Listes des définitions et théorèmes#
Corollaires#
Corollaire C1 : Estimateur de l’aire sous la courbe ROC
On dispose des scores  des expériences qui ont réussi
et
des expériences qui ont réussi
et  les scores des expériences qui ont échoué.
On suppose également que tous les scores sont indépendants.
Les scores
les scores des expériences qui ont échoué.
On suppose également que tous les scores sont indépendants.
Les scores  sont identiquement distribués,
il en est de même pour les scores
sont identiquement distribués,
il en est de même pour les scores  .
Un estimateur de l’aire
.
Un estimateur de l’aire  sous la courbe ROC” est :
sous la courbe ROC” est :
(1)#
Corollaire C1 : approximation d’une fonction créneau
Soit  ,
alors :
,
alors :

Corollaire C1 : nullité d’un coefficient
Les notations utilisées sont celles du théorème sur loi asymptotique des coefficients.
Soit  un poids du réseau de neurones
d’indice quelconque
un poids du réseau de neurones
d’indice quelconque  . Sa valeur estimée est
. Sa valeur estimée est  ,
sa valeur optimale
,
sa valeur optimale  . D’après le théorème :
. D’après le théorème :

Corollaire C2 : Variance de l’estimateur AUC
On note  et
et  .
.
 et
et  sont de même loi que
sont de même loi que  ,
,  ,
,  sont de même loi que
sont de même loi que  .
La variance de l’estimateur
.
La variance de l’estimateur  définie par (1) est :
définie par (1) est :

Corollaire C2 : approximation d’une fonction indicatrice
Soit  compact, alors :
compact, alors :

Corollaire C3 : famille libre de fonctions
Soit  l’ensemble des fonctions continues de
l’ensemble des fonctions continues de
 avec
avec  compact muni de la norme :
compact muni de la norme :
 Alors l’ensemble
Alors l’ensemble  des fonctions sigmoïdes :
des fonctions sigmoïdes :

est une base de .
Définitions#
Définition D1 : B+ tree
Soit  un B+ tree, soit
un B+ tree, soit  un noeud de ,
il contient un vecteur
un noeud de ,
il contient un vecteur  avec
avec  et
et  .
Ce noeud contient aussi exactement
.
Ce noeud contient aussi exactement  noeuds fils
notés
noeuds fils
notés  . On désigne par
. On désigne par  l’ensemble des descendants du noeud
l’ensemble des descendants du noeud  et
et
 .
Le noeud vérifie :
.
Le noeud vérifie :

Définition D1 : Courbe ROC
On suppose que est la variable aléatoire des scores
des expériences qui ont réussi.
est celle des scores des expériences qui ont échoué.
On suppose également que tous les scores sont indépendants.
On note  et
et  les fonctions de répartition de ces variables.
les fonctions de répartition de ces variables.
 et
et  .
On définit en fonction d’un seuil
.
On définit en fonction d’un seuil  :
:


