2013-01-31 Quelques règles de survie pour travailler à plusieurs
Le document suivant décrit brièvement quelques règles qui peuvent aider si on les suit lorsqu'on se lance dans un programme informatique à plusieurs ou même seul. Elles ne sont pas ni difficiles ni agaçantes si on les applique dès le début du projet. En résumé :
- Ecrire des petites fonctions,
- Séparer les calculs, le chargement des données, l'interface graphique,
- Utiliser des fonctions de tests.
Si vous aimez les nouvelles technologiques type cloud, il devient relativement facile aujourd'hui de travailler à plusieurs sans avoir à s'échanger constamment des fichiers par emails. DropBox et TortoiseSVN permettent assez rapidement d'échanger des informations et de garder l'historique des modifications.
2013-01-30 Graph matching and alignment
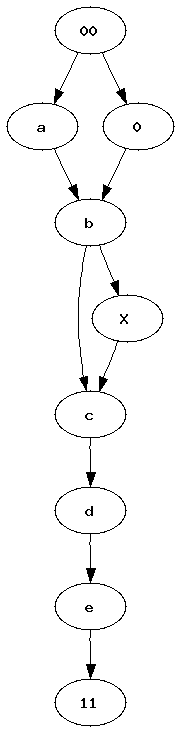
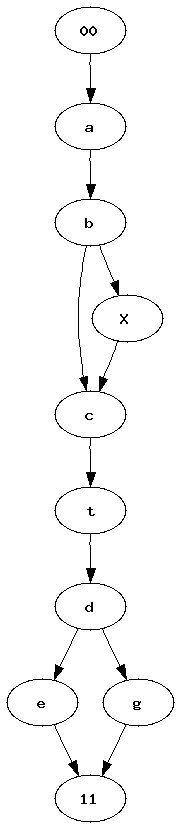
Pipelines became a quite popular way to represent a workflow. Many tools such as RapidMiner, Orange or Weka use graphs to represent the sequence of processes data follow. Most of the time, between two experiments, we just copy paste a previous one, we add or delete a few nodes. After a while, it becomes uneasy to find out what modifications were made. I was wondering how it would be possible to automate such a task. How to find what modifications were introduced in a graph ?
 |
 |
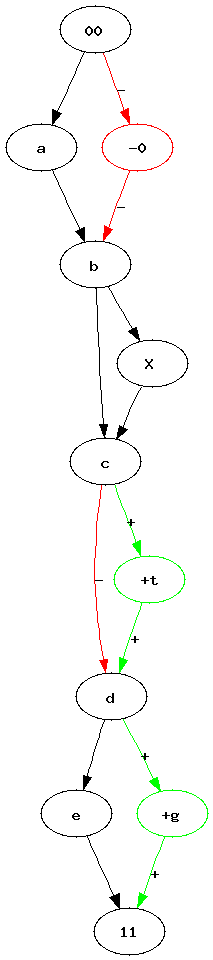 |
| Graph 1 | Graph 2 | Two graphs we would like to merge into a single one. Vertices 00 and 11 represents the only root and the only leave. |
more...
2013-01-28 Répéter les mêmes modifications sur une table
Excel est très pratique pour tracer des graphiques, écrire des formules dans une table. La seule contrainte vient parfois du fait qu'on se retrouve à faire la même chose plusieurs fois de suite. On doit produire les mêmes statistiques sur les mêmes données ou presque les mêmes : la matrice a deux colonnes en plus et trois lignes en moins. Ce n'est pas toujours évident d'adapter ses feuilles Excel. Aujourd'hui, je devais répéter la même formule sur dix colonnes différentes. J'ai donc décider de faire ça en Python. Je voulais écrire quelque chose comme ça :
table.add_column ( "has_A" + k, lambda v : 1 if "prenom" in v["name"] else 0 )L'avantage est que je peux maintenant écrire quelque chose comme :
for name in selection_colonnes :
table.add_column ( "has_" + name, lambda v : 1 if "mot clé" in v[name] else 0 )
ou encore
group = table.groupby ( lambda v: v["name"],
[ lambda v: v["d_a"],
lambda v: v["d_b"] ],
[ "name", "sum_d_a", "sum_d_b"] )
et
innerjoin = table.innerjoin (group, lambda v : v["name"],
lambda v : v["name"], "group" )
Il ne me reste plus qu'à récupérer le tout sous Excel pour faire des graphiques
ou faire de la mise en page. J'ai dû le coder plusieurs fois sous différentes
formes. Voici la dernière.
2013-01-26 Compter le nombre de cellules d'une couleur sous Excel
On cherche à compter le nombre de cellules d'une couleur spécifique sous Excel dans une plage de données. On peut considérer l'exemple suivant qui fait apparaître un rectangle contenant des cases de couleurs différentes. La première ligne contient toutes les couleurs une seule fois, la seconde ligne contient le nombre de cellules dans le rectangle de la même couleur que la case du dessus.

On veut pouvoir écrire une formule du type :
=NbColorSameAs($B$6:$D$11;B1)Il n'est pas possible de s'en sortir sans programmer soit même cette fonction. Pour cela, il faut :
- créer une document Excel qui accepte les macros,
- ouvrir l'éditeur Visual Basic (ALT + F11),
- ajouter un module (clic droit de la souris)
- copier/coller le code qui suit
Function NbColor(ByRef Plage As Range, Couleur As Byte) As Long
Dim c As Range
Dim nb As Long
nb = 0
For Each c In Plage
If c.Interior.ColorIndex = Couleur Then
nb = nb + 1
End If
Next c
NbColor = nb
End Function
Function NbColorSameAs(ByRef Plage As Range, ByRef Cellule As Range) As Long
NbColorSameAs = NbColor(Plage, Cellule.Interior.ColorIndex)
End Function
Le document Excel est maintenant prêt, il suffit d'insérer
la première formule insérée plus haut dans ce blog (vous pourrez trouver un
exemple ici).
more...
2013-01-25 How to normalize an edit distance ?
An edit distance is usually used to compute a distance between two words. The basic version gives the same weight to every mistake or operation which means every comparison, every insertion or deletion between two words weight the same. The sum of all these errors gives a integer score and most of time, it is better to keep that score within an interval such as [0,1].
Most of the time, we divide the edit distance by the length of the longest word involved in that distance. This score is not a distance anymore in a sense it does not verify the triangular inequality. There are many option and the following document studies some aspects of normalizations. Based on that, the maximum length is not the best option, the minimum length is not very good either. A third option studied in that document seems to be the best, especially if this distance is used by a machine learned model as a feature.
|
Xavier Dupré
|