Note
Click here to download the full example code
Compares implementations of Einsum#
This example compares the performance of numpy.einsum(),
torch.einsum() and its decomposition into standard
vector operations for a couple of equations.
function einsum from onnxruntime
decomposition of einsum into ONNX and processed with onnxruntime
decomposition of einsum into ONNX and processed with pytorch with the simple runtime
OnnxTorchRuntime.
Available optimisation#
The code shows which optimisation is used for the custom implementation, AVX or SSE and the number of available processors, equal to the default number of used threads to parallelize.
import numpy
import pandas
import matplotlib.pyplot as plt
from onnxruntime import InferenceSession
from skl2onnx.common.data_types import FloatTensorType
from skl2onnx.algebra.onnx_ops import OnnxEinsum
from cpyquickhelper.numbers import measure_time
from tqdm import tqdm
from mlprodict.testing.experimental_c_impl.experimental_c import (
code_optimisation)
from mlprodict.testing.einsum.einsum_fct import _einsum
from mlprodict.plotting.plotting_onnx import plot_onnx
from deeponnxcustom.onnxtorch.tchrun import OnnxTorchRuntime
print(code_optimisation())
Out:
AVX-omp=8
Einsum: common code#
The main function which benchmark a couple of options.
try:
from torch import einsum as torch_einsum, from_numpy
except ImportError:
torch_einsum = None
def build_ort_einsum(equation, op_version=14): # opset=13, 14, ...
node = OnnxEinsum('x', 'y', equation=equation,
op_version=op_version,
output_names=['z'])
onx = node.to_onnx(inputs=[('x', FloatTensorType()),
('y', FloatTensorType())],
target_opset=op_version)
sess = InferenceSession(onx.SerializeToString())
return lambda x, y: sess.run(None, {'x': x, 'y': y})
def build_ort_decomposed(equation, op_version=14): # opset=13, 14, ...
cache = _einsum(equation, numpy.float32, opset=op_version,
optimize=True, verbose=True, runtime="python")
if not hasattr(cache, 'onnx_'):
cache.build()
sess = InferenceSession(cache.onnx_.SerializeToString())
return cache.onnx_, lambda x, y: sess.run(None, {'X0': x, 'X1': y})
def build_torch_decomposed(equation, op_version=14): # opset=13, 14, ...
cache = _einsum(equation, numpy.float32, opset=op_version,
optimize=True, verbose=True, runtime="python")
if not hasattr(cache, 'onnx_'):
cache.build()
sess = OnnxTorchRuntime(cache.onnx_)
return cache.onnx_, lambda x, y: sess.run(x, y)
def loop_einsum_eq(fct, equation, xs, ys):
for x, y in zip(xs, ys):
fct(equation, x, y)
def loop_einsum_eq_th(fct, equation, xs, ys):
for x, y in zip(xs, ys):
fct(equation, x, y, nthread=-1)
def loop_einsum(fct, xs, ys):
for x, y in zip(xs, ys):
fct(x, y)
def benchmark_equation(equation, number=5, repeat=3):
# equations
ort_einsum = build_ort_einsum(equation)
einsum_onnx, ort_einsum_decomposed = build_ort_decomposed(equation)
torch_onnx, ort_torch_decomposed = build_torch_decomposed(equation)
K, S, M, E = 16, 1024, 768, 64
C = S // E * 2
SIZE_MAP = {'K': K, 'S': S, 'E': E, 'C': C, 'M': M}
pos1 = equation.find(',')
pos2 = equation.find('->')
lhs_op = equation[0:pos1]
rhs_op = equation[pos1 + 1:pos2]
lhs_shape = []
