Note
Click here to download the full example code
Benchmark Random Forests, Tree Ensemble#
The following script benchmarks different libraries implementing random forests and boosting trees. This benchmark can be replicated by installing the following packages:
python -m virtualenv env
cd env
pip install -i https://test.pypi.org/simple/ ort-nightly
pip install git+https://github.com/microsoft/onnxconverter-common.git@jenkins
pip install git+https://https://github.com/xadupre/sklearn-onnx.git@jenkins
pip install mlprodict matplotlib scikit-learn pandas threadpoolctl
pip install mlprodict lightgbm xgboost jinja2
Import#
import os
import pickle
from pprint import pprint
import numpy
import pandas
import matplotlib.pyplot as plt
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from onnxruntime import InferenceSession
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
from skl2onnx import to_onnx
from mlprodict.onnx_conv import register_converters
from mlprodict.onnxrt.validate.validate_helper import measure_time
from mlprodict.onnxrt import OnnxInference
Registers new converters for sklearn-onnx.
register_converters()
[<class 'lightgbm.sklearn.LGBMClassifier'>, <class 'lightgbm.sklearn.LGBMRegressor'>, <class 'lightgbm.basic.Booster'>, <class 'mlprodict.onnx_conv.operator_converters.parse_lightgbm.WrappedLightGbmBooster'>, <class 'mlprodict.onnx_conv.operator_converters.parse_lightgbm.WrappedLightGbmBoosterClassifier'>, <class 'xgboost.sklearn.XGBClassifier'>, <class 'xgboost.sklearn.XGBRegressor'>, <class 'mlinsights.mlmodel.transfer_transformer.TransferTransformer'>, <class 'skl2onnx.sklapi.woe_transformer.WOETransformer'>, <class 'mlprodict.onnx_conv.scorers.register.CustomScorerTransform'>]
Problem#
max_depth = 7
n_classes = 20
n_estimators = 500
n_features = 100
REPEAT = 3
NUMBER = 1
train, test = 1000, 10000
print('dataset')
X_, y_ = make_classification(n_samples=train + test, n_features=n_features,
n_classes=n_classes, n_informative=n_features - 3)
X_ = X_.astype(numpy.float32)
y_ = y_.astype(numpy.int64)
X_train, X_test = X_[:train], X_[train:]
y_train, y_test = y_[:train], y_[train:]
compilation = []
def train_cache(model, X_train, y_train, max_depth, n_estimators, n_classes):
name = "cache-{}-N{}-f{}-d{}-e{}-cl{}.pkl".format(
model.__class__.__name__, X_train.shape[0], X_train.shape[1],
max_depth, n_estimators, n_classes)
if os.path.exists(name):
with open(name, 'rb') as f:
return pickle.load(f)
else:
model.fit(X_train, y_train)
with open(name, 'wb') as f:
pickle.dump(model, f)
return model
dataset
RandomForestClassifier#
rf = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth)
print('train')
rf = train_cache(rf, X_train, y_train, max_depth, n_estimators, n_classes)
res = measure_time(rf.predict_proba, X_test[:10],
repeat=REPEAT, number=NUMBER,
div_by_number=True, first_run=True)
res['model'], res['runtime'] = rf.__class__.__name__, 'INNER'
pprint(res)
train
{'average': 0.18799911063009253,
'context_size': 64,
'deviation': 0.00019205890410295198,
'max_exec': 0.18824125092942268,
'min_exec': 0.18777147599030286,
'model': 'RandomForestClassifier',
'number': 1,
'repeat': 3,
'runtime': 'INNER',
'ttime': 0.5639973318902776}
ONNX#
def measure_onnx_runtime(model, xt, repeat=REPEAT, number=NUMBER,
verbose=True):
if verbose:
print(model.__class__.__name__)
res = measure_time(model.predict_proba, xt,
repeat=repeat, number=number,
div_by_number=True, first_run=True)
res['model'], res['runtime'] = model.__class__.__name__, 'INNER'
