1A.soft Tests unitaires, setup et ingéniérie logiciel (correction)#
Ce notebook donne des éléments de réponses pour 1A.soft - Tests unitaires, setup et ingéniérie logicielle. Le code source peut-être trouvé sur GitHub: td1a_unit_test_ci.
Ecrire une fonction#
<<<
def solve_polynom(a, b, c):
if a == 0:
# One degree.
return (-c / b, )
det = b * b - (4 * a * c)
if det < 0:
# No real solution.
return None
det = det ** 0.5
x1 = (b - det) / (2 * a)
x2 = (b + det) / (2 * a)
return x1, x2
print(solve_polynom(1, 1, -1))
>>>
(-0.6180339887498949, 1.618033988749895)
Ecrire un test unitaire#
import unittest
from polynom import solve_polynom
class TestPolynom(unittest.TestCase):
"""
The class tests the three possible cases.
Another one is still not tested...
"""
def test_solve_polynom(self):
x1, x2 = solve_polynom(1, 0, -4)
self.assertEqual((x1, x2), (-2, 2))
def test_solve_polynom_linear(self):
x1 = solve_polynom(0, 1, -4)
self.assertEqual(x1, (4,))
def test_solve_polynom_no_soolution(self):
x1 = solve_polynom(1, 1, 4)
self.assertEqual(x1, None)
if __name__ == '__main__':
unittest.main()
On peut lancer le test unitaire depuis la ligne de commande.
python -m unittest test_polynom.py
Ou tout simplement pour exécuter tous les fichiers de tests :
python -m unittest
Couverture ou coverage#
On utilise le module coverage qui se résume à une ligne de commande.
coverage run -m unittest
Un fichier .coverage apparaît. Ce sont des données brutes plus facilement lisible après leur conversion en un rapport de couverture.
coverage report -m
Ce qui donne :
Name Stmts Miss Cover Missing
-----------------------------------------------
polynom.py 10 0 100%
test_polynom.py 14 1 93% 29
-----------------------------------------------
TOTAL 24 1 96%
Ou alors au format html:
coverage html -d coverage.html
Ce qui donne coverage.html/index.html.
Créer un compte GitHub#
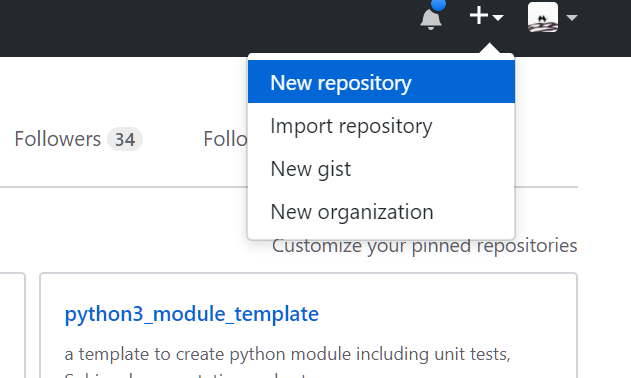
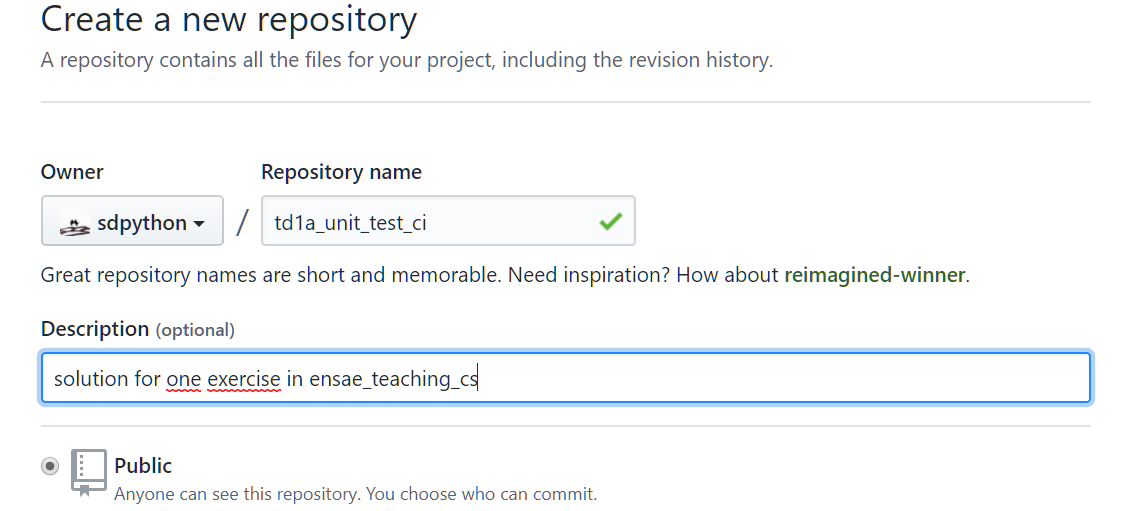
A suivre par image. Tout d’abord sur le site de GitHub, on crée un nouveau repository :
Puis depuis l’application Github Desktop où on clone le repository.
