PIG et Paramètres sur Cloudera - énoncé#
Links: notebook, html, PDF, python, slides, GitHub
Utilisation de job paramétrables en Map/Reduce avec PIG sur Cloudera.
from jyquickhelper import add_notebook_menu
add_notebook_menu()
Paramètres#
Les sites web produisent des données en continu. On utilise fréquemment le même script pour traiter les donnéesd’un jour, du lendemain, de jour d’après… Tous les jours, on veut récupérer la fréquentation de la veille. La seule chose qui change est la date des données qu’on veut traiter. Plutôt que de recopier un script en entier pour changer une date qui apparaît parfois à plusieurs endroits, il est préférable d’écrire un script ou la date apparaît comme une variable.
Ce notebook va illustrer ce procédé sur la construction d’un histogramme. Le paramètre du script sera la largeur des barres de l’histogramme (ou bin en anglais).
Connexion au cluster#
On prend le cluster
Cloudera.
Il faut exécuter ce script pour pouvoir notifier au notebook que la
variable params existe.
import pyensae, pyquickhelper
from pyquickhelper.ipythonhelper import open_html_form
params={"server":"df...fr", "username":"", "password":""}
open_html_form(params=params,title="server + credentials", key_save="params")
password
server
username
import pyensae
%load_ext pyensae
%load_ext pyenbc
password = params["password"]
server = params["server"]
username = params["username"]
client = %remote_open
client
<pyensae.remote.ssh_remote_connection.ASSHClient at 0x79ad290>
Upload version#
On commence par simuler des données.
import random
with open("random.sample.txt", "w") as f :
for i in range(0,10000) :
x = random.random()
f.write(str(x)+"\n")
On créé un répertoire sur le cluster :
%dfs_mkdir random
('', '')
%remote_up_cluster random.sample.txt random/random.sample.txt
'random/random.sample.txt'
PIG et paramètres#
On indique un paramètre par le symbole : $bins. La valeur du
paramètre est passé sous forme de chaîne de caractères au script et
remplacée telle quelle dans le script. Il en va de même des constantes
déclarées grâce au mot-clé
%declare.
La sortie du script inclut le paramètre : cela permet de retrouver comment ces données ont été générées.
%%PIG histogram.pig
values = LOAD 'random/random.sample.txt' USING PigStorage('\t') AS (x:double);
values_h = FOREACH values GENERATE x, ((int)(x / $bins)) * $bins AS h ;
hist_group = GROUP values_h BY h ;
hist = FOREACH hist_group GENERATE group, COUNT(values_h) AS nb ;
STORE hist INTO 'random/histo_$bins.txt' USING PigStorage('\t') ;
Pour supprimer les précédents résultats :
if client.dfs_exists("random/histo_0.1.txt"):
client.dfs_rm("random/histo_0.1.txt", recursive=True)
On exécute le job. Comme la commande magique supportant les paramètres
n’existe pas encore, il faut utiliser la variable client et sa
méthode
pig_submit
qui fait la même chose. Elle upload le script puis le soumet.
client.pig_submit("histogram.pig", redirection="redirection", params =dict(bins="0.1") )
('', '')
S’il se produit des erreurs, il est recommandé d’afficher plus de lignes :
%remote_cmd tail redirection.err
Total bytes written : 131 Spillable Memory Manager spill count : 0 Total bags proactively spilled: 0 Total records proactively spilled: 0 Job DAG: job_1414491244634_0168 2014-11-28 00:11:44,435 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Success!
On vérifie que tout s’est bien passé. La taille devrait être équivalent à l’entrée.
%dfs_ls random
| attributes | code | alias | folder | size | date | time | name | isdir | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | drwxr-xr-x | - | xavierdupre | xavierdupre | 0 | 2014-11-28 | 00:11 | random/histo_0.1.txt | True |
| 1 | -rw-r--r-- | 3 | xavierdupre | xavierdupre | 202586 | 2014-11-27 | 23:38 | random/random.sample.txt | False |
if os.path.exists("histo.txt") : os.remove("histo.txt")
client.download_cluster("random/histo_0.1.txt","histo.txt", merge=True)
'random/histo_0.1.txt'
import matplotlib.pyplot as plt
plt.style.use('ggplot')
import pandas
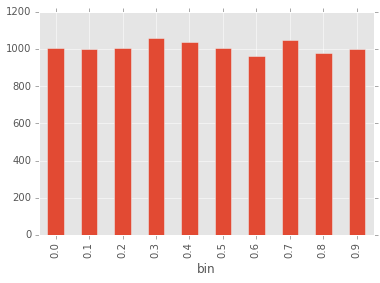
df = pandas.read_csv("histo.txt", sep="\t",names=["bin","nb"])
df.plot(x="bin", y="nb", kind="bar")
<matplotlib.axes._subplots.AxesSubplot at 0xaf7c330>
Exercice 1 : min, max#
Ajouter deux paramètres pour construire l’histogramme entre deux valeurs
a,b.