Note
Click here to download the full example code
Speed up scikit-learn inference with ONNX#
Is it possible to make scikit-learn faster with ONNX? That’s question this example tries to answer. The scenario is is the following:
a model is trained
it is converted into ONNX for inference
it selects a runtime to compute the prediction
The following runtime are tested:
python: python runtime for ONNX
onnxruntime1: onnxruntime
numpy: the ONNX graph is converted into numpy code
numba: the numpy code is accelerated with numba.
PCA#
Let’s look at a very simple model, a PCA.
import numpy
from pandas import DataFrame
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
from sklearn.decomposition import PCA
from pyquickhelper.pycode.profiling import profile
from mlprodict.sklapi import OnnxSpeedupTransformer
from cpyquickhelper.numbers.speed_measure import measure_time
from tqdm import tqdm
Data and models to test.
data, _ = make_regression(1000, n_features=20)
data = data.astype(numpy.float32)
models = [
('sklearn', PCA(n_components=10)),
('python', OnnxSpeedupTransformer(
PCA(n_components=10), runtime='python')),
('onnxruntime1', OnnxSpeedupTransformer(
PCA(n_components=10), runtime='onnxruntime1')),
('numpy', OnnxSpeedupTransformer(
PCA(n_components=10), runtime='numpy')),
('numba', OnnxSpeedupTransformer(
PCA(n_components=10), runtime='numba'))]
Training.
for name, model in tqdm(models):
model.fit(data)
0%| | 0/5 [00:00<?, ?it/s]
40%|#### | 2/5 [00:00<00:00, 11.53it/s]
80%|######## | 4/5 [00:01<00:00, 2.57it/s]
100%|##########| 5/5 [00:04<00:00, 1.33s/it]
100%|##########| 5/5 [00:04<00:00, 1.01it/s]
Profiling of runtime onnxruntime1.
def fct():
for i in range(1000):
models[2][1].transform(data)
res = profile(fct, pyinst_format="text")
print(res[1])
_ ._ __/__ _ _ _ _ _/_ Recorded: 03:25:57 AM Samples: 523
/_//_/// /_\ / //_// / //_'/ // Duration: 0.667 CPU time: 2.641
/ _/ v4.4.0
Program: somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_speedup_pca.py
0.666 profile ../pycode/profiling.py:455
`- 0.666 fct plot_speedup_pca.py:67
[28 frames hidden] plot_speedup_pca, sklearn, mlprodict,...
0.632 OnnxWholeSession.run mlprodict/onnxrt/ops_whole/session.py:97
Profiling of runtime numpy.
def fct():
for i in range(1000):
models[3][1].transform(data)
res = profile(fct, pyinst_format="text")
print(res[1])
_ ._ __/__ _ _ _ _ _/_ Recorded: 03:25:58 AM Samples: 284
/_//_/// /_\ / //_// / //_'/ // Duration: 0.304 CPU time: 0.303
/ _/ v4.4.0
Program: somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_speedup_pca.py
0.303 profile ../pycode/profiling.py:455
`- 0.303 fct plot_speedup_pca.py:79
[34 frames hidden] plot_speedup_pca, sklearn, mlprodict,...
0.269 numpy_mlprodict_ONNX_PCA <string>:11
The class OnnxSpeedupTransformer converts the PCA into ONNX and then converts it into a python code using numpy. The code is the following.
print(models[3][1].numpy_code_)
import numpy
import scipy.special as scipy_special
import scipy.spatial.distance as scipy_distance
from mlprodict.onnx_tools.exports.numpy_helper import (
argmax_use_numpy_select_last_index,
argmin_use_numpy_select_last_index,
array_feature_extrator,
make_slice)
def numpy_mlprodict_ONNX_PCA(X):
'''
Numpy function for ``mlprodict_ONNX_PCA``.
