Note
Click here to download the full example code
Quantization aims at reducing the model size but it does compute the output at a lower precision too. The static quantization estimates the best quantization parameters for every observation in a dataset. The dynamic quantization estimates these parameters for every observation at inference time. Let’s see the differences (see alse Quantize ONNX Models).
A model#
Let’s retrieve a not so big model. They are taken from the ONNX Model Zoo or can even be custom.
import os
import urllib.request
import time
import tqdm
import numpy
import onnx
import pandas
import matplotlib.pyplot as plt
from onnxruntime import InferenceSession
from onnxruntime.quantization.quantize import quantize_dynamic, quantize_static
from onnxruntime.quantization.calibrate import CalibrationDataReader
from onnxruntime.quantization.quant_utils import QuantFormat, QuantType
from onnxruntime.quantization.shape_inference import quant_pre_process
def download_file(url, name, min_size):
if not os.path.exists(name):
print(f"download '{url}'")
with urllib.request.urlopen(url) as u:
content = u.read()
if len(content) < min_size:
raise RuntimeError(
f"Unable to download '{url}' due to\n{content}")
print(f"downloaded {len(content)} bytes.")
with open(name, "wb") as f:
f.write(content)
else:
print(f"'{name}' already downloaded")
small = "small"
if small:
model_name = "mobilenetv2-12.onnx"
url_name = ("https://github.com/onnx/models/raw/main/vision/"
"classification/mobilenet/model")
else:
model_name = "resnet50-v1-12.onnx"
url_name = ("https://github.com/onnx/models/raw/main/vision/"
"classification/resnet/model")
if url_name is not None:
url_name += "/" + model_name
download_file(url_name, model_name, 100000)
download 'https://github.com/onnx/models/raw/main/vision/classification/mobilenet/model/mobilenetv2-12.onnx'
downloaded 13964571 bytes.
Inputs and outputs.
sess_full = InferenceSession(model_name, providers=["CPUExecutionProvider"])
for i in sess_full.get_inputs():
print(f"input {i}, name={i.name!r}, type={i.type}, shape={i.shape}")
input_name = i.name
input_shape = list(i.shape)
if input_shape[0] in [None, "batch_size", "N"]:
input_shape[0] = 1
output_name = None
for i in sess_full.get_outputs():
print(f"output {i}, name={i.name!r}, type={i.type}, shape={i.shape}")
if output_name is None:
output_name = i.name
print(f"input_name={input_name!r}, output_name={output_name!r}")
input NodeArg(name='input', type='tensor(float)', shape=['batch_size', 3, 224, 224]), name='input', type=tensor(float), shape=['batch_size', 3, 224, 224]
output NodeArg(name='output', type='tensor(float)', shape=['batch_size', 1000]), name='output', type=tensor(float), shape=['batch_size', 1000]
input_name='input', output_name='output'
We build random data.
maxN = 50
imgs = [numpy.random.rand(*input_shape).astype(numpy.float32)
for i in range(maxN)]
experiments = []
Static Quantization#
This quantization estimates the best quantization parameters (scale and bias) to minimize an error compare to the original model. It requires data.
class DataReader(CalibrationDataReader):
def __init__(self, input_name, imgs):
self.input_name = input_name
self.data = imgs
self.pos = -1
def get_next(self):
if self.pos >= len(self.data) - 1:
return None
self.pos += 1
return {self.input_name: self.data[self.pos]}
def rewind(self):
self.pos = -1
Runs the quantization.
quantize_name = model_name + ".qdq.onnx"
quantize_static(model_name,
quantize_name,
calibration_data_reader=DataReader(input_name, imgs),
quant_format=QuantFormat.QDQ)
WARNING:root:Please consider pre-processing before quantization. See https://github.com/microsoft/onnxruntime-inference-examples/blob/main/quantization/image_classification/cpu/ReadMe.md
WARNING:root:Please consider pre-processing before quantization. See https://github.com/microsoft/onnxruntime-inference-examples/blob/main/quantization/image_classification/cpu/ReadMe.md
Compares the size.
with open(model_name, "rb") as f:
model_onnx = onnx.load(f)
with open(quantize_name, "rb") as f:
quant_onnx = onnx.load(f)
model_onnx_bytes = model_onnx.SerializeToString()
quant_onnx_bytes = quant_onnx.SerializeToString()
print(f"Model size: {len(model_onnx_bytes)} and "
f"quantized: {len(quant_onnx_bytes)}, "
f"ratio={len(quant_onnx_bytes) / len(model_onnx_bytes)}.")
