Note
Click here to download the full example code
One model, many possible conversions with options#
There is not one way to convert a model. A new operator might have been added in a newer version of ONNX and that speeds up the converted model. The rational choice would be to use this new operator but what means the associated runtime has an implementation for it. What if two different users needs two different conversion for the same model? Let’s see how this may be done.
Option zipmap#
Every classifier is by design converted into an ONNX graph which outputs two results: the predicted label and the prediction probabilites for every label. By default, the labels are integers and the probabilites are stored in dictionaries. That’s the purpose of operator ZipMap added at the end of the following graph.
This operator is not really efficient as it copies every probabilies and labels in a different container. This time is usually significant for small classifiers. Then it makes sense to remove it.
There might be in the graph many classifiers, it is important to have a way to specify which classifier should keep its ZipMap and which is not. So it is possible to specify options by id.
from pprint import pformat
import numpy
from onnxruntime import InferenceSession
from pyquickhelper.helpgen.graphviz_helper import plot_graphviz
from sklearn.preprocessing import MinMaxScaler
from sklearn.pipeline import Pipeline
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from skl2onnx.common._registration import _converter_pool
from skl2onnx import to_onnx
from mlprodict.onnxrt import OnnxInference
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, __ = train_test_split(X, y, random_state=11)
clr = LogisticRegression()
clr.fit(X_train, y_train)
model_def = to_onnx(clr, X_train.astype(numpy.float32),
options={id(clr): {'zipmap': False}},
target_opset=17)
oinf = OnnxInference(model_def, runtime='python_compiled')
print(oinf)
somewhere/workspace/onnxcustom/onnxcustom_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py:458: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
OnnxInference(...)
def compiled_run(dict_inputs, yield_ops=None, context=None, attributes=None):
if yield_ops is not None:
raise NotImplementedError('yields_ops should be None.')
# inputs
X = dict_inputs['X']
(label, probability_tensor, ) = n0_linearclassifier(X)
(probabilities, ) = n1_normalizer(probability_tensor)
return {
'label': label,
'probabilities': probabilities,
}
Visually.
ax = plot_graphviz(oinf.to_dot())
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
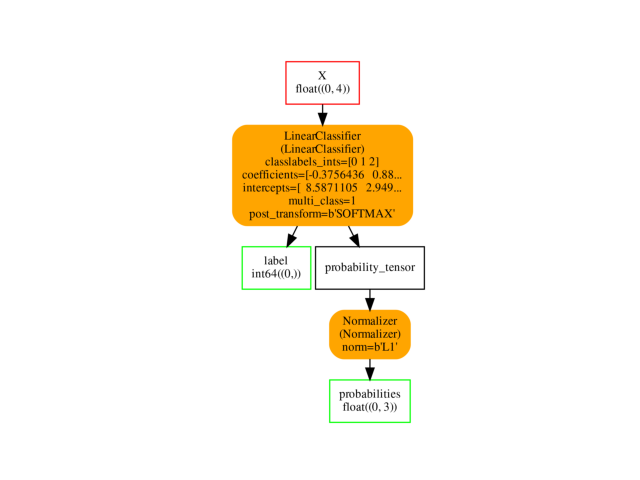
We need to compare that kind of visualisation to what it would give with operator ZipMap.
model_def = to_onnx(clr, X_train.astype(numpy.float32), target_opset=17)
oinf = OnnxInference(model_def, runtime='python_compiled')
print(oinf)
OnnxInference(...)
def compiled_run(dict_inputs, yield_ops=None, context=None, attributes=None):
if yield_ops is not None:
raise NotImplementedError('yields_ops should be None.')
# inputs
X = dict_inputs['X']
(label, probability_tensor, ) = n0_linearclassifier(X)
(output_label, ) = n1_cast(label)
(probabilities, ) = n2_normalizer(probability_tensor)
(output_probability, ) = n3_zipmap(probabilities)
return {
'output_label': output_label,
'output_probability': output_probability,
}
Visually.
