Note
Click here to download the full example code
Profling functions while using ONNX to extend pytorch#
The example creates a simple graph with many inputs so that the graph computing the gradient has many outputs. As the training of the whole model is done by torch, some time is spent just to exchange information between torch and onnxruntime. This time is minimized because the data is exchanged through DLPack protocol. That leaves the copy of the structures describing the data.
ONNX graph#
import os
import time
import numpy
from pandas import DataFrame
import matplotlib.pyplot as plt
from skl2onnx.common.data_types import FloatTensorType
from skl2onnx.algebra.onnx_ops import (
OnnxSigmoid, OnnxMatMul, OnnxAdd)
from pyquickhelper.pycode.profiling import profile, profile2graph, profile2df
from mlprodict.onnx_tools.onnx_manipulations import onnx_rename_names
from mlprodict.plotting.plotting_onnx import plot_onnx
import torch
from deeponnxcustom.onnxtorch.torchort import TorchOrtFactory
def from_numpy(v, device=None, requires_grad=False):
"""
Convers a numpy array into a torch array and
sets *device* and *requires_grad*.
"""
v = torch.from_numpy(v)
if device is not None:
v = v.to(device)
v.requires_grad_(requires_grad)
return v
def create_onnx_graph(N, d_in=3, d_out=2, n_loops=1, opv=14):
"""
Returns a weird ONNX graph and its weights.
"""
var = [('X', FloatTensorType([N, d_in]))]
sum_node = None
weights_values = []
for i in range(n_loops):
cst = numpy.random.randn(d_in, 1).astype(numpy.float32) / (i + 1)
weights_values.append(cst)
mul = OnnxMatMul(var[0], cst, op_version=opv)
tanh = OnnxSigmoid(mul, op_version=opv)
if sum_node is None:
sum_node = tanh
else:
sum_node = OnnxAdd(sum_node, tanh, op_version=opv)
cst_mul = numpy.random.randn(1, d_out).astype(numpy.float32)
weights_values.append(cst_mul)
mul = OnnxMatMul(sum_node, cst_mul, op_version=opv)
cst_add = numpy.random.randn(1, d_out).astype(numpy.float32)
weights_values.append(cst_add)
final = OnnxAdd(mul, cst_add, op_version=opv, output_names=['Y'])
onx = final.to_onnx(
var, target_opset=opv, outputs=[('Y', FloatTensorType())])
weights_name = [i.name for i in onx.graph.initializer]
new_names = ['W%03d' % i for i in range(len(weights_name))]
onx = onnx_rename_names(onx, replace=dict(zip(weights_name, new_names)))
weights = list(zip(new_names, weights_values))
return onx, weights
N, d_in, d_out = 5, 3, 2
onx, weights = create_onnx_graph(N, n_loops=20)
plot_onnx(onx.SerializeToString(), temp_dot="plot_profile_torchort.dot")

Out:
<AxesSubplot:>
Wraps ONNX as a torch.autograd.Function#
Let’s build a torch function with class
TorchOrtFactory.
fact = TorchOrtFactory(onx, [w[0] for w in weights])
cls = fact.create_class(keep_models=True)
print("torch version:", torch.__version__)
print(cls)
Out:
torch version: 1.11.0+cu102
<class 'deeponnxcustom.onnxtorch.torchort.TorchOrtFunction_140652289821232'>
The gradient graph looks like this:
fix, ax = plt.subplots(1, 1, figsize=(10, 10))
plot_onnx(cls._trained_onnx, ax=ax)

Out:
<AxesSubplot:>
Training#
The training happens on cpu or gpu depending on what is available. We try first a few iteation to see how it goes.