Model size: 13964571 and quantized: 3597737, ratio=0.2576331918825147.
Let’s measure the dIscrepancies.
def compare_with(sess_full, imgs, quantize_name):
sess = InferenceSession(quantize_name, providers=["CPUExecutionProvider"])
mean_diff = 0
mean_max = 0
time_full = 0
time_quant = 0
disa = 0
for img in tqdm.tqdm(imgs):
feeds = {input_name: img}
begin = time.perf_counter()
full = sess_full.run(None, feeds)
time_full += time.perf_counter() - begin
begin = time.perf_counter()
quant = sess.run(None, feeds)
time_quant += time.perf_counter() - begin
diff = numpy.abs(full[0] - quant[0]).ravel()
mean_max += numpy.abs(full[0].ravel().max() - quant[0].ravel().max())
mean_diff += diff.mean()
if full[0].argmax() != quant[0].argmax():
disa += 1
mean_diff /= len(imgs)
mean_max /= len(imgs)
time_full /= len(imgs)
time_quant /= len(imgs)
return dict(mean_diff=mean_diff, mean_max=mean_max,
time_full=time_full, time_quant=time_quant,
disagree=disa / len(imgs),
ratio=time_quant / time_full)
res = compare_with(sess_full, imgs, quantize_name)
res["name"] = "static"
experiments.append(res)
print(f"Discrepancies: mean={res['mean_diff']:.2f}, "
f"mean_max={res['mean_max']:.2f}, "
f"times {res['time_full']} -> {res['time_quant']}, "
f"disagreement={res['disagree']:.2f}")
res
0%| | 0/50 [00:00<?, ?it/s]
4%|4 | 2/50 [00:00<00:04, 10.24it/s]
8%|8 | 4/50 [00:00<00:04, 9.47it/s]
10%|# | 5/50 [00:00<00:05, 8.85it/s]
12%|#2 | 6/50 [00:00<00:05, 8.29it/s]
14%|#4 | 7/50 [00:00<00:05, 8.29it/s]
16%|#6 | 8/50 [00:00<00:05, 8.40it/s]
18%|#8 | 9/50 [00:01<00:04, 8.29it/s]
20%|## | 10/50 [00:01<00:04, 8.42it/s]
22%|##2 | 11/50 [00:01<00:04, 8.23it/s]
24%|##4 | 12/50 [00:01<00:04, 8.65it/s]
26%|##6 | 13/50 [00:01<00:04, 8.38it/s]
30%|### | 15/50 [00:01<00:04, 8.43it/s]
32%|###2 | 16/50 [00:01<00:04, 8.32it/s]
34%|###4 | 17/50 [00:01<00:03, 8.45it/s]
36%|###6 | 18/50 [00:02<00:03, 8.19it/s]
38%|###8 | 19/50 [00:02<00:04, 7.69it/s]
40%|#### | 20/50 [00:02<00:03, 8.15it/s]
42%|####2 | 21/50 [00:02<00:03, 8.29it/s]
44%|####4 | 22/50 [00:02<00:03, 8.22it/s]
46%|####6 | 23/50 [00:02<00:03, 8.13it/s]
48%|####8 | 24/50 [00:02<00:03, 8.32it/s]
50%|##### | 25/50 [00:02<00:02, 8.41it/s]
52%|#####2 | 26/50 [00:03<00:02, 8.47it/s]
54%|#####4 | 27/50 [00:03<00:02, 8.79it/s]
56%|#####6 | 28/50 [00:03<00:02, 9.08it/s]
58%|#####8 | 29/50 [00:03<00:02, 8.74it/s]
60%|###### | 30/50 [00:03<00:02, 8.70it/s]
62%|######2 | 31/50 [00:03<00:02, 8.58it/s]
64%|######4 | 32/50 [00:03<00:02, 8.60it/s]
66%|######6 | 33/50 [00:03<00:02, 8.38it/s]
68%|######8 | 34/50 [00:04<00:01, 8.05it/s]
