2013-07-30 IExplorer and class HTTPServer (Python)
I was wondering why I could not make something work on IExplorer while it was perfectly working with Firefox and Chrome. My simple Python web server seemed to get stuck most of the time by IExplorer (no logs) when I could see all the requests sent by Firefox. When I was leaving IExplorer, the error message was "interrupted connection". I finally found the error: IExplorer sends mulitple requests in parallel and the class HTTPServer does not handle it. To fix that, you need to do the following:
from http.server import BaseHTTPRequestHandler, HTTPServer, SimpleHTTPRequestHandler
from socketserver import ThreadingMixIn
class ThreadedServer (ThreadingMixIn, HTTPServer) :
pass
class MyHandler(BaseHTTPRequestHandler):
def respond(self, status_code):
self.send_response(status_code)
self.end_headers()
def do_GET(self):
# ...
server = ThreadedServer(('localhost', 8080), MyHandler)
server.serve_forever()
2013-07-29 Starting a coding projet
When I was young, I was writing code, running, fixing bugs and going on to something else to code. After I joined my first company, I realized many people were doing that. There were very different styles of coding, spaces anywhere, indentation not following a single rule and always some resistance to follow one set of rules. I started to work in a company with various cultures and styles. People usually write code following the style which is the clearest for them, the easiest to understand for them. I'm usually skeptical when somebody explains everybody should do this or this because it makes more sense. As a teacher, I saw too many different logics, each of them writing in their own style. And if you do different, it is because it is more simple that way for you. For example, I usually choose small variables name for a loop (n, i, t, u) because I read it as a mathematical loop (\sigma_{i=1}^n ...). I add a space before semicolon because you do this in French. One rule I follow is when I modify something written by somebody else: I try to follow the same style. I remember some code review which came back with many comments because my spaces were not good. I think there should be a tool for that.
Anyway, when you work on a big project, I'm not sure about the importance of the style but I know some tools and practice are unavoidables:
- unit tests: that should be the first thing you write,
- source repository: Git seemed to be one of the best choices,
- code review: they make it easy to share pieces of code (see ReviewBoard).
- automated help generation: it can be useful if it is started soon enough
2013-07-28 my RSS Reader
When Google Reader died, I was reluctant to move to something different. Not because others solutions are worse or anything like that, but more because I needed to create a new account, a new password, eventually to pay if the number of blogs I wanted to follow was above a given threshold. With Google, I did not have to do anything like that. I would argue that giving everything to a single company which can monitor every single move you do on the net is not a good idea.
But if I push this reasoning to its extreme, why not having a tool on my laptop which allows me to read blog posts? That way, I would download myself the blog content, I would keep any statistics about my own uage for myself. And if the design is not good enough, I just have to change it. Well, the only argument against that is the time I will need to build that tool (and to maintain it).
Well, to be honest, I also did it because I wanted to learn about some python and javascript figures of programming which I talk about in previous blogs. The tools looks that way:
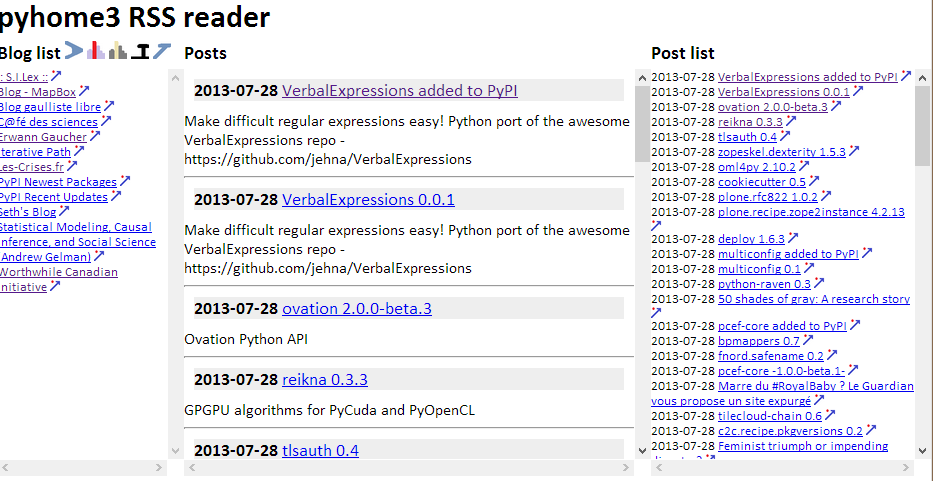
more...
2013-07-27 Logging click events on your server
Many websites log events, where users clicked for example. They want to optimize for a better use. You would assume every time a user requests a page, your server needs to provide the user with the content of the page. However some cache mechanism could prevent you from getting that information, a user could click on a link leading outside your website or the same page could be obtained from different others pages. You need a more precise information. How to log a click event then?