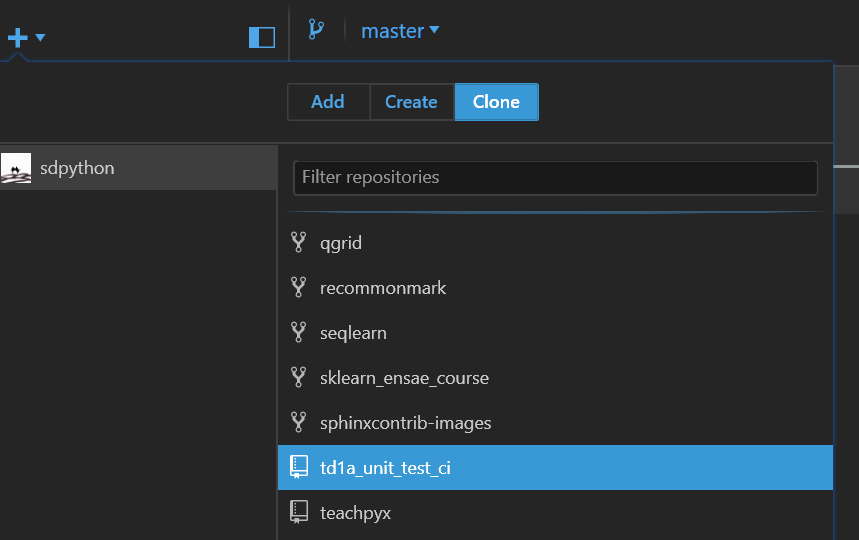
Cela correspond au repository : td1a_unit_test_ci.
Le principe :
GitHub est ce qu’on appelle un emplacement remote. GitHub est comme un serveur git, il détient l’intégralité des fichiers du projet ce lequel on travaille. Il garde l’historique des modifications apportées à ce projet. Une copie locale est crée lorsqu’on clone. Dès lors, on passe son temps à soit envoyer au remote repository ses modifications locales soit récupérer les modifications des autres développeurs apportées au remote repository. Quelques repères et conventions :
README.rst : le fichier résume le projet.
.gitignore : ce fichier indique quels fichier ne doivent pas être pris en compte dans le repository. Ce sont principalement des fichiers créés lors de la compilation ou par le programme lui-même. Les stocker n’est pas utile puisqu’ils sont créés par le programme qu’on développe.
LICENSE.rst : la licence détermine la façon dont vous souhaitez que votre travail soit utilisé. Ici, c’est la licence MIT. Elle stipule simplement que ce code peut être modifié ou réutilisé par quiconque à condition que cette licence y soit incluse afin de préciser l’auteur.
La page commit garde la trace des modifications. Pour contribuer à ce projet, il faut d’abord le rapatrier sur son propre compte GitHub en le forkant.

Intégration continue#
travis est un des plus simples. Nous allons essayer circleci. Il fonctionne comme tous les autres. Il faut d’abord créer un compte. On ajoute le projet à la liste de ceux qu’il faut exécuter de façon régulière.
