Note
Click here to download the full example code
Benchmark onnxruntime API: eager mode#
epkg:pytorch or tensorflow usually work faster if the deep learning model is entirely run outside python. The python code is only used to build the model but is then used to call the execution of the whole. In that configuration, there is no way to look into intermediate results.
It does not make it easy to debug or investigate what is going on. What the user writes is not what is executed. Eager mode is an expression which defines a situation where the code which defines the model is the same as the used to execute the model. Everything happens in python. It is slower but the gap is small if the model manipulate big matrices.
It is possible to do the same with onnxruntime. This example compares the performance of a couple of scenarios. This work is close to what is done in example Benchmark onnxruntime API: run or run_with_ort_values. The example compares the performance of a couple of methods for CPU and GPU.
The scenario#
We would like to compare two codes. The first one executes 2 additions in a single onnx graph. The second one executes 10 additions, each of them calling onnxruntime for a single addition.
import time
import numpy
from numpy.testing import assert_allclose
import pandas
import matplotlib.pyplot as plt
from tqdm import tqdm
from onnx import TensorProto
from onnx.numpy_helper import from_array
from onnx.helper import (
make_model, make_node, make_opsetid,
make_graph, make_tensor_value_info)
from onnxruntime import (
get_all_providers, InferenceSession, __version__ as ort_version,
RunOptions)
from onnxruntime.capi._pybind_state import ( # pylint: disable=E0611
OrtDevice as C_OrtDevice,
OrtMemType, OrtValue as C_OrtValue,
SessionIOBinding as C_SessionIOBinding)
try:
from onnxruntime.capi._pybind_state import OrtValueVector
except ImportError:
# You need onnxruntime>=1.14
OrtValueVector = None
from mlprodict.testing.experimental_c_impl.experimental_c import code_optimisation
Available optimisation on this machine.
print(code_optimisation())
repeat = 250
number = 250
AVX-omp=8
A single addition of a matrix of two dimension.
CST = numpy.array(list(range(100))).reshape(1, -1).astype(numpy.float32)
X = make_tensor_value_info('X', TensorProto.FLOAT, [None, CST.shape[1]])
Z = make_tensor_value_info('Z', TensorProto.FLOAT, [None, CST.shape[1]])
graph = make_graph([make_node("Add", ['X', 'Y'], ['Z'])],
'', [X], [Z], [from_array(CST, name='Y')])
onnx_add = make_model(graph, opset_imports=[make_opsetid('', 17)])
sess_add = InferenceSession(onnx_add.SerializeToString(),
providers=["CPUExecutionProvider"])
Two additions of the same matrix.
graph = make_graph([make_node("Add", ['X', 'Y'], ['T']),
make_node("Add", ['T', 'Y'], ['Z'])],
'', [X], [Z], [from_array(CST, 'Y')])
onnx_add2 = make_model(graph, opset_imports=[make_opsetid('', 17)])
sess_add2 = InferenceSession(onnx_add2.SerializeToString(),
providers=["CPUExecutionProvider"])
Let’s consider GPU as well.
has_cuda = "CUDAExecutionProvider" in get_all_providers()
if has_cuda:
sess_add_gpu = InferenceSession(onnx_add.SerializeToString(),
providers=["CUDAExecutionProvider"])
sess_add2_gpu = InferenceSession(onnx_add2.SerializeToString(),
providers=["CUDAExecutionProvider"])
else:
print("No GPU or one GPU was detected.")
