Note
Click here to download the full example code
Dealing with discrepancies (tf-idf)#
TfidfVectorizer is one transform for which the corresponding converted onnx model may produce different results. The larger the vocabulary is, the higher the probability to get different result is. This example proposes a equivalent model with no discrepancies.
Imports, setups#
All imports. It also registered onnx converters for :epgk:`xgboost` and lightgbm.
import pprint
import numpy
import pandas
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from onnxruntime import InferenceSession
from mlprodict.onnx_conv import to_onnx
from mlprodict.plotting.text_plot import onnx_simple_text_plot
from mlprodict.onnxrt import OnnxInference
from mlprodict.sklapi import OnnxTransformer, OnnxSpeedupTransformer
def print_sparse_matrix(m):
nonan = numpy.nan_to_num(m)
mi, ma = nonan.min(), nonan.max()
if mi == ma:
ma += 1
mat = numpy.empty(m.shape, dtype=numpy.str_)
mat[:, :] = '.'
if hasattr(m, 'todense'):
dense = m.todense()
else:
dense = m
for i in range(m.shape[0]):
for j in range(m.shape[1]):
if dense[i, j] > 0:
c = int((dense[i, j] - mi) / (ma - mi) * 25)
mat[i, j] = chr(ord('A') + c)
return '\n'.join(''.join(line) for line in mat)
def max_diff(a, b):
if a.shape != b.shape:
raise ValueError(
f"Cannot compare matrices with different shapes "
f"{a.shape} != {b.shape}.")
d = numpy.abs(a - b).max()
return d
Artificial datasets#
Iris + a text column.
strings = numpy.array([
"This a sentence.",
"This a sentence with more characters $^*&'(-...",
"""var = ClassName(var2, user=mail@anywhere.com, pwd"""
"""=")_~-('&]@^\\`|[{#")""",
"c79857654",
"https://complex-url.com/;76543u3456?g=hhh&h=23",
"This is a kind of timestamp 01-03-05T11:12:13",
"https://complex-url.com/;dd76543u3456?g=ddhhh&h=23",
]).reshape((-1, 1))
labels = numpy.array(['http' in s for s in strings[:, 0]], dtype=numpy.int64)
data = []
pprint.pprint(strings)
array([['This a sentence.'],
["This a sentence with more characters $^*&'(-..."],
['var = ClassName(var2, user=mail@anywhere.com, pwd=")_~-(\'&]@^\\`|[{#")'],
['c79857654'],
['https://complex-url.com/;76543u3456?g=hhh&h=23'],
['This is a kind of timestamp 01-03-05T11:12:13'],
['https://complex-url.com/;dd76543u3456?g=ddhhh&h=23']],
dtype='<U69')
Fit a TfIdfVectorizer#
tfidf = Pipeline([
('pre', ColumnTransformer([
('tfidf', TfidfVectorizer(ngram_range=(1, 2)), 0)
]))
])
We leave a couple of strings out of the training set.
tfidf.fit(strings[:-2])
tr = tfidf.transform(strings)
tfidf_step = tfidf.steps[0][1].transformers_[0][1]
pprint.pprint(f"output columns: {tfidf_step.get_feature_names_out()}")
print(f"rendered outputs, shape={tr.shape!r}")
print(print_sparse_matrix(tr))
("output columns: ['23' '76543u3456' '76543u3456 hhh' 'amp' 'amp 23' "
"'anywhere'\n"
" 'anywhere com' 'c79857654' 'characters' 'classname' 'classname var2'\n"
" 'com' 'com 76543u3456' 'com pwd' 'complex' 'complex url' 'hhh' 'hhh amp'\n"
" 'https' 'https complex' 'mail' 'mail anywhere' 'more' 'more characters'\n"
" 'pwd' 'sentence' 'sentence with' 'this' 'this sentence' 'url' 'url com'\n"
" 'user' 'user mail' 'var' 'var classname' 'var2' 'var2 user' 'with'\n"
" 'with more']")
rendered outputs, shape=(7, 39)
.........................O.OO..........
........I.............II.HIHH........II
.....GG..GGF.G......GG..G......GGGGGG..
.......Z...............................
