Note
Click here to download the full example code
Benchmark and profile of operator Slice#
This short code compares the execution of the operator Slice between numpy and onnxruntime for three configurations.
A simple example#
import json
import numpy
from numpy.testing import assert_almost_equal
import pandas
from pandas import DataFrame
import matplotlib.pyplot as plt
from onnxruntime import InferenceSession, get_device, SessionOptions
from onnxruntime.capi._pybind_state import ( # pylint: disable=E0611
OrtValue as C_OrtValue)
from skl2onnx.common.data_types import FloatTensorType
from skl2onnx.algebra.onnx_ops import OnnxSlice, OnnxAdd, OnnxMul
from cpyquickhelper.numbers import measure_time
from tqdm import tqdm
from mlprodict.testing.experimental_c_impl.experimental_c import (
code_optimisation)
from mlprodict.onnxrt.ops_whole.session import OnnxWholeSession
from onnxcustom.utils.onnxruntime_helper import get_ort_device
print([code_optimisation(), get_device()])
['AVX-omp=8', 'CPU']
The functions to compare.
def build_ort_op(op_version=14, save=None, **kwargs): # opset=13, 14, ...
slices = kwargs['slices']
slice1, slice2 = slices
slice1 = slice(0, None) if slice1 is None else slice(*slice1)
slice2 = slice(0, None) if slice2 is None else slice(*slice2)
axes = []
starts = []
ends = []
for i in [0, 1]:
if slices[i] is None:
continue
axes.append(i)
starts.append(slices[i][0])
ends.append(slices[i][1])
starts = numpy.array(starts, dtype=numpy.int64)
ends = numpy.array(ends, dtype=numpy.int64)
axes = numpy.array(axes, dtype=numpy.int64)
node1 = OnnxSlice('X', starts, ends, axes, op_version=op_version)
node2 = OnnxAdd(node1, numpy.array([1], dtype=numpy.float32),
op_version=op_version)
node3 = OnnxSlice(node2, starts, ends, axes,
op_version=op_version)
node4 = OnnxMul(node3, numpy.array([2], dtype=numpy.float32),
op_version=op_version, output_names=['Y'])
onx = node4.to_onnx(inputs=[('X', FloatTensorType([None, None]))],
target_opset=op_version)
sess = InferenceSession(onx.SerializeToString(),
providers=["CPUExecutionProvider"])
if save is not None:
with open(save, "wb") as f:
f.write(onx.SerializeToString())
def npy_fct(x):
return ((x[slice1, slice2] + 1)[slice1, slice2] * 2).copy()
rnd = numpy.random.randn(10, 10).astype(numpy.float32)
expected = npy_fct(rnd)
got = sess.run(None, {'X': rnd})[0]
try:
assert_almost_equal(expected, got)
except AssertionError as e:
raise AssertionError(
"kwargs=%r slice1=%r slice2=%r shapes=%r ? %r "
"(x[slice1, slice2].shape)=%r" % (
kwargs, slice1, slice2, expected.shape,
got.shape, rnd[slice1, slice2].shape)) from e
if get_device().upper() == 'GPU':
sessg = InferenceSession(onx.SerializeToString(),
providers=["CUDAExecutionProvider"])
io_binding = sessg.io_binding()._iobinding
device = get_ort_device('cuda:0')
def run_gpu(x):
io_binding.bind_input(
'X', device, numpy.float32, x.shape(), x.data_ptr())
io_binding.bind_output('Y', device)
return sessg._sess.run_with_iobinding(io_binding, None)
return onx, lambda x: sess.run(None, {'X': x}), npy_fct, run_gpu
else:
return onx, lambda x: sess.run(None, {'X': x}), npy_fct, None
The benchmark.
