PIG et JSON et streaming avec les données vélib - correction avec Azure#
Links: notebook, html, PDF, python, slides, GitHub
Correction.
from jyquickhelper import add_notebook_menu
add_notebook_menu()
Récupération des données#
Le code suivant télécharge les données nécessaires data_velib_paris_2014-11-11_22-23.zip.
import os, datetime
from pyensae.datasource import download_data
if not os.path.exists("velib"):
os.mkdir("velib")
files=download_data("data_velib_paris_2014-11-11_22-23.zip", website="xdtd", whereTo="velib")
files[:2]
['velib\paris.2014-11-11_22-00-18.331391.txt', 'velib\paris.2014-11-11_22-01-17.859194.txt']
Connexion au cluster et import des données#
import os
blobhp = {}
if "HDCREDENTIALS" in os.environ:
blobhp["blob_storage"], blobhp["password1"], blobhp["hadoop_server"], blobhp["password2"], blobhp["username"] = \
os.environ["HDCREDENTIALS"].split("**")
r = type(blobhp)
else:
from pyquickhelper.ipythonhelper import open_html_form
params={"blob_storage":"", "password1":"", "hadoop_server":"", "password2":"", "username":"axavier"}
r = open_html_form(params=params,title="server + hadoop + credentials", key_save="blobhp")
r
dict
import pyensae
%load_ext pyensae
%load_ext pyenbc
blobstorage = blobhp["blob_storage"]
blobpassword = blobhp["password1"]
hadoop_server = blobhp["hadoop_server"]
hadoop_password = blobhp["password2"]
username = blobhp["username"] + "az"
client, bs = %hd_open
client, bs
(<pyensae.remote.azure_connection.AzureClient at 0x955cd68>,
<azure.storage.blob.blobservice.BlobService at 0x955cda0>)
On uploade les données (sauf si vous l’avez déjà fait une fois) :
files = [ os.path.join("velib",_) for _ in os.listdir("velib") if ".txt" in _]
if not client.exists(bs, "hdblobstorage", "velib_1h1/paris.2014-11-11_22-00-18.331391.txt"):
client.upload(bs, "hdblobstorage", "velib_1h1", files)
['velib_1h1/paris.2014-11-11_22-00-18.331391.txt',
'velib_1h1/paris.2014-11-11_22-01-17.859194.txt',
'velib_1h1/paris.2014-11-11_22-02-17.544368.txt',
'velib_1h1/paris.2014-11-11_22-03-17.229557.txt',
'velib_1h1/paris.2014-11-11_22-04-18.204200.txt',
'velib_1h1/paris.2014-11-11_22-05-17.959874.txt',
'velib_1h1/paris.2014-11-11_22-06-17.495408.txt',
'velib_1h1/paris.2014-11-11_22-07-18.217540.txt',
'velib_1h1/paris.2014-11-11_22-08-17.761467.txt',
'velib_1h1/paris.2014-11-11_22-09-17.284280.txt',
'velib_1h1/paris.2014-11-11_22-10-18.054360.txt',
'velib_1h1/paris.2014-11-11_22-11-17.581191.txt',
'velib_1h1/paris.2014-11-11_22-12-18.331078.txt',
'velib_1h1/paris.2014-11-11_22-13-17.895678.txt',
'velib_1h1/paris.2014-11-11_22-14-17.444188.txt',
'velib_1h1/paris.2014-11-11_22-15-18.366028.txt',
'velib_1h1/paris.2014-11-11_22-16-18.098484.txt',
'velib_1h1/paris.2014-11-11_22-17-17.794206.txt',
'velib_1h1/paris.2014-11-11_22-18-17.563061.txt',
'velib_1h1/paris.2014-11-11_22-19-17.295153.txt',
'velib_1h1/paris.2014-11-11_22-20-18.337927.txt',
'velib_1h1/paris.2014-11-11_22-21-18.038686.txt',
'velib_1h1/paris.2014-11-11_22-22-17.728834.txt',
'velib_1h1/paris.2014-11-11_22-23-17.480023.txt',
'velib_1h1/paris.2014-11-11_22-24-17.218630.txt',
'velib_1h1/paris.2014-11-11_22-25-18.119732.txt',
'velib_1h1/paris.2014-11-11_22-26-17.878431.txt',
'velib_1h1/paris.2014-11-11_22-27-17.636192.txt',
'velib_1h1/paris.2014-11-11_22-28-17.300711.txt',
'velib_1h1/paris.2014-11-11_22-29-18.265290.txt',