GGGGG......FG.GGGGGG.........GG........
...........................Z...........
I..II......G..II..II.........II........
Conversion to ONNX#
onx = to_onnx(tfidf, strings)
print(onnx_simple_text_plot(onx))
opset: domain='' version=16
opset: domain='ai.onnx.ml' version=1
opset: domain='com.microsoft' version=1
input: name='X' type=dtype('O') shape=[None, 1]
init: name='shape_tensor' type=dtype('int64') shape=(1,) -- array([-1])
init: name='idfcst' type=dtype('float32') shape=(39,)
Reshape(X, shape_tensor) -> flattened
StringNormalizer(flattened, case_change_action=b'LOWER', is_case_sensitive=0) -> normalized
Tokenizer[com.microsoft](normalized, mark=0, mincharnum=1, pad_value=b'#', tokenexp=b'[a-zA-Z0-9_]+') -> tokenized
Flatten(tokenized) -> flattened1
TfIdfVectorizer(flattened1, max_gram_length=2, max_skip_count=0, min_gram_length=1, mode=b'TF', ngram_counts=[0,21], ngram_indexes=[0,1,3,5,7,8,9,11,14,16,18,20,22,24,25,27,29,31,33,35,37,2,4,6,10,12,13,15,17,19,21,23,26,28,30,32,34,36,38], pool_strings=57:[b'23',b'76543u3456'...b'with',b'more'], weights=39:[1.0,1.0...1.0,1.0]) -> output
Mul(output, idfcst) -> tfidftr_output
Normalizer(tfidftr_output, norm=b'L2') -> tfidftr_norm
Identity(tfidftr_norm) -> variable
output: name='variable' type=dtype('float32') shape=[None, 39]
Execution with ONNX and explanation of the discrepancies#
for rt in ['python', 'onnxruntime1']:
oinf = OnnxInference(onx, runtime=rt)
got = oinf.run({'X': strings})['variable']
d = max_diff(tr, got)
data.append(dict(diff=d, runtime=rt, exp='baseline'))
print(f"runtime={rt!r}, shape={got.shape!r}, "f"differences={d:g}")
print(print_sparse_matrix(got))
runtime='python', shape=(7, 39), differences=0.57735
.........................R.R...........
........J.............JJ.HJH.........JJ
.....GG..GGF.G......GG..G......GGGGGG..
.......Z...............................
HH.H.......FH.HHHHHH.........HH........
...........................Z...........
I..I.......G..II..II.........II........
runtime='onnxruntime1', shape=(7, 39), differences=0.57735
.........................R.R...........
........J.............JJ.HJH.........JJ
.....GG..GGF.G......GG..G......GGGGGG..
.......Z...............................
HH.H.......FH.HHHHHH.........HH........
...........................Z...........
I..I.......G..II..II.........II........
The conversion to ONNX is not exactly the same. The Tokenizer produces differences. By looking at the tokenized strings by onnx, word h appears in sequence amp|h|23 and the bi-grams amp,23 is never produced on this short example.
oinf = OnnxInference(onx, runtime='python', inplace=False)
res = oinf.run({'X': strings}, intermediate=True)
pprint.pprint(list(map(lambda s: '|'.join(s), res['tokenized'])))
['this|a|sentence|#|#|#|#|#|#|#|#',
'this|a|sentence|with|more|characters|#|#|#|#|#',
'var|classname|var2|user|mail|anywhere|com|pwd|_|#|#',
'c79857654|#|#|#|#|#|#|#|#|#|#',
'https|complex|url|com|76543u3456|g|hhh|amp|h|23|#',
'this|is|a|kind|of|timestamp|01|03|05t11|12|13',
'https|complex|url|com|dd76543u3456|g|ddhhh|amp|h|23|#']
By default, scikit-learn uses a regular expression.
print(f"tokenizer pattern: {tfidf_step.token_pattern!r}.")
tokenizer pattern: '(?u)\\b\\w\\w+\\b'.
onnxruntime uses :epkg:`re2` to handle the regular expression and there are differences with python regular expressions.