sess_add_gpu = None
sess_add2_gpu = None
somewhere/workspace/onnxcustom/onnxcustom_UT_39_std/_venv/lib/python3.9/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py:54: UserWarning: Specified provider 'CUDAExecutionProvider' is not in available provider names.Available providers: 'CPUExecutionProvider'
warnings.warn(
The functions to test#
numpy: numpy
ort: onnxruntime + numpy array as input
ort-ov: onnxruntime + C_OrtValue as input
def f_numpy(X):
"numpy"
T = X + CST
Z = T + CST
return Z
def f_ort_eager(X):
"ort-eager"
T = sess_add._sess.run(['Z'], {'X': X}, None)[0]
Z = sess_add._sess.run(['Z'], {'X': T}, None)[0]
return Z
def f_ort(X):
"ort"
Z = sess_add2._sess.run(['Z'], {'X': X}, None)[0]
return Z
def f_ort_ov_eager(X):
"ort-ov-eager"
T = sess_add._sess.run_with_ort_values({'X': X}, ['Z'], None)[0]
Z = sess_add._sess.run_with_ort_values({'X': T}, ['Z'], None)[0]
return Z
def f_ort_ov(X):
"ort-ov"
Z = sess_add2._sess.run_with_ort_values({'X': X}, ['Z'], None)[0]
return Z
cpu_device = C_OrtDevice(C_OrtDevice.cpu(), OrtMemType.DEFAULT, 0)
def f_ort_ov_bind_eager(X):
"ort-ov-bind-eager"
bind = C_SessionIOBinding(sess_add._sess)
bind.bind_ortvalue_input("X", X)
bind.bind_output("Z", cpu_device)
sess_add._sess.run_with_iobinding(bind, None)
T = bind.get_outputs()[0]
bind.bind_ortvalue_input("X", T)
sess_add._sess.run_with_iobinding(bind, None)
return bind.get_outputs()[0]
def f_ort_ov_bind(X):
"ort-ov-bind"
bind = C_SessionIOBinding(sess_add2._sess)
bind.bind_ortvalue_input("X", X)
bind.bind_output("Z", cpu_device)
sess_add2._sess.run_with_iobinding(bind, None)
return bind.get_outputs()[0]
onnxruntime >= 1.14 introduces a vector of OrtValues to bypass the building of a dictionary.
if (OrtValueVector is not None and
hasattr(sess_add._sess, "run_with_ortvaluevector")):
run_options = RunOptions()
devices = [C_OrtDevice(C_OrtDevice.cpu(), OrtMemType.DEFAULT, 0)]
def f_ort_vect_ov_eager(X):
"ort-vect-ov-eager"
vect_in = OrtValueVector()
vect_in.push_back(X)
vect_out = OrtValueVector()
temp_vect_out = OrtValueVector()
sess_add._sess.run_with_ortvaluevector(
run_options, ["X"], vect_in, ["Z"], temp_vect_out, devices)
assert len(temp_vect_out) == 1
sess_add._sess.run_with_ortvaluevector(
run_options, ["X"], temp_vect_out, ["Z"], vect_out, devices)
assert len(vect_out) == 1
return vect_out[0]
def f_ort_vect_ov(X):
"ort-vect-ov"
vect_in = OrtValueVector()
vect_in.push_back(X)
vect_out = OrtValueVector()
sess_add2._sess.run_with_ortvaluevector(
run_options, ["X"], vect_in, ["Z"], vect_out, devices)
assert len(vect_out) == 1
return vect_out[0]
else:
f_ort_vect_ov_eager = None
f_ort_vect_ov = None
If GPU is available.