'velib_1h1/paris.2014-11-11_22-30-18.018554.txt',
'velib_1h1/paris.2014-11-11_22-31-17.718195.txt',
'velib_1h1/paris.2014-11-11_22-32-17.393348.txt',
'velib_1h1/paris.2014-11-11_22-33-18.293394.txt',
'velib_1h1/paris.2014-11-11_22-34-17.948293.txt',
'velib_1h1/paris.2014-11-11_22-35-17.638521.txt',
'velib_1h1/paris.2014-11-11_22-36-17.359977.txt',
'velib_1h1/paris.2014-11-11_22-37-18.204045.txt',
'velib_1h1/paris.2014-11-11_22-38-17.783810.txt',
'velib_1h1/paris.2014-11-11_22-39-17.498726.txt',
'velib_1h1/paris.2014-11-11_22-40-18.375180.txt',
'velib_1h1/paris.2014-11-11_22-41-18.081499.txt',
'velib_1h1/paris.2014-11-11_22-42-17.771645.txt',
'velib_1h1/paris.2014-11-11_22-43-17.425107.txt',
'velib_1h1/paris.2014-11-11_22-44-18.335702.txt',
'velib_1h1/paris.2014-11-11_22-45-17.847913.txt',
'velib_1h1/paris.2014-11-11_22-46-17.364178.txt',
'velib_1h1/paris.2014-11-11_22-47-18.092905.txt',
'velib_1h1/paris.2014-11-11_22-48-17.600068.txt',
'velib_1h1/paris.2014-11-11_22-49-18.295991.txt',
'velib_1h1/paris.2014-11-11_22-50-17.777867.txt',
'velib_1h1/paris.2014-11-11_22-51-17.300775.txt',
'velib_1h1/paris.2014-11-11_22-52-18.039108.txt',
'velib_1h1/paris.2014-11-11_22-53-17.577011.txt',
'velib_1h1/paris.2014-11-11_22-54-18.248272.txt',
'velib_1h1/paris.2014-11-11_22-55-17.775525.txt',
'velib_1h1/paris.2014-11-11_22-56-17.319040.txt',
'velib_1h1/paris.2014-11-11_22-57-18.088550.txt',
'velib_1h1/paris.2014-11-11_22-58-17.579701.txt',
'velib_1h1/paris.2014-11-11_22-59-18.340122.txt',
'velib_1h1/paris.2014-11-11_23-00-17.841170.txt']
df=%blob_ls hdblobstorage/velib_1h1
df.head()
| name | last_modified | content_type | content_length | blob_type | |
|---|---|---|---|---|---|
| 0 | velib_1h1 | Wed, 04 Feb 2015 14:30:15 GMT | application/octet-stream Charset=UTF-8 | 0 | BlockBlob |
| 1 | velib_1h1/paris.2014-11-11_22-00-18.331391.txt | Sun, 15 Nov 2015 17:11:59 GMT | application/octet-stream | 523646 | BlockBlob |
| 2 | velib_1h1/paris.2014-11-11_22-01-17.859194.txt | Sun, 15 Nov 2015 17:12:30 GMT | application/octet-stream | 523470 | BlockBlob |
| 3 | velib_1h1/paris.2014-11-11_22-02-17.544368.txt | Sun, 15 Nov 2015 17:12:55 GMT | application/octet-stream | 522057 | BlockBlob |
| 4 | velib_1h1/paris.2014-11-11_22-03-17.229557.txt | Sun, 15 Nov 2015 17:13:32 GMT | application/octet-stream | 523165 | BlockBlob |
Exercice 1 : convertir les valeurs numériques#
Le programme suivant prend comme argument les colonnes à extraire des fichiers textes qui sont enregistrés au format “python”. Le streaming sur Azure est sensiblement différent du streaming présenté avec Cloudera. Cette version fonctionne également avec Cloudera. La réciproque n’est pas vraie. Les scripts python sont interprétés avec la machine virtuelle java tout comme pig. La solution suivante s’inspire de Utilisation de Python avec Hive et Pig dans HDInsight. Voir également Writing Jython UDFs.
Cette écriture impose de comprendre la façon dont PIG décrit les données et l’utilisation de schema. Le nom du script doit être jython.py pour ce notebook sinon le compilateur PIG ne sait pas dans quel langage interpréter ce script.
La version de jython utilisée sur le cluster est
2.5.3 (2.5:c56500f08d34+, Aug 13 2012, 14:54:35) [OpenJDK 64-Bit Server VM (Azul Systems, Inc.)].
La correction inclut encore un bug mais cela devrait être bientôt corrigé. Cela est dû aux différences Python/Jython.
