Heap#
Links: notebook, html, python, slides, GitHub
La structure heap ou tas en français est utilisée pour trier. Elle peut également servir à obtenir les k premiers éléments d’une liste.
from jyquickhelper import add_notebook_menu
add_notebook_menu()
Un tas est peut être considéré comme un tableau  qui vérifie
une condition assez simple, pour tout indice
qui vérifie
une condition assez simple, pour tout indice  , alors
, alors
![T[i] \geqslant \max(T[2i+1], T[2i+2])](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTEuOTU1MTY4cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNTYuNDEzMjY3IDU2Ljc4NzA0OSAxNjEuMjczNzg2IDExLjk1NTE2OCcgd2lkdGg9JzE2MS4yNzM3ODZwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNOC4wNTc3ODMgLTMuODczNDc0QzguMjQ5MDY2IC0zLjk1NzE2MSA4LjI5Njg4NyAtNC4wNDA4NDcgOC4yOTY4ODcgLTQuMTM2NDg4QzguMjk2ODg3IC00LjI5MTkwNSA4LjIxMzIgLTQuMzI3NzcxIDguMDU3NzgzIC00LjM5OTUwMkwxLjQ3MDQ4NiAtNy41MTk4MDFDMS4zMDMxMTMgLTcuNjAzNDg3IDEuMjU1MjkzIC03LjYwMzQ4NyAxLjIzMTM4MiAtNy42MDM0ODdDMS4wOTk4NzUgLTcuNjAzNDg3IDAuOTkyMjc5IC03LjQ5NTg5IDAuOTkyMjc5IC03LjM2NDM4NEMwLjk5MjI3OSAtNy4yMDg5NjYgMS4wODc5MiAtNy4xNzMxMDEgMS4yMzEzODIgLTcuMTAxMzdMNy40OTU4OSAtNC4xNDg0NDNMMS4yMTk0MjcgLTEuMTgzNTYyQzEuMDQwMSAtMS4wOTk4NzUgMC45OTIyNzkgLTEuMDI4MTQ0IDAuOTkyMjc5IC0wLjkyMDU0OEMwLjk5MjI3OSAtMC43ODkwNDEgMS4wOTk4NzUgLTAuNjgxNDQ1IDEuMjMxMzgyIC0wLjY4MTQ0NUMxLjI2NzI0OCAtMC42ODE0NDUgMS4yOTExNTggLTAuNjgxNDQ1IDEuNDQ2NTc1IC0wLjc2NTEzMUw4LjA1Nzc4MyAtMy44NzM0NzRaTTguMDU3NzgzIC0xLjU1NDE3MkM4LjI0OTA2NiAtMS42Mzc4NTggOC4yOTY4ODcgLTEuNzIxNTQ0IDguMjk2ODg3IC0xLjgxNzE4NkM4LjI5Njg4NyAtMi4wNTYyODkgOC4wNjk3MzggLTIuMDU2Mjg5IDcuOTg2MDUyIC0yLjA1NjI4OUwxLjIxOTQyNyAxLjEzNTc0MUMxLjA5OTg3NSAxLjE5NTUxNyAwLjk5MjI3OSAxLjI2NzI0OCAwLjk5MjI3OSAxLjM5ODc1NVMxLjA5OTg3NSAxLjYzNzg1OCAxLjIzMTM4MiAxLjYzNzg1OEMxLjI2NzI0OCAxLjYzNzg1OCAxLjI5MTE1OCAxLjYzNzg1OCAxLjQ0NjU3NSAxLjU1NDE3Mkw4LjA1Nzc4MyAtMS41NTQxNzJaJyBpZD0nZzAtNjInLz4KPHBhdGggZD0nTTIuMzMxMjU4IDAuMDQ3ODIxQzIuMzMxMjU4IC0wLjY0NTU3OSAyLjEwNDExIC0xLjE1OTY1MSAxLjYxMzk0OCAtMS4xNTk2NTFDMS4yMzEzODIgLTEuMTU5NjUxIDEuMDQwMSAtMC44NDg4MTcgMS4wNDAxIC0wLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3IC0wLjA0NzgyMSAyLjAyMDQyMyAtMC4xNTU0MTdDMi4wNDQzMzQgLTAuMTc5MzI4IDIuMDU2Mjg5IC0wLjE3OTMyOCAyLjA2ODI0NCAtMC4xNzkzMjhDMi4wOTIxNTQgLTAuMTc5MzI4IDIuMDkyMTU0IC0wLjAxMTk1NSAyLjA5MjE1NCAwLjA0NzgyMUMyLjA5MjE1NCAwLjQ0MjM0MSAyLjAyMDQyMyAxLjIxOTQyNyAxLjMyNzAyNCAxLjk5NjUxM0MxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjQxMDcxIDIuMzA3MzQ3IDIuMzMxMjU4IDEuNDIyNjY1IDIuMzMxMjU4IDAuMDQ3ODIxWicgaWQ9J2cxLTU5Jy8+CjxwYXRoIGQ9J000Ljk4NTMwNSAtNy4yOTI2NTNDNS4wNTcwMzYgLTcuNTc5NTc3IDUuMDgwOTQ2IC03LjY4NzE3MyA1LjI2MDI3NCAtNy43MzQ5OTRDNS4zNTU5MTUgLTcuNzU4OTA0IDUuNzUwNDM2IC03Ljc1ODkwNCA2LjAwMTQ5NCAtNy43NTg5MDRDNy4xOTcwMTEgLTcuNzU4OTA0IDcuNzU4OTA0IC03LjcxMTA4MyA3Ljc1ODkwNCAtNi43Nzg1OEM3Ljc1ODkwNCAtNi41OTkyNTMgNy43MTEwODMgLTYuMTQ0OTU2IDcuNjM5MzUyIC01LjcwMjYxNUw3LjYyNzM5NyAtNS41NTkxNTNDNy42MjczOTcgLTUuNTExMzMzIDcuNjc1MjE4IC01LjQzOTYwMSA3Ljc0Njk0OSAtNS40Mzk2MDFDNy44NjY1MDEgLTUuNDM5NjAxIDcuODY2NTAxIC01LjQ5OTM3NyA3LjkwMjM2NiAtNS42OTA2Nkw4LjI0OTA2NiAtNy44