for c in lhs_op:
lhs_shape.append(SIZE_MAP[c.upper()])
rhs_shape = []
for c in rhs_op:
rhs_shape.append(SIZE_MAP[c.upper()])
terms = equation.split('->')[0].split(',')
if 'e' in equation:
pos_left = terms[0].find('e')
pos_right = terms[1].find('e')
else:
pos_left = terms[0].find('k')
pos_right = terms[1].find('k')
def left_dim(dim):
if pos_left == -1:
return lhs_shape
cp = list(lhs_shape)
cp[pos_left] = dim
return tuple(cp)
def right_dim(dim):
if pos_right == -1:
return rhs_shape
cp = list(rhs_shape)
cp[pos_right] = dim
return tuple(cp)
sizes = [8, 16, 32, 64, 128, 256]
if max(len(rhs_shape), len(lhs_shape)) >= 3:
sizes = sizes[:4]
res = []
for dim in tqdm(sizes):
xs = [numpy.random.rand(*left_dim(dim)).astype(numpy.float32)
for _ in range(5)]
ys = [numpy.random.rand(*right_dim(dim)).astype(numpy.float32)
for _ in range(5)]
# numpy
ctx = dict(equation=equation, xs=xs, ys=ys, einsum=numpy.einsum,
loop_einsum=loop_einsum, loop_einsum_eq=loop_einsum_eq,
loop_einsum_eq_th=loop_einsum_eq_th)
obs = measure_time(
lambda: loop_einsum_eq(numpy.einsum, equation, xs, ys),
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'numpy.einsum'
res.append(obs)
# onnxruntime
ctx['einsum'] = ort_einsum
obs = measure_time(
lambda: loop_einsum(ort_einsum, xs, ys),
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'ort_einsum'
res.append(obs)
# onnxruntime decomposed
ctx['einsum'] = ort_einsum_decomposed
obs = measure_time(
lambda: loop_einsum(ort_einsum_decomposed, xs, ys),
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'ort_dec'
res.append(obs)
# torch decomposed
ctx['einsum'] = ort_torch_decomposed
ctx['xs'] = [from_numpy(x) for x in xs]
ctx['ys'] = [from_numpy(y) for y in ys]
obs = measure_time(
lambda: loop_einsum(ort_torch_decomposed, ctx['xs'], ctx['ys']),
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'torch_dec'
res.append(obs)
if torch_einsum is not None:
# torch
ctx['einsum'] = torch_einsum
obs = measure_time(
lambda: loop_einsum_eq(
torch_einsum, equation, ctx['xs'], ctx['ys']),
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'torch_einsum'
res.append(obs)
# Dataframes
df = pandas.DataFrame(res)
piv = df.pivot('dim', 'fct', 'average')
rs = piv.copy()
rs['ort_einsum'] = rs['numpy.einsum'] / rs['ort_einsum']
rs['ort_dec'] = rs['numpy.einsum'] / rs['ort_dec']
if 'torch_einsum' in rs.columns:
rs['torch_einsum'] = rs['numpy.einsum'] / rs['torch_einsum']
if 'torch_dec' in rs.columns:
rs['torch_dec'] = rs['numpy.einsum'] / rs['torch_dec']
rs['numpy.einsum'] = 1.
# Graphs.
shapes = ("%s - %s" % (left_dim('N'), right_dim('N'))).replace("'", "")
fig, ax = plt.subplots(1, 2, figsize=(14, 5))
piv.plot(logx=True, logy=True, ax=ax[0],
title="Einsum benchmark\n%s -- %s"
" lower better" % (shapes, equation))
ax[0].legend(prop={"size": 9})
rs.plot(logx=True, logy=True, ax=ax[1],
title="Einsum Speedup, baseline=numpy\n%s -- %s"
" higher better" % (shapes, equation))
ax[1].plot([min(rs.index), max(rs.index)], [0.5, 0.5], 'g--')
ax[1].plot([min(rs.index), max(rs.index)], [2., 2.], 'g--')
ax[1].legend(prop={"size": 9})
return df, rs, ax, einsum_onnx
A last function to plot the ONNX graphs.
