp>)
3418 0.002 0.000 0.002 0.000 {built-in method torch._C._has_torch_function_unary}
200 0.001 0.000 0.002 0.000 {built-in method _abc._abc_subclasscheck}
402 0.001 0.000 0.001 0.000 {method 'requires_grad_' of 'torch._C._TensorBase' objects}
2001 0.001 0.000 0.001 0.000 {method 'append' of 'list' objects}
400 0.001 0.000 0.001 0.000 {method 'size' of 'torch._C._TensorBase' objects}
201 0.001 0.000 0.001 0.000 {method 'format' of 'str' objects}
200 0.001 0.000 0.001 0.000 site-packages/onnxruntime/training/ortmodule/_io.py:299(_replace_stub_with_tensor_value)
812 0.001 0.000 0.001 0.000 {built-in method torch._C.is_grad_enabled}
200 0.001 0.000 0.001 0.000 site-packages/torch/_VF.py:25(__getattr__)
200 0.001 0.000 0.001 0.000 site-packages/onnxruntime/training/ortmodule/_torch_module_ort.py:43(is_training)
200 0.001 0.000 0.001 0.000 site-packages/onnxruntime/training/ortmodule/_graph_execution_manager.py:44(__init__)
800 0.001 0.000 0.001 0.000 site-packages/onnxruntime/training/ortmodule/_training_manager.py:165(<genexpr>)
810 0.001 0.000 0.001 0.000 {built-in method builtins.id}
200 0.000 0.000 0.001 0.000 site-packages/onnxruntime/training/ortmodule/_gradient_accumulation_manager.py:66(maybe_update_cache_before_run)
1213 0.001 0.000 0.001 0.000 {method 'items' of 'collections.OrderedDict' objects}
200 0.000 0.000 0.000 0.000 site-packages/torch/autograd/function.py:184(set_materialize_grads)
1 0.000 0.000 0.000 0.000 site-packages/torch/nn/modules/module.py:803(to)
200 0.000 0.000 0.000 0.000 site-packages/torch/autograd/__init__.py:77(_tensor_or_tensors_to_tuple)
200 0.000 0.000 0.000 0.000 site-packages/onnxruntime/training/ortmodule/_io.py:71(is_primitive_type)
1 0.000 0.000 0.000 0.000 site-packages/onnxruntime/training/ortmodule/ortmodule.py:172(_apply)
1 0.000 0.000 0.000 0.000 site-packages/onnxruntime/training/ortmodule/_torch_module_ort.py:27(_apply)
3/1 0.000 0.000 0.000 0.000 site-packages/torch/nn/modules/module.py:576(_apply)
606 0.000 0.000 0.000 0.000 {method 'add' of 'set' objects}
200 0.000 0.000 0.000 0.000 site-packages/onnxruntime/training/ortmodule/_fallback.py:164(is_pending)
200 0.000 0.000 0.000 0.000 site-packages/torch/nn/_reduction.py:7(get_enum)
408 0.000 0.000 0.000 0.000 {built-in method torch._C._set_grad_enabled}
400 0.000 0.000 0.000 0.000 site-packages/onnxruntime/training/ortmodule/_gradient_accumulation_manager.py:45(enabled)
201 0.000 0.000 0.000 0.000 {built-in method builtins.getattr}
200 0.000 0.000 0.000 0.000 site-packages/onnxruntime/training/ortmodule/_graph_execution_manager_factory.py:17(__call__)
200 0.000 0.000 0.000 0.000 /usr/local/lib/python3.9/_collections_abc.py:311(__subclasshook__)
200 0.000 0.000 0.000 0.000 {built-in method builtins.hasattr}
1 0.000 0.000 0.000 0.000 site-packages/torch/optim/sgd.py:88(__init__)
200 0.000 0.000 0.000 0.000 {method 'extend' of 'list' objects}
1 0.000 0.000 0.000 0.000 site-packages/torch/optim/optimizer.py:33(__init__)
1 0.000 0.000 0.000 0.000 site-packages/torch/nn/modules/loss.py:525(__init__)
1 0.000 0.000 0.000 0.000 site-packages/torch/nn/modules/loss.py:15(__init__)
200 0.000 0.000 0.000 0.000 {method 'numel' of 'torch._C._TensorBase' objects}
1 0.000 0.000 0.000 0.000 site-packages/torch/nn/modules/module.py:254(__init__)
200 0.000 0.000 0.000 0.000 {built-in method torch._C._has_torch_function}
236 0.000 0.000 0.000 0.000 {method 'get' of 'dict' objects}
204 0.000 0.000 0.000 0.000 site-packages/torch/_jit_internal.py:957(is_scripting)
200 0.000 0.000 0.000 0.000 {built-in method torch._C._has_torch_function_variadic}
12 0.000 0.000 0.000 0.000 site-packages/torch/nn/modules/module.py:1188(__setattr__)
3 0.000 0.000 0.000 0.000 site-packages/onnxruntime/training/ortmodule/ortmodule.py:230(parameters)
3 0.000 0.000 0.000 0.000 site-packages/onnxruntime/training/ortmodule/_torch_module_ort.py:88(parameters)
3 0.000 0.000 0.000 0.000 site-packages/torch/nn/modules/module.py:1514(parameters)
3 0.000 0.000 0.000 0.000 site-packages/torch/nn/modules/module.py:1538(named_parameters)
1 0.000 0.000 0.000 0.000 site-packages/torch/optim/optimizer.py:243(add_param_group)
2 0.000 0.000 0.000 0.000 deeponnxcustom/deeponnxcustom_UT_39_std/_doc/examples/plot_profile_ortmodule.py:31(from_numpy)
4 0.000 0.000 0.000 0.000 site-packages/torch/nn/modules/module.py:901(convert)
5 0.000 0.000 0.000 0.000 site-packages/torch/nn/modules/module.py:1612(children)