onx = to_onnx(tfidf, strings,
options={TfidfVectorizer: {'tokenexp': r'(?u)\b\w\w+\b'}})
print(onnx_simple_text_plot(onx))
try:
InferenceSession(onx.SerializeToString())
except Exception as e:
print(f"ERROR: {e!r}.")
opset: domain='' version=16
opset: domain='ai.onnx.ml' version=1
opset: domain='com.microsoft' version=1
input: name='X' type=dtype('O') shape=[None, 1]
init: name='shape_tensor' type=dtype('int64') shape=(1,) -- array([-1])
init: name='idfcst' type=dtype('float32') shape=(39,)
Reshape(X, shape_tensor) -> flattened
StringNormalizer(flattened, case_change_action=b'LOWER', is_case_sensitive=0) -> normalized
Tokenizer[com.microsoft](normalized, mark=0, mincharnum=1, pad_value=b'#', tokenexp=b'(?u)\\b\\w\\w+\\b') -> tokenized
Flatten(tokenized) -> flattened1
TfIdfVectorizer(flattened1, max_gram_length=2, max_skip_count=0, min_gram_length=1, mode=b'TF', ngram_counts=[0,21], ngram_indexes=[0,1,3,5,7,8,9,11,14,16,18,20,22,24,25,27,29,31,33,35,37,2,4,6,10,12,13,15,17,19,21,23,26,28,30,32,34,36,38], pool_strings=57:[b'23',b'76543u3456'...b'with',b'more'], weights=39:[1.0,1.0...1.0,1.0]) -> output
Mul(output, idfcst) -> tfidftr_output
Normalizer(tfidftr_output, norm=b'L2') -> tfidftr_norm
Identity(tfidftr_norm) -> variable
output: name='variable' type=dtype('float32') shape=[None, 39]
ERROR: RuntimeException('[ONNXRuntimeError] : 6 : RUNTIME_EXCEPTION : Exception during initialization: somewhereonnxruntime-jenkins_39_std/onnxruntime/onnxruntime/contrib_ops/cpu/tokenizer.cc:110 onnxruntime::contrib::Tokenizer::Tokenizer(const onnxruntime::OpKernelInfo&) Can not digest tokenexp: invalid perl operator: (?u\n').
A pipeline#
Let’s assume the pipeline is followed by a logistic regression.
pipe = Pipeline([
('pre', ColumnTransformer([
('tfidf', TfidfVectorizer(ngram_range=(1, 2)), 0)])),
('logreg', LogisticRegression())])
pipe.fit(strings[:-2], labels[:-2])
pred = pipe.predict_proba(strings)
print(f"predictions:\n{pred}")
predictions:
[[0.83726419 0.16273581]
[0.83726419 0.16273581]
[0.82362377 0.17637623]
[0.82739452 0.17260548]
[0.67439649 0.32560351]
[0.82276131 0.17723869]
[0.70203297 0.29796703]]
Let’s convert into ONNX and check the predictions.
onx = to_onnx(pipe, strings, options={'zipmap': False})
for rt in ['python', 'onnxruntime1']:
oinf = OnnxInference(onx, runtime=rt)
pred_onx = oinf.run({'X': strings})['probabilities']
d = max_diff(pred, pred_onx)
data.append(dict(diff=d, runtime=rt, exp='replace'))
print(f"ONNX prediction {rt!r} - diff={d}:\n{pred_onx!r}")
ONNX prediction 'python' - diff=0.010518579922588422:
array([[0.8310883 , 0.16891171],
[0.83295006, 0.16704996],
[0.8236238 , 0.17637622],
[0.82739455, 0.17260547],
[0.68491507, 0.31508493],
[0.82276136, 0.17723869],
[0.708203 , 0.29179698]], dtype=float32)
ONNX prediction 'onnxruntime1' - diff=0.010518579922588422:
array([[0.8310883 , 0.1689117 ],
[0.83295006, 0.16704994],
[0.8236238 , 0.17637622],
[0.82739455, 0.17260545],
[0.68491507, 0.31508493],
[0.8227613 , 0.1772387 ],
[0.708203 , 0.29179698]], dtype=float32)
There are discrepancies introduced by the fact the regular expression uses in ONNX and by scikit-learn are not exactly the same. In this case, the runtime cannot replicate what python does. The runtime can be changed (see onnxruntime-extensions). This example explores another direction.
