Note
Click here to download the full example code
Pytorch and onnxruntime#
This example compares the training between pytorch and ORTModule.
Functions#
The first function creates the neural network.
import time
import copy
import numpy
import onnx # noqa
from pandas import DataFrame
from onnxruntime import get_device
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from mlprodict.plotting.plotting_onnx import plot_onnx
from tqdm import tqdm
import torch
import torch.nn.functional as F
from onnxruntime.training import ORTModule
from deeponnxcustom.tools.onnx_helper import save_as_onnx
def from_numpy(v, device=None, requires_grad=False):
"""
Convers a numpy array into a torch array and
sets *device* and *requires_grad*.
"""
v = torch.from_numpy(v)
if device is not None:
v = v.to(device)
v.requires_grad_(requires_grad)
return v
def build_class_model():
class CustomNet(torch.nn.Module):
def __init__(self, n_features, hidden_layer_sizes, n_output):
super(CustomNet, self).__init__()
self.hidden = []
size = n_features
for i, hid in enumerate(hidden_layer_sizes):
self.hidden.append(torch.nn.Linear(size, hid))
size = hid
setattr(self, "hid%d" % i, self.hidden[-1])
self.hidden.append(torch.nn.Linear(size, n_output))
setattr(self, "predict", self.hidden[-1])
def forward(self, x):
for hid in self.hidden:
x = hid(x)
x = F.relu(x)
return x
return CustomNet
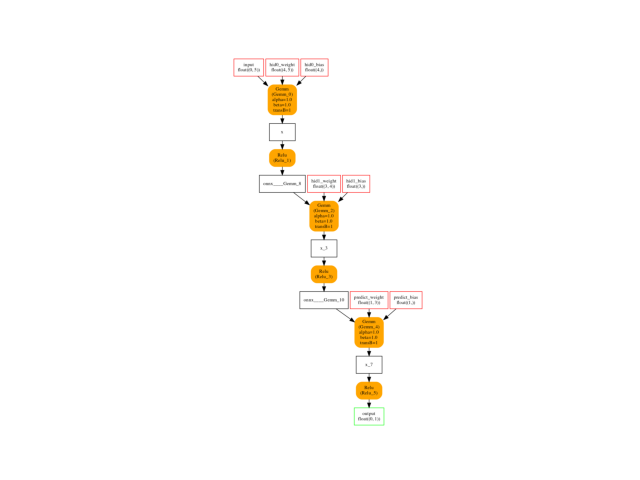
cls = build_class_model()
model = cls(5, (4, 3), 1)
save_as_onnx(model, "plot_ortmodule.onnx", 5)
plot_onnx("plot_ortmodule.onnx", temp_dot="plot_ortmodule.dot")
Out:
<AxesSubplot:>
Training#
The function train_model works with a torch.nn.Module and
ORTModule.
def train_model(nn, X_train, y_train, max_iter=25,
learning_rate_init=1e-5, batch_size=10,
device='cpu', opset=12, verbose=False,
use_ortmodule=False):
"""
Compares :epkg:`onnxruntime-training` to :epkg:`scikit-learn` for
training. Training algorithm is SGD.