4 0.000 0.000 0.000 0.000 site-packages/torch/nn/modules/module.py:580(compute_should_use_set_data)
6 0.000 0.000 0.000 0.000 {method 'to' of 'torch._C._TensorBase' objects}
5 0.000 0.000 0.000 0.000 site-packages/torch/nn/modules/module.py:1621(named_children)
2 0.000 0.000 0.000 0.000 {built-in method from_numpy}
1 0.000 0.000 0.000 0.000 site-packages/torch/optim/optimizer.py:78(_hook_for_profile)
4 0.000 0.000 0.000 0.000 {built-in method _has_compatible_shallow_copy_type}
2 0.000 0.000 0.000 0.000 {built-in method torch._C._log_api_usage_once}
1 0.000 0.000 0.000 0.000 {built-in method torch._C._nn._parse_to}
4 0.000 0.000 0.000 0.000 {method 'is_floating_point' of 'torch._C._TensorBase' objects}
2 0.000 0.000 0.000 0.000 site-packages/torch/nn/modules/module.py:1559(<lambda>)
6 0.000 0.000 0.000 0.000 {method 'setdefault' of 'dict' objects}
4 0.000 0.000 0.000 0.000 site-packages/torch/__future__.py:18(get_overwrite_module_params_on_conversion)
1 0.000 0.000 0.000 0.000 {method 'isdisjoint' of 'set' objects}
1 0.000 0.000 0.000 0.000 {method 'items' of 'dict' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
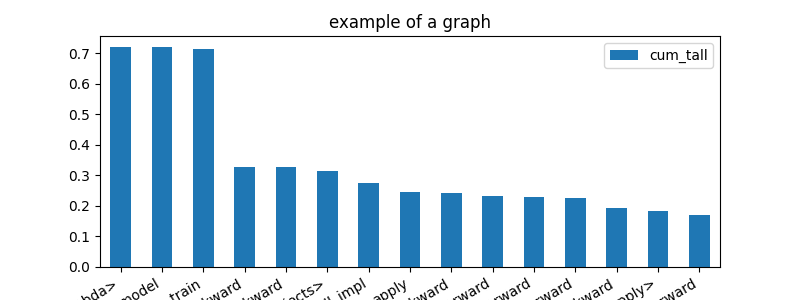
Same results in a graph.
df = profile2df(ps)
ax = df[['fct', 'cum_tall']].head(n=15).set_index(
'fct').plot(kind='bar', figsize=(8, 3), rot=30)
ax.set_title("example of a graph")
for la in ax.get_xticklabels():
la.set_horizontalalignment('right')
Presentation with partial call stack#
The previous presentation do not show any information
about where a function is called from. Let’s use
function profile2graph.
folder = folder.replace("\\", "/")
folder2 = folder2.replace("\\", "/")
def clean_text(x):
x = x.replace(folder, "").replace(folder2, "")
try:
root, nodes = profile2graph(ps, clean_text=clean_text)
text = root.to_text(fct_width=70)
print(text)
except RuntimeError as e:
print("structured profiling failed due to %r." % e)
Out:
<method 'append' of 'list' objects> -- 2001 2001 -- 0.00119 0.00119 -- None:0:<method 'append' of 'list' objects> (<method 'append' of 'list' objects>)
<method 'requires_grad_' of 'torch._C._TensorBase' objects> -- 402 402 -- 0.00127 0.00127 -- None:0:<method 'requires_grad_' of 'torch._C._TensorBase' objects> (<method 'requires_grad_' of 'torch._C._TensorBase' objects>)
<method 'to' of 'torch._C._TensorBase' objects> -- 6 6 -- 0.00003 0.00003 -- None:0:<method 'to' of 'torch._C._TensorBase' objects> (<method 'to' of 'torch._C._TensorBase' objects>)
<built-in method torch._C._has_torch_function_unary> -- 3418 3418 -- 0.00153 0.00153 -- None:0:<built-in method torch._C._has_torch_function_unary> (<built-in method torch._C._has_torch_function_unary>)
<method 'format' of 'str' objects> -- 201 201 -- 0.00113 0.00113 -- None:0:<method 'format' of 'str' objects> (<method 'format' of 'str' objects>)
<method 'get' of 'dict' objects> -- 236 236 -- 0.00017 0.00017 -- None:0:<method 'get' of 'dict' objects> (<method 'get' of 'dict' objects>)
<built-in method torch._C._log_api_usage_once> -- 2 2 -- 0.00002 0.00002 -- None:0:<built-in method torch._C._log_api_usage_once> (<built-in method torch._C._log_api_usage_once>)
<built-in method builtins.isinstance> -- 3831 3831 -- 0.00359 0.00782 -- None:0:<built-in method builtins.isinstance> (<built-in method builtins.isinstance>)
__instancecheck__ -- 600 600 -- 0.00057 0.00423 -- None:96:__instancecheck__ (__instancecheck__)
<built-in method _abc._abc_instancecheck> -- 600 600 -- 0.00189 0.00366 -- None:0:<built-in method _abc._abc_instancecheck> (<built-in method _abc._abc_instancecheck>)
__subclasscheck__ -- 200 200 -- 0.00027 0.00178 -- None:100:__subclasscheck__ (__subclasscheck__)
<built-in method _abc._abc_subclasscheck> -- 200 200 -- 0.00122 0.00150 -- None:0:<built-in method _abc._abc_subclasscheck> (<built-in method _abc._abc_subclasscheck>)
__subclasshook__ -- 200 200 -- 0.00028 0.00028 -- None:311:__subclasshook__ (__subclasshook__)
<built-in method builtins.len> -- 1403 1403 -- 0.00384 0.00384 -- None:0:<built-in method builtins.len> (<built-in method builtins.len>)
<built-in method builtins.getattr> -- 201 201 -- 0.00030 0.00030 -- None:0:<built-in method builtins.getattr> (<built-in method builtins.getattr>)
<built-in method torch._C.is_grad_enabled> -- 812 812 -- 0.00103 0.00103 -- None:0:<built-in method torch._C.is_grad_enabled> (<built-in method torch._C.is_grad_enabled>)
<method 'items' of 'collections.OrderedDict' objects> -- 1213 1213 -- 0.00059 0.00059 -- None:0:<method 'items' of 'collections.OrderedDict' objects> (<method 'items' of 'collections.OrderedDict' objects>)