def plot_onnx_einsum(equation, onx):
filename = "einsum_eq_%s.onnx" % (
equation.replace(",", "_").replace("->", "__"))
with open(filename, "wb") as f:
f.write(onx.SerializeToString())
fig, ax = plt.subplots(1, 1, figsize=(6, 6))
ax = plot_onnx(onx, ax=ax)
ax.set_title(equation)
return ax
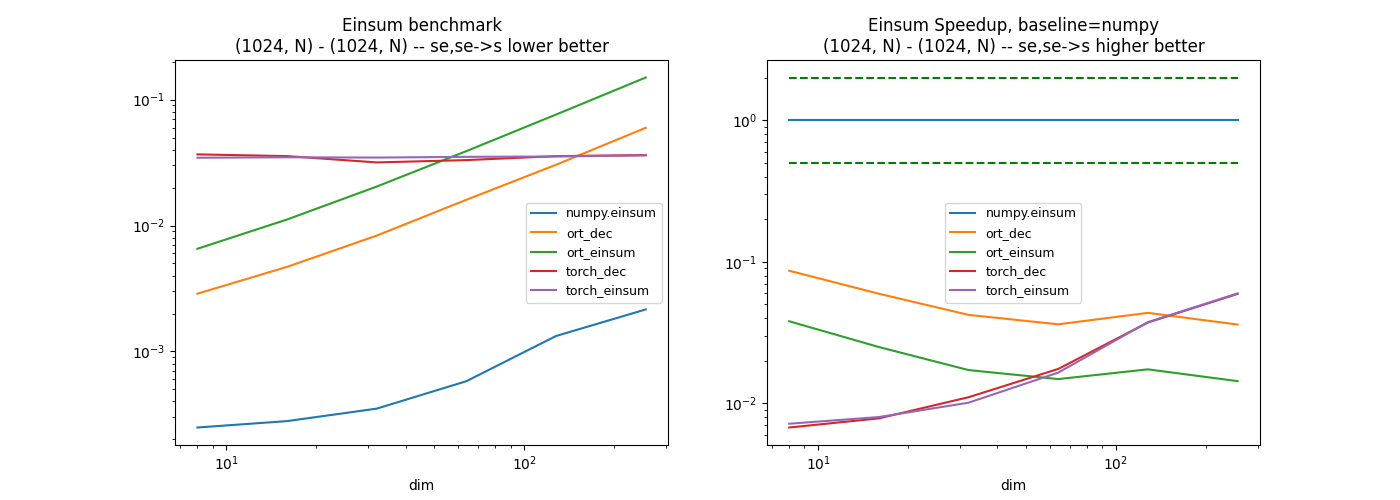
First equation: s,se->se#
dfs = []
equation = "s,se->se"
df, piv, ax, onx = benchmark_equation(equation)
df.pivot("fct", "dim", "average")
dfs.append(df)
df.pivot("dim", "fct", "average")
![Einsum benchmark [1024] - (1024, N) -- s,se->se lower better, Einsum Speedup, baseline=numpy [1024] - (1024, N) -- s,se->se higher better](../_images/sphx_glr_plot_op_einsum_001.png)
Out:
0%| | 0/3 [00:00<?, ?it/s]
0.0069 rtbest='s,se->se': 0%| | 0/3 [00:00<?, ?it/s]
0.0069 rtbest='s,se->se': 33%|###3 | 1/3 [00:00<00:01, 1.32it/s]
0.0069 rtbest='s,se->se': 100%|##########| 3/3 [00:00<00:00, 3.75it/s]
somewhere/workspace/deeponnxcustom/deeponnxcustom_UT_39_std/_doc/sphinxdoc/source/deeponnxcustom/onnxtorch/tchrun.py:173: UserWarning: The given NumPy array is not writable, and PyTorch does not support non-writable tensors. This means writing to this tensor will result in undefined behavior. You may want to copy the array to protect its data or make it writable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at ../torch/csrc/utils/tensor_numpy.cpp:178.)
res[init.name] = torch.from_numpy( # pylint: disable=E1101
0%| | 0/6 [00:00<?, ?it/s]
17%|#6 | 1/6 [00:00<00:02, 1.68it/s]
33%|###3 | 2/6 [00:01<00:02, 1.75it/s]
50%|##### | 3/6 [00:01<00:01, 1.67it/s]
67%|######6 | 4/6 [00:02<00:01, 1.20it/s]
83%|########3 | 5/6 [00:04<00:00, 1.02it/s]
100%|##########| 6/6 [00:05<00:00, 1.00it/s]
100%|##########| 6/6 [00:05<00:00, 1.14it/s]
The onnx decomposition.