La courbe ROC est le graphe  lorsque
lorsque  varie dans
varie dans  .
.
Définition D1 : Dynamic Minimum Keystroke
On définit la façon optimale de saisir une requête sachant
un système de complétion  comme étant le
minimum obtenu :
comme étant le
minimum obtenu :
(1)#![\begin{eqnarray*}
M'(q, S) &=& \min_{0 \infegal k < l(q)} \acc{ M'(q[1..k], S) +
\min( K(q, k, S), l(q) - k) }
\end{eqnarray*}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTkuMzI2NjhwdCcgdmVyc2lvbj0nMS4xJyB2aWV3Qm94PSc2OS4xMzg5MjIgODIuMjkyMjQ5IDMyNy45NzM3MzUgMTkuMzI2NjgnIHdpZHRoPSczMjcuOTczNzM1cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTcuODc4NDU2IC0yLjc0OTY4OUM4LjA4MTY5NCAtMi43NDk2ODkgOC4yOTY4ODcgLTIuNzQ5Njg5IDguMjk2ODg3IC0yLjk4ODc5MlM4LjA4MTY5NCAtMy4yMjc4OTUgNy44Nzg0NTYgLTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzIgLTMuMjI3ODk1IDAuOTkyMjc5IC0zLjIyNzg5NSAwLjk5MjI3OSAtMi45ODg3OTJTMS4yMDc0NzIgLTIuNzQ5Njg5IDEuNDEwNzEgLTIuNzQ5Njg5SDcuODc4NDU2WicgaWQ9J2cyLTAnLz4KPHBhdGggZD0nTTMuMzgzMzEzIC03LjM3NjMzOUMzLjM4MzMxMyAtNy44NTQ1NDUgMy42OTQxNDcgLTguNjE5Njc2IDQuOTk3MjYgLTguNzAzMzYyQzUuMDU3MDM2IC04LjcxNTMxOCA1LjEwNDg1NyAtOC43NjMxMzggNS4xMDQ4NTcgLTguODM0ODY5QzUuMTA0ODU3IC04Ljk2NjM3NiA1LjAwOTIxNSAtOC45NjYzNzYgNC44Nzc3MDkgLTguOTY2Mzc2QzMuNjgyMTkyIC04Ljk2NjM3NiAyLjU5NDI3MSAtOC4zNTY2NjMgMi41ODIzMTYgLTcuNDcxOThWLTQuNzQ2MjAyQzIuNTgyMzE2IC00LjI3OTk1IDIuNTgyMzE2IC0zLjg5NzM4NSAyLjEwNDExIC0zLjUwMjg2NEMxLjY4NTY3OSAtMy4xNTYxNjQgMS4yMzEzODIgLTMuMTMyMjU0IDAuOTY4MzY5IC0zLjEyMDI5OUMwLjkwODU5MyAtMy4xMDgzNDQgMC44NjA3NzIgLTMuMDYwNTIzIDAuODYwNzcyIC0yLjk4ODc5MkMwLjg2MDc3MiAtMi44NjkyNCAwLjkzMjUwMyAtMi44NjkyNCAxLjA1MjA1NSAtMi44NTcyODVDMS44NDEwOTYgLTIuODA5NDY1IDIuNDE0OTQ0IC0yLjM3OTA3OCAyLjU0NjQ1MSAtMS43OTMyNzVDMi41ODIzMTYgLTEuNjYxNzY4IDIuNTgyMzE2IC0xLjYzNzg1OCAyLjU4MjMxNiAtMS4yMDc0NzJWMS4xNTk2NTFDMi41ODIzMTYgMS42NjE3NjggMi41ODIzMTYgMi4wNDQzMzQgMy4xNTYxNjQgMi40OTg2M0MzLjYyMjQxNiAyLjg1NzI4NSA0LjQxMTQ1NyAyLjk4ODc5MiA0Ljg3NzcwOSAyLjk4ODc5MkM1LjAwOTIxNSAyLjk4ODc5MiA1LjEwNDg1NyAyLjk4ODc5MiA1LjEwNDg1NyAyLjg1NzI4NUM1LjEwNDg1NyAyLjczNzczMyA1LjAzMzEyNiAyLjczNzczMyA0LjkxMzU3NCAyLjcyNTc3OEM0LjE2MDM5OSAyLjY3Nzk1OCAzLjU3NDU5NSAyLjI5NTM5MiAzLjQxOTE3OCAxLjY4NTY3OUMzLjM4MzMxMyAxLjU3ODA4MiAzLjM4MzMxMyAxLjU1NDE3MiAzLjM4MzMxMyAxLjEyMzc4NlYtMS4zODY4QzMuMzgzMzEzIC0xLjkzNjczNyAzLjI4NzY3MSAtMi4xMzk5NzUgMi45MDUxMDYgLTIuNTIyNTRDMi42NTQwNDcgLTIuNzczNTk5IDIuMzA3MzQ3IC0yLjg5MzE1MSAxLjk3MjYwMyAtMi45ODg3OTJDMi45NTI5MjcgLTMuMjYzNzYxIDMuMzgzMzEzIC0zLjgxMzY5OSAzLjM4MzMxMyAtNC41MDcwOThWLTcuMzc2MzM5WicgaWQ9J2cyLTEwMicvPgo8cGF0aCBkPSdNMi41ODIzMTYgMS4zOTg3NTVDMi41ODIzMTYgMS44NzY5NjEgMi4yNzE0ODIgMi42NDIwOTIgMC45NjgzNjkgMi43MjU3NzhDMC45MDg1OTMgMi43Mzc3MzMgMC44NjA3NzIgMi43ODU1NTQgMC44NjA3NzIgMi44NTcyODVDMC44NjA3NzIgMi45ODg3OTIgMC45OTIyNzkgMi45ODg3OTIgMS4wOTk4NzUgMi45ODg3OTJDMi4yNTk1MjcgMi45ODg3OTIgMy4zNzEzNTcgMi40MDI5ODkgMy4zODMzMTMgMS40OTQzOTZWLTEuMjMxMzgyQzMuMzgzMzEzIC0xLjY5NzYzNCAzLjM4MzMxMyAtMi4wODAxOTkgMy44NjE1MTkgLTIuNDc0NzJDNC4yNzk5NSAtMi44MjE0MiA0LjczNDI0NyAtMi44NDUzMyA0Ljk5NzI2IC0yLjg1NzI4NUM1LjA1NzAzNiAtMi44NjkyNCA1LjEwNDg1NyAtMi45MTcwNjEgNS4xMDQ4NTcgLTIuOTg4NzkyQzUuMTA0ODU3IC0zLjEwODM0NCA1LjAzMzEyNiAtMy4xMDgzNDQgNC45MTM1NzQgLTMuMTIwMjk5QzQuMTI0NTMzIC0zLjE2ODEyIDMuNTUwNjg1IC0zLjU5ODUwNiAzLjQxOTE3OCAtNC4xODQzMDlDMy4zODMzMTMgLTQuMzE1ODE2IDMuMzgzMzEzIC00LjMzOTcyNiAzLjM4MzMxMyAtNC43NzAxMTJWLTcuMTM3MjM1QzMuMzgzMzEzIC03LjYzOTM1MiAzLjM4MzMxMyAtOC4wMjE5MTggMi44MDk0NjUgLTguNDc2MjE0QzIuMzMxMjU4IC04Ljg0NjgyNCAxLjUwNjM1MSAtOC45NjYzNzYgMS4wOTk4NzUgLTguOTY2Mzc2QzAuOTkyMjc5IC04Ljk2NjM3NiAwLjg2MDc3MiAtOC45NjYzNzYgMC44NjA3NzIgLTguODM0ODY5QzAuODYwNzcyIC04LjcxNTMxOCAwLjkzMjUwMyAtOC43MTUzMTggMS4wNTIwNTUgLTguNzAzMzYyQzEuODA1MjMgLTguNjU1NTQyIDIuMzkxMDM0IC04LjI3Mjk3NiAyLjU0NjQ1MSAtNy42NjMyNjNDMi41ODIzMTYgLTcuNTU1NjY2IDIuNTgyMzE2IC03LjUzMTc1NiAyLjU4MjMxNiAtNy4xMDEzN1YtNC41OTA3ODVDMi41ODIzMTYgLTQuMDQwODQ3IDIuNjc3OTU4IC0zLjgzNzYwOSAzLjA2MDUyMyAtMy40NTUwNDRDMy4zMTE1ODIgLTMuMjAzOTg1IDMuNjU4MjgxIC0zLjA4NDQzMyAzLjk5MzAyNiAtMi45ODg3OTJDMy4wMTI3MDIgLTIuNzEzODIzIDIuNTgyMzE2IC0yLjE2Mzg4NSAyLjU4MjMxNiAtMS40NzA0ODZWMS4zOTg3NTVaJyBpZD0nZzItMTAzJy8+CjxwYXRoIGQ9J00yLjE5OTc1MSAtMC41NzM4NDhDMi4xOTk3NTEgLTAuOTIwNTQ4IDEuOTEyODI3IC0xLjE1OTY1MSAxLjYyNTkwMyAtMS4xNTk2NTFDMS4yNzkyMDMgLTEuMTU5NjUxIDEuMDQwMSAtMC44NzI3MjcgMS4wNDAxIC0wLjU4NTgwM0MxLjA0MDEgLTAuMjM5MTAzIDEuMzI3MDI0IDAgMS42MTM5NDggMEMxLjk2MDY0OCAwIDIuMTk5NzUxIC0wLjI4NjkyNCAyLjE5OTc1MSAtMC41NzM4NDhaJyBpZD0nZzQtNTgnLz4KPHBhdGggZD0nTTIuMzMxMjU4IDAuMDQ3ODIxQzIuMzMxMjU4IC0wLjY0NTU3OSAyLjEwNDExIC0xLjE1OTY1MSAxLjYxMzk0OCAtMS4xNTk2NTFDMS4yMzEzODIgLTEuMTU5NjUxIDEuMDQwMSAtMC44NDg4MTcgMS4wNDAxIC0wLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3IC0wLjA0NzgyMSAyLjAyMDQyMyAtMC4xNTU0MTdDMi4wNDQzMzQgLTAuMTc5MzI4IDIuMDU2Mjg5IC0wLjE3OTMyOCAyLjA2ODI0NCAtMC4xNzkzMjhDMi4wOTIxNTQgLTAuMTc5MzI4IDIuMDkyMTU0IC0wLjAxMTk1NSAyLjA5MjE1NCAwLjA0NzgyMUMyLjA5MjE1NCAwLjQ0MjM0MSAyLjAyMDQyMyAxLjIxOTQyNyAxLjMyNzAyNCAxLjk5NjUxM0MxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjQxMDcxIDIuMzA3MzQ3IDIuMzMxMjU4IDEuNDIyNjY1IDIuMzMxMjU4IDAuMDQ3ODIxWicgaWQ9J2c0LTU5Jy8+CjxwYXRoIGQ9J001Ljk3NzU4NCAtNC44Mjk4ODhDNS45NjU2MjkgLTQuODY1NzUzIDUuOTE3ODA4IC00Ljk2MTM5NSA1LjkxNzgwOCAtNC45OTcyNkM1LjkxNzgwOCAtNS4wMDkyMTUgNS45Mjk3NjMgLTUuMDIxMTcxIDYuMTMzMDAxIC01LjE3NjU4OEw3LjI5MjY1MyAtNi4wODUxODFDOC44OTQ2NDUgLTcuMzI4NTE4IDkuNDIwNjcyIC03Ljc0Njk0OSAxMC4yNDU1NzkgLTcuODE4NjhDMTAuMzI5MjY1IC03LjgzMDYzNSAxMC40NDg4MTcgLTcuODMwNjM1IDEwLjQ0ODgxNyAtOC4wMzM4NzNDMTAuNDQ4ODE3IC04LjEwNTYwNCAxMC40MTI5NTEgLTguMTY1MzggMTAuMzE3MzEgLTguMTY1MzhDMTAuMTg1ODAzIC04LjE2NTM4IDEwLjA0MjM0MSAtOC4xNDE0NjkgOS45MTA4MzQgLTguMTQxNDY5SDkuNDU2NTM4QzkuMDg1OTI4IC04LjE0MTQ2OSA4LjY5MTQwNyAtOC4xNjUzOCA4LjMzMjc1MiAtOC4xNjUzOEM4LjI0OTA2NiAtOC4xNjUzOCA4LjEwNTYwNCAtOC4xNjUzOCA4LjEwNTYwNCAtNy45NTAxODdDOC4xMDU2MDQgLTcuODMwNjM1IDguMTg5MjkgLTcuODE4NjggOC4yNjEwMjEgLTcuODE4NjhDOC4zOTI1MjggLTcuODA2NzI1IDguNTQ3OTQ1IC03Ljc1ODkwNCA4LjU0Nzk0NSAtNy41OTE1MzJDOC41NDc5NDUgLTcuMzUyNDI4IDguMTg5MjkgLTcuMDY1NTA0IDguMDkzNjQ5IC02Ljk5Mzc3M0wzLjQwNzIyMyAtMy4zNDc0NDdMNC4zOTk1MDIgLTcuMjkyNjUzQzQuNTA3MDk4IC03LjY5OTEyOCA0LjUzMTAwOSAtNy44MTg2OCA1LjM3OTgyNiAtNy44MTg2OEM1LjYwNjk3NCAtNy44MTg2OCA1LjcxNDU3IC03LjgxODY4IDUuNzE0NTcgLTguMDQ1ODI4QzUuNzE0NTcgLTguMTY1MzggNS41OTUwMTkgLTguMTY1MzggNS41MzUyNDMgLTguMTY1MzhDNS4zMjAwNSAtOC4xNjUzOCA1LjA2ODk5MSAtOC4xNDE0NjkgNC44NDE4NDMgLTguMTQxNDY5SDMuNDMxMTMzQzMuMjE1OTQgLTguMTQxNDY5IDIuOTUyOTI3IC04LjE2NTM4IDIuNzM3NzMzIC04LjE2NTM4QzIuNjQyMDkyIC04LjE2NTM4IDIuNTEwNTg1IC04LjE2NTM4IDIuNTEwNTg1IC03LjkzODIzMkMyLjUxMDU4NSAtNy44MTg2OCAyLjYxODE4MiAtNy44MTg2OCAyLjc5NzUwOSAtNy44MTg2OEMzLjUyNjc3NSAtNy44MTg2OCAzLjUyNjc3NSAtNy43MjMwMzkgMy41MjY3NzUgLTcuNTkxNTMyQzMuNTI2Nzc1IC03LjU2NzYyMSAzLjUyNjc3NSAtNy40OTU4OSAzLjQ3ODk1NCAtNy4zMTY1NjNMMS44NjUwMDYgLTAuODg0NjgyQzEuNzU3NDEgLTAuNDY2MjUyIDEuNzMzNDk5IC0wLjM0NjcgMC44OTY2MzggLTAuMzQ2N0MwLjY2OTQ4OSAtMC4zNDY3IDAuNTQ5OTM4IC0wLjM0NjcgMC41NDk5MzggLTAuMTMxNTA3QzAuNTQ5OTM4IDAgMC42NTc1MzQgMCAwLjcyOTI2NSAwQzAuOTU2NDEzIDAgMS4xOTU1MTcgLTAuMDIzOTEgMS40MjI2NjUgLTAuMDIzOTFIMi44MjE0MkMzLjA0ODU2OCAtMC4wMjM5MSAzLjI5OTYyNiAwIDMuNTI2Nzc1IDBDMy42MjI0MTYgMCAzLjc1MzkyMyAwIDMuNzUzOTIzIC0wLjIyNzE0OEMzLjc1MzkyMyAtMC4zNDY3IDMuNjQ2MzI2IC0wLjM0NjcgMy40NjY5OTkgLTAuMzQ2N0MyLjczNzczMyAtMC4zNDY3IDIuNzM3NzMzIC0wLjQ0MjM0MSAyLjczNzczMyAtMC41NjE4OTNDMi43Mzc3MzMgLTAuNjQ1NTc5IDIuODA5NDY1IC0wLjk0NDQ1OCAyLjg1NzI4NSAtMS4xMzU3NDFMMy4zMjM1MzcgLTIuOTg4NzkyTDUuMTQwNzIyIC00LjQxMTQ1N0M1LjQ4NzQyMiAtMy42NDYzMjYgNi4xMjEwNDYgLTIuMTE2MDY1IDYuNjExMjA4IC0wLjk0NDQ1OEM2LjY0NzA3MyAtMC44NzI3MjcgNi42NzA5ODQgLTAuODAwOTk2IDYuNjcwOTg0IC0wLjcxNzMxQzYuNjcwOTg0IC0wLjM1ODY1NSA2LjE5Mjc3NyAtMC4zNDY3IDYuMDg1MTgxIC0wLjM0NjdTNS44NTgwMzIgLTAuMzQ2NyA1Ljg1ODAzMiAtMC4xMTk1NTJDNS44NTgwMzIgMCA1Ljk4OTUzOSAwIDYuMDI1NDA1IDBDNi40NDM4MzYgMCA2Ljg4NjE3NyAtMC4wMjM5MSA3LjMwNDYwOCAtMC4wMjM5MUg3Ljg3ODQ1NkM4LjA1Nzc4MyAtMC4wMjM5MSA4LjI2MTAyMSAwIDguNDQwMzQ5IDBDOC41MTIwOCAwIDguNjQzNTg3IDAgOC42NDM1ODcgLTAuMjI3MTQ4QzguNjQzNTg3IC0wLjM0NjcgOC41MzU5OSAtMC4zNDY3IDguNDE2NDM4IC0wLjM0NjdDNy45NzQwOTcgLTAuMzU4NjU1IDcuODE4NjggLTAuNDU0Mjk2IDcuNjM5MzUyIC0wLjg4NDY4Mkw1Ljk3NzU4NCAtNC44Mjk4ODhaJyBpZD0nZzQtNzUnLz4KPHBhdGggZD0nTTEwLjg1NTI5MyAtNy4yOTI2NTNDMTAuOTYyODg5IC03LjY5OTEyOCAxMC45ODY4IC03LjgxODY4IDExLjgzNTYxNiAtNy44MTg2OEMxMi4wNjI3NjUgLTcuODE4NjggMTIuMTcwMzYxIC03LjgxODY4IDEyLjE3MDM2MSAtOC4wNDU4MjhDMTIuMTcwMzYxIC04LjE2NTM4IDEyLjA4NjY3NSAtOC4xNjUzOCAxMS44NTk1MjcgLTguMTY1MzhIMTAuNDI0OTA3QzEwLjEyNjAyNyAtOC4xNjUzOCAxMC4xMTQwNzIgLTguMTUzNDI1IDkuOTgyNTY1IC03Ljk2MjE0Mkw1LjYxODkyOSAtMS4wNjQwMUw0LjcyMjI5MSAtNy45MDIzNjZDNC42ODY0MjYgLTguMTY1MzggNC42NzQ0NzEgLTguMTY1MzggNC4zNjM2MzYgLTguMTY1MzhIMi44ODExOTZDMi42NTQwNDcgLTguMTY1MzggMi41NDY0NTEgLTguMTY1MzggMi41NDY0NTEgLTcuOTM4MjMyQzIuNTQ2NDUxIC03LjgxODY4IDIuNjU0MDQ3IC03LjgxODY4IDIuODMzMzc1IC03LjgxODY4QzMuNTYyNjQgLTcuODE4NjggMy41NjI2NCAtNy43MjMwMzkgMy41NjI2NCAtNy41OTE1MzJDMy41NjI2NCAtNy41Njc2MjEgMy41NjI2NCAtNy40OTU4OSAzLjUxNDgxOSAtNy4zMTY1NjNMMS45ODQ1NTggLTEuMjE5NDI3QzEuODQxMDk2IC0wLjY0NTU3OSAxLjU2NjEyNyAtMC4zODI1NjUgMC43NjUxMzEgLTAuMzQ2N0MwLjcyOTI2NSAtMC4zNDY3IDAuNTg1ODAzIC0wLjMzNDc0NSAwLjU4NTgwMyAtMC4xMzE1MDdDMC41ODU4MDMgMCAwLjY5MzQgMCAwLjc0MTIyIDBDMC45ODAzMjQgMCAxLjU5MDAzNyAtMC4wMjM5MSAxLjgyOTE0MSAtMC4wMjM5MUgyLjQwMjk4OUMyLjU3MDM2MSAtMC4wMjM5MSAyLjc3MzU5OSAwIDIuOTQwOTcxIDBDMy4wMjQ2NTggMCAzLjE1NjE2NCAwIDMuMTU2MTY0IC0wLjIyNzE0OEMzLjE1NjE2NCAtMC4zMzQ3NDUgMy4wMzY2MTMgLTAuMzQ2NyAyLjk4ODc5MiAtMC4zNDY3QzIuNTk0MjcxIC0wLjM1ODY1NSAyLjIxMTcwNiAtMC40MzAzODYgMi4yMTE3MDYgLTAuODYwNzcyQzIuMjExNzA2IC0wLjk4MDMyNCAyLjIxMTcwNiAtMC45OTIyNzkgMi4yNTk1MjcgLTEuMTU5NjUxTDMuOTA5MzQgLTcuNzQ2OTQ5SDMuOTIxMjk1TDQuOTEzNTc0IC0wLjMyMjc5QzQuOTQ5NDQgLTAuMDM1ODY2IDQuOTYxMzk1IDAgNS4wNjg5OTEgMEM1LjIwMDQ5OCAwIDUuMjYwMjc0IC0wLjA5NTY0MSA1LjMyMDA1IC0wLjIwMzIzOEwxMC4xMjYwMjcgLTcuODA2NzI1SDEwLjEzNzk4M0w4LjQwNDQ4MyAtMC44ODQ2ODJDOC4yOTY4ODcgLTAuNDY2MjUyIDguMjcyOTc2IC0wLjM0NjcgNy40MzYxMTUgLTAuMzQ2N0M3LjIwODk2NiAtMC4zNDY3IDcuMDg5NDE1IC0wLjM0NjcgNy4wODk0MTUgLTAuMTMxNTA3QzcuMDg5NDE1IDAgNy4xOTcwMTEgMCA3LjI2ODc0MiAwQzcuNDcxOTggMCA3LjcxMTA4MyAtMC4wMjM5MSA3LjkxNDMyMSAtMC4wMjM5MUg5LjMyNTAzMUM5LjUyODI2OSAtMC4wMjM5MSA5Ljc3OTMyOCAwIDkuOTgyNTY1IDBDMTAuMDc4MjA3IDAgMTAuMjA5NzE0IDAgMTAuMjA5NzE0IC0wLjIyNzE0OEMxMC4yMDk3MTQgLTAuMzQ2NyAxMC4xMDIxMTcgLTAuMzQ2NyA5LjkyMjc5IC0wLjM0NjdDOS4xOTM1MjQgLTAuMzQ2NyA5LjE5MzUyNCAtMC40NDIzNDEgOS4xOTM1MjQgLTAuNTYxODkzQzkuMTkzNTI0IC0wLjU3Mzg0OCA5LjE5MzUyNCAtMC42NTc1MzQgOS4yMTc0MzUgLTAuNzUzMTc2TDEwLjg1NTI5MyAtNy4yOTI2NTNaJyBpZD0nZzQtNzcnLz4KPHBhdGggZD0nTTcuNTkxNTMyIC04LjMwODg0MkM3LjU5MTUzMiAtOC40MTY0MzggNy41MDc4NDYgLTguNDE2NDM4IDcuNDgzOTM1IC04LjQxNjQzOEM3LjQzNjExNSAtOC40MTY0MzggNy40MjQxNTkgLTguNDA0NDgzIDcuMjgwNjk3IC04LjIyNTE1NkM3LjIwODk2NiAtOC4xNDE0NjkgNi43MTg4MDQgLTcuNTE5ODAxIDYuNzA2ODQ5IC03LjUwNzg0NkM2LjMxMjMyOSAtOC4yODQ5MzIgNS41MjMyODggLTguNDE2NDM4IDUuMDIxMTcxIC04LjQxNjQzOEMzLjUwMjg2NCAtOC40MTY0MzggMi4xMjgwMiAtNy4wMjk2MzkgMi4xMjgwMiAtNS42Nzg3MDVDMi4xMjgwMiAtNC43ODIwNjcgMi42NjYwMDIgLTQuMjU2MDQgMy4yNTE4MDYgLTQuMDUyODAyQzMuMzgzMzEzIC00LjAwNDk4MSA0LjA4ODY2NyAtMy44MTM2OTkgNC40NDczMjMgLTMuNzMwMDEyQzUuMDU3MDM2IC0zLjU2MjY0IDUuMjEyNDUzIC0zLjUxNDgxOSA1LjQ2MzUxMiAtMy4yNTE4MDZDNS41MTEzMzMgLTMuMTkyMDMgNS43NTA0MzYgLTIuOTE3MDYxIDUuNzUwNDM2IC0yLjM1NTE2OEM1Ljc1MDQzNiAtMS4yNDMzMzcgNC43MjIyOTEgLTAuMDk1NjQxIDMuNTI2Nzc1IC0wLjA5NTY0MUMyLjU0NjQ1MSAtMC4wOTU2NDEgMS40NTg1MzEgLTAuNTE0MDcyIDEuNDU4NTMxIC0xLjg1MzA1MUMxLjQ1ODUzMSAtMi4wODAxOTkgMS41MDYzNTEgLTIuMzY3MTIzIDEuNTQyMjE3IC0yLjQ4NjY3NUMxLjU0MjIxNyAtMi41MjI1NCAxLjU1NDE3MiAtMi41ODIzMTYgMS41NTQxNzIgLTIuNjA2MjI3QzEuNTU0MTcyIC0yLjY1NDA0NyAxLjUzMDI2MiAtMi43MTM4MjMgMS40MzQ2MiAtMi43MTM4MjNDMS4zMjcwMjQgLTIuNzEzODIzIDEuMzE1MDY4IC0yLjY4OTkxMyAxLjI2NzI0OCAtMi40ODY2NzVMMC42NTc1MzQgLTAuMDM1ODY2QzAuNjU3NTM0IC0wLjAyMzkxIDAuNjA5NzE0IDAuMTMxNTA3IDAuNjA5NzE0IDAuMTQzNDYyQzAuNjA5NzE0IDAuMjUxMDU5IDAuNzA1MzU1IDAuMjUxMDU5IDAuNzI5MjY1IDAuMjUxMDU5QzAuNzc3MDg2IDAuMjUxMDU5IDAuNzg5MDQxIDAuMjM5MTAzIDAuOTMyNTAzIDAuMDU5Nzc2TDEuNDgyNDQxIC0wLjY1NzUzNEMxLjc2OTM2NSAtMC4yMjcxNDggMi4zOTEwMzQgMC4yNTEwNTkgMy41MDI4NjQgMC4yNTEwNTlDNS4wNDUwODEgMC4yNTEwNTkgNi40NTU3OTEgLTEuMjQzMzM3IDYuNDU1NzkxIC0yLjczNzczM0M2LjQ1NTc5MSAtMy4yMzk4NTEgNi4zMzYyMzkgLTMuNjgyMTkyIDUuODgxOTQzIC00LjEyNDUzM0M1LjYzMDg4NCAtNC4zNzU1OTIgNS40MTU2OTEgLTQuNDM1MzY3IDQuMzE1ODE2IC00LjcyMjI5MUMzLjUxNDgxOSAtNC45Mzc0ODQgMy40MDcyMjMgLTQuOTczMzUgMy4xOTIwMyAtNS4xNjQ2MzNDMi45ODg3OTIgLTUuMzY3ODcgMi44MzMzNzUgLTUuNjU0Nzk1IDIuODMzMzc1IC02LjA2MTI3QzIuODMzMzc1IC03LjA2NTUwNCAzLjg0OTU2NCAtOC4wOTM2NDkgNC45ODUzMDUgLTguMDkzNjQ5QzYuMTU2OTEyIC04LjA5MzY0OSA2LjcwNjg0OSAtNy4zNzYzMzkgNi43MDY4NDkgLTYuMjQwNTk4QzYuNzA2ODQ5IC01LjkyOTc2MyA2LjY0NzA3MyAtNS42MDY5NzQgNi42NDcwNzMgLTUuNTU5MTUzQzYuNjQ3MDczIC01LjQ1MTU1NyA2Ljc0MjcxNSAtNS40NTE1NTcgNi43Nzg1OCAtNS40NTE1NTdDNi44ODYxNzcgLTUuNDUxNTU3IDYuODk4MTMyIC01LjQ4NzQyMiA2Ljk0NTk1MyAtNS42Nzg3MDVMNy41OTE1MzIgLTguMzA4ODQyWicgaWQ9J2c0LTgzJy8+CjxwYXRoIGQ9J00zLjM1OTQwMiAtNy45OTgwMDdDMy4zNzEzNTcgLTguMDQ1ODI4IDMuMzk1MjY4IC04LjExNzU1OSAzLjM5NTI2OCAtOC4xNzczMzVDMy4zOTUyNjggLTguMjk2ODg3IDMuMjc1NzE2IC04LjI5Njg4NyAzLjI1MTgwNiAtOC4yOTY4ODdDMy4yMzk4NTEgLTguMjk2ODg3IDIuODA5NDY1IC04LjI2MTAyMSAyLjU5NDI3MSAtOC4yMzcxMTFDMi4zOTEwMzQgLTguMjI1MTU2IDIuMjExNzA2IC04LjIwMTI0NSAxLjk5NjUxMyAtOC4xODkyOUMxLjcwOTU4OSAtOC4xNjUzOCAxLjYyNTkwMyAtOC4xNTM0MjUgMS42MjU5MDMgLTcuOTM4MjMyQzEuNjI1OTAzIC03LjgxODY4IDEuNzQ1NDU1IC03LjgxODY4IDEuODY1MDA2IC03LjgxODY4QzIuNDc0NzIgLTcuODE4NjggMi40NzQ3MiAtNy43MTEwODMgMi40NzQ3MiAtNy41OTE1MzJDMi40NzQ3MiAtNy41NDM3MTEgMi40NzQ3MiAtNy41MTk4MDEgMi40MTQ5NDQgLTcuMzA0NjA4TDAuNzA1MzU1IC0wLjQ2NjI1MkMwLjY1NzUzNCAtMC4yODY5MjQgMC42NTc1MzQgLTAuMjYzMDE0IDAuNjU3NTM0IC0wLjE5MTI4M0MwLjY1NzUzNCAwLjA3MTczMSAwLjg2MDc3MiAwLjExOTU1MiAwLjk4MDMyNCAwLjExOTU1MkMxLjMxNTA2OCAwLjExOTU1MiAxLjM4NjggLTAuMTQzNDYyIDEuNDgyNDQxIC0wLjUxNDA3MkwyLjA0NDMzNCAtMi43NDk2ODlDMi45MDUxMDYgLTIuNjU0MDQ3IDMuNDE5MTc4IC0yLjI5NTM5MiAzLjQxOTE3OCAtMS43MjE1NDRDMy40MTkxNzggLTEuNjQ5ODEzIDMuNDE5MTc4IC0xLjYwMTk5MyAzLjM4MzMxMyAtMS40MjI2NjVDMy4zMzU0OTIgLTEuMjQzMzM3IDMuMzM1NDkyIC0xLjA5OTg3NSAzLjMzNTQ5MiAtMS4wNDAxQzMuMzM1NDkyIC0wLjM0NjcgMy43ODk3ODggMC4xMTk1NTIgNC4zOTk1MDIgMC4xMTk1NTJDNC45NDk0NCAwLjExOTU1MiA1LjIzNjM2NCAtMC4zODI1NjUgNS4zMzIwMDUgLTAuNTQ5OTM4QzUuNTgzMDY0IC0wLjk5MjI3OSA1LjczODQ4MSAtMS42NjE3NjggNS43Mzg0ODEgLTEuNzA5NTg5QzUuNzM4NDgxIC0xLjc2OTM2NSA1LjY5MDY2IC0xLjgxNzE4NiA1LjYxODkyOSAtMS44MTcxODZDNS41MTEzMzMgLTEuODE3MTg2IDUuNDk5Mzc3IC0xLjc2OTM2NSA1LjQ1MTU1NyAtMS41NzgwODJDNS4yODQxODQgLTAuOTU2NDEzIDUuMDMzMTI2IC0wLjExOTU1MiA0LjQyMzQxMiAtMC4xMTk1NTJDNC4xODQzMDkgLTAuMTE5NTUyIDQuMDI4ODkyIC0wLjIzOTEwMyA0LjAyODg5MiAtMC42OTM0QzQuMDI4ODkyIC0wLjkyMDU0OCA0LjA3NjcxMiAtMS4xODM1NjIgNC4xMjQ1MzMgLTEuMzYyODg5QzQuMTcyMzU0IC0xLjU3ODA4MiA0LjE3MjM1NCAtMS41OTAwMzcgNC4xNzIzNTQgLTEuNzMzNDk5QzQuMTcyMzU0IC0yLjQzODg1NCAzLjUzODczIC0yLjgzMzM3NSAyLjQzODg1NCAtMi45NzY4MzdDMi44NjkyNCAtMy4yMzk4NTEgMy4yOTk2MjYgLTMuNzA2MTAyIDMuNDY2OTk5IC0zLjg4NTQzQzQuMTQ4NDQzIC00LjY1MDU2IDQuNjE0Njk1IC01LjAzMzEyNiA1LjE2NDYzMyAtNS4wMzMxMjZDNS40Mzk2MDEgLTUuMDMzMTI2IDUuNTExMzMzIC00Ljk2MTM5NSA1LjU5NTAxOSAtNC44ODk2NjRDNS4xNTI2NzcgLTQuODQxODQzIDQuOTg1MzA1IC00LjUzMTAwOSA0Ljk4NTMwNSAtNC4yOTE5MDVDNC45ODUzMDUgLTQuMDA0OTgxIDUuMjEyNDUzIC0zLjkwOTM0IDUuMzc5ODI2IC0zLjkwOTM0QzUuNzAyNjE1IC0zLjkwOTM0IDUuOTg5NTM5IC00LjE4NDMwOSA1Ljk4OTUzOSAtNC41NjY4NzRDNS45ODk1MzkgLTQuOTEzNTc0IDUuNzE0NTcgLTUuMjcyMjI5IDUuMTc2NTg4IC01LjI3MjIyOUM0LjUxOTA1NCAtNS4yNzIyMjkgMy45ODEwNzEgLTQuODA1OTc4IDMuMTMyMjU0IC0zLjg0OTU2NEMzLjAxMjcwMiAtMy43MDYxMDIgMi41NzAzNjEgLTMuMjUxODA2IDIuMTI4MDIgLTMuMDg0NDMzTDMuMzU5NDAyIC03Ljk5ODAwN1onIGlkPSdnNC0xMDcnLz4KPHBhdGggZD0nTTMuMDM2NjEzIC03Ljk5ODAwN0MzLjA0ODU2OCAtOC4wNDU4MjggMy4wNzI0NzggLTguMTE3NTU5IDMuMDcyNDc4IC04LjE3NzMzNUMzLjA3MjQ3OCAtOC4yOTY4ODcgMi45NTI5MjcgLTguMjk2ODg3IDIuOTI5MDE2IC04LjI5Njg4N0MyLjkxNzA2MSAtOC4yOTY4ODcgMi40ODY2NzUgLTguMjYxMDIxIDIuMjcxNDgyIC04LjIzNzExMUMyLjA2ODI0NCAtOC4yMjUxNTYgMS44ODg5MTcgLTguMjAxMjQ1IDEuNjczNzI0IC04LjE4OTI5QzEuMzg2OCAtOC4xNjUzOCAxLjMwMzExMyAtOC4xNTM0MjUgMS4zMDMxMTMgLTcuOTM4MjMyQzEuMzAzMTEzIC03LjgxODY4IDEuNDIyNjY1IC03LjgxODY4IDEuNTQyMjE3IC03LjgxODY4QzIuMTUxOTMgLTcuODE4NjggMi4xNTE5MyAtNy43MTEwODMgMi4xNTE5MyAtNy41OTE1MzJDMi4xNTE5MyAtNy41NDM3MTEgMi4xNTE5MyAtNy41MTk4MDEgMi4wOTIxNTQgLTcuMzA0NjA4TDAuNjA5NzE0IC0xLjM3NDg0NEMwLjU3Mzg0OCAtMS4yNDMzMzcgMC41NDk5MzggLTEuMTQ3Njk2IDAuNTQ5OTM4IC0wLjk1NjQxM0MwLjU0OTkzOCAtMC4zNTg2NTUgMC45OTIyNzkgMC4xMTk1NTIgMS42MDE5OTMgMC4xMTk1NTJDMS45OTY1MTMgMC4xMTk1NTIgMi4yNTk1MjcgLTAuMTQzNDYyIDIuNDUwODA5IC0wLjUxNDA3MkMyLjY1NDA0NyAtMC45MDg1OTMgMi44MjE0MiAtMS42NjE3NjggMi44MjE0MiAtMS43MDk1ODlDMi44MjE0MiAtMS43NjkzNjUgMi43NzM1OTkgLTEuODE3MTg2IDIuNzAxODY4IC0xLjgxNzE4NkMyLjU5NDI3MSAtMS44MTcxODYgMi41ODIzMTYgLTEuNzU3NDEgMi41MzQ0OTYgLTEuNTc4MDgyQzIuMzE5MzAzIC0wLjc1MzE3NiAyLjEwNDExIC0wLjExOTU1MiAxLjYyNTkwMyAtMC4xMTk1NTJDMS4yNjcyNDggLTAuMTE5NTUyIDEuMjY3MjQ4IC0wLjUwMjExNyAxLjI2NzI0OCAtMC42Njk0ODlDMS4yNjcyNDggLTAuNzE3MzEgMS4yNjcyNDggLTAuOTY4MzY5IDEuMzUwOTM0IC0xLjMwMzExM0wzLjAzNjYxMyAtNy45OTgwMDdaJyBpZD0nZzQtMTA4Jy8+CjxwYXRoIGQ9J001LjI3MjIyOSAtNS4xNTI2NzdDNS4yNzIyMjkgLTUuMjEyNDUzIDUuMjI0NDA4IC01LjI2MDI3NCA1LjE2NDYzMyAtNS4yNjAyNzRDNS4wNjg5OTEgLTUuMjYwMjc0IDQuNjAyNzQgLTQuODI5ODg4IDQuMzc1NTkyIC00LjQxMTQ1N0M0LjE2MDM5OSAtNC45NDk0NCAzLjc4OTc4OCAtNS4yNzIyMjkgMy4yNzU3MTYgLTUuMjcyMjI5QzEuOTI0NzgyIC01LjI3MjIyOSAwLjQ2NjI1MiAtMy41MjY3NzUgMC40NjYyNTIgLTEuNzU3NDFDMC40NjYyNTIgLTAuNTczODQ4IDEuMTU5NjUxIDAuMTE5NTUyIDEuOTcyNjAzIDAuMTE5NTUyQzIuNjA2MjI3IDAuMTE5NTUyIDMuMTMyMjU0IC0wLjM1ODY1NSAzLjM4MzMxMyAtMC42MzM2MjRMMy4zOTUyNjggLTAuNjIxNjY5TDIuOTQwOTcxIDEuMTcxNjA2TDIuODMzMzc1IDEuNjAxOTkzQzIuNzI1Nzc4IDEuOTYwNjQ4IDIuNTQ2NDUxIDEuOTYwNjQ4IDEuOTg0NTU4IDEuOTcyNjAzQzEuODUzMDUxIDEuOTcyNjAzIDEuNzMzNDk5IDEuOTcyNjAzIDEuNzMzNDk5IDIuMTk5NzUxQzEuNzMzNDk5IDIuMjgzNDM3IDEuODA1MjMgMi4zMTkzMDMgMS44ODg5MTcgMi4zMTkzMDNDMi4wNTYyODkgMi4zMTkzMDMgMi4yNzE0ODIgMi4yOTUzOTIgMi40Mzg4NTQgMi4yOTUzOTJIMy42NTgyODFDMy44Mzc2MDkgMi4yOTUzOTIgNC4wNDA4NDcgMi4zMTkzMDMgNC4yMjAxNzQgMi4zMTkzMDNDNC4yOTE5MDUgMi4zMTkzMDMgNC40MzUzNjcgMi4zMTkzMDMgNC40MzUzNjcgMi4wOTIxNTRDNC40MzUzNjcgMS45NzI2MDMgNC4zMzk3MjYgMS45NzI2MDMgNC4xNjAzOTkgMS45NzI2MDNDMy41OTg1MDYgMS45NzI2MDMgMy41NjI2NCAxLjg4ODkxNyAzLjU2MjY0IDEuNzkzMjc1QzMuNTYyNjQgMS43MzM0OTkgMy41NzQ1OTUgMS43MjE1NDQgMy42MTA0NjEgMS41NjYxMjdMNS4yNzIyMjkgLTUuMTUyNjc3Wk0zLjU4NjU1IC0xLjQyMjY2NUMzLjUyNjc3NSAtMS4yMTk0MjcgMy41MjY3NzUgLTEuMTk1NTE3IDMuMzU5NDAyIC0wLjk2ODM2OUMzLjA5NjM4OSAtMC42MzM2MjQgMi41NzAzNjEgLTAuMTE5NTUyIDIuMDA4NDY4IC0wLjExOTU1MkMxLjUxODMwNiAtMC4xMTk1NTIgMS4yNDMzMzcgLTAuNTYxODkzIDEuMjQzMzM3IC0xLjI2NzI0OEMxLjI0MzMzNyAtMS45MjQ3ODIgMS42MTM5NDggLTMuMjYzNzYxIDEuODQxMDk2IC0zLjc2NTg3OEMyLjI0NzU3MiAtNC42MDI3NCAyLjgwOTQ2NSAtNS4wMzMxMjYgMy4yNzU3MTYgLTUuMDMzMTI2QzQuMDY0NzU3IC01LjAzMzEyNiA0LjIyMDE3NCAtNC4wNTI4MDIgNC4yMjAxNzQgLTMuOTU3MTYxQzQuMjIwMTc0IC0zLjk0NTIwNSA0LjE4NDMwOSAtMy43ODk3ODggNC4xNzIzNTQgLTMuNzY1ODc4TDMuNTg2NTUgLTEuNDIyNjY1WicgaWQ9J2c0LTExMycvPgo8cGF0aCBkPSdNMi42NTQwNDcgMS45OTI1MjhDMi43MTc4MDggMS45OTI1MjggMi44MTM0NSAxLjk5MjUyOCAyLjgxMzQ1IDEuODk2ODg3QzIuODEzNDUgMS44NjUwMDYgMi44MDU0NzkgMS44NTcwMzYgMi43MDE4NjggMS43NTM0MjVDMS42MDk5NjMgMC43MjUyOCAxLjMzODk3OSAtMC43NTcxNjEgMS4zMzg5NzkgLTEuOTkyNTI4QzEuMzM4OTc5IC00LjI4NzkyIDIuMjg3NDIyIC01LjM2Mzg4NSAyLjY5Mzg5OCAtNS43MzA1MTFDMi44MDU0NzkgLTUuODM0MTIyIDIuODEzNDUgLTUuODQyMDkyIDIuODEzNDUgLTUuODgxOTQzUzIuNzgxNTY5IC01Ljk3NzU4NCAyLjcwMTg2OCAtNS45Nzc1ODRDMi41NzQzNDYgLTUuOTc3NTg0IDIuMTc1ODQxIC01LjU3MTEwOCAyLjExMjA4IC01LjQ5OTM3N0MxLjA0NDA4NSAtNC4zODM1NjIgMC44MjA5MjIgLTIuOTQ4OTQxIDAuODIwOTIyIC0xLjk5MjUyOEMwLjgyMDkyMiAtMC4yMDcyMjMgMS41NzAxMTIgMS4yMjczOTcgMi42NTQwNDcgMS45OTI1MjhaJyBpZD0nZzUtNDAnLz4KPHBhdGggZD0nTTIuNDYyNzY1IC0xLjk5MjUyOEMyLjQ2Mjc2NSAtMi43NDk2ODkgMi4zMzUyNDMgLTMuNjU4MjgxIDEuODQxMDk2IC00LjU5ODc1NUMxLjQ1MDU2IC01LjMzMjAwNSAwLjcyNTI4IC01Ljk3NzU4NCAwLjU4MTgxOCAtNS45Nzc1ODRDMC41MDIxMTcgLTUuOTc3NTg0IDAuNDc4MjA3IC01LjkyMTc5MyAwLjQ3ODIwNyAtNS44ODE5NDNDMC40NzgyMDcgLTUuODUwMDYyIDAuNDc4MjA3IC01LjgzNDEyMiAwLjU3Mzg0OCAtNS43Mzg0ODFDMS42ODk2NjQgLTQuNjc4NDU2IDEuOTQ0NzA3IC0zLjIxOTkyNSAxLjk0NDcwNyAtMS45OTI1MjhDMS45NDQ3MDcgMC4yOTQ4OTQgMC45OTYyNjQgMS4zNzg4MjkgMC41ODk3ODggMS43NDU0NTVDMC40ODYxNzcgMS44NDkwNjYgMC40NzgyMDcgMS44NTcwMzYgMC40NzgyMDcgMS44OTY4ODdTMC41MDIxMTcgMS45OTI1MjggMC41ODE4MTggMS45OTI1MjhDMC43MDkzNCAxLjk5MjUyOCAxLjEwNzg0NiAxLjU4NjA1MiAxLjE3MTYwNiAxLjUxNDMyMUMyLjIzOTYwMSAwLjM5ODUwNiAyLjQ2Mjc2NSAtMS4wMzYxMTUgMi40NjI3NjUgLTEuOTkyNTI4WicgaWQ9J2c1LTQxJy8+CjxwYXRoIGQ9J00zLjg5NzM4NSAtMi41NDI0NjZDMy44OTczODUgLTMuMzk1MjY4IDMuODA5NzE0IC0zLjkxMzMyNSAzLjU0NjcgLTQuNDIzNDEyQzMuMTk2MDE1IC01LjEyNDc4MiAyLjU1MDQzNiAtNS4zMDAxMjUgMi4xMTIwOCAtNS4zMDAxMjVDMS4xMDc4NDYgLTUuMzAwMTI1IDAuNzQxMjIgLTQuNTUwOTM0IDAuNjI5NjM5IC00LjMyNzc3MUMwLjM0MjcxNSAtMy43NDU5NTMgMC4zMjY3NzUgLTIuOTU2OTEyIDAuMzI2Nzc1IC0yLjU0MjQ2NkMwLjMyNjc3NSAtMi4wMTY0MzggMC4zNTA2ODUgLTEuMjExNDU3IDAuNzMzMjUgLTAuNTczODQ4QzEuMDk5ODc1IDAuMDE1OTQgMS42ODk2NjQgMC4xNjczNzIgMi4xMTIwOCAwLjE2NzM3MkMyLjQ5NDY0NSAwLjE2NzM3MiAzLjE4MDA3NSAwLjA0NzgyMSAzLjU3ODU4IC0wLjc0MTIyQzMuODczNDc0IC0xLjMxNTA2OCAzLjg5NzM4NSAtMi4wMjQ0MDggMy44OTczODUgLTIuNTQyNDY2Wk0yLjExMjA4IC0wLjA1NTc5MUMxLjg0MTA5NiAtMC4wNTU3OTEgMS4yOTExNTggLTAuMTgzMzEzIDEuMTIzNzg2IC0xLjAyMDE3NEMxLjAzNjExNSAtMS40NzQ0NzEgMS4wMzYxMTUgLTIuMjIzNjYxIDEuMDM2MTE1IC0yLjYzODEwN0MxLjAzNjExNSAtMy4xODgwNDUgMS4wMzYxMTUgLTMuNzQ1OTUzIDEuMTIzNzg2IC00LjE4NDMwOUMxLjI5MTE1OCAtNC45OTcyNiAxLjkxMjgyNyAtNS4wNzY5NjEgMi4xMTIwOCAtNS4wNzY5NjFDMi4zODMwNjQgLTUuMDc2OTYxIDIuOTMzMDAxIC00Ljk0MTQ2OSAzLjA5MjQwMyAtNC4yMTYxODlDMy4xODgwNDUgLTMuNzc3ODMzIDMuMTg4MDQ1IC0zLjE4MDA3NSAzLjE4ODA0NSAtMi42MzgxMDdDMy4xODgwNDUgLTIuMTY3ODcgMy4xODgwNDUgLTEuNDUwNTYgMy4wOTI0MDMgLTEuMDA0MjM0QzIuOTI1MDMxIC0wLjE2NzM3MiAyLjM3NTA5MyAtMC4wNTU3OTEgMi4xMTIwOCAtMC4wNTU3OTFaJyBpZD0nZzUtNDgnLz4KPHBhdGggZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2IC0wLjUzNzk4MyAxLjgxNzE4NiAtMi45NzY4MzdDMS44MTcxODYgLTUuMjk2MTM5IDIuMzc5MDc4IC03LjI5MjY1MyAzLjc2NTg3OCAtOC43MDMzNjJDMy44ODU0MyAtOC44MTA5NTkgMy44ODU0MyAtOC44MzQ4NjkgMy44ODU0MyAtOC44NzA3MzVDMy44ODU0MyAtOC45NDI0NjYgMy44MjU2NTQgLTguOTY2Mzc2IDMuNzc3ODMzIC04Ljk2NjM3NkMzLjYyMjQxNiAtOC45NjYzNzYgMi42NDIwOTIgLTguMTA1NjA0IDIuMDU2Mjg5IC02LjkzMzk5OEMxLjQ0NjU3NSAtNS43MjY1MjYgMS4xNzE2MDYgLTQuNDQ3MzIzIDEuMTcxNjA2IC0yLjk3NjgzN0MxLjE3MTYwNiAtMS45MTI4MjcgMS4zMzg5NzkgLTAuNDkwMTYyIDEuOTYwNjQ4IDAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonIGlkPSdnNi00MCcvPgo8cGF0aCBkPSdNMy4zNzEzNTcgLTIuOTc2ODM3QzMuMzcxMzU3IC0zLjg4NTQzIDMuMjUxODA2IC01LjM2Nzg3IDIuNTgyMzE2IC02Ljc1NDY3QzEuODc2OTYxIC04LjE4OTI5IDAuODk2NjM4IC04Ljk2NjM3NiAwLjc2NTEzMSAtOC45NjYzNzZDMC43MTczMSAtOC45NjYzNzYgMC42NTc1MzQgLTguOTQyNDY2IDAuNjU3NTM0IC04Ljg3MDczNUMwLjY1NzUzNCAtOC44MzQ4NjkgMC42NTc1MzQgLTguODEwOTU5IDAuODYwNzcyIC04LjYwNzcyMUMyLjA1NjI4OSAtNy40MDAyNDkgMi43MjU3NzggLTUuNDI3NjQ2IDIuNzI1Nzc4IC0yLjk4ODc5MkMyLjcyNTc3OCAtMC42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgMC43NzcwODYgMi43Mzc3MzNDMC42NTc1MzQgMi44NDUzMyAwLjY1NzUzNCAyLjg2OTI0IDAuNjU3NTM0IDIuOTA1MTA2QzAuNjU3NTM0IDIuOTc2ODM3IDAuNzE3MzEgMy4wMDA3NDcgMC43NjUxMzEgMy4wMDA3NDdDMC45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgMC45NjgzNjlDMy4wOTYzODkgLTAuMjUxMDU5IDMuMzcxMzU3IC0xLjU0MjIxNyAzLjM3MTM1NyAtMi45NzY4MzdaJyBpZD0nZzYtNDEnLz4KPHBhdGggZD0nTTQuNzcwMTEyIC0yLjc2MTY0NEg4LjA2OTczOEM4LjIzNzExMSAtMi43NjE2NDQgOC40NTIzMDQgLTIuNzYxNjQ0IDguNDUyMzA0IC0yLjk3NjgzN0M4LjQ1MjMwNCAtMy4yMDM5ODUgOC4yNDkwNjYgLTMuMjAzOTg1IDguMDY5NzM4IC0zLjIwMzk4NUg0Ljc3MDExMlYtNi41MDM2MTFDNC43NzAxMTIgLTYuNjcwOTg0IDQuNzcwMTEyIC02Ljg4NjE3NyA0LjU1NDkxOSAtNi44ODYxNzdDNC4zMjc3NzEgLTYuODg2MTc3IDQuMzI3NzcxIC02LjY4MjkzOSA0LjMyNzc3MSAtNi41MDM2MTFWLTMuMjAzOTg1SDEuMDI4MTQ0QzAuODYwNzcyIC0zLjIwMzk4NSAwLjY0NTU3OSAtMy4yMDM5ODUgMC42NDU1NzkgLTIuOTg4NzkyQzAuNjQ1NTc5IC0yLjc2MTY0NCAwLjg0ODgxNyAtMi43NjE2NDQgMS4wMjgxNDQgLTIuNzYxNjQ0SDQuMzI3NzcxVjAuNTM3OTgzQzQuMzI3NzcxIDAuNzA1MzU1IDQuMzI3NzcxIDAuOTIwNTQ4IDQuNTQyOTY0IDAuOTIwNTQ4QzQuNzcwMTEyIDAuOTIwNTQ4IDQuNzcwMTEyIDAuNzE3MzEgNC43NzAxMTIgMC41Mzc5ODNWLTIuNzYxNjQ0WicgaWQ9J2c2LTQzJy8+CjxwYXRoIGQ9J00zLjQ0MzA4OCAtNy42NjMyNjNDMy40NDMwODggLTcuOTM4MjMyIDMuNDQzMDg4IC03Ljk1MDE4NyAzLjIwMzk4NSAtNy45NTAxODdDMi45MTcwNjEgLTcuNjI3Mzk3IDIuMzE5MzAzIC03LjE4NTA1NiAxLjA4NzkyIC03LjE4NTA1NlYtNi44MzgzNTZDMS4zNjI4ODkgLTYuODM4MzU2IDEuOTYwNjQ4IC02LjgzODM1NiAyLjYxODE4MiAtNy4xNDkxOTFWLTAuOTIwNTQ4QzIuNjE4MTgyIC0wLjQ5MDE2MiAyLjU4MjMxNiAtMC4zNDY3IDEuNTMwMjYyIC0wLjM0NjdIMS4xNTk2NTFWMEMxLjQ4MjQ0MSAtMC4wMjM5MSAyLjY0MjA5MiAtMC4wMjM5MSAzLjAzNjYxMyAtMC4wMjM5MVM0LjU3ODgyOSAtMC4wMjM5MSA0LjkwMTYxOSAwVi0wLjM0NjdINC41MzEwMDlDMy40Nzg5NTQgLTAuMzQ2NyAzLjQ0MzA4OCAtMC40OTAxNjIgMy40NDMwODggLTAuOTIwNTQ4Vi03LjY2MzI2M1onIGlkPSdnNi00OScvPgo8cGF0aCBkPSdNOC4wNjk3MzggLTMuODczNDc0QzguMjM3MTExIC0zLjg3MzQ3NCA4LjQ1MjMwNCAtMy44NzM0NzQgOC40NTIzMDQgLTQuMDg4NjY3QzguNDUyMzA0IC00LjMxNTgxNiA4LjI0OTA2NiAtNC4zMTU4MTYgOC4wNjk3MzggLTQuMzE1ODE2SDEuMDI4MTQ0QzAuODYwNzcyIC00LjMxNTgxNiAwLjY0NTU3OSAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMTAwNjIzQzAuNjQ1NTc5IC0zLjg3MzQ3NCAwLjg0ODgxNyAtMy44NzM0NzQgMS4wMjgxNDQgLTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOCAtMS42NDk4MTNDOC4yMzcxMTEgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS44NjUwMDZDOC40NTIzMDQgLTIuMDkyMTU0IDguMjQ5MDY2IC0yLjA5MjE1NCA4LjA2OTczOCAtMi4wOTIxNTRIMS4wMjgxNDRDMC44NjA3NzIgLTIuMDkyMTU0IDAuNjQ1NTc5IC0yLjA5MjE1NCAwLjY0NTU3OSAtMS44NzY5NjFDMC42NDU1NzkgLTEuNjQ5ODEzIDAuODQ4ODE3IC0xLjY0OTgxMyAxLjAyODE0NCAtMS42NDk4MTNIOC4wNjk3MzhaJyBpZD0nZzYtNjEnLz4KPHBhdGggZD0nTTIuOTg4NzkyIDIuOTg4NzkyVjIuNTQ2NDUxSDEuODI5MTQxVi04LjUyNDAzNUgyLjk4ODc5MlYtOC45NjYzNzZIMS4zODY4VjIuOTg4NzkySDIuOTg4NzkyWicgaWQ9J2c2LTkxJy8+CjxwYXRoIGQ9J00xLjg1MzA1MSAtOC45NjYzNzZIMC4yNTEwNTlWLTguNTI0MDM1SDEuNDEwNzFWMi41NDY0NTFIMC4yNTEwNTlWMi45ODg3OTJIMS44NTMwNTFWLTguOTY2Mzc2WicgaWQ9J2c2LTkzJy8+CjxwYXRoIGQ9J00yLjA4MDE5OSAtNy4zNjQzODRDMi4wODAxOTkgLTcuNjc1MjE4IDEuODI5MTQxIC03Ljk1MDE4NyAxLjQ5NDM5NiAtNy45NTAxODdDMS4xODM1NjIgLTcuOTUwMTg3IDAuOTIwNTQ4IC03LjY5OTEyOCAwLjkyMDU0OCAtNy4zNzYzMzlDMC45MjA1NDggLTcuMDE3Njg0IDEuMjA3NDcyIC02Ljc5MDUzNSAxLjQ5NDM5NiAtNi43OTA1MzVDMS44NjUwMDYgLTYuNzkwNTM1IDIuMDgwMTk5IC03LjEwMTM3IDIuMDgwMTk5IC03LjM2NDM4NFpNMC40MzAzODYgLTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE5NTUxNyAtNC43OTQwMjIgMS4zMDMxMTMgLTQuNzIyMjkxIDEuMzAzMTEzIC00LjEzNjQ4OFYtMC44ODQ2ODJDMS4zMDMxMTMgLTAuMzQ2NyAxLjE3MTYwNiAtMC4zNDY3IDAuMzk0NTIxIC0wLjM0NjdWMEMwLjcyOTI2NSAtMC4wMjM5MSAxLjMwMzExMyAtMC4wMjM5MSAxLjY0OTgxMyAtMC4wMjM5MUMxLjc4MTMyIC0wLjAyMzkxIDIuNDc0NzIgLTAuMDIzOTEgMi44ODExOTYgMFYtMC4zNDY3QzIuMTA0MTEgLTAuMzQ2NyAyLjA1NjI4OSAtMC40MDY0NzYgMi4wNTYyODkgLTAuODcyNzI3Vi01LjI3MjIyOUwwLjQzMDM4NiAtNS4xNDA3MjJaJyBpZD0nZzYtMTA1Jy8+CjxwYXRoIGQ9J004LjU3MTg1NiAtMi45MDUxMDZDOC41NzE4NTYgLTQuMDE2OTM2IDguNTcxODU2IC00LjM1MTY4MSA4LjI5Njg4NyAtNC43MzQyNDdDNy45NTAxODcgLTUuMjAwNDk4IDcuMzg4Mjk0IC01LjI3MjIyOSA2Ljk4MTgxOCAtNS4yNzIyMjlDNS45ODk1MzkgLTUuMjcyMjI5IDUuNDg3NDIyIC00LjU1NDkxOSA1LjI5NjEzOSAtNC4wODg2NjdDNS4xMjg3NjcgLTUuMDA5MjE1IDQuNDgzMTg4IC01LjI3MjIyOSAzLjczMDAxMiAtNS4yNzIyMjlDMi41NzAzNjEgLTUuMjcyMjI5IDIuMTE2MDY1IC00LjI3OTk1IDIuMDIwNDIzIC00LjA0MDg0N0gyLjAwODQ2OFYtNS4yNzIyMjlMMC4zODI1NjUgLTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE5NTUxNyAtNC43OTQwMjIgMS4yOTExNTggLTQuNzEwMzM2IDEuMjkxMTU4IC00LjEyNDUzM1YtMC44ODQ2ODJDMS4yOTExNTggLTAuMzQ2NyAxLjE1OTY1MSAtMC4zNDY3IDAuMzgyNTY1IC0wLjM0NjdWMEMwLjY5MzQgLTAuMDIzOTEgMS4zMzg5NzkgLTAuMDIzOTEgMS42NzM3MjQgLTAuMDIzOTFDMi4wMjA0MjMgLTAuMDIzOTEgMi42NjYwMDIgLTAuMDIzOTEgMi45NzY4MzcgMFYtMC4zNDY3QzIuMjExNzA2IC0wLjM0NjcgMi4wNjgyNDQgLTAuMzQ2NyAyLjA2ODI0NCAtMC44ODQ2ODJWLTMuMTA4MzQ0QzIuMDY4MjQ0IC00LjM2MzYzNiAyLjg5MzE1MSAtNS4wMzMxMjYgMy42MzQzNzEgLTUuMDMzMTI2UzQuNTQyOTY0IC00LjQyMzQxMiA0LjU0Mjk2NCAtMy42OTQxNDdWLTAuODg0NjgyQzQuNTQyOTY0IC0wLjM0NjcgNC40MTE0NTcgLTAuMzQ2NyAzLjYzNDM3MSAtMC4zNDY3VjBDMy45NDUyMDUgLTAuMDIzOTEgNC41OTA3ODUgLTAuMDIzOTEgNC45MjU1MjkgLTAuMDIzOTFDNS4yNzIyMjkgLTAuMDIzOTEgNS45MTc4MDggLTAuMDIzOTEgNi4yMjg2NDMgMFYtMC4zNDY3QzUuNDYzNTEyIC0wLjM0NjcgNS4zMjAwNSAtMC4zNDY3IDUuMzIwMDUgLTAuODg0NjgyVi0zLjEwODM0NEM1LjMyMDA1IC00LjM2MzYzNiA2LjE0NDk1NiAtNS4wMzMxMjYgNi44ODYxNzcgLTUuMDMzMTI2UzcuNzk0NzcgLTQuNDIzNDEyIDcuNzk0NzcgLTMuNjk0MTQ3Vi0wLjg4NDY4MkM3Ljc5NDc3IC0wLjM0NjcgNy42NjMyNjMgLTAuMzQ2NyA2Ljg4NjE3NyAtMC4zNDY3VjBDNy4xOTcwMTEgLTAuMDIzOTEgNy44NDI1OSAtMC4wMjM5MSA4LjE3NzMzNSAtMC4wMjM5MUM4LjUyNDAzNSAtMC4wMjM5MSA5LjE2OTYxNCAtMC4wMjM5MSA5LjQ4MDQ0OCAwVi0wLjM0NjdDOC44ODI2OSAtMC4zNDY3IDguNTgzODExIC0wLjM0NjcgOC41NzE4NTYgLTAuNzA1MzU1Vi0yLjkwNTEwNlonIGlkPSdnNi0xMDknLz4KPHBhdGggZD0nTTUuMzIwMDUgLTIuOTA1MTA2QzUuMzIwMDUgLTQuMDE2OTM2IDUuMzIwMDUgLTQuMzUxNjgxIDUuMDQ1MDgxIC00LjczNDI0N0M0LjY5ODM4MSAtNS4yMDA0OTggNC4xMzY0ODggLTUuMjcyMjI5IDMuNzMwMDEyIC01LjI3MjIyOUMyLjU3MDM2MSAtNS4yNzIyMjkgMi4xMTYwNjUgLTQuMjc5OTUgMi4wMjA0MjMgLTQuMDQwODQ3SDIuMDA4NDY4Vi01LjI3MjIyOUwwLjM4MjU2NSAtNS4xNDA3MjJWLTQuNzk0MDIyQzEuMTk1NTE3IC00Ljc5NDAyMiAxLjI5MTE1OCAtNC43MTAzMzYgMS4yOTExNTggLTQuMTI0NTMzVi0wLjg4NDY4MkMxLjI5MTE1OCAtMC4zNDY3IDEuMTU5NjUxIC0wLjM0NjcgMC4zODI1NjUgLTAuMzQ2N1YwQzAuNjkzNCAtMC4wMjM5MSAxLjMzODk3OSAtMC4wMjM5MSAxLjY3MzcyNCAtMC4wMjM5MUMyLjAyMDQyMyAtMC4wMjM5MSAyLjY2NjAwMiAtMC4wMjM5MSAyLjk3NjgzNyAwVi0wLjM0NjdDMi4yMTE3MDYgLTAuMzQ2NyAyLjA2ODI0NCAtMC4zNDY3IDIuMDY4MjQ0IC0wLjg4NDY4MlYtMy4xMDgzNDRDMi4wNjgyNDQgLTQuMzYzNjM2IDIuODkzMTUxIC01LjAzMzEyNiAzLjYzNDM3MSAtNS4wMzMxMjZTNC41NDI5NjQgLTQuNDIzNDEyIDQuNTQyOTY0IC0zLjY5NDE0N1YtMC44ODQ2ODJDNC41NDI5NjQgLTAuMzQ2NyA0LjQxMTQ1NyAtMC4zNDY3IDMuNjM0MzcxIC0wLjM0NjdWMEMzLjk0NTIwNSAtMC4wMjM5MSA0LjU5MDc4NSAtMC4wMjM5MSA0LjkyNTUyOSAtMC4wMjM5MUM1LjI3MjIyOSAtMC4wMjM5MSA1LjkxNzgwOCAtMC4wMjM5MSA2LjIyODY0MyAwVi0wLjM0NjdDNS42MzA4ODQgLTAuMzQ2NyA1LjMzMjAwNSAtMC4zNDY3IDUuMzIwMDUgLTAuNzA1MzU1Vi0yLjkwNTEwNlonIGlkPSdnNi0xMTAnLz4KPHBhdGggZD0nTTUuMzc5ODI2IC00LjczNDI0N0M1LjQ3NTQ2NyAtNC43ODIwNjcgNS41MzEyNTggLTQuODIxOTE4IDUuNTMxMjU4IC00LjkwOTU4OVM1LjQ1OTUyNyAtNS4wNjg5OTEgNS4zNzE4NTYgLTUuMDY4OTkxQzUuMzMyMDA1IC01LjA2ODk5MSA1LjI2MDI3NCAtNS4wMzcxMTEgNS4yMjgzOTQgLTUuMDIxMTcxTDAuODIwOTIyIC0yLjk0MDk3MUMwLjY4NTQzIC0yLjg3NzIxIDAuNjYxNTE5IC0yLjgyMTQyIDAuNjYxNTE5IC0yLjc1NzY1OVMwLjY5MzQgLTIuNjM4MTA3IDAuODIwOTIyIC0yLjU4MjMxNkw1LjIyODM5NCAtMC41MTAwODdDNS4zMzIwMDUgLTAuNDU0Mjk2IDUuMzQ3OTQ1IC0wLjQ1NDI5NiA1LjM3MTg1NiAtMC40NTQyOTZDNS40NTk1MjcgLTAuNDU0Mjk2IDUuNTMxMjU4IC0wLjUyNjAyNyA1LjUzMTI1OCAtMC42MTM2OTlDNS41MzEyNTggLTAuNzE3MzEgNS40NTk1MjcgLTAuNzQ5MTkxIDUuMzcxODU2IC0wLjc4OTA0MUwxLjE5NTUxNyAtMi43NTc2NTlMNS4zNzk4MjYgLTQuNzM0MjQ3Wk01LjIyODM5NCAxLjAzNjExNUM1LjMzMjAwNSAxLjA5MTkwNSA1LjM0Nzk0NSAxLjA5MTkwNSA1LjM3MTg1NiAxLjA5MTkwNUM1LjQ1OTUyNyAxLjA5MTkwNSA1LjUzMTI1OCAxLjAyMDE3NCA1LjUzMTI1OCAwLjkzMjUwM0M1LjUzMTI1OCAwLjgyODg5MiA1LjQ1OTUyNyAwLjc5NzAxMSA1LjM3MTg1NiAwLjc1NzE2MUwwLjk3MjM1NCAtMS4zMTUwNjhDMC44Njg3NDIgLTEuMzcwODU5IDAuODUyODAyIC0xLjM3MDg1OSAwLjgyMDkyMiAtMS4zNzA4NTlDMC43MjUyOCAtMS4zNzA4NTkgMC42NjE1MTkgLTEuMjk5MTI4IDAuNjYxNTE5IC0xLjIxMTQ1N0MwLjY2MTUxOSAtMS4xNDc2OTYgMC42OTM0IC0xLjA5MTkwNSAwLjgyMDkyMiAtMS4wMzYxMTVMNS4yMjgzOTQgMS4wMzYxMTVaJyBpZD0nZzAtNTQnLz4KPHBhdGggZD0nTTIuMTEyMDggLTMuNzc3ODMzQzIuMTUxOTMgLTMuODgxNDQ1IDIuMTgzODExIC0zLjkzNzIzNSAyLjE4MzgxMSAtNC4wMTY5MzZDMi4xODM4MTEgLTQuMjc5OTUgMS45NDQ3MDcgLTQuNDU1MjkzIDEuNzIxNTQ0IC00LjQ1NTI5M0MxLjQwMjc0IC00LjQ1NTI5MyAxLjMxNTA2OCAtNC4xNzYzMzkgMS4yODMxODggLTQuMDY0NzU3TDAuMjcwOTg0IC0wLjYyOTYzOUMwLjIzOTEwMyAtMC41MzM5OTggMC4yMzkxMDMgLTAuNTEwMDg3IDAuMjM5MTAzIC0wLjUwMjExN0MwLjIzOTEwMyAtMC40MzAzODYgMC4yODY5MjQgLTAuNDE0NDQ2IDAuMzY2NjI1IC0wLjM5MDUzNUMwLjUxMDA4NyAtMC4zMjY3NzUgMC41MjYwMjcgLTAuMzI2Nzc1IDAuNTQxOTY4IC0wLjMyNjc3NUMwLjU2NTg3OCAtMC4zMjY3NzUgMC42MTM2OTkgLTAuMzI2Nzc1IDAuNjY5NDg5IC0wLjQ2MjI2N0wyLjExMjA4IC0zLjc3NzgzM1onIGlkPSdnMS00OCcvPgo8cGF0aCBkPSdNNS43MDY2IC00LjExMjU3OEM1LjgwMjI0MiAtNC4xNjAzOTkgNS44NzM5NzMgLTQuMjA4MjE5IDUuODczOTczIC00LjMxMTgzMVM1Ljc5NDI3MSAtNC40OTUxNDMgNS42OTA2NiAtNC40OTUxNDNDNS42NjY3NSAtNC40OTUxNDMgNS42NTA4MDkgLTQuNDk1MTQzIDUuNTQ3MTk4IC00LjQzOTM1MkwwLjg2ODc0MiAtMi4xOTE3ODFDMC43NzMxMDEgLTIuMTQzOTYgMC43MDEzNyAtMi4wOTYxMzkgMC43MDEzNyAtMS45OTI1MjhTMC43NzMxMDEgLTEuODQxMDk2IDAuODY4NzQyIC0xLjc5MzI3NUw1LjU0NzE5OCAwLjQ1NDI5NkM1LjY1MDgwOSAwLjUxMDA4NyA1LjY2Njc1IDAuNTEwMDg3IDUuNjkwNjYgMC41MTAwODdDNS43OTQyNzEgMC41MTAwODcgNS44NzM5NzMgMC40MzAzODYgNS44NzM5NzMgMC4zMjY3NzVTNS44MDIyNDIgMC4xNzUzNDIgNS43MDY2IDAuMTI3NTIyTDEuMzA3MDk4IC0xLjk5MjUyOEw1LjcwNjYgLTQuMTEyNTc4WicgaWQ9J2czLTYwJy8+CjxwYXRoIGQ9J00yLjMyNzI3MyAtNS4yOTIxNTRDMi4zMzUyNDMgLTUuMzA4MDk1IDIuMzU5MTUzIC01LjQxMTcwNiAyLjM1OTE1MyAtNS40MTk2NzZDMi4zNTkxNTMgLTUuNDU5NTI3IDIuMzI3MjczIC01LjUzMTI1OCAyLjIzMTYzMSAtNS41MzEyNThDMi4xOTk3NTEgLTUuNTMxMjU4IDEuOTUyNjc3IC01LjUwNzM0NyAxLjc2OTM2NSAtNS40OTE0MDdMMS4zMjMwMzkgLTUuNDU5NTI3QzEuMTQ3Njk2IC01LjQ0MzU4NyAxLjA2Nzk5NSAtNS40MzU2MTYgMS4wNjc5OTUgLTUuMjkyMTU0QzEuMDY3OTk1IC01LjE4MDU3MyAxLjE3OTU3NyAtNS4xODA1NzMgMS4yNzUyMTggLTUuMTgwNTczQzEuNjU3NzgzIC01LjE4MDU3MyAxLjY1Nzc4MyAtNS4xMzI3NTIgMS42NTc3ODMgLTUuMDYxMDIxQzEuNjU3NzgzIC01LjAzNzExMSAxLjY1Nzc4MyAtNS4wMjExNzEgMS42MTc5MzMgLTQuODc3NzA5TDAuNDg2MTc3IC0wLjM0MjcxNUMwLjQ1NDI5NiAtMC4yMjMxNjMgMC40NTQyOTYgLTAuMTc1MzQyIDAuNDU0Mjk2IC0wLjE2NzM3MkMwLjQ1NDI5NiAtMC4wMzE4OCAwLjU2NTg3OCAwLjA3OTcwMSAwLjcxNzMxIDAuMDc5NzAxQzAuOTg4Mjk0IDAuMDc5NzAxIDEuMDUyMDU1IC0wLjE3NTM0MiAxLjA4MzkzNSAtMC4yODY5MjRDMS4xNjM2MzYgLTAuNjIxNjY5IDEuMzcwODU5IC0xLjQ2NjUwMSAxLjQ1ODUzMSAtMS44MDEyNDVDMS44OTY4ODcgLTEuNzUzNDI1IDIuNDMwODg0IC0xLjYwMTk5MyAyLjQzMDg4NCAtMS4xNDc2OTZDMi40MzA4ODQgLTEuMTA3ODQ2IDIuNDMwODg0IC0xLjA2Nzk5NSAyLjQxNDk0NCAtMC45ODgyOTRDMi4zOTEwMzQgLTAuODg0NjgyIDIuMzc1MDkzIC0wLjc3MzEwMSAyLjM3NTA5MyAtMC43MzMyNUMyLjM3NTA5MyAtMC4yNjMwMTQgMi43MjU3NzggMC4wNzk3MDEgMy4xODgwNDUgMC4wNzk3MDFDMy41MjI3OSAwLjA3OTcwMSAzLjczMDAxMiAtMC4xNjczNzIgMy44MzM2MjQgLTAuMzE4ODA0QzQuMDI0OTA3IC0wLjYxMzY5OSA0LjE1MjQyOCAtMS4wOTE5MDUgNC4xNTI0MjggLTEuMTM5NzI2QzQuMTUyNDI4IC0xLjIxOTQyNyA0LjA4ODY2NyAtMS4yNDMzMzcgNC4wMzI4NzcgLTEuMjQzMzM3QzMuOTM3MjM1IC0xLjI0MzMzNyAzLjkyMTI5NSAtMS4xOTU1MTcgMy44ODk0MTUgLTEuMDUyMDU1QzMuNzg1ODAzIC0wLjY3NzQ2IDMuNTc4NTggLTAuMTQzNDYyIDMuMjAzOTg1IC0wLjE0MzQ2MkMyLjk5Njc2MiAtMC4xNDM0NjIgMi45NDg5NDEgLTAuMzE4ODA0IDIuOTQ4OTQxIC0wLjUzMzk5OEMyLjk0ODk0MSAtMC42Mzc2MDkgMi45NTY5MTIgLTAuNzMzMjUgMi45OTY3NjIgLTAuOTE2NTYzQzMuMDA0NzMyIC0wLjk0ODQ0MyAzLjAzNjYxMyAtMS4wNzU5NjUgMy4wMzY2MTMgLTEuMTYzNjM2QzMuMDM2NjEzIC0xLjgxNzE4NiAyLjIxNTY5MSAtMS45NjA2NDggMS44MDkyMTUgLTIuMDE2NDM4QzIuMTA0MTEgLTIuMTkxNzgxIDIuMzc1MDkzIC0yLjQ2Mjc2NSAyLjQ3MDczNSAtMi41NjYzNzZDMi45MDkwOTEgLTIuOTk2NzYyIDMuMjY3NzQ2IC0zLjI5MTY1NiAzLjY1MDMxMSAtMy4yOTE2NTZDMy43NTM5MjMgLTMuMjkxNjU2IDMuODQ5NTY0IC0zLjI2Nzc0NiAzLjkxMzMyNSAtMy4xODgwNDVDMy40ODI5MzkgLTMuMTMyMjU0IDMuNDgyOTM5IC0yLjc1NzY1OSAzLjQ4MjkzOSAtMi43NDk2ODlDMy40ODI5MzkgLTIuNTc0MzQ2IDMuNjE4NDMxIC0yLjQ1NDc5NSAzLjc5Mzc3MyAtMi40NTQ3OTVDNC4wMDg5NjYgLTIuNDU0Nzk1IDQuMjQ4MDcgLTIuNjMwMTM3IDQuMjQ4MDcgLTIuOTU2OTEyQzQuMjQ4MDcgLTMuMjI3ODk1IDQuMDU2Nzg3IC0zLjUxNDgxOSAzLjY1ODI4MSAtMy41MTQ4MTlDMy4xOTYwMTUgLTMuNTE0ODE5IDIuNzgxNTY5IC0zLjE2NDEzNCAyLjMyNzI3MyAtMi43MDk4MzhDMS44NjUwMDYgLTIuMjU1NTQyIDEuNjY1NzUzIC0yLjE2Nzg3IDEuNTM4MjMyIC0yLjExMjA4TDIuMzI3MjczIC01LjI5MjE1NFonIGlkPSdnMy0xMDcnLz4KPHBhdGggZD0nTTIuMDg4MTY5IC01LjI5MjE1NEMyLjA5NjEzOSAtNS4zMDgwOTUgMi4xMjAwNSAtNS40MTE3MDYgMi4xMjAwNSAtNS40MTk2NzZDMi4xMjAwNSAtNS40NTk1MjcgMi4wODgxNjkgLTUuNTMxMjU4IDEuOTkyNTI4IC01LjUzMTI1OEwxLjE4NzU0NyAtNS40Njc0OTdDMC44OTI2NTMgLTUuNDQzNTg3IDAuODI4ODkyIC01LjQzNTYxNiAwLjgyODg5MiAtNS4yOTIxNTRDMC44Mjg4OTIgLTUuMTgwNTczIDAuOTQwNDczIC01LjE4MDU3MyAxLjAzNjExNSAtNS4xODA1NzNDMS40MTg2OCAtNS4xODA1NzMgMS40MTg2OCAtNS4xMzI3NTIgMS40MTg2OCAtNS4wNjEwMjFDMS40MTg2OCAtNS4wMzcxMTEgMS40MTg2OCAtNS4wMjExNzEgMS4zNzg4MjkgLTQuODc3NzA5TDAuMzkwNTM1IC0wLjkyNDUzM0MwLjM1ODY1NSAtMC43OTcwMTEgMC4zNTg2NTUgLTAuNjc3NDYgMC4zNTg2NTUgLTAuNjY5NDg5QzAuMzU4NjU1IC0wLjE3NTM0MiAwLjc2NTEzMSAwLjA3OTcwMSAxLjE2MzYzNiAwLjA3OTcwMUMxLjUwNjM1MSAwLjA3OTcwMSAxLjY4OTY2NCAtMC4xOTEyODMgMS43NzczMzUgLTAuMzY2NjI1QzEuOTIwNzk3IC0wLjYyOTYzOSAyLjA0MDM0OSAtMS4wOTk4NzUgMi4wNDAzNDkgLTEuMTM5NzI2QzIuMDQwMzQ5IC0xLjE4NzU0NyAyLjAxNjQzOCAtMS4yNDMzMzcgMS45MTI4MjcgLTEuMjQzMzM3QzEuODQxMDk2IC0xLjI0MzMzNyAxLjgxNzE4NiAtMS4yMDM0ODcgMS44MTcxODYgLTEuMTk1NTE3QzEuODAxMjQ1IC0xLjE3MTYwNiAxLjc2MTM5NSAtMS4wMjgxNDQgMS43Mzc0ODQgLTAuOTQwNDczQzEuNjE3OTMzIC0wLjQ3ODIwNyAxLjQ2NjUwMSAtMC4xNDM0NjIgMS4xNzk1NzcgLTAuMTQzNDYyQzAuOTg4Mjk0IC0wLjE0MzQ2MiAwLjkzMjUwMyAtMC4zMjY3NzUgMC45MzI1MDMgLTAuNTE4MDU3QzAuOTMyNTAzIC0wLjY2OTQ4OSAwLjk1NjQxMyAtMC43NTcxNjEgMC45ODAzMjQgLTAuODYwNzcyTDIuMDg4MTY5IC01LjI5MjE1NFonIGlkPSdnMy0xMDgnLz4KPHBhdGggZD0nTTMuNzkzNzczIC0zLjI4MzY4NkMzLjgwMTc0MyAtMy4zMTU1NjcgMy44MDk3MTQgLTMuMzYzMzg3IDMuODA5NzE0IC0zLjQwMzIzOEMzLjgwOTcxNCAtMy40NTEwNTkgMy43Nzc4MzMgLTMuNTE0ODE5IDMuNzA2MTAyIC0zLjUxNDgxOUMzLjYxMDQ2MSAtMy41MTQ4MTkgMy4yODM2ODYgLTMuMjAzOTg1IDMuMTU2MTY0IC0yLjk4MDgyMkMzLjA2ODQ5MyAtMy4xNTYxNjQgMi44MjkzOSAtMy41MTQ4MTkgMi4zMzUyNDMgLTMuNTE0ODE5QzEuMzg2OCAtMy41MTQ4MTkgMC4zNDI3MTUgLTIuNDA2OTc0IDAuMzQyNzE1IC0xLjIyNzM5N0MwLjM0MjcxNSAtMC4zOTg1MDYgMC44NzY3MTIgMC4wNzk3MDEgMS40OTA0MTEgMC4wNzk3MDFDMS44ODg5MTcgMC4wNzk3MDEgMi4yMTU2OTEgLTAuMTUxNDMyIDIuNDU0Nzk1IC0wLjM1ODY1NUMyLjQ0NjgyNCAtMC4zMzQ3NDUgMi4xOTk3NTEgMC42Njk0ODkgMi4xNjc4NyAwLjgwNDk4MUMyLjA0ODMxOSAxLjI2NzI0OCAyLjA0ODMxOSAxLjI3NTIxOCAxLjU0NjIwMiAxLjI4MzE4OEMxLjQ1MDU2IDEuMjgzMTg4IDEuMzQ2OTQ5IDEuMjgzMTg4IDEuMzQ2OTQ5IDEuNDM0NjJDMS4zNDY5NDkgMS40ODI0NDEgMS4zODY4IDEuNTQ2MjAyIDEuNDY2NTAxIDEuNTQ2MjAyQzEuNTcwMTEyIDEuNTQ2MjAyIDEuNzUzNDI1IDEuNTMwMjYyIDEuODU3MDM2IDEuNTIyMjkxSDIuMjc5NDUyQzIuOTE3MDYxIDEuNTIyMjkxIDMuMDYwNTIzIDEuNTQ2MjAyIDMuMTI0Mjg0IDEuNTQ2MjAyQzMuMTU2MTY0IDEuNTQ2MjAyIDMuMjc1NzE2IDEuNTQ2MjAyIDMuMjc1NzE2IDEuMzk0NzdDMy4yNzU3MTYgMS4yODMxODggMy4xNjQxMzQgMS4yODMxODggMy4wNjg0OTMgMS4yODMxODhDMi42ODU5MjggMS4yODMxODggMi42ODU5MjggMS4yMzUzNjcgMi42ODU5MjggMS4xNjM2MzZDMi42ODU5MjggMS4xNTU2NjYgMi42ODU5MjggMS4xMTU4MTYgMi43MTc4MDggMC45OTYyNjRMMy43OTM3NzMgLTMuMjgzNjg2Wk0yLjYxNDE5NyAtMC45ODgyOTRDMi41ODIzMTYgLTAuODY4NzQyIDIuNTgyMzE2IC0wLjg0NDgzMiAyLjQ0NjgyNCAtMC42OTM0QzIuMDMyMzc5IC0wLjIwNzIyMyAxLjY4MTY5NCAtMC4xNDM0NjIgMS41MTQzMjEgLTAuMTQzNDYyQzEuMTQ3Njk2IC0wLjE0MzQ2MiAwLjk2NDM4NCAtMC40NzgyMDcgMC45NjQzODQgLTAuODkyNjUzQzAuOTY0Mzg0IC0xLjI2NzI0OCAxLjE3OTU3NyAtMi4xMjAwNSAxLjM1NDkxOSAtMi40NzA3MzVDMS41ODYwNTIgLTIuOTU2OTEyIDEuOTc2NTg4IC0zLjI5MTY1NiAyLjM0MzIxMyAtMy4yOTE2NTZDMi44NzcyMSAtMy4yOTE2NTYgMy4wMTI3MDIgLTIuNjY5OTg4IDMuMDEyNzAyIC0yLjYxNDE5N0MzLjAxMjcwMiAtMi41ODIzMTYgMi45OTY3NjIgLTIuNTI2NTI2IDIuOTg4NzkyIC0yLjQ4NjY3NUwyLjYxNDE5NyAtMC45ODgyOTRaJyBpZD0nZzMtMTEzJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc2OS4xMzg5MjInIHhsaW5rOmhyZWY9JyNnNC03NycgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nODEuNzEyNTI5JyB4bGluazpocmVmPScjZzEtNDgnIHk9Jzg2LjcyMDEwMycvPgo8dXNlIHg9Jzg0LjUwNzYwNScgeGxpbms6aHJlZj0nI2c2LTQwJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PSc4OS4wNTk5MzEnIHhsaW5rOmhyZWY9JyNnNC0xMTMnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9Jzk0LjY3OTA4NycgeGxpbms6aHJlZj0nI2c0LTU5JyB5PSc5MS42NTYyODknLz4KPHVzZSB4PSc5OS45MjMyNDYnIHhsaW5rOmhyZWY9JyNnNC04MycgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMTA3LjgxODU2OScgeGxpbms6aHJlZj0nI2c2LTQxJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScxMjIuMzMzNTMxJyB4bGluazpocmVmPScjZzYtNjEnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzE0OS4xMDQxODknIHhsaW5rOmhyZWY9JyNnNi0xMDknIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzE1OC44NTkxNzMnIHhsaW5rOmhyZWY9JyNnNi0xMDUnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzE2Mi4xMTA4MzQnIHhsaW5rOmhyZWY9JyNnNi0xMTAnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzE0MS40MDA4MjMnIHhsaW5rOmhyZWY9JyNnNS00OCcgeT0nOTkuNjI2NDAxJy8+Cjx1c2UgeD0nMTQ1LjYzNTAwNicgeGxpbms6aHJlZj0nI2cwLTU0JyB5PSc5OS42MjY0MDEnLz4KPHVzZSB4PScxNTEuODM0MDA0JyB4bGluazpocmVmPScjZzMtMTA3JyB5PSc5OS42MjY0MDEnLz4KPHVzZSB4PScxNTYuNDU1NjE5JyB4bGluazpocmVmPScjZzMtNjAnIHk9Jzk5LjYyNjQwMScvPgo8dXNlIHg9JzE2My4wNDIxMjYnIHhsaW5rOmhyZWY9JyNnMy0xMDgnIHk9Jzk5LjYyNjQwMScvPgo8dXNlIHg9JzE2NS42NjQyNTEnIHhsaW5rOmhyZWY9JyNnNS00MCcgeT0nOTkuNjI2NDAxJy8+Cjx1c2UgeD0nMTY4Ljk1NzUwNCcgeGxpbms6aHJlZj0nI2czLTExMycgeT0nOTkuNjI2NDAxJy8+Cjx1c2UgeD0nMTczLjAyNDI1NScgeGxpbms6aHJlZj0nI2c1LTQxJyB5PSc5OS42MjY0MDEnLz4KPHVzZSB4PScxNzguMzEwMDA2JyB4bGluazpocmVmPScjZzItMTAyJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScxODQuMjg3NjA1JyB4bGluazpocmVmPScjZzQtNzcnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzE5Ni44NjEyMTInIHhsaW5rOmhyZWY9JyNnMS00OCcgeT0nODYuNzIwMTAzJy8+Cjx1c2UgeD0nMTk5LjY1NjI4OCcgeGxpbms6aHJlZj0nI2c2LTQwJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScyMDQuMjA4NjEzJyB4bGluazpocmVmPScjZzQtMTEzJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScyMDkuODI3NzcnIHhsaW5rOmhyZWY9JyNnNi05MScgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjEzLjA3OTQzMScgeGxpbms6aHJlZj0nI2c2LTQ5JyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScyMTguOTMyNDIxJyB4bGluazpocmVmPScjZzQtNTgnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzIyMi4xODQwODMnIHhsaW5rOmhyZWY9JyNnNC01OCcgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjI1LjQzNTc0NCcgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjMxLjkyNTI0OCcgeGxpbms6aHJlZj0nI2c2LTkzJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScyMzUuMTc2OTA5JyB4bGluazpocmVmPScjZzQtNTknIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzI0MC40MjEwNjgnIHhsaW5rOmhyZWY9JyNnNC04MycgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjQ4LjMxNjM5MScgeGxpbms6aHJlZj0nI2c2LTQxJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScyNTUuNTI1MzgnIHhsaW5rOmhyZWY9JyNnNi00MycgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjY3LjI4NjY5NScgeGxpbms6aHJlZj0nI2c2LTEwOScgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjc3LjA0MTY3OScgeGxpbms6aHJlZj0nI2c2LTEwNScgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjgwLjI5MzM0JyB4bGluazpocmVmPScjZzYtMTEwJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScyODYuNzk2NjYzJyB4bGluazpocmVmPScjZzYtNDAnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzI5MS4zNDg5ODknIHhsaW5rOmhyZWY9JyNnNC03NScgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMzAyLjE2NjY2OCcgeGxpbms6aHJlZj0nI2c2LTQwJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PSczMDYuNzE4OTk0JyB4bGluazpocmVmPScjZzQtMTEzJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PSczMTIuMzM4MTUnIHhsaW5rOmhyZWY9JyNnNC01OScgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMzE3LjU4MjMwOScgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMzI0LjA3MTgxMycgeGxpbms6aHJlZj0nI2c0LTU5JyB5PSc5MS42NTYyODknLz4KPHVzZSB4PSczMjkuMzE1OTcyJyB4bGluazpocmVmPScjZzQtODMnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzMzNy4yMTEyOTUnIHhsaW5rOmhyZWY9JyNnNi00MScgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMzQxLjc2MzYyMScgeGxpbms6aHJlZj0nI2c0LTU5JyB5PSc5MS42NTYyODknLz4KPHVzZSB4PSczNDcuMDA3NzgnIHhsaW5rOmhyZWY9JyNnNC0xMDgnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzM1MC43NTc1ODgnIHhsaW5rOmhyZWY9JyNnNi00MCcgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMzU1LjMwOTkxNCcgeGxpbms6aHJlZj0nI2c0LTExMycgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMzYwLjkyOTA3MScgeGxpbms6aHJlZj0nI2c2LTQxJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PSczNjguMTM4MDYnIHhsaW5rOmhyZWY9JyNnMi0wJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PSczODAuMDkzMjInIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzM4Ni41ODI3MjQnIHhsaW5rOmhyZWY9JyNnNi00MScgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMzkxLjEzNTA1JyB4bGluazpocmVmPScjZzItMTAzJyB5PSc5MS42NTYyODknLz4KPC9nPgo8L3N2Zz4=)
Définition D1 : Dynamic Minimum Keystroke arrière
On définit la façon optimale de saisir une requête
sachant un système de complétion
comme étant le minimum obtenu :
(1)#![\begin{eqnarray*}
M'_b(q, S) &=& \min\acc{\begin{array}{l}
\min_{0 \infegal k < l(q)} \acc{ M'_b(q[1..k], S) +
\min( K(q, k, S), l(q) - k) } \\
\min_{s \succ q} \acc{ M'_b(s, S) + l(s) - l(q) }
\end{array} }
\end{eqnarray*}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMjguNjkyNjk1cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDc4LjcwNDg0OSAzOTcuNTMzMzk3IDI4LjY5MjY5NScgd2lkdGg9JzM5Ny41MzMzOTdwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNNy44Nzg0NTYgLTIuNzQ5Njg5QzguMDgxNjk0IC0yLjc0OTY4OSA4LjI5Njg4NyAtMi43NDk2ODkgOC4yOTY4ODcgLTIuOTg4NzkyUzguMDgxNjk0IC0zLjIyNzg5NSA3Ljg3ODQ1NiAtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3MiAtMy4yMjc4OTUgMC45OTIyNzkgLTMuMjI3ODk1IDAuOTkyMjc5IC0yLjk4ODc5MlMxLjIwNzQ3MiAtMi43NDk2ODkgMS40MTA3MSAtMi43NDk2ODlINy44Nzg0NTZaJyBpZD0nZzMtMCcvPgo8cGF0aCBkPSdNMy4zODMzMTMgLTcuMzc2MzM5QzMuMzgzMzEzIC03Ljg1NDU0NSAzLjY5NDE0NyAtOC42MTk2NzYgNC45OTcyNiAtOC43MDMzNjJDNS4wNTcwMzYgLTguNzE1MzE4IDUuMTA0ODU3IC04Ljc2MzEzOCA1LjEwNDg1NyAtOC44MzQ4NjlDNS4xMDQ4NTcgLTguOTY2Mzc2IDUuMDA5MjE1IC04Ljk2NjM3NiA0Ljg3NzcwOSAtOC45NjYzNzZDMy42ODIxOTIgLTguOTY2Mzc2IDIuNTk0MjcxIC04LjM1NjY2MyAyLjU4MjMxNiAtNy40NzE5OFYtNC43NDYyMDJDMi41ODIzMTYgLTQuMjc5OTUgMi41ODIzMTYgLTMuODk3Mzg1IDIuMTA0MTEgLTMuNTAyODY0QzEuNjg1Njc5IC0zLjE1NjE2NCAxLjIzMTM4MiAtMy4xMzIyNTQgMC45NjgzNjkgLTMuMTIwMjk5QzAuOTA4NTkzIC0zLjEwODM0NCAwLjg2MDc3MiAtMy4wNjA1MjMgMC44NjA3NzIgLTIuOTg4NzkyQzAuODYwNzcyIC0yLjg2OTI0IDAuOTMyNTAzIC0yLjg2OTI0IDEuMDUyMDU1IC0yLjg1NzI4NUMxLjg0MTA5NiAtMi44MDk0NjUgMi40MTQ5NDQgLTIuMzc5MDc4IDIuNTQ2NDUxIC0xLjc5MzI3NUMyLjU4MjMxNiAtMS42NjE3NjggMi41ODIzMTYgLTEuNjM3ODU4IDIuNTgyMzE2IC0xLjIwNzQ3MlYxLjE1OTY1MUMyLjU4MjMxNiAxLjY2MTc2OCAyLjU4MjMxNiAyLjA0NDMzNCAzLjE1NjE2NCAyLjQ5ODYzQzMuNjIyNDE2IDIuODU3Mjg1IDQuNDExNDU3IDIuOTg4NzkyIDQuODc3NzA5IDIuOTg4NzkyQzUuMDA5MjE1IDIuOTg4NzkyIDUuMTA0ODU3IDIuOTg4NzkyIDUuMTA0ODU3IDIuODU3Mjg1QzUuMTA0ODU3IDIuNzM3NzMzIDUuMDMzMTI2IDIuNzM3NzMzIDQuOTEzNTc0IDIuNzI1Nzc4QzQuMTYwMzk5IDIuNjc3OTU4IDMuNTc0NTk1IDIuMjk1MzkyIDMuNDE5MTc4IDEuNjg1Njc5QzMuMzgzMzEzIDEuNTc4MDgyIDMuMzgzMzEzIDEuNTU0MTcyIDMuMzgzMzEzIDEuMTIzNzg2Vi0xLjM4NjhDMy4zODMzMTMgLTEuOTM2NzM3IDMuMjg3NjcxIC0yLjEzOTk3NSAyLjkwNTEwNiAtMi41MjI1NEMyLjY1NDA0NyAtMi43NzM1OTkgMi4zMDczNDcgLTIuODkzMTUxIDEuOTcyNjAzIC0yLjk4ODc5MkMyLjk1MjkyNyAtMy4yNjM3NjEgMy4zODMzMTMgLTMuODEzNjk5IDMuMzgzMzEzIC00LjUwNzA5OFYtNy4zNzYzMzlaJyBpZD0nZzMtMTAyJy8+CjxwYXRoIGQ9J00yLjU4MjMxNiAxLjM5ODc1NUMyLjU4MjMxNiAxLjg3Njk2MSAyLjI3MTQ4MiAyLjY0MjA5MiAwLjk2ODM2OSAyLjcyNTc3OEMwLjkwODU5MyAyLjczNzczMyAwLjg2MDc3MiAyLjc4NTU1NCAwLjg2MDc3MiAyLjg1NzI4NUMwLjg2MDc3MiAyLjk4ODc5MiAwLjk5MjI3OSAyLjk4ODc5MiAxLjA5OTg3NSAyLjk4ODc5MkMyLjI1OTUyNyAyLjk4ODc5MiAzLjM3MTM1NyAyLjQwMjk4OSAzLjM4MzMxMyAxLjQ5NDM5NlYtMS4yMzEzODJDMy4zODMzMTMgLTEuNjk3NjM0IDMuMzgzMzEzIC0yLjA4MDE5OSAzLjg2MTUxOSAtMi40NzQ3MkM0LjI3OTk1IC0yLjgyMTQyIDQuNzM0MjQ3IC0yLjg0NTMzIDQuOTk3MjYgLTIuODU3Mjg1QzUuMDU3MDM2IC0yLjg2OTI0IDUuMTA0ODU3IC0yLjkxNzA2MSA1LjEwNDg1NyAtMi45ODg3OTJDNS4xMDQ4NTcgLTMuMTA4MzQ0IDUuMDMzMTI2IC0zLjEwODM0NCA0LjkxMzU3NCAtMy4xMjAyOTlDNC4xMjQ1MzMgLTMuMTY4MTIgMy41NTA2ODUgLTMuNTk4NTA2IDMuNDE5MTc4IC00LjE4NDMwOUMzLjM4MzMxMyAtNC4zMTU4MTYgMy4zODMzMTMgLTQuMzM5NzI2IDMuMzgzMzEzIC00Ljc3MDExMlYtNy4xMzcyMzVDMy4zODMzMTMgLTcuNjM5MzUyIDMuMzgzMzEzIC04LjAyMTkxOCAyLjgwOTQ2NSAtOC40NzYyMTRDMi4zMzEyNTggLTguODQ2ODI0IDEuNTA2MzUxIC04Ljk2NjM3NiAxLjA5OTg3NSAtOC45NjYzNzZDMC45OTIyNzkgLTguOTY2Mzc2IDAuODYwNzcyIC04Ljk2NjM3NiAwLjg2MDc3MiAtOC44MzQ4NjlDMC44NjA3NzIgLTguNzE1MzE4IDAuOTMyNTAzIC04LjcxNTMxOCAxLjA1MjA1NSAtOC43MDMzNjJDMS44MDUyMyAtOC42NTU1NDIgMi4zOTEwMzQgLTguMjcyOTc2IDIuNTQ2NDUxIC03LjY2MzI2M0MyLjU4MjMxNiAtNy41NTU2NjYgMi41ODIzMTYgLTcuNTMxNzU2IDIuNTgyMzE2IC03LjEwMTM3Vi00LjU5MDc4NUMyLjU4MjMxNiAtNC4wNDA4NDcgMi42Nzc5NTggLTMuODM3NjA5IDMuMDYwNTIzIC0zLjQ1NTA0NEMzLjMxMTU4MiAtMy4yMDM5ODUgMy42NTgyODEgLTMuMDg0NDMzIDMuOTkzMDI2IC0yLjk4ODc5MkMzLjAxMjcwMiAtMi43MTM4MjMgMi41ODIzMTYgLTIuMTYzODg1IDIuNTgyMzE2IC0xLjQ3MDQ4NlYxLjM5ODc1NVonIGlkPSdnMy0xMDMnLz4KPHBhdGggZD0nTTMuNDAzMjM4IC0xLjk4NDU1OEMyLjE0Mzk2IC0xLjczNzQ4NCAxLjYwOTk2MyAtMS4yODMxODggMS40MzQ2MiAtMS4xMzE3NTZDMC43NDEyMiAtMC41MzM5OTggMC43MDEzNyAwLjI5NDg5NCAwLjcwMTM3IDAuMzI2Nzc1QzAuNzAxMzcgMC40NDYzMjYgMC43OTcwMTEgMC41MTgwNTcgMC44ODQ2ODIgMC41MTgwNTdDMC45ODAzMjQgMC41MTgwNTcgMS4wNTIwNTUgMC40NDYzMjYgMS4wNjc5OTUgMC4zNTg2NTVDMS4xMzE3NTYgLTAuMDc5NzAxIDEuMjc1MjE4IC0xLjA1MjA1NSAzLjAzNjYxMyAtMS41MjIyOTFDMy44ODk0MTUgLTEuNzQ1NDU1IDQuODQ1ODI4IC0xLjc5MzI3NSA1LjY0MjgzOSAtMS44MDEyNDVDNS42ODI2OSAtMS44MDEyNDUgNS44NzM5NzMgLTEuODAxMjQ1IDUuODczOTczIC0xLjk4NDU1OEM1Ljg3Mzk3MyAtMi4xMDQxMSA1Ljc3ODMzMSAtMi4xNDM5NiA1Ljc0NjQ1MSAtMi4xNTE5M0M1LjczMDUxMSAtMi4xNjc4NyA1LjcxNDU3IC0yLjE2Nzg3IDUuMzcxODU2IC0yLjE2Nzg3QzUuMDIxMTcxIC0yLjE2Nzg3IDQuNzk4MDA3IC0yLjE4MzgxMSA0LjQ2MzI2MyAtMi4yMTU2OTFDMi40MzA4ODQgLTIuMzgzMDY0IDEuMjY3MjQ4IC0yLjk5Njc2MiAxLjA3NTk2NSAtNC4yNDAxQzEuMDYwMDI1IC00LjM1MTY4MSAxLjAzNjExNSAtNC40ODcxNzMgMC44ODQ2ODIgLTQuNDg3MTczQzAuNzk3MDExIC00LjQ4NzE3MyAwLjcwMTM3IC00LjQxNTQ0MiAwLjcwMTM3IC00LjI5NTg5QzAuNzAxMzcgLTQuMjg3OTIgMC43MTczMSAtMy45MzcyMzUgMC45MTY1NjMgLTMuNTA2ODQ5QzEuMzc4ODI5IC0yLjU0MjQ2NiAyLjU1ODQwNiAtMi4xNTE5MyAzLjQwMzIzOCAtMS45ODQ1NThaJyBpZD0nZzItMzEnLz4KPHBhdGggZD0nTTIuMTEyMDggLTMuNzc3ODMzQzIuMTUxOTMgLTMuODgxNDQ1IDIuMTgzODExIC0zLjkzNzIzNSAyLjE4MzgxMSAtNC4wMTY5MzZDMi4xODM4MTEgLTQuMjc5OTUgMS45NDQ3MDcgLTQuNDU1MjkzIDEuNzIxNTQ0IC00LjQ1NTI5M0MxLjQwMjc0IC00LjQ1NTI5MyAxLjMxNTA2OCAtNC4xNzYzMzkgMS4yODMxODggLTQuMDY0NzU3TDAuMjcwOTg0IC0wLjYyOTYzOUMwLjIzOTEwMyAtMC41MzM5OTggMC4yMzkxMDMgLTAuNTEwMDg3IDAuMjM5MTAzIC0wLjUwMjExN0MwLjIzOTEwMyAtMC40MzAzODYgMC4yODY5MjQgLTAuNDE0NDQ2IDAuMzY2NjI1IC0wLjM5MDUzNUMwLjUxMDA4NyAtMC4zMjY3NzUgMC41MjYwMjcgLTAuMzI2Nzc1IDAuNTQxOTY4IC0wLjMyNjc3NUMwLjU2NTg3OCAtMC4zMjY3NzUgMC42MTM2OTkgLTAuMzI2Nzc1IDAuNjY5NDg5IC0wLjQ2MjI2N0wyLjExMjA4IC0zLjc3NzgzM1onIGlkPSdnMi00OCcvPgo8cGF0aCBkPSdNMi42NTQwNDcgMS45OTI1MjhDMi43MTc4MDggMS45OTI1MjggMi44MTM0NSAxLjk5MjUyOCAyLjgxMzQ1IDEuODk2ODg3QzIuODEzNDUgMS44NjUwMDYgMi44MDU0NzkgMS44NTcwMzYgMi43MDE4NjggMS43NTM0MjVDMS42MDk5NjMgMC43MjUyOCAxLjMzODk3OSAtMC43NTcxNjEgMS4zMzg5NzkgLTEuOTkyNTI4QzEuMzM4OTc5IC00LjI4NzkyIDIuMjg3NDIyIC01LjM2Mzg4NSAyLjY5Mzg5OCAtNS43MzA1MTFDMi44MDU0NzkgLTUuODM0MTIyIDIuODEzNDUgLTUuODQyMDkyIDIuODEzNDUgLTUuODgxOTQzUzIuNzgxNTY5IC01Ljk3NzU4NCAyLjcwMTg2OCAtNS45Nzc1ODRDMi41NzQzNDYgLTUuOTc3NTg0IDIuMTc1ODQxIC01LjU3MTEwOCAyLjExMjA4IC01LjQ5OTM3N0MxLjA0NDA4NSAtNC4zODM1NjIgMC44MjA5MjIgLTIuOTQ4OTQxIDAuODIwOTIyIC0xLjk5MjUyOEMwLjgyMDkyMiAtMC4yMDcyMjMgMS41NzAxMTIgMS4yMjczOTcgMi42NTQwNDcgMS45OTI1MjhaJyBpZD0nZzYtNDAnLz4KPHBhdGggZD0nTTIuNDYyNzY1IC0xLjk5MjUyOEMyLjQ2Mjc2NSAtMi43NDk2ODkgMi4zMzUyNDMgLTMuNjU4MjgxIDEuODQxMDk2IC00LjU5ODc1NUMxLjQ1MDU2IC01LjMzMjAwNSAwLjcyNTI4IC01Ljk3NzU4NCAwLjU4MTgxOCAtNS45Nzc1ODRDMC41MDIxMTcgLTUuOTc3NTg0IDAuNDc4MjA3IC01LjkyMTc5MyAwLjQ3ODIwNyAtNS44ODE5NDNDMC40NzgyMDcgLTUuODUwMDYyIDAuNDc4MjA3IC01LjgzNDEyMiAwLjU3Mzg0OCAtNS43Mzg0ODFDMS42ODk2NjQgLTQuNjc4NDU2IDEuOTQ0NzA3IC0zLjIxOTkyNSAxLjk0NDcwNyAtMS45OTI1MjhDMS45NDQ3MDcgMC4yOTQ4OTQgMC45OTYyNjQgMS4zNzg4MjkgMC41ODk3ODggMS43NDU0NTVDMC40ODYxNzcgMS44NDkwNjYgMC40NzgyMDcgMS44NTcwMzYgMC40NzgyMDcgMS44OTY4ODdTMC41MDIxMTcgMS45OTI1MjggMC41ODE4MTggMS45OTI1MjhDMC43MDkzNCAxLjk5MjUyOCAxLjEwNzg0NiAxLjU4NjA1MiAxLjE3MTYwNiAxLjUxNDMyMUMyLjIzOTYwMSAwLjM5ODUwNiAyLjQ2Mjc2NSAtMS4wMzYxMTUgMi40NjI3NjUgLTEuOTkyNTI4WicgaWQ9J2c2LTQxJy8+CjxwYXRoIGQ9J00zLjg5NzM4NSAtMi41NDI0NjZDMy44OTczODUgLTMuMzk1MjY4IDMuODA5NzE0IC0zLjkxMzMyNSAzLjU0NjcgLTQuNDIzNDEyQzMuMTk2MDE1IC01LjEyNDc4MiAyLjU1MDQzNiAtNS4zMDAxMjUgMi4xMTIwOCAtNS4zMDAxMjVDMS4xMDc4NDYgLTUuMzAwMTI1IDAuNzQxMjIgLTQuNTUwOTM0IDAuNjI5NjM5IC00LjMyNzc3MUMwLjM0MjcxNSAtMy43NDU5NTMgMC4zMjY3NzUgLTIuOTU2OTEyIDAuMzI2Nzc1IC0yLjU0MjQ2NkMwLjMyNjc3NSAtMi4wMTY0MzggMC4zNTA2ODUgLTEuMjExNDU3IDAuNzMzMjUgLTAuNTczODQ4QzEuMDk5ODc1IDAuMDE1OTQgMS42ODk2NjQgMC4xNjczNzIgMi4xMTIwOCAwLjE2NzM3MkMyLjQ5NDY0NSAwLjE2NzM3MiAzLjE4MDA3NSAwLjA0NzgyMSAzLjU3ODU4IC0wLjc0MTIyQzMuODczNDc0IC0xLjMxNTA2OCAzLjg5NzM4NSAtMi4wMjQ0MDggMy44OTczODUgLTIuNTQyNDY2Wk0yLjExMjA4IC0wLjA1NTc5MUMxLjg0MTA5NiAtMC4wNTU3OTEgMS4yOTExNTggLTAuMTgzMzEzIDEuMTIzNzg2IC0xLjAyMDE3NEMxLjAzNjExNSAtMS40NzQ0NzEgMS4wMzYxMTUgLTIuMjIzNjYxIDEuMDM2MTE1IC0yLjYzODEwN0MxLjAzNjExNSAtMy4xODgwNDUgMS4wMzYxMTUgLTMuNzQ1OTUzIDEuMTIzNzg2IC00LjE4NDMwOUMxLjI5MTE1OCAtNC45OTcyNiAxLjkxMjgyNyAtNS4wNzY5NjEgMi4xMTIwOCAtNS4wNzY5NjFDMi4zODMwNjQgLTUuMDc2OTYxIDIuOTMzMDAxIC00Ljk0MTQ2OSAzLjA5MjQwMyAtNC4yMTYxODlDMy4xODgwNDUgLTMuNzc3ODMzIDMuMTg4MDQ1IC0zLjE4MDA3NSAzLjE4ODA0NSAtMi42MzgxMDdDMy4xODgwNDUgLTIuMTY3ODcgMy4xODgwNDUgLTEuNDUwNTYgMy4wOTI0MDMgLTEuMDA0MjM0QzIuOTI1MDMxIC0wLjE2NzM3MiAyLjM3NTA5MyAtMC4wNTU3OTEgMi4xMTIwOCAtMC4wNTU3OTFaJyBpZD0nZzYtNDgnLz4KPHBhdGggZD0nTTUuMzc5ODI2IC00LjczNDI0N0M1LjQ3NTQ2NyAtNC43ODIwNjcgNS41MzEyNTggLTQuODIxOTE4IDUuNTMxMjU4IC00LjkwOTU4OVM1LjQ1OTUyNyAtNS4wNjg5OTEgNS4zNzE4NTYgLTUuMDY4OTkxQzUuMzMyMDA1IC01LjA2ODk5MSA1LjI2MDI3NCAtNS4wMzcxMTEgNS4yMjgzOTQgLTUuMDIxMTcxTDAuODIwOTIyIC0yLjk0MDk3MUMwLjY4NTQzIC0yLjg3NzIxIDAuNjYxNTE5IC0yLjgyMTQyIDAuNjYxNTE5IC0yLjc1NzY1OVMwLjY5MzQgLTIuNjM4MTA3IDAuODIwOTIyIC0yLjU4MjMxNkw1LjIyODM5NCAtMC41MTAwODdDNS4zMzIwMDUgLTAuNDU0Mjk2IDUuMzQ3OTQ1IC0wLjQ1NDI5NiA1LjM3MTg1NiAtMC40NTQyOTZDNS40NTk1MjcgLTAuNDU0Mjk2IDUuNTMxMjU4IC0wLjUyNjAyNyA1LjUzMTI1OCAtMC42MTM2OTlDNS41MzEyNTggLTAuNzE3MzEgNS40NTk1MjcgLTAuNzQ5MTkxIDUuMzcxODU2IC0wLjc4OTA0MUwxLjE5NTUxNyAtMi43NTc2NTlMNS4zNzk4MjYgLTQuNzM0MjQ3Wk01LjIyODM5NCAxLjAzNjExNUM1LjMzMjAwNSAxLjA5MTkwNSA1LjM0Nzk0NSAxLjA5MTkwNSA1LjM3MTg1NiAxLjA5MTkwNUM1LjQ1OTUyNyAxLjA5MTkwNSA1LjUzMTI1OCAxLjAyMDE3NCA1LjUzMTI1OCAwLjkzMjUwM0M1LjUzMTI1OCAwLjgyODg5MiA1LjQ1OTUyNyAwLjc5NzAxMSA1LjM3MTg1NiAwLjc1NzE2MUwwLjk3MjM1NCAtMS4zMTUwNjhDMC44Njg3NDIgLTEuMzcwODU5IDAuODUyODAyIC0xLjM3MDg1OSAwLjgyMDkyMiAtMS4zNzA4NTlDMC43MjUyOCAtMS4zNzA4NTkgMC42NjE1MTkgLTEuMjk5MTI4IDAuNjYxNTE5IC0xLjIxMTQ1N0MwLjY2MTUxOSAtMS4xNDc2OTYgMC42OTM0IC0xLjA5MTkwNSAwLjgyMDkyMiAtMS4wMzYxMTVMNS4yMjgzOTQgMS4wMzYxMTVaJyBpZD0nZzAtNTQnLz4KPHBhdGggZD0nTTUuNzA2NiAtNC4xMTI1NzhDNS44MDIyNDIgLTQuMTYwMzk5IDUuODczOTczIC00LjIwODIxOSA1Ljg3Mzk3MyAtNC4zMTE4MzFTNS43OTQyNzEgLTQuNDk1MTQzIDUuNjkwNjYgLTQuNDk1MTQzQzUuNjY2NzUgLTQuNDk1MTQzIDUuNjUwODA5IC00LjQ5NTE0MyA1LjU0NzE5OCAtNC40MzkzNTJMMC44Njg3NDIgLTIuMTkxNzgxQzAuNzczMTAxIC0yLjE0Mzk2IDAuNzAxMzcgLTIuMDk2MTM5IDAuNzAxMzcgLTEuOTkyNTI4UzAuNzczMTAxIC0xLjg0MTA5NiAwLjg2ODc0MiAtMS43OTMyNzVMNS41NDcxOTggMC40NTQyOTZDNS42NTA4MDkgMC41MTAwODcgNS42NjY3NSAwLjUxMDA4NyA1LjY5MDY2IDAuNTEwMDg3QzUuNzk0MjcxIDAuNTEwMDg3IDUuODczOTczIDAuNDMwMzg2IDUuODczOTczIDAuMzI2Nzc1UzUuODAyMjQyIDAuMTc1MzQyIDUuNzA2NiAwLjEyNzUyMkwxLjMwNzA5OCAtMS45OTI1MjhMNS43MDY2IC00LjExMjU3OFonIGlkPSdnNC02MCcvPgo8cGF0aCBkPSdNMS45NDQ3MDcgLTUuMjkyMTU0QzEuOTUyNjc3IC01LjMwODA5NSAxLjk3NjU4OCAtNS40MTE3MDYgMS45NzY1ODggLTUuNDE5Njc2QzEuOTc2NTg4IC01LjQ1OTUyNyAxLjk0NDcwNyAtNS41MzEyNTggMS44NDkwNjYgLTUuNTMxMjU4QzEuODE3MTg2IC01LjUzMTI1OCAxLjU3MDExMiAtNS41MDczNDcgMS4zODY4IC01LjQ5MTQwN0wwLjk0MDQ3MyAtNS40NTk1MjdDMC43NjUxMzEgLTUuNDQzNTg3IDAuNjg1NDMgLTUuNDM1NjE2IDAuNjg1NDMgLTUuMjkyMTU0QzAuNjg1NDMgLTUuMTgwNTczIDAuNzk3MDExIC01LjE4MDU3MyAwLjg5MjY1MyAtNS4xODA1NzNDMS4yNzUyMTggLTUuMTgwNTczIDEuMjc1MjE4IC01LjEzMjc1MiAxLjI3NTIxOCAtNS4wNjEwMjFDMS4yNzUyMTggLTUuMDEzMiAxLjE5NTUxNyAtNC42OTQzOTYgMS4xNDc2OTYgLTQuNTExMDgzTDAuNDU0Mjk2IC0xLjczNzQ4NEMwLjM5MDUzNSAtMS40NjY1MDEgMC4zOTA1MzUgLTEuMzQ2OTQ5IDAuMzkwNTM1IC0xLjIxMTQ1N0MwLjM5MDUzNSAtMC4zOTA1MzUgMC44OTI2NTMgMC4wNzk3MDEgMS41MDYzNTEgMC4wNzk3MDFDMi40ODY2NzUgMC4wNzk3MDEgMy41MDY4NDkgLTEuMDUyMDU1IDMuNTA2ODQ5IC0yLjIwNzcyMUMzLjUwNjg0OSAtMi45OTY3NjIgMi45OTY3NjIgLTMuNTE0ODE5IDIuMzU5MTUzIC0zLjUxNDgxOUMxLjkxMjgyNyAtMy41MTQ4MTkgMS41NzAxMTIgLTMuMjI3ODk1IDEuMzk0NzcgLTMuMDc2NDYzTDEuOTQ0NzA3IC01LjI5MjE1NFpNMS41MDYzNTEgLTAuMTQzNDYyQzEuMjE5NDI3IC0wLjE0MzQ2MiAwLjkzMjUwMyAtMC4zNjY2MjUgMC45MzI1MDMgLTAuOTQ4NDQzQzAuOTMyNTAzIC0xLjE2MzYzNiAwLjk2NDM4NCAtMS4zNjI4ODkgMS4wNjAwMjUgLTEuNzQ1NDU1QzEuMTE1ODE2IC0xLjk3NjU4OCAxLjE3MTYwNiAtMi4xOTk3NTEgMS4yMzUzNjcgLTIuNDMwODg0QzEuMjc1MjE4IC0yLjU3NDM0NiAxLjI3NTIxOCAtMi41OTAyODYgMS4zNzA4NTkgLTIuNzA5ODM4QzEuNjQxODQzIC0zLjA0NDU4MyAyLjAwMDQ5OCAtMy4yOTE2NTYgMi4zMzUyNDMgLTMuMjkxNjU2QzIuNzMzNzQ4IC0zLjI5MTY1NiAyLjg4NTE4MSAtMi45MDExMjEgMi44ODUxODEgLTIuNTQyNDY2QzIuODg1MTgxIC0yLjI0NzU3MiAyLjcwOTgzOCAtMS4zOTQ3NyAyLjQ3MDczNSAtMC45MjQ1MzNDMi4yNjM1MTIgLTAuNDk0MTQ3IDEuODgwOTQ2IC0wLjE0MzQ2MiAxLjUwNjM1MSAtMC4xNDM0NjJaJyBpZD0nZzQtOTgnLz4KPHBhdGggZD0nTTIuMzI3MjczIC01LjI5MjE1NEMyLjMzNTI0MyAtNS4zMDgwOTUgMi4zNTkxNTMgLTUuNDExNzA2IDIuMzU5MTUzIC01LjQxOTY3NkMyLjM1OTE1MyAtNS40NTk1MjcgMi4zMjcyNzMgLTUuNTMxMjU4IDIuMjMxNjMxIC01LjUzMTI1OEMyLjE5OTc1MSAtNS41MzEyNTggMS45NTI2NzcgLTUuNTA3MzQ3IDEuNzY5MzY1IC01LjQ5MTQwN0wxLjMyMzAzOSAtNS40NTk1MjdDMS4xNDc2OTYgLTUuNDQzNTg3IDEuMDY3OTk1IC01LjQzNTYxNiAxLjA2Nzk5NSAtNS4yOTIxNTRDMS4wNjc5OTUgLTUuMTgwNTczIDEuMTc5NTc3IC01LjE4MDU3MyAxLjI3NTIxOCAtNS4xODA1NzNDMS42NTc3ODMgLTUuMTgwNTczIDEuNjU3NzgzIC01LjEzMjc1MiAxLjY1Nzc4MyAtNS4wNjEwMjFDMS42NTc3ODMgLTUuMDM3MTExIDEuNjU3NzgzIC01LjAyMTE3MSAxLjYxNzkzMyAtNC44Nzc3MDlMMC40ODYxNzcgLTAuMzQyNzE1QzAuNDU0Mjk2IC0wLjIyMzE2MyAwLjQ1NDI5NiAtMC4xNzUzNDIgMC40NTQyOTYgLTAuMTY3MzcyQzAuNDU0Mjk2IC0wLjAzMTg4IDAuNTY1ODc4IDAuMDc5NzAxIDAuNzE3MzEgMC4wNzk3MDFDMC45ODgyOTQgMC4wNzk3MDEgMS4wNTIwNTUgLTAuMTc1MzQyIDEuMDgzOTM1IC0wLjI4NjkyNEMxLjE2MzYzNiAtMC42MjE2NjkgMS4zNzA4NTkgLTEuNDY2NTAxIDEuNDU4NTMxIC0xLjgwMTI0NUMxLjg5Njg4NyAtMS43NTM0MjUgMi40MzA4ODQgLTEuNjAxOTkzIDIuNDMwODg0IC0xLjE0NzY5NkMyLjQzMDg4NCAtMS4xMDc4NDYgMi40MzA4ODQgLTEuMDY3OTk1IDIuNDE0OTQ0IC0wLjk4ODI5NEMyLjM5MTAzNCAtMC44ODQ2ODIgMi4zNzUwOTMgLTAuNzczMTAxIDIuMzc1MDkzIC0wLjczMzI1QzIuMzc1MDkzIC0wLjI2MzAxNCAyLjcyNTc3OCAwLjA3OTcwMSAzLjE4ODA0NSAwLjA3OTcwMUMzLjUyMjc5IDAuMDc5NzAxIDMuNzMwMDEyIC0wLjE2NzM3MiAzLjgzMzYyNCAtMC4zMTg4MDRDNC4wMjQ5MDcgLTAuNjEzNjk5IDQuMTUyNDI4IC0xLjA5MTkwNSA0LjE1MjQyOCAtMS4xMzk3MjZDNC4xNTI0MjggLTEuMjE5NDI3IDQuMDg4NjY3IC0xLjI0MzMzNyA0LjAzMjg3NyAtMS4yNDMzMzdDMy45MzcyMzUgLTEuMjQzMzM3IDMuOTIxMjk1IC0xLjE5NTUxNyAzLjg4OTQxNSAtMS4wNTIwNTVDMy43ODU4MDMgLTAuNjc3NDYgMy41Nzg1OCAtMC4xNDM0NjIgMy4yMDM5ODUgLTAuMTQzNDYyQzIuOTk2NzYyIC0wLjE0MzQ2MiAyLjk0ODk0MSAtMC4zMTg4MDQgMi45NDg5NDEgLTAuNTMzOTk4QzIuOTQ4OTQxIC0wLjYzNzYwOSAyLjk1NjkxMiAtMC43MzMyNSAyLjk5Njc2MiAtMC45MTY1NjNDMy4wMDQ3MzIgLTAuOTQ4NDQzIDMuMDM2NjEzIC0xLjA3NTk2NSAzLjAzNjYxMyAtMS4xNjM2MzZDMy4wMzY2MTMgLTEuODE3MTg2IDIuMjE1NjkxIC0xLjk2MDY0OCAxLjgwOTIxNSAtMi4wMTY0MzhDMi4xMDQxMSAtMi4xOTE3ODEgMi4zNzUwOTMgLTIuNDYyNzY1IDIuNDcwNzM1IC0yLjU2NjM3NkMyLjkwOTA5MSAtMi45OTY3NjIgMy4yNjc3NDYgLTMuMjkxNjU2IDMuNjUwMzExIC0zLjI5MTY1NkMzLjc1MzkyMyAtMy4yOTE2NTYgMy44NDk1NjQgLTMuMjY3NzQ2IDMuOTEzMzI1IC0zLjE4ODA0NUMzLjQ4MjkzOSAtMy4xMzIyNTQgMy40ODI5MzkgLTIuNzU3NjU5IDMuNDgyOTM5IC0yLjc0OTY4OUMzLjQ4MjkzOSAtMi41NzQzNDYgMy42MTg0MzEgLTIuNDU0Nzk1IDMuNzkzNzczIC0yLjQ1NDc5NUM0LjAwODk2NiAtMi40NTQ3OTUgNC4yNDgwNyAtMi42MzAxMzcgNC4yNDgwNyAtMi45NTY5MTJDNC4yNDgwNyAtMy4yMjc4OTUgNC4wNTY3ODcgLTMuNTE0ODE5IDMuNjU4MjgxIC0zLjUxNDgxOUMzLjE5NjAxNSAtMy41MTQ4MTkgMi43ODE1NjkgLTMuMTY0MTM0IDIuMzI3MjczIC0yLjcwOTgzOEMxLjg2NTAwNiAtMi4yNTU1NDIgMS42NjU3NTMgLTIuMTY3ODcgMS41MzgyMzIgLTIuMTEyMDhMMi4zMjcyNzMgLTUuMjkyMTU0WicgaWQ9J2c0LTEwNycvPgo8cGF0aCBkPSdNMi4wODgxNjkgLTUuMjkyMTU0QzIuMDk2MTM5IC01LjMwODA5NSAyLjEyMDA1IC01LjQxMTcwNiAyLjEyMDA1IC01LjQxOTY3NkMyLjEyMDA1IC01LjQ1OTUyNyAyLjA4ODE2OSAtNS41MzEyNTggMS45OTI1MjggLTUuNTMxMjU4TDEuMTg3NTQ3IC01LjQ2NzQ5N0MwLjg5MjY1MyAtNS40NDM1ODcgMC44Mjg4OTIgLTUuNDM1NjE2IDAuODI4ODkyIC01LjI5MjE1NEMwLjgyODg5MiAtNS4xODA1NzMgMC45NDA0NzMgLTUuMTgwNTczIDEuMDM2MTE1IC01LjE4MDU3M0MxLjQxODY4IC01LjE4MDU3MyAxLjQxODY4IC01LjEzMjc1MiAxLjQxODY4IC01LjA2MTAyMUMxLjQxODY4IC01LjAzNzExMSAxLjQxODY4IC01LjAyMTE3MSAxLjM3ODgyOSAtNC44Nzc3MDlMMC4zOTA1MzUgLTAuOTI0NTMzQzAuMzU4NjU1IC0wLjc5NzAxMSAwLjM1ODY1NSAtMC42Nzc0NiAwLjM1ODY1NSAtMC42Njk0ODlDMC4zNTg2NTUgLTAuMTc1MzQyIDAuNzY1MTMxIDAuMDc5NzAxIDEuMTYzNjM2IDAuMDc5NzAxQzEuNTA2MzUxIDAuMDc5NzAxIDEuNjg5NjY0IC0wLjE5MTI4MyAxLjc3NzMzNSAtMC4zNjY2MjVDMS45MjA3OTcgLTAuNjI5NjM5IDIuMDQwMzQ5IC0xLjA5OTg3NSAyLjA0MDM0OSAtMS4xMzk3MjZDMi4wNDAzNDkgLTEuMTg3NTQ3IDIuMDE2NDM4IC0xLjI0MzMzNyAxLjkxMjgyNyAtMS4yNDMzMzdDMS44NDEwOTYgLTEuMjQzMzM3IDEuODE3MTg2IC0xLjIwMzQ4NyAxLjgxNzE4NiAtMS4xOTU1MTdDMS44MDEyNDUgLTEuMTcxNjA2IDEuNzYxMzk1IC0xLjAyODE0NCAxLjczNzQ4NCAtMC45NDA0NzNDMS42MTc5MzMgLTAuNDc4MjA3IDEuNDY2NTAxIC0wLjE0MzQ2MiAxLjE3OTU3NyAtMC4xNDM0NjJDMC45ODgyOTQgLTAuMTQzNDYyIDAuOTMyNTAzIC0wLjMyNjc3NSAwLjkzMjUwMyAtMC41MTgwNTdDMC45MzI1MDMgLTAuNjY5NDg5IDAuOTU2NDEzIC0wLjc1NzE2MSAwLjk4MDMyNCAtMC44NjA3NzJMMi4wODgxNjkgLTUuMjkyMTU0WicgaWQ9J2c0LTEwOCcvPgo8cGF0aCBkPSdNMy43OTM3NzMgLTMuMjgzNjg2QzMuODAxNzQzIC0zLjMxNTU2NyAzLjgwOTcxNCAtMy4zNjMzODcgMy44MDk3MTQgLTMuNDAzMjM4QzMuODA5NzE0IC0zLjQ1MTA1OSAzLjc3NzgzMyAtMy41MTQ4MTkgMy43MDYxMDIgLTMuNTE0ODE5QzMuNjEwNDYxIC0zLjUxNDgxOSAzLjI4MzY4NiAtMy4yMDM5ODUgMy4xNTYxNjQgLTIuOTgwODIyQzMuMDY4NDkzIC0zLjE1NjE2NCAyLjgyOTM5IC0zLjUxNDgxOSAyLjMzNTI0MyAtMy41MTQ4MTlDMS4zODY4IC0zLjUxNDgxOSAwLjM0MjcxNSAtMi40MDY5NzQgMC4zNDI3MTUgLTEuMjI3Mzk3QzAuMzQyNzE1IC0wLjM5ODUwNiAwLjg3NjcxMiAwLjA3OTcwMSAxLjQ5MDQxMSAwLjA3OTcwMUMxLjg4ODkxNyAwLjA3OTcwMSAyLjIxNTY5MSAtMC4xNTE0MzIgMi40NTQ3OTUgLTAuMzU4NjU1QzIuNDQ2ODI0IC0wLjMzNDc0NSAyLjE5OTc1MSAwLjY2OTQ4OSAyLjE2Nzg3IDAuODA0OTgxQzIuMDQ4MzE5IDEuMjY3MjQ4IDIuMDQ4MzE5IDEuMjc1MjE4IDEuNTQ2MjAyIDEuMjgzMTg4QzEuNDUwNTYgMS4yODMxODggMS4zNDY5NDkgMS4yODMxODggMS4zNDY5NDkgMS40MzQ2MkMxLjM0Njk0OSAxLjQ4MjQ0MSAxLjM4NjggMS41NDYyMDIgMS40NjY1MDEgMS41NDYyMDJDMS41NzAxMTIgMS41NDYyMDIgMS43NTM0MjUgMS41MzAyNjIgMS44NTcwMzYgMS41MjIyOTFIMi4yNzk0NTJDMi45MTcwNjEgMS41MjIyOTEgMy4wNjA1MjMgMS41NDYyMDIgMy4xMjQyODQgMS41NDYyMDJDMy4xNTYxNjQgMS41NDYyMDIgMy4yNzU3MTYgMS41NDYyMDIgMy4yNzU3MTYgMS4zOTQ3N0MzLjI3NTcxNiAxLjI4MzE4OCAzLjE2NDEzNCAxLjI4MzE4OCAzLjA2ODQ5MyAxLjI4MzE4OEMyLjY4NTkyOCAxLjI4MzE4OCAyLjY4NTkyOCAxLjIzNTM2NyAyLjY4NTkyOCAxLjE2MzYzNkMyLjY4NTkyOCAxLjE1NTY2NiAyLjY4NTkyOCAxLjExNTgxNiAyLjcxNzgwOCAwLjk5NjI2NEwzLjc5Mzc3MyAtMy4yODM2ODZaTTIuNjE0MTk3IC0wLjk4ODI5NEMyLjU4MjMxNiAtMC44Njg3NDIgMi41ODIzMTYgLTAuODQ0ODMyIDIuNDQ2ODI0IC0wLjY5MzRDMi4wMzIzNzkgLTAuMjA3MjIzIDEuNjgxNjk0IC0wLjE0MzQ2MiAxLjUxNDMyMSAtMC4xNDM0NjJDMS4xNDc2OTYgLTAuMTQzNDYyIDAuOTY0Mzg0IC0wLjQ3ODIwNyAwLjk2NDM4NCAtMC44OTI2NTNDMC45NjQzODQgLTEuMjY3MjQ4IDEuMTc5NTc3IC0yLjEyMDA1IDEuMzU0OTE5IC0yLjQ3MDczNUMxLjU4NjA1MiAtMi45NTY5MTIgMS45NzY1ODggLTMuMjkxNjU2IDIuMzQzMjEzIC0zLjI5MTY1NkMyLjg3NzIxIC0zLjI5MTY1NiAzLjAxMjcwMiAtMi42Njk5ODggMy4wMTI3MDIgLTIuNjE0MTk3QzMuMDEyNzAyIC0yLjU4MjMxNiAyLjk5Njc2MiAtMi41MjY1MjYgMi45ODg3OTIgLTIuNDg2Njc1TDIuNjE0MTk3IC0wLjk4ODI5NFonIGlkPSdnNC0xMTMnLz4KPHBhdGggZD0nTTMuMjExOTU1IC0yLjk5Njc2MkMzLjAyODY0MyAtMi45NjQ4ODIgMi44NjEyNyAtMi44MjE0MiAyLjg2MTI3IC0yLjYyMjE2N0MyLjg2MTI3IC0yLjQ3ODcwNSAyLjk1NjkxMiAtMi4zNzUwOTMgMy4xMzIyNTQgLTIuMzc1MDkzQzMuMjUxODA2IC0yLjM3NTA5MyAzLjQ5ODg3OSAtMi40NjI3NjUgMy40OTg4NzkgLTIuODIxNDJDMy40OTg4NzkgLTMuMzE1NTY3IDIuOTgwODIyIC0zLjUxNDgxOSAyLjQ4NjY3NSAtMy41MTQ4MTlDMS40MTg2OCAtMy41MTQ4MTkgMS4wODM5MzUgLTIuNzU3NjU5IDEuMDgzOTM1IC0yLjM1MTE4M0MxLjA4MzkzNSAtMi4yNzE0ODIgMS4wODM5MzUgLTEuOTg0NTU4IDEuMzc4ODI5IC0xLjc2MTM5NUMxLjU2MjE0MiAtMS42MTc5MzMgMS42OTc2MzQgLTEuNTk0MDIyIDIuMTEyMDggLTEuNTE0MzIxQzIuMzkxMDM0IC0xLjQ1ODUzMSAyLjg0NTMzIC0xLjM3ODgyOSAyLjg0NTMzIC0wLjk2NDM4NEMyLjg0NTMzIC0wLjc1NzE2MSAyLjY5Mzg5OCAtMC40OTQxNDcgMi40NzA3MzUgLTAuMzQyNzE1QzIuMTc1ODQxIC0wLjE1MTQzMiAxLjc4NTMwNSAtMC4xNDM0NjIgMS42NTc3ODMgLTAuMTQzNDYyQzEuNDY2NTAxIC0wLjE0MzQ2MiAwLjkyNDUzMyAtMC4xNzUzNDIgMC43MjUyOCAtMC40OTQxNDdDMS4xMzE3NTYgLTAuNTEwMDg3IDEuMTg3NTQ3IC0wLjgzNjg2MiAxLjE4NzU0NyAtMC45MzI1MDNDMS4xODc1NDcgLTEuMTcxNjA2IDAuOTcyMzU0IC0xLjIyNzM5NyAwLjg3NjcxMiAtMS4yMjczOTdDMC43NDkxOTEgLTEuMjI3Mzk3IDAuNDIyNDE2IC0xLjEzMTc1NiAwLjQyMjQxNiAtMC42OTM0QzAuNDIyNDE2IC0wLjIyMzE2MyAwLjkxNjU2MyAwLjA3OTcwMSAxLjY1Nzc4MyAwLjA3OTcwMUMzLjA0NDU4MyAwLjA3OTcwMSAzLjMzOTQ3NyAtMC45MDA2MjMgMy4zMzk0NzcgLTEuMjM1MzY3QzMuMzM5NDc3IC0xLjk1MjY3NyAyLjU1ODQwNiAtMi4xMDQxMSAyLjI2MzUxMiAtMi4xNTk5QzEuODgwOTQ2IC0yLjIzMTYzMSAxLjU3MDExMiAtMi4yODc0MjIgMS41NzAxMTIgLTIuNjIyMTY3QzEuNTcwMTEyIC0yLjc2NTYyOSAxLjcwNTYwNCAtMy4yOTE2NTYgMi40Nzg3MDUgLTMuMjkxNjU2QzIuNzgxNTY5IC0zLjI5MTY1NiAzLjA5MjQwMyAtMy4yMDM5ODUgMy4yMTE5NTUgLTIuOTk2NzYyWicgaWQ9J2c0LTExNScvPgo8cGF0aCBkPSdNMi4xOTk3NTEgLTAuNTczODQ4QzIuMTk5NzUxIC0wLjkyMDU0OCAxLjkxMjgyNyAtMS4xNTk2NTEgMS42MjU5MDMgLTEuMTU5NjUxQzEuMjc5MjAzIC0xLjE1OTY1MSAxLjA0MDEgLTAuODcyNzI3IDEuMDQwMSAtMC41ODU4MDNDMS4wNDAxIC0wLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MSAtMC4yODY5MjQgMi4xOTk3NTEgLTAuNTczODQ4WicgaWQ9J2c1LTU4Jy8+CjxwYXRoIGQ9J00yLjMzMTI1OCAwLjA0NzgyMUMyLjMzMTI1OCAtMC42NDU1NzkgMi4xMDQxMSAtMS4xNTk2NTEgMS42MTM5NDggLTEuMTU5NjUxQzEuMjMxMzgyIC0xLjE1OTY1MSAxLjA0MDEgLTAuODQ4ODE3IDEuMDQwMSAtMC41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNyAtMC4wNDc4MjEgMi4wMjA0MjMgLTAuMTU1NDE3QzIuMDQ0MzM0IC0wLjE3OTMyOCAyLjA1NjI4OSAtMC4xNzkzMjggMi4wNjgyNDQgLTAuMTc5MzI4QzIuMDkyMTU0IC0wLjE3OTMyOCAyLjA5MjE1NCAtMC4wMTE5NTUgMi4wOTIxNTQgMC4wNDc4MjFDMi4wOTIxNTQgMC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAwLjA0NzgyMVonIGlkPSdnNS01OScvPgo8cGF0aCBkPSdNNS45Nzc1ODQgLTQuODI5ODg4QzUuOTY1NjI5IC00Ljg2NTc1MyA1LjkxNzgwOCAtNC45NjEzOTUgNS45MTc4MDggLTQuOTk3MjZDNS45MTc4MDggLTUuMDA5MjE1IDUuOTI5NzYzIC01LjAyMTE3MSA2LjEzMzAwMSAtNS4xNzY1ODhMNy4yOTI2NTMgLTYuMDg1MTgxQzguODk0NjQ1IC03LjMyODUxOCA5LjQyMDY3MiAtNy43NDY5NDkgMTAuMjQ1NTc5IC03LjgxODY4QzEwLjMyOTI2NSAtNy44MzA2MzUgMTAuNDQ4ODE3IC03LjgzMDYzNSAxMC40NDg4MTcgLTguMDMzODczQzEwLjQ0ODgxNyAtOC4xMDU2MDQgMTAuNDEyOTUxIC04LjE2NTM4IDEwLjMxNzMxIC04LjE2NTM4QzEwLjE4NTgwMyAtOC4xNjUzOCAxMC4wNDIzNDEgLTguMTQxNDY5IDkuOTEwODM0IC04LjE0MTQ2OUg5LjQ1NjUzOEM5LjA4NTkyOCAtOC4xNDE0NjkgOC42OTE0MDcgLTguMTY1MzggOC4zMzI3NTIgLTguMTY1MzhDOC4yNDkwNjYgLTguMTY1MzggOC4xMDU2MDQgLTguMTY1MzggOC4xMDU2MDQgLTcuOTUwMTg3QzguMTA1NjA0IC03LjgzMDYzNSA4LjE4OTI5IC03LjgxODY4IDguMjYxMDIxIC03LjgxODY4QzguMzkyNTI4IC03LjgwNjcyNSA4LjU0Nzk0NSAtNy43NTg5MDQgOC41NDc5NDUgLTcuNTkxNTMyQzguNTQ3OTQ1IC03LjM1MjQyOCA4LjE4OTI5IC03LjA2NTUwNCA4LjA5MzY0OSAtNi45OTM3NzNMMy40MDcyMjMgLTMuMzQ3NDQ3TDQuMzk5NTAyIC03LjI5MjY1M0M0LjUwNzA5OCAtNy42OTkxMjggNC41MzEwMDkgLTcuODE4NjggNS4zNzk4MjYgLTcuODE4NjhDNS42MDY5NzQgLTcuODE4NjggNS43MTQ1NyAtNy44MTg2OCA1LjcxNDU3IC04LjA0NTgyOEM1LjcxNDU3IC04LjE2NTM4IDUuNTk1MDE5IC04LjE2NTM4IDUuNTM1MjQzIC04LjE2NTM4QzUuMzIwMDUgLTguMTY1MzggNS4wNjg5OTEgLTguMTQxNDY5IDQuODQxODQzIC04LjE0MTQ2OUgzLjQzMTEzM0MzLjIxNTk0IC04LjE0MTQ2OSAyLjk1MjkyNyAtOC4xNjUzOCAyLjczNzczMyAtOC4xNjUzOEMyLjY0MjA5MiAtOC4xNjUzOCAyLjUxMDU4NSAtOC4xNjUzOCAyLjUxMDU4NSAtNy45MzgyMzJDMi41MTA1ODUgLTcuODE4NjggMi42MTgxODIgLTcuODE4NjggMi43OTc1MDkgLTcuODE4NjhDMy41MjY3NzUgLTcuODE4NjggMy41MjY3NzUgLTcuNzIzMDM5IDMuNTI2Nzc1IC03LjU5MTUzMkMzLjUyNjc3NSAtNy41Njc2MjEgMy41MjY3NzUgLTcuNDk1ODkgMy40Nzg5NTQgLTcuMzE2NTYzTDEuODY1MDA2IC0wLjg4NDY4MkMxLjc1NzQxIC0wLjQ2NjI1MiAxLjczMzQ5OSAtMC4zNDY3IDAuODk2NjM4IC0wLjM0NjdDMC42Njk0ODkgLTAuMzQ2NyAwLjU0OTkzOCAtMC4zNDY3IDAuNTQ5OTM4IC0wLjEzMTUwN0MwLjU0OTkzOCAwIDAuNjU3NTM0IDAgMC43MjkyNjUgMEMwLjk1NjQxMyAwIDEuMTk1NTE3IC0wLjAyMzkxIDEuNDIyNjY1IC0wLjAyMzkxSDIuODIxNDJDMy4wNDg1NjggLTAuMDIzOTEgMy4yOTk2MjYgMCAzLjUyNjc3NSAwQzMuNjIyNDE2IDAgMy43NTM5MjMgMCAzLjc1MzkyMyAtMC4yMjcxNDhDMy43NTM5MjMgLTAuMzQ2NyAzLjY0NjMyNiAtMC4zNDY3IDMuNDY2OTk5IC0wLjM0NjdDMi43Mzc3MzMgLTAuMzQ2NyAyLjczNzczMyAtMC40NDIzNDEgMi43Mzc3MzMgLTAuNTYxODkzQzIuNzM3NzMzIC0wLjY0NTU3OSAyLjgwOTQ2NSAtMC45NDQ0NTggMi44NTcyODUgLTEuMTM1NzQxTDMuMzIzNTM3IC0yLjk4ODc5Mkw1LjE0MDcyMiAtNC40MTE0NTdDNS40ODc0MjIgLTMuNjQ2MzI2IDYuMTIxMDQ2IC0yLjExNjA2NSA2LjYxMTIwOCAtMC45NDQ0NThDNi42NDcwNzMgLTAuODcyNzI3IDYuNjcwOTg0IC0wLjgwMDk5NiA2LjY3MDk4NCAtMC43MTczMUM2LjY3MDk4NCAtMC4zNTg2NTUgNi4xOTI3NzcgLTAuMzQ2NyA2LjA4NTE4MSAtMC4zNDY3UzUuODU4MDMyIC0wLjM0NjcgNS44NTgwMzIgLTAuMTE5NTUyQzUuODU4MDMyIDAgNS45ODk1MzkgMCA2LjAyNTQwNSAwQzYuNDQzODM2IDAgNi44ODYxNzcgLTAuMDIzOTEgNy4zMDQ2MDggLTAuMDIzOTFINy44Nzg0NTZDOC4wNTc3ODMgLTAuMDIzOTEgOC4yNjEwMjEgMCA4LjQ0MDM0OSAwQzguNTEyMDggMCA4LjY0MzU4NyAwIDguNjQzNTg3IC0wLjIyNzE0OEM4LjY0MzU4NyAtMC4zNDY3IDguNTM1OTkgLTAuMzQ2NyA4LjQxNjQzOCAtMC4zNDY3QzcuOTc0MDk3IC0wLjM1ODY1NSA3LjgxODY4IC0wLjQ1NDI5NiA3LjYzOTM1MiAtMC44ODQ2ODJMNS45Nzc1ODQgLTQuODI5ODg4WicgaWQ9J2c1LTc1Jy8+CjxwYXRoIGQ9J00xMC44NTUyOTMgLTcuMjkyNjUzQzEwLjk2Mjg4OSAtNy42OTkxMjggMTAuOTg2OCAtNy44MTg2OCAxMS44MzU2MTYgLTcuODE4NjhDMTIuMDYyNzY1IC03LjgxODY4IDEyLjE3MDM2MSAtNy44MTg2OCAxMi4xNzAzNjEgLTguMDQ1ODI4QzEyLjE3MDM2MSAtOC4xNjUzOCAxMi4wODY2NzUgLTguMTY1MzggMTEuODU5NTI3IC04LjE2NTM4SDEwLjQyNDkwN0MxMC4xMjYwMjcgLTguMTY1MzggMTAuMTE0MDcyIC04LjE1MzQyNSA5Ljk4MjU2NSAtNy45NjIxNDJMNS42MTg5MjkgLTEuMDY0MDFMNC43MjIyOTEgLTcuOTAyMzY2QzQuNjg2NDI2IC04LjE2NTM4IDQuNjc0NDcxIC04LjE2NTM4IDQuMzYzNjM2IC04LjE2NTM4SDIuODgxMTk2QzIuNjU0MDQ3IC04LjE2NTM4IDIuNTQ2NDUxIC04LjE2NTM4IDIuNTQ2NDUxIC03LjkzODIzMkMyLjU0NjQ1MSAtNy44MTg2OCAyLjY1NDA0NyAtNy44MTg2OCAyLjgzMzM3NSAtNy44MTg2OEMzLjU2MjY0IC03LjgxODY4IDMuNTYyNjQgLTcuNzIzMDM5IDMuNTYyNjQgLTcuNTkxNTMyQzMuNTYyNjQgLTcuNTY3NjIxIDMuNTYyNjQgLTcuNDk1ODkgMy41MTQ4MTkgLTcuMzE2NTYzTDEuOTg0NTU4IC0xLjIxOTQyN0MxLjg0MTA5NiAtMC42NDU1NzkgMS41NjYxMjcgLTAuMzgyNTY1IDAuNzY1MTMxIC0wLjM0NjdDMC43MjkyNjUgLTAuMzQ2NyAwLjU4NTgwMyAtMC4zMzQ3NDUgMC41ODU4MDMgLTAuMTMxNTA3QzAuNTg1ODAzIDAgMC42OTM0IDAgMC43NDEyMiAwQzAuOTgwMzI0IDAgMS41OTAwMzcgLTAuMDIzOTEgMS44MjkxNDEgLTAuMDIzOTFIMi40MDI5ODlDMi41NzAzNjEgLTAuMDIzOTEgMi43NzM1OTkgMCAyLjk0MDk3MSAwQzMuMDI0NjU4IDAgMy4xNTYxNjQgMCAzLjE1NjE2NCAtMC4yMjcxNDhDMy4xNTYxNjQgLTAuMzM0NzQ1IDMuMDM2NjEzIC0wLjM0NjcgMi45ODg3OTIgLTAuMzQ2N0MyLjU5NDI3MSAtMC4zNTg2NTUgMi4yMTE3MDYgLTAuNDMwMzg2IDIuMjExNzA2IC0wLjg2MDc3MkMyLjIxMTcwNiAtMC45ODAzMjQgMi4yMTE3MDYgLTAuOTkyMjc5IDIuMjU5NTI3IC0xLjE1OTY1MUwzLjkwOTM0IC03Ljc0Njk0OUgzLjkyMTI5NUw0LjkxMzU3NCAtMC4zMjI3OUM0Ljk0OTQ0IC0wLjAzNTg2NiA0Ljk2MTM5NSAwIDUuMDY4OTkxIDBDNS4yMDA0OTggMCA1LjI2MDI3NCAtMC4wOTU2NDEgNS4zMjAwNSAtMC4yMDMyMzhMMTAuMTI2MDI3IC03LjgwNjcyNUgxMC4xMzc5ODNMOC40MDQ0ODMgLTAuODg0NjgyQzguMjk2ODg3IC0wLjQ2NjI1MiA4LjI3Mjk3NiAtMC4zNDY3IDcuNDM2MTE1IC0wLjM0NjdDNy4yMDg5NjYgLTAuMzQ2NyA3LjA4OTQxNSAtMC4zNDY3IDcuMDg5NDE1IC0wLjEzMTUwN0M3LjA4OTQxNSAwIDcuMTk3MDExIDAgNy4yNjg3NDIgMEM3LjQ3MTk4IDAgNy43MTEwODMgLTAuMDIzOTEgNy45MTQzMjEgLTAuMDIzOTFIOS4zMjUwMzFDOS41MjgyNjkgLTAuMDIzOTEgOS43NzkzMjggMCA5Ljk4MjU2NSAwQzEwLjA3ODIwNyAwIDEwLjIwOTcxNCAwIDEwLjIwOTcxNCAtMC4yMjcxNDhDMTAuMjA5NzE0IC0wLjM0NjcgMTAuMTAyMTE3IC0wLjM0NjcgOS45MjI3OSAtMC4zNDY3QzkuMTkzNTI0IC0wLjM0NjcgOS4xOTM1MjQgLTAuNDQyMzQxIDkuMTkzNTI0IC0wLjU2MTg5M0M5LjE5MzUyNCAtMC41NzM4NDggOS4xOTM1MjQgLTAuNjU3NTM0IDkuMjE3NDM1IC0wLjc1MzE3NkwxMC44NTUyOTMgLTcuMjkyNjUzWicgaWQ9J2c1LTc3Jy8+CjxwYXRoIGQ9J003LjU5MTUzMiAtOC4zMDg4NDJDNy41OTE1MzIgLTguNDE2NDM4IDcuNTA3ODQ2IC04LjQxNjQzOCA3LjQ4MzkzNSAtOC40MTY0MzhDNy40MzYxMTUgLTguNDE2NDM4IDcuNDI0MTU5IC04LjQwNDQ4MyA3LjI4MDY5NyAtOC4yMjUxNTZDNy4yMDg5NjYgLTguMTQxNDY5IDYuNzE4ODA0IC03LjUxOTgwMSA2LjcwNjg0OSAtNy41MDc4NDZDNi4zMTIzMjkgLTguMjg0OTMyIDUuNTIzMjg4IC04LjQxNjQzOCA1LjAyMTE3MSAtOC40MTY0MzhDMy41MDI4NjQgLTguNDE2NDM4IDIuMTI4MDIgLTcuMDI5NjM5IDIuMTI4MDIgLTUuNjc4NzA1QzIuMTI4MDIgLTQuNzgyMDY3IDIuNjY2MDAyIC00LjI1NjA0IDMuMjUxODA2IC00LjA1MjgwMkMzLjM4MzMxMyAtNC4wMDQ5ODEgNC4wODg2NjcgLTMuODEzNjk5IDQuNDQ3MzIzIC0zLjczMDAxMkM1LjA1NzAzNiAtMy41NjI2NCA1LjIxMjQ1MyAtMy41MTQ4MTkgNS40NjM1MTIgLTMuMjUxODA2QzUuNTExMzMzIC0zLjE5MjAzIDUuNzUwNDM2IC0yLjkxNzA2MSA1Ljc1MDQzNiAtMi4zNTUxNjhDNS43NTA0MzYgLTEuMjQzMzM3IDQuNzIyMjkxIC0wLjA5NTY0MSAzLjUyNjc3NSAtMC4wOTU2NDFDMi41NDY0NTEgLTAuMDk1NjQxIDEuNDU4NTMxIC0wLjUxNDA3MiAxLjQ1ODUzMSAtMS44NTMwNTFDMS40NTg1MzEgLTIuMDgwMTk5IDEuNTA2MzUxIC0yLjM2NzEyMyAxLjU0MjIxNyAtMi40ODY2NzVDMS41NDIyMTcgLTIuNTIyNTQgMS41NTQxNzIgLTIuNTgyMzE2IDEuNTU0MTcyIC0yLjYwNjIyN0MxLjU1NDE3MiAtMi42NTQwNDcgMS41MzAyNjIgLTIuNzEzODIzIDEuNDM0NjIgLTIuNzEzODIzQzEuMzI3MDI0IC0yLjcxMzgyMyAxLjMxNTA2OCAtMi42ODk5MTMgMS4yNjcyNDggLTIuNDg2Njc1TDAuNjU3NTM0IC0wLjAzNTg2NkMwLjY1NzUzNCAtMC4wMjM5MSAwLjYwOTcxNCAwLjEzMTUwNyAwLjYwOTcxNCAwLjE0MzQ2MkMwLjYwOTcxNCAwLjI1MTA1OSAwLjcwNTM1NSAwLjI1MTA1OSAwLjcyOTI2NSAwLjI1MTA1OUMwLjc3NzA4NiAwLjI1MTA1OSAwLjc4OTA0MSAwLjIzOTEwMyAwLjkzMjUwMyAwLjA1OTc3NkwxLjQ4MjQ0MSAtMC42NTc1MzRDMS43NjkzNjUgLTAuMjI3MTQ4IDIuMzkxMDM0IDAuMjUxMDU5IDMuNTAyODY0IDAuMjUxMDU5QzUuMDQ1MDgxIDAuMjUxMDU5IDYuNDU1NzkxIC0xLjI0MzMzNyA2LjQ1NTc5MSAtMi43Mzc3MzNDNi40NTU3OTEgLTMuMjM5ODUxIDYuMzM2MjM5IC0zLjY4MjE5MiA1Ljg4MTk0MyAtNC4xMjQ1MzNDNS42MzA4ODQgLTQuMzc1NTkyIDUuNDE1NjkxIC00LjQzNTM2NyA0LjMxNTgxNiAtNC43MjIyOTFDMy41MTQ4MTkgLTQuOTM3NDg0IDMuNDA3MjIzIC00Ljk3MzM1IDMuMTkyMDMgLTUuMTY0NjMzQzIuOTg4NzkyIC01LjM2Nzg3IDIuODMzMzc1IC01LjY1NDc5NSAyLjgzMzM3NSAtNi4wNjEyN0MyLjgzMzM3NSAtNy4wNjU1MDQgMy44NDk1NjQgLTguMDkzNjQ5IDQuOTg1MzA1IC04LjA5MzY0OUM2LjE1NjkxMiAtOC4wOTM2NDkgNi43MDY4NDkgLTcuMzc2MzM5IDYuNzA2ODQ5IC02LjI0MDU5OEM2LjcwNjg0OSAtNS45Mjk3NjMgNi42NDcwNzMgLTUuNjA2OTc0IDYuNjQ3MDczIC01LjU1OTE1M0M2LjY0NzA3MyAtNS40NTE1NTcgNi43NDI3MTUgLTUuNDUxNTU3IDYuNzc4NTggLTUuNDUxNTU3QzYuODg2MTc3IC01LjQ1MTU1NyA2Ljg5ODEzMiAtNS40ODc0MjIgNi45NDU5NTMgLTUuNjc4NzA1TDcuNTkxNTMyIC04LjMwODg0MlonIGlkPSdnNS04MycvPgo8cGF0aCBkPSdNMy4zNTk0MDIgLTcuOTk4MDA3QzMuMzcxMzU3IC04LjA0NTgyOCAzLjM5NTI2OCAtOC4xMTc1NTkgMy4zOTUyNjggLTguMTc3MzM1QzMuMzk1MjY4IC04LjI5Njg4NyAzLjI3NTcxNiAtOC4yOTY4ODcgMy4yNTE4MDYgLTguMjk2ODg3QzMuMjM5ODUxIC04LjI5Njg4NyAyLjgwOTQ2NSAtOC4yNjEwMjEgMi41OTQyNzEgLTguMjM3MTExQzIuMzkxMDM0IC04LjIyNTE1NiAyLjIxMTcwNiAtOC4yMDEyNDUgMS45OTY1MTMgLTguMTg5MjlDMS43MDk1ODkgLTguMTY1MzggMS42MjU5MDMgLTguMTUzNDI1IDEuNjI1OTAzIC03LjkzODIzMkMxLjYyNTkwMyAtNy44MTg2OCAxLjc0NTQ1NSAtNy44MTg2OCAxLjg2NTAwNiAtNy44MTg2OEMyLjQ3NDcyIC03LjgxODY4IDIuNDc0NzIgLTcuNzExMDgzIDIuNDc0NzIgLTcuNTkxNTMyQzIuNDc0NzIgLTcuNTQzNzExIDIuNDc0NzIgLTcuNTE5ODAxIDIuNDE0OTQ0IC03LjMwNDYwOEwwLjcwNTM1NSAtMC40NjYyNTJDMC42NTc1MzQgLTAuMjg2OTI0IDAuNjU3NTM0IC0wLjI2MzAxNCAwLjY1NzUzNCAtMC4xOTEyODNDMC42NTc1MzQgMC4wNzE3MzEgMC44NjA3NzIgMC4xMTk1NTIgMC45ODAzMjQgMC4xMTk1NTJDMS4zMTUwNjggMC4xMTk1NTIgMS4zODY4IC0wLjE0MzQ2MiAxLjQ4MjQ0MSAtMC41MTQwNzJMMi4wNDQzMzQgLTIuNzQ5Njg5QzIuOTA1MTA2IC0yLjY1NDA0NyAzLjQxOTE3OCAtMi4yOTUzOTIgMy40MTkxNzggLTEuNzIxNTQ0QzMuNDE5MTc4IC0xLjY0OTgxMyAzLjQxOTE3OCAtMS42MDE5OTMgMy4zODMzMTMgLTEuNDIyNjY1QzMuMzM1NDkyIC0xLjI0MzMzNyAzLjMzNTQ5MiAtMS4wOTk4NzUgMy4zMzU0OTIgLTEuMDQwMUMzLjMzNTQ5MiAtMC4zNDY3IDMuNzg5Nzg4IDAuMTE5NTUyIDQuMzk5NTAyIDAuMTE5NTUyQzQuOTQ5NDQgMC4xMTk1NTIgNS4yMzYzNjQgLTAuMzgyNTY1IDUuMzMyMDA1IC0wLjU0OTkzOEM1LjU4MzA2NCAtMC45OTIyNzkgNS43Mzg0ODEgLTEuNjYxNzY4IDUuNzM4NDgxIC0xLjcwOTU4OUM1LjczODQ4MSAtMS43NjkzNjUgNS42OTA2NiAtMS44MTcxODYgNS42MTg5MjkgLTEuODE3MTg2QzUuNTExMzMzIC0xLjgxNzE4NiA1LjQ5OTM3NyAtMS43NjkzNjUgNS40NTE1NTcgLTEuNTc4MDgyQzUuMjg0MTg0IC0wLjk1NjQxMyA1LjAzMzEyNiAtMC4xMTk1NTIgNC40MjM0MTIgLTAuMTE5NTUyQzQuMTg0MzA5IC0wLjExOTU1MiA0LjAyODg5MiAtMC4yMzkxMDMgNC4wMjg4OTIgLTAuNjkzNEM0LjAyODg5MiAtMC45MjA1NDggNC4wNzY3MTIgLTEuMTgzNTYyIDQuMTI0NTMzIC0xLjM2Mjg4OUM0LjE3MjM1NCAtMS41NzgwODIgNC4xNzIzNTQgLTEuNTkwMDM3IDQuMTcyMzU0IC0xLjczMzQ5OUM0LjE3MjM1NCAtMi40Mzg4NTQgMy41Mzg3MyAtMi44MzMzNzUgMi40Mzg4NTQgLTIuOTc2ODM3QzIuODY5MjQgLTMuMjM5ODUxIDMuMjk5NjI2IC0zLjcwNjEwMiAzLjQ2Njk5OSAtMy44ODU0M0M0LjE0ODQ0MyAtNC42NTA1NiA0LjYxNDY5NSAtNS4wMzMxMjYgNS4xNjQ2MzMgLTUuMDMzMTI2QzUuNDM5NjAxIC01LjAzMzEyNiA1LjUxMTMzMyAtNC45NjEzOTUgNS41OTUwMTkgLTQuODg5NjY0QzUuMTUyNjc3IC00Ljg0MTg0MyA0Ljk4NTMwNSAtNC41MzEwMDkgNC45ODUzMDUgLTQuMjkxOTA1QzQuOTg1MzA1IC00LjAwNDk4MSA1LjIxMjQ1MyAtMy45MDkzNCA1LjM3OTgyNiAtMy45MDkzNEM1LjcwMjYxNSAtMy45MDkzNCA1Ljk4OTUzOSAtNC4xODQzMDkgNS45ODk1MzkgLTQuNTY2ODc0QzUuOTg5NTM5IC00LjkxMzU3NCA1LjcxNDU3IC01LjI3MjIyOSA1LjE3NjU4OCAtNS4yNzIyMjlDNC41MTkwNTQgLTUuMjcyMjI5IDMuOTgxMDcxIC00LjgwNTk3OCAzLjEzMjI1NCAtMy44NDk1NjRDMy4wMTI3MDIgLTMuNzA2MTAyIDIuNTcwMzYxIC0zLjI1MTgwNiAyLjEyODAyIC0zLjA4NDQzM0wzLjM1OTQwMiAtNy45OTgwMDdaJyBpZD0nZzUtMTA3Jy8+CjxwYXRoIGQ9J00zLjAzNjYxMyAtNy45OTgwMDdDMy4wNDg1NjggLTguMDQ1ODI4IDMuMDcyNDc4IC04LjExNzU1OSAzLjA3MjQ3OCAtOC4xNzczMzVDMy4wNzI0NzggLTguMjk2ODg3IDIuOTUyOTI3IC04LjI5Njg4NyAyLjkyOTAxNiAtOC4yOTY4ODdDMi45MTcwNjEgLTguMjk2ODg3IDIuNDg2Njc1IC04LjI2MTAyMSAyLjI3MTQ4MiAtOC4yMzcxMTFDMi4wNjgyNDQgLTguMjI1MTU2IDEuODg4OTE3IC04LjIwMTI0NSAxLjY3MzcyNCAtOC4xODkyOUMxLjM4NjggLTguMTY1MzggMS4zMDMxMTMgLTguMTUzNDI1IDEuMzAzMTEzIC03LjkzODIzMkMxLjMwMzExMyAtNy44MTg2OCAxLjQyMjY2NSAtNy44MTg2OCAxLjU0MjIxNyAtNy44MTg2OEMyLjE1MTkzIC03LjgxODY4IDIuMTUxOTMgLTcuNzExMDgzIDIuMTUxOTMgLTcuNTkxNTMyQzIuMTUxOTMgLTcuNTQzNzExIDIuMTUxOTMgLTcuNTE5ODAxIDIuMDkyMTU0IC03LjMwNDYwOEwwLjYwOTcxNCAtMS4zNzQ4NDRDMC41NzM4NDggLTEuMjQzMzM3IDAuNTQ5OTM4IC0xLjE0NzY5NiAwLjU0OTkzOCAtMC45NTY0MTNDMC41NDk5MzggLTAuMzU4NjU1IDAuOTkyMjc5IDAuMTE5NTUyIDEuNjAxOTkzIDAuMTE5NTUyQzEuOTk2NTEzIDAuMTE5NTUyIDIuMjU5NTI3IC0wLjE0MzQ2MiAyLjQ1MDgwOSAtMC41MTQwNzJDMi42NTQwNDcgLTAuOTA4NTkzIDIuODIxNDIgLTEuNjYxNzY4IDIuODIxNDIgLTEuNzA5NTg5QzIuODIxNDIgLTEuNzY5MzY1IDIuNzczNTk5IC0xLjgxNzE4NiAyLjcwMTg2OCAtMS44MTcxODZDMi41OTQyNzEgLTEuODE3MTg2IDIuNTgyMzE2IC0xLjc1NzQxIDIuNTM0NDk2IC0xLjU3ODA4MkMyLjMxOTMwMyAtMC43NTMxNzYgMi4xMDQxMSAtMC4xMTk1NTIgMS42MjU5MDMgLTAuMTE5NTUyQzEuMjY3MjQ4IC0wLjExOTU1MiAxLjI2NzI0OCAtMC41MDIxMTcgMS4yNjcyNDggLTAuNjY5NDg5QzEuMjY3MjQ4IC0wLjcxNzMxIDEuMjY3MjQ4IC0wLjk2ODM2OSAxLjM1MDkzNCAtMS4zMDMxMTNMMy4wMzY2MTMgLTcuOTk4MDA3WicgaWQ9J2c1LTEwOCcvPgo8cGF0aCBkPSdNNS4yNzIyMjkgLTUuMTUyNjc3QzUuMjcyMjI5IC01LjIxMjQ1MyA1LjIyNDQwOCAtNS4yNjAyNzQgNS4xNjQ2MzMgLTUuMjYwMjc0QzUuMDY4OTkxIC01LjI2MDI3NCA0LjYwMjc0IC00LjgyOTg4OCA0LjM3NTU5MiAtNC40MTE0NTdDNC4xNjAzOTkgLTQuOTQ5NDQgMy43ODk3ODggLTUuMjcyMjI5IDMuMjc1NzE2IC01LjI3MjIyOUMxLjkyNDc4MiAtNS4yNzIyMjkgMC40NjYyNTIgLTMuNTI2Nzc1IDAuNDY2MjUyIC0xLjc1NzQxQzAuNDY2MjUyIC0wLjU3Mzg0OCAxLjE1OTY1MSAwLjExOTU1MiAxLjk3MjYwMyAwLjExOTU1MkMyLjYwNjIyNyAwLjExOTU1MiAzLjEzMjI1NCAtMC4zNTg2NTUgMy4zODMzMTMgLTAuNjMzNjI0TDMuMzk1MjY4IC0wLjYyMTY2OUwyLjk0MDk3MSAxLjE3MTYwNkwyLjgzMzM3NSAxLjYwMTk5M0MyLjcyNTc3OCAxLjk2MDY0OCAyLjU0NjQ1MSAxLjk2MDY0OCAxLjk4NDU1OCAxLjk3MjYwM0MxLjg1MzA1MSAxLjk3MjYwMyAxLjczMzQ5OSAxLjk3MjYwMyAxLjczMzQ5OSAyLjE5OTc1MUMxLjczMzQ5OSAyLjI4MzQzNyAxLjgwNTIzIDIuMzE5MzAzIDEuODg4OTE3IDIuMzE5MzAzQzIuMDU2Mjg5IDIuMzE5MzAzIDIuMjcxNDgyIDIuMjk1MzkyIDIuNDM4ODU0IDIuMjk1MzkySDMuNjU4MjgxQzMuODM3NjA5IDIuMjk1MzkyIDQuMDQwODQ3IDIuMzE5MzAzIDQuMjIwMTc0IDIuMzE5MzAzQzQuMjkxOTA1IDIuMzE5MzAzIDQuNDM1MzY3IDIuMzE5MzAzIDQuNDM1MzY3IDIuMDkyMTU0QzQuNDM1MzY3IDEuOTcyNjAzIDQuMzM5NzI2IDEuOTcyNjAzIDQuMTYwMzk5IDEuOTcyNjAzQzMuNTk4NTA2IDEuOTcyNjAzIDMuNTYyNjQgMS44ODg5MTcgMy41NjI2NCAxLjc5MzI3NUMzLjU2MjY0IDEuNzMzNDk5IDMuNTc0NTk1IDEuNzIxNTQ0IDMuNjEwNDYxIDEuNTY2MTI3TDUuMjcyMjI5IC01LjE1MjY3N1pNMy41ODY1NSAtMS40MjI2NjVDMy41MjY3NzUgLTEuMjE5NDI3IDMuNTI2Nzc1IC0xLjE5NTUxNyAzLjM1OTQwMiAtMC45NjgzNjlDMy4wOTYzODkgLTAuNjMzNjI0IDIuNTcwMzYxIC0wLjExOTU1MiAyLjAwODQ2OCAtMC4xMTk1NTJDMS41MTgzMDYgLTAuMTE5NTUyIDEuMjQzMzM3IC0wLjU2MTg5MyAxLjI0MzMzNyAtMS4yNjcyNDhDMS4yNDMzMzcgLTEuOTI0NzgyIDEuNjEzOTQ4IC0zLjI2Mzc2MSAxLjg0MTA5NiAtMy43NjU4NzhDMi4yNDc1NzIgLTQuNjAyNzQgMi44MDk0NjUgLTUuMDMzMTI2IDMuMjc1NzE2IC01LjAzMzEyNkM0LjA2NDc1NyAtNS4wMzMxMjYgNC4yMjAxNzQgLTQuMDUyODAyIDQuMjIwMTc0IC0zLjk1NzE2MUM0LjIyMDE3NCAtMy45NDUyMDUgNC4xODQzMDkgLTMuNzg5Nzg4IDQuMTcyMzU0IC0zLjc2NTg3OEwzLjU4NjU1IC0xLjQyMjY2NVonIGlkPSdnNS0xMTMnLz4KPHBhdGggZD0nTTIuNzI1Nzc4IC0yLjM5MTAzNEMyLjkyOTAxNiAtMi4zNTUxNjggMy4yNTE4MDYgLTIuMjgzNDM3IDMuMzIzNTM3IC0yLjI3MTQ4MkMzLjQ3ODk1NCAtMi4yMjM2NjEgNC4wMTY5MzYgLTIuMDMyMzc5IDQuMDE2OTM2IC0xLjQ1ODUzMUM0LjAxNjkzNiAtMS4wODc5MiAzLjY4MjE5MiAtMC4xMTk1NTIgMi4yOTUzOTIgLTAuMTE5NTUyQzIuMDQ0MzM0IC0wLjExOTU1MiAxLjE0NzY5NiAtMC4xNTU0MTcgMC45MDg1OTMgLTAuODEyOTUxQzEuMzg2OCAtMC43NTMxNzYgMS42MjU5MDMgLTEuMTIzNzg2IDEuNjI1OTAzIC0xLjM4NjhDMS42MjU5MDMgLTEuNjM3ODU4IDEuNDU4NTMxIC0xLjc2OTM2NSAxLjIxOTQyNyAtMS43NjkzNjVDMC45NTY0MTMgLTEuNzY5MzY1IDAuNjA5NzE0IC0xLjU2NjEyNyAwLjYwOTcxNCAtMS4wMjgxNDRDMC42MDk3MTQgLTAuMzIyNzkgMS4zMjcwMjQgMC4xMTk1NTIgMi4yODM0MzcgMC4xMTk1NTJDNC4xMDA2MjMgMC4xMTk1NTIgNC42Mzg2MDUgLTEuMjE5NDI3IDQuNjM4NjA1IC0xLjg0MTA5NkM0LjYzODYwNSAtMi4wMjA0MjMgNC42Mzg2MDUgLTIuMzU1MTY4IDQuMjU2MDQgLTIuNzM3NzMzQzMuOTU3MTYxIC0zLjAyNDY1OCAzLjY3MDIzNyAtMy4wODQ0MzMgMy4wMjQ2NTggLTMuMjE1OTRDMi43MDE4NjggLTMuMjg3NjcxIDIuMTg3Nzk2IC0zLjM5NTI2OCAyLjE4Nzc5NiAtMy45MzMyNUMyLjE4Nzc5NiAtNC4xNzIzNTQgMi40MDI5ODkgLTUuMDMzMTI2IDMuNTM4NzMgLTUuMDMzMTI2QzQuMDQwODQ3IC01LjAzMzEyNiA0LjUzMTAwOSAtNC44NDE4NDMgNC42NTA1NiAtNC40MTE0NTdDNC4xMjQ1MzMgLTQuNDExNDU3IDQuMTAwNjIzIC0zLjk1NzE2MSA0LjEwMDYyMyAtMy45NDUyMDVDNC4xMDA2MjMgLTMuNjk0MTQ3IDQuMzI3NzcxIC0zLjYyMjQxNiA0LjQzNTM2NyAtMy42MjI0MTZDNC42MDI3NCAtMy42MjI0MTYgNC45Mzc0ODQgLTMuNzUzOTIzIDQuOTM3NDg0IC00LjI1NjA0UzQuNDgzMTg4IC01LjI3MjIyOSAzLjU1MDY4NSAtNS4yNzIyMjlDMS45ODQ1NTggLTUuMjcyMjI5IDEuNTY2MTI3IC00LjA0MDg0NyAxLjU2NjEyNyAtMy41NTA2ODVDMS41NjYxMjcgLTIuNjQyMDkyIDIuNDUwODA5IC0yLjQ1MDgwOSAyLjcyNTc3OCAtMi4zOTEwMzRaJyBpZD0nZzUtMTE1Jy8+CjxwYXRoIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4NiAtMC41Mzc5ODMgMS44MTcxODYgLTIuOTc2ODM3QzEuODE3MTg2IC01LjI5NjEzOSAyLjM3OTA3OCAtNy4yOTI2NTMgMy43NjU4NzggLTguNzAzMzYyQzMuODg1NDMgLTguODEwOTU5IDMuODg1NDMgLTguODM0ODY5IDMuODg1NDMgLTguODcwNzM1QzMuODg1NDMgLTguOTQyNDY2IDMuODI1NjU0IC04Ljk2NjM3NiAzLjc3NzgzMyAtOC45NjYzNzZDMy42MjI0MTYgLTguOTY2Mzc2IDIuNjQyMDkyIC04LjEwNTYwNCAyLjA1NjI4OSAtNi45MzM5OThDMS40NDY1NzUgLTUuNzI2NTI2IDEuMTcxNjA2IC00LjQ0NzMyMyAxLjE3MTYwNiAtMi45NzY4MzdDMS4xNzE2MDYgLTEuOTEyODI3IDEuMzM4OTc5IC0wLjQ5MDE2MiAxLjk2MDY0OCAwLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJyBpZD0nZzctNDAnLz4KPHBhdGggZD0nTTMuMzcxMzU3IC0yLjk3NjgzN0MzLjM3MTM1NyAtMy44ODU0MyAzLjI1MTgwNiAtNS4zNjc4NyAyLjU4MjMxNiAtNi43NTQ2N0MxLjg3Njk2MSAtOC4xODkyOSAwLjg5NjYzOCAtOC45NjYzNzYgMC43NjUxMzEgLTguOTY2Mzc2QzAuNzE3MzEgLTguOTY2Mzc2IDAuNjU3NTM0IC04Ljk0MjQ2NiAwLjY1NzUzNCAtOC44NzA3MzVDMC42NTc1MzQgLTguODM0ODY5IDAuNjU3NTM0IC04LjgxMDk1OSAwLjg2MDc3MiAtOC42MDc3MjFDMi4wNTYyODkgLTcuNDAwMjQ5IDIuNzI1Nzc4IC01LjQyNzY0NiAyLjcyNTc3OCAtMi45ODg3OTJDMi43MjU3NzggLTAuNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IDAuNzc3MDg2IDIuNzM3NzMzQzAuNjU3NTM0IDIuODQ1MzMgMC42NTc1MzQgMi44NjkyNCAwLjY1NzUzNCAyLjkwNTEwNkMwLjY1NzUzNCAyLjk3NjgzNyAwLjcxNzMxIDMuMDAwNzQ3IDAuNzY1MTMxIDMuMDAwNzQ3QzAuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IDAuOTY4MzY5QzMuMDk2Mzg5IC0wLjI1MTA1OSAzLjM3MTM1NyAtMS41NDIyMTcgMy4zNzEzNTcgLTIuOTc2ODM3WicgaWQ9J2c3LTQxJy8+CjxwYXRoIGQ9J000Ljc3MDExMiAtMi43NjE2NDRIOC4wNjk3MzhDOC4yMzcxMTEgLTIuNzYxNjQ0IDguNDUyMzA0IC0yLjc2MTY0NCA4LjQ1MjMwNCAtMi45NzY4MzdDOC40NTIzMDQgLTMuMjAzOTg1IDguMjQ5MDY2IC0zLjIwMzk4NSA4LjA2OTczOCAtMy4yMDM5ODVINC43NzAxMTJWLTYuNTAzNjExQzQuNzcwMTEyIC02LjY3MDk4NCA0Ljc3MDExMiAtNi44ODYxNzcgNC41NTQ5MTkgLTYuODg2MTc3QzQuMzI3NzcxIC02Ljg4NjE3NyA0LjMyNzc3MSAtNi42ODI5MzkgNC4zMjc3NzEgLTYuNTAzNjExVi0zLjIwMzk4NUgxLjAyODE0NEMwLjg2MDc3MiAtMy4yMDM5ODUgMC42NDU1NzkgLTMuMjAzOTg1IDAuNjQ1NTc5IC0yLjk4ODc5MkMwLjY0NTU3OSAtMi43NjE2NDQgMC44NDg4MTcgLTIuNzYxNjQ0IDEuMDI4MTQ0IC0yLjc2MTY0NEg0LjMyNzc3MVYwLjUzNzk4M0M0LjMyNzc3MSAwLjcwNTM1NSA0LjMyNzc3MSAwLjkyMDU0OCA0LjU0Mjk2NCAwLjkyMDU0OEM0Ljc3MDExMiAwLjkyMDU0OCA0Ljc3MDExMiAwLjcxNzMxIDQuNzcwMTEyIDAuNTM3OTgzVi0yLjc2MTY0NFonIGlkPSdnNy00MycvPgo8cGF0aCBkPSdNMy40NDMwODggLTcuNjYzMjYzQzMuNDQzMDg4IC03LjkzODIzMiAzLjQ0MzA4OCAtNy45NTAxODcgMy4yMDM5ODUgLTcuOTUwMTg3QzIuOTE3MDYxIC03LjYyNzM5NyAyLjMxOTMwMyAtNy4xODUwNTYgMS4wODc5MiAtNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5IC02LjgzODM1NiAxLjk2MDY0OCAtNi44MzgzNTYgMi42MTgxODIgLTcuMTQ5MTkxVi0wLjkyMDU0OEMyLjYxODE4MiAtMC40OTAxNjIgMi41ODIzMTYgLTAuMzQ2NyAxLjUzMDI2MiAtMC4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEgLTAuMDIzOTEgMi42NDIwOTIgLTAuMDIzOTEgMy4wMzY2MTMgLTAuMDIzOTFTNC41Nzg4MjkgLTAuMDIzOTEgNC45MDE2MTkgMFYtMC4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0IC0wLjM0NjcgMy40NDMwODggLTAuNDkwMTYyIDMuNDQzMDg4IC0wLjkyMDU0OFYtNy42NjMyNjNaJyBpZD0nZzctNDknLz4KPHBhdGggZD0nTTguMDY5NzM4IC0zLjg3MzQ3NEM4LjIzNzExMSAtMy44NzM0NzQgOC40NTIzMDQgLTMuODczNDc0IDguNDUyMzA0IC00LjA4ODY2N0M4LjQ1MjMwNCAtNC4zMTU4MTYgOC4yNDkwNjYgLTQuMzE1ODE2IDguMDY5NzM4IC00LjMxNTgxNkgxLjAyODE0NEMwLjg2MDc3MiAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMzE1ODE2IDAuNjQ1NTc5IC00LjEwMDYyM0MwLjY0NTU3OSAtMy44NzM0NzQgMC44NDg4MTcgLTMuODczNDc0IDEuMDI4MTQ0IC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzggLTEuNjQ5ODEzQzguMjM3MTExIC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS42NDk4MTMgOC40NTIzMDQgLTEuODY1MDA2QzguNDUyMzA0IC0yLjA5MjE1NCA4LjI0OTA2NiAtMi4wOTIxNTQgOC4wNjk3MzggLTIuMDkyMTU0SDEuMDI4MTQ0QzAuODYwNzcyIC0yLjA5MjE1NCAwLjY0NTU3OSAtMi4wOTIxNTQgMC42NDU1NzkgLTEuODc2OTYxQzAuNjQ1NTc5IC0xLjY0OTgxMyAwLjg0ODgxNyAtMS42NDk4MTMgMS4wMjgxNDQgLTEuNjQ5ODEzSDguMDY5NzM4WicgaWQ9J2c3LTYxJy8+CjxwYXRoIGQ9J00yLjk4ODc5MiAyLjk4ODc5MlYyLjU0NjQ1MUgxLjgyOTE0MVYtOC41MjQwMzVIMi45ODg3OTJWLTguOTY2Mzc2SDEuMzg2OFYyLjk4ODc5MkgyLjk4ODc5MlonIGlkPSdnNy05MScvPgo8cGF0aCBkPSdNMS44NTMwNTEgLTguOTY2Mzc2SDAuMjUxMDU5Vi04LjUyNDAzNUgxLjQxMDcxVjIuNTQ2NDUxSDAuMjUxMDU5VjIuOTg4NzkySDEuODUzMDUxVi04Ljk2NjM3NlonIGlkPSdnNy05MycvPgo8cGF0aCBkPSdNMi4wODAxOTkgLTcuMzY0Mzg0QzIuMDgwMTk5IC03LjY3NTIxOCAxLjgyOTE0MSAtNy45NTAxODcgMS40OTQzOTYgLTcuOTUwMTg3QzEuMTgzNTYyIC03Ljk1MDE4NyAwLjkyMDU0OCAtNy42OTkxMjggMC45MjA1NDggLTcuMzc2MzM5QzAuOTIwNTQ4IC03LjAxNzY4NCAxLjIwNzQ3MiAtNi43OTA1MzUgMS40OTQzOTYgLTYuNzkwNTM1QzEuODY1MDA2IC02Ljc5MDUzNSAyLjA4MDE5OSAtNy4xMDEzNyAyLjA4MDE5OSAtNy4zNjQzODRaTTAuNDMwMzg2IC01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTcgLTQuNzk0MDIyIDEuMzAzMTEzIC00LjcyMjI5MSAxLjMwMzExMyAtNC4xMzY0ODhWLTAuODg0NjgyQzEuMzAzMTEzIC0wLjM0NjcgMS4xNzE2MDYgLTAuMzQ2NyAwLjM5NDUyMSAtMC4zNDY3VjBDMC43MjkyNjUgLTAuMDIzOTEgMS4zMDMxMTMgLTAuMDIzOTEgMS42NDk4MTMgLTAuMDIzOTFDMS43ODEzMiAtMC4wMjM5MSAyLjQ3NDcyIC0wLjAyMzkxIDIuODgxMTk2IDBWLTAuMzQ2N0MyLjEwNDExIC0wLjM0NjcgMi4wNTYyODkgLTAuNDA2NDc2IDIuMDU2Mjg5IC0wLjg3MjcyN1YtNS4yNzIyMjlMMC40MzAzODYgLTUuMTQwNzIyWicgaWQ9J2c3LTEwNScvPgo8cGF0aCBkPSdNOC41NzE4NTYgLTIuOTA1MTA2QzguNTcxODU2IC00LjAxNjkzNiA4LjU3MTg1NiAtNC4zNTE2ODEgOC4yOTY4ODcgLTQuNzM0MjQ3QzcuOTUwMTg3IC01LjIwMDQ5OCA3LjM4ODI5NCAtNS4yNzIyMjkgNi45ODE4MTggLTUuMjcyMjI5QzUuOTg5NTM5IC01LjI3MjIyOSA1LjQ4NzQyMiAtNC41NTQ5MTkgNS4yOTYxMzkgLTQuMDg4NjY3QzUuMTI4NzY3IC01LjAwOTIxNSA0LjQ4MzE4OCAtNS4yNzIyMjkgMy43MzAwMTIgLTUuMjcyMjI5QzIuNTcwMzYxIC01LjI3MjIyOSAyLjExNjA2NSAtNC4yNzk5NSAyLjAyMDQyMyAtNC4wNDA4NDdIMi4wMDg0NjhWLTUuMjcyMjI5TDAuMzgyNTY1IC01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTcgLTQuNzk0MDIyIDEuMjkxMTU4IC00LjcxMDMzNiAxLjI5MTE1OCAtNC4xMjQ1MzNWLTAuODg0NjgyQzEuMjkxMTU4IC0wLjM0NjcgMS4xNTk2NTEgLTAuMzQ2NyAwLjM4MjU2NSAtMC4zNDY3VjBDMC42OTM0IC0wLjAyMzkxIDEuMzM4OTc5IC0wLjAyMzkxIDEuNjczNzI0IC0wLjAyMzkxQzIuMDIwNDIzIC0wLjAyMzkxIDIuNjY2MDAyIC0wLjAyMzkxIDIuOTc2ODM3IDBWLTAuMzQ2N0MyLjIxMTcwNiAtMC4zNDY3IDIuMDY4MjQ0IC0wLjM0NjcgMi4wNjgyNDQgLTAuODg0NjgyVi0zLjEwODM0NEMyLjA2ODI0NCAtNC4zNjM2MzYgMi44OTMxNTEgLTUuMDMzMTI2IDMuNjM0MzcxIC01LjAzMzEyNlM0LjU0Mjk2NCAtNC40MjM0MTIgNC41NDI5NjQgLTMuNjk0MTQ3Vi0wLjg4NDY4MkM0LjU0Mjk2NCAtMC4zNDY3IDQuNDExNDU3IC0wLjM0NjcgMy42MzQzNzEgLTAuMzQ2N1YwQzMuOTQ1MjA1IC0wLjAyMzkxIDQuNTkwNzg1IC0wLjAyMzkxIDQuOTI1NTI5IC0wLjAyMzkxQzUuMjcyMjI5IC0wLjAyMzkxIDUuOTE3ODA4IC0wLjAyMzkxIDYuMjI4NjQzIDBWLTAuMzQ2N0M1LjQ2MzUxMiAtMC4zNDY3IDUuMzIwMDUgLTAuMzQ2NyA1LjMyMDA1IC0wLjg4NDY4MlYtMy4xMDgzNDRDNS4zMjAwNSAtNC4zNjM2MzYgNi4xNDQ5NTYgLTUuMDMzMTI2IDYuODg2MTc3IC01LjAzMzEyNlM3Ljc5NDc3IC00LjQyMzQxMiA3Ljc5NDc3IC0zLjY5NDE0N1YtMC44ODQ2ODJDNy43OTQ3NyAtMC4zNDY3IDcuNjYzMjYzIC0wLjM0NjcgNi44ODYxNzcgLTAuMzQ2N1YwQzcuMTk3MDExIC0wLjAyMzkxIDcuODQyNTkgLTAuMDIzOTEgOC4xNzczMzUgLTAuMDIzOTFDOC41MjQwMzUgLTAuMDIzOTEgOS4xNjk2MTQgLTAuMDIzOTEgOS40ODA0NDggMFYtMC4zNDY3QzguODgyNjkgLTAuMzQ2NyA4LjU4MzgxMSAtMC4zNDY3IDguNTcxODU2IC0wLjcwNTM1NVYtMi45MDUxMDZaJyBpZD0nZzctMTA5Jy8+CjxwYXRoIGQ9J001LjMyMDA1IC0yLjkwNTEwNkM1LjMyMDA1IC00LjAxNjkzNiA1LjMyMDA1IC00LjM1MTY4MSA1LjA0NTA4MSAtNC43MzQyNDdDNC42OTgzODEgLTUuMjAwNDk4IDQuMTM2NDg4IC01LjI3MjIyOSAzLjczMDAxMiAtNS4yNzIyMjlDMi41NzAzNjEgLTUuMjcyMjI5IDIuMTE2MDY1IC00LjI3OTk1IDIuMDIwNDIzIC00LjA0MDg0N0gyLjAwODQ2OFYtNS4yNzIyMjlMMC4zODI1NjUgLTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE5NTUxNyAtNC43OTQwMjIgMS4yOTExNTggLTQuNzEwMzM2IDEuMjkxMTU4IC00LjEyNDUzM1YtMC44ODQ2ODJDMS4yOTExNTggLTAuMzQ2NyAxLjE1OTY1MSAtMC4zNDY3IDAuMzgyNTY1IC0wLjM0NjdWMEMwLjY5MzQgLTAuMDIzOTEgMS4zMzg5NzkgLTAuMDIzOTEgMS42NzM3MjQgLTAuMDIzOTFDMi4wMjA0MjMgLTAuMDIzOTEgMi42NjYwMDIgLTAuMDIzOTEgMi45NzY4MzcgMFYtMC4zNDY3QzIuMjExNzA2IC0wLjM0NjcgMi4wNjgyNDQgLTAuMzQ2NyAyLjA2ODI0NCAtMC44ODQ2ODJWLTMuMTA4MzQ0QzIuMDY4MjQ0IC00LjM2MzYzNiAyLjg5MzE1MSAtNS4wMzMxMjYgMy42MzQzNzEgLTUuMDMzMTI2UzQuNTQyOTY0IC00LjQyMzQxMiA0LjU0Mjk2NCAtMy42OTQxNDdWLTAuODg0NjgyQzQuNTQyOTY0IC0wLjM0NjcgNC40MTE0NTcgLTAuMzQ2NyAzLjYzNDM3MSAtMC4zNDY3VjBDMy45NDUyMDUgLTAuMDIzOTEgNC41OTA3ODUgLTAuMDIzOTEgNC45MjU1MjkgLTAuMDIzOTFDNS4yNzIyMjkgLTAuMDIzOTEgNS45MTc4MDggLTAuMDIzOTEgNi4yMjg2NDMgMFYtMC4zNDY3QzUuNjMwODg0IC0wLjM0NjcgNS4zMzIwMDUgLTAuMzQ2NyA1LjMyMDA1IC0wLjcwNTM1NVYtMi45MDUxMDZaJyBpZD0nZzctMTEwJy8+CjxwYXRoIGQ9J000Ljk3MzM1IDE3LjgwMTI0NUM0Ljk3MzM1IDE3LjIzOTM1MiA0Ljk3MzM1IDE2LjM1NDY3IDQuMjIwMTc0IDE1LjM4NjMwMUMzLjc1MzkyMyAxNC43ODg1NDMgMy4wNzI0NzggMTQuMjM4NjA1IDIuMjQ3NTcyIDEzLjg2Nzk5NUM0LjU3ODgyOSAxMi43NDQyMDkgNC45NzMzNSAxMS4wMjI2NjUgNC45NzMzNSAxMC4zNDEyMlYzLjQ1NTA0NEM0Ljk3MzM1IDIuNzEzODIzIDQuOTczMzUgMS4xODM1NjIgNy4yOTI2NTMgMC4wMzU4NjZDNy4zODgyOTQgLTAuMDExOTU1IDcuMzg4Mjk0IC0wLjAzNTg2NiA3LjM4ODI5NCAtMC4yMTUxOTNDNy4zODgyOTQgLTAuNDY2MjUyIDcuMzg4Mjk0IC0wLjQ3ODIwNyA3LjEyNTI4IC0wLjQ3ODIwN0M2Ljk1NzkwOCAtMC40NzgyMDcgNi45MzM5OTggLTAuNDc4MjA3IDYuNjIzMTYzIC0wLjMzNDc0NUM1LjQzOTYwMSAwLjI1MTA1OSA0LjI2Nzk5NSAxLjE5NTUxNyA0LjAxNjkzNiAyLjY1NDA0N0MzLjk4MTA3MSAyLjg5MzE1MSAzLjk4MTA3MSAzLjAwMDc0NyAzLjk4MTA3MSAzLjgwMTc0M1Y5LjMyNTAzMUMzLjk4MTA3MSA5LjY5NTY0MSAzLjk4MTA3MSAxMC4zMTczMSAzLjk2OTExNiAxMC40NDg4MTdDMy44NjE1MTkgMTEuNzA0MTEgMy4xMzIyNTQgMTIuNzkyMDMgMS43NjkzNjUgMTMuNTQ1MjA1QzEuNTc4MDgyIDEzLjY1MjgwMiAxLjU2NjEyNyAxMy42NjQ3NTcgMS41NjYxMjcgMTMuODU2MDRDMS41NjYxMjcgMTQuMDU5Mjc4IDEuNTc4MDgyIDE0LjA3MTIzMyAxLjc0NTQ1NSAxNC4xNjY4NzRDMi41NDY0NTEgMTQuNjA5MjE1IDMuNjk0MTQ3IDE1LjQ2OTk4OCAzLjkzMzI1IDE2Ljk2NDM4NEMzLjk4MTA3MSAxNy4yMzkzNTIgMy45ODEwNzEgMTcuMjYzMjYzIDMuOTgxMDcxIDE3LjM5NDc3VjI0LjQ5NjEzOUMzLjk4MTA3MSAyNi4yMjk2MzkgNS4xNzY1ODggMjcuMzY1MzggNi42NTkwMjkgMjguMDcwNzM1QzYuOTIyMDQyIDI4LjIwMjI0MiA2Ljk0NTk1MyAyOC4yMDIyNDIgNy4xMjUyOCAyOC4yMDIyNDJDNy4zNzYzMzkgMjguMjAyMjQyIDcuMzg4Mjk0IDI4LjIwMjI0MiA3LjM4ODI5NCAyNy45MzkyMjhDNy4zODgyOTQgMjcuNzQ3OTQ1IDcuMzc2MzM5IDI3LjczNTk5IDcuMjgwNjk3IDI3LjY3NjIxNEM2Ljc5MDUzNSAyNy40MzcxMTEgNS4yNDgzMTkgMjYuNjYwMDI1IDQuOTk3MjYgMjQuOTM4NDgxQzQuOTczMzUgMjQuNzcxMTA4IDQuOTczMzUgMjQuNjM5NjAxIDQuOTczMzUgMjMuOTIyMjkxVjE3LjgwMTI0NVonIGlkPSdnMS0yNicvPgo8cGF0aCBkPSdNNC45NzMzNSAxNy42MDk5NjNDNC45NzMzNSAxNi4xOTkyNTMgNS42OTA2NiAxNC45Nzk4MjYgNy4yOTI2NTMgMTQuMTE5MDU0QzcuMzc2MzM5IDE0LjA3MTIzMyA3LjM4ODI5NCAxNC4wNTkyNzggNy4zODgyOTQgMTMuODY3OTk1QzcuMzg4Mjk0IDEzLjY2NDc1NyA3LjM3NjMzOSAxMy42NTI4MDIgNy4yNDQ4MzIgMTMuNTgxMDcxQzUuMDkyOTAyIDEyLjQzMzM3NSA0Ljk3MzM1IDEwLjY3NTk2NSA0Ljk3MzM1IDEwLjMyOTI2NVYzLjIyNzg5NUM0Ljk3MzM1IDEuNDk0Mzk2IDMuNzc3ODMzIDAuMzU4NjU1IDIuMjk1MzkyIC0wLjM0NjdDMi4wMzIzNzkgLTAuNDc4MjA3IDIuMDA4NDY4IC0wLjQ3ODIwNyAxLjgyOTE0MSAtMC40NzgyMDdDMS41NzgwODIgLTAuNDc4MjA3IDEuNTY2MTI3IC0wLjQ2NjI1MiAxLjU2NjEyNyAtMC4yMTUxOTNDMS41NjYxMjcgLTAuMDM1ODY2IDEuNTY2MTI3IC0wLjAxMTk1NSAxLjY3MzcyNCAwLjA0NzgyMUMyLjE4Nzc5NiAwLjI5ODg3OSAzLjcxODA1NyAxLjA3NTk2NSAzLjk1NzE2MSAyLjc4NTU1NEMzLjk4MTA3MSAyLjk1MjkyNyAzLjk4MTA3MSAzLjA4NDQzMyAzLjk4MTA3MSAzLjgwMTc0M1Y5LjkyMjc5QzMuOTgxMDcxIDEwLjQ4NDY4MiAzLjk4MTA3MSAxMS4zNjkzNjUgNC43MzQyNDcgMTIuMzM3NzMzQzUuMjAwNDk4IDEyLjkzNTQ5MiA1Ljg4MTk0MyAxMy40ODU0MyA2LjcwNjg0OSAxMy44NTYwNEM0LjM3NTU5MiAxNC45Nzk4MjYgMy45ODEwNzEgMTYuNzAxMzcgMy45ODEwNzEgMTcuMzgyODE0VjI0LjI2ODk5MUMzLjk4MTA3MSAyNC44OTA2NiAzLjk4MTA3MSAyNS41ODQwNiAzLjI4NzY3MSAyNi40NTY3ODdDMi43NDk2ODkgMjcuMTI2Mjc2IDIuMTYzODg1IDI3LjQzNzExMSAxLjY0OTgxMyAyNy42ODgxNjlDMS41NjYxMjcgMjcuNzM1OTkgMS41NjYxMjcgMjcuNzgzODExIDEuNTY2MTI3IDI3LjkzOTIyOEMxLjU2NjEyNyAyOC4xOTAyODYgMS41NzgwODIgMjguMjAyMjQyIDEuODI5MTQxIDI4LjIwMjI0MkMxLjk5NjUxMyAyOC4yMDIyNDIgMi4wMjA0MjMgMjguMjAyMjQyIDIuMzMxMjU4IDI4LjA1ODc4QzMuNTE0ODE5IDI3LjQ3Mjk3NiA0LjY4NjQyNiAyNi41Mjg1MTggNC45Mzc0ODQgMjUuMDY5OTg4QzQuOTczMzUgMjQuODMwODg0IDQuOTczMzUgMjQuNzIzMjg4IDQuOTczMzUgMjMuOTIyMjkxVjE3LjYwOTk2M1onIGlkPSdnMS0yNycvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMzguODU0Mjk2JyB4bGluazpocmVmPScjZzUtNzcnIHk9Jzk2LjAzOTk4MScvPgo8dXNlIHg9JzUxLjQyNzkwMycgeGxpbms6aHJlZj0nI2cyLTQ4JyB5PSc5MS4xMDM3OTUnLz4KPHVzZSB4PSc1MC4xNzkxMDcnIHhsaW5rOmhyZWY9JyNnNC05OCcgeT0nOTguOTk1NDk3Jy8+Cjx1c2UgeD0nNTQuMjk5ODI0JyB4bGluazpocmVmPScjZzctNDAnIHk9Jzk2LjAzOTk4MScvPgo8dXNlIHg9JzU4Ljg1MjE1JyB4bGluazpocmVmPScjZzUtMTEzJyB5PSc5Ni4wMzk5ODEnLz4KPHVzZSB4PSc2NC40NzEzMDYnIHhsaW5rOmhyZWY9JyNnNS01OScgeT0nOTYuMDM5OTgxJy8+Cjx1c2UgeD0nNjkuNzE1NDY1JyB4bGluazpocmVmPScjZzUtODMnIHk9Jzk2LjAzOTk4MScvPgo8dXNlIHg9Jzc3LjYxMDc4OCcgeGxpbms6aHJlZj0nI2c3LTQxJyB5PSc5Ni4wMzk5ODEnLz4KPHVzZSB4PSc5Mi4xMjU3NScgeGxpbms6aHJlZj0nI2c3LTYxJyB5PSc5Ni4wMzk5ODEnLz4KPHVzZSB4PScxMTEuMTkzMDQyJyB4bGluazpocmVmPScjZzctMTA5JyB5PSc5Ni4wMzk5ODEnLz4KPHVzZSB4PScxMjAuOTQ4MDI2JyB4bGluazpocmVmPScjZzctMTA1JyB5PSc5Ni4wMzk5ODEnLz4KPHVzZSB4PScxMjQuMTk5Njg3JyB4bGluazpocmVmPScjZzctMTEwJyB5PSc5Ni4wMzk5ODEnLz4KPHVzZSB4PScxMzIuNjk1NTA3JyB4bGluazpocmVmPScjZzEtMjYnIHk9Jzc5LjE4MzA0NCcvPgo8dXNlIHg9JzE0Ni42NDMyMTgnIHhsaW5rOmhyZWY9JyNnNy0xMDknIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzE1Ni4zOTgyMDInIHhsaW5rOmhyZWY9JyNnNy0xMDUnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzE1OS42NDk4NjMnIHhsaW5rOmhyZWY9JyNnNy0xMTAnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzE2Ni4xNTMxODYnIHhsaW5rOmhyZWY9JyNnNi00OCcgeT0nOTAuNzI2NTQ4Jy8+Cjx1c2UgeD0nMTcwLjM4NzM2OScgeGxpbms6aHJlZj0nI2cwLTU0JyB5PSc5MC43MjY1NDgnLz4KPHVzZSB4PScxNzYuNTg2MzY3JyB4bGluazpocmVmPScjZzQtMTA3JyB5PSc5MC43MjY1NDgnLz4KPHVzZSB4PScxODEuMjA3OTgyJyB4bGluazpocmVmPScjZzQtNjAnIHk9JzkwLjcyNjU0OCcvPgo8dXNlIHg9JzE4Ny43OTQ0ODknIHhsaW5rOmhyZWY9JyNnNC0xMDgnIHk9JzkwLjcyNjU0OCcvPgo8dXNlIHg9JzE5MC40MTY2MTQnIHhsaW5rOmhyZWY9JyNnNi00MCcgeT0nOTAuNzI2NTQ4Jy8+Cjx1c2UgeD0nMTkzLjcwOTg2NycgeGxpbms6aHJlZj0nI2c0LTExMycgeT0nOTAuNzI2NTQ4Jy8+Cjx1c2UgeD0nMTk3Ljc3NjYxOCcgeGxpbms6aHJlZj0nI2c2LTQxJyB5PSc5MC43MjY1NDgnLz4KPHVzZSB4PScyMDMuNTYwNTAxJyB4bGluazpocmVmPScjZzMtMTAyJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PScyMDkuNTM4MScgeGxpbms6aHJlZj0nI2c1LTc3JyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PScyMjIuMTExNzA3JyB4bGluazpocmVmPScjZzItNDgnIHk9Jzg0LjUyODQwMScvPgo8dXNlIHg9JzIyMC44NjI5MTEnIHhsaW5rOmhyZWY9JyNnNC05OCcgeT0nOTEuOTc1OTUyJy8+Cjx1c2UgeD0nMjI0Ljk4MzYyOCcgeGxpbms6aHJlZj0nI2c3LTQwJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PScyMjkuNTM1OTUzJyB4bGluazpocmVmPScjZzUtMTEzJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PScyMzUuMTU1MTEnIHhsaW5rOmhyZWY9JyNnNy05MScgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMjM4LjQwNjc3MScgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PScyNDQuMjU5NzYxJyB4bGluazpocmVmPScjZzUtNTgnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzI0Ny41MTE0MjMnIHhsaW5rOmhyZWY9JyNnNS01OCcgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMjUwLjc2MzA4NCcgeGxpbms6aHJlZj0nI2c1LTEwNycgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMjU3LjI1MjU4OCcgeGxpbms6aHJlZj0nI2c3LTkzJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PScyNjAuNTA0MjQ5JyB4bGluazpocmVmPScjZzUtNTknIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzI2NS43NDg0MDgnIHhsaW5rOmhyZWY9JyNnNS04MycgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMjczLjY0MzczMScgeGxpbms6aHJlZj0nI2c3LTQxJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PScyODAuODUyNzInIHhsaW5rOmhyZWY9JyNnNy00MycgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMjkyLjYxNDAzNScgeGxpbms6aHJlZj0nI2c3LTEwOScgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMzAyLjM2OTAxOScgeGxpbms6aHJlZj0nI2c3LTEwNScgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMzA1LjYyMDY4JyB4bGluazpocmVmPScjZzctMTEwJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSczMTIuMTI0MDAzJyB4bGluazpocmVmPScjZzctNDAnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzMxNi42NzYzMjknIHhsaW5rOmhyZWY9JyNnNS03NScgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMzI3LjQ5NDAwOCcgeGxpbms6aHJlZj0nI2c3LTQwJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSczMzIuMDQ2MzM0JyB4bGluazpocmVmPScjZzUtMTEzJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSczMzcuNjY1NDknIHhsaW5rOmhyZWY9JyNnNS01OScgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMzQyLjkwOTY0OScgeGxpbms6aHJlZj0nI2c1LTEwNycgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMzQ5LjM5OTE1MycgeGxpbms6aHJlZj0nI2c1LTU5JyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSczNTQuNjQzMzEyJyB4bGluazpocmVmPScjZzUtODMnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzM2Mi41Mzg2MzUnIHhsaW5rOmhyZWY9JyNnNy00MScgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMzY3LjA5MDk2MScgeGxpbms6aHJlZj0nI2c1LTU5JyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSczNzIuMzM1MTInIHhsaW5rOmhyZWY9JyNnNS0xMDgnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzM3Ni4wODQ5MjgnIHhsaW5rOmhyZWY9JyNnNy00MCcgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMzgwLjYzNzI1NCcgeGxpbms6aHJlZj0nI2c1LTExMycgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMzg2LjI1NjQxMScgeGxpbms6aHJlZj0nI2c3LTQxJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSczOTMuNDY1NCcgeGxpbms6aHJlZj0nI2czLTAnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzQwNS40MjA1NicgeGxpbms6aHJlZj0nI2c1LTEwNycgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nNDExLjkxMDA2NCcgeGxpbms6aHJlZj0nI2c3LTQxJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSc0MTYuNDYyMzknIHhsaW5rOmhyZWY9JyNnMy0xMDMnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzE0Ni42NDMyMTgnIHhsaW5rOmhyZWY9JyNnNy0xMDknIHk9JzEwMi44MTQ1MzQnLz4KPHVzZSB4PScxNTYuMzk4MjAyJyB4bGluazpocmVmPScjZzctMTA1JyB5PScxMDIuODE0NTM0Jy8+Cjx1c2UgeD0nMTU5LjY0OTg2MycgeGxpbms6aHJlZj0nI2c3LTExMCcgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzE2Ni4xNTMxODYnIHhsaW5rOmhyZWY9JyNnNC0xMTUnIHk9JzEwNC42MDc3OTcnLz4KPHVzZSB4PScxNzAuMDY5MTA0JyB4bGluazpocmVmPScjZzItMzEnIHk9JzEwNC42MDc3OTcnLz4KPHVzZSB4PScxNzYuNjU1NjExJyB4bGluazpocmVmPScjZzQtMTEzJyB5PScxMDQuNjA3Nzk3Jy8+Cjx1c2UgeD0nMTgzLjIxMjk5MScgeGxpbms6aHJlZj0nI2czLTEwMicgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzE4OS4xOTA1OScgeGxpbms6aHJlZj0nI2c1LTc3JyB5PScxMDIuODE0NTM0Jy8+Cjx1c2UgeD0nMjAxLjc2NDE5NycgeGxpbms6aHJlZj0nI2cyLTQ4JyB5PSc5OC40NzYwOTcnLz4KPHVzZSB4PScyMDAuNTE1NDAxJyB4bGluazpocmVmPScjZzQtOTgnIHk9JzEwNS45MjM2NDgnLz4KPHVzZSB4PScyMDQuNjM2MTE4JyB4bGluazpocmVmPScjZzctNDAnIHk9JzEwMi44MTQ1MzQnLz4KPHVzZSB4PScyMDkuMTg4NDQ0JyB4bGluazpocmVmPScjZzUtMTE1JyB5PScxMDIuODE0NTM0Jy8+Cjx1c2UgeD0nMjE0LjcwMjQ0OScgeGxpbms6aHJlZj0nI2c1LTU5JyB5PScxMDIuODE0NTM0Jy8+Cjx1c2UgeD0nMjE5Ljk0NjYwOCcgeGxpbms6aHJlZj0nI2c1LTgzJyB5PScxMDIuODE0NTM0Jy8+Cjx1c2UgeD0nMjI3Ljg0MTkzMScgeGxpbms6aHJlZj0nI2c3LTQxJyB5PScxMDIuODE0NTM0Jy8+Cjx1c2UgeD0nMjM1LjA1MDkyMScgeGxpbms6aHJlZj0nI2c3LTQzJyB5PScxMDIuODE0NTM0Jy8+Cjx1c2UgeD0nMjQ2LjgxMjIzNicgeGxpbms6aHJlZj0nI2c1LTEwOCcgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzI1MC41NjIwNDQnIHhsaW5rOmhyZWY9JyNnNy00MCcgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzI1NS4xMTQzNycgeGxpbms6aHJlZj0nI2c1LTExNScgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzI2MC42MjgzNzYnIHhsaW5rOmhyZWY9JyNnNy00MScgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzI2Ny44MzczNjUnIHhsaW5rOmhyZWY9JyNnMy0wJyB5PScxMDIuODE0NTM0Jy8+Cjx1c2UgeD0nMjc5Ljc5MjUyNScgeGxpbms6aHJlZj0nI2c1LTEwOCcgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzI4My41NDIzMzQnIHhsaW5rOmhyZWY9JyNnNy00MCcgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzI4OC4wOTQ2NicgeGxpbms6aHJlZj0nI2c1LTExMycgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzI5My43MTM4MTYnIHhsaW5rOmhyZWY9JyNnNy00MScgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzI5OC4yNjYxNDInIHhsaW5rOmhyZWY9JyNnMy0xMDMnIHk9JzEwMi44MTQ1MzQnLz4KPHVzZSB4PSc0MjcuNDIxMjk0JyB4bGluazpocmVmPScjZzEtMjcnIHk9Jzc5LjE4MzA0NCcvPgo8L2c+Cjwvc3ZnPg==)
Définition D1 : Minimum Keystroke
On définit la façon optimale de saisir une requête sachant un système de complétion
comme étant le minimum obtenu :
(1)#
La quantité  représente le nombre de touche vers le bas qu’il faut taper pour
obtenir la chaîne
représente le nombre de touche vers le bas qu’il faut taper pour
obtenir la chaîne  avec le système de complétion et les
premières lettres de .
avec le système de complétion et les
premières lettres de .
Définition D1 : Régression quantile
On dispose d’un ensemble de n couples
 avec
avec  et
et  . La régression quantile
consiste à trouver
. La régression quantile
consiste à trouver  tels que la
somme
tels que la
somme  est minimale.
est minimale.
Définition D1 : bruit blanc
Une suite de variables aléatoires réelles
 est un bruit blanc :
est un bruit blanc :
 ,
, 