def train_cls(cls, device, x, y, weights, n_iter=100, learning_rate=1e-2):
x = from_numpy(x, requires_grad=True, device=device)
y = from_numpy(y, requires_grad=True, device=device)
weights_tch = [(w[0], from_numpy(w[1], requires_grad=True, device=device))
for w in weights]
weights_values = [w[1] for w in weights_tch]
all_losses = []
for t in range(n_iter):
# forward - backward
y_pred = cls.apply(x, *weights_values)
loss = (y_pred - y).pow(2).sum()
loss.backward()
# update weights
with torch.no_grad():
for name, w in weights_tch:
w -= w.grad * learning_rate
w.grad.zero_()
all_losses.append((t, float(loss.detach().numpy())))
return all_losses, weights_tch
device_name = "cuda:0" if torch.cuda.is_available() else "cpu"
device = torch.device(device_name)
print("device:", device)
x = numpy.random.randn(N, d_in).astype(numpy.float32)
y = numpy.random.randn(N, d_out).astype(numpy.float32)
train_losses, final_weights = train_cls(cls, device, x, y, weights, n_iter=10)
train_losses = numpy.array(train_losses)
df = DataFrame(data=train_losses, columns=['iter', 'train_loss'])
df.plot(x="iter", y="train_loss", title="Training loss")
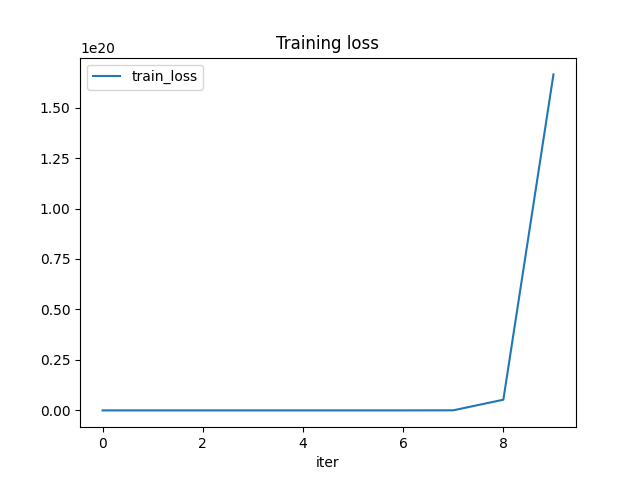
Out:
device: cpu
<AxesSubplot:title={'center':'Training loss'}, xlabel='iter'>
Profiling#
We run many more iterations and profile the execution.
folder = os.path.abspath(os.getcwd()).split('deeponnxcustom')[0]
folder2 = os.path.abspath(os.path.split(
os.path.dirname(torch.__file__))[0])[:-6]
# Same class but without any unnecessary data.
cls = fact.create_class()
begin = time.perf_counter()
train_cls(cls, device, x, y, weights, n_iter=200)
print("total time: %r" % (time.perf_counter() - begin))
Out:
total time: 1.0108971809968352
Full profile as text.
ps, text = profile(
lambda: train_cls(cls, device, x, y, weights, n_iter=200))
print(type(ps))
print(text.replace(folder, "").replace(folder2, ""))
Out:
<class 'pstats.Stats'>
61701 function calls in 1.098 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 1.098 1.098 deeponnxcustom/deeponnxcustom_UT_39_std/_doc/examples/plot_profile_torchort.py:175(<lambda>)
1 0.282 0.282 1.098 1.098 deeponnxcustom/deeponnxcustom_UT_39_std/_doc/examples/plot_profile_torchort.py:118(train_cls)
200 0.003 0.000 0.495 0.002 site-packages/torch/_tensor.py:307(backward)
200 0.003 0.000 0.492 0.002 site-packages/torch/autograd/__init__.py:85(backward)
200 0.180 0.001 0.478 0.002 {method 'run_backward' of 'torch._C._EngineBase' objects}
200 0.015 0.000 0.298 0.001 site-packages/torch/autograd/function.py:243(apply)
200 0.073 0.000 0.282 0.001 deeponnxcustom/deeponnxcustom_UT_39_std/_doc/sphinxdoc/source/deeponnxcustom/onnxtorch/torchort.py:199(ort_backward)
400 0.019 0.000 0.278 0.001 deeponnxcustom/deeponnxcustom_UT_39_std/_doc/sphinxdoc/source/deeponnxcustom/onnxtorch/torchort.py:78(from_ort_to_torch)
5200 0.163 0.000 0.256 0.000 deeponnxcustom/deeponnxcustom_UT_39_std/_doc/sphinxdoc/source/deeponnxcustom/onnxtorch/torchort.py:88(<genexpr>)
200 0.022 0.000 0.241 0.001 {built-in method apply}