To do that, we first need to do something when a user clicks on a url: we need to catch this event and to call another function. We use the following syntax:
<a href="url" onmousedown="sendlog('url')">anchor</a>
The function sendlog will be executed when the user clicks on this particular url.
The string between the quotes is the information to log. The function sendlog
is defined in another file, defsendlog.js in this case. The following lines
must be added to the HTML page (header section):
<script type="text/javascript" src="/defsendlog.js"></script>
more...
2013-07-26 Keep the scrolling position after resfreshing
I added the scrolling property to a div section:
div.divblogs{
position:absolute;
margin-top:10%;
margin-left:0%;
margin-right:0%;
text-align: left;
width:20%;
height:80%;
overflow:scroll;
}
Unfortunately, after a refresh or a click somewhere
which makes only helf the page change, every list returned to its first position.
It was bothering me. I finaly found a way to keep list the way they are after
a refresh. It requires cookies: we store the position of each section in cookies.
function createCookie(name,value,days)
{
if (days)
{
var date = new Date();
date.setTime(date.getTime()+(days*24*60*60*1000));
var expires = "; expires="+date.toGMTString();
}
else var expires = "";
document.cookie = name+"="+value+expires+"; path=/";
}
function readCookie(name)
{
var nameEQ = name + "=";
var ca = document.cookie.split(';');
for(var i=0;i < ca.length;i++) {
var c = ca[i];
while (c.charAt(0)==' ') c = c.substring(1,c.length);
if (c.indexOf(nameEQ) == 0) return c.substring(nameEQ.length,c.length);
}
return null;
}
function savePosition(document, divId)
{
var intY = document.getElementById(divId).scrollTop;
if (intY >= 0) {
createCookie("divid" + divId, "y" + intY + "_", 1) ;
}
}
function getPosition(document, divId)
{
var cook = readCookie("divid" + divId) ;
if (cook == null) return 0 ;
var start = cook.indexOf("y") ;
if (start == -1) return 0 ;
var end = cook.indexOf("_", start) ;
var sub = cook.substring( start+1, end) ;
return sub ;
}
So to save the scrolling position of a div section, you just need to call
the function savePosition each time it is updated:
<div class="divblogs" id="divblogs" onscroll="savePosition(document,'divblogs')"> ... </div>The last detail left is a function called when the page is reloading to restore each section's position:
<body onload="setPositions(document,['divblogs', 'divpostsshort', 'divpostsext'])">The function setPositions is defined as follows:
function setPositions(document, listDiv)
{
for (var i = 0 ; i < listDiv.length ; ++i)
{
var divObject = document.getElementById(listDiv[i]);
divObject.scrollTop = getPosition(document,listDiv[i]) ;
}
}
Last detail, each section div has attributes (class and id).
They are important to enable the scrolling and the make them easily
accessible.
2013-07-16 Les trucs que je ne sais jamais quand j'en ai besoin
I read two blogs about stuff I never remember when I need it. I often manipulate text file and I know the linux tools are doing quite a great job about that. But I never remember the syntax. This blog post seems to be a good pointer: Useful Unix commands for data science.
The second is about mutex and lock. The second one is used to synchronize threads among a single application. The first one (mutex) is used to synchronize processes among them (but also threads as a consequence). And if you want to use mutex all the time because it is convenient, you should read this blog post first: Lock vs. Mutex.
2013-07-10 Donner envie de partager ses données personnelles
Je lisais cet article aujourd'hui MATRIX – Ce que nos données Gmail révèlent de notre vie sociale qui décrit un outil d'analyse des emails Immersion. Le titre de l'application est assez évocateur et le journaliste plutôt enthousiaste A bien y réfléchir, à moins d'avoir un réseau démesurément grand, les informations représentées au travers de cette application ne devraient pas surprendre. On peut raisonnablement penser que chacun est susceptible de connaître les différents réseaux avec lesquels il communique, les heures auxquelles les emails sont envoyés ou reçus. La nouveauté réside dans l'aspect visuel.
Je reconnais que l'application est plutôt ludique et qu'on a envie de voir ses propres emails (même si personnellement je ne l'ai pas fait). Le concepteur aussi pu choisir une application que l'utilisateur télécharge et installe sur son ordinateur en lui laissant de récupérer ses propres données. Il a préféré emballer le tout sous forme de service acceptant volontiers de récupérer vos données pour vous les montrer. Bien sûr, il s'engage à ne les partager avec qui que ce soit voire à les effacer. On peut supposer que le MIT qui héberge l'ensemble est un organisme à qui on peut faire confiance.
Choisir une application qui s'installer aurait sans doute nuit quelque peu à la facilité d'utilisation. Toutefois, cela montre comment, avec une application ludique, on peut inciter pas mal de gens à partager leur données. Ce service, déjà présenté dans plusieurs journaux, aura probablement été essayé par plusieurs journalistes, lesquels auront utilisé leur adresse gmail. C'est ainsi qu'en quelques jours, il aura été possible de dresser une carte des connexions entre les journalistes de la presse informatique.