res['N'] = X_test.shape[0]
res["max_depth"] = max_depth
res["n_estimators"] = n_estimators
res["n_features"] = n_features
if verbose:
pprint(res)
yield res
onx = to_onnx(model, X_train[:1], options={id(model): {'zipmap': False}})
oinf = OnnxInference(onx)
res = measure_time(lambda x: oinf.run({'X': x}), xt,
repeat=repeat, number=number,
div_by_number=True, first_run=True)
res['model'], res['runtime'] = model.__class__.__name__, 'NPY/C++'
res['N'] = X_test.shape[0]
res['size'] = len(onx.SerializeToString())
res["max_depth"] = max_depth
res["n_estimators"] = n_estimators
res["n_features"] = n_features
if verbose:
pprint(res)
yield res
sess = InferenceSession(onx.SerializeToString())
res = measure_time(lambda x: sess.run(None, {'X': x}), xt,
repeat=repeat, number=number,
div_by_number=True, first_run=True)
res['model'], res['runtime'] = model.__class__.__name__, 'ORT'
res['N'] = X_test.shape[0]
res['size'] = len(onx.SerializeToString())
res["max_depth"] = max_depth
res["n_estimators"] = n_estimators
res["n_features"] = n_features
if verbose:
pprint(res)
yield res
compilation.extend(list(measure_onnx_runtime(rf, X_test)))
RandomForestClassifier
{'N': 10000,
'average': 2.98249512394735,
'context_size': 64,
'deviation': 0.0033711611917959868,
'max_depth': 7,
'max_exec': 2.9852141889277846,
'min_exec': 2.9777441159822047,
'model': 'RandomForestClassifier',
'n_estimators': 500,
'n_features': 100,
'number': 1,
'repeat': 3,
'runtime': 'INNER',
'ttime': 8.947485371842049}
{'N': 10000,
'average': 0.24357830135462186,
'context_size': 64,
'deviation': 0.007513913882899251,
'max_depth': 7,
'max_exec': 0.25021481595467776,
'min_exec': 0.23307284305337816,
'model': 'RandomForestClassifier',
'n_estimators': 500,
'n_features': 100,
'number': 1,
'repeat': 3,
'runtime': 'NPY/C++',
'size': 7584960,
'ttime': 0.7307349040638655}
{'N': 10000,
'average': 0.28693250733582926,
'context_size': 64,
'deviation': 0.0037643991047396188,
'max_depth': 7,
'max_exec': 0.29222403606399894,
'min_exec': 0.28378093300852925,
'model': 'RandomForestClassifier',
'n_estimators': 500,
'n_features': 100,
'number': 1,
'repeat': 3,
'runtime': 'ORT',
'size': 7584960,
'ttime': 0.8607975220074877}
HistGradientBoostingClassifier#
hist = HistGradientBoostingClassifier(
max_iter=n_estimators, max_depth=max_depth)
print('train')
hist = train_cache(hist, X_train, y_train, max_depth, n_estimators, n_classes)
compilation.extend(list(measure_onnx_runtime(hist, X_test)))
train
HistGradientBoostingClassifier
{'N': 10000,
'average': 85.22884982603136,
'context_size': 64,
'deviation': 28.82167033871818,
'max_depth': 7,
'max_exec': 108.58795283397194,
'min_exec': 44.62185025506187,
'model': 'HistGradientBoostingClassifier',
'n_estimators': 500,
'n_features': 100,
'number': 1,
'repeat': 3,
'runtime': 'INNER',
'ttime': 255.6865494780941}
{'N': 10000,
'average': 2.6698374029947445,
'context_size': 64,
'deviation': 0.06269689676625119,
'max_depth': 7,
'max_exec': 2.733909153030254,
'min_exec': 2.5847217820119113,
'model': 'HistGradientBoostingClassifier',
'n_estimators': 500,
'n_features': 100,
'number': 1,
'repeat': 3,
'runtime': 'NPY/C++',
'size': 4209867,
'ttime': 8.009512208984233}
{'N': 10000,
'average': 3.570415847663147,
'context_size': 64,
'deviation': 0.015217666555225818,
'max_depth': 7,
'max_exec': 3.5916835670359433,
'min_exec': 3.5569308219710365,
'model': 'HistGradientBoostingClassifier',
'n_estimators': 500,
'n_features': 100,
'number': 1,