def loop_fct(fct, xs):
for x in xs:
fct(x)
def benchmark_op(repeat=10, number=10, name="Slice", shape_slice_fct=None,
save=None, opset=14, repeat_profile=1500, verbose=1):
if verbose:
print("[benchmark_op] start repeat=%d number=%d repeat_profile=%d"
" opset=%d." % (repeat, number, repeat_profile, opset))
res = []
for dim in tqdm([8, 16, 32, 64, 100, 128, 200,
256, 400, 512, 600, 784, 800,
1000, 1024, 1200]):
shape, slices = shape_slice_fct(dim)
onx, ort_fct, npy_fct, ort_fct_gpu = build_ort_op(
save=save, op_version=opset, slices=slices)
n_arrays = 20
if dim >= 512:
n_arrays = 10
xs = [numpy.random.rand(*shape).astype(numpy.float32)
for _ in range(n_arrays)]
info = dict(shape=shape)
ctx = dict(xs=xs, loop_fct=loop_fct)
# numpy
ctx['fct'] = npy_fct
obs = measure_time(
lambda: loop_fct(npy_fct, xs),
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'numpy'
obs['shape'] = ",".join(map(str, shape))
obs['slices'] = str(slices)
obs.update(info)
res.append(obs)
# onnxruntime
ctx['fct'] = ort_fct
obs = measure_time(
lambda: loop_fct(ort_fct, xs),
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'ort'
obs['shape'] = ",".join(map(str, shape))
obs['slices'] = str(slices)
obs.update(info)
res.append(obs)
if ort_fct_gpu is not None:
# onnxruntime
dev = get_ort_device('cuda:0')
ctx['xs'] = [
C_OrtValue.ortvalue_from_numpy(x, dev)
for x in xs]
ctx['fct'] = ort_fct_gpu
obs = measure_time(
lambda: loop_fct(ort_fct_gpu, ctx['xs']),
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'ort_gpu'
obs['shape'] = ",".join(map(str, shape))
obs['slices'] = str(slices)
obs.update(info)
res.append(obs)
# profiling CPU
if verbose:
print("[benchmark_op] done.")
print("[benchmark_op] profile CPU.")
so = SessionOptions()
so.enable_profiling = True
sess = InferenceSession(onx.SerializeToString(), so,
providers=["CPUExecutionProvider"])
for i in range(0, repeat_profile):
sess.run(None, {'X': xs[-1]}, )
prof = sess.end_profiling()
with open(prof, "r") as f:
js = json.load(f)
dfprof = DataFrame(OnnxWholeSession.process_profiling(js))
dfprof['shape'] = ",".join(map(str, shape))
dfprof['slices'] = str(slices)
if verbose:
print("[benchmark_op] done.")
# profiling CPU
if ort_fct_gpu is not None:
if verbose:
print("[benchmark_op] profile GPU.")
so = SessionOptions()
so.enable_profiling = True
sess = InferenceSession(onx.SerializeToString(), so,
providers=["CUDAExecutionProvider"])
io_binding = sess.io_binding()._iobinding
device = get_ort_device('cpu')
for i in range(0, repeat_profile):
x = ctx['xs'][-1]
io_binding.bind_input(
'X', device, numpy.float32, x.shape(), x.data_ptr())
io_binding.bind_output('Y', device)
sess._sess.run_with_iobinding(io_binding, None)
prof = sess.end_profiling()
with open(prof, "r") as f:
js = json.load(f)
dfprofgpu = DataFrame(OnnxWholeSession.process_profiling(js))
dfprofgpu['shape'] = ",".join(map(str, shape))
dfprofgpu['slices'] = str(slices)
if verbose:
print("[benchmark_op] profile done.")
else:
dfprofgpu = None
# Dataframes
shape_name = str(shape).replace(str(dim), "N")
df = pandas.DataFrame(res)
piv = df.pivot('shape', 'fct', 'average')
rs = piv.copy()
for c in ['numpy', 'ort', 'ort_gpu']:
if c in rs.columns:
rs[f"numpy/{c}"] = rs['numpy'] / rs[c]
rs = rs[[c for c in rs.columns if "/numpy" not in c]].copy()
# Graphs.
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
piv.plot(logx=True, logy=True, ax=ax[0],
title=f"{name} benchmark\n{shape_name!r} lower better")
ax[0].legend(prop={"size": 9})
rs.plot(logx=True, logy=True, ax=ax[1],
title=f"{name} Speedup, baseline=numpy\n{shape_name!r} higher better")
ax[1].plot([min(rs.index), max(rs.index)], [0.5, 0.5], 'g--')
ax[1].plot([min(rs.index), max(rs.index)], [2., 2.], 'g--')
ax[1].legend(prop={"size": 9})
return dfprof, dfprofgpu, df, rs, ax
The results.