import pyensae
%%PYTHON jython.py
import datetime, sys, re
@outputSchema("brow: {(available_bike_stands:int, available_bikes:int, lat:double, lng:double, name:chararray, status:chararray)}")
def extract_columns_from_js(row):
# pour un programmeur python, les schéma sont contre plutôt intuitifs,
# { } veut dire une liste,
# ( ) un tuple dont chaque colonne est nommé
# j'écrirai peut-être une fonction détermine le schéma en fonction des données
# il faut utiliser des expressions régulières pour découper la ligne
# car cette expression ne fonctionne pas sur des lignes trop longues
# eval ( row ) --> revient à évaluer une ligne de 500 Ko
# Hadoop s'arrête sans réellement proposer de message d'erreurs qui mettent sur la bonne voie
# dans ces cas-là, il faut relancer le job après avoir commenter des lignes
# jusqu'à trouver celle qui provoque l'arrêt brutal du programme
# arrêt qui ne se vérifie pas en local
cols = ["available_bike_stands","available_bikes","lat","lng","name","status"]
exp = re.compile ("(\\{.*?\\})")
rec = exp.findall(row)
res = []
for r in rec :
station = eval(r)
vals = [ str(station[c]) for c in cols ]
res.append(tuple(vals))
return res
La vérification qui suit ne fonctionne que si la fonction à tester prend comme entrée une chaîne de caractères mais rien n’empêche de de créer une telle fonction de façon temporaire juste pour vérifier que le script fonctionne (avec Jython 2.5.3) :
%%jython jython.py extract_columns_from_js
[{'address': 'RUE DES CHAMPEAUX (PRES DE LA GARE ROUTIERE) - 93170 BAGNOLET', 'collect_date': datetime.datetime(2014, 11, 11, 22, 2, 18, 47270), 'lng': 2.416170724425901, 'contract_name': 'Paris', 'name': '31705 - CHAMPEAUX (BAGNOLET)', 'banking': 0, 'lat': 48.8645278209514, 'bonus': 0, 'status': 'OPEN', 'available_bikes': 1, 'last_update': datetime.datetime(2014, 11, 11, 21, 55, 22), 'number': 31705, 'available_bike_stands': 49, 'bike_stands': 50}]
[{'address': 'RUE DES CHAMPEAUX (PRES DE LA GARE ROUTIERE) - 93170 BAGNOLET', 'collect_date': datetime.datetime(2014, 11, 11, 22, 2, 18, 47270), 'lng': 2.416170724425901, 'contract_name': 'Paris', 'name': '31705 - CHAMPEAUX (BAGNOLET)', 'banking': 0, 'lat': 48.8645278209514, 'bonus': 0, 'status': 'OPEN', 'available_bikes': 1, 'last_update': datetime.datetime(2014, 11, 11, 21, 55, 22), 'number': 31705, 'available_bike_stands': 49, 'bike_stands': 50}]
[('49', '1', '48.864527821', '2.41617072443', '31705 - CHAMPEAUX (BAGNOLET)', 'OPEN')]
[('49', '1', '48.864527821', '2.41617072443', '31705 - CHAMPEAUX (BAGNOLET)', 'OPEN')]
On supprime la précédente exécution si besoin puis on vérifie que le répertoire contenant les résultats est vide :
if client.exists(bs, client.account_name, "$PSEUDO/velibpy_results/firstjob"):
r = client.delete_folder (bs, client.account_name, "$PSEUDO/velibpy_results/firstjob")
print(r)
['axavieraz/velibpy_results/firstjob', 'axavieraz/velibpy_results/firstjob/_SUCCESS', 'axavieraz/velibpy_results/firstjob/part-m-00000']
On écrit le script PIG qui utilise plus de colonnes :
%%PIG json_velib_python.pig
REGISTER '$CONTAINER/$SCRIPTPIG/jython.py' using jython as myfuncs;
jspy = LOAD '$CONTAINER/velib_1h1/paris.*.txt'
USING PigStorage('\t') AS (arow:chararray);
DESCRIBE jspy ;
matrice = FOREACH jspy GENERATE myfuncs.extract_columns_from_js(arow);
DESCRIBE matrice ;
multiply = FOREACH matrice GENERATE FLATTEN(brow) ;
DESCRIBE multiply ;
STORE multiply INTO '$CONTAINER/$PSEUDO/velibpy_results/firstjob' USING PigStorage('\t') ;
On soumet le job :
jid = %hd_pig_submit json_velib_python.pig -d jython.py -o --stop-on-failure
jid
{'id': 'job_1446540516812_0222'}
On regarde son statut :
st = %hd_job_status jid["id"]
(st["id"],st["percentComplete"],st["completed"],
st["status"]["jobComplete"],st["status"]["state"])
('job_1446540516812_0222', '100% complete', 'done', True, 'SUCCEEDED')
On récupère l’erreur :
%hd_tail_stderr jid["id"] -n 100
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:264)
at org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.PigTextInputFormat.listStatus(PigTextInputFormat.java:36)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:385)
at org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.PigInputFormat.getSplits(PigInputFormat.java:265)
... 18 more
2015-11-15 18:30:24,368 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - HadoopJobId: job_1446540516812_0223
2015-11-15 18:30:24,368 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Processing aliases jspy,multiply
2015-11-15 18:30:24,368 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - detailed locations: M: jspy[4,7],multiply[-1,-1] C: R:
2015-11-15 18:30:24,368 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 0% complete
2015-11-15 18:30:29,411 [main] WARN org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Ooops! Some job has failed! Specify -stop_on_failure if you want Pig to stop immediately on failure.
2015-11-15 18:30:29,411 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - job job_1446540516812_0223 has failed! Stop running all dependent jobs
2015-11-15 18:30:29,411 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 100% complete
2015-11-15 18:30:29,661 [main] INFO org.apache.hadoop.yarn.client.api.impl.TimelineClientImpl - Timeline service address: http://headnodehost:8188/ws/v1/timeline/
2015-11-15 18:30:29,661 [main] INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at headnodehost/100.89.128.19:9010
2015-11-15 18:30:29,661 [main] INFO org.apache.hadoop.yarn.client.AHSProxy - Connecting to Application History server at headnodehost/100.89.128.19:10200
2015-11-15 18:30:29,880 [main] INFO org.apache.hadoop.mapred.ClientServiceDelegate - Could not get Job info from RM for job job_1446540516812_0223. Redirecting to job history server.