:param nn: model to train
:param max_iter: number of iterations
:param learning_rate_init: initial learning rate
:param batch_size: batch size
:param device: `'cpu'` or `'cuda'`
:param opset: opset to choose for the conversion
:param use_ortmodule: use :epkg:`ORTModule`
:param verbose: displays intermediate information
"""
max_iter = int(max_iter)
learning_rate_init = float(learning_rate_init)
batch_size = int(batch_size)
if verbose:
print("N=%d" % N)
print("n_features=%d" % n_features)
print("hidden_layer_sizes=%r" % (hidden_layer_sizes, ))
print("max_iter=%d" % max_iter)
print("learning_rate_init=%f" % learning_rate_init)
print("batch_size=%d" % batch_size)
print("opset=%r (unused)" % opset)
print("device=%r" % device)
device0 = device
device = torch.device(
"cuda:0" if device in ('cuda', 'cuda:0', 'gpu') else "cpu")
if verbose:
print("fixed device=%r" % device)
print('------------------')
if device0 == 'cpu':
nn.cpu()
else:
nn.cuda(device=device)
if verbose:
print("n_parameters=%d, n_layers=%d" % (
len(list(nn.parameters())), len(nn.hidden)))
for i, p in enumerate(nn.parameters()):
print(" p[%d].shape=%r" % (i, p.shape))
if use_ortmodule:
nn = ORTModule(nn)
optimizer = torch.optim.SGD(nn.parameters(), lr=learning_rate_init)
criterion = torch.nn.MSELoss(size_average=False)
batch_no = X_train.shape[0] // batch_size
# training
inputs = torch.tensor(
X_train[:1], requires_grad=True, device=device)
nn(inputs)
def train_torch():
if verbose:
loop = tqdm(range(max_iter))
else:
loop = range(max_iter)
losses = []
for epoch in loop:
running_loss = 0.0
x, y = shuffle(X_train, y_train)
for i in range(batch_no):
start = i * batch_size
end = start + batch_size
inputs = torch.tensor(
x[start:end], requires_grad=True, device=device)
labels = torch.tensor(
y[start:end], requires_grad=True, device=device)
def step_torch():
optimizer.zero_grad()
outputs = nn(inputs)
loss = criterion(outputs, torch.unsqueeze(labels, dim=1))
loss.backward()
optimizer.step()
return loss
loss = step_torch()
running_loss += loss.item()
losses.append(running_loss / X_train.shape[0])
return losses
begin = time.perf_counter()
losses = train_torch()
dur = time.perf_counter() - begin
if verbose:
print("time_torch=%r, running_loss=%r" % (dur, losses[-1]))
return nn, losses, dur
Some data.
N = 1000
n_features = 5
X, y = make_regression(N, n_features=n_features, bias=2)
X = X.astype(numpy.float32)
y = y.astype(numpy.float32)
X_train, X_test, y_train, y_test = train_test_split(X, y)
And one model
hidden_layer_sizes = (5, 3)
cls_net = build_class_model()
nn = cls_net(n_features, hidden_layer_sizes, 1)
Training with pytorch#
device = "cuda" if get_device() == 'GPU' else 'cpu'
t_x_train = from_numpy(X_train, device=device)
t_y_train = from_numpy(y_train, device=device)
trained_nn_tch, losses_tch, duration = train_model(
copy.deepcopy(nn), t_x_train, t_y_train, verbose=True,
device=device, learning_rate_init=1e-4)
print("Torch, %d iterations, final loss=%f, duration=%f" % (
len(losses_tch), losses_tch[-1], duration))
print('type(trained_nn_tch):', type(trained_nn_tch))
Out:
N=1000
n_features=5
hidden_layer_sizes=(5, 3)
max_iter=25
learning_rate_init=0.000100
batch_size=10
opset=12 (unused)
device='cpu'
fixed device=device(type='cpu')
------------------
n_parameters=6, n_layers=3
p[0].shape=torch.Size([5, 5])
p[1].shape=torch.Size([5])
p[2].shape=torch.Size([3, 5])
p[3].shape=torch.Size([3])
p[4].shape=torch.Size([1, 3])
p[5].shape=torch.Size([1])
somewhere/workspace/deeponnxcustom/deeponnxcustom_UT_39_std/_venv/lib/python3.9/site-packages/torch/nn/_reduction.py:42: UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead.
