Note
Click here to download the full example code
numpy.digitize as a tree#
Function numpy.digitize transforms a real variable
into a discrete one by returning the buckets the variable
falls into. This bucket can be efficiently retrieved by doing a
binary search over the bins. That’s equivalent to decision tree.
Function digitize2tree.
Simple example#
import warnings
import numpy
from pandas import DataFrame, pivot, pivot_table
import matplotlib.pyplot as plt
from onnxruntime import InferenceSession
from sklearn.tree import export_text
from skl2onnx import to_onnx
from cpyquickhelper.numbers.speed_measure import measure_time
from mlinsights.mltree import digitize2tree
from tqdm import tqdm
x = numpy.array([0.2, 6.4, 3.0, 1.6])
bins = numpy.array([0.0, 1.0, 2.5, 4.0, 7.0])
expected = numpy.digitize(x, bins, right=True)
tree = digitize2tree(bins, right=True)
pred = tree.predict(x.reshape((-1, 1)))
print(expected, pred)
[1 4 3 2] [1. 4. 3. 2.]
The tree looks like the following.
print(export_text(tree, feature_names=['x']))
|--- x <= 2.50
| |--- x <= 1.00
| | |--- x <= 0.00
| | | |--- value: [0.00]
| | |--- x > 0.00
| | | |--- value: [1.00]
| |--- x > 1.00
| | |--- value: [2.00]
|--- x > 2.50
| |--- x <= 4.00
| | |--- x <= 2.50
| | | |--- value: [2.00]
| | |--- x > 2.50
| | | |--- value: [3.00]
| |--- x > 4.00
| | |--- x <= 7.00
| | | |--- x <= 4.00
| | | | |--- value: [3.00]
| | | |--- x > 4.00
| | | | |--- value: [4.00]
| | |--- x > 7.00
| | | |--- value: [5.00]
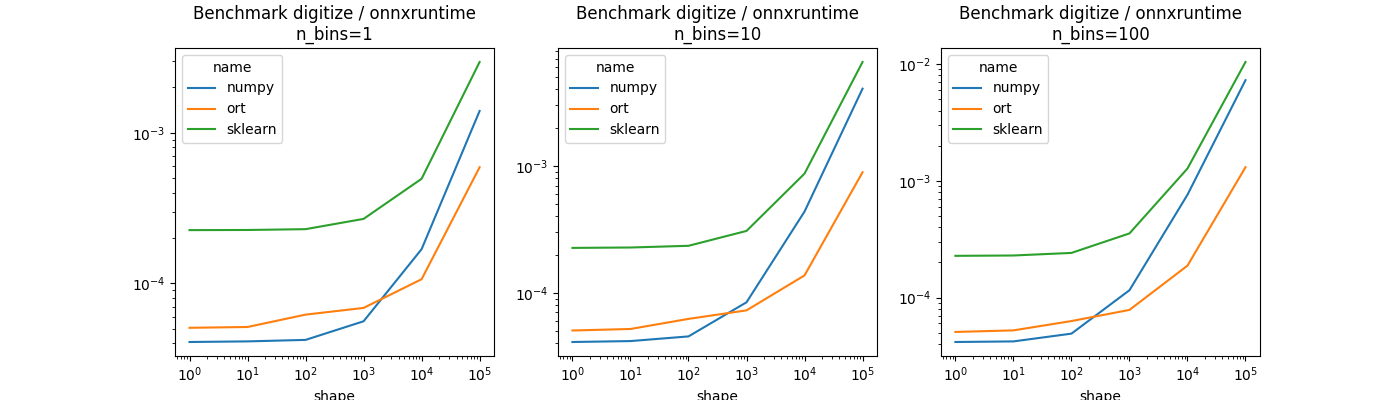
Benchmark#
Let’s measure the processing time. numpy should be much faster than scikit-learn as it is adding many verification. However, the benchmark also includes a conversion of the tree into ONNX and measure the processing time with onnxruntime.
obs = []
for shape in tqdm([1, 10, 100, 1000, 10000, 100000]):
x = numpy.random.random(shape).astype(numpy.float32)
if shape < 1000:
repeat = number = 100
else:
repeat = number = 10
for n_bins in [1, 10, 100]:
bins = (numpy.arange(n_bins) / n_bins).astype(numpy.float32)
ti = measure_time(
"numpy.digitize(x, bins, right=True)",
context={'numpy': numpy, "x": x, "bins": bins},
div_by_number=True, repeat=repeat, number=number)
ti['name'] = 'numpy'
ti['n_bins'] = n_bins
ti['shape'] = shape
obs.append(ti)
tree = digitize2tree(bins, right=True)
ti = measure_time(
"tree.predict(x)",
context={'numpy': numpy, "x": x.reshape((-1, 1)), "tree": tree},
div_by_number=True, repeat=repeat, number=number)
ti['name'] = 'sklearn'
ti['n_bins'] = n_bins
ti['shape'] = shape
obs.append(ti)
with warnings.catch_warnings():
warnings.simplefilter("ignore", category=FutureWarning)
onx = to_onnx(tree, x.reshape((-1, 1)),
target_opset=15)
sess = InferenceSession(onx.SerializeToString())
ti = measure_time(
"sess.run(None, {'X': x})",
context={'numpy': numpy, "x": x.reshape((-1, 1)), "sess": sess},
div_by_number=True, repeat=repeat, number=number)
ti['name'] = 'ort'
ti['n_bins'] = n_bins
ti['shape'] = shape
obs.append(ti)
df = DataFrame(obs)
piv = pivot_table(data=df, index="shape", columns=["n_bins", "name"],
values=["average"])
print(piv)
0%| | 0/6 [00:00<?, ?it/s]
17%|#6 | 1/6 [00:09<00:48, 9.65s/it]
33%|###3 | 2/6 [00:19<00:38, 9.71s/it]
50%|##### | 3/6 [00:29<00:30, 10.03s/it]
67%|######6 | 4/6 [00:30<00:12, 6.16s/it]
83%|########3 | 5/6 [00:30<00:04, 4.14s/it]
100%|##########| 6/6 [00:34<00:00, 3.98s/it]
100%|##########| 6/6 [00:34<00:00, 5.71s/it]
average ...
n_bins 1 ... 100
name numpy ort sklearn ... numpy ort sklearn
shape ...
1 0.000041 0.000051 0.000226 ... 0.000042 0.000051 0.000228
10 0.000041 0.000051 0.000227 ... 0.000042 0.000052 0.000229
100 0.000042 0.000062 0.000229 ... 0.000049 0.000063 0.000241
1000 0.000056 0.000069 0.000268 ... 0.000115 0.000078 0.000354
10000 0.000169 0.000107 0.000495 ... 0.000760 0.000188 0.001274
100000 0.001396 0.000591 0.002951 ... 0.007279 0.001308 0.010420
[6 rows x 9 columns]
Plotting#
n_bins = list(sorted(set(df.n_bins)))
fig, ax = plt.subplots(1, len(n_bins), figsize=(14, 4))
for i, nb in enumerate(n_bins):
piv = pivot(data=df[df.n_bins == nb], index="shape",
columns="name", values="average")
piv.plot(title="Benchmark digitize / onnxruntime\nn_bins=%d" % nb,
logx=True, logy=True, ax=ax[i])
plt.show()
Total running time of the script: ( 0 minutes 43.459 seconds)