ax = plot_graphviz(oinf.to_dot())
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
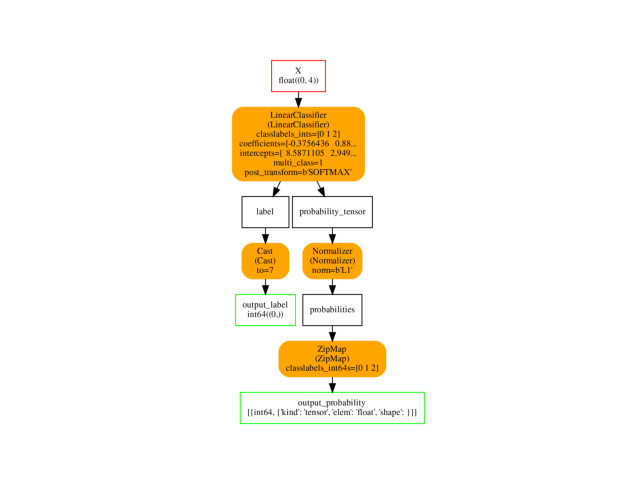
Using function id has one flaw: it is not pickable. It is just better to use strings.
model_def = to_onnx(clr, X_train.astype(numpy.float32),
options={'zipmap': False},
target_opset=17)
oinf = OnnxInference(model_def, runtime='python_compiled')
print(oinf)
OnnxInference(...)
def compiled_run(dict_inputs, yield_ops=None, context=None, attributes=None):
if yield_ops is not None:
raise NotImplementedError('yields_ops should be None.')
# inputs
X = dict_inputs['X']
(label, probability_tensor, ) = n0_linearclassifier(X)
(probabilities, ) = n1_normalizer(probability_tensor)
return {
'label': label,
'probabilities': probabilities,
}
Visually.
ax = plot_graphviz(oinf.to_dot())
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
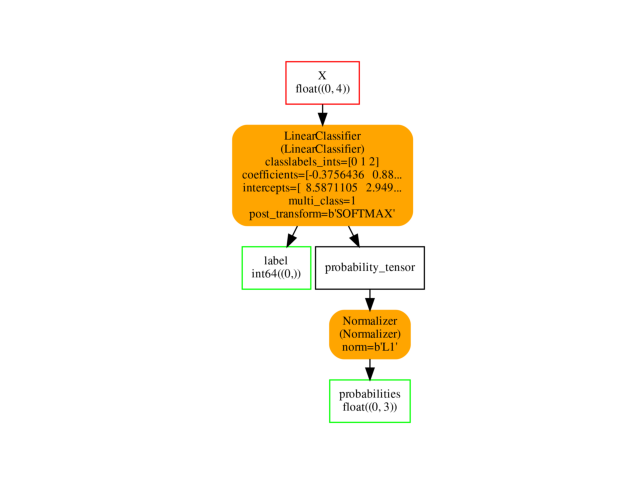
Option in a pipeline#
In a pipeline, sklearn-onnx uses the same name convention.
pipe = Pipeline([
('norm', MinMaxScaler()),
('clr', LogisticRegression())
])
pipe.fit(X_train, y_train)
model_def = to_onnx(pipe, X_train.astype(numpy.float32),
options={'clr__zipmap': False},
target_opset=17)
oinf = OnnxInference(model_def, runtime='python_compiled')
print(oinf)
OnnxInference(...)
def compiled_run(dict_inputs, yield_ops=None, context=None, attributes=None):
if yield_ops is not None:
raise NotImplementedError('yields_ops should be None.')
# init: Ad_Addcst (Ad_Addcst)
# init: Mu_Mulcst (Mu_Mulcst)
# inputs
X = dict_inputs['X']
(Ca_output0, ) = n0_cast(X)
(Mu_C0, ) = n1_mul(Ca_output0, Mu_Mulcst)
(variable, ) = n2_add(Mu_C0, Ad_Addcst)
(label, probability_tensor, ) = n3_linearclassifier(variable)
(probabilities, ) = n4_normalizer(probability_tensor)
return {
'label': label,
'probabilities': probabilities,
}
Visually.