if sess_add_gpu is not None:
def f_ort_ov_eager_gpu(X):
"ort-ov-eager-gpu"
T = sess_add_gpu._sess.run_with_ort_values({'X': X}, ['Z'], None)[0]
Z = sess_add_gpu._sess.run_with_ort_values({'X': T}, ['Z'], None)[0]
return Z
def f_ort_ov_gpu(X):
"ort-ov-gpu"
Z = sess_add2_gpu._sess.run_with_ort_values({'X': X}, ['Z'], None)[0]
return Z
gpu_device = C_OrtDevice(C_OrtDevice.cuda(), OrtMemType.DEFAULT, 0)
def f_ort_ov_bind_eager_gpu(X):
"ort-ov-bind-eager-gpu"
bind = C_SessionIOBinding(sess_add_gpu._sess)
bind.bind_ortvalue_input("X", X)
bind.bind_output("Z", gpu_device)
sess_add_gpu._sess.run_with_iobinding(bind, None)
T = bind.get_outputs()[0]
bind.bind_ortvalue_input("X", T)
sess_add_gpu._sess.run_with_iobinding(bind, None)
return bind.get_outputs()[0]
def f_ort_ov_bind_gpu(X):
"ort-ov-bind-gpu"
bind = C_SessionIOBinding(sess_add2_gpu._sess)
bind.bind_ortvalue_input("X", X)
bind.bind_output("Z", gpu_device)
sess_add2_gpu._sess.run_with_iobinding(bind, None)
return bind.get_outputs()[0]
if OrtValueVector is not None:
run_options = RunOptions()
devices = [C_OrtDevice(C_OrtDevice.cuda(), OrtMemType.DEFAULT, 0)]
def f_ort_vect_ov_eager_gpu(X):
"ort-vect-ov-eager-gpu"
vect_in = OrtValueVector()
vect_in.push_back(X)
vect_out = OrtValueVector()
temp_vect_out = OrtValueVector()
sess_add_gpu._sess.run_with_ortvaluevector(
run_options, ["X"], vect_in, ["Z"], temp_vect_out, devices)
sess_add_gpu._sess.run_with_ortvaluevector(
run_options, ["X"], temp_vect_out, ["Z"], vect_out, devices)
assert len(vect_out) == 1
return vect_out[0]
def f_ort_vect_ov_gpu(X):
"ort-vect-ov-gpu"
vect_in = OrtValueVector()
vect_in.push_back(X)
vect_out = OrtValueVector()
# crashes on the next line
sess_add2_gpu._sess.run_with_ortvaluevector(
run_options, ["X"], vect_in, ["Z"], vect_out, devices)
assert len(vect_out) == 1
return vect_out[0]
else:
f_ort_vect_ov_eager_gpu = None
f_ort_vect_ov_gpu = None
else:
f_ort_ov_eager_gpu = None
f_ort_ov_gpu = None
f_ort_vect_ov_eager_gpu = None
f_ort_vect_ov_gpu = None
f_ort_ov_bind_eager_gpu = None
f_ort_ov_bind_gpu = None
Let’s now check all these functions produces the same results.
X = numpy.random.rand(10, CST.shape[1]).astype(CST.dtype)
device = C_OrtDevice(C_OrtDevice.cpu(), OrtMemType.DEFAULT, 0)
Xov = C_OrtValue.ortvalue_from_numpy(X, device)
Ys = [
(f_numpy, X),
(f_ort_eager, X),
(f_ort, X),
(f_ort_ov_eager, Xov),
(f_ort_ov, Xov),
(f_ort_ov_bind_eager, Xov),
(f_ort_ov_bind, Xov),
]
if OrtValueVector is not None:
Ys.extend([
(f_ort_vect_ov_eager, Xov),
(f_ort_vect_ov, Xov),
])
if sess_add_gpu is not None:
device_gpu = C_OrtDevice(C_OrtDevice.cuda(), OrtMemType.DEFAULT, 0)
try:
Xov_gpu = C_OrtValue.ortvalue_from_numpy(X, device_gpu)
Ys.extend([
(f_ort_ov_eager_gpu, Xov_gpu),
(f_ort_ov_gpu, Xov_gpu),
(f_ort_ov_bind_eager_gpu, Xov_gpu),
(f_ort_ov_bind_gpu, Xov_gpu),
])
if OrtValueVector is not None:
Ys.extend([
(f_ort_vect_ov_gpu, Xov_gpu),
(f_ort_vect_ov_eager_gpu, Xov_gpu),
])
except RuntimeError:
# cuda is not available
sess_add_gpu = None
sess_add2_gpu = None
f_ort_ov_eager_gpu = None
f_ort_ov_gpu = None
f_ort_ov_bind_eager_gpu = None
f_ort_ov_bind_gpu = None
f_ort_vect_ov_eager_gpu = None
f_ort_vect_ov_gpu = None
results = []
for fct, x in Ys:
if fct is None:
continue
print(
f"check function {fct.__name__!r} and input type {x.__class__.__name__!r}")
results.append(fct(x))
for i in range(1, len(results)):
try:
assert_allclose(results[0], results[i])
except TypeError:
# OrtValue
assert_allclose(results[0], results[i].numpy())
check function 'f_numpy' and input type 'ndarray'
check function 'f_ort_eager' and input type 'ndarray'
check function 'f_ort' and input type 'ndarray'
check function 'f_ort_ov_eager' and input type 'OrtValue'
check function 'f_ort_ov' and input type 'OrtValue'
check function 'f_ort_ov_bind_eager' and input type 'OrtValue'
check function 'f_ort_ov_bind' and input type 'OrtValue'
check function 'f_ort_vect_ov_eager' and input type 'OrtValue'
check function 'f_ort_vect_ov' and input type 'OrtValue'
All outputs are the same.