<method 'is_contiguous' of 'torch._C._TensorBase' objects> -- 1600 1600 -- 0.00309 0.00309 -- None:0:<method 'is_contiguous' of 'torch._C._TensorBase' objects> (<method 'is_contiguous' of 'torch._C._TensorBase' objects>)
<method 'add' of 'set' objects> -- 606 606 -- 0.00041 0.00042 -- None:0:<method 'add' of 'set' objects> (<method 'add' of 'set' objects>)
__hash__ -- 2 2 -- 0.00000 0.00000 -- None:706:__hash__ (__hash__) +++
enabled -- 400 400 -- 0.00035 0.00035 -- None:45:enabled (enabled)
is_set -- 800 800 -- 0.00297 0.01033 -- None:61:is_set (is_set)
is_disabled -- 800 800 -- 0.00232 0.00554 -- None:69:is_disabled (is_disabled)
__contains__ -- 800 800 -- 0.00280 0.00322 -- None:748:__contains__ (__contains__) +++
__contains__ -- 800 800 -- 0.00157 0.00182 -- None:748:__contains__ (__contains__) +++
_ortvalues_to_torch_tensor -- 400 400 -- 0.02332 0.02706 -- None:67:_ortvalues_to_torch_tensor (_ortvalues_to_torch_tensor)
<built-in method builtins.isinstance> -- 400 400 -- 0.00034 0.00034 -- None:0:<built-in method builtins.isinstance> (<built-in method builtins.isinstance>) +++
<built-in method builtins.len> -- 800 800 -- 0.00340 0.00340 -- None:0:<built-in method builtins.len> (<built-in method builtins.len>) +++
__init__ -- 204 204 -- 0.00252 0.00268 -- None:121:__init__ (__init__)
is_scripting -- 204 204 -- 0.00016 0.00016 -- None:957:is_scripting (is_scripting)
<lambda> -- 1 1 -- 0.00002 0.71976 -- None:123:<lambda> (<lambda>)
train_model -- 1 1 -- 0.00369 0.71974 -- None:66:train_model (train_model)
<method 'append' of 'list' objects> -- 200 200 -- 0.00020 0.00020 -- None:0:<method 'append' of 'list' objects> (<method 'append' of 'list' objects>) +++
from_numpy -- 2 2 -- 0.00002 0.00006 -- None:31:from_numpy (from_numpy)
<built-in method from_numpy> -- 2 2 -- 0.00002 0.00002 -- None:0:<built-in method from_numpy> (<built-in method from_numpy>)
<method 'requires_grad_' of ...ch._C._TensorBase' objects> -- 2 2 -- 0.00001 0.00001 -- None:0:<method 'requires_grad_' of 'torch._C._TensorBase' objects> (<method 'requires_grad_' of 'torch._C._TensorBase' objects>) +++
<method 'to' of 'torch._C._TensorBase' objects> -- 2 2 -- 0.00001 0.00001 -- None:0:<method 'to' of 'torch._C._TensorBase' objects> (<method 'to' of 'torch._C._TensorBase' objects>) +++
step_train -- 200 200 -- 0.00550 0.71484 -- None:77:step_train (step_train)
wrapper -- 200 200 -- 0.00674 0.06712 -- None:83:wrapper (wrapper)
<method 'format' of 'str' objects> -- 200 200 -- 0.00113 0.00113 -- None:0:<method 'format' of 'str' objects> (<method 'format' of 'str' objects>) +++
decorate_context -- 200 200 -- 0.00241 0.03668 -- None:24:decorate_context (decorate_context)
clone -- 200 200 -- 0.00088 0.00353 -- None:82:clone (clone)
__init__ -- 200 200 -- 0.00249 0.00264 -- None:121:__init__ (__init__) +++
step -- 200 200 -- 0.00870 0.02490 -- None:109:step (step)
<method 'append' of 'list' objects> -- 1200 1200 -- 0.00055 0.00055 -- None:0:<method 'append' of 'list' objects> (<method 'append' of 'list' objects>) +++
sgd -- 200 200 -- 0.00244 0.01058 -- None:158:sgd (sgd)
<method 'add_' of 't...ensorBase' objects> -- 400 400 -- 0.00814 0.00814 -- None:0:<method 'add_' of 'torch._C._TensorBase' objects> (<method 'add_' of 'torch._C._TensorBase' objects>)
__hash__ -- 802 802 -- 0.00133 0.00238 -- None:706:__hash__ (__hash__) +++
grad -- 800 800 -- 0.00229 0.00268 -- None:1092:grad (grad) +++
__enter__ -- 200 200 -- 0.00183 0.00388 -- None:126:__enter__ (__enter__) +++
__exit__ -- 200 200 -- 0.00091 0.00197 -- None:130:__exit__ (__exit__) +++
__init__ -- 200 200 -- 0.00175 0.00792 -- None:426:__init__ (__init__) +++
__enter__ -- 200 200 -- 0.00267 0.01103 -- None:435:__enter__ (__enter__) +++
__exit__ -- 200 200 -- 0.00128 0.00363 -- None:439:__exit__ (__exit__) +++
zero_grad -- 200 200 -- 0.01026 0.03777 -- None:189:zero_grad (zero_grad)
<method 'requires_grad_' o...._C._TensorBase' objects> -- 400 400 -- 0.00126 0.00126 -- None:0:<method 'requires_grad_' of 'torch._C._TensorBase' objects> (<method 'requires_grad_' of 'torch._C._TensorBase' objects>) +++
<method 'zero_' of 'torch._C._TensorBase' objects> -- 400 400 -- 0.00270 0.00270 -- None:0:<method 'zero_' of 'torch._C._TensorBase' objects> (<method 'zero_' of 'torch._C._TensorBase' objects>)
<method 'get' of 'dict' objects> -- 200 200 -- 0.00016 0.00016 -- None:0:<method 'get' of 'dict' objects> (<method 'get' of 'dict' objects>) +++