ax = plot_graphviz(oinf.to_dot())
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
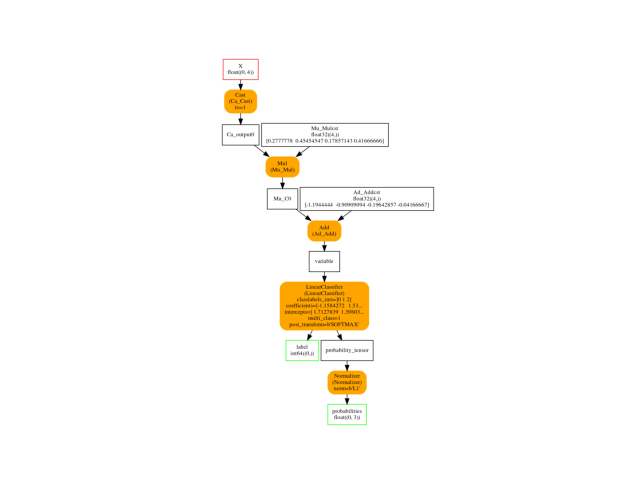
Option raw_scores#
Every classifier is converted in a graph which returns probabilities by default. But many models compute unscaled raw_scores. First, with probabilities:
pipe = Pipeline([
('norm', MinMaxScaler()),
('clr', LogisticRegression())
])
pipe.fit(X_train, y_train)
model_def = to_onnx(
pipe, X_train.astype(numpy.float32),
options={id(pipe): {'zipmap': False}},
target_opset=17)
oinf = OnnxInference(model_def, runtime='python_compiled')
print(oinf.run({'X': X.astype(numpy.float32)[:5]}))
{'label': array([0, 0, 0, 0, 0]), 'probabilities': array([[0.88268614, 0.10948392, 0.00782984],
[0.7944385 , 0.1972866 , 0.00827491],
[0.85557765, 0.13792053, 0.00650185],
[0.8262804 , 0.16634221, 0.00737737],
[0.9005015 , 0.092388 , 0.00711049]], dtype=float32)}
Then with raw scores:
model_def = to_onnx(
pipe, X_train.astype(numpy.float32),
options={id(pipe): {'raw_scores': True, 'zipmap': False}},
target_opset=17)
oinf = OnnxInference(model_def, runtime='python_compiled')
print(oinf.run({'X': X.astype(numpy.float32)[:5]}))
{'label': array([0, 0, 0, 0, 0]), 'probabilities': array([[0.88268614, 0.10948392, 0.00782984],
[0.7944385 , 0.1972866 , 0.00827491],
[0.85557765, 0.13792053, 0.00650185],
[0.8262804 , 0.16634221, 0.00737737],
[0.9005015 , 0.092388 , 0.00711049]], dtype=float32)}
It did not seem to work… We need to tell that applies on a specific part of the pipeline and not the whole pipeline.
model_def = to_onnx(
pipe, X_train.astype(numpy.float32),
options={id(pipe.steps[1][1]): {'raw_scores': True, 'zipmap': False}},
target_opset=17)
oinf = OnnxInference(model_def, runtime='python_compiled')
print(oinf.run({'X': X.astype(numpy.float32)[:5]}))
{'label': array([0, 0, 0, 0, 0]), 'probabilities': array([[ 2.2707398 , 0.18354774, -2.4542873 ],
[ 1.9857953 , 0.5928172 , -2.5786123 ],
[ 2.2349296 , 0.4098304 , -2.6447601 ],
[ 2.1071343 , 0.5042473 , -2.6113818 ],
[ 2.3727787 , 0.095824 , -2.4686027 ]], dtype=float32)}
There are negative values. That works. Strings are still easier to use.
model_def = to_onnx(
pipe, X_train.astype(numpy.float32),
options={'clr__raw_scores': True, 'clr__zipmap': False},
target_opset=17)
oinf = OnnxInference(model_def, runtime='python_compiled')
print(oinf.run({'X': X.astype(numpy.float32)[:5]}))
{'label': array([0, 0, 0, 0, 0]), 'probabilities': array([[ 2.2707398 , 0.18354774, -2.4542873 ],
[ 1.9857953 , 0.5928172 , -2.5786123 ],
[ 2.2349296 , 0.4098304 , -2.6447601 ],
[ 2.1071343 , 0.5042473 , -2.6113818 ],
[ 2.3727787 , 0.095824 , -2.4686027 ]], dtype=float32)}
Negative figures. We still have raw scores.