Benchmark the functions#
def benchmark(repeat=500000):
fcts = [
f_numpy, f_ort_eager, f_ort, f_ort_ov_eager, f_ort_ov,
f_ort_vect_ov_eager, f_ort_vect_ov,
f_ort_ov_bind_eager, f_ort_ov_bind,
f_ort_ov_eager_gpu, f_ort_ov_gpu,
f_ort_vect_ov_eager_gpu, f_ort_vect_ov_gpu,
f_ort_ov_bind_eager_gpu, f_ort_ov_bind_gpu,
]
data = []
for N in tqdm([1, 2, 5, 10, 20, 50, 100, 200, 500,
1000, 2000, 5000, 10000, 20000]):
X = numpy.random.rand(N, CST.shape[1]).astype(CST.dtype)
device = C_OrtDevice(C_OrtDevice.cpu(), OrtMemType.DEFAULT, 0)
Xov = C_OrtValue.ortvalue_from_numpy(X, device)
if f_ort_ov_gpu is not None:
device_gpu = C_OrtDevice(C_OrtDevice.cuda(), OrtMemType.DEFAULT, 0)
Xov_gpu = C_OrtValue.ortvalue_from_numpy(X, device_gpu)
r = min(500, int(repeat / N))
for f in fcts:
if f is None:
continue
obs = {'name': f.__doc__, "N": N}
if "-gpu" in f.__doc__:
begin = time.perf_counter()
for r in range(r):
_ = f(Xov_gpu)
end = time.perf_counter() - begin
elif "-ov" in f.__doc__:
begin = time.perf_counter()
for r in range(r):
_ = f(Xov)
end = time.perf_counter() - begin
else:
begin = time.perf_counter()
for r in range(r):
_ = f(X)
end = time.perf_counter() - begin
obs['time'] = end / r
data.append(obs)
return pandas.DataFrame(data)
df = benchmark()
df.to_csv("plot_benchmark_eager_mode.csv", index=False)
df