<built-in method builtins.hasattr> -- 200 200 -- 0.00024 0.00024 -- None:0:<built-in method builtins.hasattr> (<built-in method builtins.hasattr>)
__init__ -- 200 200 -- 0.00159 0.00574 -- None:426:__init__ (__init__) +++
__enter__ -- 200 200 -- 0.00249 0.00952 -- None:435:__enter__ (__enter__) +++
__exit__ -- 200 200 -- 0.00127 0.00343 -- None:439:__exit__ (__exit__) +++
grad -- 1600 1600 -- 0.00377 0.00447 -- None:1092:grad (grad) +++
backward -- 200 200 -- 0.00217 0.32861 -- None:307:backward (backward)
<built-in method torch._C._has_torch_function_unary> -- 200 200 -- 0.00010 0.00010 -- None:0:<built-in method torch._C._has_torch_function_unary> (<built-in method torch._C._has_torch_function_unary>) +++
backward -- 200 200 -- 0.00300 0.32634 -- None:85:backward (backward)
<method 'run_backward' o...C._EngineBase' objects> -- 200 200 -- 0.06631 0.31330 -- None:0:<method 'run_backward' of 'torch._C._EngineBase' objects> (<method 'run_backward' of 'torch._C._EngineBase' objects>)
apply -- 200 200 -- 0.00347 0.24699 -- None:243:apply (apply)
backward -- 200 200 -- 0.02723 0.24352 -- None:113:backward (backward)
<method 'is_contig...sorBase' objects> -- 200 200 -- 0.00051 0.00051 -- None:0:<method 'is_contiguous' of 'torch._C._TensorBase' objects> (<method 'is_contiguous' of 'torch._C._TensorBase' objects>) +++
<built-in method builtins.len> -- 200 200 -- 0.00014 0.00014 -- None:0:<built-in method builtins.len> (<built-in method builtins.len>) +++
is_set -- 200 200 -- 0.00097 0.00333 -- None:61:is_set (is_set) +++
_ortvalues_to_torch_tensor -- 200 200 -- 0.01468 0.01692 -- None:67:_ortvalues_to_torch_tensor (_ortvalues_to_torch_tensor) +++
_torch_tensor_to_dlpack -- 200 200 -- 0.00127 0.00229 -- None:127:_torch_tensor_to_dlpack (_torch_tensor_to_dlpack) +++
run_backward -- 200 200 -- 0.19233 0.19233 -- None:144:run_backward (run_backward)
<genexpr> -- 800 800 -- 0.00076 0.00076 -- None:165:<genexpr> (<genexpr>)
<built-in method builtins.isinstance> -- 400 400 -- 0.00044 0.00044 -- None:0:<built-in method builtins.isinstance> (<built-in method builtins.isinstance>) +++
<built-in method builtins.len> -- 200 200 -- 0.00013 0.00013 -- None:0:<built-in method builtins.len> (<built-in method builtins.len>) +++
_make_grads -- 200 200 -- 0.00328 0.00899 -- None:30:_make_grads (_make_grads)
<built-in method ones_like> -- 200 200 -- 0.00499 0.00499 -- None:0:<built-in method ones_like> (<built-in method ones_like>)
<method 'numel' of 'to..._TensorBase' objects> -- 200 200 -- 0.00021 0.00021 -- None:0:<method 'numel' of 'torch._C._TensorBase' objects> (<method 'numel' of 'torch._C._TensorBase' objects>)
<method 'append' of 'list' objects> -- 200 200 -- 0.00021 0.00021 -- None:0:<method 'append' of 'list' objects> (<method 'append' of 'list' objects>) +++
<built-in method builtins.isinstance> -- 200 200 -- 0.00030 0.00030 -- None:0:<built-in method builtins.isinstance> (<built-in method builtins.isinstance>) +++
_tensor_or_tensors_to_tuple -- 200 200 -- 0.00048 0.00048 -- None:77:_tensor_or_tensors_to_tuple (_tensor_or_tensors_to_tuple)
_call_impl -- 400 400 -- 0.00556 0.27585 -- None:1104:_call_impl (_call_impl)
<built-in method torch._C._get_tracing_state> -- 400 400 -- 0.00255 0.00255 -- None:0:<built-in method torch._C._get_tracing_state> (<built-in method torch._C._get_tracing_state>)
_forward -- 200 200 -- 0.00109 0.23171 -- None:390:_forward (_forward)
_forward -- 200 200 -- 0.00232 0.23062 -- None:370:_forward (_forward)
__call__ -- 200 200 -- 0.00029 0.00029 -- None:17:__call__ (__call__)
is_training -- 200 200 -- 0.00071 0.00096 -- None:43:is_training (is_training)
<built-in method torch._C.is_grad_enabled> -- 200 200 -- 0.00025 0.00025 -- None:0:<built-in method torch._C.is_grad_enabled> (<built-in method torch._C.is_grad_enabled>) +++
forward -- 200 200 -- 0.01069 0.22706 -- None:169:forward (forward)
<built-in method apply> -- 200 200 -- 0.01260 0.18175 -- None:0:<built-in method apply> (<built-in method apply>)
forward -- 200 200 -- 0.00726 0.16915 -- None:67:forward (forward)
execution_session_run_forward -- 200 200 -- 0.02560 0.15933 -- None:30:execution_session_run_forward (execution_session_run_forward)
<method 'is_co...ase' objects> -- 600 600 -- 0.00133 0.00133 -- None:0:<method 'is_contiguous' of 'torch._C._TensorBase' objects> (<method 'is_contiguous' of 'torch._C._TensorBase' objects>) +++