MDY3MjVDOC4yNzI5NzYgLTcuOTE0MzIxIDguMjcyOTc2IC03LjkzODIzMiA4LjI3Mjk3NiAtNy45NzQwOTdDOC4yNzI5NzYgLTguMTA1NjA0IDguMjAxMjQ1IC04LjEwNTYwNCA3Ljk2MjE0MiAtOC4xMDU2MDRIMS40MjI2NjVDMS4xNDc2OTYgLTguMTA1NjA0IDEuMTM1NzQxIC04LjA5MzY0OSAxLjA2NDAxIC03Ljg3ODQ1NkwwLjMzNDc0NSAtNS43MjY1MjZDMC4zMjI3OSAtNS43MDI2MTUgMC4yODY5MjQgLTUuNTcxMTA4IDAuMjg2OTI0IC01LjU1OTE1M0MwLjI4NjkyNCAtNS40OTkzNzcgMC4zMzQ3NDUgLTUuNDM5NjAxIDAuNDA2NDc2IC01LjQzOTYwMUMwLjUwMjExNyAtNS40Mzk2MDEgMC41MjYwMjcgLTUuNDg3NDIyIDAuNTczODQ4IC01LjY0MjgzOUMxLjA3NTk2NSAtNy4wODk0MTUgMS4zMjcwMjQgLTcuNzU4OTA0IDIuOTE3MDYxIC03Ljc1ODkwNEgzLjcxODA1N0M0LjAwNDk4MSAtNy43NTg5MDQgNC4xMjQ1MzMgLTcuNzU4OTA0IDQuMTI0NTMzIC03LjYyNzM5N0M0LjEyNDUzMyAtNy41OTE1MzIgNC4xMjQ1MzMgLTcuNTY3NjIxIDQuMDY0NzU3IC03LjM1MjQyOEwyLjQ2Mjc2NSAtMC45MzI1MDNDMi4zNDMyMTMgLTAuNDY2MjUyIDIuMzE5MzAzIC0wLjM0NjcgMS4wNTIwNTUgLTAuMzQ2N0MwLjc1MzE3NiAtMC4zNDY3IDAuNjY5NDg5IC0wLjM0NjcgMC42Njk0ODkgLTAuMTE5NTUyQzAuNjY5NDg5IDAgMC44MDA5OTYgMCAwLjg2MDc3MiAwQzEuMTU5NjUxIDAgMS40NzA0ODYgLTAuMDIzOTEgMS43NjkzNjUgLTAuMDIzOTFIMy42MzQzNzFDMy45MzMyNSAtMC4wMjM5MSA0LjI1NjA0IDAgNC41NTQ5MTkgMEM0LjY4NjQyNiAwIDQuODA1OTc4IDAgNC44MDU5NzggLTAuMjI3MTQ4QzQuODA1OTc4IC0wLjM0NjcgNC43MjIyOTEgLTAuMzQ2NyA0LjQxMTQ1NyAtMC4zNDY3QzMuMzM1NDkyIC0wLjM0NjcgMy4zMzU0OTIgLTAuNDU0Mjk2IDMuMzM1NDkyIC0wLjYzMzYyNEMzLjMzNTQ5MiAtMC42NDU1NzkgMy4zMzU0OTIgLTAuNzI5MjY1IDMuMzgzMzEzIC0wLjkyMDU0OEw0Ljk4NTMwNSAtNy4yOTI2NTNaJyBpZD0nZzEtODQnLz4KPHBhdGggZD0nTTMuMzgzMzEzIC0xLjcwOTU4OUMzLjM4MzMxMyAtMS43NjkzNjUgMy4zMzU0OTIgLTEuODE3MTg2IDMuMjYzNzYxIC0xLjgxNzE4NkMzLjE1NjE2NCAtMS44MTcxODYgMy4xNDQyMDkgLTEuNzgxMzIgMy4wODQ0MzMgLTEuNTc4MDgyQzIuNzczNTk5IC0wLjQ5MDE2MiAyLjI4MzQzNyAtMC4xMTk1NTIgMS44ODg5MTcgLTAuMTE5NTUyQzEuNzQ1NDU1IC0wLjExOTU1MiAxLjU3ODA4MiAtMC4xNTU0MTcgMS41NzgwODIgLTAuNTE0MDcyQzEuNTc4MDgyIC0wLjgzNjg2MiAxLjcyMTU0NCAtMS4xOTU1MTcgMS44NTMwNTEgLTEuNTU0MTcyTDIuNjg5OTEzIC0zLjc3NzgzM0MyLjcyNTc3OCAtMy44NzM0NzQgMi44MDk0NjUgLTQuMDg4NjY3IDIuODA5NDY1IC00LjMxNTgxNkMyLjgwOTQ2NSAtNC44MTc5MzMgMi40NTA4MDkgLTUuMjcyMjI5IDEuODY1MDA2IC01LjI3MjIyOUMwLjc2NTEzMSAtNS4yNzIyMjkgMC4zMjI3OSAtMy41Mzg3MyAwLjMyMjc5IC0zLjQ0MzA4OEMwLjMyMjc5IC0zLjM5NTI2OCAwLjM3MDYxIC0zLjMzNTQ5MiAwLjQ1NDI5NiAtMy4zMzU0OTJDMC41NjE4OTMgLTMuMzM1NDkyIDAuNTczODQ4IC0zLjM4MzMxMyAwLjYyMTY2OSAtMy41NTA2ODVDMC45MDg1OTMgLTQuNTU0OTE5IDEuMzYyODg5IC01LjAzMzEyNiAxLjgyOTE0MSAtNS4wMzMxMjZDMS45MzY3MzcgLTUuMDMzMTI2IDIuMTM5OTc1IC01LjAyMTE3MSAyLjEzOTk3NSAtNC42Mzg2MDVDMi4xMzk5NzUgLTQuMzI3NzcxIDEuOTg0NTU4IC0zLjkzMzI1IDEuODg4OTE3IC0zLjY3MDIzN0wxLjA1MjA1NSAtMS40NDY1NzVDMC45ODAzMjQgLTEuMjU1MjkzIDAuOTA4NTkzIC0xLjA2NDAxIDAuOTA4NTkzIC0wLjg0ODgxN0MwLjkwODU5MyAtMC4zMTA4MzQgMS4yNzkyMDMgMC4xMTk1NTIgMS44NTMwNTEgMC4xMTk1NTJDMi45NTI5MjcgMC4xMTk1NTIgMy4zODMzMTMgLTEuNjI1OTAzIDMuMzgzMzEzIC0xLjcwOTU4OVpNMy4yODc2NzEgLTcuNDYwMDI1QzMuMjg3NjcxIC03LjYzOTM1MiAzLjE0NDIwOSAtNy44NTQ1NDUgMi44ODExOTYgLTcuODU0NTQ1QzIuNjA2MjI3IC03Ljg1NDU0NSAyLjI5NTM5MiAtNy41OTE1MzIgMi4yOTUzOTIgLTcuMjgwNjk3QzIuMjk1MzkyIC02Ljk4MTgxOCAyLjU0NjQ1MSAtNi44ODYxNzcgMi42ODk5MTMgLTYuODg2MTc3QzMuMDEyNzAyIC02Ljg4NjE3NyAzLjI4NzY3MSAtNy4xOTcwMTEgMy4yODc2NzEgLTcuNDYwMDI1WicgaWQ9J2cxLTEwNScvPgo8cGF0aCBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYgLTAuNTM3OTgzIDEuODE3MTg2IC0yLjk3NjgzN0MxLjgxNzE4NiAtNS4yOTYxMzkgMi4zNzkwNzggLTcuMjkyNjUzIDMuNzY1ODc4IC04LjcwMzM2MkMzLjg4NTQzIC04LjgxMDk1OSAzLjg4NTQzIC04LjgzNDg2OSAzLjg4NTQzIC04Ljg3MDczNUMzLjg4NTQzIC04Ljk0MjQ2NiAzLjgyNTY1NCAtOC45NjYzNzYgMy43Nzc4MzMgLTguOTY2Mzc2QzMuNjIyNDE2IC04Ljk2NjM3NiAyLjY0MjA5MiAtOC4xMDU2MDQgMi4wNTYyODkgLTYuOTMzOTk4QzEuNDQ2NTc1IC01LjcyNjUyNiAxLjE3MTYwNiAtNC40NDczMjMgMS4xNzE2MDYgLTIuOTc2ODM3QzEuMTcxNjA2IC0xLjkxMjgyNyAxLjMzODk3OSAtMC40OTAxNjIgMS45NjA2NDggMC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicgaWQ9J2cyLTQwJy8+CjxwYXRoIGQ9J00zLjM3MTM1NyAtMi45NzY4MzdDMy4zNzEzNTcgLTMuODg1NDMgMy4yNTE4MDYgLTUuMzY3ODcgMi41ODIzMTYgLTYuNzU0NjdDMS44NzY5NjEgLTguMTg5MjkgMC44OTY2MzggLTguOTY2Mzc2IDAuNzY1MTMxIC04Ljk2NjM3NkMwLjcxNzMxIC04Ljk2NjM3NiAwLjY1NzUzNCAtOC45NDI0NjYgMC42NTc1MzQgLTguODcwNzM1QzAuNjU3NTM0IC04LjgzNDg2OSAwLjY1NzUzNCAtOC44MTA5NTkgMC44NjA3NzIgLTguNjA3NzIxQzIuMDU2Mjg5IC03LjQwMDI0OSAyLjcyNTc3OCAtNS40Mjc2NDYgMi43MjU3NzggLTIuOTg4NzkyQzIuNzI1Nzc4IC0wLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAwLjc3NzA4NiAyLjczNzczM0MwLjY1NzUzNCAyLjg0NTMzIDAuNjU3NTM0IDIuODY5MjQgMC42NTc1MzQgMi45MDUxMDZDMC42NTc1MzQgMi45NzY4MzcgMC43MTczMSAzLjAwMDc0NyAwLjc2NTEzMSAzLjAwMDc0N0MwLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAwLjk2ODM2OUMzLjA5NjM4OSAtMC4yNTEwNTkgMy4zNzEzNTcgLTEuNTQyMjE3IDMuMzcxMzU3IC0yLjk3NjgzN1onIGlkPSdnMi00MScvPgo8cGF0aCBkPSdNNC43NzAxMTIgLTIuNzYxNjQ0SDguMDY5NzM4QzguMjM3MTExIC0yLjc2MTY0NCA4LjQ1MjMwNCAtMi43NjE2NDQgOC40NTIzMDQgLTIuOTc2ODM3QzguNDUyMzA0IC0zLjIwMzk4NSA4LjI0OTA2NiAtMy4yMDM5ODUgOC4wNjk3MzggLTMuMjAzOTg1SDQuNzcwMTEyVi02LjUwMzYxMUM0Ljc3MDExMiAtNi42NzA5ODQgNC43NzAxMTIgLTYuODg2MTc3IDQuNTU0OTE5IC02Ljg4NjE3N0M0LjMyNzc3MSAtNi44ODYxNzcgNC4zMjc3NzEgLTYuNjgyOTM5IDQuMzI3NzcxIC02LjUwMzYxMVYtMy4yMDM5ODVIMS4wMjgxNDRDMC44NjA3NzIgLTMuMjAzOTg1IDAuNjQ1NTc5IC0zLjIwMzk4NSAwLjY0NTU3OSAtMi45ODg3OTJDMC42NDU1NzkgLTIuNzYxNjQ0IDAuODQ4ODE3IC0yLjc2MTY0NCAxLjAyODE0NCAtMi43NjE2NDRINC4zMjc3NzFWMC41Mzc5ODNDNC4zMjc3NzEgMC43MDUzNTUgNC4zMjc3NzEgMC45MjA1NDggNC41NDI5NjQgMC45MjA1NDhDNC43NzAxMTIgMC45MjA1NDggNC43NzAxMTIgMC43MTczMSA0Ljc3MDExMiAwLjUzNzk4M1YtMi43NjE2NDRaJyBpZD0nZzItNDMnLz4KPHBhdGggZD0nTTMuNDQzMDg4IC03LjY2MzI2M0MzLjQ0MzA4OCAtNy45MzgyMzIgMy40NDMwODggLTcuOTUwMTg3IDMuMjAzOTg1IC03Ljk1MDE4N0MyLjkxNzA2MSAtNy42MjczOTcgMi4zMTkzMDMgLTcuMTg1MDU2IDEuMDg3OTIgLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OSAtNi44MzgzNTYgMS45NjA2NDggLTYuODM4MzU2IDIuNjE4MTgyIC03LjE0OTE5MVYtMC45MjA1NDhDMi42MTgxODIgLTAuNDkwMTYyIDIuNTgyMzE2IC0wLjM0NjcgMS41MzAyNjIgLTAuMzQ2N0gxLjE1OTY1MVYwQzEuNDgyNDQxIC0wLjAyMzkxIDIuNjQyMDkyIC0wLjAyMzkxIDMuMDM2NjEzIC0wLjAyMzkxUzQuNTc4ODI5IC0wLjAyMzkxIDQuOTAxNjE5IDBWLTAuMzQ2N0g0LjUzMTAwOUMzLjQ3ODk1NCAtMC4zNDY3IDMuNDQzMDg4IC0wLjQ5MDE2MiAzLjQ0MzA4OCAtMC45MjA1NDhWLTcuNjYzMjYzWicgaWQ9J2cyLTQ5Jy8+CjxwYXRoIGQ9J001LjI2MDI3NCAtMi4wMDg0NjhINC45OTcyNkM0Ljk2MTM5NSAtMS44MDUyMyA0Ljg2NTc1MyAtMS4xNDc2OTYgNC43NDYyMDIgLTAuOTU2NDEzQzQuNjYyNTE2IC0wLjg0ODgxNyAzLjk4MTA3MSAtMC44NDg4MTcgMy42MjI0MTYgLTAuODQ4ODE3SDEuNDEwNzFDMS43MzM0OTkgLTEuMTIzNzg2IDIuNDYyNzY1IC0xLjg4ODkxNyAyLjc3MzU5OSAtMi4xNzU4NDFDNC41OTA3ODUgLTMuODQ5NTY0IDUuMjYwMjc0IC00LjQ3MTIzMyA1LjI2MDI3NCAtNS42NTQ3OTVDNS4yNjAyNzQgLTcuMDI5NjM5IDQuMTcyMzU0IC03Ljk1MDE4NyAyLjc4NTU1NCAtNy45NTAxODdTMC41ODU4MDMgLTYuNzY2NjI1IDAuNTg1ODAzIC01LjczODQ4MUMwLjU4NTgwMyAtNS4xMjg3NjcgMS4xMTE4MzEgLTUuMTI4NzY3IDEuMTQ3Njk2IC01LjEyODc2N0MxLjM5ODc1NSAtNS4xMjg3NjcgMS43MDk1ODkgLTUuMzA4MDk1IDEuNzA5NTg5IC01LjY5MDY2QzEuNzA5NTg5IC02LjAyNTQwNSAxLjQ4MjQ0MSAtNi4yNTI1NTMgMS4xNDc2OTYgLTYuMjUyNTUzQzEuMDQwMSAtNi4yNTI1NTMgMS4wMTYxODkgLTYuMjUyNTUzIDAuOTgwMzI0IC02LjI0MDU5OEMxLjIwNzQ3MiAtNy4wNTM1NDkgMS44NTMwNTEgLTcuNjAzNDg3IDIuNjMwMTM3IC03LjYwMzQ4N0MzLjY0NjMyNiAtNy42MDM0ODcgNC4yNjc5OTUgLTYuNzU0NjcgNC4yNjc5OTUgLTUuNjU0Nzk1QzQuMjY3OTk1IC00LjYzODYwNSAzLjY4MjE5MiAtMy43NTM5MjMgMy4wMDA3NDcgLTIuOTg4NzkyTDAuNTg1ODAzIC0wLjI4NjkyNFYwSDQuOTQ5NDRMNS4yNjAyNzQgLTIuMDA4NDY4WicgaWQ9J2cyLTUwJy8+CjxwYXRoIGQ9J00yLjk4ODc5MiAyLjk4ODc5MlYyLjU0NjQ1MUgxLjgyOTE0MVYtOC41MjQwMzVIMi45ODg3OTJWLTguOTY2Mzc2SDEuMzg2OFYyLjk4ODc5MkgyLjk4ODc5MlonIGlkPSdnMi05MScvPgo8cGF0aCBkPSdNMS44NTMwNTEgLTguOTY2Mzc2SDAuMjUxMDU5Vi04LjUyNDAzNUgxLjQxMDcxVjIuNTQ2NDUxSDAuMjUxMDU5VjIuOTg4NzkySDEuODUzMDUxVi04Ljk2NjM3NlonIGlkPSdnMi05MycvPgo8cGF0aCBkPSdNNC42MTQ2OTUgLTMuMTkyMDNDNC42MTQ2OTUgLTMuODM3NjA5IDQuNjE0Njk1IC00LjMxNTgxNiA0LjA4ODY2NyAtNC43ODIwNjdDMy42NzAyMzcgLTUuMTY0NjMzIDMuMTMyMjU0IC01LjMzMjAwNSAyLjYwNjIyNyAtNS4zMzIwMDVDMS42MjU5MDMgLTUuMzMyMDA1IDAuODcyNzI3IC00LjY4NjQyNiAwLjg3MjcyNyAtMy45MDkzNEMwLjg3MjcyNyAtMy41NjI2NCAxLjA5OTg3NSAtMy4zOTUyNjggMS4zNzQ4NDQgLTMuMzk1MjY4QzEuNjYxNzY4IC0zLjM5NTI2OCAxLjg2NTAwNiAtMy41OTg1MDYgMS44NjUwMDYgLTMuODg1NDNDMS44NjUwMDYgLTQuMzc1NTkyIDEuNDM0NjIgLTQuMzc1NTkyIDEuMjU1MjkzIC00LjM3NTU5MkMxLjUzMDI2MiAtNC44Nzc3MDkgMi4xMDQxMSAtNS4wOTI5MDIgMi41ODIzMTYgLTUuMDkyOTAyQzMuMTMyMjU0IC01LjA5MjkwMiAzLjgzNzYwOSAtNC42Mzg2MDUgMy44Mzc2MDkgLTMuNTYyNjRWLTMuMDg0NDMzQzEuNDM0NjIgLTMuMDQ4NTY4IDAuNTI2MDI3IC0yLjA0NDMzNCAwLjUyNjAyNyAtMS4xMjM3ODZDMC41MjYwMjcgLTAuMTc5MzI4IDEuNjI1OTAzIDAuMTE5NTUyIDIuMzU1MTY4IDAuMTE5NTUyQzMuMTQ0MjA5IDAuMTE5NTUyIDMuNjgyMTkyIC0wLjM1ODY1NSAzLjkwOTM0IC0wLjkzMjUwM0MzLjk1NzE2MSAtMC4zNzA2MSA0LjMyNzc3MSAwLjA1OTc3NiA0Ljg0MTg0MyAwLjA1OTc3NkM1LjA5MjkwMiAwLjA1OTc3NiA1Ljc4NjMwMSAtMC4xMDc1OTcgNS43ODYzMDEgLTEuMDY0MDFWLTEuNzMzNDk5SDUuNTIzMjg4Vi0xLjA2NDAxQzUuNTIzMjg4IC0wLjM4MjU2NSA1LjIzNjM2NCAtMC4yODY5MjQgNS4wNjg5OTEgLTAuMjg2OTI0QzQuNjE0Njk1IC0wLjI4NjkyNCA0LjYxNDY5NSAtMC45MjA1NDggNC42MTQ2OTUgLTEuMDk5ODc1Vi0zLjE5MjAzWk0zLjgzNzYwOSAtMS42ODU2NzlDMy44Mzc2MDkgLTAuNTE0MDcyIDIuOTY0ODgyIC0wLjExOTU1MiAyLjQ1MDgwOSAtMC4xMTk1NTJDMS44NjUwMDYgLTAuMTE5NTUyIDEuMzc0ODQ0IC0wLjU0OTkzOCAxLjM3NDg0NCAtMS4xMjM3ODZDMS4zNzQ4NDQgLTIuNzAxODY4IDMuNDA3MjIzIC0yLjg0NTMzIDMuODM3NjA5IC0yLjg2OTI0Vi0xLjY4NTY3OVonIGlkPSdnMi05NycvPgo8cGF0aCBkPSdNOC41NzE4NTYgLTIuOTA1MTA2QzguNTcxODU2IC00LjAxNjkzNiA4LjU3MTg1NiAtNC4zNTE2ODEgOC4yOTY4ODcgLTQuNzM0MjQ3QzcuOTUwMTg3IC01LjIwMDQ5OCA3LjM4ODI5NCAtNS4yNzIyMjkgNi45ODE4MTggLTUuMjcyMjI5QzUuOTg5NTM5IC01LjI3MjIyOSA1LjQ4NzQyMiAtNC41NTQ5MTkgNS4yOTYxMzkgLTQuMDg4NjY3QzUuMTI4NzY3IC01LjAwOTIxNSA0LjQ4MzE4OCAtNS4yNzIyMjkgMy43MzAwMTIgLTUuMjcyMjI5QzIuNTcwMzYxIC01LjI3MjIyOSAyLjExNjA2NSAtNC4yNzk5NSAyLjAyMDQyMyAtNC4wNDA4NDdIMi4wMDg0NjhWLTUuMjcyMjI5TDAuMzgyNTY1IC01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTcgLTQuNzk0MDIyIDEuMjkxMTU4IC00LjcxMDMzNiAxLjI5MTE1OCAtNC4xMjQ1MzNWLTAuODg0NjgyQzEuMjkxMTU4IC0wLjM0NjcgMS4xNTk2NTEgLTAuMzQ2NyAwLjM4MjU2NSAtMC4zNDY3VjBDMC42OTM0IC0wLjAyMzkxIDEuMzM4OTc5IC0wLjAyMzkxIDEuNjczNzI0IC0wLjAyMzkxQzIuMDIwNDIzIC0wLjAyMzkxIDIuNjY2MDAyIC0wLjAyMzkxIDIuOTc2ODM3IDBWLTAuMzQ2N0MyLjIxMTcwNiAtMC4zNDY3IDIuMDY4MjQ0IC0wLjM0NjcgMi4wNjgyNDQgLTAuODg0NjgyVi0zLjEwODM0NEMyLjA2ODI0NCAtNC4zNjM2MzYgMi44OTMxNTEgLTUuMDMzMTI2IDMuNjM0MzcxIC01LjAzMzEyNlM0LjU0Mjk2NCAtNC40MjM0MTIgNC41NDI5NjQgLTMuNjk0MTQ3Vi0wLjg4NDY4MkM0LjU0Mjk2NCAtMC4zNDY3IDQuNDExNDU3IC0wLjM0NjcgMy42MzQzNzEgLTAuMzQ2N1YwQzMuOTQ1MjA1IC0wLjAyMzkxIDQuNTkwNzg1IC0wLjAyMzkxIDQuOTI1NTI5IC0wLjAyMzkxQzUuMjcyMjI5IC0wLjAyMzkxIDUuOTE3ODA4IC0wLjAyMzkxIDYuMjI4NjQzIDBWLTAuMzQ2N0M1LjQ2MzUxMiAtMC4zNDY3IDUuMzIwMDUgLTAuMzQ2NyA1LjMyMDA1IC0wLjg4NDY4MlYtMy4xMDgzNDRDNS4zMjAwNSAtNC4zNjM2MzYgNi4xNDQ5NTYgLTUuMDMzMTI2IDYuODg2MTc3IC01LjAzMzEyNlM3Ljc5NDc3IC00LjQyMzQxMiA3Ljc5NDc3IC0zLjY5NDE0N1YtMC44ODQ2ODJDNy43OTQ3NyAtMC4zNDY3IDcuNjYzMjYzIC0wLjM0NjcgNi44ODYxNzcgLTAuMzQ2N1YwQzcuMTk3MDExIC0wLjAyMzkxIDcuODQyNTkgLTAuMDIzOTEgOC4xNzczMzUgLTAuMDIzOTFDOC41MjQwMzUgLTAuMDIzOTEgOS4xNjk2MTQgLTAuMDIzOTEgOS40ODA0NDggMFYtMC4zNDY3QzguODgyNjkgLTAuMzQ2NyA4LjU4MzgxMSAtMC4zNDY3IDguNTcxODU2IC0wLjcwNTM1NVYtMi45MDUxMDZaJyBpZD0nZzItMTA5Jy8+CjxwYXRoIGQ9J00zLjM0NzQ0NyAtMi44MjE0MkMzLjY5NDE0NyAtMy4yNzU3MTYgNC4xOTYyNjQgLTMuOTIxMjk1IDQuNDIzNDEyIC00LjE3MjM1NEM0LjkxMzU3NCAtNC43MjIyOTEgNS40NzU0NjcgLTQuODA1OTc4IDUuODU4MDMyIC00LjgwNTk3OFYtNS4xNTI2NzdDNS4zNDM5NiAtNS4xMjg3NjcgNS4zMjAwNSAtNS4xMjg3NjcgNC44NTM3OTggLTUuMTI4NzY3QzQuMzk5NTAyIC01LjEyODc2NyA0LjM3NTU5MiAtNS4xMjg3NjcgMy43Nzc4MzMgLTUuMTUyNjc3Vi00LjgwNTk3OEMzLjkzMzI1IC00Ljc4MjA2NyA0LjEyNDUzMyAtNC43MTAzMzYgNC4xMjQ1MzMgLTQuNDM1MzY3QzQuMTI0NTMzIC00LjIzMjEzIDQuMDE2OTM2IC00LjEwMDYyMyAzLjk0NTIwNSAtNC4wMDQ5ODFMMy4xODAwNzUgLTMuMDM2NjEzTDIuMjQ3NTcyIC00LjI2Nzk5NUMyLjIxMTcwNiAtNC4zMTU4MTYgMi4xMzk5NzUgLTQuNDIzNDEyIDIuMTM5OTc1IC00LjUwNzA5OEMyLjEzOTk3NSAtNC41Nzg4MjkgMi4xOTk3NTEgLTQuNzk0MDIyIDIuNTU4NDA2IC00LjgwNTk3OFYtNS4xNTI2NzdDMi4yNTk1MjcgLTUuMTI4NzY3IDEuNjQ5ODEzIC01LjEyODc2NyAxLjMyNzAyNCAtNS4xMjg3NjdDMC45MzI1MDMgLTUuMTI4NzY3IDAuOTA4NTkzIC01LjEyODc2NyAwLjE3OTMyOCAtNS4xNTI2NzdWLTQuODA1OTc4QzAuNzg5MDQxIC00LjgwNTk3OCAxLjAxNjE4OSAtNC43ODIwNjcgMS4yNjcyNDggLTQuNDU5Mjc4TDIuNjY2MDAyIC0yLjYzMDEzN0MyLjY4OTkxMyAtMi42MDYyMjcgMi43Mzc3MzMgLTIuNTM0NDk2IDIuNzM3NzMzIC0yLjQ5ODYzUzEuODA1MjMgLTEuMjkxMTU4IDEuNjg1Njc5IC0xLjEzNTc0MUMxLjE1OTY1MSAtMC40OTAxNjIgMC42MzM2MjQgLTAuMzU4NjU1IDAuMTE5NTUyIC0wLjM0NjdWMEMwLjU3Mzg0OCAtMC4wMjM5MSAwLjU5Nzc1OCAtMC4wMjM5MSAxLjExMTgzMSAtMC4wMjM5MUMxLjU2NjEyNyAtMC4wMjM5MSAxLjU5MDAzNyAtMC4wMjM5MSAyLjE4Nzc5NiAwVi0wLjM0NjdDMS45MDA4NzIgLTAuMzgyNTY1IDEuODUzMDUxIC0wLjU2MTg5MyAxLjg1MzA1MSAtMC43MjkyNjVDMS44NTMwNTEgLTAuOTIwNTQ4IDEuOTM2NzM3IC0xLjAxNjE4OSAyLjA1NjI4OSAtMS4xNzE2MDZDMi4yMzU2MTYgLTEuNDIyNjY1IDIuNjMwMTM3IC0xLjkxMjgyNyAyLjkxNzA2MSAtMi4yODM0MzdMMy44OTczODUgLTEuMDA0MjM0QzQuMTAwNjIzIC0wLjc0MTIyIDQuMTAwNjIzIC0wLjcxNzMxIDQuMTAwNjIzIC0wLjY0NTU3OUM0LjEwMDYyMyAtMC41NDk5MzggNC4wMDQ5ODEgLTAuMzU4NjU1IDMuNjgyMTkyIC0wLjM0NjdWMEMzLjk5MzAyNiAtMC4wMjM5MSA0LjU3ODgyOSAtMC4wMjM5MSA0LjkxMzU3NCAtMC4wMjM5MUM1LjMwODA5NSAtMC4wMjM5MSA1LjMzMjAwNSAtMC4wMjM5MSA2LjA0OTMxNSAwVi0wLjM0NjdDNS40MTU2OTEgLTAuMzQ2NyA1LjIwMDQ5OCAtMC4zNzA2MSA0LjkxMzU3NCAtMC43NTMxNzZMMy4zNDc0NDcgLTIuODIxNDJaJyBpZD0nZzItMTIwJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc1Ni40MTMyNjcnIHhsaW5rOmhyZWY9JyNnMS04NCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNjQuOTAwMTAzJyB4bGluazpocmVmPScjZzItOTEnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzY4LjE1MTc2NCcgeGxpbms6aHJlZj0nI2cxLTEwNScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNzIuMTQ1MTk2JyB4bGluazpocmVmPScjZzItOTMnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9Jzc4LjcxNzY4NycgeGxpbms6aHJlZj0nI2cwLTYyJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc5MS4zMzcwMTMnIHhsaW5rOmhyZWY9JyNnMi0xMDknIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEwMS4wOTE5OTcnIHhsaW5rOmhyZWY9JyNnMi05NycgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTA2Ljk0NDk4NycgeGxpbms6aHJlZj0nI2cyLTEyMCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTEzLjEyMzE0NCcgeGxpbms6aHJlZj0nI2cyLTQwJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMTcuNjc1NDcnIHhsaW5rOmhyZWY9JyNnMS04NCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTI2LjE2MjMwNScgeGxpbms6aHJlZj0nI2cyLTkxJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMjkuNDEzOTY3JyB4bGluazpocmVmPScjZzItNTAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEzNS4yNjY5NTcnIHhsaW5rOmhyZWY9JyNnMS0xMDUnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE0MS45MTcwNTMnIHhsaW5rOmhyZWY9JyNnMi00MycgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTUzLjY3ODM2OCcgeGxpbms6aHJlZj0nI2cyLTQ5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxNTkuNTMxMzU4JyB4bGluazpocmVmPScjZzItOTMnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE2Mi43ODMwMTknIHhsaW5rOmhyZWY9JyNnMS01OScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTY4LjAyNzE3OCcgeGxpbms6aHJlZj0nI2cxLTg0JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxNzYuNTE0MDE0JyB4bGluazpocmVmPScjZzItOTEnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE3OS43NjU2NzUnIHhsaW5rOmhyZWY9JyNnMi01MCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTg1LjYxODY2NScgeGxpbms6aHJlZj0nI2cxLTEwNScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTkyLjI2ODc2MScgeGxpbms6aHJlZj0nI2cyLTQzJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScyMDQuMDMwMDc2JyB4bGluazpocmVmPScjZzItNTAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzIwOS44ODMwNjYnIHhsaW5rOmhyZWY9JyNnMi05MycgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMjEzLjEzNDcyOCcgeGxpbms6aHJlZj0nI2cyLTQxJyB5PSc2NS43NTM0MjUnLz4KPC9nPgo8L3N2Zz4=) . On en déduit
nécessairement que le premier élément du tableau est le plus grand.
Maintenant comment transformer un tableau en un autre qui respecte cette
contrainte ?
. On en déduit
nécessairement que le premier élément du tableau est le plus grand.
Maintenant comment transformer un tableau en un autre qui respecte cette
contrainte ?