plot_onnx_einsum(equation, onx)
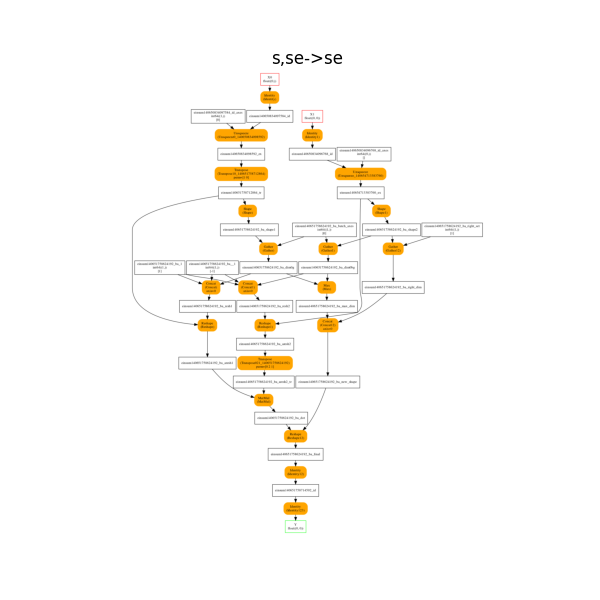
Out:
<AxesSubplot:title={'center':'s,se->se'}>
Second equation: se,sc->sec#
dfs = []
equation = "se,sc->sec"
df, piv, ax, onx = benchmark_equation(equation)
df.pivot("fct", "dim", "average")
dfs.append(df)
df.pivot("dim", "fct", "average")
![Einsum benchmark (1024, N) - [1024, 32] -- se,sc->sec lower better, Einsum Speedup, baseline=numpy (1024, N) - [1024, 32] -- se,sc->sec higher better](../_images/sphx_glr_plot_op_einsum_003.png)
Out:
0%| | 0/7 [00:00<?, ?it/s]
0.0083 rtbest='se,sc->sec': 0%| | 0/7 [00:00<?, ?it/s]
0.0082 rtbest='es,ec->esc': 0%| | 0/7 [00:00<?, ?it/s]
0.0082 rtbest='es,ec->esc': 57%|#####7 | 4/7 [00:00<00:00, 37.36it/s]
0.0081 rtbest='ec,es->ecs': 57%|#####7 | 4/7 [00:00<00:00, 37.36it/s]
0.0079 rtbest='cs,ce->cse': 57%|#####7 | 4/7 [00:00<00:00, 37.36it/s]
0.0079 rtbest='cs,ce->cse': 100%|##########| 7/7 [00:00<00:00, 38.92it/s]
0%| | 0/6 [00:00<?, ?it/s]
17%|#6 | 1/6 [00:01<00:05, 1.01s/it]
33%|###3 | 2/6 [00:02<00:05, 1.31s/it]
50%|##### | 3/6 [00:04<00:04, 1.54s/it]
67%|######6 | 4/6 [00:06<00:03, 1.94s/it]
83%|########3 | 5/6 [00:10<00:02, 2.66s/it]
100%|##########| 6/6 [00:20<00:00, 5.06s/it]
100%|##########| 6/6 [00:20<00:00, 3.42s/it]
The onnx decomposition.