nth = int(code_optimisation().split('=')[1])
cols_profile = ["shape", "slices", "args_op_name", 'args_provider']
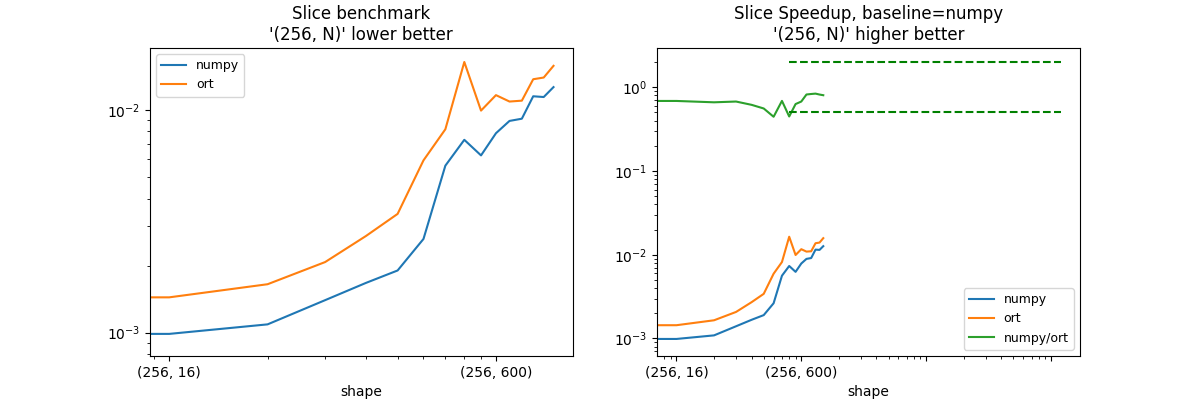
shape = (100, N) - slice = [1:-1], :#
dfs = []
dfprof, dfprofgpu, df, piv, ax = benchmark_op(
shape_slice_fct=lambda dim: ((256, dim), ((1, -1), None)),
save="bslice.onnx", number=nth * 4, repeat=8, repeat_profile=100 * nth)
dfs.append(df)
piv2 = df.pivot("fct", "shape", "average")
print("slices = [1:-1], :")
print(piv.to_markdown())
print(dfprof.drop(['pid', 'tid', 'ts'], axis=1).groupby(
cols_profile).sum().to_markdown())
if dfprofgpu is not None:
print(dfprofgpu.drop(['pid', 'tid'], axis=1).groupby(
cols_profile).sum().to_markdown())
[benchmark_op] start repeat=8 number=32 repeat_profile=800 opset=14.
0%| | 0/16 [00:00<?, ?it/s]
6%|6 | 1/16 [00:00<00:09, 1.64it/s]
12%|#2 | 2/16 [00:01<00:08, 1.58it/s]
19%|#8 | 3/16 [00:01<00:08, 1.48it/s]
25%|##5 | 4/16 [00:02<00:09, 1.29it/s]
31%|###1 | 5/16 [00:04<00:10, 1.10it/s]
38%|###7 | 6/16 [00:05<00:10, 1.08s/it]
44%|####3 | 7/16 [00:07<00:13, 1.46s/it]
50%|##### | 8/16 [00:11<00:17, 2.14s/it]
56%|#####6 | 9/16 [00:17<00:23, 3.39s/it]
62%|######2 | 10/16 [00:21<00:21, 3.65s/it]
69%|######8 | 11/16 [00:26<00:20, 4.08s/it]
75%|#######5 | 12/16 [00:31<00:17, 4.41s/it]
81%|########1 | 13/16 [00:37<00:13, 4.65s/it]
88%|########7 | 14/16 [00:43<00:10, 5.23s/it]
94%|#########3| 15/16 [00:50<00:05, 5.64s/it]
100%|##########| 16/16 [00:57<00:00, 6.16s/it]
100%|##########| 16/16 [00:57<00:00, 3.60s/it]
[benchmark_op] done.
[benchmark_op] profile CPU.