Replace the TfIdfVectorizer by ONNX before next step#
Let’s start by training the
sklearn.feature_extraction.text.TfidfVectorizer.
tfidf = TfidfVectorizer(ngram_range=(1, 2))
tfidf.fit(strings[:-2, 0])
Once it is trained, we convert it into ONNX and replace
it by a new transformer using onnx to transform the feature.
That’s the purpose of class
mlprodict.sklapi.onnx_transformer.OnnxTransformer.
It takes an onnx graph and executes it to transform
the input features. It follows scikit-learn API.
onx = to_onnx(tfidf, strings)
pipe = Pipeline([
('pre', ColumnTransformer([
('tfidf', OnnxTransformer(onx, runtime='onnxruntime1'), [0])])),
('logreg', LogisticRegression())])
pipe.fit(strings[:-2], labels[:-2])
pred = pipe.predict_proba(strings)
print(f"predictions:\n{pred}")
predictions:
[[0.83640605 0.16359395]
[0.83640605 0.16359395]
[0.82389007 0.17610993]
[0.82794648 0.17205352]
[0.67529626 0.32470374]
[0.82686831 0.17313169]
[0.70074971 0.29925029]]
Let’s convert the whole pipeline to ONNX.
onx = to_onnx(pipe, strings, options={'zipmap': False})
for rt in ['python', 'onnxruntime1']:
oinf = OnnxInference(onx, runtime=rt)
pred_onx = oinf.run({'X': strings})['probabilities']
d = max_diff(pred, pred_onx)
data.append(dict(diff=d, runtime=rt, exp='OnnxTransformer'))
print(f"ONNX prediction {rt!r} - diff={d}:\n{pred_onx!r}")
ONNX prediction 'python' - diff=4.761855731949538e-08:
array([[0.83640605, 0.16359393],
[0.83640605, 0.16359393],
[0.82389003, 0.17610994],
[0.8279465 , 0.17205353],
[0.67529625, 0.32470372],
[0.8268683 , 0.17313169],
[0.70074975, 0.29925027]], dtype=float32)
ONNX prediction 'onnxruntime1' - diff=5.830354410374383e-08:
array([[0.8364061 , 0.16359392],
[0.8364061 , 0.16359392],
[0.8238901 , 0.17610991],
[0.8279464 , 0.17205355],
[0.6752963 , 0.32470372],
[0.8268683 , 0.1731317 ],
[0.70074975, 0.29925025]], dtype=float32)
There are no discrepancies anymore. However this option implies to train first a transformer, to convert it into ONNX and to replace it by an equivalent transformer based on ONNX. Another class is doing all of it automatically.
Train with scikit-learn, transform with ONNX#
Everything is done with the following class:
mlprodict.sklapi.onnx_speed_up.OnnxSpeedupTransformer.
pipe = Pipeline([
('pre', ColumnTransformer([
('tfidf', OnnxSpeedupTransformer(
TfidfVectorizer(ngram_range=(1, 2)),
runtime='onnxruntime1',
enforce_float32=False), 0)])),
('logreg', LogisticRegression())])
pipe.fit(strings[:-2], labels[:-2])
pred = pipe.predict_proba(strings)
print(f"predictions:\n{pred}")
predictions:
[[0.83640605 0.16359395]
[0.83640605 0.16359395]
[0.82389007 0.17610993]
[0.82794648 0.17205352]
[0.67529626 0.32470374]
[0.82686831 0.17313169]
[0.70074971 0.29925029]]
Let’s convert the whole pipeline to ONNX.