200 0.084 0.000 0.219 0.001 deeponnxcustom/deeponnxcustom_UT_39_std/_doc/sphinxdoc/source/deeponnxcustom/onnxtorch/torchort.py:94(ort_forward)
4800 0.055 0.000 0.093 0.000 site-packages/torch/utils/dlpack.py:47(from_dlpack)
400 0.049 0.000 0.064 0.000 deeponnxcustom/deeponnxcustom_UT_39_std/_doc/sphinxdoc/source/deeponnxcustom/onnxtorch/torchort.py:60(from_torch_to_ort)
4800 0.033 0.000 0.033 0.000 {built-in method torch._C._from_dlpack}
8800 0.024 0.000 0.028 0.000 site-packages/torch/_tensor.py:1092(grad)
4400 0.019 0.000 0.019 0.000 {method 'zero_' of 'torch._C._TensorBase' objects}
200 0.003 0.000 0.010 0.000 site-packages/torch/autograd/__init__.py:30(_make_grads)
200 0.009 0.000 0.009 0.000 {method 'sum' of 'torch._C._TensorBase' objects}
200 0.009 0.000 0.009 0.000 {method 'pow' of 'torch._C._TensorBase' objects}
4800 0.008 0.000 0.008 0.000 {built-in method torch._C._to_dlpack}
4800 0.007 0.000 0.007 0.000 {method 'is_contiguous' of 'torch._C._TensorBase' objects}
5600 0.006 0.000 0.006 0.000 {built-in method builtins.hasattr}
200 0.005 0.000 0.005 0.000 {built-in method ones_like}
9000 0.004 0.000 0.004 0.000 {built-in method torch._C._has_torch_function_unary}
200 0.002 0.000 0.004 0.000 site-packages/torch/autograd/grad_mode.py:126(__enter__)
1400 0.003 0.000 0.003 0.000 {built-in method builtins.len}
200 0.003 0.000 0.003 0.000 site-packages/torch/autograd/grad_mode.py:121(__init__)
400 0.002 0.000 0.003 0.000 site-packages/torch/autograd/grad_mode.py:215(__init__)
200 0.003 0.000 0.003 0.000 {method 'detach' of 'torch._C._TensorBase' objects}
200 0.001 0.000 0.002 0.000 site-packages/torch/autograd/grad_mode.py:130(__exit__)
200 0.002 0.000 0.002 0.000 {method 'numpy' of 'torch._C._TensorBase' objects}
800 0.001 0.000 0.001 0.000 {built-in method torch._C.is_grad_enabled}
600 0.001 0.000 0.001 0.000 {method 'append' of 'list' objects}
600 0.001 0.000 0.001 0.000 {built-in method builtins.isinstance}
200 0.001 0.000 0.001 0.000 site-packages/torch/autograd/__init__.py:77(_tensor_or_tensors_to_tuple)
200 0.001 0.000 0.001 0.000 site-packages/torch/autograd/function.py:14(save_for_backward)
24 0.000 0.000 0.000 0.000 deeponnxcustom/deeponnxcustom_UT_39_std/_doc/examples/plot_profile_torchort.py:37(from_numpy)
1 0.000 0.000 0.000 0.000 deeponnxcustom/deeponnxcustom_UT_39_std/_doc/examples/plot_profile_torchort.py:122(<listcomp>)
200 0.000 0.000 0.000 0.000 {method 'pop' of 'list' objects}
400 0.000 0.000 0.000 0.000 {built-in method torch._C._set_grad_enabled}
200 0.000 0.000 0.000 0.000 {built-in method builtins.any}
200 0.000 0.000 0.000 0.000 {method 'numel' of 'torch._C._TensorBase' objects}
24 0.000 0.000 0.000 0.000 {built-in method from_numpy}
200 0.000 0.000 0.000 0.000 site-packages/torch/_jit_internal.py:957(is_scripting)
24 0.000 0.000 0.000 0.000 {method 'to' of 'torch._C._TensorBase' objects}
24 0.000 0.000 0.000 0.000 {method 'requires_grad_' of 'torch._C._TensorBase' objects}
1 0.000 0.000 0.000 0.000 deeponnxcustom/deeponnxcustom_UT_39_std/_doc/examples/plot_profile_torchort.py:124(<listcomp>)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
Same results in a graph.