[benchmark_op] done.
slices = [1:-1], :
| shape | numpy | ort | numpy/ort |
|:------------|------------:|-----------:|------------:|
| (256, 8) | 0.000908095 | 0.00138613 | 0.655131 |
| (256, 16) | 0.000987474 | 0.00144066 | 0.685431 |
| (256, 32) | 0.0010896 | 0.00164982 | 0.660438 |
| (256, 64) | 0.00139936 | 0.00207445 | 0.674568 |
| (256, 100) | 0.00167248 | 0.00271555 | 0.615891 |
| (256, 128) | 0.00190174 | 0.0034128 | 0.557239 |
| (256, 200) | 0.00263419 | 0.00593416 | 0.443904 |
| (256, 256) | 0.0056182 | 0.00818404 | 0.686482 |
| (256, 400) | 0.00733815 | 0.0164008 | 0.447428 |
| (256, 512) | 0.0062465 | 0.00992516 | 0.62936 |
| (256, 600) | 0.00785661 | 0.0116455 | 0.674648 |
| (256, 784) | 0.00892036 | 0.0108995 | 0.818417 |
| (256, 800) | 0.00912778 | 0.0109985 | 0.829913 |
| (256, 1000) | 0.0115086 | 0.0137245 | 0.838542 |
| (256, 1024) | 0.0114202 | 0.0139681 | 0.817587 |
| (256, 1200) | 0.0126533 | 0.0157651 | 0.802612 |
| | dur |
|:-----------------------------------------------------------------|-------:|
| ('256,1200', '((1, -1), None)', 'Add', 'CPUExecutionProvider') | 174743 |
| ('256,1200', '((1, -1), None)', 'Mul', 'CPUExecutionProvider') | 158162 |
| ('256,1200', '((1, -1), None)', 'Slice', 'CPUExecutionProvider') | 712055 |
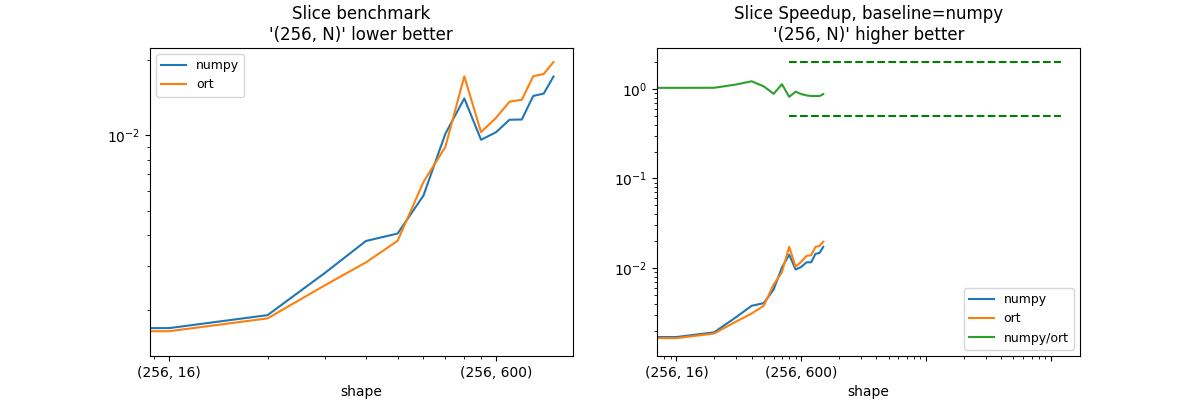
shape = (100, N) - slice = :, [1:-1]#
dfs = []
dfprof, dfprofgpu, df, piv, ax = benchmark_op(
shape_slice_fct=lambda dim: ((256, dim), (None, (1, -1))),
save="bslice.onnx", number=nth * 4, repeat=8, repeat_profile=100 * nth)
dfs.append(df)
piv2 = df.pivot("fct", "shape", "average")
print("slices = :, [1:-1]")
print(piv.to_markdown())
print(dfprof.drop(['pid', 'tid', 'ts'], axis=1).groupby(
cols_profile).sum().to_markdown())
if dfprofgpu is not None:
print(dfprofgpu.drop(['pid', 'tid'], axis=1).groupby(
cols_profile).sum().to_markdown())
[benchmark_op] start repeat=8 number=32 repeat_profile=800 opset=14.