Option decision_path#
scikit-learn implements a function to retrieve the decision path. It can be enabled by option decision_path.
clrrf = RandomForestClassifier(n_estimators=2, max_depth=2)
clrrf.fit(X_train, y_train)
clrrf.predict(X_test[:2])
paths, n_nodes_ptr = clrrf.decision_path(X_test[:2])
print(paths.todense())
model_def = to_onnx(clrrf, X_train.astype(numpy.float32),
options={id(clrrf): {'decision_path': True,
'zipmap': False}},
target_opset=17)
sess = InferenceSession(model_def.SerializeToString(),
providers=['CPUExecutionProvider'])
[[1 0 1 0 1 1 0 1 0 1]
[1 0 1 0 1 1 0 1 0 1]]
The model produces 3 outputs.
print([o.name for o in sess.get_outputs()])
['label', 'probabilities', 'decision_path']
Let’s display the last one.
res = sess.run(None, {'X': X_test[:2].astype(numpy.float32)})
print(res[-1])
[['10101' '10101']
['10101' '10101']]
List of available options#
Options are registered for every converted to detect any supported options while running the conversion.
all_opts = set()
for k, v in sorted(_converter_pool.items()):
opts = v.get_allowed_options()
if not isinstance(opts, dict):
continue
name = k.replace('Sklearn', '')
print(f"{name}{' ' * (30 - len(name))} {opts!r}")
for o in opts:
all_opts.add(o)
print('all options:', pformat(list(sorted(all_opts))))
LgbmClassifier {'zipmap': [True, False], 'nocl': [True, False]}
LightGbmBooster {'cast': [True, False]}
LightGbmLGBMClassifier {'nocl': [True, False], 'zipmap': [True, False, 'columns']}
LightGbmLGBMRegressor {'split': None}
Skl2onnxTraceableCountVectorizer {'tokenexp': None, 'separators': None, 'nan': [True, False], 'keep_empty_string': [True, False]}
Skl2onnxTraceableTfidfVectorizer {'tokenexp': None, 'separators': None, 'nan': [True, False], 'keep_empty_string': [True, False]}
AdaBoostClassifier {'zipmap': [True, False, 'columns'], 'nocl': [True, False], 'output_class_labels': [False, True], 'raw_scores': [True, False]}
BaggingClassifier {'zipmap': [True, False, 'columns'], 'nocl': [True, False], 'output_class_labels': [False, True], 'raw_scores': [True, False]}
BayesianGaussianMixture {'score_samples': [True, False]}
BayesianRidge {'return_std': [True, False]}
BernoulliNB {'zipmap': [True, False, 'columns'], 'output_class_labels': [False, True], 'nocl': [True, False]}
CalibratedClassifierCV {'zipmap': [True, False, 'columns'], 'output_class_labels': [False, True], 'nocl': [True, False]}
CategoricalNB {'zipmap': [True, False, 'columns'], 'output_class_labels': [False, True], 'nocl': [True, False]}
ComplementNB {'zipmap': [True, False, 'columns'], 'output_class_labels': [False, True], 'nocl': [True, False]}
CountVectorizer {'tokenexp': None, 'separators': None, 'nan': [True, False], 'keep_empty_string': [True, False]}
DecisionTreeClassifier {'zipmap': [True, False, 'columns'], 'nocl': [True, False], 'output_class_labels': [False, True], 'decision_path': [True, False], 'decision_leaf': [True, False]}
DecisionTreeRegressor {'decision_path': [True, False], 'decision_leaf': [True, False]}
ExtraTreeClassifier {'zipmap': [True, False, 'columns'], 'nocl': [True, False], 'output_class_labels': [False, True], 'decision_path': [True, False], 'decision_leaf': [True, False]}
ExtraTreeRegressor {'decision_path': [True, False], 'decision_leaf': [True, False]}
ExtraTreesClassifier {'zipmap': [True, False, 'columns'], 'raw_scores': [True, False], 'nocl': [True, False], 'output_class_labels': [False, True], 'decision_path': [True, False], 'decision_leaf': [True, False]}
ExtraTreesRegressor {'decision_path': [True, False], 'decision_leaf': [True, False]}
GaussianMixture {'score_samples': [True, False]}
GaussianNB {'zipmap': [True, False, 'columns'], 'output_class_labels': [False, True], 'nocl': [True, False]}
GaussianProcessClassifier {'optim': [None, 'cdist'], 'nocl': [False, True], 'output_class_labels': [False, True], 'zipmap': [False, True]}
GaussianProcessRegressor {'return_cov': [False, True], 'return_std': [False, True], 'optim': [None, 'cdist']}