Définition D1 : loi de Poisson et loi exponentielle
Si une variable suit une loi de Poisson de
paramète  , elle a pour densité :
, elle a pour densité :

Si une variable suit une loi exponentielle de paramètre  , elle a pour densité :
, elle a pour densité :

Définition D1 : mot
On note  l’espace des caractères ou des symboles. Un mot ou une séquence est
une suite finie de . On note
l’espace des caractères ou des symboles. Un mot ou une séquence est
une suite finie de . On note
 l’espace des mots formés
de caractères appartenant à .
l’espace des mots formés
de caractères appartenant à .
Définition D1 : mélange de lois normales
Soit une variable aléatoire d’un espace vectoriel de dimension  ,
suit un la loi d’un mélange de lois gaussiennes de paramètres
,
suit un la loi d’un mélange de lois gaussiennes de paramètres
 ,
alors la densité
,
alors la densité  de est de la forme :
de est de la forme :

Avec :  .
.
Définition D1 : neurone
Un neurone à  entrées est une fonction
entrées est une fonction
 définie par :
définie par :

 ,
, 
 avec
avec 
Définition D1 : neurone distance
Un neurone distance à entrées est une fonction
définie par :

- ,

 avec
avec
Définition D1 : orthonormalisation de Schmidt
L’orthonormalisation de Shmidt :
Soit  une base de
une base de 
On définit la famille  par :
par :