plot_onnx_einsum(equation, onx)
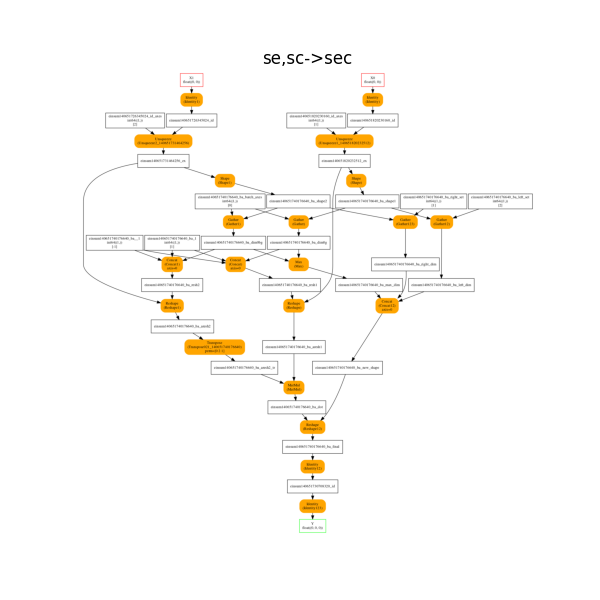
Out:
<AxesSubplot:title={'center':'se,sc->sec'}>
Third equation: se,se->s#
dfs = []
equation = "se,se->s"
df, piv, ax, onx = benchmark_equation(equation)
df.pivot("fct", "dim", "average")
dfs.append(df)
df.pivot("dim", "fct", "average")
Out:
0%| | 0/3 [00:00<?, ?it/s]
0.0076 rtbest='se,se->s': 0%| | 0/3 [00:00<?, ?it/s]
0.0076 rtbest='se,se->s': 100%|##########| 3/3 [00:00<00:00, 39.19it/s]
0%| | 0/6 [00:00<?, ?it/s]
17%|#6 | 1/6 [00:01<00:06, 1.22s/it]
33%|###3 | 2/6 [00:02<00:05, 1.27s/it]
50%|##### | 3/6 [00:03<00:04, 1.35s/it]
67%|######6 | 4/6 [00:05<00:03, 1.56s/it]
83%|########3 | 5/6 [00:08<00:01, 1.98s/it]
100%|##########| 6/6 [00:12<00:00, 2.78s/it]
100%|##########| 6/6 [00:12<00:00, 2.15s/it]
The onnx decomposition.
plot_onnx_einsum(equation, onx)
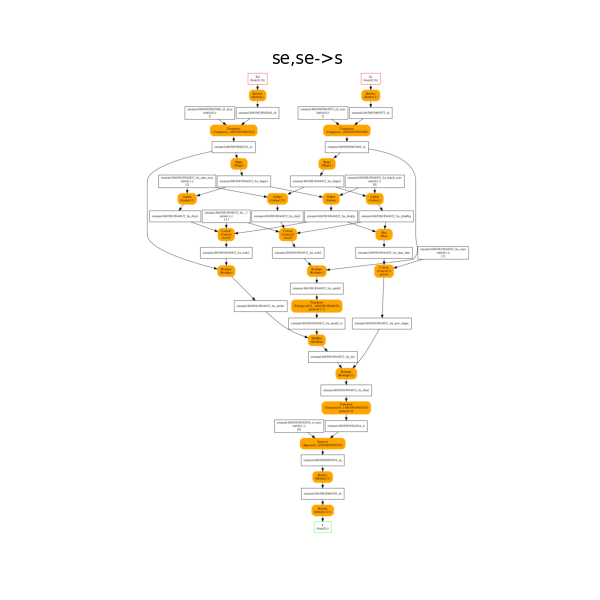
Out:
<AxesSubplot:title={'center':'se,se->s'}>
Fourth equation: ks,ksm->sm#
dfs = []
equation = "ks,ksm->sm"
df, piv, ax, onx = benchmark_equation(equation)
df.pivot("fct", "dim", "average")
dfs.append(df)
df.pivot("dim", "fct", "average")
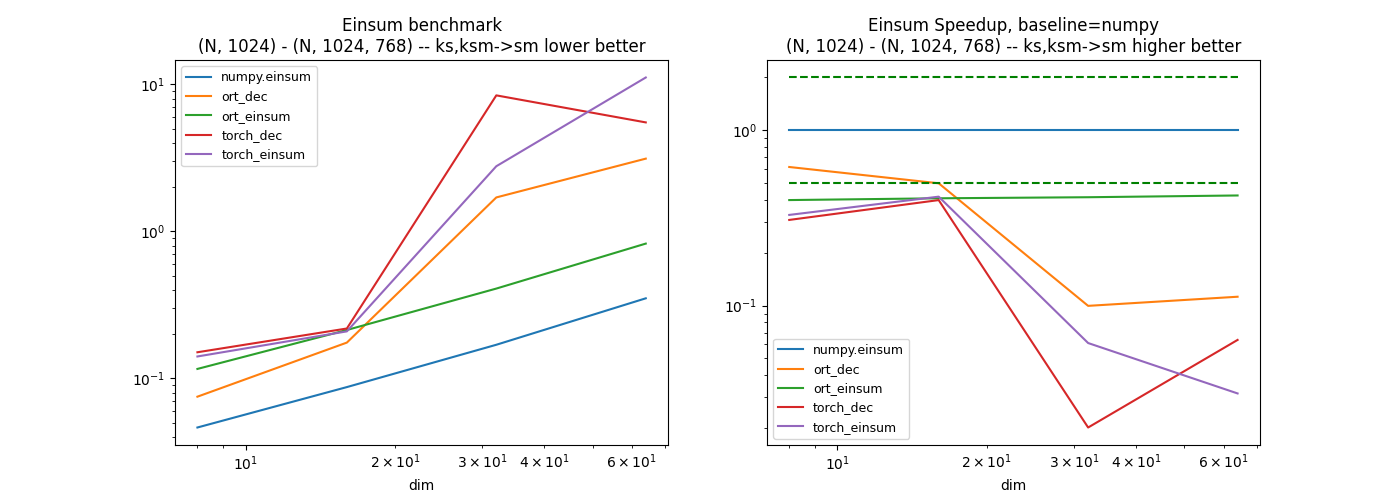
Out:
0%| | 0/7 [00:00<?, ?it/s]
0.009 rtbest='ks,ksm->sm': 0%| | 0/7 [00:00<?, ?it/s]
0.009 rtbest='km,kms->ms': 0%| | 0/7 [00:00<?, ?it/s]
0.009 rtbest='km,kms->ms': 57%|#####7 | 4/7 [00:00<00:00, 35.30it/s]