<built-in method builtins.len> -- 200 200 -- 0.00017 0.00017 -- None:0:<built-in method builtins.len> (<built-in method builtins.len>) +++
__init__ -- 200 200 -- 0.00083 0.00083 -- None:44:__init__ (__init__)
extract_output..._update_cache -- 200 200 -- 0.00112 0.01138 -- None:50:extract_outputs_and_maybe_update_cache (extract_outputs_and_maybe_update_cache)
enabled -- 200 200 -- 0.00012 0.00012 -- None:45:enabled (enabled) +++
_ortvalues_to_torch_tensor -- 200 200 -- 0.00864 0.01014 -- None:67:_ortvalues_to_torch_tensor (_ortvalues_to_torch_tensor) +++
<listcomp> -- 200 200 -- 0.00155 0.00155 -- None:57:<listcomp> (<listcomp>)
_torch_tensor_to_dlpack -- 600 600 -- 0.00292 0.00577 -- None:127:_torch_tensor_to_dlpack (_torch_tensor_to_dlpack) +++
run_forward -- 200 200 -- 0.11268 0.11268 -- None:134:run_forward (run_forward)
is_set -- 200 200 -- 0.00062 0.00207 -- None:61:is_set (is_set) +++
set_materialize_grads -- 200 200 -- 0.00049 0.00049 -- None:184:set_materialize_grads (set_materialize_grads)
is_set -- 400 400 -- 0.00138 0.00493 -- None:61:is_set (is_set) +++
maybe_update_cache_before_run -- 200 200 -- 0.00047 0.00069 -- None:66:maybe_update_cache_before_run (maybe_update_cache_before_run)
enabled -- 200 200 -- 0.00023 0.00023 -- None:45:enabled (enabled) +++
_combine_input_buffers_initializers -- 200 200 -- 0.00369 0.02657 -- None:152:_combine_input_buffers_initializers (_combine_input_buffers_initializers)
<method 'append' of 'list' objects> -- 200 200 -- 0.00010 0.00010 -- None:0:<method 'append' of 'list' objects> (<method 'append' of 'list' objects>) +++
<method 'extend' of 'list' objects> -- 200 200 -- 0.00023 0.00023 -- None:0:<method 'extend' of 'list' objects> (<method 'extend' of 'list' objects>)
is_primitive_type -- 200 200 -- 0.00048 0.00048 -- None:71:is_primitive_type (is_primitive_type)
_expand_inputs -- 200 200 -- 0.00134 0.00833 -- None:160:_expand_inputs (_expand_inputs) +++
<dictcomp> -- 200 200 -- 0.00041 0.01374 -- None:184:<dictcomp> (<dictcomp>)
named_buffers -- 200 200 -- 0.00141 0.01333 -- None:1586:named_buffers (named_buffers)
_named_members -- 200 200 -- 0.00308 0.01191 -- None:1501:_named_members (_named_members) +++
is_pending -- 200 200 -- 0.00041 0.00041 -- None:164:is_pending (is_pending)
unflatten_user_output -- 200 200 -- 0.00099 0.00202 -- None:296:unflatten_user_output (unflatten_user_output)
_replace_stub_with_tensor_value -- 200 200 -- 0.00094 0.00104 -- None:299:_replace_stub_with_tensor_value (_replace_stub_with_tensor_value)
<built-in method...ins.isinstance> -- 200 200 -- 0.00009 0.00009 -- None:0:<built-in method builtins.isinstance> (<built-in method builtins.isinstance>) +++
forward -- 200 200 -- 0.00128 0.03603 -- None:528:forward (forward)
mse_loss -- 200 200 -- 0.00378 0.03475 -- None:3234:mse_loss (mse_loss)
<built-in method torch...ch_function_variadic> -- 200 200 -- 0.00016 0.00016 -- None:0:<built-in method torch._C._has_torch_function_variadic> (<built-in method torch._C._has_torch_function_variadic>)
<method 'size' of 'tor..._TensorBase' objects> -- 400 400 -- 0.00118 0.00118 -- None:0:<method 'size' of 'torch._C._TensorBase' objects> (<method 'size' of 'torch._C._TensorBase' objects>)
<built-in method torch._C._nn.mse_loss> -- 200 200 -- 0.01965 0.01965 -- None:0:<built-in method torch._C._nn.mse_loss> (<built-in method torch._C._nn.mse_loss>)
get_enum -- 200 200 -- 0.00040 0.00040 -- None:7:get_enum (get_enum)
broadcast_tensors -- 200 200 -- 0.00399 0.00958 -- None:46:broadcast_tensors (broadcast_tensors)
<built-in method tor...has_torch_function> -- 200 200 -- 0.00018 0.00018 -- None:0:<built-in method torch._C._has_torch_function> (<built-in method torch._C._has_torch_function>)
<built-in method broadcast_tensors> -- 200 200 -- 0.00442 0.00442 -- None:0:<built-in method broadcast_tensors> (<built-in method broadcast_tensors>)
__getattr__ -- 200 200 -- 0.00068 0.00098 -- None:25:__getattr__ (__getattr__)
<built-in method builtins.getattr> -- 200 200 -- 0.00030 0.00030 -- None:0:<built-in method builtins.getattr> (<built-in method builtins.getattr>) +++
__init__ -- 1 1 -- 0.00001 0.00024 -- None:88:__init__ (__init__)
__init__ -- 1 1 -- 0.00003 0.00023 -- None:33:__init__ (__init__)
<built-in method torch._C._log_api_usage_once> -- 1 1 -- 0.00000 0.00000 -- None:0:<built-in method torch._C._log_api_usage_once> (<built-in method torch._C._log_api_usage_once>) +++