0%| | 0/14 [00:00<?, ?it/s]
7%|7 | 1/14 [00:00<00:03, 4.11it/s]
14%|#4 | 2/14 [00:00<00:03, 4.00it/s]
21%|##1 | 3/14 [00:00<00:02, 3.91it/s]
29%|##8 | 4/14 [00:01<00:02, 3.84it/s]
36%|###5 | 5/14 [00:01<00:02, 3.73it/s]
43%|####2 | 6/14 [00:01<00:02, 3.53it/s]
50%|##### | 7/14 [00:01<00:02, 3.21it/s]
57%|#####7 | 8/14 [00:02<00:02, 2.72it/s]
64%|######4 | 9/14 [00:03<00:02, 1.77it/s]
71%|#######1 | 10/14 [00:04<00:03, 1.20it/s]
79%|#######8 | 11/14 [00:06<00:02, 1.06it/s]
86%|########5 | 12/14 [00:07<00:02, 1.09s/it]
93%|#########2| 13/14 [00:08<00:01, 1.17s/it]
100%|##########| 14/14 [00:10<00:00, 1.21s/it]
100%|##########| 14/14 [00:10<00:00, 1.37it/s]
Graphs#
def make_graph(df):
def subgraph(row, cols):
if "numpy" not in cols:
cols.append("numpy")
piv = piv_all[cols].copy()
piv.plot(ax=ax[row, 0],
title="Time execution(s)" if row == 0 else "",
logy=True, logx=True)
piv2 = piv / piv.index.values.reshape((-1, 1))
piv2.plot(ax=ax[row, 1],
title="Time(s) per execution / N" if row == 0 else "",
logx=True)
piv3 = piv / piv["numpy"].values.reshape((-1, 1))
piv3.plot(ax=ax[row, 2],
title="Ratio against numpy" if row == 0 else "",
logy=True, logx=True)
for j in range(0, 3):
ax[row, j].legend(fontsize="x-small")
fig, ax = plt.subplots(5, 3, figsize=(15, 9))
fig.suptitle("Time execution Eager Add + Add - lower is better")