0.0089 rtbest='sm,smk->mk': 57%|#####7 | 4/7 [00:00<00:00, 35.30it/s]
0.0089 rtbest='sm,smk->mk': 100%|##########| 7/7 [00:00<00:00, 36.02it/s]
0%| | 0/4 [00:00<?, ?it/s]
25%|##5 | 1/4 [00:08<00:26, 8.80s/it]
50%|##### | 2/4 [00:24<00:25, 12.62s/it]
75%|#######5 | 3/4 [03:49<01:40, 100.71s/it]
100%|##########| 4/4 [09:12<00:00, 188.50s/it]
100%|##########| 4/4 [09:12<00:00, 138.17s/it]
The onnx decomposition.
plot_onnx_einsum(equation, onx)
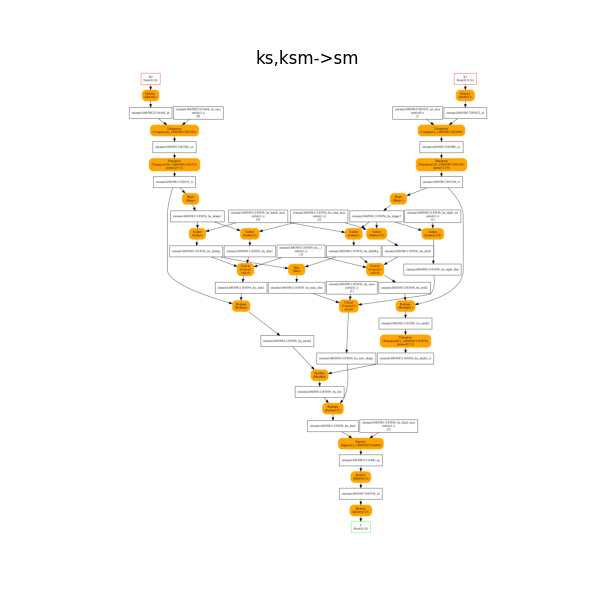
Out:
<AxesSubplot:title={'center':'ks,ksm->sm'}>
Fifth equation: sec,sm->ecm#
dfs = []
equation = "sec,sm->ecm"
df, piv, ax, onx = benchmark_equation(equation, number=1, repeat=1)
df.pivot("fct", "dim", "average")
dfs.append(df)
df.pivot("dim", "fct", "average")
![Einsum benchmark (1024, N, 32) - [1024, 768] -- sec,sm->ecm lower better, Einsum Speedup, baseline=numpy (1024, N, 32) - [1024, 768] -- sec,sm->ecm higher better](../_images/sphx_glr_plot_op_einsum_009.png)
Out:
0%| | 0/25 [00:00<?, ?it/s]
0.012 rtbest='sec,sm->ecm': 0%| | 0/25 [00:00<?, ?it/s]
0.0091 rtbest='sec,sm->ecm': 0%| | 0/25 [00:00<?, ?it/s]
0.0091 rtbest='sec,sm->ecm': 16%|#6 | 4/25 [00:00<00:00, 31.96it/s]
0.009 rtbest='esc,em->scm': 16%|#6 | 4/25 [00:00<00:00, 31.96it/s]
0.0087 rtbest='sce,sm->cem': 16%|#6 | 4/25 [00:00<00:00, 31.96it/s]
0.0087 rtbest='sce,sm->cem': 32%|###2 | 8/25 [00:00<00:00, 34.15it/s]