2015-11-15 18:30:30,724 [main] ERROR org.apache.pig.tools.pigstats.PigStats - ERROR 0: java.lang.IllegalStateException: Job in state DEFINE instead of RUNNING
2015-11-15 18:30:30,724 [main] ERROR org.apache.pig.tools.pigstats.mapreduce.MRPigStatsUtil - 1 map reduce job(s) failed!
2015-11-15 18:30:30,724 [main] INFO org.apache.pig.tools.pigstats.mapreduce.SimplePigStats - Script Statistics:
HadoopVersion PigVersion UserId StartedAt FinishedAt Features
2.6.0.2.2.7.1-33 0.14.0.2.2.7.1-33 hdp 2015-11-15 18:30:20 2015-11-15 18:30:30 UNKNOWN
Failed!
Failed Jobs:
JobId Alias Feature Message Outputs
job_1446540516812_0223 jspy,multiply MAP_ONLY Message: org.apache.pig.backend.executionengine.ExecException: ERROR 2118: Input Pattern wasb://hdblobstorage@hdblobstorage.blob.core.windows.net/velib_1h1/paris.*.txt matches 0 files
at org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.PigInputFormat.getSplits(PigInputFormat.java:279)
at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:597)
at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:614)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:492)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1296)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1293)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1293)
at org.apache.hadoop.mapreduce.lib.jobcontrol.ControlledJob.submit(ControlledJob.java:335)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.pig.backend.hadoop23.PigJobControl.submit(PigJobControl.java:128)
at org.apache.pig.backend.hadoop23.PigJobControl.run(PigJobControl.java:194)
at java.lang.Thread.run(Thread.java:745)
at org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher$1.run(MapReduceLauncher.java:276)
Caused by: org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input Pattern wasb://hdblobstorage@hdblobstorage.blob.core.windows.net/velib_1h1/paris.*.txt matches 0 files
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:321)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:264)
at org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.PigTextInputFormat.listStatus(PigTextInputFormat.java:36)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:385)
at org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.PigInputFormat.getSplits(PigInputFormat.java:265)
... 18 more
wasb://hdblobstorage@hdblobstorage.blob.core.windows.net//axavieraz/velibpy_results/firstjob,
Input(s):
Failed to read data from "wasb://hdblobstorage@hdblobstorage.blob.core.windows.net//velib_1h1/paris.*.txt"
Output(s):
Failed to produce result in "wasb://hdblobstorage@hdblobstorage.blob.core.windows.net//axavieraz/velibpy_results/firstjob"
Counters:
Total records written : 0
Total bytes written : 0
Spillable Memory Manager spill count : 0
Total bags proactively spilled: 0
Total records proactively spilled: 0
Job DAG:
job_1446540516812_0223
2015-11-15 18:30:30,724 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Failed!
2015-11-15 18:30:30,755 [main] ERROR org.apache.pig.tools.grunt.GruntParser - ERROR 0: java.lang.IllegalStateException: Job in state DEFINE instead of RUNNING
2015-11-15 18:30:30,755 [main] ERROR org.apache.pig.tools.grunt.GruntParser - org.apache.pig.backend.executionengine.ExecException: ERROR 0: java.lang.IllegalStateException: Job in state DEFINE instead of RUNNING
at org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher.getStats(MapReduceLauncher.java:822)
at org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher.launchPig(MapReduceLauncher.java:452)
at org.apache.pig.backend.hadoop.executionengine.HExecutionEngine.launchPig(HExecutionEngine.java:282)
at org.apache.pig.PigServer.launchPlan(PigServer.java:1390)
at org.apache.pig.PigServer.executeCompiledLogicalPlan(PigServer.java:1375)
at org.apache.pig.PigServer.execute(PigServer.java:1364)
at org.apache.pig.PigServer.executeBatch(PigServer.java:415)
at org.apache.pig.PigServer.executeBatch(PigServer.java:398)
at org.apache.pig.tools.grunt.GruntParser.executeBatch(GruntParser.java:171)
at org.apache.pig.tools.grunt.GruntParser.parseStopOnError(GruntParser.java:234)
at org.apache.pig.tools.grunt.GruntParser.parseStopOnError(GruntParser.java:205)
at org.apache.pig.tools.grunt.Grunt.exec(Grunt.java:81)
at org.apache.pig.Main.run(Main.java:495)
at org.apache.pig.Main.main(Main.java:170)
Caused by: java.lang.IllegalStateException: Job in state DEFINE instead of RUNNING
at org.apache.hadoop.mapreduce.Job.ensureState(Job.java:294)