<built-in method builtins.isinstance> -- 2 2 -- 0.00000 0.00000 -- None:0:<built-in method builtins.isinstance> (<built-in method builtins.isinstance>) +++
<built-in method builtins.len> -- 1 1 -- 0.00000 0.00000 -- None:0:<built-in method builtins.len> (<built-in method builtins.len>) +++
_hook_for_profile -- 1 1 -- 0.00002 0.00002 -- None:78:_hook_for_profile (_hook_for_profile)
<method 'format' of 'str' objects> -- 1 1 -- 0.00000 0.00000 -- None:0:<method 'format' of 'str' objects> (<method 'format' of 'str' objects>) +++
<built-in method builtins.getattr> -- 1 1 -- 0.00000 0.00000 -- None:0:<built-in method builtins.getattr> (<built-in method builtins.getattr>) +++
parameters -- 3 3 -- 0.00001 0.00010 -- None:230:parameters (parameters)
parameters -- 3 3 -- 0.00001 0.00009 -- None:88:parameters (parameters)
parameters -- 3 3 -- 0.00001 0.00008 -- None:1514:parameters (parameters)
named_parameters -- 3 3 -- 0.00001 0.00007 -- None:1538:named_parameters (named_parameters)
_named_members -- 3 3 -- 0.00002 0.00007 -- None:1501:_named_members (_named_members) +++
add_param_group -- 1 1 -- 0.00005 0.00007 -- None:243:add_param_group (add_param_group)
<method 'append' of 'list' objects> -- 1 1 -- 0.00000 0.00000 -- None:0:<method 'append' of 'list' objects> (<method 'append' of 'list' objects>) +++
<method 'setdefault' of 'dict' objects> -- 6 6 -- 0.00000 0.00000 -- None:0:<method 'setdefault' of 'dict' objects> (<method 'setdefault' of 'dict' objects>)
<method 'items' of 'dict' objects> -- 1 1 -- 0.00000 0.00000 -- None:0:<method 'items' of 'dict' objects> (<method 'items' of 'dict' objects>)
<method 'isdisjoint' of 'set' objects> -- 1 1 -- 0.00000 0.00000 -- None:0:<method 'isdisjoint' of 'set' objects> (<method 'isdisjoint' of 'set' objects>)
<built-in method builtins.isinstance> -- 5 5 -- 0.00000 0.00000 -- None:0:<built-in method builtins.isinstance> (<built-in method builtins.isinstance>) +++
<built-in method builtins.len> -- 2 2 -- 0.00000 0.00000 -- None:0:<built-in method builtins.len> (<built-in method builtins.len>) +++
__hash__ -- 4 4 -- 0.00000 0.00001 -- None:706:__hash__ (__hash__) +++
__init__ -- 1 1 -- 0.00001 0.00022 -- None:525:__init__ (__init__)
__init__ -- 1 1 -- 0.00001 0.00021 -- None:15:__init__ (__init__)
__init__ -- 1 1 -- 0.00004 0.00019 -- None:254:__init__ (__init__)
<built-in method torch._C._log_api_usage_once> -- 1 1 -- 0.00001 0.00001 -- None:0:<built-in method torch._C._log_api_usage_once> (<built-in method torch._C._log_api_usage_once>) +++
__setattr__ -- 11 11 -- 0.00010 0.00014 -- None:1188:__setattr__ (__setattr__) +++
__setattr__ -- 1 1 -- 0.00001 0.00001 -- None:1188:__setattr__ (__setattr__) +++
to -- 1 1 -- 0.00002 0.00049 -- None:803:to (to)
<built-in method torch._C._nn._parse_to> -- 1 1 -- 0.00001 0.00001 -- None:0:<built-in method torch._C._nn._parse_to> (<built-in method torch._C._nn._parse_to>)
_apply -- 1 1 -- 0.00001 0.00045 -- None:172:_apply (_apply)
_apply -- 1 1 -- 0.00001 0.00045 -- None:27:_apply (_apply)
_apply -- 1 1 -- 0.00002 0.00044 -- None:576:_apply (_apply) +++
__enter__ -- 204 204 -- 0.00185 0.00394 -- None:126:__enter__ (__enter__)
<built-in method torch._C.is_grad_enabled> -- 204 204 -- 0.00037 0.00037 -- None:0:<built-in method torch._C.is_grad_enabled> (<built-in method torch._C.is_grad_enabled>) +++
__init__ -- 204 204 -- 0.00133 0.00172 -- None:215:__init__ (__init__) +++
_torch_tensor_to_dlpack -- 800 800 -- 0.00419 0.00806 -- None:127:_torch_tensor_to_dlpack (_torch_tensor_to_dlpack)
<built-in method torch._C._to_dlpack> -- 800 800 -- 0.00263 0.00263 -- None:0:<built-in method torch._C._to_dlpack> (<built-in method torch._C._to_dlpack>)
<method 'is_contiguous' of 'torch._C._TensorBase' objects> -- 800 800 -- 0.00125 0.00125 -- None:0:<method 'is_contiguous' of 'torch._C._TensorBase' objects> (<method 'is_contiguous' of 'torch._C._TensorBase' objects>) +++
__exit__ -- 204 204 -- 0.00092 0.00200 -- None:130:__exit__ (__exit__)
__init__ -- 204 204 -- 0.00069 0.00108 -- None:215:__init__ (__init__) +++
_expand_inputs -- 200 400 -- 0.00227 0.00833 -- None:160:_expand_inputs (_expand_inputs)
<method 'append' of 'list' objects> -- 200 200 -- 0.00012 0.00012 -- None:0:<method 'append' of 'list' objects> (<method 'append' of 'list' objects>) +++
<built-in method builtins.isinstance> -- 1000 1000 -- 0.00170 0.00594 -- None:0:<built-in method builtins.isinstance> (<built-in method builtins.isinstance>) +++
_expand_inputs -- 200 200 -- 0.00093 0.00286 -- None:160:_expand_inputs (_expand_inputs) +++