0.0087 rtbest='sce,sm->cem': 48%|####8 | 12/25 [00:00<00:00, 35.39it/s]
0.0087 rtbest='sem,sc->emc': 48%|####8 | 12/25 [00:00<00:00, 35.39it/s]
0.0087 rtbest='sem,sc->emc': 64%|######4 | 16/25 [00:00<00:00, 34.86it/s]
0.0087 rtbest='sem,sc->emc': 80%|######## | 20/25 [00:00<00:00, 35.38it/s]
0.0087 rtbest='sem,sc->emc': 96%|#########6| 24/25 [00:00<00:00, 35.92it/s]
0.0087 rtbest='sem,sc->emc': 100%|##########| 25/25 [00:00<00:00, 35.29it/s]
0%| | 0/4 [00:00<?, ?it/s]
25%|##5 | 1/4 [00:01<00:03, 1.20s/it]
50%|##### | 2/4 [00:04<00:04, 2.21s/it]
75%|#######5 | 3/4 [00:09<00:03, 3.85s/it]
100%|##########| 4/4 [00:21<00:00, 6.75s/it]
100%|##########| 4/4 [00:21<00:00, 5.28s/it]
The onnx decomposition.
plot_onnx_einsum(equation, onx)
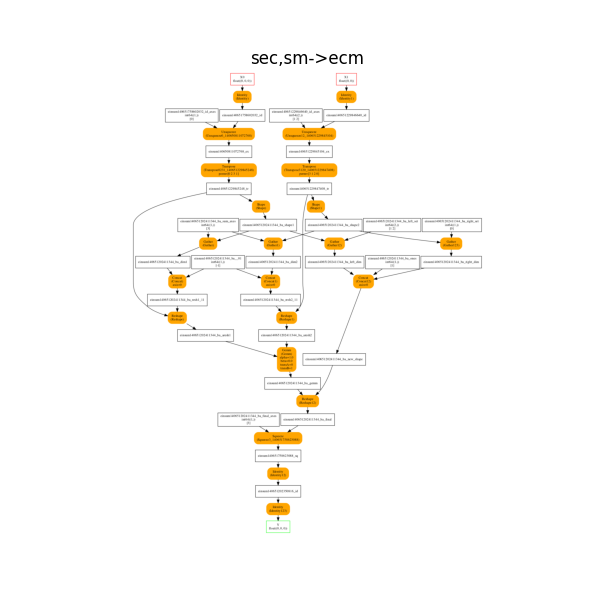
Out:
<AxesSubplot:title={'center':'sec,sm->ecm'}>
Sixth equation: sec,ecm->sm#
dfs = []
equation = "sec,ecm->sm"
df, piv, ax, onx = benchmark_equation(equation, number=1, repeat=1)
df.pivot("fct", "dim", "average")
dfs.append(df)
df.pivot("dim", "fct", "average")

Out:
0%| | 0/25 [00:00<?, ?it/s]
0.0098 rtbest='sec,ecm->sm': 0%| | 0/25 [00:00<?, ?it/s]
0.0098 rtbest='sec,ecm->sm': 16%|#6 | 4/25 [00:00<00:00, 31.93it/s]
0.0097 rtbest='sce,cem->sm': 16%|#6 | 4/25 [00:00<00:00, 31.93it/s]
0.0097 rtbest='sce,cem->sm': 32%|###2 | 8/25 [00:00<00:00, 32.63it/s]
0.0097 rtbest='mcs,cse->me': 32%|###2 | 8/25 [00:00<00:00, 32.63it/s]