70%|####### | 35/50 [00:04<00:01, 7.94it/s]
72%|#######2 | 36/50 [00:04<00:01, 8.39it/s]
74%|#######4 | 37/50 [00:04<00:01, 8.45it/s]
76%|#######6 | 38/50 [00:04<00:01, 8.60it/s]
78%|#######8 | 39/50 [00:04<00:01, 8.23it/s]
80%|######## | 40/50 [00:04<00:01, 8.48it/s]
82%|########2 | 41/50 [00:04<00:01, 8.22it/s]
84%|########4 | 42/50 [00:04<00:00, 8.39it/s]
86%|########6 | 43/50 [00:05<00:00, 8.28it/s]
88%|########8 | 44/50 [00:05<00:00, 7.94it/s]
90%|######### | 45/50 [00:05<00:00, 7.86it/s]
92%|#########2| 46/50 [00:05<00:00, 7.95it/s]
94%|#########3| 47/50 [00:05<00:00, 8.16it/s]
98%|#########8| 49/50 [00:05<00:00, 8.61it/s]
100%|##########| 50/50 [00:05<00:00, 8.44it/s]
Discrepancies: mean=0.39, mean_max=0.33, times 0.045105748001951725 -> 0.07221101615577936, disagreement=0.82
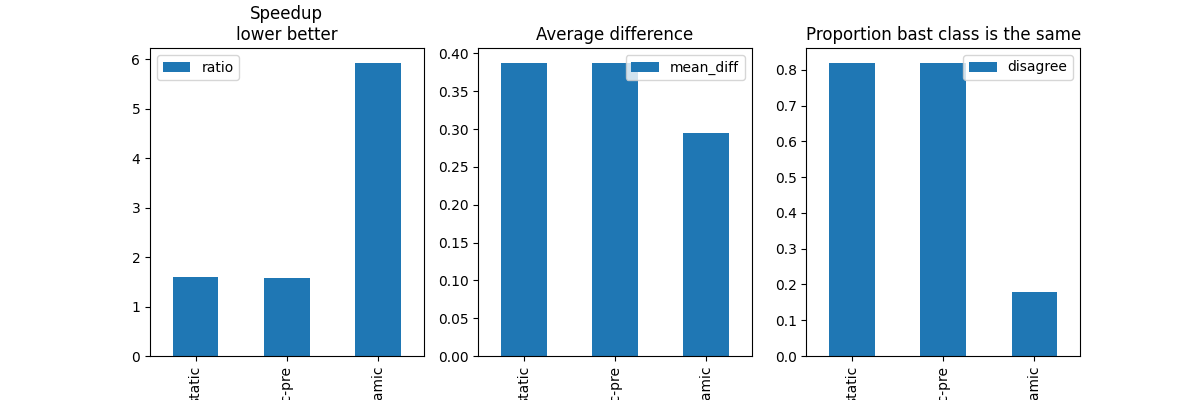
{'mean_diff': 0.38776373863220215, 'mean_max': 0.33206552505493164, 'time_full': 0.045105748001951725, 'time_quant': 0.07221101615577936, 'disagree': 0.82, 'ratio': 1.600927140209598, 'name': 'static'}
With preprocessing#
preprocessed_name = model_name + ".pre.onnx"
quant_pre_process(model_name, preprocessed_name)
And quantization again.
quantize_static(preprocessed_name,
quantize_name,
calibration_data_reader=DataReader(input_name, imgs),
quant_format=QuantFormat.QDQ)
res = compare_with(sess_full, imgs, quantize_name)
res["name"] = "static-pre"
experiments.append(res)
print(f"Discrepancies: mean={res['mean_diff']:.2f}, "
f"mean_max={res['mean_max']:.2f}, "
f"times {res['time_full']} -> {res['time_quant']}, "
f"disagreement={res['disagree']:.2f}")
res
0%| | 0/50 [00:00<?, ?it/s]
2%|2 | 1/50 [00:00<00:04, 9.98it/s]
4%|4 | 2/50 [00:00<00:05, 9.40it/s]
6%|6 | 3/50 [00:00<00:05, 8.07it/s]
8%|8 | 4/50 [00:00<00:05, 7.72it/s]
10%|# | 5/50 [00:00<00:05, 7.90it/s]
12%|#2 | 6/50 [00:00<00:05, 8.33it/s]
14%|#4 | 7/50 [00:00<00:05, 7.92it/s]
16%|#6 | 8/50 [00:00<00:05, 8.30it/s]
18%|#8 | 9/50 [00:01<00:04, 8.57it/s]
20%|## | 10/50 [00:01<00:04, 8.11it/s]
22%|##2 | 11/50 [00:01<00:04, 8.13it/s]
24%|##4 | 12/50 [00:01<00:04, 8.33it/s]
26%|##6 | 13/50 [00:01<00:04, 8.10it/s]
28%|##8 | 14/50 [00:01<00:04, 8.42it/s]
30%|### | 15/50 [00:01<00:04, 8.15it/s]
32%|###2 | 16/50 [00:01<00:04, 8.40it/s]
34%|###4 | 17/50 [00:02<00:04, 8.12it/s]
36%|###6 | 18/50 [00:02<00:03, 8.12it/s]
38%|###8 | 19/50 [00:02<00:03, 7.93it/s]
40%|#### | 20/50 [00:02<00:03, 8.08it/s]
42%|####2 | 21/50 [00:02<00:03, 8.23it/s]
44%|####4 | 22/50 [00:02<00:03, 7.97it/s]
46%|####6 | 23/50 [00:02<00:03, 8.25it/s]