__init__ -- 408 408 -- 0.00202 0.00280 -- None:215:__init__ (__init__)
<built-in method torch._C._set_grad_enabled> -- 408 408 -- 0.00036 0.00036 -- None:0:<built-in method torch._C._set_grad_enabled> (<built-in method torch._C._set_grad_enabled>)
<built-in method torch._C.is_grad_enabled> -- 408 408 -- 0.00042 0.00042 -- None:0:<built-in method torch._C.is_grad_enabled> (<built-in method torch._C.is_grad_enabled>) +++
__init__ -- 400 400 -- 0.00333 0.01366 -- None:426:__init__ (__init__)
<built-in method zeros> -- 400 400 -- 0.01032 0.01032 -- None:0:<built-in method zeros> (<built-in method zeros>)
__enter__ -- 400 400 -- 0.00516 0.02055 -- None:435:__enter__ (__enter__)
<built-in method torch._ops.profiler._record_function_enter> -- 400 400 -- 0.01539 0.01539 -- None:0:<built-in method torch._ops.profiler._record_function_enter> (<built-in method torch._ops.profiler._record_function_enter>)
__exit__ -- 400 400 -- 0.00255 0.00706 -- None:439:__exit__ (__exit__)
<built-in method torch._ops.profiler._record_function_exit> -- 400 400 -- 0.00451 0.00451 -- None:0:<built-in method torch._ops.profiler._record_function_exit> (<built-in method torch._ops.profiler._record_function_exit>)
_apply -- 1 3 -- 0.00013 0.00044 -- None:576:_apply (_apply)
<method 'items' of 'collections.OrderedDict' objects> -- 6 6 -- 0.00000 0.00000 -- None:0:<method 'items' of 'collections.OrderedDict' objects> (<method 'items' of 'collections.OrderedDict' objects>) +++
__init__ -- 4 4 -- 0.00003 0.00003 -- None:121:__init__ (__init__) +++
__enter__ -- 4 4 -- 0.00003 0.00006 -- None:126:__enter__ (__enter__) +++
__exit__ -- 4 4 -- 0.00002 0.00004 -- None:130:__exit__ (__exit__) +++
_apply -- 2 1 -- 0.00012 0.00040 -- None:576:_apply (_apply) +++
compute_should_use_set_data -- 4 4 -- 0.00002 0.00004 -- None:580:compute_should_use_set_data (compute_should_use_set_data)
<built-in method _has_compatible_shallow_copy_type> -- 4 4 -- 0.00002 0.00002 -- None:0:<built-in method _has_compatible_shallow_copy_type> (<built-in method _has_compatible_shallow_copy_type>)
get_overwrite_module_params_on_conversion -- 4 4 -- 0.00000 0.00000 -- None:18:get_overwrite_module_params_on_conversion (get_overwrite_module_params_on_conversion)
convert -- 4 4 -- 0.00003 0.00006 -- None:901:convert (convert)
<method 'to' of 'torch._C._TensorBase' objects> -- 4 4 -- 0.00002 0.00002 -- None:0:<method 'to' of 'torch._C._TensorBase' objects> (<method 'to' of 'torch._C._TensorBase' objects>) +++
<method 'is_floating_point' of 'torch._C._TensorBase' objects> -- 4 4 -- 0.00001 0.00001 -- None:0:<method 'is_floating_point' of 'torch._C._TensorBase' objects> (<method 'is_floating_point' of 'torch._C._TensorBase' objects>)
grad -- 8 8 -- 0.00003 0.00003 -- None:1092:grad (grad) +++
children -- 5 5 -- 0.00001 0.00005 -- None:1612:children (children)
named_children -- 5 5 -- 0.00003 0.00003 -- None:1621:named_children (named_children)
<method 'items' of 'collections.OrderedDict' objects> -- 3 3 -- 0.00000 0.00000 -- None:0:<method 'items' of 'collections.OrderedDict' objects> (<method 'items' of 'collections.OrderedDict' objects>) +++
<method 'add' of 'set' objects> -- 2 2 -- 0.00000 0.00000 -- None:0:<method 'add' of 'set' objects> (<method 'add' of 'set' objects>) +++
__hash__ -- 810 810 -- 0.00134 0.00240 -- None:706:__hash__ (__hash__)
<built-in method torch._C._has_torch_function_unary> -- 810 810 -- 0.00034 0.00034 -- None:0:<built-in method torch._C._has_torch_function_unary> (<built-in method torch._C._has_torch_function_unary>) +++
<built-in method builtins.id> -- 810 810 -- 0.00072 0.00072 -- None:0:<built-in method builtins.id> (<built-in method builtins.id>)
__contains__ -- 1600 1600 -- 0.00437 0.00504 -- None:748:__contains__ (__contains__)
<built-in method builtins.isinstance> -- 1600 1600 -- 0.00067 0.00067 -- None:0:<built-in method builtins.isinstance> (<built-in method builtins.isinstance>) +++
grad -- 2408 2408 -- 0.00609 0.00718 -- None:1092:grad (grad)
<built-in method torch._C._has_torch_function_unary> -- 2408 2408 -- 0.00109 0.00109 -- None:0:<built-in method torch._C._has_torch_function_unary> (<built-in method torch._C._has_torch_function_unary>) +++
__setattr__ -- 12 12 -- 0.00011 0.00015 -- None:1188:__setattr__ (__setattr__)
<method 'get' of 'dict' objects> -- 36 36 -- 0.00001 0.00001 -- None:0:<method 'get' of 'dict' objects> (<method 'get' of 'dict' objects>) +++