df = profile2df(ps)
ax = df[['fct', 'cum_tall']].head(n=15).set_index(
'fct').plot(kind='bar', figsize=(8, 3), rot=30)
ax.set_title("example of a graph")
for la in ax.get_xticklabels():
la.set_horizontalalignment('right')
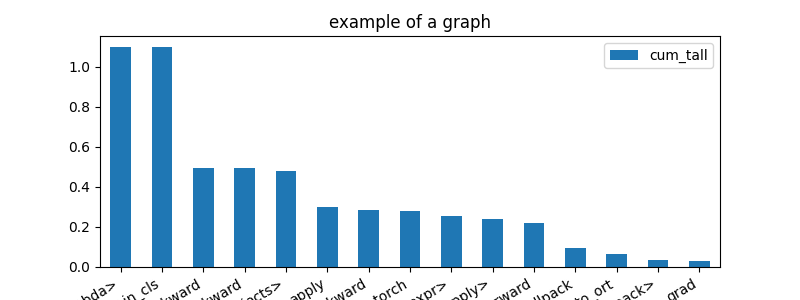
Presentation with partial call stack#
The previous presentation do not show any information
about where a function is called from. Let’s use
function profile2graph.
folder = folder.replace("\\", "/")
folder2 = folder2.replace("\\", "/")
def clean_text(x):
x = x.replace(folder, "").replace(folder2, "")
root, nodes = profile2graph(ps, clean_text=clean_text)
text = root.to_text(fct_width=70)
print(text)
Out:
<method 'append' of 'list' objects> -- 600 600 -- 0.00100 0.00100 -- None:0:<method 'append' of 'list' objects> (<method 'append' of 'list' objects>)
<built-in method torch._C.is_grad_enabled> -- 800 800 -- 0.00102 0.00102 -- None:0:<built-in method torch._C.is_grad_enabled> (<built-in method torch._C.is_grad_enabled>)
<built-in method torch._C._has_torch_function_unary> -- 9000 9000 -- 0.00450 0.00450 -- None:0:<built-in method torch._C._has_torch_function_unary> (<built-in method torch._C._has_torch_function_unary>)
<built-in method builtins.isinstance> -- 600 600 -- 0.00093 0.00093 -- None:0:<built-in method builtins.isinstance> (<built-in method builtins.isinstance>)
<built-in method builtins.len> -- 1400 1400 -- 0.00337 0.00337 -- None:0:<built-in method builtins.len> (<built-in method builtins.len>)
<built-in method builtins.hasattr> -- 5600 5600 -- 0.00568 0.00568 -- None:0:<built-in method builtins.hasattr> (<built-in method builtins.hasattr>)
from_numpy -- 24 24 -- 0.00013 0.00049 -- None:37:from_numpy (from_numpy)
<built-in method from_numpy> -- 24 24 -- 0.00018 0.00018 -- None:0:<built-in method from_numpy> (<built-in method from_numpy>)
<method 'requires_grad_' of 'torch._C._TensorBase' objects> -- 24 24 -- 0.00007 0.00007 -- None:0:<method 'requires_grad_' of 'torch._C._TensorBase' objects> (<method 'requires_grad_' of 'torch._C._TensorBase' objects>)
<method 'to' of 'torch._C._TensorBase' objects> -- 24 24 -- 0.00011 0.00011 -- None:0:<method 'to' of 'torch._C._TensorBase' objects> (<method 'to' of 'torch._C._TensorBase' objects>)
from_torch_to_ort -- 400 400 -- 0.04872 0.06409 -- None:60:from_torch_to_ort (from_torch_to_ort)
<built-in method torch._C._to_dlpack> -- 4800 4800 -- 0.00832 0.00832 -- None:0:<built-in method torch._C._to_dlpack> (<built-in method torch._C._to_dlpack>)
<method 'is_contiguous' of 'torch._C._TensorBase' objects> -- 4800 4800 -- 0.00669 0.00669 -- None:0:<method 'is_contiguous' of 'torch._C._TensorBase' objects> (<method 'is_contiguous' of 'torch._C._TensorBase' objects>)
<built-in method builtins.len> -- 400 400 -- 0.00036 0.00036 -- None:0:<built-in method builtins.len> (<built-in method builtins.len>) +++
from_ort_to_torch -- 400 400 -- 0.01864 0.27810 -- None:78:from_ort_to_torch (from_ort_to_torch)
<built-in method builtins.hasattr> -- 800 800 -- 0.00097 0.00097 -- None:0:<built-in method builtins.hasattr> (<built-in method builtins.hasattr>) +++
<built-in method builtins.len> -- 400 400 -- 0.00267 0.00267 -- None:0:<built-in method builtins.len> (<built-in method builtins.len>) +++