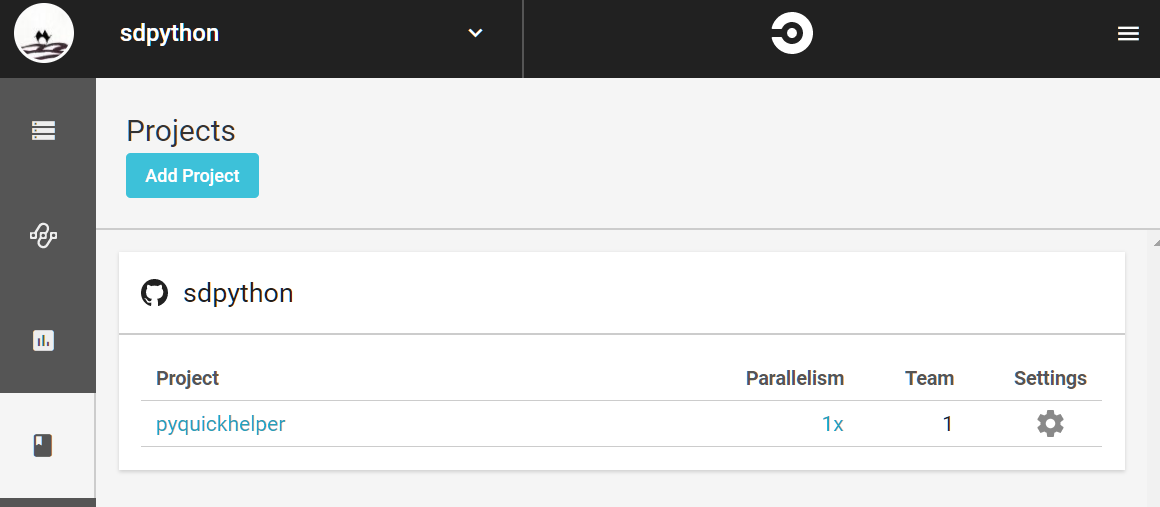

On suit les instructions et on crée un fichier de configuration .circleci/config.yml
qui précise la commande à lancer pour exécuter les tests unitaires.
Le fichier config.yml précise la version de
Python à utiliser. Il peut y en avoir plusieurs.
On spécifie les modules à installer dans le fichier requirements.txt
(qui ne contient que la ligne coverage) puis
la commande à exécuter :
version: 2
jobs:
build:
docker:
- image: circleci/python:3.6.1
working_directory: ~/repo
steps:
- checkout
- restore_cache:
keys:
- v1-dependencies-{{ checksum "requirements.txt" }}
- v1-dependencies-
- run:
name: install dependencies
command: |
python3 -m venv venv
. venv/bin/activate
pip install -r requirements.txt
- save_cache:
paths:
- ./venv
key: v1-dependencies-{{ checksum "requirements.txt" }}
- run:
name: run tests
command: |
. venv/bin/activate
python -m unittest
- store_artifacts:
path: test-reports
destination: test-reports
Le résultat est disponible à circleci/td1a_unit_test_ci. Le site génère une image pour indiquer le statut de la dernière exécution.
Et on l’insère dans le fichier README.rst:
.. image:: https://circleci.com/gh/sdpython/td1a_unit_test_ci/tree/master.svg?style=svg
:target: https://circleci.com/gh/sdpython/td1a_unit_test_ci/tree/master
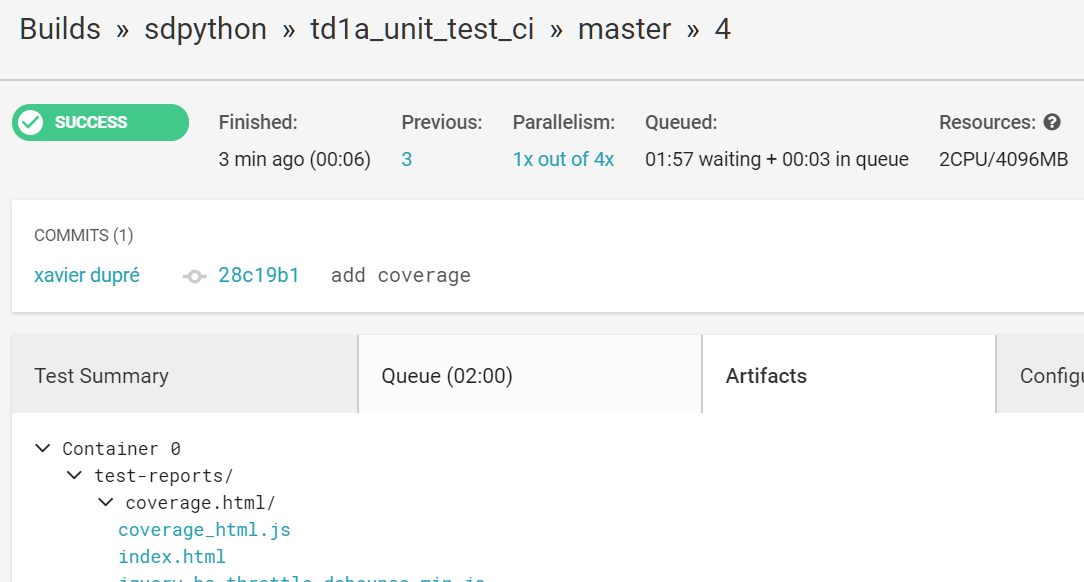
Le résultat est tout de suite visible sur GitHub. Le dashboard résume les résultats des dernières exécution de tous les projets. On ajoute une ligne pour produire le rapport de couverture : commit add coverage. Ce changement crée le rapport de couverture dans un endroit spécifique appellé artifacts et circleci conserve tout ce qui copié dans ce répertoire. On peut alors les consulter.