GradientBoostingClassifier {'zipmap': [True, False, 'columns'], 'raw_scores': [True, False], 'output_class_labels': [False, True], 'nocl': [True, False]}
HistGradientBoostingClassifier {'zipmap': [True, False, 'columns'], 'raw_scores': [True, False], 'output_class_labels': [False, True], 'nocl': [True, False]}
HistGradientBoostingRegressor {'zipmap': [True, False, 'columns'], 'raw_scores': [True, False], 'output_class_labels': [False, True], 'nocl': [True, False]}
IsolationForest {'score_samples': [True, False]}
KMeans {'gemm': [True, False]}
KNNImputer {'optim': [None, 'cdist']}
KNeighborsClassifier {'zipmap': [True, False, 'columns'], 'nocl': [True, False], 'raw_scores': [True, False], 'output_class_labels': [False, True], 'optim': [None, 'cdist']}
KNeighborsRegressor {'optim': [None, 'cdist']}
KNeighborsTransformer {'optim': [None, 'cdist']}
KernelPCA {'optim': [None, 'cdist']}
LinearClassifier {'zipmap': [True, False, 'columns'], 'nocl': [True, False], 'output_class_labels': [False, True], 'raw_scores': [True, False]}
LinearSVC {'nocl': [True, False], 'output_class_labels': [False, True], 'raw_scores': [True, False]}
LocalOutlierFactor {'score_samples': [True, False], 'optim': [None, 'cdist']}
MLPClassifier {'zipmap': [True, False, 'columns'], 'output_class_labels': [False, True], 'nocl': [True, False]}
MaxAbsScaler {'div': ['std', 'div', 'div_cast']}
MiniBatchKMeans {'gemm': [True, False]}
MultiOutputClassifier {'nocl': [False, True], 'output_class_labels': [False, True], 'zipmap': [False, True]}
MultinomialNB {'zipmap': [True, False, 'columns'], 'output_class_labels': [False, True], 'nocl': [True, False]}
NearestNeighbors {'optim': [None, 'cdist']}
OneVsOneClassifier {'zipmap': [True, False, 'columns'], 'nocl': [True, False], 'output_class_labels': [False, True]}
OneVsRestClassifier {'zipmap': [True, False, 'columns'], 'nocl': [True, False], 'output_class_labels': [False, True], 'raw_scores': [True, False]}
QuadraticDiscriminantAnalysis {'zipmap': [True, False, 'columns'], 'nocl': [True, False], 'output_class_labels': [False, True]}
RadiusNeighborsClassifier {'zipmap': [True, False, 'columns'], 'nocl': [True, False], 'raw_scores': [True, False], 'output_class_labels': [False, True], 'optim': [None, 'cdist']}
RadiusNeighborsRegressor {'optim': [None, 'cdist']}
RandomForestClassifier {'zipmap': [True, False, 'columns'], 'raw_scores': [True, False], 'nocl': [True, False], 'output_class_labels': [False, True], 'decision_path': [True, False], 'decision_leaf': [True, False]}
RandomForestRegressor {'decision_path': [True, False], 'decision_leaf': [True, False]}
RobustScaler {'div': ['std', 'div', 'div_cast']}
SGDClassifier {'zipmap': [True, False, 'columns'], 'nocl': [True, False], 'output_class_labels': [False, True], 'raw_scores': [True, False]}
SVC {'zipmap': [True, False, 'columns'], 'nocl': [True, False], 'output_class_labels': [False, True], 'raw_scores': [True, False]}
Scaler {'div': ['std', 'div', 'div_cast']}
StackingClassifier {'zipmap': [True, False, 'columns'], 'nocl': [True, False], 'output_class_labels': [False, True], 'raw_scores': [True, False]}
TfidfTransformer {'nan': [True, False]}
TfidfVectorizer {'tokenexp': None, 'separators': None, 'nan': [True, False], 'keep_empty_string': [True, False]}
VotingClassifier {'zipmap': [True, False, 'columns'], 'output_class_labels': [False, True], 'nocl': [True, False]}
WrappedLightGbmBoosterClassifier {'zipmap': [True, False], 'nocl': [True, False]}
XGBoostXGBClassifier {'zipmap': [True, False], 'raw_scores': [True, False], 'nocl': [True, False]}
fct_score_cdist_sum {'cdist': [None, 'single-node']}
all options: ['cast',
'cdist',
'decision_leaf',
'decision_path',
'div',
'gemm',
'keep_empty_string',
'nan',
'nocl',
'optim',
'output_class_labels',
'raw_scores',
'return_cov',
'return_std',
'score_samples',
'separators',
'split',
'tokenexp',
'zipmap']
Total running time of the script: ( 0 minutes 3.447 seconds)