* producer: skl2onnx
* version: 0
* description:
'''
# initializers
list_value = [-0.5067367553710938, -0.32151809334754944, -0.05145944654941559, 0.07127761840820312, -0.04267493635416031, -0.11673732101917267, -0.1473727971315384, -0.15029238164424896, -0.23439958691596985, 0.39646437764167786, 0.30630427598953247, -0.37292757630348206, -0.07508348673582077, 0.004433620721101761, 0.04703060910105705, 0.29840517044067383, -0.06853567808866501, 0.24013546109199524, 0.4505208730697632, -0.015199273824691772, 0.11567263305187225, -0.11265850067138672, -0.3801497519016266, -0.13729508221149445, 0.08391162008047104, -0.03998395800590515, -0.3874768614768982, 0.12708556652069092, -0.07222757488489151, 0.10994700342416763, 0.23622679710388184, -0.20161578059196472, -0.17666909098625183, 0.3874513506889343, 0.1987515389919281, 0.17488011717796326, 0.21308909356594086, -0.14792722463607788, -0.07723761349916458, -0.3194519877433777, 0.005792118608951569, 0.18009474873542786, 0.3363724648952484, 0.25799739360809326, 0.27424877882003784, -0.29587453603744507, 0.1344870626926422, -0.14384956657886505, 0.4493676722049713, 0.2463940978050232, 0.03778448700904846, -0.33750906586647034, -0.2391706109046936, -0.03157924860715866, 0.0777701586484909, -0.19794175028800964, 0.05461816489696503, -0.18469876050949097, -0.11378421634435654, -0.013973366469144821, 0.12114843726158142, 0.21663418412208557, 0.12665724754333496, -0.19134721159934998, -0.2386147528886795, 0.14158907532691956, 0.1323249787092209, 0.005949962884187698, -0.21775154769420624, -0.1683511883020401, 0.20672805607318878, -0.10196325182914734, -0.01040369551628828, -0.23020119965076447, 0.08534082025289536, -0.0859760120511055, 0.058721136301755905, 0.23717492818832397, 0.19332104921340942, 0.1748892217874527, 0.14939863979816437, 0.3381364643573761, -0.3807629644870758, 0.010121817700564861, -0.13125498592853546, 0.15186849236488342, 0.01093701459467411, 0.037533052265644073, -0.06356837600469589, 0.29494503140449524, 0.12641650438308716, -0.01686842553317547, -0.030905520543456078, 0.22283193469047546, -0.16051693260669708, -0.10563787072896957, -0.24627335369586945, -0.3385445177555084, 0.23178917169570923,
0.2573137581348419, 0.45094603300094604, -0.06837690621614456, 0.13998538255691528, 0.2980887293815613, -0.5009583830833435, -0.1906174123287201, -0.039430104196071625, 0.20523692667484283, -0.1839393973350525, 0.3247809112071991, -0.26199373602867126, 0.011608600616455078, 0.006415803916752338, -0.06258974224328995, 0.20644383132457733, 0.05381537601351738, -0.20593087375164032, 0.44394606351852417, 0.21169179677963257, 0.09889845550060272, -0.18559519946575165, 0.26332205533981323, -0.22970151901245117, 0.6082763671875, 0.10286825150251389, 0.0329391285777092, 0.06118611618876457, 0.16409413516521454, -0.04447919875383377, -0.09132901579141617, -0.05354955792427063, 0.33986032009124756, -0.21200034022331238, -0.3175372779369354, -0.19614379107952118, 0.07239825278520584, 0.09320909529924393, -0.3494255840778351, 0.31601786613464355, 0.056582849472761154, 0.04646087810397148, 0.042027346789836884, 0.4445549547672272, 0.04736742004752159, -0.10475647449493408, 0.009311294183135033, -0.5570416450500488, -0.1053469181060791, 0.016088340431451797, -0.3296317458152771, -0.17308159172534943, 0.010242731310427189, -0.014094172976911068, 0.2028052657842636, -0.20289117097854614, 0.5946755409240723, -0.06317837536334991, -0.07546507567167282, 0.20626795291900635, 0.15703515708446503, 0.17143671214580536, 0.07143831998109818, -0.3368282616138458, 0.00934063270688057, 0.07573540508747101, -0.37361574172973633, -0.15489810705184937, -0.21196970343589783, 0.18515163660049438, -0.2139422446489334, 0.0381578654050827, -0.00867514032870531, -0.08442331105470657, 0.04178505390882492, 0.06234220042824745, 0.21655569970607758, -0.43873488903045654, -0.25793230533599854, -0.05557382106781006, -0.080104760825634, 0.3089466691017151, 0.01674206741154194, 0.21306872367858887, -0.09531918168067932, 0.5193166732788086, 0.29290080070495605, 0.045323487371206284, -0.2897208333015442, -0.2799742817878723, 0.3735027015209198, -0.1237722784280777, -0.4346633851528168, 0.0490194708108902, -0.03333911672234535, -0.29473116993904114, 0.07211415469646454, 0.29329872131347656, -0.23274967074394226, 0.18552133440971375, -0.059958960860967636]
B = numpy.array(list_value, dtype=numpy.float32).reshape((20, 10))
list_value = [-0.016928449273109436, 0.004371359944343567, -0.04217253997921944, -0.014449816197156906, -0.03853035345673561, 0.049470629543066025, -0.039256710559129715, 0.007685807067900896, 0.013661731965839863, -0.013782888650894165,
0.011968047358095646, 0.010710232891142368, 0.005895240232348442, 0.005286639556288719, -0.024296876043081284, 0.0047693196684122086, -0.007472604978829622, -0.0024257597979158163, -0.02468179538846016, -0.07006240636110306]
C = numpy.array(list_value, dtype=numpy.float32)
# nodes
D = X - C
variable = D @ B
return variable
Benchmark.