0.0097 rtbest='mcs,cse->me': 48%|####8 | 12/25 [00:00<00:00, 33.26it/s]
0.0096 rtbest='ecs,csm->em': 48%|####8 | 12/25 [00:00<00:00, 33.26it/s]
0.0095 rtbest='sem,emc->sc': 48%|####8 | 12/25 [00:00<00:00, 33.26it/s]
0.0095 rtbest='sem,emc->sc': 64%|######4 | 16/25 [00:00<00:00, 32.73it/s]
0.0095 rtbest='mes,esc->mc': 64%|######4 | 16/25 [00:00<00:00, 32.73it/s]
0.0093 rtbest='ems,msc->ec': 64%|######4 | 16/25 [00:00<00:00, 32.73it/s]
0.0093 rtbest='ems,msc->ec': 80%|######## | 20/25 [00:00<00:00, 33.41it/s]
0.0093 rtbest='ems,msc->ec': 96%|#########6| 24/25 [00:00<00:00, 33.96it/s]
0.0093 rtbest='ems,msc->ec': 100%|##########| 25/25 [00:00<00:00, 33.53it/s]
0%| | 0/4 [00:00<?, ?it/s]
25%|##5 | 1/4 [00:01<00:03, 1.15s/it]
50%|##### | 2/4 [00:03<00:03, 1.91s/it]
75%|#######5 | 3/4 [00:08<00:03, 3.18s/it]
100%|##########| 4/4 [00:17<00:00, 5.74s/it]
100%|##########| 4/4 [00:17<00:00, 4.49s/it]
The onnx decomposition.
plot_onnx_einsum(equation, onx)
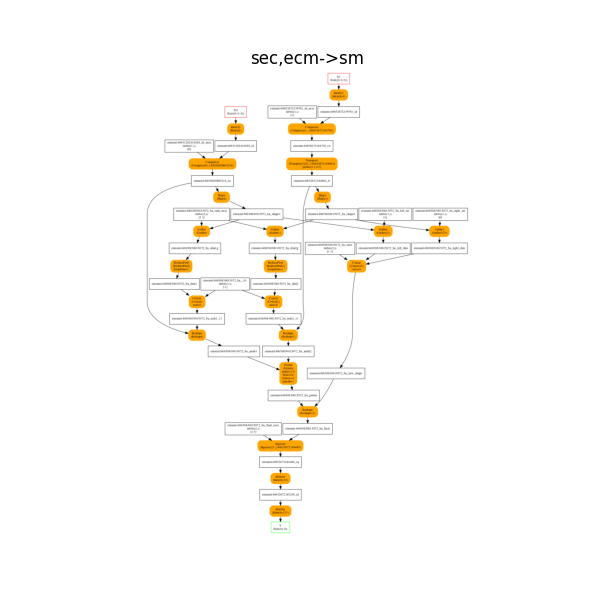
Out:
<AxesSubplot:title={'center':'sec,ecm->sm'}>
Conclusion#
pytorch seems quite efficient on these examples.
merged = pandas.concat(dfs)
name = "einsum"
merged.to_csv("plot_%s.csv" % name, index=False)
merged.to_excel("plot_%s.xlsx" % name, index=False)
plt.savefig("plot_%s.png" % name)
# plt.show()

Total running time of the script: ( 10 minutes 55.111 seconds)