warnings.warn(warning.format(ret))
somewhere/workspace/deeponnxcustom/deeponnxcustom_UT_39_std/_doc/examples/plot_ortmodule.py:143: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
inputs = torch.tensor(
0%| | 0/25 [00:00<?, ?it/s]somewhere/workspace/deeponnxcustom/deeponnxcustom_UT_39_std/_doc/examples/plot_ortmodule.py:160: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
inputs = torch.tensor(
somewhere/workspace/deeponnxcustom/deeponnxcustom_UT_39_std/_doc/examples/plot_ortmodule.py:162: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
labels = torch.tensor(
4%|4 | 1/25 [00:00<00:03, 6.06it/s]
8%|8 | 2/25 [00:00<00:03, 6.21it/s]
12%|#2 | 3/25 [00:00<00:03, 6.18it/s]
16%|#6 | 4/25 [00:00<00:03, 6.19it/s]
20%|## | 5/25 [00:00<00:03, 6.23it/s]
24%|##4 | 6/25 [00:00<00:03, 6.25it/s]
28%|##8 | 7/25 [00:01<00:02, 6.27it/s]
32%|###2 | 8/25 [00:01<00:02, 6.24it/s]
36%|###6 | 9/25 [00:01<00:02, 6.23it/s]
40%|#### | 10/25 [00:01<00:02, 6.26it/s]
44%|####4 | 11/25 [00:01<00:02, 6.24it/s]
48%|####8 | 12/25 [00:01<00:02, 6.22it/s]
52%|#####2 | 13/25 [00:02<00:01, 6.22it/s]
56%|#####6 | 14/25 [00:02<00:01, 6.21it/s]
60%|###### | 15/25 [00:02<00:01, 6.21it/s]
64%|######4 | 16/25 [00:02<00:01, 6.25it/s]
68%|######8 | 17/25 [00:02<00:01, 6.23it/s]
72%|#######2 | 18/25 [00:02<00:01, 6.22it/s]
76%|#######6 | 19/25 [00:03<00:00, 6.25it/s]
80%|######## | 20/25 [00:03<00:00, 6.27it/s]
84%|########4 | 21/25 [00:03<00:00, 6.25it/s]
88%|########8 | 22/25 [00:03<00:00, 6.23it/s]
92%|#########2| 23/25 [00:03<00:00, 6.26it/s]
96%|#########6| 24/25 [00:03<00:00, 6.28it/s]
100%|##########| 25/25 [00:04<00:00, 6.29it/s]
100%|##########| 25/25 [00:04<00:00, 6.24it/s]
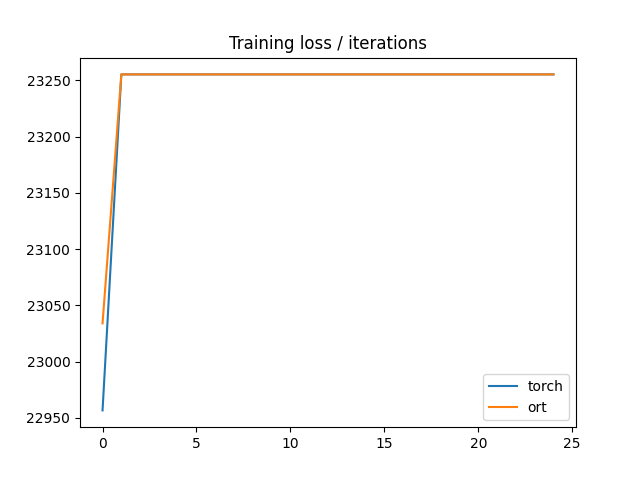
time_torch=4.009416713990504, running_loss=23255.341375
Torch, 25 iterations, final loss=23255.341375, duration=4.009417
type(trained_nn_tch): <class '__main__.build_class_model.<locals>.CustomNet'>
Training with ORTModule#
trained_nn_ort, losses_ort, duration = train_model(
copy.deepcopy(nn), X_train, y_train, verbose=True,
device=device, learning_rate_init=1e-4, use_ortmodule=True)
print("ORT, %d iterations, final loss=%f, duration=%f" % (
len(losses_ort), losses_ort[-1], duration))
print('type(trained_nn_ort):', type(trained_nn_ort))
Out:
N=1000
n_features=5
hidden_layer_sizes=(5, 3)
max_iter=25
learning_rate_init=0.000100
batch_size=10
opset=12 (unused)
device='cpu'
fixed device=device(type='cpu')
------------------
n_parameters=6, n_layers=3
p[0].shape=torch.Size([5, 5])
p[1].shape=torch.Size([5])
p[2].shape=torch.Size([3, 5])
p[3].shape=torch.Size([3])
p[4].shape=torch.Size([1, 3])
p[5].shape=torch.Size([1])
somewhere/workspace/deeponnxcustom/deeponnxcustom_UT_39_std/_venv/lib/python3.9/site-packages/torch/nn/_reduction.py:42: UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead.