Définition D2 : Dynamic Minimum Keystroke modifié
On définit la façon optimale de saisir une requête sachant
un système de complétion comme étant le
minimum obtenu :
(2)#![\begin{eqnarray*}
M"(q, S) &=& \min \left\{ \begin{array}{l}
\min_{1 \infegal k \infegal l(q)} \acc{ M"(q[1..k-1], S) + 1 +\min( K(q, k, S), l(q) - k) } \\
\min_{0 \infegal k \infegal l(q)} \acc{ M"(q[1..k], S) + \delta + \min( K(q, k, S), l(q) - k) }
\end{array} \right .
\end{eqnarray*}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMjguNjkyNjk1cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDc4LjcwNDg0OSA0MjkuODk2MTE0IDI4LjY5MjY5NScgd2lkdGg9JzQyOS44OTYxMTRwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNNy44Nzg0NTYgLTIuNzQ5Njg5QzguMDgxNjk0IC0yLjc0OTY4OSA4LjI5Njg4NyAtMi43NDk2ODkgOC4yOTY4ODcgLTIuOTg4NzkyUzguMDgxNjk0IC0zLjIyNzg5NSA3Ljg3ODQ1NiAtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3MiAtMy4yMjc4OTUgMC45OTIyNzkgLTMuMjI3ODk1IDAuOTkyMjc5IC0yLjk4ODc5MlMxLjIwNzQ3MiAtMi43NDk2ODkgMS40MTA3MSAtMi43NDk2ODlINy44Nzg0NTZaJyBpZD0nZzItMCcvPgo8cGF0aCBkPSdNMy4zODMzMTMgLTcuMzc2MzM5QzMuMzgzMzEzIC03Ljg1NDU0NSAzLjY5NDE0NyAtOC42MTk2NzYgNC45OTcyNiAtOC43MDMzNjJDNS4wNTcwMzYgLTguNzE1MzE4IDUuMTA0ODU3IC04Ljc2MzEzOCA1LjEwNDg1NyAtOC44MzQ4NjlDNS4xMDQ4NTcgLTguOTY2Mzc2IDUuMDA5MjE1IC04Ljk2NjM3NiA0Ljg3NzcwOSAtOC45NjYzNzZDMy42ODIxOTIgLTguOTY2Mzc2IDIuNTk0MjcxIC04LjM1NjY2MyAyLjU4MjMxNiAtNy40NzE5OFYtNC43NDYyMDJDMi41ODIzMTYgLTQuMjc5OTUgMi41ODIzMTYgLTMuODk3Mzg1IDIuMTA0MTEgLTMuNTAyODY0QzEuNjg1Njc5IC0zLjE1NjE2NCAxLjIzMTM4MiAtMy4xMzIyNTQgMC45NjgzNjkgLTMuMTIwMjk5QzAuOTA4NTkzIC0zLjEwODM0NCAwLjg2MDc3MiAtMy4wNjA1MjMgMC44NjA3NzIgLTIuOTg4NzkyQzAuODYwNzcyIC0yLjg2OTI0IDAuOTMyNTAzIC0yLjg2OTI0IDEuMDUyMDU1IC0yLjg1NzI4NUMxLjg0MTA5NiAtMi44MDk0NjUgMi40MTQ5NDQgLTIuMzc5MDc4IDIuNTQ2NDUxIC0xLjc5MzI3NUMyLjU4MjMxNiAtMS42NjE3NjggMi41ODIzMTYgLTEuNjM3ODU4IDIuNTgyMzE2IC0xLjIwNzQ3MlYxLjE1OTY1MUMyLjU4MjMxNiAxLjY2MTc2OCAyLjU4MjMxNiAyLjA0NDMzNCAzLjE1NjE2NCAyLjQ5ODYzQzMuNjIyNDE2IDIuODU3Mjg1IDQuNDExNDU3IDIuOTg4NzkyIDQuODc3NzA5IDIuOTg4NzkyQzUuMDA5MjE1IDIuOTg4NzkyIDUuMTA0ODU3IDIuOTg4NzkyIDUuMTA0ODU3IDIuODU3Mjg1QzUuMTA0ODU3IDIuNzM3NzMzIDUuMDMzMTI2IDIuNzM3NzMzIDQuOTEzNTc0IDIuNzI1Nzc4QzQuMTYwMzk5IDIuNjc3OTU4IDMuNTc0NTk1IDIuMjk1MzkyIDMuNDE5MTc4IDEuNjg1Njc5QzMuMzgzMzEzIDEuNTc4MDgyIDMuMzgzMzEzIDEuNTU0MTcyIDMuMzgzMzEzIDEuMTIzNzg2Vi0xLjM4NjhDMy4zODMzMTMgLTEuOTM2NzM3IDMuMjg3NjcxIC0yLjEzOTk3NSAyLjkwNTEwNiAtMi41MjI1NEMyLjY1NDA0NyAtMi43NzM1OTkgMi4zMDczNDcgLTIuODkzMTUxIDEuOTcyNjAzIC0yLjk4ODc5MkMyLjk1MjkyNyAtMy4yNjM3NjEgMy4zODMzMTMgLTMuODEzNjk5IDMuMzgzMzEzIC00LjUwNzA5OFYtNy4zNzYzMzlaJyBpZD0nZzItMTAyJy8+CjxwYXRoIGQ9J00yLjU4MjMxNiAxLjM5ODc1NUMyLjU4MjMxNiAxLjg3Njk2MSAyLjI3MTQ4MiAyLjY0MjA5MiAwLjk2ODM2OSAyLjcyNTc3OEMwLjkwODU5MyAyLjczNzczMyAwLjg2MDc3MiAyLjc4NTU1NCAwLjg2MDc3MiAyLjg1NzI4NUMwLjg2MDc3MiAyLjk4ODc5MiAwLjk5MjI3OSAyLjk4ODc5MiAxLjA5OTg3NSAyLjk4ODc5MkMyLjI1OTUyNyAyLjk4ODc5MiAzLjM3MTM1NyAyLjQwMjk4OSAzLjM4MzMxMyAxLjQ5NDM5NlYtMS4yMzEzODJDMy4zODMzMTMgLTEuNjk3NjM0IDMuMzgzMzEzIC0yLjA4MDE5OSAzLjg2MTUxOSAtMi40NzQ3MkM0LjI3OTk1IC0yLjgyMTQyIDQuNzM0MjQ3IC0yLjg0NTMzIDQuOTk3MjYgLTIuODU3Mjg1QzUuMDU3MDM2IC0yLjg2OTI0IDUuMTA0ODU3IC0yLjkxNzA2MSA1LjEwNDg1NyAtMi45ODg3OTJDNS4xMDQ4NTcgLTMuMTA4MzQ0IDUuMDMzMTI2IC0zLjEwODM0NCA0LjkxMzU3NCAtMy4xMjAyOTlDNC4xMjQ1MzMgLTMuMTY4MTIgMy41NTA2ODUgLTMuNTk4NTA2IDMuNDE5MTc4IC00LjE4NDMwOUMzLjM4MzMxMyAtNC4zMTU4MTYgMy4zODMzMTMgLTQuMzM5NzI2IDMuMzgzMzEzIC00Ljc3MDExMlYtNy4xMzcyMzVDMy4zODMzMTMgLTcuNjM5MzUyIDMuMzgzMzEzIC04LjAyMTkxOCAyLjgwOTQ2NSAtOC40NzYyMTRDMi4zMzEyNTggLTguODQ2ODI0IDEuNTA2MzUxIC04Ljk2NjM3NiAxLjA5OTg3NSAtOC45NjYzNzZDMC45OTIyNzkgLTguOTY2Mzc2IDAuODYwNzcyIC04Ljk2NjM3NiAwLjg2MDc3MiAtOC44MzQ4NjlDMC44NjA3NzIgLTguNzE1MzE4IDAuOTMyNTAzIC04LjcxNTMxOCAxLjA1MjA1NSAtOC43MDMzNjJDMS44MDUyMyAtOC42NTU1NDIgMi4zOTEwMzQgLTguMjcyOTc2IDIuNTQ2NDUxIC03LjY2MzI2M0MyLjU4MjMxNiAtNy41NTU2NjYgMi41ODIzMTYgLTcuNTMxNzU2IDIuNTgyMzE2IC03LjEwMTM3Vi00LjU5MDc4NUMyLjU4MjMxNiAtNC4wNDA4NDcgMi42Nzc5NTggLTMuODM3NjA5IDMuMDYwNTIzIC0zLjQ1NTA0NEMzLjMxMTU4MiAtMy4yMDM5ODUgMy42NTgyODEgLTMuMDg0NDMzIDMuOTkzMDI2IC0yLjk4ODc5MkMzLjAxMjcwMiAtMi43MTM4MjMgMi41ODIzMTYgLTIuMTYzODg1IDIuNTgyMzE2IC0xLjQ3MDQ4NlYxLjM5ODc1NVonIGlkPSdnMi0xMDMnLz4KPHBhdGggZD0nTTUuMzc5ODI2IC00LjczNDI0N0M1LjQ3NTQ2NyAtNC43ODIwNjcgNS41MzEyNTggLTQuODIxOTE4IDUuNTMxMjU4IC00LjkwOTU4OVM1LjQ1OTUyNyAtNS4wNjg5OTEgNS4zNzE4NTYgLTUuMDY4OTkxQzUuMzMyMDA1IC01LjA2ODk5MSA1LjI2MDI3NCAtNS4wMzcxMTEgNS4yMjgzOTQgLTUuMDIxMTcxTDAuODIwOTIyIC0yLjk0MDk3MUMwLjY4NTQzIC0yLjg3NzIxIDAuNjYxNTE5IC0yLjgyMTQyIDAuNjYxNTE5IC0yLjc1NzY1OVMwLjY5MzQgLTIuNjM4MTA3IDAuODIwOTIyIC0yLjU4MjMxNkw1LjIyODM5NCAtMC41MTAwODdDNS4zMzIwMDUgLTAuNDU0Mjk2IDUuMzQ3OTQ1IC0wLjQ1NDI5NiA1LjM3MTg1NiAtMC40NTQyOTZDNS40NTk1MjcgLTAuNDU0Mjk2IDUuNTMxMjU4IC0wLjUyNjAyNyA1LjUzMTI1OCAtMC42MTM2OTlDNS41MzEyNTggLTAuNzE3MzEgNS40NTk1MjcgLTAuNzQ5MTkxIDUuMzcxODU2IC0wLjc4OTA0MUwxLjE5NTUxNyAtMi43NTc2NTlMNS4zNzk4MjYgLTQuNzM0MjQ3Wk01LjIyODM5NCAxLjAzNjExNUM1LjMzMjAwNSAxLjA5MTkwNSA1LjM0Nzk0NSAxLjA5MTkwNSA1LjM3MTg1NiAxLjA5MTkwNUM1LjQ1OTUyNyAxLjA5MTkwNSA1LjUzMTI1OCAxLjAyMDE3NCA1LjUzMTI1OCAwLjkzMjUwM0M1LjUzMTI1OCAwLjgyODg5MiA1LjQ1OTUyNyAwLjc5NzAxMSA1LjM3MTg1NiAwLjc1NzE2MUwwLjk3MjM1NCAtMS4zMTUwNjhDMC44Njg3NDIgLTEuMzcwODU5IDAuODUyODAyIC0xLjM3MDg1OSAwLjgyMDkyMiAtMS4zNzA4NTlDMC43MjUyOCAtMS4zNzA4NTkgMC42NjE1MTkgLTEuMjk5MTI4IDAuNjYxNTE5IC0xLjIxMTQ1N0MwLjY2MTUxOSAtMS4xNDc2OTYgMC42OTM0IC0xLjA5MTkwNSAwLjgyMDkyMiAtMS4wMzYxMTVMNS4yMjgzOTQgMS4wMzYxMTVaJyBpZD0nZzAtNTQnLz4KPHBhdGggZD0nTTMuMTA4MzQ0IC01LjIxMjQ1M0MxLjU3ODA4MiAtNC44NDE4NDMgMC40NzgyMDcgLTMuMjUxODA2IDAuNDc4MjA3IC0xLjg1MzA1MUMwLjQ3ODIwNyAtMC41NzM4NDggMS4zMzg5NzkgMC4xNDM0NjIgMi4yOTUzOTIgMC4xNDM0NjJDMy43MDYxMDIgMC4xNDM0NjIgNC42NjI1MTYgLTEuNzkzMjc1IDQuNjYyNTE2IC0zLjM4MzMxM0M0LjY2MjUxNiAtNC40NTkyNzggNC4xNjAzOTkgLTUuMTE2ODEyIDMuODYxNTE5IC01LjUxMTMzM0MzLjQxOTE3OCAtNi4wNzMyMjUgMi43MDE4NjggLTYuOTkzNzczIDIuNzAxODY4IC03LjU2NzYyMUMyLjcwMTg2OCAtNy43NzA4NTkgMi44NTcyODUgLTguMTI5NTE0IDMuMzgzMzEzIC04LjEyOTUxNEMzLjc1MzkyMyAtOC4xMjk1MTQgMy45ODEwNzEgLTcuOTk4MDA3IDQuMzM5NzI2IC03Ljc5NDc3QzQuNDQ3MzIzIC03LjcyMzAzOSA0LjcyMjI5MSAtNy41Njc2MjEgNC44Nzc3MDkgLTcuNTY3NjIxQzUuMTI4NzY3IC03LjU2NzYyMSA1LjMwODA5NSAtNy44MTg2OCA1LjMwODA5NSAtOC4wMDk5NjNDNS4zMDgwOTUgLTguMjM3MTExIDUuMTI4NzY3IC04LjI3Mjk3NiA0LjcxMDMzNiAtOC4zNjg2MThDNC4xNDg0NDMgLTguNDg4MTY5IDMuOTgxMDcxIC04LjQ4ODE2OSAzLjc3NzgzMyAtOC40ODgxNjlTMi40MDI5ODkgLTguNDg4MTY5IDIuNDAyOTg5IC03LjI2ODc0MkMyLjQwMjk4OSAtNi42ODI5MzkgMi43MDE4NjggLTYuMDAxNDk0IDMuMTA4MzQ0IC01LjIxMjQ1M1pNMy4yMzk4NTEgLTQuOTg1MzA1QzMuNjk0MTQ3IC00LjA0MDg0NyAzLjg3MzQ3NCAtMy42ODIxOTIgMy44NzM0NzQgLTIuOTA1MTA2QzMuODczNDc0IC0xLjk3MjYwMyAzLjM3MTM1NyAtMC4wOTU2NDEgMi4zMDczNDcgLTAuMDk1NjQxQzEuODQxMDk2IC0wLjA5NTY0MSAxLjE3MTYwNiAtMC40MDY0NzYgMS4xNzE2MDYgLTEuNTE4MzA2QzEuMTcxNjA2IC0yLjI5NTM5MiAxLjYxMzk0OCAtNC41NTQ5MTkgMy4yMzk4NTEgLTQuOTg1MzA1WicgaWQ9J2c0LTE0Jy8+CjxwYXRoIGQ9J00yLjE5OTc1MSAtMC41NzM4NDhDMi4xOTk3NTEgLTAuOTIwNTQ4IDEuOTEyODI3IC0xLjE1OTY1MSAxLjYyNTkwMyAtMS4xNTk2NTFDMS4yNzkyMDMgLTEuMTU5NjUxIDEuMDQwMSAtMC44NzI3MjcgMS4wNDAxIC0wLjU4NTgwM0MxLjA0MDEgLTAuMjM5MTAzIDEuMzI3MDI0IDAgMS42MTM5NDggMEMxLjk2MDY0OCAwIDIuMTk5NzUxIC0wLjI4NjkyNCAyLjE5OTc1MSAtMC41NzM4NDhaJyBpZD0nZzQtNTgnLz4KPHBhdGggZD0nTTIuMzMxMjU4IDAuMDQ3ODIxQzIuMzMxMjU4IC0wLjY0NTU3OSAyLjEwNDExIC0xLjE1OTY1MSAxLjYxMzk0OCAtMS4xNTk2NTFDMS4yMzEzODIgLTEuMTU5NjUxIDEuMDQwMSAtMC44NDg4MTcgMS4wNDAxIC0wLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3IC0wLjA0NzgyMSAyLjAyMDQyMyAtMC4xNTU0MTdDMi4wNDQzMzQgLTAuMTc5MzI4IDIuMDU2Mjg5IC0wLjE3OTMyOCAyLjA2ODI0NCAtMC4xNzkzMjhDMi4wOTIxNTQgLTAuMTc5MzI4IDIuMDkyMTU0IC0wLjAxMTk1NSAyLjA5MjE1NCAwLjA0NzgyMUMyLjA5MjE1NCAwLjQ0MjM0MSAyLjAyMDQyMyAxLjIxOTQyNyAxLjMyNzAyNCAxLjk5NjUxM0MxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjQxMDcxIDIuMzA3MzQ3IDIuMzMxMjU4IDEuNDIyNjY1IDIuMzMxMjU4IDAuMDQ3ODIxWicgaWQ9J2c0LTU5Jy8+CjxwYXRoIGQ9J001Ljk3NzU4NCAtNC44Mjk4ODhDNS45NjU2MjkgLTQuODY1NzUzIDUuOTE3ODA4IC00Ljk2MTM5NSA1LjkxNzgwOCAtNC45OTcyNkM1LjkxNzgwOCAtNS4wMDkyMTUgNS45Mjk3NjMgLTUuMDIxMTcxIDYuMTMzMDAxIC01LjE3NjU4OEw3LjI5MjY1MyAtNi4wODUxODFDOC44OTQ2NDUgLTcuMzI4NTE4IDkuNDIwNjcyIC03Ljc0Njk0OSAxMC4yNDU1NzkgLTcuODE4NjhDMTAuMzI5MjY1IC03LjgzMDYzNSAxMC40NDg4MTcgLTcuODMwNjM1IDEwLjQ0ODgxNyAtOC4wMzM4NzNDMTAuNDQ4ODE3IC04LjEwNTYwNCAxMC40MTI5NTEgLTguMTY1MzggMTAuMzE3MzEgLTguMTY1MzhDMTAuMTg1ODAzIC04LjE2NTM4IDEwLjA0MjM0MSAtOC4xNDE0NjkgOS45MTA4MzQgLTguMTQxNDY5SDkuNDU2NTM4QzkuMDg1OTI4IC04LjE0MTQ2OSA4LjY5MTQwNyAtOC4xNjUzOCA4LjMzMjc1MiAtOC4xNjUzOEM4LjI0OTA2NiAtOC4xNjUzOCA4LjEwNTYwNCAtOC4xNjUzOCA4LjEwNTYwNCAtNy45NTAxODdDOC4xMDU2MDQgLTcuODMwNjM1IDguMTg5MjkgLTcuODE4NjggOC4yNjEwMjEgLTcuODE4NjhDOC4zOTI1MjggLTcuODA2NzI1IDguNTQ3OTQ1IC03Ljc1ODkwNCA4LjU0Nzk0NSAtNy41OTE1MzJDOC41NDc5NDUgLTcuMzUyNDI4IDguMTg5MjkgLTcuMDY1NTA0IDguMDkzNjQ5IC02Ljk5Mzc3M0wzLjQwNzIyMyAtMy4zNDc0NDdMNC4zOTk1MDIgLTcuMjkyNjUzQzQuNTA3MDk4IC03LjY5OTEyOCA0LjUzMTAwOSAtNy44MTg2OCA1LjM3OTgyNiAtNy44MTg2OEM1LjYwNjk3NCAtNy44MTg2OCA1LjcxNDU3IC03LjgxODY4IDUuNzE0NTcgLTguMDQ1ODI4QzUuNzE0NTcgLTguMTY1MzggNS41OTUwMTkgLTguMTY1MzggNS41MzUyNDMgLTguMTY1MzhDNS4zMjAwNSAtOC4xNjUzOCA1LjA2ODk5MSAtOC4xNDE0NjkgNC44NDE4NDMgLTguMTQxNDY5SDMuNDMxMTMzQzMuMjE1OTQgLTguMTQxNDY5IDIuOTUyOTI3IC04LjE2NTM4IDIuNzM3NzMzIC04LjE2NTM4QzIuNjQyMDkyIC04LjE2NTM4IDIuNTEwNTg1IC04LjE2NTM4IDIuNTEwNTg1IC03LjkzODIzMkMyLjUxMDU4NSAtNy44MTg2OCAyLjYxODE4MiAtNy44MTg2OCAyLjc5NzUwOSAtNy44MTg2OEMzLjUyNjc3NSAtNy44MTg2OCAzLjUyNjc3NSAtNy43MjMwMzkgMy41MjY3NzUgLTcuNTkxNTMyQzMuNTI2Nzc1IC03LjU2NzYyMSAzLjUyNjc3NSAtNy40OTU4OSAzLjQ3ODk1NCAtNy4zMTY1NjNMMS44NjUwMDYgLTAuODg0NjgyQzEuNzU3NDEgLTAuNDY2MjUyIDEuNzMzNDk5IC0wLjM0NjcgMC44OTY2MzggLTAuMzQ2N0MwLjY2OTQ4OSAtMC4zNDY3IDAuNTQ5OTM4IC0wLjM0NjcgMC41NDk5MzggLTAuMTMxNTA3QzAuNTQ5OTM4IDAgMC42NTc1MzQgMCAwLjcyOTI2NSAwQzAuOTU2NDEzIDAgMS4xOTU1MTcgLTAuMDIzOTEgMS40MjI2NjUgLTAuMDIzOTFIMi44MjE0MkMzLjA0ODU2OCAtMC4wMjM5MSAzLjI5OTYyNiAwIDMuNTI2Nzc1IDBDMy42MjI0MTYgMCAzLjc1MzkyMyAwIDMuNzUzOTIzIC0wLjIyNzE0OEMzLjc1MzkyMyAtMC4zNDY3IDMuNjQ2MzI2IC0wLjM0NjcgMy40NjY5OTkgLTAuMzQ2N0MyLjczNzczMyAtMC4zNDY3IDIuNzM3NzMzIC0wLjQ0MjM0MSAyLjczNzczMyAtMC41NjE4OTNDMi43Mzc3MzMgLTAuNjQ1NTc5IDIuODA5NDY1IC0wLjk0NDQ1OCAyLjg1NzI4NSAtMS4xMzU3NDFMMy4zMjM1MzcgLTIuOTg4NzkyTDUuMTQwNzIyIC00LjQxMTQ1N0M1LjQ4NzQyMiAtMy42NDYzMjYgNi4xMjEwNDYgLTIuMTE2MDY1IDYuNjExMjA4IC0wLjk0NDQ1OEM2LjY0NzA3MyAtMC44NzI3MjcgNi42NzA5ODQgLTAuODAwOTk2IDYuNjcwOTg0IC0wLjcxNzMxQzYuNjcwOTg0IC0wLjM1ODY1NSA2LjE5Mjc3NyAtMC4zNDY3IDYuMDg1MTgxIC0wLjM0NjdTNS44NTgwMzIgLTAuMzQ2NyA1Ljg1ODAzMiAtMC4xMTk1NTJDNS44NTgwMzIgMCA1Ljk4OTUzOSAwIDYuMDI1NDA1IDBDNi40NDM4MzYgMCA2Ljg4NjE3NyAtMC4wMjM5MSA3LjMwNDYwOCAtMC4wMjM5MUg3Ljg3ODQ1NkM4LjA1Nzc4MyAtMC4wMjM5MSA4LjI2MTAyMSAwIDguNDQwMzQ5IDBDOC41MTIwOCAwIDguNjQzNTg3IDAgOC42NDM1ODcgLTAuMjI3MTQ4QzguNjQzNTg3IC0wLjM0NjcgOC41MzU5OSAtMC4zNDY3IDguNDE2NDM4IC0wLjM0NjdDNy45NzQwOTcgLTAuMzU4NjU1IDcuODE4NjggLTAuNDU0Mjk2IDcuNjM5MzUyIC0wLjg4NDY4Mkw1Ljk3NzU4NCAtNC44Mjk4ODhaJyBpZD0nZzQtNzUnLz4KPHBhdGggZD0nTTEwLjg1NTI5MyAtNy4yOTI2NTNDMTAuOTYyODg5IC03LjY5OTEyOCAxMC45ODY4IC03LjgxODY4IDExLjgzNTYxNiAtNy44MTg2OEMxMi4wNjI3NjUgLTcuODE4NjggMTIuMTcwMzYxIC03LjgxODY4IDEyLjE3MDM2MSAtOC4wNDU4MjhDMTIuMTcwMzYxIC04LjE2NTM4IDEyLjA4NjY3NSAtOC4xNjUzOCAxMS44NTk1MjcgLTguMTY1MzhIMTAuNDI0OTA3QzEwLjEyNjAyNyAtOC4xNjUzOCAxMC4xMTQwNzIgLTguMTUzNDI1IDkuOTgyNTY1IC03Ljk2MjE0Mkw1LjYxODkyOSAtMS4wNjQwMUw0LjcyMjI5MSAtNy45MDIzNjZDNC42ODY0MjYgLTguMTY1MzggNC42NzQ0NzEgLTguMTY1MzggNC4zNjM2MzYgLTguMTY1MzhIMi44ODExOTZDMi42NTQwNDcgLTguMTY1MzggMi41NDY0NTEgLTguMTY1MzggMi41NDY0NTEgLTcuOTM4MjMyQzIuNTQ2NDUxIC03LjgxODY4IDIuNjU0MDQ3IC03LjgxODY4IDIuODMzMzc1IC03LjgxODY4QzMuNTYyNjQgLTcuODE4NjggMy41NjI2NCAtNy43MjMwMzkgMy41NjI2NCAtNy41OTE1MzJDMy41NjI2NCAtNy41Njc2MjEgMy41NjI2NCAtNy40OTU4OSAzLjUxNDgxOSAtNy4zMTY1NjNMMS45ODQ1NTggLTEuMjE5NDI3QzEuODQxMDk2IC0wLjY0NTU3OSAxLjU2NjEyNyAtMC4zODI1NjUgMC43NjUxMzEgLTAuMzQ2N0MwLjcyOTI2NSAtMC4zNDY3IDAuNTg1ODAzIC0wLjMzNDc0NSAwLjU4NTgwMyAtMC4xMzE1MDdDMC41ODU4MDMgMCAwLjY5MzQgMCAwLjc0MTIyIDBDMC45ODAzMjQgMCAxLjU5MDAzNyAtMC4wMjM5MSAxLjgyOTE0MSAtMC4wMjM5MUgyLjQwMjk4OUMyLjU3MDM2MSAtMC4wMjM5MSAyLjc3MzU5OSAwIDIuOTQwOTcxIDBDMy4wMjQ2NTggMCAzLjE1NjE2NCAwIDMuMTU2MTY0IC0wLjIyNzE0OEMzLjE1NjE2NCAtMC4zMzQ3NDUgMy4wMzY2MTMgLTAuMzQ2NyAyLjk4ODc5MiAtMC4zNDY3QzIuNTk0MjcxIC0wLjM1ODY1NSAyLjIxMTcwNiAtMC40MzAzODYgMi4yMTE3MDYgLTAuODYwNzcyQzIuMjExNzA2IC0wLjk4MDMyNCAyLjIxMTcwNiAtMC45OTIyNzkgMi4yNTk1MjcgLTEuMTU5NjUxTDMuOTA5MzQgLTcuNzQ2OTQ5SDMuOTIxMjk1TDQuOTEzNTc0IC0wLjMyMjc5QzQuOTQ5NDQgLTAuMDM1ODY2IDQuOTYxMzk1IDAgNS4wNjg5OTEgMEM1LjIwMDQ5OCAwIDUuMjYwMjc0IC0wLjA5NTY0MSA1LjMyMDA1IC0wLjIwMzIzOEwxMC4xMjYwMjcgLTcuODA2NzI1SDEwLjEzNzk4M0w4LjQwNDQ4MyAtMC44ODQ2ODJDOC4yOTY4ODcgLTAuNDY2MjUyIDguMjcyOTc2IC0wLjM0NjcgNy40MzYxMTUgLTAuMzQ2N0M3LjIwODk2NiAtMC4zNDY3IDcuMDg5NDE1IC0wLjM0NjcgNy4wODk0MTUgLTAuMTMxNTA3QzcuMDg5NDE1IDAgNy4xOTcwMTEgMCA3LjI2ODc0MiAwQzcuNDcxOTggMCA3LjcxMTA4MyAtMC4wMjM5MSA3LjkxNDMyMSAtMC4wMjM5MUg5LjMyNTAzMUM5LjUyODI2OSAtMC4wMjM5MSA5Ljc3OTMyOCAwIDkuOTgyNTY1IDBDMTAuMDc4MjA3IDAgMTAuMjA5NzE0IDAgMTAuMjA5NzE0IC0wLjIyNzE0OEMxMC4yMDk3MTQgLTAuMzQ2NyAxMC4xMDIxMTcgLTAuMzQ2NyA5LjkyMjc5IC0wLjM0NjdDOS4xOTM1MjQgLTAuMzQ2NyA5LjE5MzUyNCAtMC40NDIzNDEgOS4xOTM1MjQgLTAuNTYxODkzQzkuMTkzNTI0IC0wLjU3Mzg0OCA5LjE5MzUyNCAtMC42NTc1MzQgOS4yMTc0MzUgLTAuNzUzMTc2TDEwLjg1NTI5MyAtNy4yOTI2NTNaJyBpZD0nZzQtNzcnLz4KPHBhdGggZD0nTTcuNTkxNTMyIC04LjMwODg0MkM3LjU5MTUzMiAtOC40MTY0MzggNy41MDc4NDYgLTguNDE2NDM4IDcuNDgzOTM1IC04LjQxNjQzOEM3LjQzNjExNSAtOC40MTY0MzggNy40MjQxNTkgLTguNDA0NDgzIDcuMjgwNjk3IC04LjIyNTE1NkM3LjIwODk2NiAtOC4xNDE0NjkgNi43MTg4MDQgLTcuNTE5ODAxIDYuNzA2ODQ5IC03LjUwNzg0NkM2LjMxMjMyOSAtOC4yODQ5MzIgNS41MjMyODggLTguNDE2NDM4IDUuMDIxMTcxIC04LjQxNjQzOEMzLjUwMjg2NCAtOC40MTY0MzggMi4xMjgwMiAtNy4wMjk2MzkgMi4xMjgwMiAtNS42Nzg3MDVDMi4xMjgwMiAtNC43ODIwNjcgMi42NjYwMDIgLTQuMjU2MDQgMy4yNTE4MDYgLTQuMDUyODAyQzMuMzgzMzEzIC00LjAwNDk4MSA0LjA4ODY2NyAtMy44MTM2OTkgNC40NDczMjMgLTMuNzMwMDEyQzUuMDU3MDM2IC0zLjU2MjY0IDUuMjEyNDUzIC0zLjUxNDgxOSA1LjQ2MzUxMiAtMy4yNTE4MDZDNS41MTEzMzMgLTMuMTkyMDMgNS43NTA0MzYgLTIuOTE3MDYxIDUuNzUwNDM2IC0yLjM1NTE2OEM1Ljc1MDQzNiAtMS4yNDMzMzcgNC43MjIyOTEgLTAuMDk1NjQxIDMuNTI2Nzc1IC0wLjA5NTY0MUMyLjU0NjQ1MSAtMC4wOTU2NDEgMS40NTg1MzEgLTAuNTE0MDcyIDEuNDU4NTMxIC0xLjg1MzA1MUMxLjQ1ODUzMSAtMi4wODAxOTkgMS41MDYzNTEgLTIuMzY3MTIzIDEuNTQyMjE3IC0yLjQ4NjY3NUMxLjU0MjIxNyAtMi41MjI1NCAxLjU1NDE3MiAtMi41ODIzMTYgMS41NTQxNzIgLTIuNjA2MjI3QzEuNTU0MTcyIC0yLjY1NDA0NyAxLjUzMDI2MiAtMi43MTM4MjMgMS40MzQ2MiAtMi43MTM4MjNDMS4zMjcwMjQgLTIuNzEzODIzIDEuMzE1MDY4IC0yLjY4OTkxMyAxLjI2NzI0OCAtMi40ODY2NzVMMC42NTc1MzQgLTAuMDM1ODY2QzAuNjU3NTM0IC0wLjAyMzkxIDAuNjA5NzE0IDAuMTMxNTA3IDAuNjA5NzE0IDAuMTQzNDYyQzAuNjA5NzE0IDAuMjUxMDU5IDAuNzA1MzU1IDAuMjUxMDU5IDAuNzI5MjY1IDAuMjUxMDU5QzAuNzc3MDg2IDAuMjUxMDU5IDAuNzg5MDQxIDAuMjM5MTAzIDAuOTMyNTAzIDAuMDU5Nzc2TDEuNDgyNDQxIC0wLjY1NzUzNEMxLjc2OTM2NSAtMC4yMjcxNDggMi4zOTEwMzQgMC4yNTEwNTkgMy41MDI4NjQgMC4yNTEwNTlDNS4wNDUwODEgMC4yNTEwNTkgNi40NTU3OTEgLTEuMjQzMzM3IDYuNDU1NzkxIC0yLjczNzczM0M2LjQ1NTc5MSAtMy4yMzk4NTEgNi4zMzYyMzkgLTMuNjgyMTkyIDUuODgxOTQzIC00LjEyNDUzM0M1LjYzMDg4NCAtNC4zNzU1OTIgNS40MTU2OTEgLTQuNDM1MzY3IDQuMzE1ODE2IC00LjcyMjI5MUMzLjUxNDgxOSAtNC45Mzc0ODQgMy40MDcyMjMgLTQuOTczMzUgMy4xOTIwMyAtNS4xNjQ2MzNDMi45ODg3OTIgLTUuMzY3ODcgMi44MzMzNzUgLTUuNjU0Nzk1IDIuODMzMzc1IC02LjA2MTI3QzIuODMzMzc1IC03LjA2NTUwNCAzLjg0OTU2NCAtOC4wOTM2NDkgNC45ODUzMDUgLTguMDkzNjQ5QzYuMTU2OTEyIC04LjA5MzY0OSA2LjcwNjg0OSAtNy4zNzYzMzkgNi43MDY4NDkgLTYuMjQwNTk4QzYuNzA2ODQ5IC01LjkyOTc2MyA2LjY0NzA3MyAtNS42MDY5NzQgNi42NDcwNzMgLTUuNTU5MTUzQzYuNjQ3MDczIC01LjQ1MTU1NyA2Ljc0MjcxNSAtNS40NTE1NTcgNi43Nzg1OCAtNS40NTE1NTdDNi44ODYxNzcgLTUuNDUxNTU3IDYuODk4MTMyIC01LjQ4NzQyMiA2Ljk0NTk1MyAtNS42Nzg3MDVMNy41OTE1MzIgLTguMzA4ODQyWicgaWQ9J2c0LTgzJy8+CjxwYXRoIGQ9J00zLjM1OTQwMiAtNy45OTgwMDdDMy4zNzEzNTcgLTguMDQ1ODI4IDMuMzk1MjY4IC04LjExNzU1OSAzLjM5NTI2OCAtOC4xNzczMzVDMy4zOTUyNjggLTguMjk2ODg3IDMuMjc1NzE2IC04LjI5Njg4NyAzLjI1MTgwNiAtOC4yOTY4ODdDMy4yMzk4NTEgLTguMjk2ODg3IDIuODA5NDY1IC04LjI2MTAyMSAyLjU5NDI3MSAtOC4yMzcxMTFDMi4zOTEwMzQgLTguMjI1MTU2IDIuMjExNzA2IC04LjIwMTI0NSAxLjk5NjUxMyAtOC4xODkyOUMxLjcwOTU4OSAtOC4xNjUzOCAxLjYyNTkwMyAtOC4xNTM0MjUgMS42MjU5MDMgLTcuOTM4MjMyQzEuNjI1OTAzIC03LjgxODY4IDEuNzQ1NDU1IC03LjgxODY4IDEuODY1MDA2IC03LjgxODY4QzIuNDc0NzIgLTcuODE4NjggMi40NzQ3MiAtNy43MTEwODMgMi40NzQ3MiAtNy41OTE1MzJDMi40NzQ3MiAtNy41NDM3MTEgMi40NzQ3MiAtNy41MTk4MDEgMi40MTQ5NDQgLTcuMzA0NjA4TDAuNzA1MzU1IC0wLjQ2NjI1MkMwLjY1NzUzNCAtMC4yODY5MjQgMC42NTc1MzQgLTAuMjYzMDE0IDAuNjU3NTM0IC0wLjE5MTI4M0MwLjY1NzUzNCAwLjA3MTczMSAwLjg2MDc3MiAwLjExOTU1MiAwLjk4MDMyNCAwLjExOTU1MkMxLjMxNTA2OCAwLjExOTU1MiAxLjM4NjggLTAuMTQzNDYyIDEuNDgyNDQxIC0wLjUxNDA3MkwyLjA0NDMzNCAtMi43NDk2ODlDMi45MDUxMDYgLTIuNjU0MDQ3IDMuNDE5MTc4IC0yLjI5NTM5MiAzLjQxOTE3OCAtMS43MjE1NDRDMy40MTkxNzggLTEuNjQ5ODEzIDMuNDE5MTc4IC0xLjYwMTk5MyAzLjM4MzMxMyAtMS40MjI2NjVDMy4zMzU0OTIgLTEuMjQzMzM3IDMuMzM1NDkyIC0xLjA5OTg3NSAzLjMzNTQ5MiAtMS4wNDAxQzMuMzM1NDkyIC0wLjM0NjcgMy43ODk3ODggMC4xMTk1NTIgNC4zOTk1MDIgMC4xMTk1NTJDNC45NDk0NCAwLjExOTU1MiA1LjIzNjM2NCAtMC4zODI1NjUgNS4zMzIwMDUgLTAuNTQ5OTM4QzUuNTgzMDY0IC0wLjk5MjI3OSA1LjczODQ4MSAtMS42NjE3NjggNS43Mzg0ODEgLTEuNzA5NTg5QzUuNzM4NDgxIC0xLjc2OTM2NSA1LjY5MDY2IC0xLjgxNzE4NiA1LjYxODkyOSAtMS44MTcxODZDNS41MTEzMzMgLTEuODE3MTg2IDUuNDk5Mzc3IC0xLjc2OTM2NSA1LjQ1MTU1NyAtMS41NzgwODJDNS4yODQxODQgLTAuOTU2NDEzIDUuMDMzMTI2IC0wLjExOTU1MiA0LjQyMzQxMiAtMC4xMTk1NTJDNC4xODQzMDkgLTAuMTE5NTUyIDQuMDI4ODkyIC0wLjIzOTEwMyA0LjAyODg5MiAtMC42OTM0QzQuMDI4ODkyIC0wLjkyMDU0OCA0LjA3NjcxMiAtMS4xODM1NjIgNC4xMjQ1MzMgLTEuMzYyODg5QzQuMTcyMzU0IC0xLjU3ODA4MiA0LjE3MjM1NCAtMS41OTAwMzcgNC4xNzIzNTQgLTEuNzMzNDk5QzQuMTcyMzU0IC0yLjQzODg1NCAzLjUzODczIC0yLjgzMzM3NSAyLjQzODg1NCAtMi45NzY4MzdDMi44NjkyNCAtMy4yMzk4NTEgMy4yOTk2MjYgLTMuNzA2MTAyIDMuNDY2OTk5IC0zLjg4NTQzQzQuMTQ4NDQzIC00LjY1MDU2IDQuNjE0Njk1IC01LjAzMzEyNiA1LjE2NDYzMyAtNS4wMzMxMjZDNS40Mzk2MDEgLTUuMDMzMTI2IDUuNTExMzMzIC00Ljk2MTM5NSA1LjU5NTAxOSAtNC44ODk2NjRDNS4xNTI2NzcgLTQuODQxODQzIDQuOTg1MzA1IC00LjUzMTAwOSA0Ljk4NTMwNSAtNC4yOTE5MDVDNC45ODUzMDUgLTQuMDA0OTgxIDUuMjEyNDUzIC0zLjkwOTM0IDUuMzc5ODI2IC0zLjkwOTM0QzUuNzAyNjE1IC0zLjkwOTM0IDUuOTg5NTM5IC00LjE4NDMwOSA1Ljk4OTUzOSAtNC41NjY4NzRDNS45ODk1MzkgLTQuOTEzNTc0IDUuNzE0NTcgLTUuMjcyMjI5IDUuMTc2NTg4IC01LjI3MjIyOUM0LjUxOTA1NCAtNS4yNzIyMjkgMy45ODEwNzEgLTQuODA1OTc4IDMuMTMyMjU0IC0zLjg0OTU2NEMzLjAxMjcwMiAtMy43MDYxMDIgMi41NzAzNjEgLTMuMjUxODA2IDIuMTI4MDIgLTMuMDg0NDMzTDMuMzU5NDAyIC03Ljk5ODAwN1onIGlkPSdnNC0xMDcnLz4KPHBhdGggZD0nTTMuMDM2NjEzIC03Ljk5ODAwN0MzLjA0ODU2OCAtOC4wNDU4MjggMy4wNzI0NzggLTguMTE3NTU5IDMuMDcyNDc4IC04LjE3NzMzNUMzLjA3MjQ3OCAtOC4yOTY4ODcgMi45NTI5MjcgLTguMjk2ODg3IDIuOTI5MDE2IC04LjI5Njg4N0MyLjkxNzA2MSAtOC4yOTY4ODcgMi40ODY2NzUgLTguMjYxMDIxIDIuMjcxNDgyIC04LjIzNzExMUMyLjA2ODI0NCAtOC4yMjUxNTYgMS44ODg5MTcgLTguMjAxMjQ1IDEuNjczNzI0IC04LjE4OTI5QzEuMzg2OCAtOC4xNjUzOCAxLjMwMzExMyAtOC4xNTM0MjUgMS4zMDMxMTMgLTcuOTM4MjMyQzEuMzAzMTEzIC03LjgxODY4IDEuNDIyNjY1IC03LjgxODY4IDEuNTQyMjE3IC03LjgxODY4QzIuMTUxOTMgLTcuODE4NjggMi4xNTE5MyAtNy43MTEwODMgMi4xNTE5MyAtNy41OTE1MzJDMi4xNTE5MyAtNy41NDM3MTEgMi4xNTE5MyAtNy41MTk4MDEgMi4wOTIxNTQgLTcuMzA0NjA4TDAuNjA5NzE0IC0xLjM3NDg0NEMwLjU3Mzg0OCAtMS4yNDMzMzcgMC41NDk5MzggLTEuMTQ3Njk2IDAuNTQ5OTM4IC0wLjk1NjQxM0MwLjU0OTkzOCAtMC4zNTg2NTUgMC45OTIyNzkgMC4xMTk1NTIgMS42MDE5OTMgMC4xMTk1NTJDMS45OTY1MTMgMC4xMTk1NTIgMi4yNTk1MjcgLTAuMTQzNDYyIDIuNDUwODA5IC0wLjUxNDA3MkMyLjY1NDA0NyAtMC45MDg1OTMgMi44MjE0MiAtMS42NjE3NjggMi44MjE0MiAtMS43MDk1ODlDMi44MjE0MiAtMS43NjkzNjUgMi43NzM1OTkgLTEuODE3MTg2IDIuNzAxODY4IC0xLjgxNzE4NkMyLjU5NDI3MSAtMS44MTcxODYgMi41ODIzMTYgLTEuNzU3NDEgMi41MzQ0OTYgLTEuNTc4MDgyQzIuMzE5MzAzIC0wLjc1MzE3NiAyLjEwNDExIC0wLjExOTU1MiAxLjYyNTkwMyAtMC4xMTk1NTJDMS4yNjcyNDggLTAuMTE5NTUyIDEuMjY3MjQ4IC0wLjUwMjExNyAxLjI2NzI0OCAtMC42Njk0ODlDMS4yNjcyNDggLTAuNzE3MzEgMS4yNjcyNDggLTAuOTY4MzY5IDEuMzUwOTM0IC0xLjMwMzExM0wzLjAzNjYxMyAtNy45OTgwMDdaJyBpZD0nZzQtMTA4Jy8+CjxwYXRoIGQ9J001LjI3MjIyOSAtNS4xNTI2NzdDNS4yNzIyMjkgLTUuMjEyNDUzIDUuMjI0NDA4IC01LjI2MDI3NCA1LjE2NDYzMyAtNS4yNjAyNzRDNS4wNjg5OTEgLTUuMjYwMjc0IDQuNjAyNzQgLTQuODI5ODg4IDQuMzc1NTkyIC00LjQxMTQ1N0M0LjE2MDM5OSAtNC45NDk0NCAzLjc4OTc4OCAtNS4yNzIyMjkgMy4yNzU3MTYgLTUuMjcyMjI5QzEuOTI0NzgyIC01LjI3MjIyOSAwLjQ2NjI1MiAtMy41MjY3NzUgMC40NjYyNTIgLTEuNzU3NDFDMC40NjYyNTIgLTAuNTczODQ4IDEuMTU5NjUxIDAuMTE5NTUyIDEuOTcyNjAzIDAuMTE5NTUyQzIuNjA2MjI3IDAuMTE5NTUyIDMuMTMyMjU0IC0wLjM1ODY1NSAzLjM4MzMxMyAtMC42MzM2MjRMMy4zOTUyNjggLTAuNjIxNjY5TDIuOTQwOTcxIDEuMTcxNjA2TDIuODMzMzc1IDEuNjAxOTkzQzIuNzI1Nzc4IDEuOTYwNjQ4IDIuNTQ2NDUxIDEuOTYwNjQ4IDEuOTg0NTU4IDEuOTcyNjAzQzEuODUzMDUxIDEuOTcyNjAzIDEuNzMzNDk5IDEuOTcyNjAzIDEuNzMzNDk5IDIuMTk5NzUxQzEuNzMzNDk5IDIuMjgzNDM3IDEuODA1MjMgMi4zMTkzMDMgMS44ODg5MTcgMi4zMTkzMDNDMi4wNTYyODkgMi4zMTkzMDMgMi4yNzE0ODIgMi4yOTUzOTIgMi40Mzg4NTQgMi4yOTUzOTJIMy42NTgyODFDMy44Mzc2MDkgMi4yOTUzOTIgNC4wNDA4NDcgMi4zMTkzMDMgNC4yMjAxNzQgMi4zMTkzMDNDNC4yOTE5MDUgMi4zMTkzMDMgNC40MzUzNjcgMi4zMTkzMDMgNC40MzUzNjcgMi4wOTIxNTRDNC40MzUzNjcgMS45NzI2MDMgNC4zMzk3MjYgMS45NzI2MDMgNC4xNjAzOTkgMS45NzI2MDNDMy41OTg1MDYgMS45NzI2MDMgMy41NjI2NCAxLjg4ODkxNyAzLjU2MjY0IDEuNzkzMjc1QzMuNTYyNjQgMS43MzM0OTkgMy41NzQ1OTUgMS43MjE1NDQgMy42MTA0NjEgMS41NjYxMjdMNS4yNzIyMjkgLTUuMTUyNjc3Wk0zLjU4NjU1IC0xLjQyMjY2NUMzLjUyNjc3NSAtMS4yMTk0MjcgMy41MjY3NzUgLTEuMTk1NTE3IDMuMzU5NDAyIC0wLjk2ODM2OUMzLjA5NjM4OSAtMC42MzM2MjQgMi41NzAzNjEgLTAuMTE5NTUyIDIuMDA4NDY4IC0wLjExOTU1MkMxLjUxODMwNiAtMC4xMTk1NTIgMS4yNDMzMzcgLTAuNTYxODkzIDEuMjQzMzM3IC0xLjI2NzI0OEMxLjI0MzMzNyAtMS45MjQ3ODIgMS42MTM5NDggLTMuMjYzNzYxIDEuODQxMDk2IC0zLjc2NTg3OEMyLjI0NzU3MiAtNC42MDI3NCAyLjgwOTQ2NSAtNS4wMzMxMjYgMy4yNzU3MTYgLTUuMDMzMTI2QzQuMDY0NzU3IC01LjAzMzEyNiA0LjIyMDE3NCAtNC4wNTI4MDIgNC4yMjAxNzQgLTMuOTU3MTYxQzQuMjIwMTc0IC0zLjk0NTIwNSA0LjE4NDMwOSAtMy43ODk3ODggNC4xNzIzNTQgLTMuNzY1ODc4TDMuNTg2NTUgLTEuNDIyNjY1WicgaWQ9J2c0LTExMycvPgo8cGF0aCBkPSdNNC45NzMzNSAxNy44MDEyNDVDNC45NzMzNSAxNy4yMzkzNTIgNC45NzMzNSAxNi4zNTQ2NyA0LjIyMDE3NCAxNS4zODYzMDFDMy43NTM5MjMgMTQuNzg4NTQzIDMuMDcyNDc4IDE0LjIzODYwNSAyLjI0NzU3MiAxMy44Njc5OTVDNC41Nzg4MjkgMTIuNzQ0MjA5IDQuOTczMzUgMTEuMDIyNjY1IDQuOTczMzUgMTAuMzQxMjJWMy40NTUwNDRDNC45NzMzNSAyLjcxMzgyMyA0Ljk3MzM1IDEuMTgzNTYyIDcuMjkyNjUzIDAuMDM1ODY2QzcuMzg4Mjk0IC0wLjAxMTk1NSA3LjM4ODI5NCAtMC4wMzU4NjYgNy4zODgyOTQgLTAuMjE1MTkzQzcuMzg4Mjk0IC0wLjQ2NjI1MiA3LjM4ODI5NCAtMC40NzgyMDcgNy4xMjUyOCAtMC40NzgyMDdDNi45NTc5MDggLTAuNDc4MjA3IDYuOTMzOTk4IC0wLjQ3ODIwNyA2LjYyMzE2MyAtMC4zMzQ3NDVDNS40Mzk2MDEgMC4yNTEwNTkgNC4yNjc5OTUgMS4xOTU1MTcgNC4wMTY5MzYgMi42NTQwNDdDMy45ODEwNzEgMi44OTMxNTEgMy45ODEwNzEgMy4wMDA3NDcgMy45ODEwNzEgMy44MDE3NDNWOS4zMjUwMzFDMy45ODEwNzEgOS42OTU2NDEgMy45ODEwNzEgMTAuMzE3MzEgMy45NjkxMTYgMTAuNDQ4ODE3QzMuODYxNTE5IDExLjcwNDExIDMuMTMyMjU0IDEyLjc5MjAzIDEuNzY5MzY1IDEzLjU0NTIwNUMxLjU3ODA4MiAxMy42NTI4MDIgMS41NjYxMjcgMTMuNjY0NzU3IDEuNTY2MTI3IDEzLjg1NjA0QzEuNTY2MTI3IDE0LjA1OTI3OCAxLjU3ODA4MiAxNC4wNzEyMzMgMS43NDU0NTUgMTQuMTY2ODc0QzIuNTQ2NDUxIDE0LjYwOTIxNSAzLjY5NDE0NyAxNS40Njk5ODggMy45MzMyNSAxNi45NjQzODRDMy45ODEwNzEgMTcuMjM5MzUyIDMuOTgxMDcxIDE3LjI2MzI2MyAzLjk4MTA3MSAxNy4zOTQ3N1YyNC40OTYxMzlDMy45ODEwNzEgMjYuMjI5NjM5IDUuMTc2NTg4IDI3LjM2NTM4IDYuNjU5MDI5IDI4LjA3MDczNUM2LjkyMjA0MiAyOC4yMDIyNDIgNi45NDU5NTMgMjguMjAyMjQyIDcuMTI1MjggMjguMjAyMjQyQzcuMzc2MzM5IDI4LjIwMjI0MiA3LjM4ODI5NCAyOC4yMDIyNDIgNy4zODgyOTQgMjcuOTM5MjI4QzcuMzg4Mjk0IDI3Ljc0Nzk0NSA3LjM3NjMzOSAyNy43MzU5OSA3LjI4MDY5NyAyNy42NzYyMTRDNi43OTA1MzUgMjcuNDM3MTExIDUuMjQ4MzE5IDI2LjY2MDAyNSA0Ljk5NzI2IDI0LjkzODQ4MUM0Ljk3MzM1IDI0Ljc3MTEwOCA0Ljk3MzM1IDI0LjYzOTYwMSA0Ljk3MzM1IDIzLjkyMjI5MVYxNy44MDEyNDVaJyBpZD0nZzEtMjYnLz4KPHBhdGggZD0nTTIuNjU0MDQ3IDEuOTkyNTI4QzIuNzE3ODA4IDEuOTkyNTI4IDIuODEzNDUgMS45OTI1MjggMi44MTM0NSAxLjg5Njg4N0MyLjgxMzQ1IDEuODY1MDA2IDIuODA1NDc5IDEuODU3MDM2IDIuNzAxODY4IDEuNzUzNDI1QzEuNjA5OTYzIDAuNzI1MjggMS4zMzg5NzkgLTAuNzU3MTYxIDEuMzM4OTc5IC0xLjk5MjUyOEMxLjMzODk3OSAtNC4yODc5MiAyLjI4NzQyMiAtNS4zNjM4ODUgMi42OTM4OTggLTUuNzMwNTExQzIuODA1NDc5IC01LjgzNDEyMiAyLjgxMzQ1IC01Ljg0MjA5MiAyLjgxMzQ1IC01Ljg4MTk0M1MyLjc4MTU2OSAtNS45Nzc1ODQgMi43MDE4NjggLTUuOTc3NTg0QzIuNTc0MzQ2IC01Ljk3NzU4NCAyLjE3NTg0MSAtNS41NzExMDggMi4xMTIwOCAtNS40OTkzNzdDMS4wNDQwODUgLTQuMzgzNTYyIDAuODIwOTIyIC0yLjk0ODk0MSAwLjgyMDkyMiAtMS45OTI1MjhDMC44MjA5MjIgLTAuMjA3MjIzIDEuNTcwMTEyIDEuMjI3Mzk3IDIuNjU0MDQ3IDEuOTkyNTI4WicgaWQ9J2c1LTQwJy8+CjxwYXRoIGQ9J00yLjQ2Mjc2NSAtMS45OTI1MjhDMi40NjI3NjUgLTIuNzQ5Njg5IDIuMzM1MjQzIC0zLjY1ODI4MSAxLjg0MTA5NiAtNC41OTg3NTVDMS40NTA1NiAtNS4zMzIwMDUgMC43MjUyOCAtNS45Nzc1ODQgMC41ODE4MTggLTUuOTc3NTg0QzAuNTAyMTE3IC01Ljk3NzU4NCAwLjQ3ODIwNyAtNS45MjE3OTMgMC40NzgyMDcgLTUuODgxOTQzQzAuNDc4MjA3IC01Ljg1MDA2MiAwLjQ3ODIwNyAtNS44MzQxMjIgMC41NzM4NDggLTUuNzM4NDgxQzEuNjg5NjY0IC00LjY3ODQ1NiAxLjk0NDcwNyAtMy4yMTk5MjUgMS45NDQ3MDcgLTEuOTkyNTI4QzEuOTQ0NzA3IDAuMjk0ODk0IDAuOTk2MjY0IDEuMzc4ODI5IDAuNTg5Nzg4IDEuNzQ1NDU1QzAuNDg2MTc3IDEuODQ5MDY2IDAuNDc4MjA3IDEuODU3MDM2IDAuNDc4MjA3IDEuODk2ODg3UzAuNTAyMTE3IDEuOTkyNTI4IDAuNTgxODE4IDEuOTkyNTI4QzAuNzA5MzQgMS45OTI1MjggMS4xMDc4NDYgMS41ODYwNTIgMS4xNzE2MDYgMS41MTQzMjFDMi4yMzk2MDEgMC4zOTg1MDYgMi40NjI3NjUgLTEuMDM2MTE1IDIuNDYyNzY1IC0xLjk5MjUyOFonIGlkPSdnNS00MScvPgo8cGF0aCBkPSdNMy44OTczODUgLTIuNTQyNDY2QzMuODk3Mzg1IC0zLjM5NTI2OCAzLjgwOTcxNCAtMy45MTMzMjUgMy41NDY3IC00LjQyMzQxMkMzLjE5NjAxNSAtNS4xMjQ3ODIgMi41NTA0MzYgLTUuMzAwMTI1IDIuMTEyMDggLTUuMzAwMTI1QzEuMTA3ODQ2IC01LjMwMDEyNSAwLjc0MTIyIC00LjU1MDkzNCAwLjYyOTYzOSAtNC4zMjc3NzFDMC4zNDI3MTUgLTMuNzQ1OTUzIDAuMzI2Nzc1IC0yLjk1NjkxMiAwLjMyNjc3NSAtMi41NDI0NjZDMC4zMjY3NzUgLTIuMDE2NDM4IDAuMzUwNjg1IC0xLjIxMTQ1NyAwLjczMzI1IC0wLjU3Mzg0OEMxLjA5OTg3NSAwLjAxNTk0IDEuNjg5NjY0IDAuMTY3MzcyIDIuMTEyMDggMC4xNjczNzJDMi40OTQ2NDUgMC4xNjczNzIgMy4xODAwNzUgMC4wNDc4MjEgMy41Nzg1OCAtMC43NDEyMkMzLjg3MzQ3NCAtMS4zMTUwNjggMy44OTczODUgLTIuMDI0NDA4IDMuODk3Mzg1IC0yLjU0MjQ2NlpNMi4xMTIwOCAtMC4wNTU3OTFDMS44NDEwOTYgLTAuMDU1NzkxIDEuMjkxMTU4IC0wLjE4MzMxMyAxLjEyMzc4NiAtMS4wMjAxNzRDMS4wMzYxMTUgLTEuNDc0NDcxIDEuMDM2MTE1IC0yLjIyMzY2MSAxLjAzNjExNSAtMi42MzgxMDdDMS4wMzYxMTUgLTMuMTg4MDQ1IDEuMDM2MTE1IC0zLjc0NTk1MyAxLjEyMzc4NiAtNC4xODQzMDlDMS4yOTExNTggLTQuOTk3MjYgMS45MTI4MjcgLTUuMDc2OTYxIDIuMTEyMDggLTUuMDc2OTYxQzIuMzgzMDY0IC01LjA3Njk2MSAyLjkzMzAwMSAtNC45NDE0NjkgMy4wOTI0MDMgLTQuMjE2MTg5QzMuMTg4MDQ1IC0zLjc3NzgzMyAzLjE4ODA0NSAtMy4xODAwNzUgMy4xODgwNDUgLTIuNjM4MTA3QzMuMTg4MDQ1IC0yLjE2Nzg3IDMuMTg4MDQ1IC0xLjQ1MDU2IDMuMDkyNDAzIC0xLjAwNDIzNEMyLjkyNTAzMSAtMC4xNjczNzIgMi4zNzUwOTMgLTAuMDU1NzkxIDIuMTEyMDggLTAuMDU1NzkxWicgaWQ9J2c1LTQ4Jy8+CjxwYXRoIGQ9J00yLjUwMjYxNSAtNS4wNzY5NjFDMi41MDI2MTUgLTUuMjkyMTU0IDIuNDg2Njc1IC01LjMwMDEyNSAyLjI3MTQ4MiAtNS4zMDAxMjVDMS45NDQ3MDcgLTQuOTgxMzIgMS41MjIyOTEgLTQuNzkwMDM3IDAuNzY1MTMxIC00Ljc5MDAzN1YtNC41MjcwMjRDMC45ODAzMjQgLTQuNTI3MDI0IDEuNDEwNzEgLTQuNTI3MDI0IDEuODcyOTc2IC00Ljc0MjIxN1YtMC42NTM1NDlDMS44NzI5NzYgLTAuMzU4NjU1IDEuODQ5MDY2IC0wLjI2MzAxNCAxLjA5MTkwNSAtMC4yNjMwMTRIMC44MTI5NTFWMEMxLjEzOTcyNiAtMC4wMjM5MSAxLjgyNTE1NiAtMC4wMjM5MSAyLjE4MzgxMSAtMC4wMjM5MVMzLjIzNTg2NiAtMC4wMjM5MSAzLjU2MjY0IDBWLTAuMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2IC0wLjI2MzAxNCAyLjUwMjYxNSAtMC4zNTg2NTUgMi41MDI2MTUgLTAuNjUzNTQ5Vi01LjA3Njk2MVonIGlkPSdnNS00OScvPgo8cGF0aCBkPSdNMS40NTg1MzEgLTcuMzc2MzM5QzEuNDcwNDg2IC03LjI5MjY1MyAxLjQ4MjQ0MSAtNy4yMzI4NzcgMS40ODI0NDEgLTcuMDc3NDZDMS40ODI0NDEgLTYuOTEwMDg3IDEuNDgyNDQxIC01Ljk0MTcxOSAwLjY1NzUzNCAtNS4xMTY4MTJDMC41NDk5MzggLTUuMDA5MjE1IDAuNTQ5OTM4IC00Ljk4NTMwNSAwLjU0OTkzOCAtNC45NDk0NEMwLjU0OTkzOCAtNC44ODk2NjQgMC42MDk3MTQgLTQuODI5ODg4IDAuNjY5NDg5IC00LjgyOTg4OEMwLjc3NzA4NiAtNC44Mjk4ODggMS43MjE1NDQgLTUuNzE0NTcgMS43MjE1NDQgLTcuMDc3NDZDMS43MjE1NDQgLTcuODE4NjggMS40NDY1NzUgLTguMjk2ODg3IDAuOTY4MzY5IC04LjI5Njg4N0MwLjYyMTY2OSAtOC4yOTY4ODcgMC4zOTQ1MjEgLTguMDMzODczIDAuMzk0NTIxIC03LjcyMzAzOUMwLjM5NDUyMSAtNy40MDAyNDkgMC42MjE2NjkgLTcuMTM3MjM1IDAuOTgwMzI0IC03LjEzNzIzNUMxLjMwMzExMyAtNy4xMzcyMzUgMS40NTg1MzEgLTcuMzY0Mzg0IDEuNDU4NTMxIC03LjM3NjMzOVpNMy43MzAwMTIgLTcuMzc2MzM5QzMuNzQxOTY4IC03LjI5MjY1MyAzLjc1MzkyMyAtNy4yMzI4NzcgMy43NTM5MjMgLTcuMDc3NDZDMy43NTM5MjMgLTYuOTEwMDg3IDMuNzUzOTIzIC01Ljk0MTcxOSAyLjkyOTAxNiAtNS4xMTY4MTJDMi44MjE0MiAtNS4wMDkyMTUgMi44MjE0MiAtNC45ODUzMDUgMi44MjE0MiAtNC45NDk0NEMyLjgyMTQyIC00Ljg4OTY2NCAyLjg4MTE5NiAtNC44Mjk4ODggMi45NDA5NzEgLTQuODI5ODg4QzMuMDQ4NTY4IC00LjgyOTg4OCAzLjk5MzAyNiAtNS43MTQ1NyAzLjk5MzAyNiAtNy4wNzc0NkMzLjk5MzAyNiAtNy44MTg2OCAzLjcxODA1NyAtOC4yOTY4ODcgMy4yMzk4NTEgLTguMjk2ODg3QzIuODkzMTUxIC04LjI5Njg4NyAyLjY2NjAwMiAtOC4wMzM4NzMgMi42NjYwMDIgLTcuNzIzMDM5QzIuNjY2MDAyIC03LjQwMDI0OSAyLjg5MzE1MSAtNy4xMzcyMzUgMy4yNTE4MDYgLTcuMTM3MjM1QzMuNTc0NTk1IC03LjEzNzIzNSAzLjczMDAxMiAtNy4zNjQzODQgMy43MzAwMTIgLTcuMzc2MzM5WicgaWQ9J2c2LTM0Jy8+CjxwYXRoIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4NiAtMC41Mzc5ODMgMS44MTcxODYgLTIuOTc2ODM3QzEuODE3MTg2IC01LjI5NjEzOSAyLjM3OTA3OCAtNy4yOTI2NTMgMy43NjU4NzggLTguNzAzMzYyQzMuODg1NDMgLTguODEwOTU5IDMuODg1NDMgLTguODM0ODY5IDMuODg1NDMgLTguODcwNzM1QzMuODg1NDMgLTguOTQyNDY2IDMuODI1NjU0IC04Ljk2NjM3NiAzLjc3NzgzMyAtOC45NjYzNzZDMy42MjI0MTYgLTguOTY2Mzc2IDIuNjQyMDkyIC04LjEwNTYwNCAyLjA1NjI4OSAtNi45MzM5OThDMS40NDY1NzUgLTUuNzI2NTI2IDEuMTcxNjA2IC00LjQ0NzMyMyAxLjE3MTYwNiAtMi45NzY4MzdDMS4xNzE2MDYgLTEuOTEyODI3IDEuMzM4OTc5IC0wLjQ5MDE2MiAxLjk2MDY0OCAwLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJyBpZD0nZzYtNDAnLz4KPHBhdGggZD0nTTMuMzcxMzU3IC0yLjk3NjgzN0MzLjM3MTM1NyAtMy44ODU0MyAzLjI1MTgwNiAtNS4zNjc4NyAyLjU4MjMxNiAtNi43NTQ2N0MxLjg3Njk2MSAtOC4xODkyOSAwLjg5NjYzOCAtOC45NjYzNzYgMC43NjUxMzEgLTguOTY2Mzc2QzAuNzE3MzEgLTguOTY2Mzc2IDAuNjU3NTM0IC04Ljk0MjQ2NiAwLjY1NzUzNCAtOC44NzA3MzVDMC42NTc1MzQgLTguODM0ODY5IDAuNjU3NTM0IC04LjgxMDk1OSAwLjg2MDc3MiAtOC42MDc3MjFDMi4wNTYyODkgLTcuNDAwMjQ5IDIuNzI1Nzc4IC01LjQyNzY0NiAyLjcyNTc3OCAtMi45ODg3OTJDMi43MjU3NzggLTAuNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IDAuNzc3MDg2IDIuNzM3NzMzQzAuNjU3NTM0IDIuODQ1MzMgMC42NTc1MzQgMi44NjkyNCAwLjY1NzUzNCAyLjkwNTEwNkMwLjY1NzUzNCAyLjk3NjgzNyAwLjcxNzMxIDMuMDAwNzQ3IDAuNzY1MTMxIDMuMDAwNzQ3QzAuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IDAuOTY4MzY5QzMuMDk2Mzg5IC0wLjI1MTA1OSAzLjM3MTM1NyAtMS41NDIyMTcgMy4zNzEzNTcgLTIuOTc2ODM3WicgaWQ9J2c2LTQxJy8+CjxwYXRoIGQ9J000Ljc3MDExMiAtMi43NjE2NDRIOC4wNjk3MzhDOC4yMzcxMTEgLTIuNzYxNjQ0IDguNDUyMzA0IC0yLjc2MTY0NCA4LjQ1MjMwNCAtMi45NzY4MzdDOC40NTIzMDQgLTMuMjAzOTg1IDguMjQ5MDY2IC0zLjIwMzk4NSA4LjA2OTczOCAtMy4yMDM5ODVINC43NzAxMTJWLTYuNTAzNjExQzQuNzcwMTEyIC02LjY3MDk4NCA0Ljc3MDExMiAtNi44ODYxNzcgNC41NTQ5MTkgLTYuODg2MTc3QzQuMzI3NzcxIC02Ljg4NjE3NyA0LjMyNzc3MSAtNi42ODI5MzkgNC4zMjc3NzEgLTYuNTAzNjExVi0zLjIwMzk4NUgxLjAyODE0NEMwLjg2MDc3MiAtMy4yMDM5ODUgMC42NDU1NzkgLTMuMjAzOTg1IDAuNjQ1NTc5IC0yLjk4ODc5MkMwLjY0NTU3OSAtMi43NjE2NDQgMC44NDg4MTcgLTIuNzYxNjQ0IDEuMDI4MTQ0IC0yLjc2MTY0NEg0LjMyNzc3MVYwLjUzNzk4M0M0LjMyNzc3MSAwLjcwNTM1NSA0LjMyNzc3MSAwLjkyMDU0OCA0LjU0Mjk2NCAwLjkyMDU0OEM0Ljc3MDExMiAwLjkyMDU0OCA0Ljc3MDExMiAwLjcxNzMxIDQuNzcwMTEyIDAuNTM3OTgzVi0yLjc2MTY0NFonIGlkPSdnNi00MycvPgo8cGF0aCBkPSdNMy40NDMwODggLTcuNjYzMjYzQzMuNDQzMDg4IC03LjkzODIzMiAzLjQ0MzA4OCAtNy45NTAxODcgMy4yMDM5ODUgLTcuOTUwMTg3QzIuOTE3MDYxIC03LjYyNzM5NyAyLjMxOTMwMyAtNy4xODUwNTYgMS4wODc5MiAtNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5IC02LjgzODM1NiAxLjk2MDY0OCAtNi44MzgzNTYgMi42MTgxODIgLTcuMTQ5MTkxVi0wLjkyMDU0OEMyLjYxODE4MiAtMC40OTAxNjIgMi41ODIzMTYgLTAuMzQ2NyAxLjUzMDI2MiAtMC4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEgLTAuMDIzOTEgMi42NDIwOTIgLTAuMDIzOTEgMy4wMzY2MTMgLTAuMDIzOTFTNC41Nzg4MjkgLTAuMDIzOTEgNC45MDE2MTkgMFYtMC4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0IC0wLjM0NjcgMy40NDMwODggLTAuNDkwMTYyIDMuNDQzMDg4IC0wLjkyMDU0OFYtNy42NjMyNjNaJyBpZD0nZzYtNDknLz4KPHBhdGggZD0nTTguMDY5NzM4IC0zLjg3MzQ3NEM4LjIzNzExMSAtMy44NzM0NzQgOC40NTIzMDQgLTMuODczNDc0IDguNDUyMzA0IC00LjA4ODY2N0M4LjQ1MjMwNCAtNC4zMTU4MTYgOC4yNDkwNjYgLTQuMzE1ODE2IDguMDY5NzM4IC00LjMxNTgxNkgxLjAyODE0NEMwLjg2MDc3MiAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMzE1ODE2IDAuNjQ1NTc5IC00LjEwMDYyM0MwLjY0NTU3OSAtMy44NzM0NzQgMC44NDg4MTcgLTMuODczNDc0IDEuMDI4MTQ0IC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzggLTEuNjQ5ODEzQzguMjM3MTExIC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS42NDk4MTMgOC40NTIzMDQgLTEuODY1MDA2QzguNDUyMzA0IC0yLjA5MjE1NCA4LjI0OTA2NiAtMi4wOTIxNTQgOC4wNjk3MzggLTIuMDkyMTU0SDEuMDI4MTQ0QzAuODYwNzcyIC0yLjA5MjE1NCAwLjY0NTU3OSAtMi4wOTIxNTQgMC42NDU1NzkgLTEuODc2OTYxQzAuNjQ1NTc5IC0xLjY0OTgxMyAwLjg0ODgxNyAtMS42NDk4MTMgMS4wMjgxNDQgLTEuNjQ5ODEzSDguMDY5NzM4WicgaWQ9J2c2LTYxJy8+CjxwYXRoIGQ9J00yLjk4ODc5MiAyLjk4ODc5MlYyLjU0NjQ1MUgxLjgyOTE0MVYtOC41MjQwMzVIMi45ODg3OTJWLTguOTY2Mzc2SDEuMzg2OFYyLjk4ODc5MkgyLjk4ODc5MlonIGlkPSdnNi05MScvPgo8cGF0aCBkPSdNMS44NTMwNTEgLTguOTY2Mzc2SDAuMjUxMDU5Vi04LjUyNDAzNUgxLjQxMDcxVjIuNTQ2NDUxSDAuMjUxMDU5VjIuOTg4NzkySDEuODUzMDUxVi04Ljk2NjM3NlonIGlkPSdnNi05MycvPgo8cGF0aCBkPSdNMi4wODAxOTkgLTcuMzY0Mzg0QzIuMDgwMTk5IC03LjY3NTIxOCAxLjgyOTE0MSAtNy45NTAxODcgMS40OTQzOTYgLTcuOTUwMTg3QzEuMTgzNTYyIC03Ljk1MDE4NyAwLjkyMDU0OCAtNy42OTkxMjggMC45MjA1NDggLTcuMzc2MzM5QzAuOTIwNTQ4IC03LjAxNzY4NCAxLjIwNzQ3MiAtNi43OTA1MzUgMS40OTQzOTYgLTYuNzkwNTM1QzEuODY1MDA2IC02Ljc5MDUzNSAyLjA4MDE5OSAtNy4xMDEzNyAyLjA4MDE5OSAtNy4zNjQzODRaTTAuNDMwMzg2IC01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTcgLTQuNzk0MDIyIDEuMzAzMTEzIC00LjcyMjI5MSAxLjMwMzExMyAtNC4xMzY0ODhWLTAuODg0NjgyQzEuMzAzMTEzIC0wLjM0NjcgMS4xNzE2MDYgLTAuMzQ2NyAwLjM5NDUyMSAtMC4zNDY3VjBDMC43MjkyNjUgLTAuMDIzOTEgMS4zMDMxMTMgLTAuMDIzOTEgMS42NDk4MTMgLTAuMDIzOTFDMS43ODEzMiAtMC4wMjM5MSAyLjQ3NDcyIC0wLjAyMzkxIDIuODgxMTk2IDBWLTAuMzQ2N0MyLjEwNDExIC0wLjM0NjcgMi4wNTYyODkgLTAuNDA2NDc2IDIuMDU2Mjg5IC0wLjg3MjcyN1YtNS4yNzIyMjlMMC40MzAzODYgLTUuMTQwNzIyWicgaWQ9J2c2LTEwNScvPgo8cGF0aCBkPSdNOC41NzE4NTYgLTIuOTA1MTA2QzguNTcxODU2IC00LjAxNjkzNiA4LjU3MTg1NiAtNC4zNTE2ODEgOC4yOTY4ODcgLTQuNzM0MjQ3QzcuOTUwMTg3IC01LjIwMDQ5OCA3LjM4ODI5NCAtNS4yNzIyMjkgNi45ODE4MTggLTUuMjcyMjI5QzUuOTg5NTM5IC01LjI3MjIyOSA1LjQ4NzQyMiAtNC41NTQ5MTkgNS4yOTYxMzkgLTQuMDg4NjY3QzUuMTI4NzY3IC01LjAwOTIxNSA0LjQ4MzE4OCAtNS4yNzIyMjkgMy43MzAwMTIgLTUuMjcyMjI5QzIuNTcwMzYxIC01LjI3MjIyOSAyLjExNjA2NSAtNC4yNzk5NSAyLjAyMDQyMyAtNC4wNDA4NDdIMi4wMDg0NjhWLTUuMjcyMjI5TDAuMzgyNTY1IC01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTcgLTQuNzk0MDIyIDEuMjkxMTU4IC00LjcxMDMzNiAxLjI5MTE1OCAtNC4xMjQ1MzNWLTAuODg0NjgyQzEuMjkxMTU4IC0wLjM0NjcgMS4xNTk2NTEgLTAuMzQ2NyAwLjM4MjU2NSAtMC4zNDY3VjBDMC42OTM0IC0wLjAyMzkxIDEuMzM4OTc5IC0wLjAyMzkxIDEuNjczNzI0IC0wLjAyMzkxQzIuMDIwNDIzIC0wLjAyMzkxIDIuNjY2MDAyIC0wLjAyMzkxIDIuOTc2ODM3IDBWLTAuMzQ2N0MyLjIxMTcwNiAtMC4zNDY3IDIuMDY4MjQ0IC0wLjM0NjcgMi4wNjgyNDQgLTAuODg0NjgyVi0zLjEwODM0NEMyLjA2ODI0NCAtNC4zNjM2MzYgMi44OTMxNTEgLTUuMDMzMTI2IDMuNjM0MzcxIC01LjAzMzEyNlM0LjU0Mjk2NCAtNC40MjM0MTIgNC41NDI5NjQgLTMuNjk0MTQ3Vi0wLjg4NDY4MkM0LjU0Mjk2NCAtMC4zNDY3IDQuNDExNDU3IC0wLjM0NjcgMy42MzQzNzEgLTAuMzQ2N1YwQzMuOTQ1MjA1IC0wLjAyMzkxIDQuNTkwNzg1IC0wLjAyMzkxIDQuOTI1NTI5IC0wLjAyMzkxQzUuMjcyMjI5IC0wLjAyMzkxIDUuOTE3ODA4IC0wLjAyMzkxIDYuMjI4NjQzIDBWLTAuMzQ2N0M1LjQ2MzUxMiAtMC4zNDY3IDUuMzIwMDUgLTAuMzQ2NyA1LjMyMDA1IC0wLjg4NDY4MlYtMy4xMDgzNDRDNS4zMjAwNSAtNC4zNjM2MzYgNi4xNDQ5NTYgLTUuMDMzMTI2IDYuODg2MTc3IC01LjAzMzEyNlM3Ljc5NDc3IC00LjQyMzQxMiA3Ljc5NDc3IC0zLjY5NDE0N1YtMC44ODQ2ODJDNy43OTQ3NyAtMC4zNDY3IDcuNjYzMjYzIC0wLjM0NjcgNi44ODYxNzcgLTAuMzQ2N1YwQzcuMTk3MDExIC0wLjAyMzkxIDcuODQyNTkgLTAuMDIzOTEgOC4xNzczMzUgLTAuMDIzOTFDOC41MjQwMzUgLTAuMDIzOTEgOS4xNjk2MTQgLTAuMDIzOTEgOS40ODA0NDggMFYtMC4zNDY3QzguODgyNjkgLTAuMzQ2NyA4LjU4MzgxMSAtMC4zNDY3IDguNTcxODU2IC0wLjcwNTM1NVYtMi45MDUxMDZaJyBpZD0nZzYtMTA5Jy8+CjxwYXRoIGQ9J001LjMyMDA1IC0yLjkwNTEwNkM1LjMyMDA1IC00LjAxNjkzNiA1LjMyMDA1IC00LjM1MTY4MSA1LjA0NTA4MSAtNC43MzQyNDdDNC42OTgzODEgLTUuMjAwNDk4IDQuMTM2NDg4IC01LjI3MjIyOSAzLjczMDAxMiAtNS4yNzIyMjlDMi41NzAzNjEgLTUuMjcyMjI5IDIuMTE2MDY1IC00LjI3OTk1IDIuMDIwNDIzIC00LjA0MDg0N0gyLjAwODQ2OFYtNS4yNzIyMjlMMC4zODI1NjUgLTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE5NTUxNyAtNC43OTQwMjIgMS4yOTExNTggLTQuNzEwMzM2IDEuMjkxMTU4IC00LjEyNDUzM1YtMC44ODQ2ODJDMS4yOTExNTggLTAuMzQ2NyAxLjE1OTY1MSAtMC4zNDY3IDAuMzgyNTY1IC0wLjM0NjdWMEMwLjY5MzQgLTAuMDIzOTEgMS4zMzg5NzkgLTAuMDIzOTEgMS42NzM3MjQgLTAuMDIzOTFDMi4wMjA0MjMgLTAuMDIzOTEgMi42NjYwMDIgLTAuMDIzOTEgMi45NzY4MzcgMFYtMC4zNDY3QzIuMjExNzA2IC0wLjM0NjcgMi4wNjgyNDQgLTAuMzQ2NyAyLjA2ODI0NCAtMC44ODQ2ODJWLTMuMTA4MzQ0QzIuMDY4MjQ0IC00LjM2MzYzNiAyLjg5MzE1MSAtNS4wMzMxMjYgMy42MzQzNzEgLTUuMDMzMTI2UzQuNTQyOTY0IC00LjQyMzQxMiA0LjU0Mjk2NCAtMy42OTQxNDdWLTAuODg0NjgyQzQuNTQyOTY0IC0wLjM0NjcgNC40MTE0NTcgLTAuMzQ2NyAzLjYzNDM3MSAtMC4zNDY3VjBDMy45NDUyMDUgLTAuMDIzOTEgNC41OTA3ODUgLTAuMDIzOTEgNC45MjU1MjkgLTAuMDIzOTFDNS4yNzIyMjkgLTAuMDIzOTEgNS45MTc4MDggLTAuMDIzOTEgNi4yMjg2NDMgMFYtMC4zNDY3QzUuNjMwODg0IC0wLjM0NjcgNS4zMzIwMDUgLTAuMzQ2NyA1LjMyMDA1IC0wLjcwNTM1NVYtMi45MDUxMDZaJyBpZD0nZzYtMTEwJy8+CjxwYXRoIGQ9J00yLjMyNzI3MyAtNS4yOTIxNTRDMi4zMzUyNDMgLTUuMzA4MDk1IDIuMzU5MTUzIC01LjQxMTcwNiAyLjM1OTE1MyAtNS40MTk2NzZDMi4zNTkxNTMgLTUuNDU5NTI3IDIuMzI3MjczIC01LjUzMTI1OCAyLjIzMTYzMSAtNS41MzEyNThDMi4xOTk3NTEgLTUuNTMxMjU4IDEuOTUyNjc3IC01LjUwNzM0NyAxLjc2OTM2NSAtNS40OTE0MDdMMS4zMjMwMzkgLTUuNDU5NTI3QzEuMTQ3Njk2IC01LjQ0MzU4NyAxLjA2Nzk5NSAtNS40MzU2MTYgMS4wNjc5OTUgLTUuMjkyMTU0QzEuMDY3OTk1IC01LjE4MDU3MyAxLjE3OTU3NyAtNS4xODA1NzMgMS4yNzUyMTggLTUuMTgwNTczQzEuNjU3NzgzIC01LjE4MDU3MyAxLjY1Nzc4MyAtNS4xMzI3NTIgMS42NTc3ODMgLTUuMDYxMDIxQzEuNjU3NzgzIC01LjAzNzExMSAxLjY1Nzc4MyAtNS4wMjExNzEgMS42MTc5MzMgLTQuODc3NzA5TDAuNDg2MTc3IC0wLjM0MjcxNUMwLjQ1NDI5NiAtMC4yMjMxNjMgMC40NTQyOTYgLTAuMTc1MzQyIDAuNDU0Mjk2IC0wLjE2NzM3MkMwLjQ1NDI5NiAtMC4wMzE4OCAwLjU2NTg3OCAwLjA3OTcwMSAwLjcxNzMxIDAuMDc5NzAxQzAuOTg4Mjk0IDAuMDc5NzAxIDEuMDUyMDU1IC0wLjE3NTM0MiAxLjA4MzkzNSAtMC4yODY5MjRDMS4xNjM2MzYgLTAuNjIxNjY5IDEuMzcwODU5IC0xLjQ2NjUwMSAxLjQ1ODUzMSAtMS44MDEyNDVDMS44OTY4ODcgLTEuNzUzNDI1IDIuNDMwODg0IC0xLjYwMTk5MyAyLjQzMDg4NCAtMS4xNDc2OTZDMi40MzA4ODQgLTEuMTA3ODQ2IDIuNDMwODg0IC0xLjA2Nzk5NSAyLjQxNDk0NCAtMC45ODgyOTRDMi4zOTEwMzQgLTAuODg0NjgyIDIuMzc1MDkzIC0wLjc3MzEwMSAyLjM3NTA5MyAtMC43MzMyNUMyLjM3NTA5MyAtMC4yNjMwMTQgMi43MjU3NzggMC4wNzk3MDEgMy4xODgwNDUgMC4wNzk3MDFDMy41MjI3OSAwLjA3OTcwMSAzLjczMDAxMiAtMC4xNjczNzIgMy44MzM2MjQgLTAuMzE4ODA0QzQuMDI0OTA3IC0wLjYxMzY5OSA0LjE1MjQyOCAtMS4wOTE5MDUgNC4xNTI0MjggLTEuMTM5NzI2QzQuMTUyNDI4IC0xLjIxOTQyNyA0LjA4ODY2NyAtMS4yNDMzMzcgNC4wMzI4NzcgLTEuMjQzMzM3QzMuOTM3MjM1IC0xLjI0MzMzNyAzLjkyMTI5NSAtMS4xOTU1MTcgMy44ODk0MTUgLTEuMDUyMDU1QzMuNzg1ODAzIC0wLjY3NzQ2IDMuNTc4NTggLTAuMTQzNDYyIDMuMjAzOTg1IC0wLjE0MzQ2MkMyLjk5Njc2MiAtMC4xNDM0NjIgMi45NDg5NDEgLTAuMzE4ODA0IDIuOTQ4OTQxIC0wLjUzMzk5OEMyLjk0ODk0MSAtMC42Mzc2MDkgMi45NTY5MTIgLTAuNzMzMjUgMi45OTY3NjIgLTAuOTE2NTYzQzMuMDA0NzMyIC0wLjk0ODQ0MyAzLjAzNjYxMyAtMS4wNzU5NjUgMy4wMzY2MTMgLTEuMTYzNjM2QzMuMDM2NjEzIC0xLjgxNzE4NiAyLjIxNTY5MSAtMS45NjA2NDggMS44MDkyMTUgLTIuMDE2NDM4QzIuMTA0MTEgLTIuMTkxNzgxIDIuMzc1MDkzIC0yLjQ2Mjc2NSAyLjQ3MDczNSAtMi41NjYzNzZDMi45MDkwOTEgLTIuOTk2NzYyIDMuMjY3NzQ2IC0zLjI5MTY1NiAzLjY1MDMxMSAtMy4yOTE2NTZDMy43NTM5MjMgLTMuMjkxNjU2IDMuODQ5NTY0IC0zLjI2Nzc0NiAzLjkxMzMyNSAtMy4xODgwNDVDMy40ODI5MzkgLTMuMTMyMjU0IDMuNDgyOTM5IC0yLjc1NzY1OSAzLjQ4MjkzOSAtMi43NDk2ODlDMy40ODI5MzkgLTIuNTc0MzQ2IDMuNjE4NDMxIC0yLjQ1NDc5NSAzLjc5Mzc3MyAtMi40NTQ3OTVDNC4wMDg5NjYgLTIuNDU0Nzk1IDQuMjQ4MDcgLTIuNjMwMTM3IDQuMjQ4MDcgLTIuOTU2OTEyQzQuMjQ4MDcgLTMuMjI3ODk1IDQuMDU2Nzg3IC0zLjUxNDgxOSAzLjY1ODI4MSAtMy41MTQ4MTlDMy4xOTYwMTUgLTMuNTE0ODE5IDIuNzgxNTY5IC0zLjE2NDEzNCAyLjMyNzI3MyAtMi43MDk4MzhDMS44NjUwMDYgLTIuMjU1NTQyIDEuNjY1NzUzIC0yLjE2Nzg3IDEuNTM4MjMyIC0yLjExMjA4TDIuMzI3MjczIC01LjI5MjE1NFonIGlkPSdnMy0xMDcnLz4KPHBhdGggZD0nTTIuMDg4MTY5IC01LjI5MjE1NEMyLjA5NjEzOSAtNS4zMDgwOTUgMi4xMjAwNSAtNS40MTE3MDYgMi4xMjAwNSAtNS40MTk2NzZDMi4xMjAwNSAtNS40NTk1MjcgMi4wODgxNjkgLTUuNTMxMjU4IDEuOTkyNTI4IC01LjUzMTI1OEwxLjE4NzU0NyAtNS40Njc0OTdDMC44OTI2NTMgLTUuNDQzNTg3IDAuODI4ODkyIC01LjQzNTYxNiAwLjgyODg5MiAtNS4yOTIxNTRDMC44Mjg4OTIgLTUuMTgwNTczIDAuOTQwNDczIC01LjE4MDU3MyAxLjAzNjExNSAtNS4xODA1NzNDMS40MTg2OCAtNS4xODA1NzMgMS40MTg2OCAtNS4xMzI3NTIgMS40MTg2OCAtNS4wNjEwMjFDMS40MTg2OCAtNS4wMzcxMTEgMS40MTg2OCAtNS4wMjExNzEgMS4zNzg4MjkgLTQuODc3NzA5TDAuMzkwNTM1IC0wLjkyNDUzM0MwLjM1ODY1NSAtMC43OTcwMTEgMC4zNTg2NTUgLTAuNjc3NDYgMC4zNTg2NTUgLTAuNjY5NDg5QzAuMzU4NjU1IC0wLjE3NTM0MiAwLjc2NTEzMSAwLjA3OTcwMSAxLjE2MzYzNiAwLjA3OTcwMUMxLjUwNjM1MSAwLjA3OTcwMSAxLjY4OTY2NCAtMC4xOTEyODMgMS43NzczMzUgLTAuMzY2NjI1QzEuOTIwNzk3IC0wLjYyOTYzOSAyLjA0MDM0OSAtMS4wOTk4NzUgMi4wNDAzNDkgLTEuMTM5NzI2QzIuMDQwMzQ5IC0xLjE4NzU0NyAyLjAxNjQzOCAtMS4yNDMzMzcgMS45MTI4MjcgLTEuMjQzMzM3QzEuODQxMDk2IC0xLjI0MzMzNyAxLjgxNzE4NiAtMS4yMDM0ODcgMS44MTcxODYgLTEuMTk1NTE3QzEuODAxMjQ1IC0xLjE3MTYwNiAxLjc2MTM5NSAtMS4wMjgxNDQgMS43Mzc0ODQgLTAuOTQwNDczQzEuNjE3OTMzIC0wLjQ3ODIwNyAxLjQ2NjUwMSAtMC4xNDM0NjIgMS4xNzk1NzcgLTAuMTQzNDYyQzAuOTg4Mjk0IC0wLjE0MzQ2MiAwLjkzMjUwMyAtMC4zMjY3NzUgMC45MzI1MDMgLTAuNTE4MDU3QzAuOTMyNTAzIC0wLjY2OTQ4OSAwLjk1NjQxMyAtMC43NTcxNjEgMC45ODAzMjQgLTAuODYwNzcyTDIuMDg4MTY5IC01LjI5MjE1NFonIGlkPSdnMy0xMDgnLz4KPHBhdGggZD0nTTMuNzkzNzczIC0zLjI4MzY4NkMzLjgwMTc0MyAtMy4zMTU1NjcgMy44MDk3MTQgLTMuMzYzMzg3IDMuODA5NzE0IC0zLjQwMzIzOEMzLjgwOTcxNCAtMy40NTEwNTkgMy43Nzc4MzMgLTMuNTE0ODE5IDMuNzA2MTAyIC0zLjUxNDgxOUMzLjYxMDQ2MSAtMy41MTQ4MTkgMy4yODM2ODYgLTMuMjAzOTg1IDMuMTU2MTY0IC0yLjk4MDgyMkMzLjA2ODQ5MyAtMy4xNTYxNjQgMi44MjkzOSAtMy41MTQ4MTkgMi4zMzUyNDMgLTMuNTE0ODE5QzEuMzg2OCAtMy41MTQ4MTkgMC4zNDI3MTUgLTIuNDA2OTc0IDAuMzQyNzE1IC0xLjIyNzM5N0MwLjM0MjcxNSAtMC4zOTg1MDYgMC44NzY3MTIgMC4wNzk3MDEgMS40OTA0MTEgMC4wNzk3MDFDMS44ODg5MTcgMC4wNzk3MDEgMi4yMTU2OTEgLTAuMTUxNDMyIDIuNDU0Nzk1IC0wLjM1ODY1NUMyLjQ0NjgyNCAtMC4zMzQ3NDUgMi4xOTk3NTEgMC42Njk0ODkgMi4xNjc4NyAwLjgwNDk4MUMyLjA0ODMxOSAxLjI2NzI0OCAyLjA0ODMxOSAxLjI3NTIxOCAxLjU0NjIwMiAxLjI4MzE4OEMxLjQ1MDU2IDEuMjgzMTg4IDEuMzQ2OTQ5IDEuMjgzMTg4IDEuMzQ2OTQ5IDEuNDM0NjJDMS4zNDY5NDkgMS40ODI0NDEgMS4zODY4IDEuNTQ2MjAyIDEuNDY2NTAxIDEuNTQ2MjAyQzEuNTcwMTEyIDEuNTQ2MjAyIDEuNzUzNDI1IDEuNTMwMjYyIDEuODU3MDM2IDEuNTIyMjkxSDIuMjc5NDUyQzIuOTE3MDYxIDEuNTIyMjkxIDMuMDYwNTIzIDEuNTQ2MjAyIDMuMTI0Mjg0IDEuNTQ2MjAyQzMuMTU2MTY0IDEuNTQ2MjAyIDMuMjc1NzE2IDEuNTQ2MjAyIDMuMjc1NzE2IDEuMzk0NzdDMy4yNzU3MTYgMS4yODMxODggMy4xNjQxMzQgMS4yODMxODggMy4wNjg0OTMgMS4yODMxODhDMi42ODU5MjggMS4yODMxODggMi42ODU5MjggMS4yMzUzNjcgMi42ODU5MjggMS4xNjM2MzZDMi42ODU5MjggMS4xNTU2NjYgMi42ODU5MjggMS4xMTU4MTYgMi43MTc4MDggMC45OTYyNjRMMy43OTM3NzMgLTMuMjgzNjg2Wk0yLjYxNDE5NyAtMC45ODgyOTRDMi41ODIzMTYgLTAuODY4NzQyIDIuNTgyMzE2IC0wLjg0NDgzMiAyLjQ0NjgyNCAtMC42OTM0QzIuMDMyMzc5IC0wLjIwNzIyMyAxLjY4MTY5NCAtMC4xNDM0NjIgMS41MTQzMjEgLTAuMTQzNDYyQzEuMTQ3Njk2IC0wLjE0MzQ2MiAwLjk2NDM4NCAtMC40NzgyMDcgMC45NjQzODQgLTAuODkyNjUzQzAuOTY0Mzg0IC0xLjI2NzI0OCAxLjE3OTU3NyAtMi4xMjAwNSAxLjM1NDkxOSAtMi40NzA3MzVDMS41ODYwNTIgLTIuOTU2OTEyIDEuOTc2NTg4IC0zLjI5MTY1NiAyLjM0MzIxMyAtMy4yOTE2NTZDMi44NzcyMSAtMy4yOTE2NTYgMy4wMTI3MDIgLTIuNjY5OTg4IDMuMDEyNzAyIC0yLjYxNDE5N0MzLjAxMjcwMiAtMi41ODIzMTYgMi45OTY3NjIgLTIuNTI2NTI2IDIuOTg4NzkyIC0yLjQ4NjY3NUwyLjYxNDE5NyAtMC45ODgyOTRaJyBpZD0nZzMtMTEzJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSczOC44NTQyOTYnIHhsaW5rOmhyZWY9JyNnNC03NycgeT0nOTYuMDM5OTgxJy8+Cjx1c2UgeD0nNTEuNDI3OTAzJyB4bGluazpocmVmPScjZzYtMzQnIHk9Jzk2LjAzOTk4MScvPgo8dXNlIHg9JzU3LjI4MDg5NCcgeGxpbms6aHJlZj0nI2c2LTQwJyB5PSc5Ni4wMzk5ODEnLz4KPHVzZSB4PSc2MS44MzMyMTknIHhsaW5rOmhyZWY9JyNnNC0xMTMnIHk9Jzk2LjAzOTk4MScvPgo8dXNlIHg9JzY3LjQ1MjM3NicgeGxpbms6aHJlZj0nI2c0LTU5JyB5PSc5Ni4wMzk5ODEnLz4KPHVzZSB4PSc3Mi42OTY1MzUnIHhsaW5rOmhyZWY9JyNnNC04MycgeT0nOTYuMDM5OTgxJy8+Cjx1c2UgeD0nODAuNTkxODU4JyB4bGluazpocmVmPScjZzYtNDEnIHk9Jzk2LjAzOTk4MScvPgo8dXNlIHg9Jzk1LjEwNjgyJyB4bGluazpocmVmPScjZzYtNjEnIHk9Jzk2LjAzOTk4MScvPgo8dXNlIHg9JzExNC4xNzQxMTEnIHhsaW5rOmhyZWY9JyNnNi0xMDknIHk9Jzk2LjAzOTk4MScvPgo8dXNlIHg9JzEyMy45MjkwOTUnIHhsaW5rOmhyZWY9JyNnNi0xMDUnIHk9Jzk2LjAzOTk4MScvPgo8dXNlIHg9JzEyNy4xODA3NTYnIHhsaW5rOmhyZWY9JyNnNi0xMTAnIHk9Jzk2LjAzOTk4MScvPgo8dXNlIHg9JzEzNS42NzY1NzcnIHhsaW5rOmhyZWY9JyNnMS0yNicgeT0nNzkuMTgzMDQ0Jy8+Cjx1c2UgeD0nMTQ5LjYyNDI4OCcgeGxpbms6aHJlZj0nI2c2LTEwOScgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMTU5LjM3OTI3MicgeGxpbms6aHJlZj0nI2c2LTEwNScgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMTYyLjYzMDkzMycgeGxpbms6aHJlZj0nI2c2LTExMCcgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMTY5LjEzNDI1NScgeGxpbms6aHJlZj0nI2c1LTQ5JyB5PSc5MC43MjY1NDgnLz4KPHVzZSB4PScxNzMuMzY4NDM4JyB4bGluazpocmVmPScjZzAtNTQnIHk9JzkwLjcyNjU0OCcvPgo8dXNlIHg9JzE3OS41Njc0MzYnIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9JzkwLjcyNjU0OCcvPgo8dXNlIHg9JzE4NC4xODkwNTInIHhsaW5rOmhyZWY9JyNnMC01NCcgeT0nOTAuNzI2NTQ4Jy8+Cjx1c2UgeD0nMTkwLjM4ODA1JyB4bGluazpocmVmPScjZzMtMTA4JyB5PSc5MC43MjY1NDgnLz4KPHVzZSB4PScxOTMuMDEwMTc1JyB4bGluazpocmVmPScjZzUtNDAnIHk9JzkwLjcyNjU0OCcvPgo8dXNlIHg9JzE5Ni4zMDM0MjgnIHhsaW5rOmhyZWY9JyNnMy0xMTMnIHk9JzkwLjcyNjU0OCcvPgo8dXNlIHg9JzIwMC4zNzAxNzknIHhsaW5rOmhyZWY9JyNnNS00MScgeT0nOTAuNzI2NTQ4Jy8+Cjx1c2UgeD0nMjA2LjE1NDA2MicgeGxpbms6aHJlZj0nI2cyLTEwMicgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMjEyLjEzMTY2MScgeGxpbms6aHJlZj0nI2c0LTc3JyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PScyMjQuNzA1MjY4JyB4bGluazpocmVmPScjZzYtMzQnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzIzMC41NTgyNTgnIHhsaW5rOmhyZWY9JyNnNi00MCcgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMjM1LjExMDU4NCcgeGxpbms6aHJlZj0nI2c0LTExMycgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMjQwLjcyOTc0JyB4bGluazpocmVmPScjZzYtOTEnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzI0My45ODE0MDInIHhsaW5rOmhyZWY9JyNnNi00OScgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMjQ5LjgzNDM5MicgeGxpbms6aHJlZj0nI2c0LTU4JyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PScyNTMuMDg2MDUzJyB4bGluazpocmVmPScjZzQtNTgnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzI1Ni4zMzc3MTQnIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzI2NS40ODM4ODInIHhsaW5rOmhyZWY9JyNnMi0wJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PScyNzcuNDM5MDQyJyB4bGluazpocmVmPScjZzYtNDknIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzI4My4yOTIwMzMnIHhsaW5rOmhyZWY9JyNnNi05MycgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMjg2LjU0MzY5NCcgeGxpbms6aHJlZj0nI2c0LTU5JyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PScyOTEuNzg3ODUzJyB4bGluazpocmVmPScjZzQtODMnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzI5OS42ODMxNzYnIHhsaW5rOmhyZWY9JyNnNi00MScgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMzA2Ljg5MjE2NScgeGxpbms6aHJlZj0nI2c2LTQzJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSczMTguNjUzNDgnIHhsaW5rOmhyZWY9JyNnNi00OScgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMzI3LjE2MzEzNCcgeGxpbms6aHJlZj0nI2c2LTQzJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSczMzguOTI0NDQ5JyB4bGluazpocmVmPScjZzYtMTA5JyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSczNDguNjc5NDMzJyB4bGluazpocmVmPScjZzYtMTA1JyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSczNTEuOTMxMDk0JyB4bGluazpocmVmPScjZzYtMTEwJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSczNTguNDM0NDE2JyB4bGluazpocmVmPScjZzYtNDAnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzM2Mi45ODY3NDInIHhsaW5rOmhyZWY9JyNnNC03NScgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nMzczLjgwNDQyMicgeGxpbms6aHJlZj0nI2c2LTQwJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSczNzguMzU2NzQ3JyB4bGluazpocmVmPScjZzQtMTEzJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSczODMuOTc1OTA0JyB4bGluazpocmVmPScjZzQtNTknIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzM4OS4yMjAwNjMnIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzM5NS43MDk1NjcnIHhsaW5rOmhyZWY9JyNnNC01OScgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nNDAwLjk1MzcyNicgeGxpbms6aHJlZj0nI2c0LTgzJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSc0MDguODQ5MDQ5JyB4bGluazpocmVmPScjZzYtNDEnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzQxMy40MDEzNzQnIHhsaW5rOmhyZWY9JyNnNC01OScgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nNDE4LjY0NTUzMycgeGxpbms6aHJlZj0nI2c0LTEwOCcgeT0nODguODY2ODM4Jy8+Cjx1c2UgeD0nNDIyLjM5NTM0MicgeGxpbms6aHJlZj0nI2c2LTQwJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSc0MjYuOTQ3NjY4JyB4bGluazpocmVmPScjZzQtMTEzJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSc0MzIuNTY2ODI0JyB4bGluazpocmVmPScjZzYtNDEnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzQzOS43NzU4MTMnIHhsaW5rOmhyZWY9JyNnMi0wJyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSc0NTEuNzMwOTc0JyB4bGluazpocmVmPScjZzQtMTA3JyB5PSc4OC44NjY4MzgnLz4KPHVzZSB4PSc0NTguMjIwNDc4JyB4bGluazpocmVmPScjZzYtNDEnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzQ2Mi43NzI4MDQnIHhsaW5rOmhyZWY9JyNnMi0xMDMnIHk9Jzg4Ljg2NjgzOCcvPgo8dXNlIHg9JzE0OS42MjQyODgnIHhsaW5rOmhyZWY9JyNnNi0xMDknIHk9JzEwMi44MTQ1MzQnLz4KPHVzZSB4PScxNTkuMzc5MjcyJyB4bGluazpocmVmPScjZzYtMTA1JyB5PScxMDIuODE0NTM0Jy8+Cjx1c2UgeD0nMTYyLjYzMDkzMycgeGxpbms6aHJlZj0nI2c2LTExMCcgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzE2OS4xMzQyNTUnIHhsaW5rOmhyZWY9JyNnNS00OCcgeT0nMTA0LjY3NDI0NCcvPgo8dXNlIHg9JzE3My4zNjg0MzgnIHhsaW5rOmhyZWY9JyNnMC01NCcgeT0nMTA0LjY3NDI0NCcvPgo8dXNlIHg9JzE3OS41Njc0MzYnIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9JzEwNC42NzQyNDQnLz4KPHVzZSB4PScxODQuMTg5MDUyJyB4bGluazpocmVmPScjZzAtNTQnIHk9JzEwNC42NzQyNDQnLz4KPHVzZSB4PScxOTAuMzg4MDUnIHhsaW5rOmhyZWY9JyNnMy0xMDgnIHk9JzEwNC42NzQyNDQnLz4KPHVzZSB4PScxOTMuMDEwMTc1JyB4bGluazpocmVmPScjZzUtNDAnIHk9JzEwNC42NzQyNDQnLz4KPHVzZSB4PScxOTYuMzAzNDI4JyB4bGluazpocmVmPScjZzMtMTEzJyB5PScxMDQuNjc0MjQ0Jy8+Cjx1c2UgeD0nMjAwLjM3MDE3OScgeGxpbms6aHJlZj0nI2c1LTQxJyB5PScxMDQuNjc0MjQ0Jy8+Cjx1c2UgeD0nMjA2LjE1NDA2MicgeGxpbms6aHJlZj0nI2cyLTEwMicgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzIxMi4xMzE2NjEnIHhsaW5rOmhyZWY9JyNnNC03NycgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzIyNC43MDUyNjgnIHhsaW5rOmhyZWY9JyNnNi0zNCcgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzIzMC41NTgyNTgnIHhsaW5rOmhyZWY9JyNnNi00MCcgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzIzNS4xMTA1ODQnIHhsaW5rOmhyZWY9JyNnNC0xMTMnIHk9JzEwMi44MTQ1MzQnLz4KPHVzZSB4PScyNDAuNzI5NzQnIHhsaW5rOmhyZWY9JyNnNi05MScgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzI0My45ODE0MDInIHhsaW5rOmhyZWY9JyNnNi00OScgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzI0OS44MzQzOTInIHhsaW5rOmhyZWY9JyNnNC01OCcgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzI1My4wODYwNTMnIHhsaW5rOmhyZWY9JyNnNC01OCcgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzI1Ni4zMzc3MTQnIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9JzEwMi44MTQ1MzQnLz4KPHVzZSB4PScyNjIuODI3MjE4JyB4bGluazpocmVmPScjZzYtOTMnIHk9JzEwMi44MTQ1MzQnLz4KPHVzZSB4PScyNjYuMDc4ODgnIHhsaW5rOmhyZWY9JyNnNC01OScgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzI3MS4zMjMwMzgnIHhsaW5rOmhyZWY9JyNnNC04MycgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzI3OS4yMTgzNjInIHhsaW5rOmhyZWY9JyNnNi00MScgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzI4Ni40MjczNTEnIHhsaW5rOmhyZWY9JyNnNi00MycgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzI5OC4xODg2NjYnIHhsaW5rOmhyZWY9JyNnNC0xNCcgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzMwNi40NzgyODUnIHhsaW5rOmhyZWY9JyNnNi00MycgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzMxOC4yMzk2JyB4bGluazpocmVmPScjZzYtMTA5JyB5PScxMDIuODE0NTM0Jy8+Cjx1c2UgeD0nMzI3Ljk5NDU4NCcgeGxpbms6aHJlZj0nI2c2LTEwNScgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzMzMS4yNDYyNDUnIHhsaW5rOmhyZWY9JyNnNi0xMTAnIHk9JzEwMi44MTQ1MzQnLz4KPHVzZSB4PSczMzcuNzQ5NTY4JyB4bGluazpocmVmPScjZzYtNDAnIHk9JzEwMi44MTQ1MzQnLz4KPHVzZSB4PSczNDIuMzAxODkzJyB4bGluazpocmVmPScjZzQtNzUnIHk9JzEwMi44MTQ1MzQnLz4KPHVzZSB4PSczNTMuMTE5NTczJyB4bGluazpocmVmPScjZzYtNDAnIHk9JzEwMi44MTQ1MzQnLz4KPHVzZSB4PSczNTcuNjcxODk5JyB4bGluazpocmVmPScjZzQtMTEzJyB5PScxMDIuODE0NTM0Jy8+Cjx1c2UgeD0nMzYzLjI5MTA1NScgeGxpbms6aHJlZj0nI2c0LTU5JyB5PScxMDIuODE0NTM0Jy8+Cjx1c2UgeD0nMzY4LjUzNTIxNCcgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzM3NS4wMjQ3MTgnIHhsaW5rOmhyZWY9JyNnNC01OScgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzM4MC4yNjg4NzcnIHhsaW5rOmhyZWY9JyNnNC04MycgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzM4OC4xNjQyJyB4bGluazpocmVmPScjZzYtNDEnIHk9JzEwMi44MTQ1MzQnLz4KPHVzZSB4PSczOTIuNzE2NTI2JyB4bGluazpocmVmPScjZzQtNTknIHk9JzEwMi44MTQ1MzQnLz4KPHVzZSB4PSczOTcuOTYwNjg1JyB4bGluazpocmVmPScjZzQtMTA4JyB5PScxMDIuODE0NTM0Jy8+Cjx1c2UgeD0nNDAxLjcxMDQ5MycgeGxpbms6aHJlZj0nI2c2LTQwJyB5PScxMDIuODE0NTM0Jy8+Cjx1c2UgeD0nNDA2LjI2MjgxOScgeGxpbms6aHJlZj0nI2c0LTExMycgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzQxMS44ODE5NzUnIHhsaW5rOmhyZWY9JyNnNi00MScgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzQxOS4wOTA5NjUnIHhsaW5rOmhyZWY9JyNnMi0wJyB5PScxMDIuODE0NTM0Jy8+Cjx1c2UgeD0nNDMxLjA0NjEyNScgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzQzNy41MzU2MjknIHhsaW5rOmhyZWY9JyNnNi00MScgeT0nMTAyLjgxNDUzNCcvPgo8dXNlIHg9JzQ0Mi4wODc5NTUnIHhsaW5rOmhyZWY9JyNnMi0xMDMnIHk9JzEwMi44MTQ1MzQnLz4KPC9nPgo8L3N2Zz4=)
Définition D2 : Régression quantile
On dispose d’un ensemble de n couples
avec
et . La régression quantile
consiste à trouver tels que la
somme  est minimale.
est minimale.
Définition D2 : couche de neurones
Soit et  deux entiers naturels,
on note
deux entiers naturels,
on note  avec
avec  .
Une couche de neurones et entrées est une fonction :
.
Une couche de neurones et entrées est une fonction :

vérfifiant :
 est un neurone.
est un neurone.
Définition D2 : distance d’édition
La distance d’édition sur  est définie par :
est définie par :

Définition D2 : neurone distance pondérée
Pour un vecteur donné  ,
on note
,
on note  .
Un neurone distance pondérée à entrées est une fonction
.
Un neurone distance pondérée à entrées est une fonction
 définie par :
définie par :
 ,
, 
 avec
avec
Définition D2 : taux de classification à erreur fixe
On cherche un taux de reconnaissance pour un taux d’erreur donné.
On dispose pour cela d’une courbe ROC obtenue par
l’algorithme de la courbe ROC et définie par les points
 .
On suppose ici que
.
On suppose ici que  et
et  .
Si ce n’est pas le cas, on
ajoute ces valeurs à l’ensemble
.
Si ce n’est pas le cas, on
ajoute ces valeurs à l’ensemble  .
.
Pour un taux d’erreur donné  , on cherche
, on cherche  tel que :
tel que :

Le taux de reconnaissance  cherché est donné par :
cherché est donné par :

Définition D3 : distance entre caractères
Soit  l’ensemble des caractères ajouté au caractère vide
l’ensemble des caractères ajouté au caractère vide ..
On note  la fonction coût définie comme suit :
la fonction coût définie comme suit :
(1)#
On note  l’ensemble des suites finies de
l’ensemble des suites finies de  .
.
Définition D3 : réseau de neurones multi-couches ou perceptron
Un réseau de neurones multi-couches à sorties,
entrées et couches est une liste de couches
 connectées les unes aux autres de telle sorte que :
connectées les unes aux autres de telle sorte que :
 ,
chaque couche
,
chaque couche  possède
possède  neurones et
neurones et  entrées
entrées ,
de plus
,
de plus  et
et 
Les coefficients de la couche sont notés
 , cette couche définit une fonction
, cette couche définit une fonction
 .
Soit la suite
.
Soit la suite  définie par :
définie par :

On pose  ,
le réseau de neurones ainsi défini est une fonction
,
le réseau de neurones ainsi défini est une fonction  telle que :
telle que :

Définition D4 : mot acceptable
Soit  un mot tel qu’il est défini précédemment.
Soit
un mot tel qu’il est défini précédemment.
Soit  une suite infinie de caractères, on dit que
une suite infinie de caractères, on dit que
 est un mot acceptable pour
est un mot acceptable pour  si et seulement si la sous-suite
extraite de contenant tous les caractères différents de
si et seulement si la sous-suite
extraite de contenant tous les caractères différents de  est égal au mot . On note
est égal au mot . On note  l’ensemble des mots acceptables pour le mot .
l’ensemble des mots acceptables pour le mot .