Ecrire un setup#
Le setup permet de construire un fichier de telle sorte qu’un autre utilisateur pourra utiliser le module en l’installant avec pip :
pip install td1a_unit_test_ci
Le setup est assez court et toujours dans un fichier setup.py.
C’est le plus souvent un copier/coller. On déplace également le code
de façon à avoir un répertoire de source et un de test. On ajoute également
un fichier __init__.py vide pour signifer que c’est un module
ce que le setup découvrira automatiquement grâce à la fonction
find-packages.
On crée un package .tar.gz qui contient l’ensemble des sources avec l’instruction :
python setup.py sdist
On crée un fichier .whl qui ne contient que les fichiers sources avec l’instruction :
python setup.py bdist_wheel
Pour créer un wheel, il faut installer le package wheel et l’ajouter aux dépendances du build. Ceci est résumé dans le commit move source for the setup. Il reste à mettre à jour la configuration de l’intégration continue et ses changements sont visibles dans les commits suivants. Le build fait maintenant partie des artifacts et chaque version du module peut être installée.
Ecrire la documentation#
L’outil le plus utilisé pour écrire la documentation d’un module est
Sphinx. Il reprend
la documentation de chaque fonction pour en faire un site HTML,
un document PDF. Il requiert l’installation de dépendences
telles que MiKTeX, pandoc, InkScape
pour faire inclure des formules de mathématiques ou des documents PDF.
Il faut lire la documentation du site pour apprendre la syntaxe
ReST.
Dans l’immédiat, on commence avec une documentation quasi vide
dans le répertoire doc et
sphinx-quickstart.
sphinx-quickstart
Il suffit de répondre à une batterie de question pour confgurer le projet. Après quelques modifications, j’ai abouti aux modifications suivantes : commit sphinx configuration. Et quand tout est fini, il faut exécuter :
sphinx-build -M html doc build
Et on obtient :
Running Sphinx v1.6.3
loading translations [fr]... done
loading pickled environment... not yet created
loading intersphinx inventory from https://docs.python.org/objects.inv...
intersphinx inventory has moved: https://docs.python.org/objects.inv -> https://docs.python.org/2/objects.inv
building [mo]: targets for 0 po files that are out of date
building [html]: targets for 1 source files that are out of date
updating environment: 1 added, 0 changed, 0 removed
reading sources... [100%] index
looking for now-outdated files... none found
pickling environment... done
checking consistency... done
preparing documents... done
writing output... [100%] index
generating indices... genindex
writing additional pages... search
copying static files... done
copying extra files... done
dumping search index in French (code: fr) ... done
dumping object inventory... done
build succeeded.
Le thème le plus courant pour la documentation d’un module Python est readthedocs. On le change avec les instructions de configuration. Voir commit change sphinx theme.
Il reste à ajouter une page sur le fichier qui contient l’unique module de l’extension ce qu’on fait avec l’instruction automodule. Voir commit add module polynom into the documentation. Il ne reste plus qu’à ajouter ces instructions au process d’intégration continue : commit add documentation to circleci. Le dernier commit divise l’unique commande en plusieurs afin que cela soit plus visible sur le site de circleci. Voir commit split circleci commands.