warnings.warn(warning.format(ret))
somewhere/workspace/deeponnxcustom/deeponnxcustom_UT_39_std/_venv/lib/python3.9/site-packages/onnxruntime/training/ortmodule/_training_manager.py:190: UserWarning: Fast path enabled - skipping checks. Rebuild graph: True, Execution agent: True, Device check: True
warnings.warn(
0%| | 0/25 [00:00<?, ?it/s]
4%|4 | 1/25 [00:00<00:04, 5.32it/s]
8%|8 | 2/25 [00:00<00:04, 5.46it/s]
12%|#2 | 3/25 [00:00<00:03, 5.51it/s]
16%|#6 | 4/25 [00:00<00:03, 5.52it/s]
20%|## | 5/25 [00:00<00:03, 5.53it/s]
24%|##4 | 6/25 [00:01<00:03, 5.54it/s]
28%|##8 | 7/25 [00:01<00:03, 5.55it/s]
32%|###2 | 8/25 [00:01<00:03, 5.56it/s]
36%|###6 | 9/25 [00:01<00:02, 5.57it/s]
40%|#### | 10/25 [00:01<00:02, 5.57it/s]
44%|####4 | 11/25 [00:01<00:02, 5.58it/s]
48%|####8 | 12/25 [00:02<00:02, 5.59it/s]
52%|#####2 | 13/25 [00:02<00:02, 5.59it/s]
56%|#####6 | 14/25 [00:02<00:01, 5.59it/s]
60%|###### | 15/25 [00:02<00:01, 5.59it/s]
64%|######4 | 16/25 [00:02<00:01, 5.60it/s]
68%|######8 | 17/25 [00:03<00:01, 5.60it/s]
72%|#######2 | 18/25 [00:03<00:01, 5.60it/s]
76%|#######6 | 19/25 [00:03<00:01, 5.61it/s]
80%|######## | 20/25 [00:03<00:00, 5.61it/s]
84%|########4 | 21/25 [00:03<00:00, 5.61it/s]
88%|########8 | 22/25 [00:03<00:00, 5.61it/s]
92%|#########2| 23/25 [00:04<00:00, 5.61it/s]
96%|#########6| 24/25 [00:04<00:00, 5.61it/s]
100%|##########| 25/25 [00:04<00:00, 5.60it/s]
100%|##########| 25/25 [00:04<00:00, 5.58it/s]
time_torch=4.484404376999009, running_loss=23255.341333333334
ORT, 25 iterations, final loss=23255.341333, duration=4.484404
type(trained_nn_ort): <class 'onnxruntime.training.ortmodule.ortmodule.ORTModule'>
Visualisation#
df = DataFrame(dict(torch=losses_tch, ort=losses_ort))
df.plot(title="Training loss / iterations")
Out:
<AxesSubplot:title={'center':'Training loss / iterations'}>
Performance#
N = X_test.shape[0]
t_x_test = from_numpy(X_test, device=device)
t_y_test = from_numpy(y_test, device=device)
pred_tch = trained_nn_tch(t_x_test)
pred_ort = trained_nn_ort(t_x_test)
error_tch = ((pred_tch.ravel() - t_y_test.ravel()) ** 2).sum() / N
error_ort = ((pred_ort.ravel() - t_y_test.ravel()) ** 2).sum() / N
print("error torch: %f" % error_tch)
print("error ort: %f" % error_ort)
# import matplotlib.pyplot as plt
# plt.show()
Out:
error torch: 23460.455078
error ort: 23460.455078
Total running time of the script: ( 0 minutes 10.295 seconds)