Définition D6 : distance d’édition étendue
Soit d^* la distance d’édition définie en 2
pour laquelle les coûts de comparaison, d’insertion et de suppression
sont tous égaux à 1.
La distance d’édition  sur est définie par :
sur est définie par :
(5)#
Définition D7 : distance d’édition tronquée
Soient deux mots  , on définit la suite :
, on définit la suite :

Par :
![\left\{
\begin{array}[c]{l}%
d_{0,0}=0\\
d_{i,j}=\min\left\{
\begin{array}{lll}
d_{i-1,j-1} & + & \text{comparaison} \left( m_1^i,m_2^j\right), \\
d_{i,j-1} & + & \text{insertion} \left( m_2^j\right), \\
d_{i-1,j} & + & \text{suppression} \left( m_1^i\right)
\end{array}
\right\}%
\end{array}
\right.](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nNTcuMzg1MzkxcHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nODguMzc0NDk4IDc5LjA4MDc5NyAyODMuMzI1NzI0IDU3LjM4NTM5MScgd2lkdGg9JzI4My4zMjU3MjRwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNMS40OTA0MTEgLTAuMTE5NTUyQzEuNDkwNDExIDAuMzk4NTA2IDEuMzc4ODI5IDAuODUyODAyIDAuODg0NjgyIDEuMzQ2OTQ5QzAuODUyODAyIDEuMzcwODU5IDAuODM2ODYyIDEuMzg2OCAwLjgzNjg2MiAxLjQyNjY1QzAuODM2ODYyIDEuNDkwNDExIDAuOTAwNjIzIDEuNTM4MjMyIDAuOTU2NDEzIDEuNTM4MjMyQzEuMDUyMDU1IDEuNTM4MjMyIDEuNzEzNTc0IDAuOTA4NTkzIDEuNzEzNTc0IC0wLjAyMzkxQzEuNzEzNTc0IC0wLjUzMzk5OCAxLjUyMjI5MSAtMC44ODQ2ODIgMS4xNzE2MDYgLTAuODg0NjgyQzAuODkyNjUzIC0wLjg4NDY4MiAwLjczMzI1IC0wLjY2MTUxOSAwLjczMzI1IC0wLjQ0NjMyNkMwLjczMzI1IC0wLjIyMzE2MyAwLjg4NDY4MiAwIDEuMTc5NTc3IDBDMS4zNzA4NTkgMCAxLjQ5MDQxMSAtMC4xMTE1ODIgMS40OTA0MTEgLTAuMTE5NTUyWicgaWQ9J2cyLTU5Jy8+CjxwYXRoIGQ9J00yLjM3NTA5MyAtNC45NzMzNUMyLjM3NTA5MyAtNS4xNDg2OTIgMi4yNDc1NzIgLTUuMjc2MjE0IDIuMDY0MjU5IC01LjI3NjIxNEMxLjg1NzAzNiAtNS4yNzYyMTQgMS42MjU5MDMgLTUuMDg0OTMyIDEuNjI1OTAzIC00Ljg0NTgyOEMxLjYyNTkwMyAtNC42NzA0ODYgMS43NTM0MjUgLTQuNTQyOTY0IDEuOTM2NzM3IC00LjU0Mjk2NEMyLjE0Mzk2IC00LjU0Mjk2NCAyLjM3NTA5MyAtNC43MzQyNDcgMi4zNzUwOTMgLTQuOTczMzVaTTEuMjExNDU3IC0yLjA0ODMxOUwwLjc4MTA3MSAtMC45NDg0NDNDMC43NDEyMiAtMC44Mjg4OTIgMC43MDEzNyAtMC43MzMyNSAwLjcwMTM3IC0wLjU5Nzc1OEMwLjcwMTM3IC0wLjIwNzIyMyAxLjAwNDIzNCAwLjA3OTcwMSAxLjQyNjY1IDAuMDc5NzAxQzIuMTk5NzUxIDAuMDc5NzAxIDIuNTI2NTI2IC0xLjAzNjExNSAyLjUyNjUyNiAtMS4xMzk3MjZDMi41MjY1MjYgLTEuMjE5NDI3IDIuNDYyNzY1IC0xLjI0MzMzNyAyLjQwNjk3NCAtMS4yNDMzMzdDMi4zMTEzMzMgLTEuMjQzMzM3IDIuMjk1MzkyIC0xLjE4NzU0NyAyLjI3MTQ4MiAtMS4xMDc4NDZDMi4wODgxNjkgLTAuNDcwMjM3IDEuNzYxMzk1IC0wLjE0MzQ2MiAxLjQ0MjU5IC0wLjE0MzQ2MkMxLjM0Njk0OSAtMC4xNDM0NjIgMS4yNTEzMDggLTAuMTgzMzEzIDEuMjUxMzA4IC0wLjM5ODUwNkMxLjI1MTMwOCAtMC41ODk3ODggMS4zMDcwOTggLTAuNzMzMjUgMS40MTA3MSAtMC45ODAzMjRDMS40OTA0MTEgLTEuMTk1NTE3IDEuNTcwMTEyIC0xLjQxMDcxIDEuNjU3NzgzIC0xLjYyNTkwM0wxLjkwNDg1NyAtMi4yNzE0ODJDMS45NzY1ODggLTIuNDU0Nzk1IDIuMDcyMjI5IC0yLjcwMTg2OCAyLjA3MjIyOSAtMi44MzczNkMyLjA3MjIyOSAtMy4yMzU4NjYgMS43NTM0MjUgLTMuNTE0ODE5IDEuMzQ2OTQ5IC0zLjUxNDgxOUMwLjU3Mzg0OCAtMy41MTQ4MTkgMC4yMzkxMDMgLTIuMzk5MDA0IDAuMjM5MTAzIC0yLjI5NTM5MkMwLjIzOTEwMyAtMi4yMjM2NjEgMC4yOTQ4OTQgLTIuMTkxNzgxIDAuMzU4NjU1IC0yLjE5MTc4MUMwLjQ2MjI2NyAtMi4xOTE3ODEgMC40NzAyMzcgLTIuMjM5NjAxIDAuNDk0MTQ3IC0yLjMxOTMwM0MwLjcxNzMxIC0zLjA3NjQ2MyAxLjA4MzkzNSAtMy4yOTE2NTYgMS4zMjMwMzkgLTMuMjkxNjU2QzEuNDM0NjIgLTMuMjkxNjU2IDEuNTE0MzIxIC0zLjI1MTgwNiAxLjUxNDMyMSAtMy4wMjg2NDNDMS41MTQzMjEgLTIuOTQ4OTQxIDEuNTA2MzUxIC0yLjgzNzM2IDEuNDI2NjUgLTIuNTk4MjU3TDEuMjExNDU3IC0yLjA0ODMxOVonIGlkPSdnMi0xMDUnLz4KPHBhdGggZD0nTTMuMjkxNjU2IC00Ljk3MzM1QzMuMjkxNjU2IC01LjEyNDc4MiAzLjE3MjEwNSAtNS4yNzYyMTQgMi45ODA4MjIgLTUuMjc2MjE0QzIuNzQxNzE5IC01LjI3NjIxNCAyLjUzNDQ5NiAtNS4wNTMwNTEgMi41MzQ0OTYgLTQuODQ1ODI4QzIuNTM0NDk2IC00LjY5NDM5NiAyLjY1NDA0NyAtNC41NDI5NjQgMi44NDUzMyAtNC41NDI5NjRDMy4wODQ0MzMgLTQuNTQyOTY0IDMuMjkxNjU2IC00Ljc2NjEyNyAzLjI5MTY1NiAtNC45NzMzNVpNMS42MjU5MDMgMC4zOTg1MDZDMS41MDYzNTEgMC44ODQ2ODIgMS4xMTU4MTYgMS40MDI3NCAwLjYyOTYzOSAxLjQwMjc0QzAuNTAyMTE3IDEuNDAyNzQgMC4zODI1NjUgMS4zNzA4NTkgMC4zNjY2MjUgMS4zNjI4ODlDMC42MTM2OTkgMS4yNDMzMzcgMC42NDU1NzkgMS4wMjgxNDQgMC42NDU1NzkgMC45NTY0MTNDMC42NDU1NzkgMC43NjUxMzEgMC41MDIxMTcgMC42NjE1MTkgMC4zMzQ3NDUgMC42NjE1MTlDMC4xMDM2MTEgMC42NjE1MTkgLTAuMTExNTgyIDAuODYwNzcyIC0wLjExMTU4MiAxLjEyMzc4NkMtMC4xMTE1ODIgMS40MjY2NSAwLjE4MzMxMyAxLjYyNTkwMyAwLjYzNzYwOSAxLjYyNTkwM0MxLjEyMzc4NiAxLjYyNTkwMyAyLjAwMDQ5OCAxLjMyMzAzOSAyLjIzOTYwMSAwLjM2NjYyNUwyLjk1NjkxMiAtMi40ODY2NzVDMi45ODA4MjIgLTIuNTgyMzE2IDIuOTk2NzYyIC0yLjY0NjA3NyAyLjk5Njc2MiAtMi43NjU2MjlDMi45OTY3NjIgLTMuMjAzOTg1IDIuNjQ2MDc3IC0zLjUxNDgxOSAyLjE4MzgxMSAtMy41MTQ4MTlDMS4zMzg5NzkgLTMuNTE0ODE5IDAuODQ0ODMyIC0yLjM5OTAwNCAwLjg0NDgzMiAtMi4yOTUzOTJDMC44NDQ4MzIgLTIuMjIzNjYxIDAuOTAwNjIzIC0yLjE5MTc4MSAwLjk2NDM4NCAtMi4xOTE3ODFDMS4wNTIwNTUgLTIuMTkxNzgxIDEuMDYwMDI1IC0yLjIxNTY5MSAxLjExNTgxNiAtMi4zMzUyNDNDMS4zNTQ5MTkgLTIuODg1MTgxIDEuNzYxMzk1IC0zLjI5MTY1NiAyLjE1OTkgLTMuMjkxNjU2QzIuMzI3MjczIC0zLjI5MTY1NiAyLjQyMjkxNCAtMy4xODAwNzUgMi40MjI5MTQgLTIuOTE3MDYxQzIuNDIyOTE0IC0yLjgwNTQ3OSAyLjM5OTAwNCAtMi42OTM4OTggMi4zNzUwOTMgLTIuNTgyMzE2TDEuNjI1OTAzIDAuMzk4NTA2WicgaWQ9J2cyLTEwNicvPgo8cGF0aCBkPSdNNS41NzExMDggLTEuODA5MjE1QzUuNjk4NjMgLTEuODA5MjE1IDUuODczOTczIC0xLjgwOTIxNSA1Ljg3Mzk3MyAtMS45OTI1MjhTNS42OTg2MyAtMi4xNzU4NDEgNS41NzExMDggLTIuMTc1ODQxSDEuMDA0MjM0QzAuODc2NzEyIC0yLjE3NTg0MSAwLjcwMTM3IC0yLjE3NTg0MSAwLjcwMTM3IC0xLjk5MjUyOFMwLjg3NjcxMiAtMS44MDkyMTUgMS4wMDQyMzQgLTEuODA5MjE1SDUuNTcxMTA4WicgaWQ9J2cxLTAnLz4KPHBhdGggZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2IC0wLjUzNzk4MyAxLjgxNzE4NiAtMi45NzY4MzdDMS44MTcxODYgLTUuMjk2MTM5IDIuMzc5MDc4IC03LjI5MjY1MyAzLjc2NTg3OCAtOC43MDMzNjJDMy44ODU0MyAtOC44MTA5NTkgMy44ODU0MyAtOC44MzQ4NjkgMy44ODU0MyAtOC44NzA3MzVDMy44ODU0MyAtOC45NDI0NjYgMy44MjU2NTQgLTguOTY2Mzc2IDMuNzc3ODMzIC04Ljk2NjM3NkMzLjYyMjQxNiAtOC45NjYzNzYgMi42NDIwOTIgLTguMTA1NjA0IDIuMDU2Mjg5IC02LjkzMzk5OEMxLjQ0NjU3NSAtNS43MjY1MjYgMS4xNzE2MDYgLTQuNDQ3MzIzIDEuMTcxNjA2IC0yLjk3NjgzN0MxLjE3MTYwNiAtMS45MTI4MjcgMS4zMzg5NzkgLTAuNDkwMTYyIDEuOTYwNjQ4IDAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonIGlkPSdnNS00MCcvPgo8cGF0aCBkPSdNMy4zNzEzNTcgLTIuOTc2ODM3QzMuMzcxMzU3IC0zLjg4NTQzIDMuMjUxODA2IC01LjM2Nzg3IDIuNTgyMzE2IC02Ljc1NDY3QzEuODc2OTYxIC04LjE4OTI5IDAuODk2NjM4IC04Ljk2NjM3NiAwLjc2NTEzMSAtOC45NjYzNzZDMC43MTczMSAtOC45NjYzNzYgMC42NTc1MzQgLTguOTQyNDY2IDAuNjU3NTM0IC04Ljg3MDczNUMwLjY1NzUzNCAtOC44MzQ4NjkgMC42NTc1MzQgLTguODEwOTU5IDAuODYwNzcyIC04LjYwNzcyMUMyLjA1NjI4OSAtNy40MDAyNDkgMi43MjU3NzggLTUuNDI3NjQ2IDIuNzI1Nzc4IC0yLjk4ODc5MkMyLjcyNTc3OCAtMC42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgMC43NzcwODYgMi43Mzc3MzNDMC42NTc1MzQgMi44NDUzMyAwLjY1NzUzNCAyLjg2OTI0IDAuNjU3NTM0IDIuOTA1MTA2QzAuNjU3NTM0IDIuOTc2ODM3IDAuNzE3MzEgMy4wMDA3NDcgMC43NjUxMzEgMy4wMDA3NDdDMC45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgMC45NjgzNjlDMy4wOTYzODkgLTAuMjUxMDU5IDMuMzcxMzU3IC0xLjU0MjIxNyAzLjM3MTM1NyAtMi45NzY4MzdaJyBpZD0nZzUtNDEnLz4KPHBhdGggZD0nTTQuNzcwMTEyIC0yLjc2MTY0NEg4LjA2OTczOEM4LjIzNzExMSAtMi43NjE2NDQgOC40NTIzMDQgLTIuNzYxNjQ0IDguNDUyMzA0IC0yLjk3NjgzN0M4LjQ1MjMwNCAtMy4yMDM5ODUgOC4yNDkwNjYgLTMuMjAzOTg1IDguMDY5NzM4IC0zLjIwMzk4NUg0Ljc3MDExMlYtNi41MDM2MTFDNC43NzAxMTIgLTYuNjcwOTg0IDQuNzcwMTEyIC02Ljg4NjE3NyA0LjU1NDkxOSAtNi44ODYxNzdDNC4zMjc3NzEgLTYuODg2MTc3IDQuMzI3NzcxIC02LjY4MjkzOSA0LjMyNzc3MSAtNi41MDM2MTFWLTMuMjAzOTg1SDEuMDI4MTQ0QzAuODYwNzcyIC0zLjIwMzk4NSAwLjY0NTU3OSAtMy4yMDM5ODUgMC42NDU1NzkgLTIuOTg4NzkyQzAuNjQ1NTc5IC0yLjc2MTY0NCAwLjg0ODgxNyAtMi43NjE2NDQgMS4wMjgxNDQgLTIuNzYxNjQ0SDQuMzI3NzcxVjAuNTM3OTgzQzQuMzI3NzcxIDAuNzA1MzU1IDQuMzI3NzcxIDAuOTIwNTQ4IDQuNTQyOTY0IDAuOTIwNTQ4QzQuNzcwMTEyIDAuOTIwNTQ4IDQuNzcwMTEyIDAuNzE3MzEgNC43NzAxMTIgMC41Mzc5ODNWLTIuNzYxNjQ0WicgaWQ9J2c1LTQzJy8+CjxwYXRoIGQ9J001LjM1NTkxNSAtMy44MjU2NTRDNS4zNTU5MTUgLTQuODE3OTMzIDUuMjk2MTM5IC01Ljc4NjMwMSA0Ljg2NTc1MyAtNi42OTQ4OTRDNC4zNzU1OTIgLTcuNjg3MTczIDMuNTE0ODE5IC03Ljk1MDE4NyAyLjkyOTAxNiAtNy45NTAxODdDMi4yMzU2MTYgLTcuOTUwMTg3IDEuMzg2OCAtNy42MDM0ODcgMC45NDQ0NTggLTYuNjExMjA4QzAuNjA5NzE0IC01Ljg1ODAzMiAwLjQ5MDE2MiAtNS4xMTY4MTIgMC40OTAxNjIgLTMuODI1NjU0QzAuNDkwMTYyIC0yLjY2NjAwMiAwLjU3Mzg0OCAtMS43OTMyNzUgMS4wMDQyMzQgLTAuOTQ0NDU4QzEuNDcwNDg2IC0wLjAzNTg2NiAyLjI5NTM5MiAwLjI1MTA1OSAyLjkxNzA2MSAwLjI1MTA1OUMzLjk1NzE2MSAwLjI1MTA1OSA0LjU1NDkxOSAtMC4zNzA2MSA0LjkwMTYxOSAtMS4wNjQwMUM1LjMzMjAwNSAtMS45NjA2NDggNS4zNTU5MTUgLTMuMTMyMjU0IDUuMzU1OTE1IC0zLjgyNTY1NFpNMi45MTcwNjEgMC4wMTE5NTVDMi41MzQ0OTYgMC4wMTE5NTUgMS43NTc0MSAtMC4yMDMyMzggMS41MzAyNjIgLTEuNTA2MzUxQzEuMzk4NzU1IC0yLjIyMzY2MSAxLjM5ODc1NSAtMy4xMzIyNTQgMS4zOTg3NTUgLTMuOTY5MTE2QzEuMzk4NzU1IC00Ljk0OTQ0IDEuMzk4NzU1IC01LjgzNDEyMiAxLjU5MDAzNyAtNi41Mzk0NzdDMS43OTMyNzUgLTcuMzQwNDczIDIuNDAyOTg5IC03LjcxMTA4MyAyLjkxNzA2MSAtNy43MTEwODNDMy4zNzEzNTcgLTcuNzExMDgzIDQuMDY0NzU3IC03LjQzNjExNSA0LjI5MTkwNSAtNi40MDc5N0M0LjQ0NzMyMyAtNS43MjY1MjYgNC40NDczMjMgLTQuNzgyMDY3IDQuNDQ3MzIzIC0zLjk2OTExNkM0LjQ0NzMyMyAtMy4xNjgxMiA0LjQ0NzMyMyAtMi4yNTk1MjcgNC4zMTU4MTYgLTEuNTMwMjYyQzQuMDg4NjY3IC0wLjIxNTE5MyAzLjMzNTQ5MiAwLjAxMTk1NSAyLjkxNzA2MSAwLjAxMTk1NVonIGlkPSdnNS00OCcvPgo8cGF0aCBkPSdNOC4wNjk3MzggLTMuODczNDc0QzguMjM3MTExIC0zLjg3MzQ3NCA4LjQ1MjMwNCAtMy44NzM0NzQgOC40NTIzMDQgLTQuMDg4NjY3QzguNDUyMzA0IC00LjMxNTgxNiA4LjI0OTA2NiAtNC4zMTU4MTYgOC4wNjk3MzggLTQuMzE1ODE2SDEuMDI4MTQ0QzAuODYwNzcyIC00LjMxNTgxNiAwLjY0NTU3OSAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMTAwNjIzQzAuNjQ1NTc5IC0zLjg3MzQ3NCAwLjg0ODgxNyAtMy44NzM0NzQgMS4wMjgxNDQgLTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOCAtMS42NDk4MTNDOC4yMzcxMTEgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS44NjUwMDZDOC40NTIzMDQgLTIuMDkyMTU0IDguMjQ5MDY2IC0yLjA5MjE1NCA4LjA2OTczOCAtMi4wOTIxNTRIMS4wMjgxNDRDMC44NjA3NzIgLTIuMDkyMTU0IDAuNjQ1NTc5IC0yLjA5MjE1NCAwLjY0NTU3OSAtMS44NzY5NjFDMC42NDU1NzkgLTEuNjQ5ODEzIDAuODQ4ODE3IC0xLjY0OTgxMyAxLjAyODE0NCAtMS42NDk4MTNIOC4wNjk3MzhaJyBpZD0nZzUtNjEnLz4KPHBhdGggZD0nTTQuNjE0Njk1IC0zLjE5MjAzQzQuNjE0Njk1IC0zLjgzNzYwOSA0LjYxNDY5NSAtNC4zMTU4MTYgNC4wODg2NjcgLTQuNzgyMDY3QzMuNjcwMjM3IC01LjE2NDYzMyAzLjEzMjI1NCAtNS4zMzIwMDUgMi42MDYyMjcgLTUuMzMyMDA1QzEuNjI1OTAzIC01LjMzMjAwNSAwLjg3MjcyNyAtNC42ODY0MjYgMC44NzI3MjcgLTMuOTA5MzRDMC44NzI3MjcgLTMuNTYyNjQgMS4wOTk4NzUgLTMuMzk1MjY4IDEuMzc0ODQ0IC0zLjM5NTI2OEMxLjY2MTc2OCAtMy4zOTUyNjggMS44NjUwMDYgLTMuNTk4NTA2IDEuODY1MDA2IC0zLjg4NTQzQzEuODY1MDA2IC00LjM3NTU5MiAxLjQzNDYyIC00LjM3NTU5MiAxLjI1NTI5MyAtNC4zNzU1OTJDMS41MzAyNjIgLTQuODc3NzA5IDIuMTA0MTEgLTUuMDkyOTAyIDIuNTgyMzE2IC01LjA5MjkwMkMzLjEzMjI1NCAtNS4wOTI5MDIgMy44Mzc2MDkgLTQuNjM4NjA1IDMuODM3NjA5IC0zLjU2MjY0Vi0zLjA4NDQzM0MxLjQzNDYyIC0zLjA0ODU2OCAwLjUyNjAyNyAtMi4wNDQzMzQgMC41MjYwMjcgLTEuMTIzNzg2QzAuNTI2MDI3IC0wLjE3OTMyOCAxLjYyNTkwMyAwLjExOTU1MiAyLjM1NTE2OCAwLjExOTU1MkMzLjE0NDIwOSAwLjExOTU1MiAzLjY4MjE5MiAtMC4zNTg2NTUgMy45MDkzNCAtMC45MzI1MDNDMy45NTcxNjEgLTAuMzcwNjEgNC4zMjc3NzEgMC4wNTk3NzYgNC44NDE4NDMgMC4wNTk3NzZDNS4wOTI5MDIgMC4wNTk3NzYgNS43ODYzMDEgLTAuMTA3NTk3IDUuNzg2MzAxIC0xLjA2NDAxVi0xLjczMzQ5OUg1LjUyMzI4OFYtMS4wNjQwMUM1LjUyMzI4OCAtMC4zODI1NjUgNS4yMzYzNjQgLTAuMjg2OTI0IDUuMDY4OTkxIC0wLjI4NjkyNEM0LjYxNDY5NSAtMC4yODY5MjQgNC42MTQ2OTUgLTAuOTIwNTQ4IDQuNjE0Njk1IC0xLjA5OTg3NVYtMy4xOTIwM1pNMy44Mzc2MDkgLTEuNjg1Njc5QzMuODM3NjA5IC0wLjUxNDA3MiAyLjk2NDg4MiAtMC4xMTk1NTIgMi40NTA4MDkgLTAuMTE5NTUyQzEuODY1MDA2IC0wLjExOTU1MiAxLjM3NDg0NCAtMC41NDk5MzggMS4zNzQ4NDQgLTEuMTIzNzg2QzEuMzc0ODQ0IC0yLjcwMTg2OCAzLjQwNzIyMyAtMi44NDUzMyAzLjgzNzYwOSAtMi44NjkyNFYtMS42ODU2NzlaJyBpZD0nZzUtOTcnLz4KPHBhdGggZD0nTTQuMzI3NzcxIC00LjQyMzQxMkM0LjE4NDMwOSAtNC40MjM0MTIgMy43NDE5NjggLTQuNDIzNDEyIDMuNzQxOTY4IC0zLjkzMzI1QzMuNzQxOTY4IC0zLjY0NjMyNiAzLjk0NTIwNSAtMy40NDMwODggNC4yMzIxMyAtMy40NDMwODhDNC41MDcwOTggLTMuNDQzMDg4IDQuNzM0MjQ3IC0zLjYxMDQ2MSA0LjczNDI0NyAtMy45NTcxNjFDNC43MzQyNDcgLTQuNzU4MTU3IDMuODk3Mzg1IC01LjMzMjAwNSAyLjkyOTAxNiAtNS4zMzIwMDVDMS41MzAyNjIgLTUuMzMyMDA1IDAuNDE4NDMxIC00LjA4ODY2NyAwLjQxODQzMSAtMi41ODIzMTZDMC40MTg0MzEgLTEuMDUyMDU1IDEuNTY2MTI3IDAuMTE5NTUyIDIuOTE3MDYxIDAuMTE5NTUyQzQuNDk1MTQzIDAuMTE5NTUyIDQuODUzNzk4IC0xLjMxNTA2OCA0Ljg1Mzc5OCAtMS40MjI2NjVTNC43NzAxMTIgLTEuNTMwMjYyIDQuNzM0MjQ3IC0xLjUzMDI2MkM0LjYyNjY1IC0xLjUzMDI2MiA0LjYxNDY5NSAtMS40OTQzOTYgNC41Nzg4MjkgLTEuMzUwOTM0QzQuMzE1ODE2IC0wLjUwMjExNyAzLjY3MDIzNyAtMC4xNDM0NjIgMy4wMjQ2NTggLTAuMTQzNDYyQzIuMjk1MzkyIC0wLjE0MzQ2MiAxLjMyNzAyNCAtMC43NzcwODYgMS4zMjcwMjQgLTIuNTk0MjcxQzEuMzI3MDI0IC00LjU3ODgyOSAyLjM0MzIxMyAtNS4wNjg5OTEgMi45NDA5NzEgLTUuMDY4OTkxQzMuMzk1MjY4IC01LjA2ODk5MSA0LjA1MjgwMiAtNC44ODk2NjQgNC4zMjc3NzEgLTQuNDIzNDEyWicgaWQ9J2c1LTk5Jy8+CjxwYXRoIGQ9J000LjU3ODgyOSAtMi43NzM1OTlDNC44NDE4NDMgLTIuNzczNTk5IDQuODY1NzUzIC0yLjc3MzU5OSA0Ljg2NTc1MyAtMy4wMDA3NDdDNC44NjU3NTMgLTQuMjA4MjE5IDQuMjIwMTc0IC01LjMzMjAwNSAyLjc3MzU5OSAtNS4zMzIwMDVDMS40MTA3MSAtNS4zMzIwMDUgMC4zNTg2NTUgLTQuMTAwNjIzIDAuMzU4NjU1IC0yLjYxODE4MkMwLjM1ODY1NSAtMS4wNDAxIDEuNTc4MDgyIDAuMTE5NTUyIDIuOTA1MTA2IDAuMTE5NTUyQzQuMzI3NzcxIDAuMTE5NTUyIDQuODY1NzUzIC0xLjE3MTYwNiA0Ljg2NTc1MyAtMS40MjI2NjVDNC44NjU3NTMgLTEuNDk0Mzk2IDQuODA1OTc4IC0xLjU0MjIxNyA0LjczNDI0NyAtMS41NDIyMTdDNC42Mzg2MDUgLTEuNTQyMjE3IDQuNjE0Njk1IC0xLjQ4MjQ0MSA0LjU5MDc4NSAtMS40MjI2NjVDNC4yNzk5NSAtMC40MTg0MzEgMy40Nzg5NTQgLTAuMTQzNDYyIDIuOTc2ODM3IC0wLjE0MzQ2MlMxLjI2NzI0OCAtMC40NzgyMDcgMS4yNjcyNDggLTIuNTQ2NDUxVi0yLjc3MzU5OUg0LjU3ODgyOVpNMS4yNzkyMDMgLTMuMDAwNzQ3QzEuMzc0ODQ0IC00Ljg3NzcwOSAyLjQyNjg5OSAtNS4wOTI5MDIgMi43NjE2NDQgLTUuMDkyOTAyQzQuMDQwODQ3IC01LjA5MjkwMiA0LjExMjU3OCAtMy40MDcyMjMgNC4xMjQ1MzMgLTMuMDAwNzQ3SDEuMjc5MjAzWicgaWQ9J2c1LTEwMScvPgo8cGF0aCBkPSdNMi4wODAxOTkgLTcuMzY0Mzg0QzIuMDgwMTk5IC03LjY3NTIxOCAxLjgyOTE0MSAtNy45NTAxODcgMS40OTQzOTYgLTcuOTUwMTg3QzEuMTgzNTYyIC03Ljk1MDE4NyAwLjkyMDU0OCAtNy42OTkxMjggMC45MjA1NDggLTcuMzc2MzM5QzAuOTIwNTQ4IC03LjAxNzY4NCAxLjIwNzQ3MiAtNi43OTA1MzUgMS40OTQzOTYgLTYuNzkwNTM1QzEuODY1MDA2IC02Ljc5MDUzNSAyLjA4MDE5OSAtNy4xMDEzNyAyLjA4MDE5OSAtNy4zNjQzODRaTTAuNDMwMzg2IC01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTcgLTQuNzk0MDIyIDEuMzAzMTEzIC00LjcyMjI5MSAxLjMwMzExMyAtNC4xMzY0ODhWLTAuODg0NjgyQzEuMzAzMTEzIC0wLjM0NjcgMS4xNzE2MDYgLTAuMzQ2NyAwLjM5NDUyMSAtMC4zNDY3VjBDMC43MjkyNjUgLTAuMDIzOTEgMS4zMDMxMTMgLTAuMDIzOTEgMS42NDk4MTMgLTAuMDIzOTFDMS43ODEzMiAtMC4wMjM5MSAyLjQ3NDcyIC0wLjAyMzkxIDIuODgxMTk2IDBWLTAuMzQ2N0MyLjEwNDExIC0wLjM0NjcgMi4wNTYyODkgLTAuNDA2NDc2IDIuMDU2Mjg5IC0wLjg3MjcyN1YtNS4yNzIyMjlMMC40MzAzODYgLTUuMTQwNzIyWicgaWQ9J2c1LTEwNScvPgo8cGF0aCBkPSdNOC41NzE4NTYgLTIuOTA1MTA2QzguNTcxODU2IC00LjAxNjkzNiA4LjU3MTg1NiAtNC4zNTE2ODEgOC4yOTY4ODcgLTQuNzM0MjQ3QzcuOTUwMTg3IC01LjIwMDQ5OCA3LjM4ODI5NCAtNS4yNzIyMjkgNi45ODE4MTggLTUuMjcyMjI5QzUuOTg5NTM5IC01LjI3MjIyOSA1LjQ4NzQyMiAtNC41NTQ5MTkgNS4yOTYxMzkgLTQuMDg4NjY3QzUuMTI4NzY3IC01LjAwOTIxNSA0LjQ4MzE4OCAtNS4yNzIyMjkgMy43MzAwMTIgLTUuMjcyMjI5QzIuNTcwMzYxIC01LjI3MjIyOSAyLjExNjA2NSAtNC4yNzk5NSAyLjAyMDQyMyAtNC4wNDA4NDdIMi4wMDg0NjhWLTUuMjcyMjI5TDAuMzgyNTY1IC01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTcgLTQuNzk0MDIyIDEuMjkxMTU4IC00LjcxMDMzNiAxLjI5MTE1OCAtNC4xMjQ1MzNWLTAuODg0NjgyQzEuMjkxMTU4IC0wLjM0NjcgMS4xNTk2NTEgLTAuMzQ2NyAwLjM4MjU2NSAtMC4zNDY3VjBDMC42OTM0IC0wLjAyMzkxIDEuMzM4OTc5IC0wLjAyMzkxIDEuNjczNzI0IC0wLjAyMzkxQzIuMDIwNDIzIC0wLjAyMzkxIDIuNjY2MDAyIC0wLjAyMzkxIDIuOTc2ODM3IDBWLTAuMzQ2N0MyLjIxMTcwNiAtMC4zNDY3IDIuMDY4MjQ0IC0wLjM0NjcgMi4wNjgyNDQgLTAuODg0NjgyVi0zLjEwODM0NEMyLjA2ODI0NCAtNC4zNjM2MzYgMi44OTMxNTEgLTUuMDMzMTI2IDMuNjM0MzcxIC01LjAzMzEyNlM0LjU0Mjk2NCAtNC40MjM0MTIgNC41NDI5NjQgLTMuNjk0MTQ3Vi0wLjg4NDY4MkM0LjU0Mjk2NCAtMC4zNDY3IDQuNDExNDU3IC0wLjM0NjcgMy42MzQzNzEgLTAuMzQ2N1YwQzMuOTQ1MjA1IC0wLjAyMzkxIDQuNTkwNzg1IC0wLjAyMzkxIDQuOTI1NTI5IC0wLjAyMzkxQzUuMjcyMjI5IC0wLjAyMzkxIDUuOTE3ODA4IC0wLjAyMzkxIDYuMjI4NjQzIDBWLTAuMzQ2N0M1LjQ2MzUxMiAtMC4zNDY3IDUuMzIwMDUgLTAuMzQ2NyA1LjMyMDA1IC0wLjg4NDY4MlYtMy4xMDgzNDRDNS4zMjAwNSAtNC4zNjM2MzYgNi4xNDQ5NTYgLTUuMDMzMTI2IDYuODg2MTc3IC01LjAzMzEyNlM3Ljc5NDc3IC00LjQyMzQxMiA3Ljc5NDc3IC0zLjY5NDE0N1YtMC44ODQ2ODJDNy43OTQ3NyAtMC4zNDY3IDcuNjYzMjYzIC0wLjM0NjcgNi44ODYxNzcgLTAuMzQ2N1YwQzcuMTk3MDExIC0wLjAyMzkxIDcuODQyNTkgLTAuMDIzOTEgOC4xNzczMzUgLTAuMDIzOTFDOC41MjQwMzUgLTAuMDIzOTEgOS4xNjk2MTQgLTAuMDIzOTEgOS40ODA0NDggMFYtMC4zNDY3QzguODgyNjkgLTAuMzQ2NyA4LjU4MzgxMSAtMC4zNDY3IDguNTcxODU2IC0wLjcwNTM1NVYtMi45MDUxMDZaJyBpZD0nZzUtMTA5Jy8+CjxwYXRoIGQ9J001LjMyMDA1IC0yLjkwNTEwNkM1LjMyMDA1IC00LjAxNjkzNiA1LjMyMDA1IC00LjM1MTY4MSA1LjA0NTA4MSAtNC43MzQyNDdDNC42OTgzODEgLTUuMjAwNDk4IDQuMTM2NDg4IC01LjI3MjIyOSAzLjczMDAxMiAtNS4yNzIyMjlDMi41NzAzNjEgLTUuMjcyMjI5IDIuMTE2MDY1IC00LjI3OTk1IDIuMDIwNDIzIC00LjA0MDg0N0gyLjAwODQ2OFYtNS4yNzIyMjlMMC4zODI1NjUgLTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE5NTUxNyAtNC43OTQwMjIgMS4yOTExNTggLTQuNzEwMzM2IDEuMjkxMTU4IC00LjEyNDUzM1YtMC44ODQ2ODJDMS4yOTExNTggLTAuMzQ2NyAxLjE1OTY1MSAtMC4zNDY3IDAuMzgyNTY1IC0wLjM0NjdWMEMwLjY5MzQgLTAuMDIzOTEgMS4zMzg5NzkgLTAuMDIzOTEgMS42NzM3MjQgLTAuMDIzOTFDMi4wMjA0MjMgLTAuMDIzOTEgMi42NjYwMDIgLTAuMDIzOTEgMi45NzY4MzcgMFYtMC4zNDY3QzIuMjExNzA2IC0wLjM0NjcgMi4wNjgyNDQgLTAuMzQ2NyAyLjA2ODI0NCAtMC44ODQ2ODJWLTMuMTA4MzQ0QzIuMDY4MjQ0IC00LjM2MzYzNiAyLjg5MzE1MSAtNS4wMzMxMjYgMy42MzQzNzEgLTUuMDMzMTI2UzQuNTQyOTY0IC00LjQyMzQxMiA0LjU0Mjk2NCAtMy42OTQxNDdWLTAuODg0NjgyQzQuNTQyOTY0IC0wLjM0NjcgNC40MTE0NTcgLTAuMzQ2NyAzLjYzNDM3MSAtMC4zNDY3VjBDMy45NDUyMDUgLTAuMDIzOTEgNC41OTA3ODUgLTAuMDIzOTEgNC45MjU1MjkgLTAuMDIzOTFDNS4yNzIyMjkgLTAuMDIzOTEgNS45MTc4MDggLTAuMDIzOTEgNi4yMjg2NDMgMFYtMC4zNDY3QzUuNjMwODg0IC0wLjM0NjcgNS4zMzIwMDUgLTAuMzQ2NyA1LjMyMDA1IC0wLjcwNTM1NVYtMi45MDUxMDZaJyBpZD0nZzUtMTEwJy8+CjxwYXRoIGQ9J001LjQ4NzQyMiAtMi41NTg0MDZDNS40ODc0MjIgLTQuMTAwNjIzIDQuMzE1ODE2IC01LjMzMjAwNSAyLjkyOTAxNiAtNS4zMzIwMDVDMS40OTQzOTYgLTUuMzMyMDA1IDAuMzU4NjU1IC00LjA2NDc1NyAwLjM1ODY1NSAtMi41NTg0MDZDMC4zNTg2NTUgLTEuMDI4MTQ0IDEuNTU0MTcyIDAuMTE5NTUyIDIuOTE3MDYxIDAuMTE5NTUyQzQuMzI3NzcxIDAuMTE5NTUyIDUuNDg3NDIyIC0xLjA1MjA1NSA1LjQ4NzQyMiAtMi41NTg0MDZaTTIuOTI5MDE2IC0wLjE0MzQ2MkMyLjQ4NjY3NSAtMC4xNDM0NjIgMS45NDg2OTIgLTAuMzM0NzQ1IDEuNjAxOTkzIC0wLjkyMDU0OEMxLjI3OTIwMyAtMS40NTg1MzEgMS4yNjcyNDggLTIuMTYzODg1IDEuMjY3MjQ4IC0yLjY2NjAwMkMxLjI2NzI0OCAtMy4xMjAyOTkgMS4yNjcyNDggLTMuODQ5NTY0IDEuNjM3ODU4IC00LjM4NzU0N0MxLjk3MjYwMyAtNC45MDE2MTkgMi40OTg2MyAtNS4wOTI5MDIgMi45MTcwNjEgLTUuMDkyOTAyQzMuMzgzMzEzIC01LjA5MjkwMiAzLjg4NTQzIC00Ljg3NzcwOSA0LjIwODIxOSAtNC40MTE0NTdDNC41Nzg4MjkgLTMuODYxNTE5IDQuNTc4ODI5IC0zLjEwODM0NCA0LjU3ODgyOSAtMi42NjYwMDJDNC41Nzg4MjkgLTIuMjQ3NTcyIDQuNTc4ODI5IC0xLjUwNjM1MSA0LjI2Nzk5NSAtMC45NDQ0NThDMy45MzMyNSAtMC4zNzA2MSAzLjM4MzMxMyAtMC4xNDM0NjIgMi45MjkwMTYgLTAuMTQzNDYyWicgaWQ9J2c1LTExMScvPgo8cGF0aCBkPSdNMi45MjkwMTYgMS45NzI2MDNDMi4xNjM4ODUgMS45NzI2MDMgMi4wMjA0MjMgMS45NzI2MDMgMi4wMjA0MjMgMS40MzQ2MlYtMC42NDU1NzlDMi4yMzU2MTYgLTAuMzQ2NyAyLjcyNTc3OCAwLjExOTU1MiAzLjQ5MDkwOSAwLjExOTU1MkM0Ljg2NTc1MyAwLjExOTU1MiA2LjA3MzIyNSAtMS4wNDAxIDYuMDczMjI1IC0yLjU4MjMxNkM2LjA3MzIyNSAtNC4xMDA2MjMgNC45NDk0NCAtNS4yNzIyMjkgMy42NDYzMjYgLTUuMjcyMjI5QzIuNTk0MjcxIC01LjI3MjIyOSAyLjAzMjM3OSAtNC41MTkwNTQgMS45OTY1MTMgLTQuNDcxMjMzVi01LjI3MjIyOUwwLjMzNDc0NSAtNS4xNDA3MjJWLTQuNzk0MDIyQzEuMTcxNjA2IC00Ljc5NDAyMiAxLjI0MzMzNyAtNC43MTAzMzYgMS4yNDMzMzcgLTQuMTg0MzA5VjEuNDM0NjJDMS4yNDMzMzcgMS45NzI2MDMgMS4xMTE4MzEgMS45NzI2MDMgMC4zMzQ3NDUgMS45NzI2MDNWMi4zMTkzMDNDMC42NDU1NzkgMi4yOTUzOTIgMS4yOTExNTggMi4yOTUzOTIgMS42MjU5MDMgMi4yOTUzOTJDMS45NzI2MDMgMi4yOTUzOTIgMi42MTgxODIgMi4yOTUzOTIgMi45MjkwMTYgMi4zMTkzMDNWMS45NzI2MDNaTTIuMDIwNDIzIC0zLjgxMzY5OUMyLjAyMDQyMyAtNC4wNDA4NDcgMi4wMjA0MjMgLTQuMDUyODAyIDIuMTUxOTMgLTQuMjQ0MDg1QzIuNTEwNTg1IC00Ljc4MjA2NyAzLjA5NjM4OSAtNS4wMDkyMTUgMy41NTA2ODUgLTUuMDA5MjE1QzQuNDQ3MzIzIC01LjAwOTIxNSA1LjE2NDYzMyAtMy45MjEyOTUgNS4xNjQ2MzMgLTIuNTgyMzE2QzUuMTY0NjMzIC0xLjE1OTY1MSA0LjM1MTY4MSAtMC4xMTk1NTIgMy40MzExMzMgLTAuMTE5NTUyQzMuMDYwNTIzIC0wLjExOTU1MiAyLjcxMzgyMyAtMC4yNzQ5NjkgMi40NzQ3MiAtMC41MDIxMTdDMi4xOTk3NTEgLTAuNzc3MDg2IDIuMDIwNDIzIC0xLjAxNjE4OSAyLjAyMDQyMyAtMS4zNTA5MzRWLTMuODEzNjk5WicgaWQ9J2c1LTExMicvPgo8cGF0aCBkPSdNMS45OTY1MTMgLTIuNzg1NTU0QzEuOTk2NTEzIC0zLjk0NTIwNSAyLjQ3NDcyIC01LjAzMzEyNiAzLjM5NTI2OCAtNS4wMzMxMjZDMy40OTA5MDkgLTUuMDMzMTI2IDMuNTE0ODE5IC01LjAzMzEyNiAzLjU2MjY0IC01LjAyMTE3MUMzLjQ2Njk5OSAtNC45NzMzNSAzLjI3NTcxNiAtNC45MDE2MTkgMy4yNzU3MTYgLTQuNTc4ODI5QzMuMjc1NzE2IC00LjIzMjEzIDMuNTUwNjg1IC00LjEwMDYyMyAzLjc0MTk2OCAtNC4xMDA2MjNDMy45ODEwNzEgLTQuMTAwNjIzIDQuMjIwMTc0IC00LjI1NjA0IDQuMjIwMTc0IC00LjU3ODgyOUM0LjIyMDE3NCAtNC45Mzc0ODQgMy44OTczODUgLTUuMjcyMjI5IDMuMzgzMzEzIC01LjI3MjIyOUMyLjM2NzEyMyAtNS4yNzIyMjkgMi4wMjA0MjMgLTQuMTcyMzU0IDEuOTQ4NjkyIC0zLjk0NTIwNUgxLjkzNjczN1YtNS4yNzIyMjlMMC4zMzQ3NDUgLTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE0NzY5NiAtNC43OTQwMjIgMS4yNDMzMzcgLTQuNzEwMzM2IDEuMjQzMzM3IC00LjEyNDUzM1YtMC44ODQ2ODJDMS4yNDMzMzcgLTAuMzQ2NyAxLjExMTgzMSAtMC4zNDY3IDAuMzM0NzQ1IC0wLjM0NjdWMEMwLjY2OTQ4OSAtMC4wMjM5MSAxLjMyNzAyNCAtMC4wMjM5MSAxLjY4NTY3OSAtMC4wMjM5MUMyLjAwODQ2OCAtMC4wMjM5MSAyLjg1NzI4NSAtMC4wMjM5MSAzLjEzMjI1NCAwVi0wLjM0NjdIMi44OTMxNTFDMi4wMjA0MjMgLTAuMzQ2NyAxLjk5NjUxMyAtMC40NzgyMDcgMS45OTY1MTMgLTAuOTA4NTkzVi0yLjc4NTU1NFonIGlkPSdnNS0xMTQnLz4KPHBhdGggZD0nTTMuOTIxMjk1IC01LjA1NzAzNkMzLjkyMTI5NSAtNS4yNzIyMjkgMy45MjEyOTUgLTUuMzMyMDA1IDMuODAxNzQzIC01LjMzMjAwNUMzLjcwNjEwMiAtNS4zMzIwMDUgMy40Nzg5NTQgLTUuMDY4OTkxIDMuMzk1MjY4IC00Ljk2MTM5NUMzLjAyNDY1OCAtNS4yNjAyNzQgMi42NTQwNDcgLTUuMzMyMDA1IDIuMjcxNDgyIC01LjMzMjAwNUMwLjgyNDkwNyAtNS4zMzIwMDUgMC4zOTQ1MjEgLTQuNTQyOTY0IDAuMzk0NTIxIC0zLjg4NTQzQzAuMzk0NTIxIC0zLjc1MzkyMyAwLjM5NDUyMSAtMy4zMzU0OTIgMC44NDg4MTcgLTIuOTE3MDYxQzEuMjMxMzgyIC0yLjU4MjMxNiAxLjYzNzg1OCAtMi40OTg2MyAyLjE4Nzc5NiAtMi4zOTEwMzRDMi44NDUzMyAtMi4yNTk1MjcgMy4wMDA3NDcgLTIuMjIzNjYxIDMuMjk5NjI2IC0xLjk4NDU1OEMzLjUxNDgxOSAtMS44MDUyMyAzLjY3MDIzNyAtMS41NDIyMTcgMy42NzAyMzcgLTEuMjA3NDcyQzMuNjcwMjM3IC0wLjY5MzQgMy4zNzEzNTcgLTAuMTE5NTUyIDIuMzE5MzAzIC0wLjExOTU1MkMxLjUzMDI2MiAtMC4xMTk1NTIgMC45NTY0MTMgLTAuNTczODQ4IDAuNjkzNCAtMS43NjkzNjVDMC42NDU1NzkgLTEuOTg0NTU4IDAuNjQ1NTc5IC0xLjk5NjUxMyAwLjYzMzYyNCAtMi4wMDg0NjhDMC42MDk3MTQgLTIuMDU2Mjg5IDAuNTYxODkzIC0yLjA1NjI4OSAwLjUyNjAyNyAtMi4wNTYyODlDMC4zOTQ1MjEgLTIuMDU2Mjg5IDAuMzk0NTIxIC0xLjk5NjUxMyAwLjM5NDUyMSAtMS43ODEzMlYtMC4xNTU0MTdDMC4zOTQ1MjEgMC4wNTk3NzYgMC4zOTQ1MjEgMC4xMTk1NTIgMC41MTQwNzIgMC4xMTk1NTJDMC41NzM4NDggMC4xMTk1NTIgMC41ODU4MDMgMC4xMDc1OTcgMC43ODkwNDEgLTAuMTQzNDYyQzAuODQ4ODE3IC0wLjIyNzE0OCAwLjg0ODgxNyAtMC4yNTEwNTkgMS4wMjgxNDQgLTAuNDQyMzQxQzEuNDgyNDQxIDAuMTE5NTUyIDIuMTI4MDIgMC4xMTk1NTIgMi4zMzEyNTggMC4xMTk1NTJDMy41ODY1NSAwLjExOTU1MiA0LjIwODIxOSAtMC41NzM4NDggNC4yMDgyMTkgLTEuNTE4MzA2QzQuMjA4MjE5IC0yLjE2Mzg4NSAzLjgxMzY5OSAtMi41NDY0NTEgMy43MDYxMDIgLTIuNjU0MDQ3QzMuMjc1NzE2IC0zLjAyNDY1OCAyLjk1MjkyNyAtMy4wOTYzODkgMi4xNjM4ODUgLTMuMjM5ODUxQzEuODA1MjMgLTMuMzExNTgyIDAuOTMyNTAzIC0zLjQ3ODk1NCAwLjkzMjUwMyAtNC4xOTYyNjRDMC45MzI1MDMgLTQuNTY2ODc0IDEuMTgzNTYyIC01LjExNjgxMiAyLjI1OTUyNyAtNS4xMTY4MTJDMy41NjI2NCAtNS4xMTY4MTIgMy42MzQzNzEgLTQuMDA0OTgxIDMuNjU4MjgxIC0zLjYzNDM3MUMzLjY3MDIzNyAtMy41Mzg3MyAzLjc1MzkyMyAtMy41Mzg3MyAzLjc4OTc4OCAtMy41Mzg3M0MzLjkyMTI5NSAtMy41Mzg3MyAzLjkyMTI5NSAtMy41OTg1MDYgMy45MjEyOTUgLTMuODEzNjk5Vi01LjA1NzAzNlonIGlkPSdnNS0xMTUnLz4KPHBhdGggZD0nTTIuMDA4NDY4IC00LjgwNTk3OEgzLjY5NDE0N1YtNS4xNTI2NzdIMi4wMDg0NjhWLTcuMzUyNDI4SDEuNzQ1NDU1QzEuNzMzNDk5IC02LjIyODY0MyAxLjMwMzExMyAtNS4wODA5NDYgMC4yMTUxOTMgLTUuMDQ1MDgxVi00LjgwNTk3OEgxLjIzMTM4MlYtMS40ODI0NDFDMS4yMzEzODIgLTAuMTU1NDE3IDIuMTE2MDY1IDAuMTE5NTUyIDIuNzQ5Njg5IDAuMTE5NTUyQzMuNTAyODY0IDAuMTE5NTUyIDMuODk3Mzg1IC0wLjYyMTY2OSAzLjg5NzM4NSAtMS40ODI0NDFWLTIuMTYzODg1SDMuNjM0MzcxVi0xLjUwNjM1MUMzLjYzNDM3MSAtMC42NDU1NzkgMy4yODc2NzEgLTAuMTQzNDYyIDIuODIxNDIgLTAuMTQzNDYyQzIuMDA4NDY4IC0wLjE0MzQ2MiAyLjAwODQ2OCAtMS4yNTUyOTMgMi4wMDg0NjggLTEuNDU4NTMxVi00LjgwNTk3OFonIGlkPSdnNS0xMTYnLz4KPHBhdGggZD0nTTMuNjM0MzcxIC01LjE0MDcyMlYtNC43OTQwMjJDNC40NDczMjMgLTQuNzk0MDIyIDQuNTQyOTY0IC00LjcxMDMzNiA0LjU0Mjk2NCAtNC4xMjQ1MzNWLTEuOTg0NTU4QzQuNTQyOTY0IC0wLjk2ODM2OSA0LjAwNDk4MSAtMC4xMTk1NTIgMy4xMDgzNDQgLTAuMTE5NTUyQzIuMTI4MDIgLTAuMTE5NTUyIDIuMDY4MjQ0IC0wLjY4MTQ0NSAyLjA2ODI0NCAtMS4zMTUwNjhWLTUuMjcyMjI5TDAuMzgyNTY1IC01LjE0MDcyMlYtNC43OTQwMjJDMS4yOTExNTggLTQuNzk0MDIyIDEuMjkxMTU4IC00Ljc1ODE1NyAxLjI5MTE1OCAtMy42OTQxNDdWLTEuOTAwODcyQzEuMjkxMTU4IC0xLjE1OTY1MSAxLjI5MTE1OCAtMC43MjkyNjUgMS42NDk4MTMgLTAuMzM0NzQ1QzEuOTM2NzM3IC0wLjAyMzkxIDIuNDI2ODk5IDAuMTE5NTUyIDMuMDM2NjEzIDAuMTE5NTUyQzMuMjM5ODUxIDAuMTE5NTUyIDMuNjIyNDE2IDAuMTE5NTUyIDQuMDI4ODkyIC0wLjIyNzE0OEM0LjM3NTU5MiAtMC41MDIxMTcgNC41NjY4NzQgLTAuOTU2NDEzIDQuNTY2ODc0IC0wLjk1NjQxM1YwLjExOTU1Mkw2LjIyODY0MyAwVi0wLjM0NjdDNS40MTU2OTEgLTAuMzQ2NyA1LjMyMDA1IC0wLjQzMDM4NiA1LjMyMDA1IC0xLjAxNjE4OVYtNS4yNzIyMjlMMy42MzQzNzEgLTUuMTQwNzIyWicgaWQ9J2c1LTExNycvPgo8cGF0aCBkPSdNMy44OTczODUgLTIuNTQyNDY2QzMuODk3Mzg1IC0zLjM5NTI2OCAzLjgwOTcxNCAtMy45MTMzMjUgMy41NDY3IC00LjQyMzQxMkMzLjE5NjAxNSAtNS4xMjQ3ODIgMi41NTA0MzYgLTUuMzAwMTI1IDIuMTEyMDggLTUuMzAwMTI1QzEuMTA3ODQ2IC01LjMwMDEyNSAwLjc0MTIyIC00LjU1MDkzNCAwLjYyOTYzOSAtNC4zMjc3NzFDMC4zNDI3MTUgLTMuNzQ1OTUzIDAuMzI2Nzc1IC0yLjk1NjkxMiAwLjMyNjc3NSAtMi41NDI0NjZDMC4zMjY3NzUgLTIuMDE2NDM4IDAuMzUwNjg1IC0xLjIxMTQ1NyAwLjczMzI1IC0wLjU3Mzg0OEMxLjA5OTg3NSAwLjAxNTk0IDEuNjg5NjY0IDAuMTY3MzcyIDIuMTEyMDggMC4xNjczNzJDMi40OTQ2NDUgMC4xNjczNzIgMy4xODAwNzUgMC4wNDc4MjEgMy41Nzg1OCAtMC43NDEyMkMzLjg3MzQ3NCAtMS4zMTUwNjggMy44OTczODUgLTIuMDI0NDA4IDMuODk3Mzg1IC0yLjU0MjQ2NlpNMi4xMTIwOCAtMC4wNTU3OTFDMS44NDEwOTYgLTAuMDU1NzkxIDEuMjkxMTU4IC0wLjE4MzMxMyAxLjEyMzc4NiAtMS4wMjAxNzRDMS4wMzYxMTUgLTEuNDc0NDcxIDEuMDM2MTE1IC0yLjIyMzY2MSAxLjAzNjExNSAtMi42MzgxMDdDMS4wMzYxMTUgLTMuMTg4MDQ1IDEuMDM2MTE1IC0zLjc0NTk1MyAxLjEyMzc4NiAtNC4xODQzMDlDMS4yOTExNTggLTQuOTk3MjYgMS45MTI4MjcgLTUuMDc2OTYxIDIuMTEyMDggLTUuMDc2OTYxQzIuMzgzMDY0IC01LjA3Njk2MSAyLjkzMzAwMSAtNC45NDE0NjkgMy4wOTI0MDMgLTQuMjE2MTg5QzMuMTg4MDQ1IC0zLjc3NzgzMyAzLjE4ODA0NSAtMy4xODAwNzUgMy4xODgwNDUgLTIuNjM4MTA3QzMuMTg4MDQ1IC0yLjE2Nzg3IDMuMTg4MDQ1IC0xLjQ1MDU2IDMuMDkyNDAzIC0xLjAwNDIzNEMyLjkyNTAzMSAtMC4xNjczNzIgMi4zNzUwOTMgLTAuMDU1NzkxIDIuMTEyMDggLTAuMDU1NzkxWicgaWQ9J2c0LTQ4Jy8+CjxwYXRoIGQ9J00yLjUwMjYxNSAtNS4wNzY5NjFDMi41MDI2MTUgLTUuMjkyMTU0IDIuNDg2Njc1IC01LjMwMDEyNSAyLjI3MTQ4MiAtNS4zMDAxMjVDMS45NDQ3MDcgLTQuOTgxMzIgMS41MjIyOTEgLTQuNzkwMDM3IDAuNzY1MTMxIC00Ljc5MDAzN1YtNC41MjcwMjRDMC45ODAzMjQgLTQuNTI3MDI0IDEuNDEwNzEgLTQuNTI3MDI0IDEuODcyOTc2IC00Ljc0MjIxN1YtMC42NTM1NDlDMS44NzI5NzYgLTAuMzU4NjU1IDEuODQ5MDY2IC0wLjI2MzAxNCAxLjA5MTkwNSAtMC4yNjMwMTRIMC44MTI5NTFWMEMxLjEzOTcyNiAtMC4wMjM5MSAxLjgyNTE1NiAtMC4wMjM5MSAyLjE4MzgxMSAtMC4wMjM5MVMzLjIzNTg2NiAtMC4wMjM5MSAzLjU2MjY0IDBWLTAuMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2IC0wLjI2MzAxNCAyLjUwMjYxNSAtMC4zNTg2NTUgMi41MDI2MTUgLTAuNjUzNTQ5Vi01LjA3Njk2MVonIGlkPSdnNC00OScvPgo8cGF0aCBkPSdNMi4yNDc1NzIgLTEuNjI1OTAzQzIuMzc1MDkzIC0xLjc0NTQ1NSAyLjcwOTgzOCAtMi4wMDg0NjggMi44MzczNiAtMi4xMjAwNUMzLjMzMTUwNyAtMi41NzQzNDYgMy44MDE3NDMgLTMuMDEyNzAyIDMuODAxNzQzIC0zLjczNzk4M0MzLjgwMTc0MyAtNC42ODY0MjYgMy4wMDQ3MzIgLTUuMzAwMTI1IDIuMDA4NDY4IC01LjMwMDEyNUMxLjA1MjA1NSAtNS4zMDAxMjUgMC40MjI0MTYgLTQuNTc0ODQ0IDAuNDIyNDE2IC0zLjg2NTUwNEMwLjQyMjQxNiAtMy40NzQ5NjkgMC43MzMyNSAtMy40MTkxNzggMC44NDQ4MzIgLTMuNDE5MTc4QzEuMDEyMjA0IC0zLjQxOTE3OCAxLjI1OTI3OCAtMy41Mzg3MyAxLjI1OTI3OCAtMy44NDE1OTRDMS4yNTkyNzggLTQuMjU2MDQgMC44NjA3NzIgLTQuMjU2MDQgMC43NjUxMzEgLTQuMjU2MDRDMC45OTYyNjQgLTQuODM3ODU4IDEuNTMwMjYyIC01LjAzNzExMSAxLjkyMDc5NyAtNS4wMzcxMTFDMi42NjIwMTcgLTUuMDM3MTExIDMuMDQ0NTgzIC00LjQwNzQ3MiAzLjA0NDU4MyAtMy43Mzc5ODNDMy4wNDQ1ODMgLTIuOTA5MDkxIDIuNDYyNzY1IC0yLjMwMzM2MiAxLjUyMjI5MSAtMS4zMzg5NzlMMC41MTgwNTcgLTAuMzAyODY0QzAuNDIyNDE2IC0wLjIxNTE5MyAwLjQyMjQxNiAtMC4xOTkyNTMgMC40MjI0MTYgMEgzLjU3MDYxTDMuODAxNzQzIC0xLjQyNjY1SDMuNTU0NjdDMy41MzA3NiAtMS4yNjcyNDggMy40NjY5OTkgLTAuODY4NzQyIDMuMzcxMzU3IC0wLjcxNzMxQzMuMzIzNTM3IC0wLjY1MzU0OSAyLjcxNzgwOCAtMC42NTM1NDkgMi41OTAyODYgLTAuNjUzNTQ5SDEuMTcxNjA2TDIuMjQ3NTcyIC0xLjYyNTkwM1onIGlkPSdnNC01MCcvPgo8cGF0aCBkPSdNNC45Mzc0ODQgMTMuNzM2NDg4QzQuOTM3NDg0IDEzLjY4ODY2NyA0LjkxMzU3NCAxMy42NjQ3NTcgNC44ODk2NjQgMTMuNjI4ODkyQzQuMzM5NzI2IDEzLjA0MzA4OCAzLjUyNjc3NSAxMi4wNzQ3MiAzLjAyNDY1OCAxMC4xMjYwMjdDMi43NDk2ODkgOS4wMzgxMDcgMi42NDIwOTIgNy44MDY3MjUgMi42NDIwOTIgNi42OTQ4OTRDMi42NDIwOTIgMy41NTA2ODUgMy4zOTUyNjggMS4zNTA5MzQgNC44Mjk4ODggLTAuMjAzMjM4QzQuOTM3NDg0IC0wLjMxMDgzNCA0LjkzNzQ4NCAtMC4zMzQ3NDUgNC45Mzc0ODQgLTAuMzU4NjU1QzQuOTM3NDg0IC0wLjQ3ODIwNyA0Ljg0MTg0MyAtMC40NzgyMDcgNC43OTQwMjIgLTAuNDc4MjA3QzQuNjE0Njk1IC0wLjQ3ODIwNyAzLjk2OTExNiAwLjIzOTEwMyAzLjgxMzY5OSAwLjQxODQzMUMyLjU5NDI3MSAxLjg2NTAwNiAxLjgxNzE4NiA0LjAxNjkzNiAxLjgxNzE4NiA2LjY4MjkzOUMxLjgxNzE4NiA4LjM4MDU3MyAyLjExNjA2NSAxMC43ODM1NjIgMy42ODIxOTIgMTIuODAzOTg1QzMuODAxNzQzIDEyLjk0NzQ0NyA0LjU3ODgyOSAxMy44NTYwNCA0Ljc5NDAyMiAxMy44NTYwNEM0Ljg0MTg0MyAxMy44NTYwNCA0LjkzNzQ4NCAxMy44NTYwNCA0LjkzNzQ4NCAxMy43MzY0ODhaJyBpZD0nZzAtMCcvPgo8cGF0aCBkPSdNMy42NDYzMjYgNi42OTQ4OTRDMy42NDYzMjYgNC45OTcyNiAzLjM0NzQ0NyAyLjU5NDI3MSAxLjc4MTMyIDAuNTczODQ4QzEuNjYxNzY4IDAuNDMwMzg2IDAuODg0NjgyIC0wLjQ3ODIwNyAwLjY2OTQ4OSAtMC40NzgyMDdDMC42MDk3MTQgLTAuNDc4MjA3IDAuNTI2MDI3IC0wLjQ1NDI5NiAwLjUyNjAyNyAtMC4zNTg2NTVDMC41MjYwMjcgLTAuMzEwODM0IDAuNTQ5OTM4IC0wLjI3NDk2OSAwLjU5Nzc1OCAtMC4yMzkxMDNDMS4xNzE2MDYgMC4zODI1NjUgMS45NDg2OTIgMS4zNTA5MzQgMi40Mzg4NTQgMy4yNTE4MDZDMi43MTM4MjMgNC4zMzk3MjYgMi44MjE0MiA1LjU3MTEwOCAyLjgyMTQyIDYuNjgyOTM5QzIuODIxNDIgNy44OTA0MTEgMi43MTM4MjMgOS4xMDk4MzggMi40MDI5ODkgMTAuMjgxNDQ1QzEuOTQ4NjkyIDExLjk1NTE2OCAxLjI0MzMzNyAxMi45MTE1ODIgMC42MzM2MjQgMTMuNTgxMDcxQzAuNTI2MDI3IDEzLjY4ODY2NyAwLjUyNjAyNyAxMy43MTI1NzggMC41MjYwMjcgMTMuNzM2NDg4QzAuNTI2MDI3IDEzLjgzMjEzIDAuNjA5NzE0IDEzLjg1NjA0IDAuNjY5NDg5IDEzLjg1NjA0QzAuODQ4ODE3IDEzLjg1NjA0IDEuNTA2MzUxIDEzLjEyNjc3NSAxLjY0OTgxMyAxMi45NTk0MDJDMi44NjkyNCAxMS41MTI4MjcgMy42NDYzMjYgOS4zNjA4OTcgMy42NDYzMjYgNi42OTQ4OTRaJyBpZD0nZzAtMScvPgo8cGF0aCBkPSdNNi4wMjU0MDUgNS40MTU2OTFDNi4wMjU0MDUgNC40MzUzNjcgNi4yODg0MTggMi4xNTE5MyA4LjQxNjQzOCAwLjY0NTU3OUM4LjU3MTg1NiAwLjUyNjAyNyA4LjU4MzgxMSAwLjUxNDA3MiA4LjU4MzgxMSAwLjI5ODg3OUM4LjU4MzgxMSAwLjAyMzkxIDguNTcxODU2IDAuMDExOTU1IDguMjcyOTc2IDAuMDExOTU1SDguMDgxNjk0QzUuNTExMzMzIDEuMzk4NzU1IDQuNTkwNzg1IDMuNjU4MjgxIDQuNTkwNzg1IDUuNDE1NjkxVjEwLjU1NjQxM0M0LjU5MDc4NSAxMC44NjcyNDggNC42MDI3NCAxMC44NzkyMDMgNC45MjU1MjkgMTAuODc5MjAzSDUuNjkwNjZDNi4wMTM0NSAxMC44NzkyMDMgNi4wMjU0MDUgMTAuODY3MjQ4IDYuMDI1NDA1IDEwLjU1NjQxM1Y1LjQxNTY5MVonIGlkPSdnMC01NicvPgo8cGF0aCBkPSdNNC41OTA3ODUgMTAuNTU2NDEzQzQuNTkwNzg1IDEwLjg2NzI0OCA0LjYwMjc0IDEwLjg3OTIwMyA0LjkyNTUyOSAxMC44NzkyMDNINS42OTA2NkM2LjAxMzQ1IDEwLjg3OTIwMyA2LjAyNTQwNSAxMC44NjcyNDggNi4wMjU0MDUgMTAuNTU2NDEzVjUuNDE1NjkxQzYuMDI1NDA1IDMuNjU4MjgxIDUuMTA0ODU3IDEuMzk4NzU1IDIuNTM0NDk2IDAuMDExOTU1SDIuMzU1MTY4QzIuMDQ0MzM0IDAuMDExOTU1IDIuMDMyMzc5IDAuMDIzOTEgMi4wMzIzNzkgMC4yOTg4NzlDMi4wMzIzNzkgMC41MTQwNzIgMi4wNDQzMzQgMC41MjYwMjcgMi4wOTIxNTQgMC41NjE4OTNDMi40NjI3NjUgMC44MzY4NjIgMy4zMjM1MzcgMS40NDY1NzUgMy44ODU0MyAyLjU0NjQ1MUM0LjIwODIxOSAzLjE5MjAzIDQuNTkwNzg1IDQuMTI0NTMzIDQuNTkwNzg1IDUuNDE1NjkxVjEwLjU1NjQxM1onIGlkPSdnMC01NycvPgo8cGF0aCBkPSdNOC4yNzI5NzYgMTAuNzQ3Njk2QzguNTcxODU2IDEwLjc0NzY5NiA4LjU4MzgxMSAxMC43MzU3NDEgOC41ODM4MTEgMTAuNDYwNzcyQzguNTgzODExIDEwLjI0NTU3OSA4LjU3MTg1NiAxMC4yMzM2MjQgOC41MjQwMzUgMTAuMTk3NzU4QzguMTUzNDI1IDkuOTIyNzkgNy4yOTI2NTMgOS4zMTMwNzYgNi43MzA3NiA4LjIxMzJDNi4yNjQ1MDggNy4zMDQ2MDggNi4wMjU0MDUgNi4zODQwNiA2LjAyNTQwNSA1LjM0Mzk2VjAuMjAzMjM4QzYuMDI1NDA1IC0wLjEwNzU5NyA2LjAxMzQ1IC0wLjExOTU1MiA1LjY5MDY2IC0wLjExOTU1Mkg0LjkyNTUyOUM0LjYwMjc0IC0wLjExOTU1MiA0LjU5MDc4NSAtMC4xMDc1OTcgNC41OTA3ODUgMC4yMDMyMzhWNS4zNDM5NkM0LjU5MDc4NSA3LjExMzMyNSA1LjUxMTMzMyA5LjM3Mjg1MiA4LjA4MTY5NCAxMC43NDc2OTZIOC4yNzI5NzZaJyBpZD0nZzAtNTgnLz4KPHBhdGggZD0nTTQuNTkwNzg1IDUuMzQzOTZDNC41OTA3ODUgNi4zODQwNiA0LjMwMzg2MSA4LjYzMTYzMSAyLjE5OTc1MSAxMC4xMTQwNzJDMi4wNDQzMzQgMTAuMjMzNjI0IDIuMDMyMzc5IDEwLjI0NTU3OSAyLjAzMjM3OSAxMC40NjA3NzJDMi4wMzIzNzkgMTAuNzM1NzQxIDIuMDQ0MzM0IDEwLjc0NzY5NiAyLjM1NTE2OCAxMC43NDc2OTZIMi41MzQ0OTZDNS4xMTY4MTIgOS4zNjA4OTcgNi4wMjU0MDUgNy4xMDEzNyA2LjAyNTQwNSA1LjM0Mzk2VjAuMjAzMjM4QzYuMDI1NDA1IC0wLjEwNzU5NyA2LjAxMzQ1IC0wLjExOTU1MiA1LjY5MDY2IC0wLjExOTU1Mkg0LjkyNTUyOUM0LjYwMjc0IC0wLjExOTU1MiA0LjU5MDc4NSAtMC4xMDc1OTcgNC41OTA3ODUgMC4yMDMyMzhWNS4zNDM5NlonIGlkPSdnMC01OScvPgo8cGF0aCBkPSdNNC41OTA3ODUgMjEuMzE2MDY1QzQuNTkwNzg1IDIxLjYyNjg5OSA0LjYwMjc0IDIxLjYzODg1NCA0LjkyNTUyOSAyMS42Mzg4NTRINS42OTA2NkM2LjAxMzQ1IDIxLjYzODg1NCA2LjAyNTQwNSAyMS42MjY4OTkgNi4wMjU0MDUgMjEuMzE2MDY1VjE2LjI3MDk4NEM2LjAyNTQwNSAxNC44MjQ0MDggNS40MTU2OTEgMTIuMzg1NTU0IDIuNzM3NzMzIDEwLjc1OTY1MUM1LjQzOTYwMSA5LjEyMTc5MyA2LjAyNTQwNSA2LjY1OTAyOSA2LjAyNTQwNSA1LjI0ODMxOVYwLjIwMzIzOEM2LjAyNTQwNSAtMC4xMDc1OTcgNi4wMTM0NSAtMC4xMTk1NTIgNS42OTA2NiAtMC4xMTk1NTJINC45MjU1MjlDNC42MDI3NCAtMC4xMTk1NTIgNC41OTA3ODUgLTAuMTA3NTk3IDQuNTkwNzg1IDAuMjAzMjM4VjUuMjYwMjc0QzQuNTkwNzg1IDYuMjY0NTA4IDQuMzc1NTkyIDguNzUxMTgzIDIuMTc1ODQxIDEwLjQyNDkwN0MyLjA0NDMzNCAxMC41MzI1MDMgMi4wMzIzNzkgMTAuNTQ0NDU4IDIuMDMyMzc5IDEwLjc1OTY1MVMyLjA0NDMzNCAxMC45ODY4IDIuMTc1ODQxIDExLjA5NDM5NkMyLjQ4NjY3NSAxMS4zMzM0OTkgMy4zMTE1ODIgMTEuOTY3MTIzIDMuODg1NDMgMTMuMTc0NTk1QzQuMzUxNjgxIDE0LjEzMTAwOSA0LjU5MDc4NSAxNS4xOTUwMTkgNC41OTA3ODUgMTYuMjU5MDI5VjIxLjMxNjA2NVonIGlkPSdnMC02MCcvPgo8cGF0aCBkPSdNNi4wMjU0MDUgMTYuMjU5MDI5QzYuMDI1NDA1IDE1LjI1NDc5NSA2LjI0MDU5OCAxMi43NjgxMiA4LjQ0MDM0OSAxMS4wOTQzOTZDOC41NzE4NTYgMTAuOTg2OCA4LjU4MzgxMSAxMC45NzQ4NDQgOC41ODM4MTEgMTAuNzU5NjUxUzguNTcxODU2IDEwLjUzMjUwMyA4LjQ0MDM0OSAxMC40MjQ5MDdDOC4xMjk1MTQgMTAuMTg1ODAzIDcuMzA0NjA4IDkuNTUyMTc5IDYuNzMwNzYgOC4zNDQ3MDdDNi4yNjQ1MDggNy4zODgyOTQgNi4wMjU0MDUgNi4zMjQyODQgNi4wMjU0MDUgNS4yNjAyNzRWMC4yMDMyMzhDNi4wMjU0MDUgLTAuMTA3NTk3IDYuMDEzNDUgLTAuMTE5NTUyIDUuNjkwNjYgLTAuMTE5NTUySDQuOTI1NTI5QzQuNjAyNzQgLTAuMTE5NTUyIDQuNTkwNzg1IC0wLjEwNzU5NyA0LjU5MDc4NSAwLjIwMzIzOFY1LjI0ODMxOUM0LjU5MDc4NSA2LjY5NDg5NCA1LjIwMDQ5OCA5LjEzMzc0OCA3Ljg3ODQ1NiAxMC43NTk2NTFDNS4xNzY1ODggMTIuMzk3NTA5IDQuNTkwNzg1IDE0Ljg2MDI3NCA0LjU5MDc4NSAxNi4yNzA5ODRWMjEuMzE2MDY1QzQuNTkwNzg1IDIxLjYyNjg5OSA0LjYwMjc0IDIxLjYzODg1NCA0LjkyNTUyOSAyMS42Mzg4NTRINS42OTA2NkM2LjAxMzQ1IDIxLjYzODg1NCA2LjAyNTQwNSAyMS42MjY4OTkgNi4wMjU0MDUgMjEuMzE2MDY1VjE2LjI1OTAyOVonIGlkPSdnMC02MScvPgo8cGF0aCBkPSdNNi4wMjU0MDUgMC4yMDMyMzhDNi4wMjU0MDUgLTAuMTA3NTk3IDYuMDEzNDUgLTAuMTE5NTUyIDUuNjkwNjYgLTAuMTE5NTUySDQuOTI1NTI5QzQuNjAyNzQgLTAuMTE5NTUyIDQuNTkwNzg1IC0wLjEwNzU5NyA0LjU5MDc4NSAwLjIwMzIzOFYzLjM4MzMxM0M0LjU5MDc4NSAzLjY5NDE0NyA0LjYwMjc0IDMuNzA2MTAyIDQuOTI1NTI5IDMuNzA2MTAySDUuNjkwNjZDNi4wMTM0NSAzLjcwNjEwMiA2LjAyNTQwNSAzLjY5NDE0NyA2LjAyNTQwNSAzLjM4MzMxM1YwLjIwMzIzOFonIGlkPSdnMC02MicvPgo8cGF0aCBkPSdNMi4zMzEyNTggMC4wNDc4MjFDMi4zMzEyNTggLTAuNjQ1NTc5IDIuMTA0MTEgLTEuMTU5NjUxIDEuNjEzOTQ4IC0xLjE1OTY1MUMxLjIzMTM4MiAtMS4xNTk2NTEgMS4wNDAxIC0wLjg0ODgxNyAxLjA0MDEgLTAuNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjcgLTAuMDQ3ODIxIDIuMDIwNDIzIC0wLjE1NTQxN0MyLjA0NDMzNCAtMC4xNzkzMjggMi4wNTYyODkgLTAuMTc5MzI4IDIuMDY4MjQ0IC0wLjE3OTMyOEMyLjA5MjE1NCAtMC4xNzkzMjggMi4wOTIxNTQgLTAuMDExOTU1IDIuMDkyMTU0IDAuMDQ3ODIxQzIuMDkyMTU0IDAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggMC4wNDc4MjFaJyBpZD0nZzMtNTknLz4KPHBhdGggZD0nTTYuMDEzNDUgLTcuOTk4MDA3QzYuMDI1NDA1IC04LjA0NTgyOCA2LjA0OTMxNSAtOC4xMTc1NTkgNi4wNDkzMTUgLTguMTc3MzM1QzYuMDQ5MzE1IC04LjI5Njg4NyA1LjkyOTc2MyAtOC4yOTY4ODcgNS45MDU4NTMgLTguMjk2ODg3QzUuODkzODk4IC04LjI5Njg4NyA1LjMwODA5NSAtOC4yNDkwNjYgNS4yNDgzMTkgLTguMjM3MTExQzUuMDQ1MDgxIC04LjIyNTE1NiA0Ljg2NTc1MyAtOC4yMDEyNDUgNC42NTA1NiAtOC4xODkyOUM0LjM1MTY4MSAtOC4xNjUzOCA0LjI2Nzk5NSAtOC4xNTM0MjUgNC4yNjc5OTUgLTcuOTM4MjMyQzQuMjY3OTk1IC03LjgxODY4IDQuMzYzNjM2IC03LjgxODY4IDQuNTMxMDA5IC03LjgxODY4QzUuMTE2ODEyIC03LjgxODY4IDUuMTI4NzY3IC03LjcxMTA4MyA1LjEyODc2NyAtNy41OTE1MzJDNS4xMjg3NjcgLTcuNTE5ODAxIDUuMTA0ODU3IC03LjQyNDE1OSA1LjA5MjkwMiAtNy4zODgyOTRMNC4zNjM2MzYgLTQuNDgzMTg4QzQuMjMyMTMgLTQuNzk0MDIyIDMuOTA5MzQgLTUuMjcyMjI5IDMuMjg3NjcxIC01LjI3MjIyOUMxLjkzNjczNyAtNS4yNzIyMjkgMC40NzgyMDcgLTMuNTI2Nzc1IDAuNDc4MjA3IC0xLjc1NzQxQzAuNDc4MjA3IC0wLjU3Mzg0OCAxLjE3MTYwNiAwLjExOTU1MiAxLjk4NDU1OCAwLjExOTU1MkMyLjY0MjA5MiAwLjExOTU1MiAzLjIwMzk4NSAtMC4zOTQ1MjEgMy41Mzg3MyAtMC43ODkwNDFDMy42NTgyODEgLTAuMDgzNjg2IDQuMjIwMTc0IDAuMTE5NTUyIDQuNTc4ODI5IDAuMTE5NTUyUzUuMjI0NDA4IC0wLjA5NTY0MSA1LjQzOTYwMSAtMC41MjYwMjdDNS42MzA4ODQgLTAuOTMyNTAzIDUuNzk4MjU3IC0xLjY2MTc2OCA1Ljc5ODI1NyAtMS43MDk1ODlDNS43OTgyNTcgLTEuNzY5MzY1IDUuNzUwNDM2IC0xLjgxNzE4NiA1LjY3ODcwNSAtMS44MTcxODZDNS41NzExMDggLTEuODE3MTg2IDUuNTU5MTUzIC0xLjc1NzQxIDUuNTExMzMzIC0xLjU3ODA4MkM1LjMzMjAwNSAtMC44NzI3MjcgNS4xMDQ4NTcgLTAuMTE5NTUyIDQuNjE0Njk1IC0wLjExOTU1MkM0LjI2Nzk5NSAtMC4xMTk1NTIgNC4yNDQwODUgLTAuNDMwMzg2IDQuMjQ0MDg1IC0wLjY2OTQ4OUM0LjI0NDA4NSAtMC43MTczMSA0LjI0NDA4NSAtMC45NjgzNjkgNC4zMjc3NzEgLTEuMzAzMTEzTDYuMDEzNDUgLTcuOTk4MDA3Wk0zLjU5ODUwNiAtMS40MjI2NjVDMy41Mzg3MyAtMS4yMTk0MjcgMy41Mzg3MyAtMS4xOTU1MTcgMy4zNzEzNTcgLTAuOTY4MzY5QzMuMTA4MzQ0IC0wLjYzMzYyNCAyLjU4MjMxNiAtMC4xMTk1NTIgMi4wMjA0MjMgLTAuMTE5NTUyQzEuNTMwMjYyIC0wLjExOTU1MiAxLjI1NTI5MyAtMC41NjE4OTMgMS4yNTUyOTMgLTEuMjY3MjQ4QzEuMjU1MjkzIC0xLjkyNDc4MiAxLjYyNTkwMyAtMy4yNjM3NjEgMS44NTMwNTEgLTMuNzY1ODc4QzIuMjU5NTI3IC00LjYwMjc0IDIuODIxNDIgLTUuMDMzMTI2IDMuMjg3NjcxIC01LjAzMzEyNkM0LjA3NjcxMiAtNS4wMzMxMjYgNC4yMzIxMyAtNC4wNTI4MDIgNC4yMzIxMyAtMy45NTcxNjFDNC4yMzIxMyAtMy45NDUyMDUgNC4xOTYyNjQgLTMuNzg5Nzg4IDQuMTg0MzA5IC0zLjc2NTg3OEwzLjU5ODUwNiAtMS40MjI2NjVaJyBpZD0nZzMtMTAwJy8+CjxwYXRoIGQ9J00yLjQ2Mjc2NSAtMy41MDI4NjRDMi40ODY2NzUgLTMuNTc0NTk1IDIuNzg1NTU0IC00LjE3MjM1NCAzLjIyNzg5NSAtNC41NTQ5MTlDMy41Mzg3MyAtNC44NDE4NDMgMy45NDUyMDUgLTUuMDMzMTI2IDQuNDExNDU3IC01LjAzMzEyNkM0Ljg4OTY2NCAtNS4wMzMxMjYgNS4wNTcwMzYgLTQuNjc0NDcxIDUuMDU3MDM2IC00LjE5NjI2NEM1LjA1NzAzNiAtNC4xMjQ1MzMgNS4wNTcwMzYgLTMuODg1NDMgNC45MTM1NzQgLTMuMzIzNTM3TDQuNjE0Njk1IC0yLjA5MjE1NEM0LjUxOTA1NCAtMS43MzM0OTkgNC4yOTE5MDUgLTAuODQ4ODE3IDQuMjY3OTk1IC0wLjcxNzMxQzQuMjIwMTc0IC0wLjUzNzk4MyA0LjE0ODQ0MyAtMC4yMjcxNDggNC4xNDg0NDMgLTAuMTc5MzI4QzQuMTQ4NDQzIC0wLjAxMTk1NSA0LjI3OTk1IDAuMTE5NTUyIDQuNDU5Mjc4IDAuMTE5NTUyQzQuODE3OTMzIDAuMTE5NTUyIDQuODc3NzA5IC0wLjE1NTQxNyA0Ljk4NTMwNSAtMC41ODU4MDNMNS43MDI2MTUgLTMuNDQzMDg4QzUuNzI2NTI2IC0zLjUzODczIDYuMzQ4MTk0IC01LjAzMzEyNiA3LjY2MzI2MyAtNS4wMzMxMjZDOC4xNDE0NjkgLTUuMDMzMTI2IDguMzA4ODQyIC00LjY3NDQ3MSA4LjMwODg0MiAtNC4xOTYyNjRDOC4zMDg4NDIgLTMuNTI2Nzc1IDcuODQyNTkgLTIuMjIzNjYxIDcuNTc5NTc3IC0xLjUwNjM1MUM3LjQ3MTk4IC0xLjIxOTQyNyA3LjQxMjIwNCAtMS4wNjQwMSA3LjQxMjIwNCAtMC44NDg4MTdDNy40MTIyMDQgLTAuMzEwODM0IDcuNzgyODE0IDAuMTE5NTUyIDguMzU2NjYzIDAuMTE5NTUyQzkuNDY4NDkzIDAuMTE5NTUyIDkuODg2OTI0IC0xLjYzNzg1OCA5Ljg4NjkyNCAtMS43MDk1ODlDOS44ODY5MjQgLTEuNzY5MzY1IDkuODM5MTAzIC0xLjgxNzE4NiA5Ljc2NzM3MiAtMS44MTcxODZDOS42NTk3NzYgLTEuODE3MTg2IDkuNjQ3ODIxIC0xLjc4MTMyIDkuNTg4MDQ1IC0xLjU3ODA4MkM5LjMxMzA3NiAtMC42MjE2NjkgOC44NzA3MzUgLTAuMTE5NTUyIDguMzkyNTI4IC0wLjExOTU1MkM4LjI3Mjk3NiAtMC4xMTk1NTIgOC4wODE2OTQgLTAuMTMxNTA3IDguMDgxNjk0IC0wLjUxNDA3MkM4LjA4MTY5NCAtMC44MjQ5MDcgOC4yMjUxNTYgLTEuMjA3NDcyIDguMjcyOTc2IC0xLjMzODk3OUM4LjQ4ODE2OSAtMS45MTI4MjcgOS4wMjYxNTIgLTMuMzIzNTM3IDkuMDI2MTUyIC00LjAxNjkzNkM5LjAyNjE1MiAtNC43MzQyNDcgOC42MDc3MjEgLTUuMjcyMjI5IDcuNjk5MTI4IC01LjI3MjIyOUM2Ljg5ODEzMiAtNS4yNzIyMjkgNi4yNTI1NTMgLTQuODE3OTMzIDUuNzc0MzQ2IC00LjExMjU3OEM1LjczODQ4MSAtNC43NTgxNTcgNS4zNDM5NiAtNS4yNzIyMjkgNC40NDczMjMgLTUuMjcyMjI5QzMuMzgzMzEzIC01LjI3MjIyOSAyLjgyMTQyIC00LjUxOTA1NCAyLjYwNjIyNyAtNC4yMjAxNzRDMi41NzAzNjEgLTQuOTAxNjE5IDIuMDgwMTk5IC01LjI3MjIyOSAxLjU1NDE3MiAtNS4yNzIyMjlDMS4yMDc0NzIgLTUuMjcyMjI5IDAuOTMyNTAzIC01LjEwNDg1NyAwLjcwNTM1NSAtNC42NTA1NkMwLjQ5MDE2MiAtNC4yMjAxNzQgMC4zMjI3OSAtMy40OTA5MDkgMC4zMjI3OSAtMy40NDMwODhTMC4zNzA2MSAtMy4zMzU0OTIgMC40NTQyOTYgLTMuMzM1NDkyQzAuNTQ5OTM4IC0zLjMzNTQ5MiAwLjU2MTg5MyAtMy4zNDc0NDcgMC42MzM2MjQgLTMuNjIyNDE2QzAuODEyOTUxIC00LjMyNzc3MSAxLjA0MDEgLTUuMDMzMTI2IDEuNTE4MzA2IC01LjAzMzEyNkMxLjc5MzI3NSAtNS4wMzMxMjYgMS44ODg5MTcgLTQuODQxODQzIDEuODg4OTE3IC00LjQ4MzE4OEMxLjg4ODkxNyAtNC4yMjAxNzQgMS43NjkzNjUgLTMuNzUzOTIzIDEuNjg1Njc5IC0zLjM4MzMxM0wxLjM1MDkzNCAtMi4wOTIxNTRDMS4zMDMxMTMgLTEuODY1MDA2IDEuMTcxNjA2IC0xLjMyNzAyNCAxLjExMTgzMSAtMS4xMTE4MzFDMS4wMjgxNDQgLTAuODAwOTk2IDAuODk2NjM4IC0wLjIzOTEwMyAwLjg5NjYzOCAtMC4xNzkzMjhDMC44OTY2MzggLTAuMDExOTU1IDEuMDI4MTQ0IDAuMTE5NTUyIDEuMjA3NDcyIDAuMTE5NTUyQzEuMzUwOTM0IDAuMTE5NTUyIDEuNTE4MzA2IDAuMDQ3ODIxIDEuNjEzOTQ4IC0wLjEzMTUwN0MxLjYzNzg1OCAtMC4xOTEyODMgMS43NDU0NTUgLTAuNjA5NzE0IDEuODA1MjMgLTAuODQ4ODE3TDIuMDY4MjQ0IC0xLjkyNDc4MkwyLjQ2Mjc2NSAtMy41MDI4NjRaJyBpZD0nZzMtMTA5Jy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc4OC4zNzQ0OTgnIHhsaW5rOmhyZWY9JyNnMC01NicgeT0nNzkuMDgwNzk3Jy8+Cjx1c2UgeD0nODguMzc0NDk4JyB4bGluazpocmVmPScjZzAtNjInIHk9Jzg5Ljg0MDU1OCcvPgo8dXNlIHg9Jzg4LjM3NDQ5OCcgeGxpbms6aHJlZj0nI2cwLTYyJyB5PSc5My40MjcxNDUnLz4KPHVzZSB4PSc4OC4zNzQ0OTgnIHhsaW5rOmhyZWY9JyNnMC02MCcgeT0nOTcuMDEzNzMxJy8+Cjx1c2UgeD0nODguMzc0NDk4JyB4bGluazpocmVmPScjZzAtNjInIHk9JzExOC41MzMyNTMnLz4KPHVzZSB4PSc4OC4zNzQ0OTgnIHhsaW5rOmhyZWY9JyNnMC02MicgeT0nMTIyLjExOTg0Jy8+Cjx1c2UgeD0nODguMzc0NDk4JyB4bGluazpocmVmPScjZzAtNTgnIHk9JzEyNS43MDY0MjcnLz4KPHVzZSB4PScxMDMuOTgyNjU0JyB4bGluazpocmVmPScjZzMtMTAwJyB5PSc4OC40NjgyMDInLz4KPHVzZSB4PScxMTAuMDY1MzQ3JyB4bGluazpocmVmPScjZzQtNDgnIHk9JzkwLjI2MTQ2NScvPgo8dXNlIHg9JzExNC4yOTk1MycgeGxpbms6aHJlZj0nI2cyLTU5JyB5PSc5MC4yNjE0NjUnLz4KPHVzZSB4PScxMTYuNjUxODU0JyB4bGluazpocmVmPScjZzQtNDgnIHk9JzkwLjI2MTQ2NScvPgo8dXNlIHg9JzEyNC43MDQ5OTgnIHhsaW5rOmhyZWY9JyNnNS02MScgeT0nODguNDY4MjAyJy8+Cjx1c2UgeD0nMTM3LjEzMDQ3OScgeGxpbms6aHJlZj0nI2c1LTQ4JyB5PSc4OC40NjgyMDInLz4KPHVzZSB4PScxMDMuOTgyNjU0JyB4bGluazpocmVmPScjZzMtMTAwJyB5PScxMTcuNzM2MTMyJy8+Cjx1c2UgeD0nMTEwLjA2NTM0NycgeGxpbms6aHJlZj0nI2cyLTEwNScgeT0nMTE5LjUyOTM5NScvPgo8dXNlIHg9JzExMi45NDg0ODcnIHhsaW5rOmhyZWY9JyNnMi01OScgeT0nMTE5LjUyOTM5NScvPgo8dXNlIHg9JzExNS4zMDA4MTEnIHhsaW5rOmhyZWY9JyNnMi0xMDYnIHk9JzExOS41MjkzOTUnLz4KPHVzZSB4PScxMjMuMDAzNzk3JyB4bGluazpocmVmPScjZzUtNjEnIHk9JzExNy43MzYxMzInLz4KPHVzZSB4PScxMzUuNDI5Mjc4JyB4bGluazpocmVmPScjZzUtMTA5JyB5PScxMTcuNzM2MTMyJy8+Cjx1c2UgeD0nMTQ1LjE4NDI2MicgeGxpbms6aHJlZj0nI2c1LTEwNScgeT0nMTE3LjczNjEzMicvPgo8dXNlIHg9JzE0OC40MzU5MjMnIHhsaW5rOmhyZWY9JyNnNS0xMTAnIHk9JzExNy43MzYxMzInLz4KPHVzZSB4PScxNTYuOTMxNzQzJyB4bGluazpocmVmPScjZzAtNTYnIHk9JzkzLjIyNzgxOScvPgo8dXNlIHg9JzE1Ni45MzE3NDMnIHhsaW5rOmhyZWY9JyNnMC02MCcgeT0nMTAzLjk4NzU4Jy8+Cjx1c2UgeD0nMTU2LjkzMTc0MycgeGxpbms6aHJlZj0nI2cwLTU4JyB5PScxMjUuNTA3MTAxJy8+Cjx1c2UgeD0nMTcyLjUzOTg5OScgeGxpbms6aHJlZj0nI2czLTEwMCcgeT0nMTAzLjU4OTExJy8+Cjx1c2UgeD0nMTc4LjYyMjU5MicgeGxpbms6aHJlZj0nI2cyLTEwNScgeT0nMTA1LjM4MjM3MycvPgo8dXNlIHg9JzE4MS41MDU3MzInIHhsaW5rOmhyZWY9JyNnMS0wJyB5PScxMDUuMzgyMzczJy8+Cjx1c2UgeD0nMTg4LjA5MjIzOScgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxMDUuMzgyMzczJy8+Cjx1c2UgeD0nMTkyLjMyNjQyMScgeGxpbms6aHJlZj0nI2cyLTU5JyB5PScxMDUuMzgyMzczJy8+Cjx1c2UgeD0nMTk0LjY3ODc0NScgeGxpbms6aHJlZj0nI2cyLTEwNicgeT0nMTA1LjM4MjM3MycvPgo8dXNlIHg9JzE5OC41NjI3NycgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzEwNS4zODIzNzMnLz4KPHVzZSB4PScyMDUuMTQ5Mjc3JyB4bGluazpocmVmPScjZzQtNDknIHk9JzEwNS4zODIzNzMnLz4KPHVzZSB4PScyMTkuODQ0MjI4JyB4bGluazpocmVmPScjZzUtNDMnIHk9JzEwMy41ODkxMScvPgo8dXNlIHg9JzIzOC45MTE1MicgeGxpbms6aHJlZj0nI2c1LTk5JyB5PScxMDMuNTg5MTEnLz4KPHVzZSB4PScyNDQuMTE0MTc4JyB4bGluazpocmVmPScjZzUtMTExJyB5PScxMDMuNTg5MTEnLz4KPHVzZSB4PScyNDkuOTY3MTY4JyB4bGluazpocmVmPScjZzUtMTA5JyB5PScxMDMuNTg5MTEnLz4KPHVzZSB4PScyNTkuNzIyMTUyJyB4bGluazpocmVmPScjZzUtMTEyJyB5PScxMDMuNTg5MTEnLz4KPHVzZSB4PScyNjYuMjI1NDc0JyB4bGluazpocmVmPScjZzUtOTcnIHk9JzEwMy41ODkxMScvPgo8dXNlIHg9JzI3Mi4wNzg0NjQnIHhsaW5rOmhyZWY9JyNnNS0xMTQnIHk9JzEwMy41ODkxMScvPgo8dXNlIHg9JzI3Ni42MzA3OScgeGxpbms6aHJlZj0nI2c1LTk3JyB5PScxMDMuNTg5MTEnLz4KPHVzZSB4PScyODIuNDgzNzgnIHhsaW5rOmhyZWY9JyNnNS0xMDUnIHk9JzEwMy41ODkxMScvPgo8dXNlIHg9JzI4NS43MzU0NDInIHhsaW5rOmhyZWY9JyNnNS0xMTUnIHk9JzEwMy41ODkxMScvPgo8dXNlIHg9JzI5MC4zNTI4MDEnIHhsaW5rOmhyZWY9JyNnNS0xMTEnIHk9JzEwMy41ODkxMScvPgo8dXNlIHg9JzI5Ni4yMDU3OTEnIHhsaW5rOmhyZWY9JyNnNS0xMTAnIHk9JzEwMy41ODkxMScvPgo8dXNlIHg9JzMwNC43MDE2MTEnIHhsaW5rOmhyZWY9JyNnMC0wJyB5PSc5My45MDUzNDcnLz4KPHVzZSB4PSczMTAuMTgxMDk0JyB4bGluazpocmVmPScjZzMtMTA5JyB5PScxMDMuNTg5MTEnLz4KPHVzZSB4PSczMjAuNDIwMzYnIHhsaW5rOmhyZWY9JyNnMi0xMDUnIHk9Jzk5LjI1MDY3NCcvPgo8dXNlIHg9JzMyMC40MjAzNicgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxMDYuNTQ0NjI2Jy8+Cjx1c2UgeD0nMzI1LjE1MjY3NScgeGxpbms6aHJlZj0nI2czLTU5JyB5PScxMDMuNTg5MTEnLz4KPHVzZSB4PSczMzAuMzk2ODM0JyB4bGluazpocmVmPScjZzMtMTA5JyB5PScxMDMuNTg5MTEnLz4KPHVzZSB4PSczNDAuNjM2MTAxJyB4bGluazpocmVmPScjZzItMTA2JyB5PSc5Ny45MjE0OTEnLz4KPHVzZSB4PSczNDAuNjM2MTAxJyB4bGluazpocmVmPScjZzQtNTAnIHk9JzEwNi41MjAyODgnLz4KPHVzZSB4PSczNDUuMzY4NDE2JyB4bGluazpocmVmPScjZzAtMScgeT0nOTMuOTA1MzQ3Jy8+Cjx1c2UgeD0nMzUyLjg0MDM5NicgeGxpbms6aHJlZj0nI2czLTU5JyB5PScxMDMuNTg5MTEnLz4KPHVzZSB4PScxNzIuNTM5ODk5JyB4bGluazpocmVmPScjZzMtMTAwJyB5PScxMTguNzEwMDUnLz4KPHVzZSB4PScxNzguNjIyNTkyJyB4bGluazpocmVmPScjZzItMTA1JyB5PScxMjAuNTAzMzEzJy8+Cjx1c2UgeD0nMTgxLjUwNTczMicgeGxpbms6aHJlZj0nI2cyLTU5JyB5PScxMjAuNTAzMzEzJy8+Cjx1c2UgeD0nMTgzLjg1ODA1NicgeGxpbms6aHJlZj0nI2cyLTEwNicgeT0nMTIwLjUwMzMxMycvPgo8dXNlIHg9JzE4Ny43NDIwODEnIHhsaW5rOmhyZWY9JyNnMS0wJyB5PScxMjAuNTAzMzEzJy8+Cjx1c2UgeD0nMTk0LjMyODU4NycgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxMjAuNTAzMzEzJy8+Cjx1c2UgeD0nMjE5Ljg0NDIyOCcgeGxpbms6aHJlZj0nI2c1LTQzJyB5PScxMTguNzEwMDUnLz4KPHVzZSB4PScyMzguOTExNTInIHhsaW5rOmhyZWY9JyNnNS0xMDUnIHk9JzExOC43MTAwNScvPgo8dXNlIHg9JzI0Mi4xNjMxODEnIHhsaW5rOmhyZWY9JyNnNS0xMTAnIHk9JzExOC43MTAwNScvPgo8dXNlIHg9JzI0OC42NjY1MDMnIHhsaW5rOmhyZWY9JyNnNS0xMTUnIHk9JzExOC43MTAwNScvPgo8dXNlIHg9JzI1My4yODM4NjInIHhsaW5rOmhyZWY9JyNnNS0xMDEnIHk9JzExOC43MTAwNScvPgo8dXNlIHg9JzI1OC40ODY1MicgeGxpbms6aHJlZj0nI2c1LTExNCcgeT0nMTE4LjcxMDA1Jy8+Cjx1c2UgeD0nMjYzLjAzODg0NicgeGxpbms6aHJlZj0nI2c1LTExNicgeT0nMTE4LjcxMDA1Jy8+Cjx1c2UgeD0nMjY3LjU5MTE3MicgeGxpbms6aHJlZj0nI2c1LTEwNScgeT0nMTE4LjcxMDA1Jy8+Cjx1c2UgeD0nMjcwLjg0MjgzMycgeGxpbms6aHJlZj0nI2c1LTExMScgeT0nMTE4LjcxMDA1Jy8+Cjx1c2UgeD0nMjc2LjY5NTgyMycgeGxpbms6aHJlZj0nI2c1LTExMCcgeT0nMTE4LjcxMDA1Jy8+Cjx1c2UgeD0nMjg1LjE5MTY0NCcgeGxpbms6aHJlZj0nI2cwLTAnIHk9JzEwOS4wMjYyODYnLz4KPHVzZSB4PScyOTAuNjcxMTI2JyB4bGluazpocmVmPScjZzMtMTA5JyB5PScxMTguNzEwMDUnLz4KPHVzZSB4PSczMDAuOTEwMzkzJyB4bGluazpocmVmPScjZzItMTA2JyB5PScxMTMuMDQyNDMnLz4KPHVzZSB4PSczMDAuOTEwMzkzJyB4bGluazpocmVmPScjZzQtNTAnIHk9JzEyMS42NDEyMjcnLz4KPHVzZSB4PSczMDUuNjQyNzA4JyB4bGluazpocmVmPScjZzAtMScgeT0nMTA5LjAyNjI4NicvPgo8dXNlIHg9JzMxMy4xMTQ2ODgnIHhsaW5rOmhyZWY9JyNnMy01OScgeT0nMTE4LjcxMDA1Jy8+Cjx1c2UgeD0nMTcyLjUzOTg5OScgeGxpbms6aHJlZj0nI2czLTEwMCcgeT0nMTMyLjY1Nzc3NicvPgo8dXNlIHg9JzE3OC42MjI1OTInIHhsaW5rOmhyZWY9JyNnMi0xMDUnIHk9JzEzNC40NTEwMzknLz4KPHVzZSB4PScxODEuNTA1NzMyJyB4bGluazpocmVmPScjZzEtMCcgeT0nMTM0LjQ1MTAzOScvPgo8dXNlIHg9JzE4OC4wOTIyMzknIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nMTM0LjQ1MTAzOScvPgo8dXNlIHg9JzE5Mi4zMjY0MjEnIHhsaW5rOmhyZWY9JyNnMi01OScgeT0nMTM0LjQ1MTAzOScvPgo8dXNlIHg9JzE5NC42Nzg3NDUnIHhsaW5rOmhyZWY9JyNnMi0xMDYnIHk9JzEzNC40NTEwMzknLz4KPHVzZSB4PScyMTkuODQ0MjI4JyB4bGluazpocmVmPScjZzUtNDMnIHk9JzEzMi42NTc3NzYnLz4KPHVzZSB4PScyMzguOTExNTInIHhsaW5rOmhyZWY9JyNnNS0xMTUnIHk9JzEzMi42NTc3NzYnLz4KPHVzZSB4PScyNDMuNTI4ODc5JyB4bGluazpocmVmPScjZzUtMTE3JyB5PScxMzIuNjU3Nzc2Jy8+Cjx1c2UgeD0nMjUwLjAzMjIwMScgeGxpbms6aHJlZj0nI2c1LTExMicgeT0nMTMyLjY1Nzc3NicvPgo8dXNlIHg9JzI1Ni41MzU1MjQnIHhsaW5rOmhyZWY9JyNnNS0xMTInIHk9JzEzMi42NTc3NzYnLz4KPHVzZSB4PScyNjMuMDM4ODQ2JyB4bGluazpocmVmPScjZzUtMTE0JyB5PScxMzIuNjU3Nzc2Jy8+Cjx1c2UgeD0nMjY3LjU5MTE3MicgeGxpbms6aHJlZj0nI2c1LTEwMScgeT0nMTMyLjY1Nzc3NicvPgo8dXNlIHg9JzI3Mi43OTM4MycgeGxpbms6aHJlZj0nI2c1LTExNScgeT0nMTMyLjY1Nzc3NicvPgo8dXNlIHg9JzI3Ny40MTExODknIHhsaW5rOmhyZWY9JyNnNS0xMTUnIHk9JzEzMi42NTc3NzYnLz4KPHVzZSB4PScyODIuMDI4NTQ4JyB4bGluazpocmVmPScjZzUtMTA1JyB5PScxMzIuNjU3Nzc2Jy8+Cjx1c2UgeD0nMjg1LjI4MDIwOScgeGxpbms6aHJlZj0nI2c1LTExMScgeT0nMTMyLjY1Nzc3NicvPgo8dXNlIHg9JzI5MS4xMzMxOTknIHhsaW5rOmhyZWY9JyNnNS0xMTAnIHk9JzEzMi42NTc3NzYnLz4KPHVzZSB4PScyOTkuNjI5MDInIHhsaW5rOmhyZWY9JyNnNS00MCcgeT0nMTMyLjY1Nzc3NicvPgo8dXNlIHg9JzMwNC4xODEzNDUnIHhsaW5rOmhyZWY9JyNnMy0xMDknIHk9JzEzMi42NTc3NzYnLz4KPHVzZSB4PSczMTQuNDIwNjEyJyB4bGluazpocmVmPScjZzItMTA1JyB5PScxMjguMzE5MzQnLz4KPHVzZSB4PSczMTQuNDIwNjEyJyB4bGluazpocmVmPScjZzQtNDknIHk9JzEzNS42MTMyOTInLz4KPHVzZSB4PSczMTkuMTUyOTI3JyB4bGluazpocmVmPScjZzUtNDEnIHk9JzEzMi42NTc3NzYnLz4KPHVzZSB4PSczNjEuMDczMzc3JyB4bGluazpocmVmPScjZzAtNTcnIHk9JzkzLjIyNzgxOScvPgo8dXNlIHg9JzM2MS4wNzMzNzcnIHhsaW5rOmhyZWY9JyNnMC02MScgeT0nMTAzLjk4NzU4Jy8+Cjx1c2UgeD0nMzYxLjA3MzM3NycgeGxpbms6aHJlZj0nI2cwLTU5JyB5PScxMjUuNTA3MTAxJy8+CjwvZz4KPC9zdmc+)