'repeat': 3,
'runtime': 'ORT',
'size': 4209867,
'ttime': 10.71124754298944}
LightGBM#
lgb = LGBMClassifier(n_estimators=n_estimators,
max_depth=max_depth, pred_early_stop=False)
print('train')
lgb = train_cache(lgb, X_train, y_train, max_depth, n_estimators, n_classes)
compilation.extend(list(measure_onnx_runtime(lgb, X_test)))
train
LGBMClassifier
{'N': 10000,
'average': 5.831168214286056,
'context_size': 64,
'deviation': 0.27501433476724213,
'max_depth': 7,
'max_exec': 6.218533685896546,
'min_exec': 5.607313968008384,
'model': 'LGBMClassifier',
'n_estimators': 500,
'n_features': 100,
'number': 1,
'repeat': 3,
'runtime': 'INNER',
'ttime': 17.49350464285817}
{'N': 10000,
'average': 2.5389815070278323,
'context_size': 64,
'deviation': 0.08075870466112009,
'max_depth': 7,
'max_exec': 2.6443328809691593,
'min_exec': 2.4481119910487905,
'model': 'LGBMClassifier',
'n_estimators': 500,
'n_features': 100,
'number': 1,
'repeat': 3,
'runtime': 'NPY/C++',
'size': 4379909,
'ttime': 7.6169445210834965}
{'N': 10000,
'average': 3.6518890756803253,
'context_size': 64,
'deviation': 0.061455764062153626,
'max_depth': 7,
'max_exec': 3.7236981639871374,
'min_exec': 3.573583971010521,
'model': 'LGBMClassifier',
'n_estimators': 500,
'n_features': 100,
'number': 1,
'repeat': 3,
'runtime': 'ORT',
'size': 4379909,
'ttime': 10.955667227040976}
XGBoost#
xgb = XGBClassifier(n_estimators=n_estimators, max_depth=max_depth)
print('train')
xgb = train_cache(xgb, X_train, y_train, max_depth, n_estimators, n_classes)
compilation.extend(list(measure_onnx_runtime(xgb, X_test)))
train
XGBClassifier
{'N': 10000,
'average': 0.25692815830310184,
'context_size': 64,
'deviation': 0.0039055194336706208,
'max_depth': 7,
'max_exec': 0.2622134640114382,
'min_exec': 0.2528966999379918,
'model': 'XGBClassifier',
'n_estimators': 500,
'n_features': 100,
'number': 1,
'repeat': 3,
'runtime': 'INNER',
'ttime': 0.7707844749093056}
{'N': 10000,
'average': 2.2041568466229364,
'context_size': 64,
'deviation': 0.0357332566951394,
'max_depth': 7,
'max_exec': 2.249848361941986,
'min_exec': 2.1626158349681646,
'model': 'XGBClassifier',
'n_estimators': 500,
'n_features': 100,
'number': 1,
'repeat': 3,
'runtime': 'NPY/C++',
'size': 1459429,
'ttime': 6.612470539868809}
{'N': 10000,
'average': 3.524398478718164,
'context_size': 64,
'deviation': 0.0011338089516868518,
'max_depth': 7,
'max_exec': 3.525900510023348,
'min_exec': 3.523161448072642,
'model': 'XGBClassifier',
'n_estimators': 500,
'n_features': 100,
'number': 1,
'repeat': 3,
'runtime': 'ORT',
'size': 1459429,
'ttime': 10.573195436154492}
Summary#
All data
name = 'plot_time_tree_ensemble'
df = pandas.DataFrame(compilation)
df.to_csv(f'{name}.csv', index=False)
df.to_excel(f'{name}.xlsx', index=False)
df
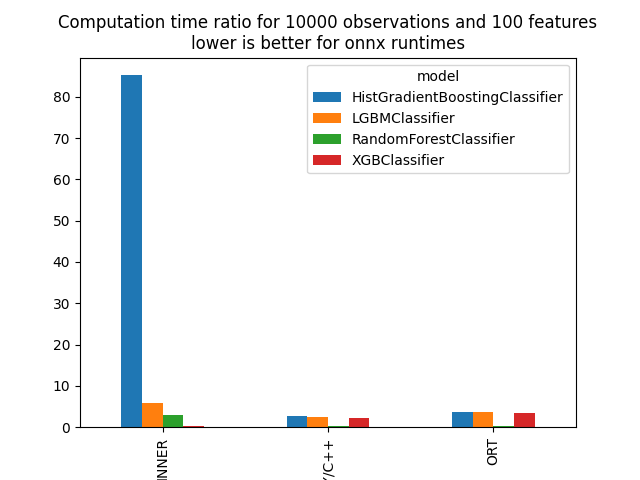
Time per model and runtime.
piv = df.pivot("model", "runtime", "average")
piv
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_time_tree_ensemble.py:201: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
piv = df.pivot("model", "runtime", "average")
Graphs.
ax = piv.T.plot(kind="bar")
ax.set_title("Computation time ratio for %d observations and %d features\n"
"lower is better for onnx runtimes" % X_test.shape)
plt.savefig(f'{name}.png')
Available optimisation on this machine:
from mlprodict.testing.experimental_c_impl.experimental_c import code_optimisation
print(code_optimisation())
plt.show()
AVX-omp=8
Total running time of the script: ( 56 minutes 41.300 seconds)