<genexpr> -- 5200 5200 -- 0.16329 0.25583 -- None:88:<genexpr> (<genexpr>)
from_dlpack -- 4800 4800 -- 0.05487 0.09254 -- None:47:from_dlpack (from_dlpack)
<built-in method torch._C._from_dlpack> -- 4800 4800 -- 0.03295 0.03295 -- None:0:<built-in method torch._C._from_dlpack> (<built-in method torch._C._from_dlpack>)
<built-in method builtins.hasattr> -- 4800 4800 -- 0.00472 0.00472 -- None:0:<built-in method builtins.hasattr> (<built-in method builtins.hasattr>) +++
<lambda> -- 1 1 -- 0.00005 1.09775 -- None:175:<lambda> (<lambda>)
train_cls -- 1 1 -- 0.28179 1.09770 -- None:118:train_cls (train_cls)
<method 'numpy' of 'torch._C._TensorBase' objects> -- 200 200 -- 0.00151 0.00151 -- None:0:<method 'numpy' of 'torch._C._TensorBase' objects> (<method 'numpy' of 'torch._C._TensorBase' objects>)
<method 'detach' of 'torch._C._TensorBase' objects> -- 200 200 -- 0.00293 0.00293 -- None:0:<method 'detach' of 'torch._C._TensorBase' objects> (<method 'detach' of 'torch._C._TensorBase' objects>)
<method 'pow' of 'torch._C._TensorBase' objects> -- 200 200 -- 0.00855 0.00855 -- None:0:<method 'pow' of 'torch._C._TensorBase' objects> (<method 'pow' of 'torch._C._TensorBase' objects>)
<method 'sum' of 'torch._C._TensorBase' objects> -- 200 200 -- 0.00911 0.00911 -- None:0:<method 'sum' of 'torch._C._TensorBase' objects> (<method 'sum' of 'torch._C._TensorBase' objects>)
<method 'zero_' of 'torch._C._TensorBase' objects> -- 4400 4400 -- 0.01862 0.01862 -- None:0:<method 'zero_' of 'torch._C._TensorBase' objects> (<method 'zero_' of 'torch._C._TensorBase' objects>)
<built-in method apply> -- 200 200 -- 0.02222 0.24106 -- None:0:<built-in method apply> (<built-in method apply>)
ort_forward -- 200 200 -- 0.08392 0.21884 -- None:94:ort_forward (ort_forward)
<built-in method torch._C.is_grad_enabled> -- 200 200 -- 0.00023 0.00023 -- None:0:<built-in method torch._C.is_grad_enabled> (<built-in method torch._C.is_grad_enabled>) +++
<method 'append' of 'list' objects> -- 200 200 -- 0.00036 0.00036 -- None:0:<method 'append' of 'list' objects> (<method 'append' of 'list' objects>) +++
<built-in method builtins.any> -- 200 200 -- 0.00035 0.00035 -- None:0:<built-in method builtins.any> (<built-in method builtins.any>)
<built-in method builtins.len> -- 200 200 -- 0.00012 0.00012 -- None:0:<built-in method builtins.len> (<built-in method builtins.len>) +++
save_for_backward -- 200 200 -- 0.00052 0.00052 -- None:14:save_for_backward (save_for_backward)
from_torch_to_ort -- 200 200 -- 0.04159 0.05563 -- None:60:from_torch_to_ort (from_torch_to_ort) +++
from_ort_to_torch -- 200 200 -- 0.00797 0.07772 -- None:78:from_ort_to_torch (from_ort_to_torch) +++
<method 'append' of 'list' objects> -- 200 200 -- 0.00039 0.00039 -- None:0:<method 'append' of 'list' objects> (<method 'append' of 'list' objects>) +++
from_numpy -- 2 2 -- 0.00003 0.00009 -- None:37:from_numpy (from_numpy) +++
__init__ -- 200 200 -- 0.00311 0.00325 -- None:121:__init__ (__init__)
is_scripting -- 200 200 -- 0.00014 0.00014 -- None:957:is_scripting (is_scripting)
<listcomp> -- 1 1 -- 0.00006 0.00046 -- None:122:<listcomp> (<listcomp>)