0%| | 0/16 [00:00<?, ?it/s]
6%|6 | 1/16 [00:00<00:12, 1.23it/s]
12%|#2 | 2/16 [00:01<00:11, 1.17it/s]
19%|#8 | 3/16 [00:02<00:11, 1.09it/s]
25%|##5 | 4/16 [00:04<00:13, 1.11s/it]
31%|###1 | 5/16 [00:05<00:14, 1.36s/it]
38%|###7 | 6/16 [00:07<00:15, 1.59s/it]
44%|####3 | 7/16 [00:11<00:19, 2.11s/it]
50%|##### | 8/16 [00:16<00:24, 3.02s/it]
56%|#####6 | 9/16 [00:24<00:32, 4.60s/it]
62%|######2 | 10/16 [00:29<00:28, 4.78s/it]
69%|######8 | 11/16 [00:35<00:25, 5.07s/it]
75%|#######5 | 12/16 [00:41<00:22, 5.51s/it]
81%|########1 | 13/16 [00:48<00:17, 5.84s/it]
88%|########7 | 14/16 [00:56<00:13, 6.55s/it]
94%|#########3| 15/16 [01:04<00:07, 7.09s/it]
100%|##########| 16/16 [01:14<00:00, 7.83s/it]
100%|##########| 16/16 [01:14<00:00, 4.64s/it]
[benchmark_op] done.
[benchmark_op] profile CPU.
[benchmark_op] done.
slices = :, [1:-1]
| shape | numpy | ort | numpy/ort |
|:------------|-----------:|-----------:|------------:|
| (256, 8) | 0.0014885 | 0.00158511 | 0.939055 |
| (256, 16) | 0.00169195 | 0.00164421 | 1.02904 |
| (256, 32) | 0.00190663 | 0.00185056 | 1.0303 |
| (256, 64) | 0.00281769 | 0.00251374 | 1.12092 |
| (256, 100) | 0.00377699 | 0.00310113 | 1.21794 |
| (256, 128) | 0.00404475 | 0.00378238 | 1.06937 |
| (256, 200) | 0.00574436 | 0.00650954 | 0.882452 |
| (256, 256) | 0.0101444 | 0.00898629 | 1.12887 |
| (256, 400) | 0.0140587 | 0.0172373 | 0.815598 |
| (256, 512) | 0.0096035 | 0.0103051 | 0.931919 |
| (256, 600) | 0.0102877 | 0.0117481 | 0.875688 |
| (256, 784) | 0.0115459 | 0.0136387 | 0.846552 |
| (256, 800) | 0.0115765 | 0.0138887 | 0.833524 |
| (256, 1000) | 0.0143795 | 0.0172419 | 0.833989 |
| (256, 1024) | 0.0146941 | 0.0176174 | 0.834069 |
| (256, 1200) | 0.0171993 | 0.0196638 | 0.874668 |
| | dur |
|:-----------------------------------------------------------------|-------:|
| ('256,1200', '(None, (1, -1))', 'Add', 'CPUExecutionProvider') | 203998 |
| ('256,1200', '(None, (1, -1))', 'Mul', 'CPUExecutionProvider') | 215858 |
| ('256,1200', '(None, (1, -1))', 'Slice', 'CPUExecutionProvider') | 940817 |
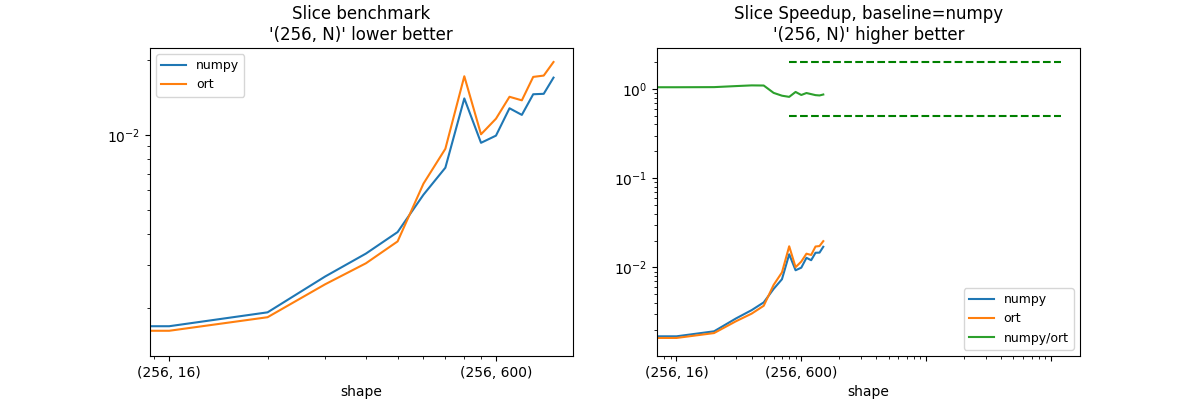
shape = (100, N) - slice = [1:-1], [1:-1]#
dfs = []
dfprof, dfprofgpu, df, piv, ax = benchmark_op(
shape_slice_fct=lambda dim: ((256, dim), ((1, -1), (1, -1))),
save="bslice.onnx", number=nth * 4, repeat=8, repeat_profile=100 * nth)
dfs.append(df)
piv2 = df.pivot("fct", "shape", "average")
print("slices = [1:-1], [1:-1]")
print(piv.to_markdown())
print(dfprof.drop(['pid', 'tid', 'ts'], axis=1).groupby(
cols_profile).sum().to_markdown())
if dfprofgpu is not None:
print(dfprofgpu.drop(['pid', 'tid'], axis=1).groupby(
cols_profile).sum().to_markdown())
[benchmark_op] start repeat=8 number=32 repeat_profile=800 opset=14.
