Confidence Interval and p-Value#
This document explains the relationship between p-value and confidence intervals. It goes on with the specific case of a binamial law. Assuming we want to determine whether or not two binomial laws are significantly different, how many observations we need to get the p-value under a given threshold.
Introduction#
The term p-value is very popular in the world of search engines. I usually prefer confidence interval 95%, I think it is easier to understand. Plus, because p-Value are real values, we could be tempted to compare them and it is usually wrong. On the other hand, it is more difficult to compare confidence intervals, especially if they are related to complete different variables. Their nature prevents you from doing that. Howerver p-Values and confidence interval are similar: they tell you whether or not a metric difference is significant.
Usually, it starts from a set of identically distributed random variables
 . We then estimate the average
. We then estimate the average
 and we ask
the question is
and we ask
the question is  null? In others terms, we
want to know if the average is significantly different from zero. If
the random variable
null? In others terms, we
want to know if the average is significantly different from zero. If
the random variable  follows a random law which has a standard
deviation, we can use the central limit theorem
which tells us:
follows a random law which has a standard
deviation, we can use the central limit theorem
which tells us:

Not all of them have a standard deviation. For example, if follows a
Cauchy law,
 which does not exist.
This remark also concerns every distribution known as heavy tail distribution.
which does not exist.
This remark also concerns every distribution known as heavy tail distribution.
If  , then we have
, then we have
 . That is why we can say:
. That is why we can say:

And the confidence intervalle at 95% would be:

When  , it becomes:
, it becomes:

We usually want to check if the mean is equal to a specific value using a statistical test:

We validate  if:
if:

p-value#
With confidence intervals, you first choose a confidence level and then you get an interval. You then check if your value is inside or outside your interval. Inside, the gain is not significant, outside, it is.
With a p-value, we consider the problem the other way, given
, what is the probability that the
difference  is significant?
Let’s consider
is significant?
Let’s consider  following a normal law
following a normal law  .
We are looking for:
.
We are looking for:

 is the p-value.
is the p-value.
(1)#
At this point, we should not forget that we use a theorem which tells us that
 when
when  , which means everything we said is true
when
, which means everything we said is true
when  is great enough.
is great enough.
Significant difference between samples mean#
Usually, we do not want to test if an average is null but if the difference
between two averages is null. We consider two random samples having the same
size, each of them described by  and
and  .
All variables are independant. are distributed according the
same law, we assume the same for . We expect the following
difference to be null.
.
All variables are independant. are distributed according the
same law, we assume the same for . We expect the following
difference to be null.
(2)#
Considering expression (2), we can applying the central
limit theorem on variable  , we get (
, we get ( ):
):

If both samples do not have the same number of observations, this expression becomes:

Application on binomial variables#
A binomial variable  is defined by:
is defined by:

Let’s consider two series of observations  and
and  . We assume
. We assume  and we want
to determine how many observations we need to get a p-value below 5%.
We know that
and we want
to determine how many observations we need to get a p-value below 5%.
We know that  and
and  .
Next table shows the values. First column contains values for
.
Next table shows the values. First column contains values for  ,
first row contains values for
,
first row contains values for  . We also assume we have the same number
of random observations for each variable. The statistical
test cen be defined like following:
. We also assume we have the same number
of random observations for each variable. The statistical
test cen be defined like following:

If H0 is true, then:


Given a binomial law with parameter and a difference
 , this table gives the number of
observations needed on both sides to get a significant difference
assuming is the expected pourcentage
, this table gives the number of
observations needed on both sides to get a significant difference
assuming is the expected pourcentage
Estimate a p-value by using the distribution function#
Expression (1) gives a way to estimate the p-value.
Computing the integral is not always possible but there is a way to do it
using Monte Carlo method.
Let’s assume  . We denote
. We denote  as the
density function of . We also consider an interval
as the
density function of . We also consider an interval
 . Then we have
. Then we have  and:
and:

This is true because  is decreasing for
is decreasing for  .
The p-value for a estimator
.
The p-value for a estimator  using Monte Carlo method is:
using Monte Carlo method is:

Assuming every  follows a normal law .
follows a normal law .
Correlated variables#
Let’s assume we now have a vector a correlated variables  drawn following a law
drawn following a law  .
.
The central limit theorem is still valid:

We know estimators for the average and the covariance matrix defined as follows:

We usually want to check if:
If  is diagonal matrix of
is diagonal matrix of  (diagonal matrix with eigen values).
All eigen values are real and positive, we then define:
(diagonal matrix with eigen values).
All eigen values are real and positive, we then define:

We consider  .
We then have
.
We then have  and
and  where
where
 is the identity matrix. We could now consider each
dimension of
is the identity matrix. We could now consider each
dimension of  independently as illustrated in next figure:
it shows the difference on an example if we consider the correlation of
two variables correlated such as
independently as illustrated in next figure:
it shows the difference on an example if we consider the correlation of
two variables correlated such as
 .
.
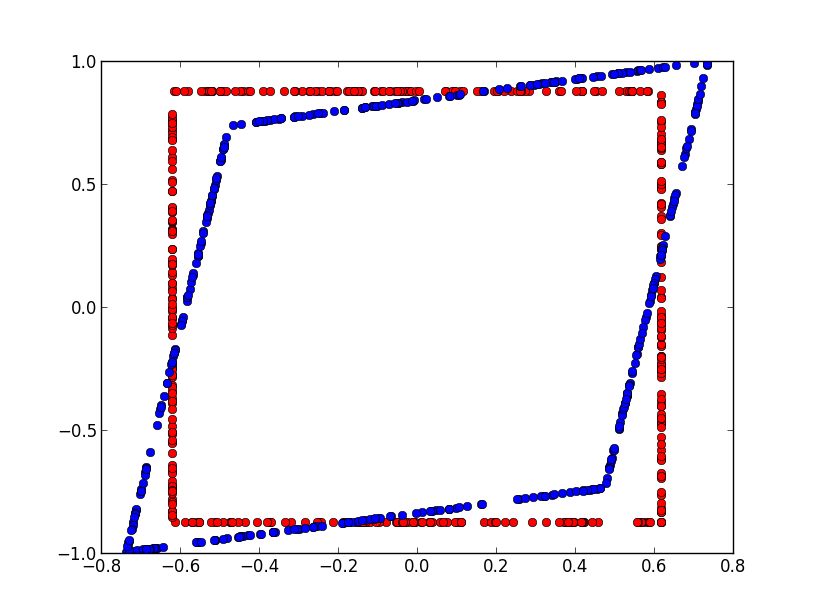
We assume we observe two Bernouilli
variables correlated. Red points represents the area
for which we would accept hypothesis H0 in case both variables are independant.
Blue area represents the same but with the correlation.
But that would not be the best way to do it. The confidence interval for a couple
of indenpendant gaussian  variables is an ellipse.
Two independent normal variables
variables is an ellipse.
Two independent normal variables  with a null mean
and standard deviation equal to one follows a
with a null mean
and standard deviation equal to one follows a  law. Based on that,
we can deduce a boundary for the confidence zone at 95%.
Next figure shows this zone for a non-correlated couple and a correlated couple
().
law. Based on that,
we can deduce a boundary for the confidence zone at 95%.
Next figure shows this zone for a non-correlated couple and a correlated couple
().
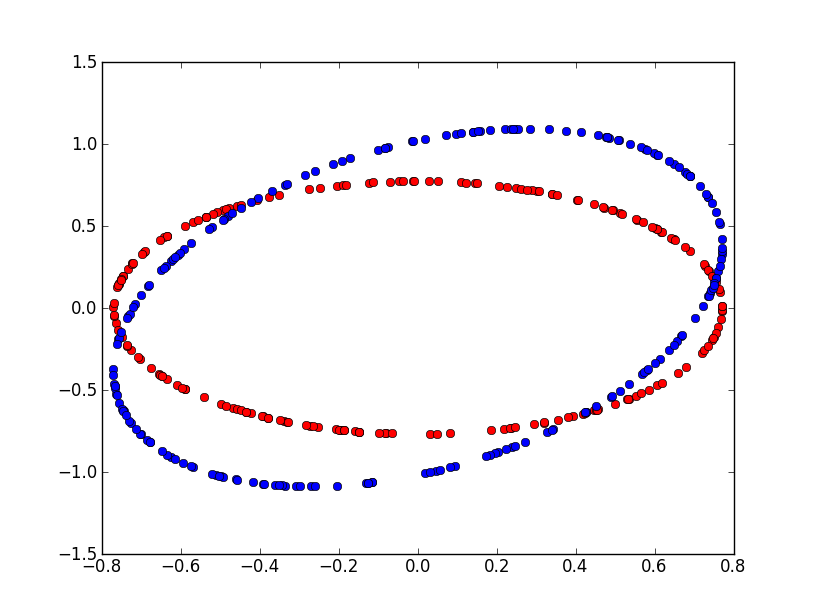
We assume we observe two Bernouilli variables correlated. Red points represents the area for which we would accept hypothesis H0 in case both variables are independant. Blue area represents the same but with the correlation.
Multiple comparisons problem#
The problem of Multiple comparisons happens when dealing with many metrics measyring a change. That’s allways the case when two version of the sam websire are compared in a test A/B. The metrics are correlated but it is unlikely that all metrics differences will be significant or not. The Holm–Bonferroni method proposes a way to define an hypthesis on the top of the existing ones.
Algorithm Expectation-Maximization#
We here assume there are two populations mixed defined by random variable  .
Let’s be a mixture of two binomial laws of parameters
and
.
Let’s be a mixture of two binomial laws of parameters
and  . It is for example the case for a series draws coming from two different coins.
. It is for example the case for a series draws coming from two different coins.

The likelihood of a random sample  ,
the class we do not observe are
,
the class we do not observe are  :
:

The parameters are  . We use an algorithm
Expectation-Maximization (EM)
to determine the parameters.
We define at iteration
. We use an algorithm
Expectation-Maximization (EM)
to determine the parameters.
We define at iteration  :
:

We then update the parameters:

Notebooks#
The following notebook produces the figures displayed in this document.