from_numpy -- 22 22 -- 0.00010 0.00040 -- None:37:from_numpy (from_numpy) +++
<listcomp> -- 1 1 -- 0.00000 0.00000 -- None:124:<listcomp> (<listcomp>)
__enter__ -- 200 200 -- 0.00191 0.00412 -- None:126:__enter__ (__enter__)
<built-in method torch._C.is_grad_enabled> -- 200 200 -- 0.00041 0.00041 -- None:0:<built-in method torch._C.is_grad_enabled> (<built-in method torch._C.is_grad_enabled>) +++
__init__ -- 200 200 -- 0.00141 0.00179 -- None:215:__init__ (__init__) +++
__exit__ -- 200 200 -- 0.00126 0.00242 -- None:130:__exit__ (__exit__)
__init__ -- 200 200 -- 0.00078 0.00117 -- None:215:__init__ (__init__) +++
backward -- 200 200 -- 0.00293 0.49539 -- None:307:backward (backward)
<built-in method torch._C._has_torch_function_unary> -- 200 200 -- 0.00015 0.00015 -- None:0:<built-in method torch._C._has_torch_function_unary> (<built-in method torch._C._has_torch_function_unary>) +++
backward -- 200 200 -- 0.00343 0.49231 -- None:85:backward (backward)
<method 'run_backward' of ...._C._EngineBase' objects> -- 200 200 -- 0.18036 0.47787 -- None:0:<method 'run_backward' of 'torch._C._EngineBase' objects> (<method 'run_backward' of 'torch._C._EngineBase' objects>)
apply -- 200 200 -- 0.01550 0.29751 -- None:243:apply (apply)
ort_backward -- 200 200 -- 0.07263 0.28201 -- None:199:ort_backward (ort_backward)
<method 'pop' of 'list' objects> -- 200 200 -- 0.00043 0.00043 -- None:0:<method 'pop' of 'list' objects> (<method 'pop' of 'list' objects>)
<built-in method builtins.len> -- 200 200 -- 0.00011 0.00011 -- None:0:<built-in method builtins.len> (<built-in method builtins.len>) +++
from_torch_to_ort -- 200 200 -- 0.00712 0.00846 -- None:60:from_torch_to_ort (from_torch_to_ort) +++
from_ort_to_torch -- 200 200 -- 0.01067 0.20038 -- None:78:from_ort_to_torch (from_ort_to_torch) +++
<built-in method builtins.isinstance> -- 400 400 -- 0.00063 0.00063 -- None:0:<built-in method builtins.isinstance> (<built-in method builtins.isinstance>) +++
<built-in method builtins.len> -- 200 200 -- 0.00011 0.00011 -- None:0:<built-in method builtins.len> (<built-in method builtins.len>) +++
_make_grads -- 200 200 -- 0.00349 0.00976 -- None:30:_make_grads (_make_grads)
<built-in method ones_like> -- 200 200 -- 0.00541 0.00541 -- None:0:<built-in method ones_like> (<built-in method ones_like>)
<method 'numel' of 'torch._C._TensorBase' objects> -- 200 200 -- 0.00030 0.00030 -- None:0:<method 'numel' of 'torch._C._TensorBase' objects> (<method 'numel' of 'torch._C._TensorBase' objects>)
<method 'append' of 'list' objects> -- 200 200 -- 0.00026 0.00026 -- None:0:<method 'append' of 'list' objects> (<method 'append' of 'list' objects>) +++
<built-in method builtins.isinstance> -- 200 200 -- 0.00031 0.00031 -- None:0:<built-in method builtins.isinstance> (<built-in method builtins.isinstance>) +++
_tensor_or_tensors_to_tuple -- 200 200 -- 0.00052 0.00052 -- None:77:_tensor_or_tensors_to_tuple (_tensor_or_tensors_to_tuple)
grad -- 8800 8800 -- 0.02364 0.02799 -- None:1092:grad (grad)
<built-in method torch._C._has_torch_function_unary> -- 8800 8800 -- 0.00435 0.00435 -- None:0:<built-in method torch._C._has_torch_function_unary> (<built-in method torch._C._has_torch_function_unary>) +++