Coding Style#
Le style est le genre de querelles sans fin où les développeurs s’écharpent à propos de la façon d’écrire le code le plus lisible qui soit. Je ne vais pas ici décider du meilleur style pour deux raisons. La première est que bien souvent chacun a son propre style. La seconde est que le langage Python a décidé de décrire un style standard sous la forme de règles : PEP8 et que la grande majorité des développeurs les suit. Le troisième est que je serais bien incapable de vous décrire ces règles car je ne les connais pas. J’utilise un outil qui modifie mon code afin qu’il suive ces règles : autopep8. Je l’applique à l’ensemble du répertoire :
autopep8 --in-place --aggressive --aggressive --recursive .
Cela donne commit applies autopep8. Pour tester si le style est correct, on peut utiliser le module flake8.
flake8
.\doc\conf.py:12:1: E402 module level import not at top of file
.\doc\conf.py:36:1: E402 module level import not at top of file
.\td1a_unit_test_ci\__init__.py:1:1: E265 block comment should start with '# '
Il existe aussi des règles pour la documentation PEP 257. docformatter permet de formatter la documentation.
docformatter -r -i td1a_unit_test_ci
Le module pydocstyle vérifie que les règles sont respectées.
pydocstring td1a_unit_test_ci
Un dernier module unify
unifie la façon dont les chaînes de caractères sont écrites,
plus souvent des ' que des ".
Est-ce vraiment utile ?
Oui pour deux raisons. La première est de rendre un programme plus lisible. Peu à peu on s’habitue à un style. Un code est plus facile à lire si les mêmes conventions sont appliquées. La seconde raison est liée à git. Si tout le monde suit les mêmes règles, cela minimise les différences entre un code écrit par un développeur et le même code modifié par un autre.
Dernière étape : PyPi#
Pour soumettre sur PyPi, il faut d’abord s’enregister
sur le site, choisir un login et un mot de passe. Il faut ensuite créer le fichier
.pypirc dans le répertoire utilisateur
(variable d’environnement
USERPROFILE sous Windows, $HOME sous Linux). Vous pouvez aussi suivre les instructions
décrites sur The .pypirc file.
[distutils]
index-servers =
pypi
[pypi]
repository=https://pypi.python.org/pypi
username=<login>
password=<password>
Pour publier le package, il suffit d’exécuter la ligne de commande :
python setup.py bdist_wheel upload
Il est également de publier la documentation avec :
python setup.py upload_docs --upload-dir=doc/build
Agilité#
open source / propriétaire
Mettre les sources sur GitHub et CircleCI ne pose pas de problème pour un projet open source. Pour un projet propriétaire, il faut soit payer le service proposé par ces deux sites soit installer soi-même le même type d’outils. GitLab est open source et peut être installé en tant que serveur git. Jenkins est très facile à installer en locale et remplit les mêmes fonctions que CircleCI.
travailler à plusieurs
Dans ce cas, il est essentiel de comprendre le concept de branche. Chaque développeur crée une branche pour effectuer ses modifications puis soumet une pull request lorsqu’il a terminé pour propager ses modifications dans la branche principale. Il s’ensuit une revue de code où les auteurs principaux (ceux qui ont droit de modifier la branche principale) argumentent telle ou telle partie du code, demandent des changements ou approuvent.
historique
Il est d’usage de garder la trace des nouvelles fonctionnalités ajoutées ou bugs fixés à chaque modification. Il est aisé alors de communiquer sur les changements intervenus d’une version à la suivante. C’est grâce à un historique comme celui scikit-learn que vous pouvez décider si cela résoud le problème qui vous occupe actuellement.
Prolongements#
dépendances internes
Travailler à plusieurs, créer, fusionner des branches sur git devient vite une tâche quotidienne. Les tests unitaires augmentent la durée des tests et on se pose vite la question de continuer à développement la librairie en un seul tenant ou à la diviser en deux ou trois parties plus faciles à traiter indépendemment les unes des autres. On un vient vite à créer un système de dépendances. Cela veut dire entre autre maintenant un système de dépendance interne, ce qu’on peut faire en Python avec pypiserver.
tests de vitesse
La version 3 du langage Python était beaucoup plus lente que la version 2. C’est une des raisons qui fait que celle-ci perdure plus longtemps qu’espéré. C’est pourquoi maintenant un site a été mis sur pied pour évaluer la vitesse du langage sur une série de test Python Speed Center. C’est sans doute une chose à laquelle il faudra songer pour mesurer des améliorations sur une grande variété de situations.