<built-in method builtins.isinstance> -- 24 24 -- 0.00002 0.00002 -- None:0:<built-in method builtins.isinstance> (<built-in method builtins.isinstance>) +++
_named_members -- 203 203 -- 0.00311 0.01198 -- None:1501:_named_members (_named_members)
<method 'add' of 'set' objects> -- 2 2 -- 0.00000 0.00001 -- None:0:<method 'add' of 'set' objects> (<method 'add' of 'set' objects>) +++
__hash__ -- 2 2 -- 0.00001 0.00001 -- None:706:__hash__ (__hash__) +++
<lambda> -- 2 2 -- 0.00000 0.00000 -- None:1559:<lambda> (<lambda>)
<method 'items' of 'collections.OrderedDict' objects> -- 2 2 -- 0.00000 0.00000 -- None:0:<method 'items' of 'collections.OrderedDict' objects> (<method 'items' of 'collections.OrderedDict' objects>) +++
<lambda> -- 600 600 -- 0.00135 0.00168 -- None:1607:<lambda> (<lambda>)
<method 'items' of 'collections.OrderedDict' objects> -- 600 600 -- 0.00033 0.00033 -- None:0:<method 'items' of 'collections.OrderedDict' objects> (<method 'items' of 'collections.OrderedDict' objects>) +++
named_modules -- 803 803 -- 0.00294 0.00717 -- None:1668:named_modules (named_modules) +++
named_modules -- 803 1805 -- 0.00650 0.00717 -- None:1668:named_modules (named_modules)
<method 'items' of 'collections.OrderedDict' objects> -- 602 602 -- 0.00026 0.00026 -- None:0:<method 'items' of 'collections.OrderedDict' objects> (<method 'items' of 'collections.OrderedDict' objects>) +++
<method 'add' of 'set' objects> -- 602 602 -- 0.00041 0.00041 -- None:0:<method 'add' of 'set' objects> (<method 'add' of 'set' objects>) +++
named_modules -- 1002 602 -- 0.00356 0.00393 -- None:1668:named_modules (named_modules) +++
Torch profiler#
model = ORTModule(NLayerNet(d_in, d_out))
train_model(model, device, x, y, n_iter=2)
with torch.profiler.profile(
activities=[torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA],
with_stack=True) as p:
train_model(model, device, x, y, n_iter=200, profiler=p)
print(p.key_averages(group_by_stack_n=0).table(
sort_by="self_cuda_time_total", row_limit=-1))
# plt.show()
Out:
somewhere/workspace/deeponnxcustom/deeponnxcustom_UT_39_std/_venv/lib/python3.9/site-packages/onnxruntime/training/ortmodule/_training_manager.py:190: UserWarning: Fast path enabled - skipping checks. Rebuild graph: True, Execution agent: True, Device check: True
warnings.warn(
somewhere/workspace/deeponnxcustom/deeponnxcustom_UT_39_std/_venv/lib/python3.9/site-packages/torch/autograd/profiler.py:151: UserWarning: CUDA is not available, disabling CUDA profiling
warn("CUDA is not available, disabling CUDA profiling")
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
aten::to 0.00% 9.000us 0.00% 9.000us 1.500us 6
aten::_has_compatible_shallow_copy_type 0.00% 7.000us 0.00% 7.000us 0.875us 8
_ORTModuleFunction 29.59% 184.536ms 29.59% 184.536ms 922.680us 200
aten::broadcast_tensors 0.12% 743.000us 0.12% 743.000us 3.715us 200
aten::mse_loss 1.74% 10.857ms 3.82% 23.846ms 119.230us 200
aten::empty 1.36% 8.491ms 1.36% 8.491ms 6.065us 1400
aten::sum 1.47% 9.180ms 1.72% 10.758ms 53.790us 200
aten::as_strided 0.16% 1.011ms 0.16% 1.011ms 5.055us 200
aten::fill_ 0.13% 837.000us 0.13% 837.000us 2.092us 400
aten::zeros 0.97% 6.019ms 1.47% 9.199ms 22.997us 400
aten::zero_ 0.44% 2.764ms 0.44% 2.764ms 2.303us 1200
Optimizer.zero_grad#SGD.zero_grad 3.49% 21.748ms 3.90% 24.310ms 121.550us 200
aten::ones_like 0.35% 2.178ms 0.91% 5.648ms 28.240us 200
aten::empty_like 0.72% 4.502ms 1.24% 7.757ms 12.928us 600
aten::empty_strided 0.20% 1.262ms 0.20% 1.262ms 6.310us 200
autograd::engine::evaluate_function: MseLossBackward... 0.46% 2.877ms 4.08% 25.426ms 127.130us 200
MseLossBackward0 0.50% 3.106ms 3.62% 22.549ms 112.745us 200
aten::mse_loss_backward 1.69% 10.550ms 3.93% 24.534ms 30.668us 800
aten::zeros_like 0.63% 3.915ms 1.43% 8.893ms 22.233us 400
autograd::engine::evaluate_function: torch::autograd... 1.10% 6.850ms 5.10% 31.781ms 39.726us 800
torch::autograd::AccumulateGrad 1.97% 12.303ms 4.00% 24.931ms 31.164us 800
aten::detach 0.00% 11.000us 0.00% 31.000us 15.500us 2
detach 0.00% 20.000us 0.00% 20.000us 10.000us 2
autograd::engine::evaluate_function: _ORTModuleFunct... 1.13% 7.041ms 43.20% 269.449ms 1.347ms 200
_ORTModuleFunctionBackward 42.08% 262.408ms 42.08% 262.408ms 1.312ms 200
aten::add_ 2.82% 17.557ms 2.82% 17.557ms 14.655us 1198
Optimizer.step#SGD.step 6.88% 42.880ms 7.81% 48.708ms 243.540us 200
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 623.662ms
Total running time of the script: ( 0 minutes 19.244 seconds)