at org.apache.hadoop.mapreduce.Job.getTaskReports(Job.java:540)
at org.apache.pig.backend.hadoop.executionengine.shims.HadoopShims.getTaskReports(HadoopShims.java:235)
at org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher.getStats(MapReduceLauncher.java:801)
... 13 more
Details also at logfile: C:\apps\dist\hadoop-2.6.0.2.2.7.1-33\logs\pig_1447612207167.log
2015-11-15 18:30:30,786 [main] INFO org.apache.pig.Main - Pig script completed in 23 seconds and 933 milliseconds (23933 ms)
OUT:
jspy: {arow: chararray}
matrice: {brow: {(available_bike_stands: int,available_bikes: int,lat: double,lng: double,name: chararray,status: chararray)}}
multiply: {brow::available_bike_stands: int,brow::available_bikes: int,brow::lat: double,brow::lng: double,brow::name: chararray,brow::status: chararray}
%blob_ls /$PSEUDO/velibpy_results
| name | last_modified | content_type | content_length | blob_type | |
|---|---|---|---|---|---|
| 0 | axavieraz/velibpy_results | Sun, 15 Nov 2015 18:24:17 GMT | application/octet-stream | 0 | BlockBlob |
| 1 | axavieraz/velibpy_results/firstjob | Sun, 15 Nov 2015 18:24:42 GMT | 0 | BlockBlob | |
| 2 | axavieraz/velibpy_results/firstjob/_SUCCESS | Sun, 15 Nov 2015 18:24:42 GMT | application/octet-stream | 0 | BlockBlob |
| 3 | axavieraz/velibpy_results/firstjob/part-m-00000 | Sun, 15 Nov 2015 18:24:42 GMT | application/octet-stream | 76956 | BlockBlob |
On récupère les informations qu’on affiche sous forme de dataframe :
if os.path.exists("velib_exo1.txt") : os.remove("velib_exo1.txt")
%blob_downmerge /$PSEUDO/velibpy_results/firstjob velib_exo1.txt
'velib_exo1.txt'
%head velib_exo1.txt
47 3 48.864527821 2.41617072443 31705 - CHAMPEAUX (BAGNOLET) OPEN 5 28 48.8724200631 2.34839523628 10042 - POISSONNIÃRE - ENGHIEN OPEN 42 1 48.8821489456 2.31986005477 08020 - METRO ROME OPEN 5 31 48.8682170168 2.3304935114 01022 - RUE DE LA PAIX OPEN 20 5 48.8932686647 2.41271573339 35014 - DE GAULLE (PANTIN) OPEN 23 3 48.8703936716 2.38422247271 20040 - PARC DE BELLEVILLE OPEN 0 60 48.884478 2.24772065 28002 - SOLJENITSYNE (PUTEAUX) OPEN 12 12 48.8346588628 2.29578948032 15111 - SERRES OPEN 2 51 48.8390411459 2.43765533908 12124 - PYRAMIDE ARTILLERIE CLOSED 16 6 48.8778722783 2.3374468042 09021 - SAINT GEORGES OPEN
import pandas
df = pandas.read_csv("velib_hd.txt", sep="\t",
names=["available_bike_stands","available_bikes","lat","lng","name","status"])
df.head()
| available_bike_stands | available_bikes | lat | lng | name | status | |
|---|---|---|---|---|---|---|
| 0 | 47 | 3 | 48.864528 | 2.416171 | 31705 - CHAMPEAUX (BAGNOLET) | OPEN |
| 1 | 5 | 28 | 48.872420 | 2.348395 | 10042 - POISSONNIÈRE - ENGHIEN | OPEN |
| 2 | 42 | 1 | 48.882149 | 2.319860 | 08020 - METRO ROME | OPEN |
| 3 | 5 | 31 | 48.868217 | 2.330494 | 01022 - RUE DE LA PAIX | OPEN |
| 4 | 20 | 5 | 48.893269 | 2.412716 | 35014 - DE GAULLE (PANTIN) | OPEN |
Exercice 2 : stations fermées#
Les stations fermées ne le sont pas tout le temps. On veut calculer le ratio minutes/stations fermées / total des minutes/stations. Le script python permettant de lire les données ne change pas, il suffit juste de déclarer les sorties numériques comme telles. Quelques détails sur les tables :
jspy: contient les données brutes dans une liste de fichiersmatrice: d’après le job qui précède, la table contient une ligne par stations et par minute, chaque ligne décrit le status de la stationgrstation: tablematricegroupée par statusfermees: pour chaque groupe, on aggrégé le nombre de minutes multipliés par le nombre de vélosgr*,dist*: distribution du nombre de stations (Y) en fonction du nombre de vélos ou places disponibles
En cas d’exécution précédentes :
for sub in [ "multiply.txt"]:
if client.exists(bs, client.account_name, "$PSEUDO/velibpy_results/" + sub):
r = client.delete_folder (bs, client.account_name, "$PSEUDO/velibpy_results/" + sub)
print(r)
['xavierdupre/velibpy_results/fermees.txt']
['xavierdupre/velibpy_results/distribution_bikes.txt']
['xavierdupre/velibpy_results/distribution_stands.txt']
On va exécuter le job en deux fois. Le premier job met tout à plat. Le second calcule les aggrégations. La plupart du temps, le travaille de recherche concerne la seconde partie. Mais si le job n’est pas scindé, la première partie est toujours exécutée à chaque itération. Dans ce cas-ci, on scinde le job en deux. La première partie forme une table à partir des données initiales. La seconde les agrègre.