48%|####8 | 24/50 [00:02<00:03, 8.61it/s]
50%|##### | 25/50 [00:03<00:02, 8.57it/s]
52%|#####2 | 26/50 [00:03<00:02, 8.48it/s]
54%|#####4 | 27/50 [00:03<00:02, 8.03it/s]
58%|#####8 | 29/50 [00:03<00:02, 8.73it/s]
60%|###### | 30/50 [00:03<00:02, 8.44it/s]
64%|######4 | 32/50 [00:03<00:02, 8.64it/s]
66%|######6 | 33/50 [00:03<00:02, 8.23it/s]
68%|######8 | 34/50 [00:04<00:02, 7.91it/s]
70%|####### | 35/50 [00:04<00:01, 8.08it/s]
72%|#######2 | 36/50 [00:04<00:01, 8.10it/s]
74%|#######4 | 37/50 [00:04<00:01, 7.71it/s]
76%|#######6 | 38/50 [00:04<00:01, 7.65it/s]
78%|#######8 | 39/50 [00:04<00:01, 7.56it/s]
80%|######## | 40/50 [00:04<00:01, 7.76it/s]
82%|########2 | 41/50 [00:05<00:01, 8.07it/s]
84%|########4 | 42/50 [00:05<00:01, 7.36it/s]
86%|########6 | 43/50 [00:05<00:00, 7.78it/s]
90%|######### | 45/50 [00:05<00:00, 7.86it/s]
92%|#########2| 46/50 [00:05<00:00, 7.92it/s]
94%|#########3| 47/50 [00:05<00:00, 7.58it/s]
96%|#########6| 48/50 [00:05<00:00, 7.68it/s]
98%|#########8| 49/50 [00:06<00:00, 7.33it/s]
100%|##########| 50/50 [00:06<00:00, 7.84it/s]
100%|##########| 50/50 [00:06<00:00, 8.07it/s]
Discrepancies: mean=0.39, mean_max=0.33, times 0.04743068429874256 -> 0.07532987864222378, disagreement=0.82
{'mean_diff': 0.38776373863220215, 'mean_max': 0.33206552505493164, 'time_full': 0.04743068429874256, 'time_quant': 0.07532987864222378, 'disagree': 0.82, 'ratio': 1.5882098214682696, 'name': 'static-pre'}
Dynamic quantization#
quantize_name = model_name + ".qdq.dyn.onnx"
quantize_dynamic(preprocessed_name, quantize_name,
weight_type=QuantType.QUInt8)
res = compare_with(sess_full, imgs, quantize_name)
res["name"] = "dynamic"
experiments.append(res)
print(f"Discrepancies: mean={res['mean_diff']:.2f}, "
f"mean_max={res['mean_max']:.2f}, "
f"times {res['time_full']} -> {res['time_quant']}, "
f"disagreement={res['disagree']:.2f}")
res
0%| | 0/50 [00:00<?, ?it/s]
2%|2 | 1/50 [00:00<00:07, 6.97it/s]
4%|4 | 2/50 [00:00<00:07, 6.42it/s]
6%|6 | 3/50 [00:00<00:07, 6.40it/s]
8%|8 | 4/50 [00:00<00:07, 6.14it/s]
10%|# | 5/50 [00:00<00:07, 6.35it/s]
12%|#2 | 6/50 [00:00<00:07, 6.09it/s]
14%|#4 | 7/50 [00:01<00:06, 6.50it/s]
16%|#6 | 8/50 [00:01<00:06, 6.48it/s]
18%|#8 | 9/50 [00:01<00:06, 6.74it/s]
20%|## | 10/50 [00:01<00:05, 6.76it/s]
22%|##2 | 11/50 [00:01<00:06, 6.46it/s]
24%|##4 | 12/50 [00:01<00:05, 6.35it/s]
26%|##6 | 13/50 [00:02<00:05, 6.33it/s]
28%|##8 | 14/50 [00:02<00:05, 6.39it/s]
30%|### | 15/50 [00:02<00:05, 6.32it/s]
32%|###2 | 16/50 [00:02<00:05, 6.60it/s]
34%|###4 | 17/50 [00:02<00:04, 6.80it/s]
36%|###6 | 18/50 [00:02<00:04, 6.92it/s]