%matplotlib inline
Transformer en tas#
def swap(tab, i, j):
"Echange deux éléments."
tab[i], tab[j] = tab[j], tab[i]
def entas(heap):
"Organise un ensemble selon un tas."
modif = 1
while modif > 0:
modif = 0
i = len(heap) - 1
while i > 0:
root = (i-1) // 2
if heap[root] < heap[i]:
swap(heap, root, i)
modif += 1
i -= 1
return heap
ens = [1,2,3,4,7,10,5,6,11,12,3]
entas(ens)
[12, 11, 5, 10, 7, 3, 1, 6, 4, 3, 2]
Comme ce n’est pas facile de vérifer que c’est un tas, on le dessine.
Dessiner un tas#
from pyensae.graphhelper import draw_diagram
def dessine_tas(heap):
rows = ["blockdiag {"]
for i, v in enumerate(heap):
if i*2+1 < len(heap):
rows.append('"[{}]={}" -> "[{}]={}";'.format(
i, heap[i], i * 2 + 1, heap[i*2+1]))
if i*2+2 < len(heap):
rows.append('"[{}]={}" -> "[{}]={}";'.format(
i, heap[i], i * 2 + 2, heap[i*2+2]))
rows.append("}")
return draw_diagram("\n".join(rows))
ens = [1,2,3,4,7,10,5,6,11,12,3]
dessine_tas(entas(ens))
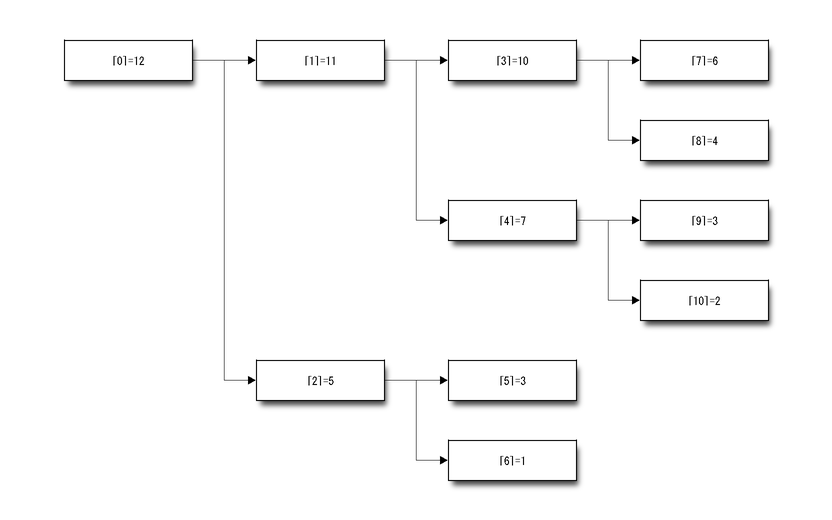
Le nombre entre crochets est la position, l’autre nombre est la valeur à cette position. Cette représentation fait apparaître une structure d’arbre binaire.
Première version#
def swap(tab, i, j):
"Echange deux éléments."
tab[i], tab[j] = tab[j], tab[i]
def _heapify_max_bottom(heap):
"Organise un ensemble selon un tas."
modif = 1
while modif > 0:
modif = 0
i = len(heap) - 1
while i > 0:
root = (i-1) // 2
if heap[root] < heap[i]:
swap(heap, root, i)
modif += 1
i -= 1
def _heapify_max_up(heap):
"Organise un ensemble selon un tas."
i = 0
while True:
left = 2*i + 1
right = left+1
if right < len(heap):
if heap[left] > heap[i] >= heap[right]:
swap(heap, i, left)
i = left
elif heap[right] > heap[i]:
swap(heap, i, right)
i = right
else:
break
elif left < len(heap) and heap[left] > heap[i]:
swap(heap, i, left)
i = left
else:
break
def topk_min(ens, k):
"Retourne les k plus petits éléments d'un ensemble."
heap = ens[:k]
_heapify_max_bottom(heap)
for el in ens[k:]:
if el < heap[0]:
heap[0] = el
_heapify_max_up(heap)
return heap
ens = [1,2,3,4,7,10,5,6,11,12,3]
for k in range(1, len(ens)-1):
print(k, topk_min(ens, k))
1 [1]
2 [2, 1]
3 [3, 2, 1]
4 [3, 3, 1, 2]
5 [4, 3, 1, 3, 2]
6 [5, 4, 3, 3, 2, 1]
7 [5, 6, 3, 4, 2, 3, 1]
8 [5, 7, 3, 6, 2, 3, 1, 4]
9 [5, 10, 3, 7, 2, 3, 1, 6, 4]
Même chose avec les indices au lieu des valeurs#
def _heapify_max_bottom_position(ens, pos):
"Organise un ensemble selon un tas."
modif = 1
while modif > 0:
modif = 0
i = len(pos) - 1
while i > 0:
root = (i-1) // 2
if ens[pos[root]] < ens[pos[i]]:
swap(pos, root, i)
modif += 1
i -= 1
def _heapify_max_up_position(ens, pos):
"Organise un ensemble selon un tas."
i = 0
while True:
left = 2*i + 1
right = left+1
if right < len(pos):
if ens[pos[left]] > ens[pos[i]] >= ens[pos[right]]:
swap(pos, i, left)
i = left
elif ens[pos[right]] > ens[pos[i]]:
swap(pos, i, right)
i = right
else:
break
elif left < len(pos) and ens[pos[left]] > ens[pos[i]]:
swap(pos, i, left)
i = left
else:
break
def topk_min_position(ens, k):
"Retourne les positions des k plus petits éléments d'un ensemble."