%%PIG json_velib_python2.pig
REGISTER '$CONTAINER/$SCRIPTPIG/jython.py' using jython as myfuncs;
jspy = LOAD '$CONTAINER/velib_1h1/*.txt' USING PigStorage('\t') AS (arow:chararray);
DESCRIBE jspy ;
matrice = FOREACH jspy GENERATE myfuncs.extract_columns_from_js(arow);
DESCRIBE matrice ;
multiply = FOREACH matrice GENERATE FLATTEN(brow) ;
DESCRIBE multiply ;
STORE multiply INTO '$CONTAINER/$PSEUDO/velibpy_results/multiply.txt' USING PigStorage('\t') ;
jid = %hd_pig_submit json_velib_python2.pig -d jython.py --stop-on-failure
jid
{'id': 'job_1416874839254_0125'}
st = %hd_job_status jid["id"]
st["id"],st["percentComplete"],st["status"]["jobComplete"]
('job_1416874839254_0125', '100% complete', True)
%blob_ls /$PSEUDO/velibpy_results/multiply.txt
| name | last_modified | content_type | content_length | blob_type | |
|---|---|---|---|---|---|
| 0 | xavierdupre/velibpy_results/multiply.txt | Fri, 28 Nov 2014 01:46:41 GMT | 0 | BlockBlob | |
| 1 | xavierdupre/velibpy_results/multiply.txt/_SUCCESS | Fri, 28 Nov 2014 01:46:41 GMT | application/octet-stream | 0 | BlockBlob |
| 2 | xavierdupre/velibpy_results/multiply.txt/part-... | Fri, 28 Nov 2014 01:46:41 GMT | application/octet-stream | 4693699 | BlockBlob |
for sub in ["fermees.txt", "distribution_bikes.txt", "distribution_stands.txt"]:
if client.exists(bs, client.account_name, "$PSEUDO/velibpy_results/" + sub):
r = client.delete_folder (bs, client.account_name, "$PSEUDO/velibpy_results/" + sub)
print(r)
['xavierdupre/velibpy_results/fermees.txt', 'xavierdupre/velibpy_results/fermees.txt/_temporary', 'xavierdupre/velibpy_results/fermees.txt/_temporary/1']
['xavierdupre/velibpy_results/distribution_bikes.txt', 'xavierdupre/velibpy_results/distribution_bikes.txt/_temporary', 'xavierdupre/velibpy_results/distribution_bikes.txt/_temporary/1']
['xavierdupre/velibpy_results/distribution_stands.txt', 'xavierdupre/velibpy_results/distribution_stands.txt/_temporary', 'xavierdupre/velibpy_results/distribution_stands.txt/_temporary/1']
%%PIG json_velib_python3.pig
multiply = LOAD '$CONTAINER/$PSEUDO/velibpy_results/multiply.txt' USING PigStorage('\t') AS
(available_bike_stands:int, available_bikes:int, lat:double, lng:double, name:chararray, status:chararray) ;
DESCRIBE multiply ;
grstation = GROUP multiply BY status ;
DESCRIBE grstation ;
fermees = FOREACH grstation GENERATE
group
,SUM(multiply.available_bikes) AS available_bikes
,SUM(multiply.available_bike_stands) AS available_bike_stands
;
DESCRIBE fermees ;
gr_av = GROUP multiply BY available_bikes ;
DESCRIBE gr_av;
dist_av = FOREACH gr_av GENERATE group, COUNT(multiply) ;
DESCRIBE dist_av;
gr_pl = GROUP multiply BY available_bike_stands ;
DESCRIBE gr_pl;
dist_pl = FOREACH gr_pl GENERATE group, COUNT(multiply) ;
DESCRIBE dist_pl;
STORE fermees INTO '$CONTAINER/$PSEUDO/velibpy_results/fermees.txt' USING PigStorage('\t') ;
STORE dist_av INTO '$CONTAINER/$PSEUDO/velibpy_results/distribution_bikes.txt' USING PigStorage('\t') ;
STORE dist_pl INTO '$CONTAINER/$PSEUDO/velibpy_results/distribution_stands.txt' USING PigStorage('\t') ;
jid = %hd_pig_submit json_velib_python3.pig --stop-on-failure
jid
{'id': 'job_1416874839254_0127'}
st = %hd_job_status jid["id"]
st["id"],st["percentComplete"],st["status"]["jobComplete"]
('job_1416874839254_0127', '100% complete', True)
%tail_stderr jid["id"] 10
job_1416874839254_0128 2014-11-28 01:51:00,154 [main] WARN org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - No FileSystem for scheme: wasb. Not creating success file 2014-11-28 01:51:00,154 [main] WARN org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - No FileSystem for scheme: wasb. Not creating success file 2014-11-28 01:51:00,154 [main] WARN org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - No FileSystem for scheme: wasb. Not creating success file 2014-11-28 01:51:00,154 [main] INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at headnodehost/100.74.20.101:9010 2014-11-28 01:51:00,279 [main] INFO org.apache.hadoop.mapred.ClientServiceDelegate - Application state is completed. FinalApplicationStatus=SUCCEEDED. Redirecting to job history server 2014-11-28 01:51:01,592 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Success!