38%|###8 | 19/50 [00:02<00:04, 6.79it/s]
40%|#### | 20/50 [00:03<00:04, 6.78it/s]
42%|####2 | 21/50 [00:03<00:04, 6.86it/s]
44%|####4 | 22/50 [00:03<00:04, 6.86it/s]
46%|####6 | 23/50 [00:03<00:03, 7.03it/s]
48%|####8 | 24/50 [00:03<00:03, 6.75it/s]
50%|##### | 25/50 [00:03<00:03, 6.68it/s]
52%|#####2 | 26/50 [00:03<00:03, 6.83it/s]
54%|#####4 | 27/50 [00:04<00:03, 6.74it/s]
56%|#####6 | 28/50 [00:04<00:03, 6.68it/s]
58%|#####8 | 29/50 [00:04<00:03, 6.25it/s]
60%|###### | 30/50 [00:04<00:03, 6.31it/s]
62%|######2 | 31/50 [00:04<00:03, 6.31it/s]
64%|######4 | 32/50 [00:04<00:02, 6.53it/s]
66%|######6 | 33/50 [00:05<00:02, 6.66it/s]
68%|######8 | 34/50 [00:05<00:02, 6.55it/s]
70%|####### | 35/50 [00:05<00:02, 6.41it/s]
72%|#######2 | 36/50 [00:05<00:02, 6.40it/s]
74%|#######4 | 37/50 [00:05<00:02, 6.46it/s]
76%|#######6 | 38/50 [00:05<00:01, 6.39it/s]
78%|#######8 | 39/50 [00:05<00:01, 6.39it/s]
80%|######## | 40/50 [00:06<00:01, 6.37it/s]
82%|########2 | 41/50 [00:06<00:01, 6.42it/s]
84%|########4 | 42/50 [00:06<00:01, 6.63it/s]
86%|########6 | 43/50 [00:06<00:01, 6.56it/s]
88%|########8 | 44/50 [00:06<00:00, 6.57it/s]
90%|######### | 45/50 [00:06<00:00, 6.61it/s]
92%|#########2| 46/50 [00:07<00:00, 6.51it/s]
94%|#########3| 47/50 [00:07<00:00, 6.52it/s]
96%|#########6| 48/50 [00:07<00:00, 6.47it/s]
98%|#########8| 49/50 [00:07<00:00, 6.30it/s]
100%|##########| 50/50 [00:07<00:00, 6.37it/s]
100%|##########| 50/50 [00:07<00:00, 6.52it/s]
Discrepancies: mean=0.29, mean_max=0.20, times 0.021916336235590278 -> 0.13009194625774398, disagreement=0.18
{'mean_diff': 0.294784417450428, 'mean_max': 0.1978781032562256, 'time_full': 0.021916336235590278, 'time_quant': 0.13009194625774398, 'disagree': 0.18, 'ratio': 5.935843694827316, 'name': 'dynamic'}
Conclusion#
The static quantization (same quantized parameters for all observations) is not really working. The quantized model disagrees on almost all observations. Dynamic quantization (quantized parameters different for each observation) is a lot better but a lot slower too.
fig, ax = plt.subplots(1, 3, figsize=(12, 4))
df = pandas.DataFrame(experiments).set_index("name")
df[["ratio"]].plot(ax=ax[0], title="Speedup\nlower better", kind="bar")
df[["mean_diff"]].plot(ax=ax[1], title="Average difference", kind="bar")
df[["disagree"]].plot(
ax=ax[2], title="Proportion bast class is the same", kind="bar")
# plt.show()
<AxesSubplot: title={'center': 'Proportion bast class is the same'}, xlabel='name'>
Total running time of the script: ( 0 minutes 40.287 seconds)