piv_all = df.pivot(index="N", columns="name", values="time")
# no gpu, no vect, no bind
subgraph(0, [c for c in piv_all.columns
if "-gpu" not in c and "-vect" not in c and "-bind" not in c])
# no gpu, ov, no bind
subgraph(1, [c for c in piv_all.columns
if "-gpu" not in c and "-ov" in c and "-bind" not in c])
# no gpu, vect or bind
subgraph(2, [c for c in piv_all.columns
if "-gpu" not in c and ("-bind" in c or '-vect' in c)])
# gpu, no bind
cols = [c for c in piv_all.columns
if "-gpu" in c and "-ov" in c and "-bind" not in c]
subgraph(3, cols)
# gpu, vect or bind
cols = [c for c in piv_all.columns
if "-gpu" in c and ("-bind" in c or '-vect' in c)]
subgraph(4, cols)
fig.savefig("eager_mode_cpu.png" if len(cols) == 0
else "eager_mode_gpu.png", dpi=250)
return fig, ax
fig, ax = make_graph(df)
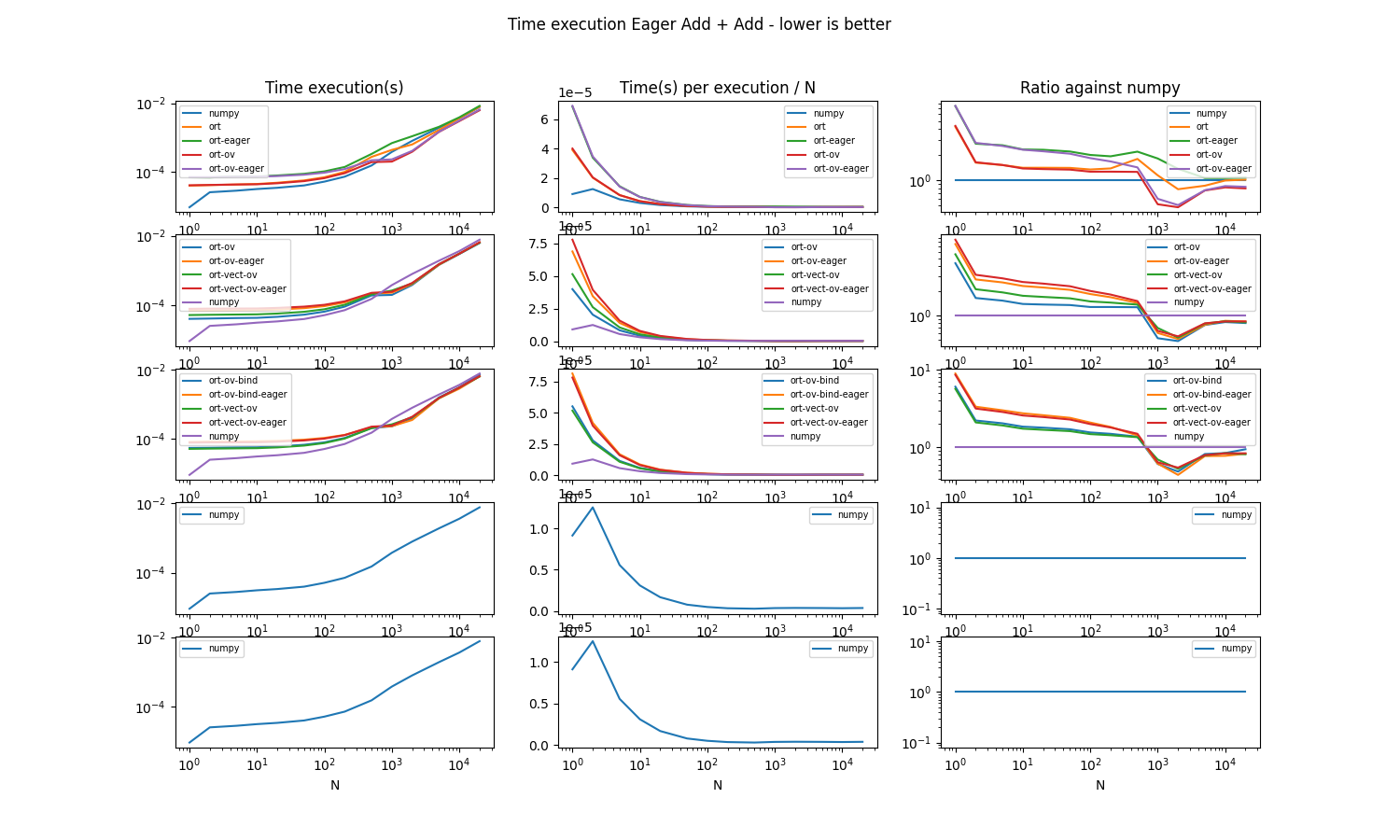
Conclusion#
The eager mode is slower than numpy for small arrays then is faster. This is probably due to pybind11 binding when numpy is using the direct python API. This could be improved by using cython. Eager mode must use OrtValue. It is faster and it reduces the differences between using two additions in a single graph or two graphs of a single addition on CPU. On GPU, it is still faster but eager mode is slighly slower with method run_with_ortvaluevector or run_with_iobinding. Both methods show similar performances.