OUT:
multiply: {available_bike_stands: int,available_bikes: int,lat: double,lng: double,name: chararray,status: chararray}
grstation: {group: chararray,multiply: {(available_bike_stands: int,available_bikes: int,lat: double,lng: double,name: chararray,status: chararray)}}
fermees: {group: chararray,available_bikes: long,available_bike_stands: long}
gr_av: {group: int,multiply: {(available_bike_stands: int,available_bikes: int,lat: double,lng: double,name: chararray,status: chararray)}}
dist_av: {group: int,long}
gr_pl: {group: int,multiply: {(available_bike_stands: int,available_bikes: int,lat: double,lng: double,name: chararray,status: chararray)}}
dist_pl: {group: int,long}
%blob_ls /$PSEUDO/velibpy_results
| name | last_modified | content_type | content_length | blob_type | |
|---|---|---|---|---|---|
| 0 | xavierdupre/velibpy_results | Thu, 27 Nov 2014 08:56:03 GMT | application/octet-stream | 0 | BlockBlob |
| 1 | xavierdupre/velibpy_results/distribution_bikes... | Fri, 28 Nov 2014 01:50:54 GMT | 0 | BlockBlob | |
| 2 | xavierdupre/velibpy_results/distribution_bikes... | Fri, 28 Nov 2014 01:50:54 GMT | application/octet-stream | 0 | BlockBlob |
| 3 | xavierdupre/velibpy_results/distribution_bikes... | Fri, 28 Nov 2014 01:50:54 GMT | application/octet-stream | 497 | BlockBlob |
| 4 | xavierdupre/velibpy_results/distribution_stand... | Fri, 28 Nov 2014 01:50:55 GMT | 0 | BlockBlob | |
| 5 | xavierdupre/velibpy_results/distribution_stand... | Fri, 28 Nov 2014 01:50:55 GMT | application/octet-stream | 0 | BlockBlob |
| 6 | xavierdupre/velibpy_results/distribution_stand... | Fri, 28 Nov 2014 01:50:55 GMT | application/octet-stream | 477 | BlockBlob |
| 7 | xavierdupre/velibpy_results/fermees.txt | Fri, 28 Nov 2014 01:50:54 GMT | 0 | BlockBlob | |
| 8 | xavierdupre/velibpy_results/fermees.txt/_SUCCESS | Fri, 28 Nov 2014 01:50:54 GMT | application/octet-stream | 0 | BlockBlob |
| 9 | xavierdupre/velibpy_results/fermees.txt/part-r... | Fri, 28 Nov 2014 01:50:53 GMT | application/octet-stream | 37 | BlockBlob |
| 10 | xavierdupre/velibpy_results/firstjob | Thu, 27 Nov 2014 22:39:39 GMT | 0 | BlockBlob | |
| 11 | xavierdupre/velibpy_results/firstjob/_SUCCESS | Thu, 27 Nov 2014 22:39:39 GMT | application/octet-stream | 0 | BlockBlob |
| 12 | xavierdupre/velibpy_results/firstjob/part-m-00000 | Thu, 27 Nov 2014 22:39:39 GMT | application/octet-stream | 4693699 | BlockBlob |
| 13 | xavierdupre/velibpy_results/multiply.txt | Fri, 28 Nov 2014 01:46:41 GMT | 0 | BlockBlob | |
| 14 | xavierdupre/velibpy_results/multiply.txt/_SUCCESS | Fri, 28 Nov 2014 01:46:41 GMT | application/octet-stream | 0 | BlockBlob |
| 15 | xavierdupre/velibpy_results/multiply.txt/part-... | Fri, 28 Nov 2014 01:46:41 GMT | application/octet-stream | 4693699 | BlockBlob |
if os.path.exists("distribution_bikes.txt") : os.remove("distribution_bikes.txt")
%blob_downmerge /$PSEUDO/velibpy_results/distribution_bikes.txt distribution_bikes.txt
'distribution_bikes.txt'
import pandas
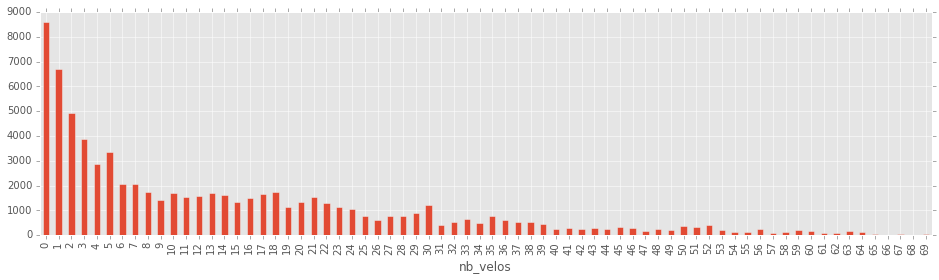
df = pandas.read_csv("distribution_bikes.txt", sep="\t", names=["nb_velos", "nb_stations_minutes"])
df.head()
| nb_velos | nb_stations_minutes | |
|---|---|---|
| 0 | 0 | 8586 |
| 1 | 1 | 6698 |
| 2 | 2 | 4904 |
| 3 | 3 | 3863 |
| 4 | 4 | 2887 |
import matplotlib.pyplot as plt
plt.style.use('ggplot')
df.plot(x="nb_velos",y="nb_stations_minutes",kind="bar",figsize=(16,4))
<matplotlib.axes._subplots.AxesSubplot at 0xae39f90>
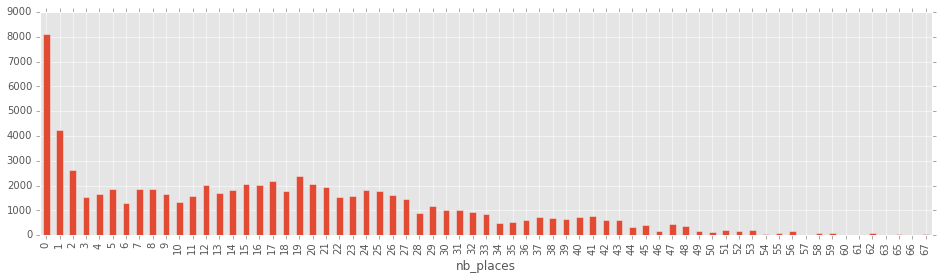
if os.path.exists("distribution_stands.txt") : os.remove("distribution_stands.txt")
%blob_downmerge /$PSEUDO/velibpy_results/distribution_stands.txt distribution_stands.txt
'distribution_stands.txt'