bench = []
for name, model in tqdm(models):
for size in (1, 10, 100, 1000, 10000, 100000, 200000):
data, _ = make_regression(size, n_features=20)
data = data.astype(numpy.float32)
# We run it a first time (numba compiles
# the function during the first execution).
model.transform(data)
res = measure_time(
lambda: model.transform(data), div_by_number=True,
context={'data': data, 'model': model})
res['name'] = name
res['size'] = size
bench.append(res)
df = DataFrame(bench)
piv = df.pivot("size", "name", "average")
piv
0%| | 0/5 [00:00<?, ?it/s]
20%|## | 1/5 [00:31<02:05, 31.49s/it]
40%|#### | 2/5 [00:56<01:23, 27.74s/it]
60%|###### | 3/5 [01:08<00:40, 20.31s/it]
80%|######## | 4/5 [01:31<00:21, 21.55s/it]
100%|##########| 5/5 [02:00<00:00, 24.28s/it]
100%|##########| 5/5 [02:00<00:00, 24.13s/it]
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_speedup_pca.py:114: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
piv = df.pivot("size", "name", "average")
Graph.
fig, ax = plt.subplots(1, 2, figsize=(10, 4))
piv.plot(title="Speedup PCA with ONNX (lower better)",
logx=True, logy=True, ax=ax[0])
piv2 = piv.copy()
for c in piv2.columns:
piv2[c] /= piv['sklearn']
print(piv2)
piv2.plot(title="baseline=scikit-learn (lower better)",
logx=True, logy=True, ax=ax[1])
plt.show()
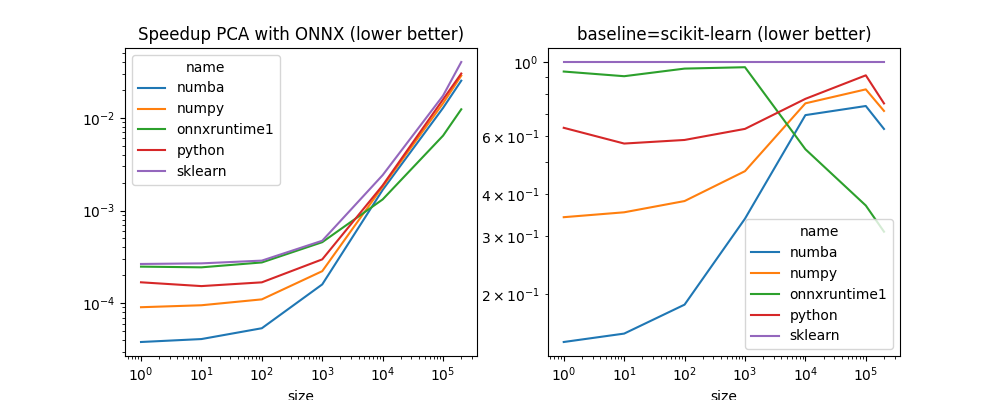
name numba numpy onnxruntime1 python sklearn
size
1 0.143822 0.341372 0.936087 0.633956 1.0
10 0.152444 0.353136 0.906268 0.568480 1.0
100 0.186291 0.381746 0.955312 0.582807 1.0
1000 0.337874 0.469534 0.964486 0.629264 1.0
10000 0.692215 0.751055 0.546553 0.774775 1.0
100000 0.737314 0.827304 0.370113 0.911817 1.0
200000 0.628970 0.712530 0.308767 0.750558 1.0
Total running time of the script: ( 2 minutes 9.585 seconds)