onx = to_onnx(pipe, strings, options={'zipmap': False})
for rt in ['python', 'onnxruntime1']:
oinf = OnnxInference(onx, runtime=rt)
pred_onx = oinf.run({'X': strings})['probabilities']
d = max_diff(pred, pred_onx)
data.append(dict(diff=d, runtime=rt, exp='OnnxSpeedupTransformer'))
print(f"ONNX prediction {rt!r} - diff={d}:\n{pred_onx!r}")
ONNX prediction 'python' - diff=4.761855731949538e-08:
array([[0.83640605, 0.16359393],
[0.83640605, 0.16359393],
[0.82389003, 0.17610994],
[0.8279465 , 0.17205353],
[0.67529625, 0.32470372],
[0.8268683 , 0.17313169],
[0.70074975, 0.29925027]], dtype=float32)
ONNX prediction 'onnxruntime1' - diff=5.830354410374383e-08:
array([[0.8364061 , 0.16359392],
[0.8364061 , 0.16359392],
[0.8238901 , 0.17610991],
[0.8279464 , 0.17205355],
[0.6752963 , 0.32470372],
[0.8268683 , 0.1731317 ],
[0.70074975, 0.29925025]], dtype=float32)
This class was originally created to replace one part of a pipeline with ONNX to speed up predictions. There is no discrepancy. Let’s display the pipeline.
print(onnx_simple_text_plot(onx))
opset: domain='com.microsoft' version=1
opset: domain='' version=16
opset: domain='ai.onnx.ml' version=1
input: name='X' type=dtype('O') shape=[None, 1]
init: name='shape_tensor' type=dtype('int64') shape=(1,) -- array([-1])
init: name='idfcst' type=dtype('float32') shape=(39,)
Reshape(X, shape_tensor) -> flattened1
StringNormalizer(flattened1, case_change_action=b'LOWER', is_case_sensitive=0) -> normalized1
Tokenizer[com.microsoft](normalized1, mark=0, mincharnum=1, pad_value=b'#', tokenexp=b'[a-zA-Z0-9_]+') -> tokenized1
Flatten(tokenized1) -> flattened12
TfIdfVectorizer(flattened12, max_gram_length=2, max_skip_count=0, min_gram_length=1, mode=b'TF', ngram_counts=[0,21], ngram_indexes=[0,1,3,5,7,8,9,11,14,16,18,20,22,24,25,27,29,31,33,35,37,2,4,6,10,12,13,15,17,19,21,23,26,28,30,32,34,36,38], pool_strings=57:[b'23',b'76543u3456'...b'with',b'more'], weights=39:[1.0,1.0...1.0,1.0]) -> output1
Mul(output1, idfcst) -> tfidftr_output1
Normalizer(tfidftr_output1, norm=b'L2') -> tfidftr_norm1
LinearClassifier(tfidftr_norm1, classlabels_ints=[0,1], coefficients=78:[-0.18985678255558014,-0.18985678255558014...-0.06052912771701813,-0.06052912771701813], intercepts=[1.3991031646728516,-1.3991031646728516], multi_class=1, post_transform=b'LOGISTIC') -> label, probability_tensor
Normalizer(probability_tensor, norm=b'L1') -> probabilities
output: name='label' type=dtype('int64') shape=[None]
output: name='probabilities' type=dtype('float32') shape=[None, 2]
Graph#
df = pandas.DataFrame(data)
df
plot
df[df.runtime == 'onnxruntime1'][['exp', 'diff']].set_index(
'exp').plot(kind='barh')
# import matplotlib.pyplot as plt
# plt.show()
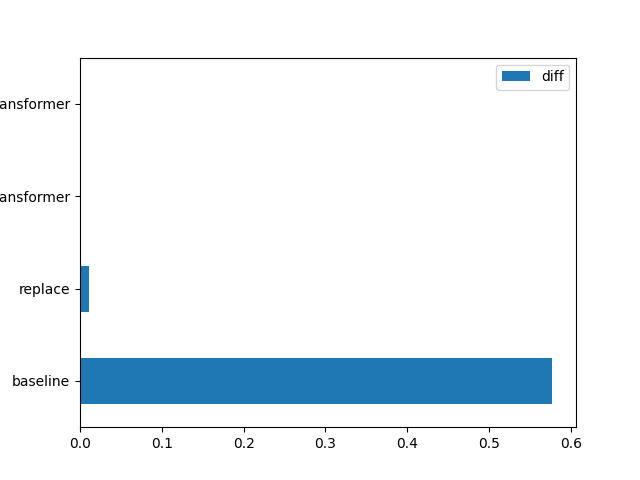
<AxesSubplot: ylabel='exp'>
Total running time of the script: ( 0 minutes 0.854 seconds)