__init__ -- 400 400 -- 0.00219 0.00296 -- None:215:__init__ (__init__)
<built-in method torch._C._set_grad_enabled> -- 400 400 -- 0.00039 0.00039 -- None:0:<built-in method torch._C._set_grad_enabled> (<built-in method torch._C._set_grad_enabled>)
<built-in method torch._C.is_grad_enabled> -- 400 400 -- 0.00038 0.00038 -- None:0:<built-in method torch._C.is_grad_enabled> (<built-in method torch._C.is_grad_enabled>) +++
Torch profiler#
with torch.profiler.profile(
activities=[torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA],
with_stack=True) as p:
train_cls(cls, device, x, y, weights, n_iter=200)
print(p.key_averages(group_by_stack_n=0).table(
sort_by="self_cuda_time_total", row_limit=-1))
# plt.show()
Out:
somewhere/workspace/deeponnxcustom/deeponnxcustom_UT_39_std/_venv/lib/python3.9/site-packages/torch/autograd/profiler.py:151: UserWarning: CUDA is not available, disabling CUDA profiling
warn("CUDA is not available, disabling CUDA profiling")
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
aten::to 2.06% 21.311ms 11.82% 122.216ms 24.326us 5024
TorchOrtFunction_140652289821232 22.97% 237.386ms 22.97% 237.386ms 1.187ms 200
aten::sub 0.79% 8.191ms 0.79% 8.191ms 40.955us 200
aten::pow 1.27% 13.133ms 1.65% 17.073ms 42.682us 400
aten::result_type 0.09% 902.000us 0.09% 902.000us 2.255us 400
aten::sum 0.98% 10.091ms 1.12% 11.584ms 57.920us 200
aten::as_strided 0.19% 1.941ms 0.19% 1.941ms 4.853us 400
aten::fill_ 0.07% 707.000us 0.07% 707.000us 1.768us 400
aten::ones_like 0.21% 2.135ms 0.56% 5.784ms 28.920us 200
aten::empty_like 0.20% 2.016ms 0.33% 3.439ms 17.195us 200
aten::empty_strided 1.97% 20.323ms 1.97% 20.323ms 4.234us 4800
autograd::engine::evaluate_function: SumBackward0 0.23% 2.341ms 0.76% 7.883ms 39.415us 200
SumBackward0 0.15% 1.525ms 0.54% 5.542ms 27.710us 200
aten::expand 0.30% 3.072ms 0.39% 4.017ms 20.085us 200
autograd::engine::evaluate_function: PowBackward0 0.30% 3.082ms 3.18% 32.831ms 164.155us 200
PowBackward0 0.42% 4.389ms 2.88% 29.749ms 148.745us 200
aten::copy_ 3.23% 33.394ms 3.23% 33.394ms 6.957us 4800
aten::mul 9.06% 93.688ms 20.84% 215.408ms 44.877us 4800
aten::_to_copy 4.95% 51.182ms 9.76% 100.905ms 21.936us 4600
autograd::engine::evaluate_function: SubBackward0 0.19% 1.963ms 0.62% 6.403ms 32.015us 200
SubBackward0 0.16% 1.689ms 0.43% 4.440ms 22.200us 200
aten::neg 0.27% 2.751ms 0.27% 2.751ms 13.755us 200
autograd::engine::evaluate_function: torch::autograd... 3.76% 38.914ms 14.47% 149.529ms 31.152us 4800
torch::autograd::AccumulateGrad 6.28% 64.952ms 10.70% 110.615ms 23.045us 4800
aten::detach 0.10% 989.000us 0.30% 3.140ms 14.018us 224
detach 0.21% 2.151ms 0.21% 2.151ms 9.603us 224
autograd::engine::evaluate_function: TorchOrtFunctio... 1.03% 10.697ms 30.19% 312.098ms 1.560ms 200
TorchOrtFunction_140652289821232Backward 29.16% 301.401ms 29.16% 301.401ms 1.507ms 200
aten::sub_ 3.95% 40.801ms 3.95% 40.801ms 9.273us 4400
aten::zero_ 1.07% 11.070ms 1.07% 11.070ms 2.516us 4400
aten::add_ 4.40% 45.445ms 4.40% 45.445ms 9.515us 4776
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 1.034s
Total running time of the script: ( 0 minutes 49.405 seconds)