On peut imaginer que l'application soit étendue aux données Facebook. Il est probable qu'on retrouve des réseaux similaires sur gmail et Facebook. Et en peu de temps et quelques algorithmes plus loin, on aura pu associer un profil facebook avec une adresse gmail.
2013-07-07 Build a Python 64 bit extension on Windows 8
I was using MinGW on Windows to build a Python extension including C++ code. The 32bit mode was working fine and I was using the following command line:
python setup.by build --compiler=mingw32I thought it would be easy to run it with the Python 64 bit version. No change would be required. I was a little bit over confident.
Traceback (most recent call last):
File "setup.py", line 11, in <module>
author_email = '...',
File "c:\python33_x64\lib\distutils\core.py", line 148, in setup
dist.run_commands()
File "c:\python33_x64\lib\distutils\dist.py", line 929, in run_commands
self.run_command(cmd)
File "c:\python33_x64\lib\distutils\dist.py", line 948, in run_command
cmd_obj.run()
File "c:\python33_x64\lib\distutils\command\build_ext.py", line 323, in run
force=self.force)
File "c:\python33_x64\lib\distutils\ccompiler.py", line 1034, in new_compiler
return klass(None, dry_run, force)
File "c:\python33_x64\lib\distutils\cygwinccompiler.py", line 125, in __init__
if self.ld_version >= "2.10.90":
TypeError: unorderable types: NoneType() >= str()
I decided to switch to Visual Studio Express 2012 to build my extension.
but I went through some error related to the file vcvarsall.bat because
Python was not able to find the file vsvars64.bat (for one very good
reason, it does not exist). I read some blogs where people suggest to reinstall
Visual Studio Express
but I did not remember the setup asking me anything about options.
When I checked the folder of Visual Studio, I found the following file
vcvarsx86_amd64.bat. Then, after some research (stubborness is mandatory for those parts)
and some tweaks, I discovered two mistakes in the package distutils.
They need to be fixed in the file msvc9compiler.py:
- The file uses the version Visual Studio used to compile Python (2010),
which is not the version I used, so I manually updated the function
get_build_version to get:
if majorVersion >= 6: # pick on of the following line majorVersion = 11 # VS 2012 majorVersion = 12 # VS 2013 majorVersion = 14 # VS 2015 return majorVersion + minorVersionNot the best but it works. - The second modification is at the beginning of the same file which contains:
PLAT_TO_VCVARS = { 'win32' : 'x86', 'win-amd64' : 'amd64', 'win-ia64' : 'ia64', }The flag amd64 must be replaced by x86_amd64.
python setup.by build --compiler=msvc --plat-name=win-amd64And I understood why it was failing without any mysterious new installation. I checked about 64 bit version of MinGW but it looked a longer path than the one I chose. Who knows? You will find some others details here. I wrote a function which import a module written in one single C++ file. If the module does not exist, it compiles it inplace.
As a conclusion, I would say it was difficult to find the proper instructions. Maybe the number of documents related to that issue has increased, or the search engines I used were not able to give me the answer. All I know is I do not want to go through that again even if I know there will be a next time when I update Python or when I change my laptop. I hope next time I face that problem, search engines will show me my own page.
2013-07-01 Unit test, what a relief ?
To be honest, I hesitated. French, English, I was pissed off by own coding (I speak French in that case) but saved by a unit test...
Function signature are a bit tricky in python because this definition does not exist. There is only one function and you have to tweak around the parameters' type. So... this is an example of a case where unit tests were useful to me.
def function_nobody(input) :
if isinstance (input, list) :
for line in list :
# ....
elif isinstance (input ,str) :
with open(input, "r", encoding="utf8") as f :
for line in f :
# ...
So basically, the previous function accepts a file or a list. But I
wanted it to be more generic and to accept iterators:
import collections
def function_nobody(input) :
if isinstance (input, list) or isinstance (file, collections.Iterable) :
for line in list :
# ....
elif isinstance (input ,str) :
with open(input, "r", encoding="utf8") as f :
for line in f :
# ...
I added isinstance (file, collections.Iterable). But a string falls under
that condition which made the second case useless. But because I wrote
unit tests, I was able to catch my mistake. I just reverted the two tests:
import collections
def function_nobody(input) :
if isinstance (input ,str) :
with open(input, "r", encoding="utf8") as f :
for line in f :
# ...
elif isinstance (input, list) or isinstance (file, collections.Iterable) :
for line in list :
# ....
And it worked. I confess I did not lose two much time and I would not have lost
any even without unit tests because I would not know my failure.
However, I don't want to guess how much crazyness
I could have gone through if one of my scripts fails because of that a month,
two, three months later. How could I guess it is because of that...
Please do unit testing... Ok, it is late, my style might be overdramatic. But, please remember this when it is your time to experience one of these overdramatic scenarii. (I used the latin plural for scenario, don't know if it works in English).
|
Xavier Dupré
|