pos = list(range(k))
_heapify_max_bottom_position(ens, pos)
for i, el in enumerate(ens[k:]):
if el < ens[pos[0]]:
pos[0] = k + i
_heapify_max_up_position(ens, pos)
return pos
ens = [1,2,3,7,10,4,5,6,11,12,3]
for k in range(1, len(ens)-1):
pos = topk_min_position(ens, k)
print(k, pos, [ens[i] for i in pos])
1 [0] [1]
2 [1, 0] [2, 1]
3 [2, 1, 0] [3, 2, 1]
4 [10, 2, 0, 1] [3, 3, 1, 2]
5 [5, 10, 0, 2, 1] [4, 3, 1, 3, 2]
6 [6, 5, 2, 10, 1, 0] [5, 4, 3, 3, 2, 1]
7 [5, 7, 10, 6, 1, 2, 0] [4, 6, 3, 5, 2, 3, 1]
8 [5, 3, 10, 7, 1, 2, 0, 6] [4, 7, 3, 6, 2, 3, 1, 5]
9 [5, 4, 10, 3, 1, 2, 0, 7, 6] [4, 10, 3, 7, 2, 3, 1, 6, 5]
import numpy.random as rnd
X = rnd.randn(10000)
%timeit topk_min(X, 20)
5.59 ms ± 728 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit topk_min_position(X, 20)
7.85 ms ± 544 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Coût de l’algorithme#
from cpyquickhelper.numbers import measure_time
from tqdm import tqdm
from pandas import DataFrame
rows = []
for n in tqdm(list(range(1000, 20001, 1000))):
X = rnd.randn(n)
res = measure_time('topk_min_position(X, 100)',
{'X': X, 'topk_min_position': topk_min_position},
div_by_number=True,
number=10)
res["size"] = n
rows.append(res)
df = DataFrame(rows)
df.head()
100%|██████████| 20/20 [00:23<00:00, 1.78s/it]
| average | deviation | min_exec | max_exec | repeat | number | context_size | size | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.003916 | 0.000363 | 0.003336 | 0.004570 | 10 | 10 | 240 | 1000 |
| 1 | 0.005436 | 0.001039 | 0.004235 | 0.007412 | 10 | 10 | 240 | 2000 |
| 2 | 0.005306 | 0.001051 | 0.004090 | 0.007401 | 10 | 10 | 240 | 3000 |
| 3 | 0.005341 | 0.000830 | 0.004376 | 0.007003 | 10 | 10 | 240 | 4000 |
| 4 | 0.007047 | 0.001786 | 0.005223 | 0.012082 | 10 | 10 | 240 | 5000 |
import matplotlib.pyplot as plt
df[['size', 'average']].set_index('size').plot()
plt.title("Coût topk en fonction de la taille du tableau");
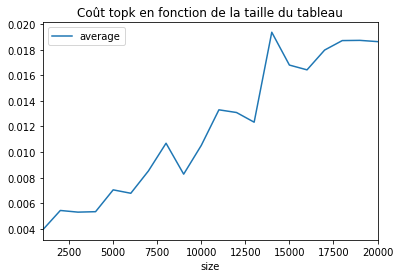
A peu près linéaire comme attendu.
rows = []
X = rnd.randn(10000)
for k in tqdm(list(range(500, 2001, 150))):
res = measure_time('topk_min_position(X, k)',
{'X': X, 'topk_min_position': topk_min_position, 'k': k},
div_by_number=True,
number=5)
res["k"] = k
rows.append(res)
df = DataFrame(rows)
df.head()
0%| | 0/11 [00:00<?, ?it/s]
9%|▉ | 1/11 [00:00<00:09, 1.11it/s]
18%|█▊ | 2/11 [00:02<00:09, 1.05s/it]
27%|██▋ | 3/11 [00:03<00:09, 1.20s/it]
36%|███▋ | 4/11 [00:05<00:09, 1.34s/it]
45%|████▌ | 5/11 [00:07<00:08, 1.44s/it]
55%|█████▍ | 6/11 [00:08<00:07, 1.54s/it]
64%|██████▎ | 7/11 [00:10<00:06, 1.64s/it]
73%|███████▎ | 8/11 [00:13<00:05, 1.86s/it]
82%|████████▏ | 9/11 [00:15<00:03, 1.93s/it]
91%|█████████ | 10/11 [00:17<00:01, 1.98s/it]
100%|██████████| 11/11 [00:19<00:00, 2.16s/it]
| average | deviation | min_exec | max_exec | repeat | number | context_size | k | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.018026 | 0.002823 | 0.015226 | 0.025344 | 10 | 5 | 240 | 500 |
| 1 | 0.027577 | 0.008949 | 0.018939 | 0.043367 | 10 | 5 | 240 | 650 |
| 2 | 0.031409 | 0.011282 | 0.020159 | 0.056507 | 10 | 5 | 240 | 800 |
| 3 | 0.032973 | 0.007518 | 0.025192 | 0.047946 | 10 | 5 | 240 | 950 |
| 4 | 0.033467 | 0.007725 | 0.025187 | 0.051844 | 10 | 5 | 240 | 1100 |
df[['k', 'average']].set_index('k').plot()
plt.title("Coût topk en fonction de k");
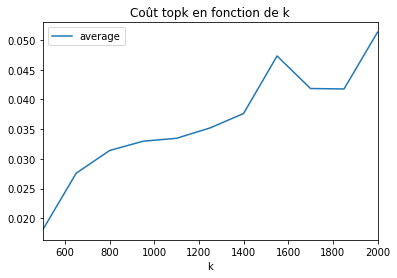
Pas évident, au pire en  , au mieux en
, au mieux en  .
.
Version simplifiée#
A-t-on vraiment besoin de _heapify_max_bottom_position ?
def _heapify_max_up_position_simple(ens, pos, first):
"Organise un ensemble selon un tas."
i = first
while True:
left = 2*i + 1
right = left+1
if right < len(pos):
if ens[pos[left]] > ens[pos[i]] >= ens[pos[right]]:
swap(pos, i, left)
i = left
elif ens[pos[right]] > ens[pos[i]]:
swap(pos, i, right)
i = right
else:
break
elif left < len(pos) and ens[pos[left]] > ens[pos[i]]:
swap(pos, i, left)
i = left
else:
break
def topk_min_position_simple(ens, k):
"Retourne les positions des k plus petits éléments d'un ensemble."
pos = list(range(k))
pos[k-1] = 0
for i in range(1, k):
pos[k-i-1] = i
_heapify_max_up_position_simple(ens, pos, k-i-1)
for i, el in enumerate(ens[k:]):
if el < ens[pos[0]]:
pos[0] = k + i
_heapify_max_up_position_simple(ens, pos, 0)
return pos
ens = [1,2,3,7,10,4,5,6,11,12,3]
for k in range(1, len(ens)-1):
pos = topk_min_position_simple(ens, k)
print(k, pos, [ens[i] for i in pos])
1 [0] [1]
2 [1, 0] [2, 1]
3 [2, 1, 0] [3, 2, 1]
4 [10, 2, 1, 0] [3, 3, 2, 1]
5 [5, 10, 2, 1, 0] [4, 3, 3, 2, 1]
6 [5, 6, 10, 2, 1, 0] [4, 5, 3, 3, 2, 1]
7 [6, 7, 10, 5, 2, 1, 0] [5, 6, 3, 4, 3, 2, 1]
8 [5, 4, 10, 7, 6, 2, 1, 0] [4, 10, 3, 6, 5, 3, 2, 1]
9 [3, 4, 6, 5, 7, 10, 2, 1, 0] [7, 10, 5, 4, 6, 3, 3, 2, 1]
X = rnd.randn(10000)
%timeit topk_min_position_simple(X, 20)
7.5 ms ± 810 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)