0%| | 0/16 [00:00<?, ?it/s]
6%|6 | 1/16 [00:00<00:11, 1.28it/s]
12%|#2 | 2/16 [00:01<00:11, 1.19it/s]
19%|#8 | 3/16 [00:02<00:11, 1.10it/s]
25%|##5 | 4/16 [00:04<00:13, 1.09s/it]
31%|###1 | 5/16 [00:05<00:14, 1.30s/it]
38%|###7 | 6/16 [00:07<00:15, 1.55s/it]
44%|####3 | 7/16 [00:10<00:18, 2.07s/it]
50%|##### | 8/16 [00:15<00:21, 2.75s/it]
56%|#####6 | 9/16 [00:23<00:30, 4.42s/it]
62%|######2 | 10/16 [00:28<00:27, 4.61s/it]
69%|######8 | 11/16 [00:33<00:24, 4.92s/it]
75%|#######5 | 12/16 [00:40<00:22, 5.55s/it]
81%|########1 | 13/16 [00:47<00:17, 5.90s/it]
88%|########7 | 14/16 [00:55<00:13, 6.60s/it]
94%|#########3| 15/16 [01:04<00:07, 7.11s/it]
100%|##########| 16/16 [01:13<00:00, 7.84s/it]
100%|##########| 16/16 [01:13<00:00, 4.60s/it]
[benchmark_op] done.
[benchmark_op] profile CPU.
[benchmark_op] done.
slices = [1:-1], [1:-1]
| shape | numpy | ort | numpy/ort |
|:------------|-----------:|-----------:|------------:|
| (256, 8) | 0.00146459 | 0.00150623 | 0.972356 |
| (256, 16) | 0.00169569 | 0.00162551 | 1.04318 |
| (256, 32) | 0.00192915 | 0.00184365 | 1.04638 |
| (256, 64) | 0.00269043 | 0.0025028 | 1.07497 |
| (256, 100) | 0.00332919 | 0.00304228 | 1.09431 |
| (256, 128) | 0.00406502 | 0.00372723 | 1.09063 |
| (256, 200) | 0.00575205 | 0.00637526 | 0.902246 |
| (256, 256) | 0.00738916 | 0.00880809 | 0.838906 |
| (256, 400) | 0.0140624 | 0.0172757 | 0.814002 |
| (256, 512) | 0.0093116 | 0.0100792 | 0.923846 |
| (256, 600) | 0.00995245 | 0.0116477 | 0.854459 |
| (256, 784) | 0.0128342 | 0.0142776 | 0.898904 |
| (256, 800) | 0.0120674 | 0.0138135 | 0.873596 |
| (256, 1000) | 0.0146161 | 0.0171719 | 0.851165 |
| (256, 1024) | 0.0146771 | 0.0173843 | 0.844274 |
| (256, 1200) | 0.0170569 | 0.0197211 | 0.864907 |
| | dur |
|:--------------------------------------------------------------------|-------:|
| ('256,1200', '((1, -1), (1, -1))', 'Add', 'CPUExecutionProvider') | 213874 |
| ('256,1200', '((1, -1), (1, -1))', 'Mul', 'CPUExecutionProvider') | 211995 |
| ('256,1200', '((1, -1), (1, -1))', 'Slice', 'CPUExecutionProvider') | 962413 |
Total running time of the script: ( 3 minutes 38.499 seconds)