However, method run_with_ort_values is not recommended because the output device cannot be specified. Therefore, onnxruntime requests the output on CPU. On eager mode, this output is used again an input for the second call to run_with_ort_values and the data needs to be copied from CPU to GPU.
if sess_add_gpu is None:
print("With GPU")
df = pandas.read_csv("data/plot_benchmark_eager_mode.csv")
_, ax = make_graph(df)
else:
ax = None
ax
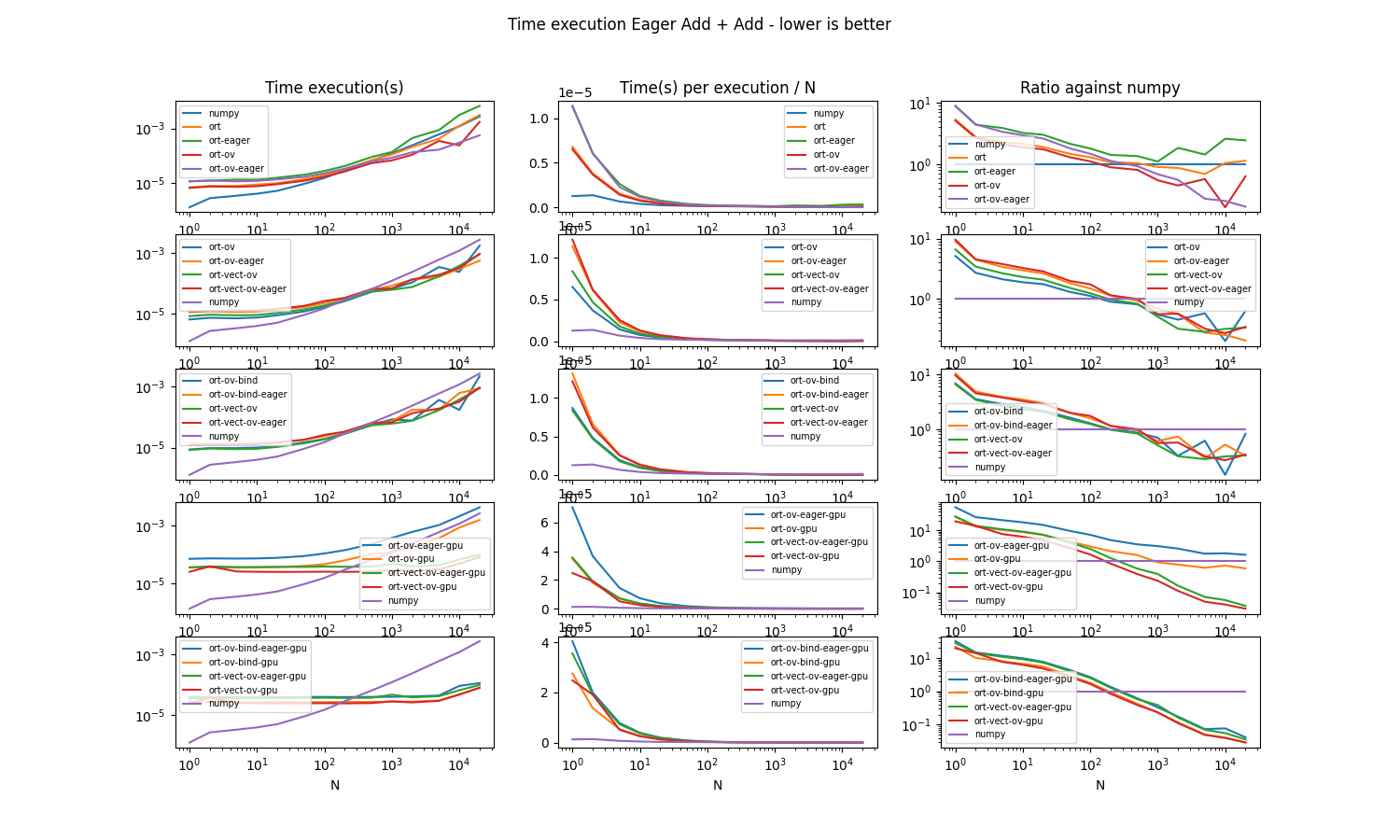
With GPU
array([[<AxesSubplot: title={'center': 'Time execution(s)'}, xlabel='N'>,
<AxesSubplot: title={'center': 'Time(s) per execution / N'}, xlabel='N'>,
<AxesSubplot: title={'center': 'Ratio against numpy'}, xlabel='N'>],
[<AxesSubplot: xlabel='N'>, <AxesSubplot: xlabel='N'>,
<AxesSubplot: xlabel='N'>],
[<AxesSubplot: xlabel='N'>, <AxesSubplot: xlabel='N'>,
<AxesSubplot: xlabel='N'>],
[<AxesSubplot: xlabel='N'>, <AxesSubplot: xlabel='N'>,
<AxesSubplot: xlabel='N'>],
[<AxesSubplot: xlabel='N'>, <AxesSubplot: xlabel='N'>,
<AxesSubplot: xlabel='N'>]], dtype=object)
Results obtained with the following version.
print(f"onnxruntime.__version__ = {ort_version!r}")
# plt.show()
onnxruntime.__version__ = '1.14.92+cpu'
Total running time of the script: ( 0 minutes 45.887 seconds)