df = pandas.read_csv("distribution_stands.txt", sep="\t", names=["nb_places", "nb_stations_minutes"])
df.plot(x="nb_places",y="nb_stations_minutes",kind="bar",figsize=(16,4))
<matplotlib.axes._subplots.AxesSubplot at 0xab50d50>
if os.path.exists("fermees.txt") : os.remove("fermees.txt")
%blob_downmerge /$PSEUDO/velibpy_results/fermees.txt fermees.txt
'fermees.txt'
df = pandas.read_csv("fermees.txt", sep="\t", names=["status", "nb_velos_stations_minutes", "nb_places_stations_minutes"])
df=df.set_index("status")
df = df.T
df["%close"] = df.CLOSED / (df.CLOSED + df.OPEN)
df
| status | OPEN | CLOSED | %close |
|---|---|---|---|
| nb_velos_stations_minutes | 1066055 | 3111 | 0.002910 |
| nb_places_stations_minutes | 1276138 | 122 | 0.000096 |
Ce dernier tableau n’est vrai que dans la mesure où les nombres reportées sont fiables lorsque les stations sont fermées.
Exercice 3 : stations fermées, journée complète#
Appliquer cela à une journée complète revient à lancer le même job sur des données plus grandes. On verra bientôt commencer éviter de recopier le job une seconde fois (introduisant une source potentielle d’erreur).
Exercice 4 : astuces#
Les erreurs de PIG ne sont pas très explicite surtout si elles se produisent dans le script python. Un moyen simple de débugger est d’attraper les exceptions produites par python et de les récupérer sous PIG (le reste du job est enlevé). On peut tout-à-fait imaginer ajouter la version de python installée sur le cluster ainsi que la liste de modules
%%PYTHON jython.py
import sys
@outputSchema("brow:chararray")
def information(row):
return (";".join([str(sys.version), str(sys.executable)])).replace("\n"," ")
On vérifie que le script fonctionne avec jython :
%%jython jython.py information
n'importe quoi
2.5.3 (2.5:c56500f08d34+, Aug 13 2012, 14:54:35) [Java HotSpot(TM) 64-Bit Server VM (Oracle Corporation)];None
%%PIG info.pig
REGISTER '$CONTAINER/$SCRIPTPIG/jython.py' using jython as myfuncs;
jspy = LOAD '$CONTAINER/velib_1h1/*.txt' USING PigStorage('\t') AS (arow:chararray);
one = LIMIT jspy 1 ;
infos = FOREACH one GENERATE myfuncs.information(arow);
STORE infos INTO '$CONTAINER/$PSEUDO/results/infos' USING PigStorage('\t') ;
if client.exists(bs, client.account_name, "$PSEUDO/results/infos"):
r = client.delete_folder (bs, client.account_name, "$PSEUDO/results/infos")
print(r)
jid = %hd_pig_submit info.pig jython.py --stop-on-failure
jid
{'id': 'job_1416874839254_0107'}
st = %hd_job_status jid["id"]
st["id"],st["percentComplete"],st["status"]["jobComplete"]
('job_1416874839254_0107', '100% complete', True)
%tail_stderr jid["id"] 10
job_1416874839254_0109 2014-11-28 00:11:44,316 [main] INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at headnodehost/100.74.20.101:9010 2014-11-28 00:11:44,394 [main] INFO org.apache.hadoop.mapred.ClientServiceDelegate - Application state is completed. FinalApplicationStatus=SUCCEEDED. Redirecting to job history server 2014-11-28 00:11:44,613 [main] WARN org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - No FileSystem for scheme: wasb. Not creating success file 2014-11-28 00:11:44,628 [main] INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at headnodehost/100.74.20.101:9010 2014-11-28 00:11:44,707 [main] INFO org.apache.hadoop.mapred.ClientServiceDelegate - Application state is completed. FinalApplicationStatus=SUCCEEDED. Redirecting to job history server 2014-11-28 00:11:45,331 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Success!
if os.path.exists("infos.txt") : os.remove("infos.txt")
%blob_downmerge /$PSEUDO/results/infos infos.txt
'infos.txt'
%head infos.txt
2.5.3 (2.5:c56500f08d34+, Aug 13 2012, 14:54:35) [OpenJDK 64-Bit Server VM (Azul Systems, Inc.)];None