Définition D8 : distance d’édition tronquée étendue
Soit deux mots , on définit la suite :
par :
![\left\{
\begin{array}[c]{l}%
d_{0,0}=0\\
d_{i,j}=\min\left\{
\begin{array}{lll}
d_{i-1,j-1} & + & \text{comparaison} \pa{m_1^i,m_2^j}, \\
d_{i,j-1} & + & \text{insertion} \pa{m_2^j,i}, \\
d_{i-1,j} & + & \text{suppression} \pa{m_1^i,j}, \\
d_{i-2,j-2} & + & \text{permutation} \pa{ \pa{m_1^{i-1}, m_1^i},\pa{m_2^{j-1}, m_2^j}}
\end{array}
\right\}%
\end{array}
\right.](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nNzIuNDk0OTgycHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNDkuMjEzMjE3IDc5LjQ2ODA5MyAzNjEuNjQ4Mjg2IDcyLjQ5NDk4Micgd2lkdGg9JzM2MS42NDgyODZwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNMS40OTA0MTEgLTAuMTE5NTUyQzEuNDkwNDExIDAuMzk4NTA2IDEuMzc4ODI5IDAuODUyODAyIDAuODg0NjgyIDEuMzQ2OTQ5QzAuODUyODAyIDEuMzcwODU5IDAuODM2ODYyIDEuMzg2OCAwLjgzNjg2MiAxLjQyNjY1QzAuODM2ODYyIDEuNDkwNDExIDAuOTAwNjIzIDEuNTM4MjMyIDAuOTU2NDEzIDEuNTM4MjMyQzEuMDUyMDU1IDEuNTM4MjMyIDEuNzEzNTc0IDAuOTA4NTkzIDEuNzEzNTc0IC0wLjAyMzkxQzEuNzEzNTc0IC0wLjUzMzk5OCAxLjUyMjI5MSAtMC44ODQ2ODIgMS4xNzE2MDYgLTAuODg0NjgyQzAuODkyNjUzIC0wLjg4NDY4MiAwLjczMzI1IC0wLjY2MTUxOSAwLjczMzI1IC0wLjQ0NjMyNkMwLjczMzI1IC0wLjIyMzE2MyAwLjg4NDY4MiAwIDEuMTc5NTc3IDBDMS4zNzA4NTkgMCAxLjQ5MDQxMSAtMC4xMTE1ODIgMS40OTA0MTEgLTAuMTE5NTUyWicgaWQ9J2cyLTU5Jy8+CjxwYXRoIGQ9J00yLjM3NTA5MyAtNC45NzMzNUMyLjM3NTA5MyAtNS4xNDg2OTIgMi4yNDc1NzIgLTUuMjc2MjE0IDIuMDY0MjU5IC01LjI3NjIxNEMxLjg1NzAzNiAtNS4yNzYyMTQgMS42MjU5MDMgLTUuMDg0OTMyIDEuNjI1OTAzIC00Ljg0NTgyOEMxLjYyNTkwMyAtNC42NzA0ODYgMS43NTM0MjUgLTQuNTQyOTY0IDEuOTM2NzM3IC00LjU0Mjk2NEMyLjE0Mzk2IC00LjU0Mjk2NCAyLjM3NTA5MyAtNC43MzQyNDcgMi4zNzUwOTMgLTQuOTczMzVaTTEuMjExNDU3IC0yLjA0ODMxOUwwLjc4MTA3MSAtMC45NDg0NDNDMC43NDEyMiAtMC44Mjg4OTIgMC43MDEzNyAtMC43MzMyNSAwLjcwMTM3IC0wLjU5Nzc1OEMwLjcwMTM3IC0wLjIwNzIyMyAxLjAwNDIzNCAwLjA3OTcwMSAxLjQyNjY1IDAuMDc5NzAxQzIuMTk5NzUxIDAuMDc5NzAxIDIuNTI2NTI2IC0xLjAzNjExNSAyLjUyNjUyNiAtMS4xMzk3MjZDMi41MjY1MjYgLTEuMjE5NDI3IDIuNDYyNzY1IC0xLjI0MzMzNyAyLjQwNjk3NCAtMS4yNDMzMzdDMi4zMTEzMzMgLTEuMjQzMzM3IDIuMjk1MzkyIC0xLjE4NzU0NyAyLjI3MTQ4MiAtMS4xMDc4NDZDMi4wODgxNjkgLTAuNDcwMjM3IDEuNzYxMzk1IC0wLjE0MzQ2MiAxLjQ0MjU5IC0wLjE0MzQ2MkMxLjM0Njk0OSAtMC4xNDM0NjIgMS4yNTEzMDggLTAuMTgzMzEzIDEuMjUxMzA4IC0wLjM5ODUwNkMxLjI1MTMwOCAtMC41ODk3ODggMS4zMDcwOTggLTAuNzMzMjUgMS40MTA3MSAtMC45ODAzMjRDMS40OTA0MTEgLTEuMTk1NTE3IDEuNTcwMTEyIC0xLjQxMDcxIDEuNjU3NzgzIC0xLjYyNTkwM0wxLjkwNDg1NyAtMi4yNzE0ODJDMS45NzY1ODggLTIuNDU0Nzk1IDIuMDcyMjI5IC0yLjcwMTg2OCAyLjA3MjIyOSAtMi44MzczNkMyLjA3MjIyOSAtMy4yMzU4NjYgMS43NTM0MjUgLTMuNTE0ODE5IDEuMzQ2OTQ5IC0zLjUxNDgxOUMwLjU3Mzg0OCAtMy41MTQ4MTkgMC4yMzkxMDMgLTIuMzk5MDA0IDAuMjM5MTAzIC0yLjI5NTM5MkMwLjIzOTEwMyAtMi4yMjM2NjEgMC4yOTQ4OTQgLTIuMTkxNzgxIDAuMzU4NjU1IC0yLjE5MTc4MUMwLjQ2MjI2NyAtMi4xOTE3ODEgMC40NzAyMzcgLTIuMjM5NjAxIDAuNDk0MTQ3IC0yLjMxOTMwM0MwLjcxNzMxIC0zLjA3NjQ2MyAxLjA4MzkzNSAtMy4yOTE2NTYgMS4zMjMwMzkgLTMuMjkxNjU2QzEuNDM0NjIgLTMuMjkxNjU2IDEuNTE0MzIxIC0zLjI1MTgwNiAxLjUxNDMyMSAtMy4wMjg2NDNDMS41MTQzMjEgLTIuOTQ4OTQxIDEuNTA2MzUxIC0yLjgzNzM2IDEuNDI2NjUgLTIuNTk4MjU3TDEuMjExNDU3IC0yLjA0ODMxOVonIGlkPSdnMi0xMDUnLz4KPHBhdGggZD0nTTMuMjkxNjU2IC00Ljk3MzM1QzMuMjkxNjU2IC01LjEyNDc4MiAzLjE3MjEwNSAtNS4yNzYyMTQgMi45ODA4MjIgLTUuMjc2MjE0QzIuNzQxNzE5IC01LjI3NjIxNCAyLjUzNDQ5NiAtNS4wNTMwNTEgMi41MzQ0OTYgLTQuODQ1ODI4QzIuNTM0NDk2IC00LjY5NDM5NiAyLjY1NDA0NyAtNC41NDI5NjQgMi44NDUzMyAtNC41NDI5NjRDMy4wODQ0MzMgLTQuNTQyOTY0IDMuMjkxNjU2IC00Ljc2NjEyNyAzLjI5MTY1NiAtNC45NzMzNVpNMS42MjU5MDMgMC4zOTg1MDZDMS41MDYzNTEgMC44ODQ2ODIgMS4xMTU4MTYgMS40MDI3NCAwLjYyOTYzOSAxLjQwMjc0QzAuNTAyMTE3IDEuNDAyNzQgMC4zODI1NjUgMS4zNzA4NTkgMC4zNjY2MjUgMS4zNjI4ODlDMC42MTM2OTkgMS4yNDMzMzcgMC42NDU1NzkgMS4wMjgxNDQgMC42NDU1NzkgMC45NTY0MTNDMC42NDU1NzkgMC43NjUxMzEgMC41MDIxMTcgMC42NjE1MTkgMC4zMzQ3NDUgMC42NjE1MTlDMC4xMDM2MTEgMC42NjE1MTkgLTAuMTExNTgyIDAuODYwNzcyIC0wLjExMTU4MiAxLjEyMzc4NkMtMC4xMTE1ODIgMS40MjY2NSAwLjE4MzMxMyAxLjYyNTkwMyAwLjYzNzYwOSAxLjYyNTkwM0MxLjEyMzc4NiAxLjYyNTkwMyAyLjAwMDQ5OCAxLjMyMzAzOSAyLjIzOTYwMSAwLjM2NjYyNUwyLjk1NjkxMiAtMi40ODY2NzVDMi45ODA4MjIgLTIuNTgyMzE2IDIuOTk2NzYyIC0yLjY0NjA3NyAyLjk5Njc2MiAtMi43NjU2MjlDMi45OTY3NjIgLTMuMjAzOTg1IDIuNjQ2MDc3IC0zLjUxNDgxOSAyLjE4MzgxMSAtMy41MTQ4MTlDMS4zMzg5NzkgLTMuNTE0ODE5IDAuODQ0ODMyIC0yLjM5OTAwNCAwLjg0NDgzMiAtMi4yOTUzOTJDMC44NDQ4MzIgLTIuMjIzNjYxIDAuOTAwNjIzIC0yLjE5MTc4MSAwLjk2NDM4NCAtMi4xOTE3ODFDMS4wNTIwNTUgLTIuMTkxNzgxIDEuMDYwMDI1IC0yLjIxNTY5MSAxLjExNTgxNiAtMi4zMzUyNDNDMS4zNTQ5MTkgLTIuODg1MTgxIDEuNzYxMzk1IC0zLjI5MTY1NiAyLjE1OTkgLTMuMjkxNjU2QzIuMzI3MjczIC0zLjI5MTY1NiAyLjQyMjkxNCAtMy4xODAwNzUgMi40MjI5MTQgLTIuOTE3MDYxQzIuNDIyOTE0IC0yLjgwNTQ3OSAyLjM5OTAwNCAtMi42OTM4OTggMi4zNzUwOTMgLTIuNTgyMzE2TDEuNjI1OTAzIDAuMzk4NTA2WicgaWQ9J2cyLTEwNicvPgo8cGF0aCBkPSdNNS41NzExMDggLTEuODA5MjE1QzUuNjk4NjMgLTEuODA5MjE1IDUuODczOTczIC0xLjgwOTIxNSA1Ljg3Mzk3MyAtMS45OTI1MjhTNS42OTg2MyAtMi4xNzU4NDEgNS41NzExMDggLTIuMTc1ODQxSDEuMDA0MjM0QzAuODc2NzEyIC0yLjE3NTg0MSAwLjcwMTM3IC0yLjE3NTg0MSAwLjcwMTM3IC0xLjk5MjUyOFMwLjg3NjcxMiAtMS44MDkyMTUgMS4wMDQyMzQgLTEuODA5MjE1SDUuNTcxMTA4WicgaWQ9J2cxLTAnLz4KPHBhdGggZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2IC0wLjUzNzk4MyAxLjgxNzE4NiAtMi45NzY4MzdDMS44MTcxODYgLTUuMjk2MTM5IDIuMzc5MDc4IC03LjI5MjY1MyAzLjc2NTg3OCAtOC43MDMzNjJDMy44ODU0MyAtOC44MTA5NTkgMy44ODU0MyAtOC44MzQ4NjkgMy44ODU0MyAtOC44NzA3MzVDMy44ODU0MyAtOC45NDI0NjYgMy44MjU2NTQgLTguOTY2Mzc2IDMuNzc3ODMzIC04Ljk2NjM3NkMzLjYyMjQxNiAtOC45NjYzNzYgMi42NDIwOTIgLTguMTA1NjA0IDIuMDU2Mjg5IC02LjkzMzk5OEMxLjQ0NjU3NSAtNS43MjY1MjYgMS4xNzE2MDYgLTQuNDQ3MzIzIDEuMTcxNjA2IC0yLjk3NjgzN0MxLjE3MTYwNiAtMS45MTI4MjcgMS4zMzg5NzkgLTAuNDkwMTYyIDEuOTYwNjQ4IDAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonIGlkPSdnNS00MCcvPgo8cGF0aCBkPSdNMy4zNzEzNTcgLTIuOTc2ODM3QzMuMzcxMzU3IC0zLjg4NTQzIDMuMjUxODA2IC01LjM2Nzg3IDIuNTgyMzE2IC02Ljc1NDY3QzEuODc2OTYxIC04LjE4OTI5IDAuODk2NjM4IC04Ljk2NjM3NiAwLjc2NTEzMSAtOC45NjYzNzZDMC43MTczMSAtOC45NjYzNzYgMC42NTc1MzQgLTguOTQyNDY2IDAuNjU3NTM0IC04Ljg3MDczNUMwLjY1NzUzNCAtOC44MzQ4NjkgMC42NTc1MzQgLTguODEwOTU5IDAuODYwNzcyIC04LjYwNzcyMUMyLjA1NjI4OSAtNy40MDAyNDkgMi43MjU3NzggLTUuNDI3NjQ2IDIuNzI1Nzc4IC0yLjk4ODc5MkMyLjcyNTc3OCAtMC42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgMC43NzcwODYgMi43Mzc3MzNDMC42NTc1MzQgMi44NDUzMyAwLjY1NzUzNCAyLjg2OTI0IDAuNjU3NTM0IDIuOTA1MTA2QzAuNjU3NTM0IDIuOTc2ODM3IDAuNzE3MzEgMy4wMDA3NDcgMC43NjUxMzEgMy4wMDA3NDdDMC45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgMC45NjgzNjlDMy4wOTYzODkgLTAuMjUxMDU5IDMuMzcxMzU3IC0xLjU0MjIxNyAzLjM3MTM1NyAtMi45NzY4MzdaJyBpZD0nZzUtNDEnLz4KPHBhdGggZD0nTTQuNzcwMTEyIC0yLjc2MTY0NEg4LjA2OTczOEM4LjIzNzExMSAtMi43NjE2NDQgOC40NTIzMDQgLTIuNzYxNjQ0IDguNDUyMzA0IC0yLjk3NjgzN0M4LjQ1MjMwNCAtMy4yMDM5ODUgOC4yNDkwNjYgLTMuMjAzOTg1IDguMDY5NzM4IC0zLjIwMzk4NUg0Ljc3MDExMlYtNi41MDM2MTFDNC43NzAxMTIgLTYuNjcwOTg0IDQuNzcwMTEyIC02Ljg4NjE3NyA0LjU1NDkxOSAtNi44ODYxNzdDNC4zMjc3NzEgLTYuODg2MTc3IDQuMzI3NzcxIC02LjY4MjkzOSA0LjMyNzc3MSAtNi41MDM2MTFWLTMuMjAzOTg1SDEuMDI4MTQ0QzAuODYwNzcyIC0zLjIwMzk4NSAwLjY0NTU3OSAtMy4yMDM5ODUgMC42NDU1NzkgLTIuOTg4NzkyQzAuNjQ1NTc5IC0yLjc2MTY0NCAwLjg0ODgxNyAtMi43NjE2NDQgMS4wMjgxNDQgLTIuNzYxNjQ0SDQuMzI3NzcxVjAuNTM3OTgzQzQuMzI3NzcxIDAuNzA1MzU1IDQuMzI3NzcxIDAuOTIwNTQ4IDQuNTQyOTY0IDAuOTIwNTQ4QzQuNzcwMTEyIDAuOTIwNTQ4IDQuNzcwMTEyIDAuNzE3MzEgNC43NzAxMTIgMC41Mzc5ODNWLTIuNzYxNjQ0WicgaWQ9J2c1LTQzJy8+CjxwYXRoIGQ9J001LjM1NTkxNSAtMy44MjU2NTRDNS4zNTU5MTUgLTQuODE3OTMzIDUuMjk2MTM5IC01Ljc4NjMwMSA0Ljg2NTc1MyAtNi42OTQ4OTRDNC4zNzU1OTIgLTcuNjg3MTczIDMuNTE0ODE5IC03Ljk1MDE4NyAyLjkyOTAxNiAtNy45NTAxODdDMi4yMzU2MTYgLTcuOTUwMTg3IDEuMzg2OCAtNy42MDM0ODcgMC45NDQ0NTggLTYuNjExMjA4QzAuNjA5NzE0IC01Ljg1ODAzMiAwLjQ5MDE2MiAtNS4xMTY4MTIgMC40OTAxNjIgLTMuODI1NjU0QzAuNDkwMTYyIC0yLjY2NjAwMiAwLjU3Mzg0OCAtMS43OTMyNzUgMS4wMDQyMzQgLTAuOTQ0NDU4QzEuNDcwNDg2IC0wLjAzNTg2NiAyLjI5NTM5MiAwLjI1MTA1OSAyLjkxNzA2MSAwLjI1MTA1OUMzLjk1NzE2MSAwLjI1MTA1OSA0LjU1NDkxOSAtMC4zNzA2MSA0LjkwMTYxOSAtMS4wNjQwMUM1LjMzMjAwNSAtMS45NjA2NDggNS4zNTU5MTUgLTMuMTMyMjU0IDUuMzU1OTE1IC0zLjgyNTY1NFpNMi45MTcwNjEgMC4wMTE5NTVDMi41MzQ0OTYgMC4wMTE5NTUgMS43NTc0MSAtMC4yMDMyMzggMS41MzAyNjIgLTEuNTA2MzUxQzEuMzk4NzU1IC0yLjIyMzY2MSAxLjM5ODc1NSAtMy4xMzIyNTQgMS4zOTg3NTUgLTMuOTY5MTE2QzEuMzk4NzU1IC00Ljk0OTQ0IDEuMzk4NzU1IC01LjgzNDEyMiAxLjU5MDAzNyAtNi41Mzk0NzdDMS43OTMyNzUgLTcuMzQwNDczIDIuNDAyOTg5IC03LjcxMTA4MyAyLjkxNzA2MSAtNy43MTEwODNDMy4zNzEzNTcgLTcuNzExMDgzIDQuMDY0NzU3IC03LjQzNjExNSA0LjI5MTkwNSAtNi40MDc5N0M0LjQ0NzMyMyAtNS43MjY1MjYgNC40NDczMjMgLTQuNzgyMDY3IDQuNDQ3MzIzIC0zLjk2OTExNkM0LjQ0NzMyMyAtMy4xNjgxMiA0LjQ0NzMyMyAtMi4yNTk1MjcgNC4zMTU4MTYgLTEuNTMwMjYyQzQuMDg4NjY3IC0wLjIxNTE5MyAzLjMzNTQ5MiAwLjAxMTk1NSAyLjkxNzA2MSAwLjAxMTk1NVonIGlkPSdnNS00OCcvPgo8cGF0aCBkPSdNOC4wNjk3MzggLTMuODczNDc0QzguMjM3MTExIC0zLjg3MzQ3NCA4LjQ1MjMwNCAtMy44NzM0NzQgOC40NTIzMDQgLTQuMDg4NjY3QzguNDUyMzA0IC00LjMxNTgxNiA4LjI0OTA2NiAtNC4zMTU4MTYgOC4wNjk3MzggLTQuMzE1ODE2SDEuMDI4MTQ0QzAuODYwNzcyIC00LjMxNTgxNiAwLjY0NTU3OSAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMTAwNjIzQzAuNjQ1NTc5IC0zLjg3MzQ3NCAwLjg0ODgxNyAtMy44NzM0NzQgMS4wMjgxNDQgLTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOCAtMS42NDk4MTNDOC4yMzcxMTEgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS44NjUwMDZDOC40NTIzMDQgLTIuMDkyMTU0IDguMjQ5MDY2IC0yLjA5MjE1NCA4LjA2OTczOCAtMi4wOTIxNTRIMS4wMjgxNDRDMC44NjA3NzIgLTIuMDkyMTU0IDAuNjQ1NTc5IC0yLjA5MjE1NCAwLjY0NTU3OSAtMS44NzY5NjFDMC42NDU1NzkgLTEuNjQ5ODEzIDAuODQ4ODE3IC0xLjY0OTgxMyAxLjAyODE0NCAtMS42NDk4MTNIOC4wNjk3MzhaJyBpZD0nZzUtNjEnLz4KPHBhdGggZD0nTTQuNjE0Njk1IC0zLjE5MjAzQzQuNjE0Njk1IC0zLjgzNzYwOSA0LjYxNDY5NSAtNC4zMTU4MTYgNC4wODg2NjcgLTQuNzgyMDY3QzMuNjcwMjM3IC01LjE2NDYzMyAzLjEzMjI1NCAtNS4zMzIwMDUgMi42MDYyMjcgLTUuMzMyMDA1QzEuNjI1OTAzIC01LjMzMjAwNSAwLjg3MjcyNyAtNC42ODY0MjYgMC44NzI3MjcgLTMuOTA5MzRDMC44NzI3MjcgLTMuNTYyNjQgMS4wOTk4NzUgLTMuMzk1MjY4IDEuMzc0ODQ0IC0zLjM5NTI2OEMxLjY2MTc2OCAtMy4zOTUyNjggMS44NjUwMDYgLTMuNTk4NTA2IDEuODY1MDA2IC0zLjg4NTQzQzEuODY1MDA2IC00LjM3NTU5MiAxLjQzNDYyIC00LjM3NTU5MiAxLjI1NTI5MyAtNC4zNzU1OTJDMS41MzAyNjIgLTQuODc3NzA5IDIuMTA0MTEgLTUuMDkyOTAyIDIuNTgyMzE2IC01LjA5MjkwMkMzLjEzMjI1NCAtNS4wOTI5MDIgMy44Mzc2MDkgLTQuNjM4NjA1IDMuODM3NjA5IC0zLjU2MjY0Vi0zLjA4NDQzM0MxLjQzNDYyIC0zLjA0ODU2OCAwLjUyNjAyNyAtMi4wNDQzMzQgMC41MjYwMjcgLTEuMTIzNzg2QzAuNTI2MDI3IC0wLjE3OTMyOCAxLjYyNTkwMyAwLjExOTU1MiAyLjM1NTE2OCAwLjExOTU1MkMzLjE0NDIwOSAwLjExOTU1MiAzLjY4MjE5MiAtMC4zNTg2NTUgMy45MDkzNCAtMC45MzI1MDNDMy45NTcxNjEgLTAuMzcwNjEgNC4zMjc3NzEgMC4wNTk3NzYgNC44NDE4NDMgMC4wNTk3NzZDNS4wOTI5MDIgMC4wNTk3NzYgNS43ODYzMDEgLTAuMTA3NTk3IDUuNzg2MzAxIC0xLjA2NDAxVi0xLjczMzQ5OUg1LjUyMzI4OFYtMS4wNjQwMUM1LjUyMzI4OCAtMC4zODI1NjUgNS4yMzYzNjQgLTAuMjg2OTI0IDUuMDY4OTkxIC0wLjI4NjkyNEM0LjYxNDY5NSAtMC4yODY5MjQgNC42MTQ2OTUgLTAuOTIwNTQ4IDQuNjE0Njk1IC0xLjA5OTg3NVYtMy4xOTIwM1pNMy44Mzc2MDkgLTEuNjg1Njc5QzMuODM3NjA5IC0wLjUxNDA3MiAyLjk2NDg4MiAtMC4xMTk1NTIgMi40NTA4MDkgLTAuMTE5NTUyQzEuODY1MDA2IC0wLjExOTU1MiAxLjM3NDg0NCAtMC41NDk5MzggMS4zNzQ4NDQgLTEuMTIzNzg2QzEuMzc0ODQ0IC0yLjcwMTg2OCAzLjQwNzIyMyAtMi44NDUzMyAzLjgzNzYwOSAtMi44NjkyNFYtMS42ODU2NzlaJyBpZD0nZzUtOTcnLz4KPHBhdGggZD0nTTQuMzI3NzcxIC00LjQyMzQxMkM0LjE4NDMwOSAtNC40MjM0MTIgMy43NDE5NjggLTQuNDIzNDEyIDMuNzQxOTY4IC0zLjkzMzI1QzMuNzQxOTY4IC0zLjY0NjMyNiAzLjk0NTIwNSAtMy40NDMwODggNC4yMzIxMyAtMy40NDMwODhDNC41MDcwOTggLTMuNDQzMDg4IDQuNzM0MjQ3IC0zLjYxMDQ2MSA0LjczNDI0NyAtMy45NTcxNjFDNC43MzQyNDcgLTQuNzU4MTU3IDMuODk3Mzg1IC01LjMzMjAwNSAyLjkyOTAxNiAtNS4zMzIwMDVDMS41MzAyNjIgLTUuMzMyMDA1IDAuNDE4NDMxIC00LjA4ODY2NyAwLjQxODQzMSAtMi41ODIzMTZDMC40MTg0MzEgLTEuMDUyMDU1IDEuNTY2MTI3IDAuMTE5NTUyIDIuOTE3MDYxIDAuMTE5NTUyQzQuNDk1MTQzIDAuMTE5NTUyIDQuODUzNzk4IC0xLjMxNTA2OCA0Ljg1Mzc5OCAtMS40MjI2NjVTNC43NzAxMTIgLTEuNTMwMjYyIDQuNzM0MjQ3IC0xLjUzMDI2MkM0LjYyNjY1IC0xLjUzMDI2MiA0LjYxNDY5NSAtMS40OTQzOTYgNC41Nzg4MjkgLTEuMzUwOTM0QzQuMzE1ODE2IC0wLjUwMjExNyAzLjY3MDIzNyAtMC4xNDM0NjIgMy4wMjQ2NTggLTAuMTQzNDYyQzIuMjk1MzkyIC0wLjE0MzQ2MiAxLjMyNzAyNCAtMC43NzcwODYgMS4zMjcwMjQgLTIuNTk0MjcxQzEuMzI3MDI0IC00LjU3ODgyOSAyLjM0MzIxMyAtNS4wNjg5OTEgMi45NDA5NzEgLTUuMDY4OTkxQzMuMzk1MjY4IC01LjA2ODk5MSA0LjA1MjgwMiAtNC44ODk2NjQgNC4zMjc3NzEgLTQuNDIzNDEyWicgaWQ9J2c1LTk5Jy8+CjxwYXRoIGQ9J000LjU3ODgyOSAtMi43NzM1OTlDNC44NDE4NDMgLTIuNzczNTk5IDQuODY1NzUzIC0yLjc3MzU5OSA0Ljg2NTc1MyAtMy4wMDA3NDdDNC44NjU3NTMgLTQuMjA4MjE5IDQuMjIwMTc0IC01LjMzMjAwNSAyLjc3MzU5OSAtNS4zMzIwMDVDMS40MTA3MSAtNS4zMzIwMDUgMC4zNTg2NTUgLTQuMTAwNjIzIDAuMzU4NjU1IC0yLjYxODE4MkMwLjM1ODY1NSAtMS4wNDAxIDEuNTc4MDgyIDAuMTE5NTUyIDIuOTA1MTA2IDAuMTE5NTUyQzQuMzI3NzcxIDAuMTE5NTUyIDQuODY1NzUzIC0xLjE3MTYwNiA0Ljg2NTc1MyAtMS40MjI2NjVDNC44NjU3NTMgLTEuNDk0Mzk2IDQuODA1OTc4IC0xLjU0MjIxNyA0LjczNDI0NyAtMS41NDIyMTdDNC42Mzg2MDUgLTEuNTQyMjE3IDQuNjE0Njk1IC0xLjQ4MjQ0MSA0LjU5MDc4NSAtMS40MjI2NjVDNC4yNzk5NSAtMC40MTg0MzEgMy40Nzg5NTQgLTAuMTQzNDYyIDIuOTc2ODM3IC0wLjE0MzQ2MlMxLjI2NzI0OCAtMC40NzgyMDcgMS4yNjcyNDggLTIuNTQ2NDUxVi0yLjc3MzU5OUg0LjU3ODgyOVpNMS4yNzkyMDMgLTMuMDAwNzQ3QzEuMzc0ODQ0IC00Ljg3NzcwOSAyLjQyNjg5OSAtNS4wOTI5MDIgMi43NjE2NDQgLTUuMDkyOTAyQzQuMDQwODQ3IC01LjA5MjkwMiA0LjExMjU3OCAtMy40MDcyMjMgNC4xMjQ1MzMgLTMuMDAwNzQ3SDEuMjc5MjAzWicgaWQ9J2c1LTEwMScvPgo8cGF0aCBkPSdNMi4wODAxOTkgLTcuMzY0Mzg0QzIuMDgwMTk5IC03LjY3NTIxOCAxLjgyOTE0MSAtNy45NTAxODcgMS40OTQzOTYgLTcuOTUwMTg3QzEuMTgzNTYyIC03Ljk1MDE4NyAwLjkyMDU0OCAtNy42OTkxMjggMC45MjA1NDggLTcuMzc2MzM5QzAuOTIwNTQ4IC03LjAxNzY4NCAxLjIwNzQ3MiAtNi43OTA1MzUgMS40OTQzOTYgLTYuNzkwNTM1QzEuODY1MDA2IC02Ljc5MDUzNSAyLjA4MDE5OSAtNy4xMDEzNyAyLjA4MDE5OSAtNy4zNjQzODRaTTAuNDMwMzg2IC01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTcgLTQuNzk0MDIyIDEuMzAzMTEzIC00LjcyMjI5MSAxLjMwMzExMyAtNC4xMzY0ODhWLTAuODg0NjgyQzEuMzAzMTEzIC0wLjM0NjcgMS4xNzE2MDYgLTAuMzQ2NyAwLjM5NDUyMSAtMC4zNDY3VjBDMC43MjkyNjUgLTAuMDIzOTEgMS4zMDMxMTMgLTAuMDIzOTEgMS42NDk4MTMgLTAuMDIzOTFDMS43ODEzMiAtMC4wMjM5MSAyLjQ3NDcyIC0wLjAyMzkxIDIuODgxMTk2IDBWLTAuMzQ2N0MyLjEwNDExIC0wLjM0NjcgMi4wNTYyODkgLTAuNDA2NDc2IDIuMDU2Mjg5IC0wLjg3MjcyN1YtNS4yNzIyMjlMMC40MzAzODYgLTUuMTQwNzIyWicgaWQ9J2c1LTEwNScvPgo8cGF0aCBkPSdNOC41NzE4NTYgLTIuOTA1MTA2QzguNTcxODU2IC00LjAxNjkzNiA4LjU3MTg1NiAtNC4zNTE2ODEgOC4yOTY4ODcgLTQuNzM0MjQ3QzcuOTUwMTg3IC01LjIwMDQ5OCA3LjM4ODI5NCAtNS4yNzIyMjkgNi45ODE4MTggLTUuMjcyMjI5QzUuOTg5NTM5IC01LjI3MjIyOSA1LjQ4NzQyMiAtNC41NTQ5MTkgNS4yOTYxMzkgLTQuMDg4NjY3QzUuMTI4NzY3IC01LjAwOTIxNSA0LjQ4MzE4OCAtNS4yNzIyMjkgMy43MzAwMTIgLTUuMjcyMjI5QzIuNTcwMzYxIC01LjI3MjIyOSAyLjExNjA2NSAtNC4yNzk5NSAyLjAyMDQyMyAtNC4wNDA4NDdIMi4wMDg0NjhWLTUuMjcyMjI5TDAuMzgyNTY1IC01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTcgLTQuNzk0MDIyIDEuMjkxMTU4IC00LjcxMDMzNiAxLjI5MTE1OCAtNC4xMjQ1MzNWLTAuODg0NjgyQzEuMjkxMTU4IC0wLjM0NjcgMS4xNTk2NTEgLTAuMzQ2NyAwLjM4MjU2NSAtMC4zNDY3VjBDMC42OTM0IC0wLjAyMzkxIDEuMzM4OTc5IC0wLjAyMzkxIDEuNjczNzI0IC0wLjAyMzkxQzIuMDIwNDIzIC0wLjAyMzkxIDIuNjY2MDAyIC0wLjAyMzkxIDIuOTc2ODM3IDBWLTAuMzQ2N0MyLjIxMTcwNiAtMC4zNDY3IDIuMDY4MjQ0IC0wLjM0NjcgMi4wNjgyNDQgLTAuODg0NjgyVi0zLjEwODM0NEMyLjA2ODI0NCAtNC4zNjM2MzYgMi44OTMxNTEgLTUuMDMzMTI2IDMuNjM0MzcxIC01LjAzMzEyNlM0LjU0Mjk2NCAtNC40MjM0MTIgNC41NDI5NjQgLTMuNjk0MTQ3Vi0wLjg4NDY4MkM0LjU0Mjk2NCAtMC4zNDY3IDQuNDExNDU3IC0wLjM0NjcgMy42MzQzNzEgLTAuMzQ2N1YwQzMuOTQ1MjA1IC0wLjAyMzkxIDQuNTkwNzg1IC0wLjAyMzkxIDQuOTI1NTI5IC0wLjAyMzkxQzUuMjcyMjI5IC0wLjAyMzkxIDUuOTE3ODA4IC0wLjAyMzkxIDYuMjI4NjQzIDBWLTAuMzQ2N0M1LjQ2MzUxMiAtMC4zNDY3IDUuMzIwMDUgLTAuMzQ2NyA1LjMyMDA1IC0wLjg4NDY4MlYtMy4xMDgzNDRDNS4zMjAwNSAtNC4zNjM2MzYgNi4xNDQ5NTYgLTUuMDMzMTI2IDYuODg2MTc3IC01LjAzMzEyNlM3Ljc5NDc3IC00LjQyMzQxMiA3Ljc5NDc3IC0zLjY5NDE0N1YtMC44ODQ2ODJDNy43OTQ3NyAtMC4zNDY3IDcuNjYzMjYzIC0wLjM0NjcgNi44ODYxNzcgLTAuMzQ2N1YwQzcuMTk3MDExIC0wLjAyMzkxIDcuODQyNTkgLTAuMDIzOTEgOC4xNzczMzUgLTAuMDIzOTFDOC41MjQwMzUgLTAuMDIzOTEgOS4xNjk2MTQgLTAuMDIzOTEgOS40ODA0NDggMFYtMC4zNDY3QzguODgyNjkgLTAuMzQ2NyA4LjU4MzgxMSAtMC4zNDY3IDguNTcxODU2IC0wLjcwNTM1NVYtMi45MDUxMDZaJyBpZD0nZzUtMTA5Jy8+CjxwYXRoIGQ9J001LjMyMDA1IC0yLjkwNTEwNkM1LjMyMDA1IC00LjAxNjkzNiA1LjMyMDA1IC00LjM1MTY4MSA1LjA0NTA4MSAtNC43MzQyNDdDNC42OTgzODEgLTUuMjAwNDk4IDQuMTM2NDg4IC01LjI3MjIyOSAzLjczMDAxMiAtNS4yNzIyMjlDMi41NzAzNjEgLTUuMjcyMjI5IDIuMTE2MDY1IC00LjI3OTk1IDIuMDIwNDIzIC00LjA0MDg0N0gyLjAwODQ2OFYtNS4yNzIyMjlMMC4zODI1NjUgLTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE5NTUxNyAtNC43OTQwMjIgMS4yOTExNTggLTQuNzEwMzM2IDEuMjkxMTU4IC00LjEyNDUzM1YtMC44ODQ2ODJDMS4yOTExNTggLTAuMzQ2NyAxLjE1OTY1MSAtMC4zNDY3IDAuMzgyNTY1IC0wLjM0NjdWMEMwLjY5MzQgLTAuMDIzOTEgMS4zMzg5NzkgLTAuMDIzOTEgMS42NzM3MjQgLTAuMDIzOTFDMi4wMjA0MjMgLTAuMDIzOTEgMi42NjYwMDIgLTAuMDIzOTEgMi45NzY4MzcgMFYtMC4zNDY3QzIuMjExNzA2IC0wLjM0NjcgMi4wNjgyNDQgLTAuMzQ2NyAyLjA2ODI0NCAtMC44ODQ2ODJWLTMuMTA4MzQ0QzIuMDY4MjQ0IC00LjM2MzYzNiAyLjg5MzE1MSAtNS4wMzMxMjYgMy42MzQzNzEgLTUuMDMzMTI2UzQuNTQyOTY0IC00LjQyMzQxMiA0LjU0Mjk2NCAtMy42OTQxNDdWLTAuODg0NjgyQzQuNTQyOTY0IC0wLjM0NjcgNC40MTE0NTcgLTAuMzQ2NyAzLjYzNDM3MSAtMC4zNDY3VjBDMy45NDUyMDUgLTAuMDIzOTEgNC41OTA3ODUgLTAuMDIzOTEgNC45MjU1MjkgLTAuMDIzOTFDNS4yNzIyMjkgLTAuMDIzOTEgNS45MTc4MDggLTAuMDIzOTEgNi4yMjg2NDMgMFYtMC4zNDY3QzUuNjMwODg0IC0wLjM0NjcgNS4zMzIwMDUgLTAuMzQ2NyA1LjMyMDA1IC0wLjcwNTM1NVYtMi45MDUxMDZaJyBpZD0nZzUtMTEwJy8+CjxwYXRoIGQ9J001LjQ4NzQyMiAtMi41NTg0MDZDNS40ODc0MjIgLTQuMTAwNjIzIDQuMzE1ODE2IC01LjMzMjAwNSAyLjkyOTAxNiAtNS4zMzIwMDVDMS40OTQzOTYgLTUuMzMyMDA1IDAuMzU4NjU1IC00LjA2NDc1NyAwLjM1ODY1NSAtMi41NTg0MDZDMC4zNTg2NTUgLTEuMDI4MTQ0IDEuNTU0MTcyIDAuMTE5NTUyIDIuOTE3MDYxIDAuMTE5NTUyQzQuMzI3NzcxIDAuMTE5NTUyIDUuNDg3NDIyIC0xLjA1MjA1NSA1LjQ4NzQyMiAtMi41NTg0MDZaTTIuOTI5MDE2IC0wLjE0MzQ2MkMyLjQ4NjY3NSAtMC4xNDM0NjIgMS45NDg2OTIgLTAuMzM0NzQ1IDEuNjAxOTkzIC0wLjkyMDU0OEMxLjI3OTIwMyAtMS40NTg1MzEgMS4yNjcyNDggLTIuMTYzODg1IDEuMjY3MjQ4IC0yLjY2NjAwMkMxLjI2NzI0OCAtMy4xMjAyOTkgMS4yNjcyNDggLTMuODQ5NTY0IDEuNjM3ODU4IC00LjM4NzU0N0MxLjk3MjYwMyAtNC45MDE2MTkgMi40OTg2MyAtNS4wOTI5MDIgMi45MTcwNjEgLTUuMDkyOTAyQzMuMzgzMzEzIC01LjA5MjkwMiAzLjg4NTQzIC00Ljg3NzcwOSA0LjIwODIxOSAtNC40MTE0NTdDNC41Nzg4MjkgLTMuODYxNTE5IDQuNTc4ODI5IC0zLjEwODM0NCA0LjU3ODgyOSAtMi42NjYwMDJDNC41Nzg4MjkgLTIuMjQ3NTcyIDQuNTc4ODI5IC0xLjUwNjM1MSA0LjI2Nzk5NSAtMC45NDQ0NThDMy45MzMyNSAtMC4zNzA2MSAzLjM4MzMxMyAtMC4xNDM0NjIgMi45MjkwMTYgLTAuMTQzNDYyWicgaWQ9J2c1LTExMScvPgo8cGF0aCBkPSdNMi45MjkwMTYgMS45NzI2MDNDMi4xNjM4ODUgMS45NzI2MDMgMi4wMjA0MjMgMS45NzI2MDMgMi4wMjA0MjMgMS40MzQ2MlYtMC42NDU1NzlDMi4yMzU2MTYgLTAuMzQ2NyAyLjcyNTc3OCAwLjExOTU1MiAzLjQ5MDkwOSAwLjExOTU1MkM0Ljg2NTc1MyAwLjExOTU1MiA2LjA3MzIyNSAtMS4wNDAxIDYuMDczMjI1IC0yLjU4MjMxNkM2LjA3MzIyNSAtNC4xMDA2MjMgNC45NDk0NCAtNS4yNzIyMjkgMy42NDYzMjYgLTUuMjcyMjI5QzIuNTk0MjcxIC01LjI3MjIyOSAyLjAzMjM3OSAtNC41MTkwNTQgMS45OTY1MTMgLTQuNDcxMjMzVi01LjI3MjIyOUwwLjMzNDc0NSAtNS4xNDA3MjJWLTQuNzk0MDIyQzEuMTcxNjA2IC00Ljc5NDAyMiAxLjI0MzMzNyAtNC43MTAzMzYgMS4yNDMzMzcgLTQuMTg0MzA5VjEuNDM0NjJDMS4yNDMzMzcgMS45NzI2MDMgMS4xMTE4MzEgMS45NzI2MDMgMC4zMzQ3NDUgMS45NzI2MDNWMi4zMTkzMDNDMC42NDU1NzkgMi4yOTUzOTIgMS4yOTExNTggMi4yOTUzOTIgMS42MjU5MDMgMi4yOTUzOTJDMS45NzI2MDMgMi4yOTUzOTIgMi42MTgxODIgMi4yOTUzOTIgMi45MjkwMTYgMi4zMTkzMDNWMS45NzI2MDNaTTIuMDIwNDIzIC0zLjgxMzY5OUMyLjAyMDQyMyAtNC4wNDA4NDcgMi4wMjA0MjMgLTQuMDUyODAyIDIuMTUxOTMgLTQuMjQ0MDg1QzIuNTEwNTg1IC00Ljc4MjA2NyAzLjA5NjM4OSAtNS4wMDkyMTUgMy41NTA2ODUgLTUuMDA5MjE1QzQuNDQ3MzIzIC01LjAwOTIxNSA1LjE2NDYzMyAtMy45MjEyOTUgNS4xNjQ2MzMgLTIuNTgyMzE2QzUuMTY0NjMzIC0xLjE1OTY1MSA0LjM1MTY4MSAtMC4xMTk1NTIgMy40MzExMzMgLTAuMTE5NTUyQzMuMDYwNTIzIC0wLjExOTU1MiAyLjcxMzgyMyAtMC4yNzQ5NjkgMi40NzQ3MiAtMC41MDIxMTdDMi4xOTk3NTEgLTAuNzc3MDg2IDIuMDIwNDIzIC0xLjAxNjE4OSAyLjAyMDQyMyAtMS4zNTA5MzRWLTMuODEzNjk5WicgaWQ9J2c1LTExMicvPgo8cGF0aCBkPSdNMS45OTY1MTMgLTIuNzg1NTU0QzEuOTk2NTEzIC0zLjk0NTIwNSAyLjQ3NDcyIC01LjAzMzEyNiAzLjM5NTI2OCAtNS4wMzMxMjZDMy40OTA5MDkgLTUuMDMzMTI2IDMuNTE0ODE5IC01LjAzMzEyNiAzLjU2MjY0IC01LjAyMTE3MUMzLjQ2Njk5OSAtNC45NzMzNSAzLjI3NTcxNiAtNC45MDE2MTkgMy4yNzU3MTYgLTQuNTc4ODI5QzMuMjc1NzE2IC00LjIzMjEzIDMuNTUwNjg1IC00LjEwMDYyMyAzLjc0MTk2OCAtNC4xMDA2MjNDMy45ODEwNzEgLTQuMTAwNjIzIDQuMjIwMTc0IC00LjI1NjA0IDQuMjIwMTc0IC00LjU3ODgyOUM0LjIyMDE3NCAtNC45Mzc0ODQgMy44OTczODUgLTUuMjcyMjI5IDMuMzgzMzEzIC01LjI3MjIyOUMyLjM2NzEyMyAtNS4yNzIyMjkgMi4wMjA0MjMgLTQuMTcyMzU0IDEuOTQ4NjkyIC0zLjk0NTIwNUgxLjkzNjczN1YtNS4yNzIyMjlMMC4zMzQ3NDUgLTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE0NzY5NiAtNC43OTQwMjIgMS4yNDMzMzcgLTQuNzEwMzM2IDEuMjQzMzM3IC00LjEyNDUzM1YtMC44ODQ2ODJDMS4yNDMzMzcgLTAuMzQ2NyAxLjExMTgzMSAtMC4zNDY3IDAuMzM0NzQ1IC0wLjM0NjdWMEMwLjY2OTQ4OSAtMC4wMjM5MSAxLjMyNzAyNCAtMC4wMjM5MSAxLjY4NTY3OSAtMC4wMjM5MUMyLjAwODQ2OCAtMC4wMjM5MSAyLjg1NzI4NSAtMC4wMjM5MSAzLjEzMjI1NCAwVi0wLjM0NjdIMi44OTMxNTFDMi4wMjA0MjMgLTAuMzQ2NyAxLjk5NjUxMyAtMC40NzgyMDcgMS45OTY1MTMgLTAuOTA4NTkzVi0yLjc4NTU1NFonIGlkPSdnNS0xMTQnLz4KPHBhdGggZD0nTTMuOTIxMjk1IC01LjA1NzAzNkMzLjkyMTI5NSAtNS4yNzIyMjkgMy45MjEyOTUgLTUuMzMyMDA1IDMuODAxNzQzIC01LjMzMjAwNUMzLjcwNjEwMiAtNS4zMzIwMDUgMy40Nzg5NTQgLTUuMDY4OTkxIDMuMzk1MjY4IC00Ljk2MTM5NUMzLjAyNDY1OCAtNS4yNjAyNzQgMi42NTQwNDcgLTUuMzMyMDA1IDIuMjcxNDgyIC01LjMzMjAwNUMwLjgyNDkwNyAtNS4zMzIwMDUgMC4zOTQ1MjEgLTQuNTQyOTY0IDAuMzk0NTIxIC0zLjg4NTQzQzAuMzk0NTIxIC0zLjc1MzkyMyAwLjM5NDUyMSAtMy4zMzU0OTIgMC44NDg4MTcgLTIuOTE3MDYxQzEuMjMxMzgyIC0yLjU4MjMxNiAxLjYzNzg1OCAtMi40OTg2MyAyLjE4Nzc5NiAtMi4zOTEwMzRDMi44NDUzMyAtMi4yNTk1MjcgMy4wMDA3NDcgLTIuMjIzNjYxIDMuMjk5NjI2IC0xLjk4NDU1OEMzLjUxNDgxOSAtMS44MDUyMyAzLjY3MDIzNyAtMS41NDIyMTcgMy42NzAyMzcgLTEuMjA3NDcyQzMuNjcwMjM3IC0wLjY5MzQgMy4zNzEzNTcgLTAuMTE5NTUyIDIuMzE5MzAzIC0wLjExOTU1MkMxLjUzMDI2MiAtMC4xMTk1NTIgMC45NTY0MTMgLTAuNTczODQ4IDAuNjkzNCAtMS43NjkzNjVDMC42NDU1NzkgLTEuOTg0NTU4IDAuNjQ1NTc5IC0xLjk5NjUxMyAwLjYzMzYyNCAtMi4wMDg0NjhDMC42MDk3MTQgLTIuMDU2Mjg5IDAuNTYxODkzIC0yLjA1NjI4OSAwLjUyNjAyNyAtMi4wNTYyODlDMC4zOTQ1MjEgLTIuMDU2Mjg5IDAuMzk0NTIxIC0xLjk5NjUxMyAwLjM5NDUyMSAtMS43ODEzMlYtMC4xNTU0MTdDMC4zOTQ1MjEgMC4wNTk3NzYgMC4zOTQ1MjEgMC4xMTk1NTIgMC41MTQwNzIgMC4xMTk1NTJDMC41NzM4NDggMC4xMTk1NTIgMC41ODU4MDMgMC4xMDc1OTcgMC43ODkwNDEgLTAuMTQzNDYyQzAuODQ4ODE3IC0wLjIyNzE0OCAwLjg0ODgxNyAtMC4yNTEwNTkgMS4wMjgxNDQgLTAuNDQyMzQxQzEuNDgyNDQxIDAuMTE5NTUyIDIuMTI4MDIgMC4xMTk1NTIgMi4zMzEyNTggMC4xMTk1NTJDMy41ODY1NSAwLjExOTU1MiA0LjIwODIxOSAtMC41NzM4NDggNC4yMDgyMTkgLTEuNTE4MzA2QzQuMjA4MjE5IC0yLjE2Mzg4NSAzLjgxMzY5OSAtMi41NDY0NTEgMy43MDYxMDIgLTIuNjU0MDQ3QzMuMjc1NzE2IC0zLjAyNDY1OCAyLjk1MjkyNyAtMy4wOTYzODkgMi4xNjM4ODUgLTMuMjM5ODUxQzEuODA1MjMgLTMuMzExNTgyIDAuOTMyNTAzIC0zLjQ3ODk1NCAwLjkzMjUwMyAtNC4xOTYyNjRDMC45MzI1MDMgLTQuNTY2ODc0IDEuMTgzNTYyIC01LjExNjgxMiAyLjI1OTUyNyAtNS4xMTY4MTJDMy41NjI2NCAtNS4xMTY4MTIgMy42MzQzNzEgLTQuMDA0OTgxIDMuNjU4MjgxIC0zLjYzNDM3MUMzLjY3MDIzNyAtMy41Mzg3MyAzLjc1MzkyMyAtMy41Mzg3MyAzLjc4OTc4OCAtMy41Mzg3M0MzLjkyMTI5NSAtMy41Mzg3MyAzLjkyMTI5NSAtMy41OTg1MDYgMy45MjEyOTUgLTMuODEzNjk5Vi01LjA1NzAzNlonIGlkPSdnNS0xMTUnLz4KPHBhdGggZD0nTTIuMDA4NDY4IC00LjgwNTk3OEgzLjY5NDE0N1YtNS4xNTI2NzdIMi4wMDg0NjhWLTcuMzUyNDI4SDEuNzQ1NDU1QzEuNzMzNDk5IC02LjIyODY0MyAxLjMwMzExMyAtNS4wODA5NDYgMC4yMTUxOTMgLTUuMDQ1MDgxVi00LjgwNTk3OEgxLjIzMTM4MlYtMS40ODI0NDFDMS4yMzEzODIgLTAuMTU1NDE3IDIuMTE2MDY1IDAuMTE5NTUyIDIuNzQ5Njg5IDAuMTE5NTUyQzMuNTAyODY0IDAuMTE5NTUyIDMuODk3Mzg1IC0wLjYyMTY2OSAzLjg5NzM4NSAtMS40ODI0NDFWLTIuMTYzODg1SDMuNjM0MzcxVi0xLjUwNjM1MUMzLjYzNDM3MSAtMC42NDU1NzkgMy4yODc2NzEgLTAuMTQzNDYyIDIuODIxNDIgLTAuMTQzNDYyQzIuMDA4NDY4IC0wLjE0MzQ2MiAyLjAwODQ2OCAtMS4yNTUyOTMgMi4wMDg0NjggLTEuNDU4NTMxVi00LjgwNTk3OFonIGlkPSdnNS0xMTYnLz4KPHBhdGggZD0nTTMuNjM0MzcxIC01LjE0MDcyMlYtNC43OTQwMjJDNC40NDczMjMgLTQuNzk0MDIyIDQuNTQyOTY0IC00LjcxMDMzNiA0LjU0Mjk2NCAtNC4xMjQ1MzNWLTEuOTg0NTU4QzQuNTQyOTY0IC0wLjk2ODM2OSA0LjAwNDk4MSAtMC4xMTk1NTIgMy4xMDgzNDQgLTAuMTE5NTUyQzIuMTI4MDIgLTAuMTE5NTUyIDIuMDY4MjQ0IC0wLjY4MTQ0NSAyLjA2ODI0NCAtMS4zMTUwNjhWLTUuMjcyMjI5TDAuMzgyNTY1IC01LjE0MDcyMlYtNC43OTQwMjJDMS4yOTExNTggLTQuNzk0MDIyIDEuMjkxMTU4IC00Ljc1ODE1NyAxLjI5MTE1OCAtMy42OTQxNDdWLTEuOTAwODcyQzEuMjkxMTU4IC0xLjE1OTY1MSAxLjI5MTE1OCAtMC43MjkyNjUgMS42NDk4MTMgLTAuMzM0NzQ1QzEuOTM2NzM3IC0wLjAyMzkxIDIuNDI2ODk5IDAuMTE5NTUyIDMuMDM2NjEzIDAuMTE5NTUyQzMuMjM5ODUxIDAuMTE5NTUyIDMuNjIyNDE2IDAuMTE5NTUyIDQuMDI4ODkyIC0wLjIyNzE0OEM0LjM3NTU5MiAtMC41MDIxMTcgNC41NjY4NzQgLTAuOTU2NDEzIDQuNTY2ODc0IC0wLjk1NjQxM1YwLjExOTU1Mkw2LjIyODY0MyAwVi0wLjM0NjdDNS40MTU2OTEgLTAuMzQ2NyA1LjMyMDA1IC0wLjQzMDM4NiA1LjMyMDA1IC0xLjAxNjE4OVYtNS4yNzIyMjlMMy42MzQzNzEgLTUuMTQwNzIyWicgaWQ9J2c1LTExNycvPgo8cGF0aCBkPSdNMy44OTczODUgLTIuNTQyNDY2QzMuODk3Mzg1IC0zLjM5NTI2OCAzLjgwOTcxNCAtMy45MTMzMjUgMy41NDY3IC00LjQyMzQxMkMzLjE5NjAxNSAtNS4xMjQ3ODIgMi41NTA0MzYgLTUuMzAwMTI1IDIuMTEyMDggLTUuMzAwMTI1QzEuMTA3ODQ2IC01LjMwMDEyNSAwLjc0MTIyIC00LjU1MDkzNCAwLjYyOTYzOSAtNC4zMjc3NzFDMC4zNDI3MTUgLTMuNzQ1OTUzIDAuMzI2Nzc1IC0yLjk1NjkxMiAwLjMyNjc3NSAtMi41NDI0NjZDMC4zMjY3NzUgLTIuMDE2NDM4IDAuMzUwNjg1IC0xLjIxMTQ1NyAwLjczMzI1IC0wLjU3Mzg0OEMxLjA5OTg3NSAwLjAxNTk0IDEuNjg5NjY0IDAuMTY3MzcyIDIuMTEyMDggMC4xNjczNzJDMi40OTQ2NDUgMC4xNjczNzIgMy4xODAwNzUgMC4wNDc4MjEgMy41Nzg1OCAtMC43NDEyMkMzLjg3MzQ3NCAtMS4zMTUwNjggMy44OTczODUgLTIuMDI0NDA4IDMuODk3Mzg1IC0yLjU0MjQ2NlpNMi4xMTIwOCAtMC4wNTU3OTFDMS44NDEwOTYgLTAuMDU1NzkxIDEuMjkxMTU4IC0wLjE4MzMxMyAxLjEyMzc4NiAtMS4wMjAxNzRDMS4wMzYxMTUgLTEuNDc0NDcxIDEuMDM2MTE1IC0yLjIyMzY2MSAxLjAzNjExNSAtMi42MzgxMDdDMS4wMzYxMTUgLTMuMTg4MDQ1IDEuMDM2MTE1IC0zLjc0NTk1MyAxLjEyMzc4NiAtNC4xODQzMDlDMS4yOTExNTggLTQuOTk3MjYgMS45MTI4MjcgLTUuMDc2OTYxIDIuMTEyMDggLTUuMDc2OTYxQzIuMzgzMDY0IC01LjA3Njk2MSAyLjkzMzAwMSAtNC45NDE0NjkgMy4wOTI0MDMgLTQuMjE2MTg5QzMuMTg4MDQ1IC0zLjc3NzgzMyAzLjE4ODA0NSAtMy4xODAwNzUgMy4xODgwNDUgLTIuNjM4MTA3QzMuMTg4MDQ1IC0yLjE2Nzg3IDMuMTg4MDQ1IC0xLjQ1MDU2IDMuMDkyNDAzIC0xLjAwNDIzNEMyLjkyNTAzMSAtMC4xNjczNzIgMi4zNzUwOTMgLTAuMDU1NzkxIDIuMTEyMDggLTAuMDU1NzkxWicgaWQ9J2c0LTQ4Jy8+CjxwYXRoIGQ9J00yLjUwMjYxNSAtNS4wNzY5NjFDMi41MDI2MTUgLTUuMjkyMTU0IDIuNDg2Njc1IC01LjMwMDEyNSAyLjI3MTQ4MiAtNS4zMDAxMjVDMS45NDQ3MDcgLTQuOTgxMzIgMS41MjIyOTEgLTQuNzkwMDM3IDAuNzY1MTMxIC00Ljc5MDAzN1YtNC41MjcwMjRDMC45ODAzMjQgLTQuNTI3MDI0IDEuNDEwNzEgLTQuNTI3MDI0IDEuODcyOTc2IC00Ljc0MjIxN1YtMC42NTM1NDlDMS44NzI5NzYgLTAuMzU4NjU1IDEuODQ5MDY2IC0wLjI2MzAxNCAxLjA5MTkwNSAtMC4yNjMwMTRIMC44MTI5NTFWMEMxLjEzOTcyNiAtMC4wMjM5MSAxLjgyNTE1NiAtMC4wMjM5MSAyLjE4MzgxMSAtMC4wMjM5MVMzLjIzNTg2NiAtMC4wMjM5MSAzLjU2MjY0IDBWLTAuMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2IC0wLjI2MzAxNCAyLjUwMjYxNSAtMC4zNTg2NTUgMi41MDI2MTUgLTAuNjUzNTQ5Vi01LjA3Njk2MVonIGlkPSdnNC00OScvPgo8cGF0aCBkPSdNMi4yNDc1NzIgLTEuNjI1OTAzQzIuMzc1MDkzIC0xLjc0NTQ1NSAyLjcwOTgzOCAtMi4wMDg0NjggMi44MzczNiAtMi4xMjAwNUMzLjMzMTUwNyAtMi41NzQzNDYgMy44MDE3NDMgLTMuMDEyNzAyIDMuODAxNzQzIC0zLjczNzk4M0MzLjgwMTc0MyAtNC42ODY0MjYgMy4wMDQ3MzIgLTUuMzAwMTI1IDIuMDA4NDY4IC01LjMwMDEyNUMxLjA1MjA1NSAtNS4zMDAxMjUgMC40MjI0MTYgLTQuNTc0ODQ0IDAuNDIyNDE2IC0zLjg2NTUwNEMwLjQyMjQxNiAtMy40NzQ5NjkgMC43MzMyNSAtMy40MTkxNzggMC44NDQ4MzIgLTMuNDE5MTc4QzEuMDEyMjA0IC0zLjQxOTE3OCAxLjI1OTI3OCAtMy41Mzg3MyAxLjI1OTI3OCAtMy44NDE1OTRDMS4yNTkyNzggLTQuMjU2MDQgMC44NjA3NzIgLTQuMjU2MDQgMC43NjUxMzEgLTQuMjU2MDRDMC45OTYyNjQgLTQuODM3ODU4IDEuNTMwMjYyIC01LjAzNzExMSAxLjkyMDc5NyAtNS4wMzcxMTFDMi42NjIwMTcgLTUuMDM3MTExIDMuMDQ0NTgzIC00LjQwNzQ3MiAzLjA0NDU4MyAtMy43Mzc5ODNDMy4wNDQ1ODMgLTIuOTA5MDkxIDIuNDYyNzY1IC0yLjMwMzM2MiAxLjUyMjI5MSAtMS4zMzg5NzlMMC41MTgwNTcgLTAuMzAyODY0QzAuNDIyNDE2IC0wLjIxNTE5MyAwLjQyMjQxNiAtMC4xOTkyNTMgMC40MjI0MTYgMEgzLjU3MDYxTDMuODAxNzQzIC0xLjQyNjY1SDMuNTU0NjdDMy41MzA3NiAtMS4yNjcyNDggMy40NjY5OTkgLTAuODY4NzQyIDMuMzcxMzU3IC0wLjcxNzMxQzMuMzIzNTM3IC0wLjY1MzU0OSAyLjcxNzgwOCAtMC42NTM1NDkgMi41OTAyODYgLTAuNjUzNTQ5SDEuMTcxNjA2TDIuMjQ3NTcyIC0xLjYyNTkwM1onIGlkPSdnNC01MCcvPgo8cGF0aCBkPSdNNC45Mzc0ODQgMTMuNzM2NDg4QzQuOTM3NDg0IDEzLjY4ODY2NyA0LjkxMzU3NCAxMy42NjQ3NTcgNC44ODk2NjQgMTMuNjI4ODkyQzQuMzM5NzI2IDEzLjA0MzA4OCAzLjUyNjc3NSAxMi4wNzQ3MiAzLjAyNDY1OCAxMC4xMjYwMjdDMi43NDk2ODkgOS4wMzgxMDcgMi42NDIwOTIgNy44MDY3MjUgMi42NDIwOTIgNi42OTQ4OTRDMi42NDIwOTIgMy41NTA2ODUgMy4zOTUyNjggMS4zNTA5MzQgNC44Mjk4ODggLTAuMjAzMjM4QzQuOTM3NDg0IC0wLjMxMDgzNCA0LjkzNzQ4NCAtMC4zMzQ3NDUgNC45Mzc0ODQgLTAuMzU4NjU1QzQuOTM3NDg0IC0wLjQ3ODIwNyA0Ljg0MTg0MyAtMC40NzgyMDcgNC43OTQwMjIgLTAuNDc4MjA3QzQuNjE0Njk1IC0wLjQ3ODIwNyAzLjk2OTExNiAwLjIzOTEwMyAzLjgxMzY5OSAwLjQxODQzMUMyLjU5NDI3MSAxLjg2NTAwNiAxLjgxNzE4NiA0LjAxNjkzNiAxLjgxNzE4NiA2LjY4MjkzOUMxLjgxNzE4NiA4LjM4MDU3MyAyLjExNjA2NSAxMC43ODM1NjIgMy42ODIxOTIgMTIuODAzOTg1QzMuODAxNzQzIDEyLjk0NzQ0NyA0LjU3ODgyOSAxMy44NTYwNCA0Ljc5NDAyMiAxMy44NTYwNEM0Ljg0MTg0MyAxMy44NTYwNCA0LjkzNzQ4NCAxMy44NTYwNCA0LjkzNzQ4NCAxMy43MzY0ODhaJyBpZD0nZzAtMCcvPgo8cGF0aCBkPSdNMy42NDYzMjYgNi42OTQ4OTRDMy42NDYzMjYgNC45OTcyNiAzLjM0NzQ0NyAyLjU5NDI3MSAxLjc4MTMyIDAuNTczODQ4QzEuNjYxNzY4IDAuNDMwMzg2IDAuODg0NjgyIC0wLjQ3ODIwNyAwLjY2OTQ4OSAtMC40NzgyMDdDMC42MDk3MTQgLTAuNDc4MjA3IDAuNTI2MDI3IC0wLjQ1NDI5NiAwLjUyNjAyNyAtMC4zNTg2NTVDMC41MjYwMjcgLTAuMzEwODM0IDAuNTQ5OTM4IC0wLjI3NDk2OSAwLjU5Nzc1OCAtMC4yMzkxMDNDMS4xNzE2MDYgMC4zODI1NjUgMS45NDg2OTIgMS4zNTA5MzQgMi40Mzg4NTQgMy4yNTE4MDZDMi43MTM4MjMgNC4zMzk3MjYgMi44MjE0MiA1LjU3MTEwOCAyLjgyMTQyIDYuNjgyOTM5QzIuODIxNDIgNy44OTA0MTEgMi43MTM4MjMgOS4xMDk4MzggMi40MDI5ODkgMTAuMjgxNDQ1QzEuOTQ4NjkyIDExLjk1NTE2OCAxLjI0MzMzNyAxMi45MTE1ODIgMC42MzM2MjQgMTMuNTgxMDcxQzAuNTI2MDI3IDEzLjY4ODY2NyAwLjUyNjAyNyAxMy43MTI1NzggMC41MjYwMjcgMTMuNzM2NDg4QzAuNTI2MDI3IDEzLjgzMjEzIDAuNjA5NzE0IDEzLjg1NjA0IDAuNjY5NDg5IDEzLjg1NjA0QzAuODQ4ODE3IDEzLjg1NjA0IDEuNTA2MzUxIDEzLjEyNjc3NSAxLjY0OTgxMyAxMi45NTk0MDJDMi44NjkyNCAxMS41MTI4MjcgMy42NDYzMjYgOS4zNjA4OTcgMy42NDYzMjYgNi42OTQ4OTRaJyBpZD0nZzAtMScvPgo8cGF0aCBkPSdNNi4wMjU0MDUgNS40MTU2OTFDNi4wMjU0MDUgNC40MzUzNjcgNi4yODg0MTggMi4xNTE5MyA4LjQxNjQzOCAwLjY0NTU3OUM4LjU3MTg1NiAwLjUyNjAyNyA4LjU4MzgxMSAwLjUxNDA3MiA4LjU4MzgxMSAwLjI5ODg3OUM4LjU4MzgxMSAwLjAyMzkxIDguNTcxODU2IDAuMDExOTU1IDguMjcyOTc2IDAuMDExOTU1SDguMDgxNjk0QzUuNTExMzMzIDEuMzk4NzU1IDQuNTkwNzg1IDMuNjU4MjgxIDQuNTkwNzg1IDUuNDE1NjkxVjEwLjU1NjQxM0M0LjU5MDc4NSAxMC44NjcyNDggNC42MDI3NCAxMC44NzkyMDMgNC45MjU1MjkgMTAuODc5MjAzSDUuNjkwNjZDNi4wMTM0NSAxMC44NzkyMDMgNi4wMjU0MDUgMTAuODY3MjQ4IDYuMDI1NDA1IDEwLjU1NjQxM1Y1LjQxNTY5MVonIGlkPSdnMC01NicvPgo8cGF0aCBkPSdNNC41OTA3ODUgMTAuNTU2NDEzQzQuNTkwNzg1IDEwLjg2NzI0OCA0LjYwMjc0IDEwLjg3OTIwMyA0LjkyNTUyOSAxMC44NzkyMDNINS42OTA2NkM2LjAxMzQ1IDEwLjg3OTIwMyA2LjAyNTQwNSAxMC44NjcyNDggNi4wMjU0MDUgMTAuNTU2NDEzVjUuNDE1NjkxQzYuMDI1NDA1IDMuNjU4MjgxIDUuMTA0ODU3IDEuMzk4NzU1IDIuNTM0NDk2IDAuMDExOTU1SDIuMzU1MTY4QzIuMDQ0MzM0IDAuMDExOTU1IDIuMDMyMzc5IDAuMDIzOTEgMi4wMzIzNzkgMC4yOTg4NzlDMi4wMzIzNzkgMC41MTQwNzIgMi4wNDQzMzQgMC41MjYwMjcgMi4wOTIxNTQgMC41NjE4OTNDMi40NjI3NjUgMC44MzY4NjIgMy4zMjM1MzcgMS40NDY1NzUgMy44ODU0MyAyLjU0NjQ1MUM0LjIwODIxOSAzLjE5MjAzIDQuNTkwNzg1IDQuMTI0NTMzIDQuNTkwNzg1IDUuNDE1NjkxVjEwLjU1NjQxM1onIGlkPSdnMC01NycvPgo8cGF0aCBkPSdNOC4yNzI5NzYgMTAuNzQ3Njk2QzguNTcxODU2IDEwLjc0NzY5NiA4LjU4MzgxMSAxMC43MzU3NDEgOC41ODM4MTEgMTAuNDYwNzcyQzguNTgzODExIDEwLjI0NTU3OSA4LjU3MTg1NiAxMC4yMzM2MjQgOC41MjQwMzUgMTAuMTk3NzU4QzguMTUzNDI1IDkuOTIyNzkgNy4yOTI2NTMgOS4zMTMwNzYgNi43MzA3NiA4LjIxMzJDNi4yNjQ1MDggNy4zMDQ2MDggNi4wMjU0MDUgNi4zODQwNiA2LjAyNTQwNSA1LjM0Mzk2VjAuMjAzMjM4QzYuMDI1NDA1IC0wLjEwNzU5NyA2LjAxMzQ1IC0wLjExOTU1MiA1LjY5MDY2IC0wLjExOTU1Mkg0LjkyNTUyOUM0LjYwMjc0IC0wLjExOTU1MiA0LjU5MDc4NSAtMC4xMDc1OTcgNC41OTA3ODUgMC4yMDMyMzhWNS4zNDM5NkM0LjU5MDc4NSA3LjExMzMyNSA1LjUxMTMzMyA5LjM3Mjg1MiA4LjA4MTY5NCAxMC43NDc2OTZIOC4yNzI5NzZaJyBpZD0nZzAtNTgnLz4KPHBhdGggZD0nTTQuNTkwNzg1IDUuMzQzOTZDNC41OTA3ODUgNi4zODQwNiA0LjMwMzg2MSA4LjYzMTYzMSAyLjE5OTc1MSAxMC4xMTQwNzJDMi4wNDQzMzQgMTAuMjMzNjI0IDIuMDMyMzc5IDEwLjI0NTU3OSAyLjAzMjM3OSAxMC40NjA3NzJDMi4wMzIzNzkgMTAuNzM1NzQxIDIuMDQ0MzM0IDEwLjc0NzY5NiAyLjM1NTE2OCAxMC43NDc2OTZIMi41MzQ0OTZDNS4xMTY4MTIgOS4zNjA4OTcgNi4wMjU0MDUgNy4xMDEzNyA2LjAyNTQwNSA1LjM0Mzk2VjAuMjAzMjM4QzYuMDI1NDA1IC0wLjEwNzU5NyA2LjAxMzQ1IC0wLjExOTU1MiA1LjY5MDY2IC0wLjExOTU1Mkg0LjkyNTUyOUM0LjYwMjc0IC0wLjExOTU1MiA0LjU5MDc4NSAtMC4xMDc1OTcgNC41OTA3ODUgMC4yMDMyMzhWNS4zNDM5NlonIGlkPSdnMC01OScvPgo8cGF0aCBkPSdNNC41OTA3ODUgMjEuMzE2MDY1QzQuNTkwNzg1IDIxLjYyNjg5OSA0LjYwMjc0IDIxLjYzODg1NCA0LjkyNTUyOSAyMS42Mzg4NTRINS42OTA2NkM2LjAxMzQ1IDIxLjYzODg1NCA2LjAyNTQwNSAyMS42MjY4OTkgNi4wMjU0MDUgMjEuMzE2MDY1VjE2LjI3MDk4NEM2LjAyNTQwNSAxNC44MjQ0MDggNS40MTU2OTEgMTIuMzg1NTU0IDIuNzM3NzMzIDEwLjc1OTY1MUM1LjQzOTYwMSA5LjEyMTc5MyA2LjAyNTQwNSA2LjY1OTAyOSA2LjAyNTQwNSA1LjI0ODMxOVYwLjIwMzIzOEM2LjAyNTQwNSAtMC4xMDc1OTcgNi4wMTM0NSAtMC4xMTk1NTIgNS42OTA2NiAtMC4xMTk1NTJINC45MjU1MjlDNC42MDI3NCAtMC4xMTk1NTIgNC41OTA3ODUgLTAuMTA3NTk3IDQuNTkwNzg1IDAuMjAzMjM4VjUuMjYwMjc0QzQuNTkwNzg1IDYuMjY0NTA4IDQuMzc1NTkyIDguNzUxMTgzIDIuMTc1ODQxIDEwLjQyNDkwN0MyLjA0NDMzNCAxMC41MzI1MDMgMi4wMzIzNzkgMTAuNTQ0NDU4IDIuMDMyMzc5IDEwLjc1OTY1MVMyLjA0NDMzNCAxMC45ODY4IDIuMTc1ODQxIDExLjA5NDM5NkMyLjQ4NjY3NSAxMS4zMzM0OTkgMy4zMTE1ODIgMTEuOTY3MTIzIDMuODg1NDMgMTMuMTc0NTk1QzQuMzUxNjgxIDE0LjEzMTAwOSA0LjU5MDc4NSAxNS4xOTUwMTkgNC41OTA3ODUgMTYuMjU5MDI5VjIxLjMxNjA2NVonIGlkPSdnMC02MCcvPgo8cGF0aCBkPSdNNi4wMjU0MDUgMTYuMjU5MDI5QzYuMDI1NDA1IDE1LjI1NDc5NSA2LjI0MDU5OCAxMi43NjgxMiA4LjQ0MDM0OSAxMS4wOTQzOTZDOC41NzE4NTYgMTAuOTg2OCA4LjU4MzgxMSAxMC45NzQ4NDQgOC41ODM4MTEgMTAuNzU5NjUxUzguNTcxODU2IDEwLjUzMjUwMyA4LjQ0MDM0OSAxMC40MjQ5MDdDOC4xMjk1MTQgMTAuMTg1ODAzIDcuMzA0NjA4IDkuNTUyMTc5IDYuNzMwNzYgOC4zNDQ3MDdDNi4yNjQ1MDggNy4zODgyOTQgNi4wMjU0MDUgNi4zMjQyODQgNi4wMjU0MDUgNS4yNjAyNzRWMC4yMDMyMzhDNi4wMjU0MDUgLTAuMTA3NTk3IDYuMDEzNDUgLTAuMTE5NTUyIDUuNjkwNjYgLTAuMTE5NTUySDQuOTI1NTI5QzQuNjAyNzQgLTAuMTE5NTUyIDQuNTkwNzg1IC0wLjEwNzU5NyA0LjU5MDc4NSAwLjIwMzIzOFY1LjI0ODMxOUM0LjU5MDc4NSA2LjY5NDg5NCA1LjIwMDQ5OCA5LjEzMzc0OCA3Ljg3ODQ1NiAxMC43NTk2NTFDNS4xNzY1ODggMTIuMzk3NTA5IDQuNTkwNzg1IDE0Ljg2MDI3NCA0LjU5MDc4NSAxNi4yNzA5ODRWMjEuMzE2MDY1QzQuNTkwNzg1IDIxLjYyNjg5OSA0LjYwMjc0IDIxLjYzODg1NCA0LjkyNTUyOSAyMS42Mzg4NTRINS42OTA2NkM2LjAxMzQ1IDIxLjYzODg1NCA2LjAyNTQwNSAyMS42MjY4OTkgNi4wMjU0MDUgMjEuMzE2MDY1VjE2LjI1OTAyOVonIGlkPSdnMC02MScvPgo8cGF0aCBkPSdNNi4wMjU0MDUgMC4yMDMyMzhDNi4wMjU0MDUgLTAuMTA3NTk3IDYuMDEzNDUgLTAuMTE5NTUyIDUuNjkwNjYgLTAuMTE5NTUySDQuOTI1NTI5QzQuNjAyNzQgLTAuMTE5NTUyIDQuNTkwNzg1IC0wLjEwNzU5NyA0LjU5MDc4NSAwLjIwMzIzOFYzLjM4MzMxM0M0LjU5MDc4NSAzLjY5NDE0NyA0LjYwMjc0IDMuNzA2MTAyIDQuOTI1NTI5IDMuNzA2MTAySDUuNjkwNjZDNi4wMTM0NSAzLjcwNjEwMiA2LjAyNTQwNSAzLjY5NDE0NyA2LjAyNTQwNSAzLjM4MzMxM1YwLjIwMzIzOFonIGlkPSdnMC02MicvPgo8cGF0aCBkPSdNMi4zMzEyNTggMC4wNDc4MjFDMi4zMzEyNTggLTAuNjQ1NTc5IDIuMTA0MTEgLTEuMTU5NjUxIDEuNjEzOTQ4IC0xLjE1OTY1MUMxLjIzMTM4MiAtMS4xNTk2NTEgMS4wNDAxIC0wLjg0ODgxNyAxLjA0MDEgLTAuNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjcgLTAuMDQ3ODIxIDIuMDIwNDIzIC0wLjE1NTQxN0MyLjA0NDMzNCAtMC4xNzkzMjggMi4wNTYyODkgLTAuMTc5MzI4IDIuMDY4MjQ0IC0wLjE3OTMyOEMyLjA5MjE1NCAtMC4xNzkzMjggMi4wOTIxNTQgLTAuMDExOTU1IDIuMDkyMTU0IDAuMDQ3ODIxQzIuMDkyMTU0IDAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggMC4wNDc4MjFaJyBpZD0nZzMtNTknLz4KPHBhdGggZD0nTTYuMDEzNDUgLTcuOTk4MDA3QzYuMDI1NDA1IC04LjA0NTgyOCA2LjA0OTMxNSAtOC4xMTc1NTkgNi4wNDkzMTUgLTguMTc3MzM1QzYuMDQ5MzE1IC04LjI5Njg4NyA1LjkyOTc2MyAtOC4yOTY4ODcgNS45MDU4NTMgLTguMjk2ODg3QzUuODkzODk4IC04LjI5Njg4NyA1LjMwODA5NSAtOC4yNDkwNjYgNS4yNDgzMTkgLTguMjM3MTExQzUuMDQ1MDgxIC04LjIyNTE1NiA0Ljg2NTc1MyAtOC4yMDEyNDUgNC42NTA1NiAtOC4xODkyOUM0LjM1MTY4MSAtOC4xNjUzOCA0LjI2Nzk5NSAtOC4xNTM0MjUgNC4yNjc5OTUgLTcuOTM4MjMyQzQuMjY3OTk1IC03LjgxODY4IDQuMzYzNjM2IC03LjgxODY4IDQuNTMxMDA5IC03LjgxODY4QzUuMTE2ODEyIC03LjgxODY4IDUuMTI4NzY3IC03LjcxMTA4MyA1LjEyODc2NyAtNy41OTE1MzJDNS4xMjg3NjcgLTcuNTE5ODAxIDUuMTA0ODU3IC03LjQyNDE1OSA1LjA5MjkwMiAtNy4zODgyOTRMNC4zNjM2MzYgLTQuNDgzMTg4QzQuMjMyMTMgLTQuNzk0MDIyIDMuOTA5MzQgLTUuMjcyMjI5IDMuMjg3NjcxIC01LjI3MjIyOUMxLjkzNjczNyAtNS4yNzIyMjkgMC40NzgyMDcgLTMuNTI2Nzc1IDAuNDc4MjA3IC0xLjc1NzQxQzAuNDc4MjA3IC0wLjU3Mzg0OCAxLjE3MTYwNiAwLjExOTU1MiAxLjk4NDU1OCAwLjExOTU1MkMyLjY0MjA5MiAwLjExOTU1MiAzLjIwMzk4NSAtMC4zOTQ1MjEgMy41Mzg3MyAtMC43ODkwNDFDMy42NTgyODEgLTAuMDgzNjg2IDQuMjIwMTc0IDAuMTE5NTUyIDQuNTc4ODI5IDAuMTE5NTUyUzUuMjI0NDA4IC0wLjA5NTY0MSA1LjQzOTYwMSAtMC41MjYwMjdDNS42MzA4ODQgLTAuOTMyNTAzIDUuNzk4MjU3IC0xLjY2MTc2OCA1Ljc5ODI1NyAtMS43MDk1ODlDNS43OTgyNTcgLTEuNzY5MzY1IDUuNzUwNDM2IC0xLjgxNzE4NiA1LjY3ODcwNSAtMS44MTcxODZDNS41NzExMDggLTEuODE3MTg2IDUuNTU5MTUzIC0xLjc1NzQxIDUuNTExMzMzIC0xLjU3ODA4MkM1LjMzMjAwNSAtMC44NzI3MjcgNS4xMDQ4NTcgLTAuMTE5NTUyIDQuNjE0Njk1IC0wLjExOTU1MkM0LjI2Nzk5NSAtMC4xMTk1NTIgNC4yNDQwODUgLTAuNDMwMzg2IDQuMjQ0MDg1IC0wLjY2OTQ4OUM0LjI0NDA4NSAtMC43MTczMSA0LjI0NDA4NSAtMC45NjgzNjkgNC4zMjc3NzEgLTEuMzAzMTEzTDYuMDEzNDUgLTcuOTk4MDA3Wk0zLjU5ODUwNiAtMS40MjI2NjVDMy41Mzg3MyAtMS4yMTk0MjcgMy41Mzg3MyAtMS4xOTU1MTcgMy4zNzEzNTcgLTAuOTY4MzY5QzMuMTA4MzQ0IC0wLjYzMzYyNCAyLjU4MjMxNiAtMC4xMTk1NTIgMi4wMjA0MjMgLTAuMTE5NTUyQzEuNTMwMjYyIC0wLjExOTU1MiAxLjI1NTI5MyAtMC41NjE4OTMgMS4yNTUyOTMgLTEuMjY3MjQ4QzEuMjU1MjkzIC0xLjkyNDc4MiAxLjYyNTkwMyAtMy4yNjM3NjEgMS44NTMwNTEgLTMuNzY1ODc4QzIuMjU5NTI3IC00LjYwMjc0IDIuODIxNDIgLTUuMDMzMTI2IDMuMjg3NjcxIC01LjAzMzEyNkM0LjA3NjcxMiAtNS4wMzMxMjYgNC4yMzIxMyAtNC4wNTI4MDIgNC4yMzIxMyAtMy45NTcxNjFDNC4yMzIxMyAtMy45NDUyMDUgNC4xOTYyNjQgLTMuNzg5Nzg4IDQuMTg0MzA5IC0zLjc2NTg3OEwzLjU5ODUwNiAtMS40MjI2NjVaJyBpZD0nZzMtMTAwJy8+CjxwYXRoIGQ9J00zLjM4MzMxMyAtMS43MDk1ODlDMy4zODMzMTMgLTEuNzY5MzY1IDMuMzM1NDkyIC0xLjgxNzE4NiAzLjI2Mzc2MSAtMS44MTcxODZDMy4xNTYxNjQgLTEuODE3MTg2IDMuMTQ0MjA5IC0xLjc4MTMyIDMuMDg0NDMzIC0xLjU3ODA4MkMyLjc3MzU5OSAtMC40OTAxNjIgMi4yODM0MzcgLTAuMTE5NTUyIDEuODg4OTE3IC0wLjExOTU1MkMxLjc0NTQ1NSAtMC4xMTk1NTIgMS41NzgwODIgLTAuMTU1NDE3IDEuNTc4MDgyIC0wLjUxNDA3MkMxLjU3ODA4MiAtMC44MzY4NjIgMS43MjE1NDQgLTEuMTk1NTE3IDEuODUzMDUxIC0xLjU1NDE3MkwyLjY4OTkxMyAtMy43Nzc4MzNDMi43MjU3NzggLTMuODczNDc0IDIuODA5NDY1IC00LjA4ODY2NyAyLjgwOTQ2NSAtNC4zMTU4MTZDMi44MDk0NjUgLTQuODE3OTMzIDIuNDUwODA5IC01LjI3MjIyOSAxLjg2NTAwNiAtNS4yNzIyMjlDMC43NjUxMzEgLTUuMjcyMjI5IDAuMzIyNzkgLTMuNTM4NzMgMC4zMjI3OSAtMy40NDMwODhDMC4zMjI3OSAtMy4zOTUyNjggMC4zNzA2MSAtMy4zMzU0OTIgMC40NTQyOTYgLTMuMzM1NDkyQzAuNTYxODkzIC0zLjMzNTQ5MiAwLjU3Mzg0OCAtMy4zODMzMTMgMC42MjE2NjkgLTMuNTUwNjg1QzAuOTA4NTkzIC00LjU1NDkxOSAxLjM2Mjg4OSAtNS4wMzMxMjYgMS44MjkxNDEgLTUuMDMzMTI2QzEuOTM2NzM3IC01LjAzMzEyNiAyLjEzOTk3NSAtNS4wMjExNzEgMi4xMzk5NzUgLTQuNjM4NjA1QzIuMTM5OTc1IC00LjMyNzc3MSAxLjk4NDU1OCAtMy45MzMyNSAxLjg4ODkxNyAtMy42NzAyMzdMMS4wNTIwNTUgLTEuNDQ2NTc1QzAuOTgwMzI0IC0xLjI1NTI5MyAwLjkwODU5MyAtMS4wNjQwMSAwLjkwODU5MyAtMC44NDg4MTdDMC45MDg1OTMgLTAuMzEwODM0IDEuMjc5MjAzIDAuMTE5NTUyIDEuODUzMDUxIDAuMTE5NTUyQzIuOTUyOTI3IDAuMTE5NTUyIDMuMzgzMzEzIC0xLjYyNTkwMyAzLjM4MzMxMyAtMS43MDk1ODlaTTMuMjg3NjcxIC03LjQ2MDAyNUMzLjI4NzY3MSAtNy42MzkzNTIgMy4xNDQyMDkgLTcuODU0NTQ1IDIuODgxMTk2IC03Ljg1NDU0NUMyLjYwNjIyNyAtNy44NTQ1NDUgMi4yOTUzOTIgLTcuNTkxNTMyIDIuMjk1MzkyIC03LjI4MDY5N0MyLjI5NTM5MiAtNi45ODE4MTggMi41NDY0NTEgLTYuODg2MTc3IDIuNjg5OTEzIC02Ljg4NjE3N0MzLjAxMjcwMiAtNi44ODYxNzcgMy4yODc2NzEgLTcuMTk3MDExIDMuMjg3NjcxIC03LjQ2MDAyNVonIGlkPSdnMy0xMDUnLz4KPHBhdGggZD0nTTQuMTg0MzA5IC0zLjc4OTc4OEM0LjIzMjEzIC0zLjk4MTA3MSA0LjIzMjEzIC00LjE0ODQ0MyA0LjIzMjEzIC00LjE5NjI2NEM0LjIzMjEzIC00Ljg4OTY2NCAzLjcxODA1NyAtNS4yNzIyMjkgMy4xODAwNzUgLTUuMjcyMjI5QzEuOTcyNjAzIC01LjI3MjIyOSAxLjMyNzAyNCAtMy41MjY3NzUgMS4zMjcwMjQgLTMuNDQzMDg4QzEuMzI3MDI0IC0zLjM4MzMxMyAxLjM3NDg0NCAtMy4zMzU0OTIgMS40NDY1NzUgLTMuMzM1NDkyQzEuNTQyMjE3IC0zLjMzNTQ5MiAxLjU1NDE3MiAtMy4zODMzMTMgMS42MTM5NDggLTMuNTAyODY0QzIuMDkyMTU0IC00LjY2MjUxNiAyLjY4OTkxMyAtNS4wMzMxMjYgMy4xNDQyMDkgLTUuMDMzMTI2QzMuMzk1MjY4IC01LjAzMzEyNiAzLjUyNjc3NSAtNC45MDE2MTkgMy41MjY3NzUgLTQuNDgzMTg4QzMuNTI2Nzc1IC00LjE5NjI2NCAzLjQ5MDkwOSAtNC4wNzY3MTIgMy40NDMwODggLTMuODYxNTE5TDIuMzA3MzQ3IDAuNjQ1NTc5QzIuMDgwMTk5IDEuNTMwMjYyIDEuNTE4MzA2IDIuMTk5NzUxIDAuODYwNzcyIDIuMTk5NzUxQzAuODEyOTUxIDIuMTk5NzUxIDAuNTYxODkzIDIuMTk5NzUxIDAuMzM0NzQ1IDIuMDgwMTk5QzAuNjIxNjY5IDIuMDIwNDIzIDAuODQ4ODE3IDEuNzkzMjc1IDAuODQ4ODE3IDEuNTA2MzUxQzAuODQ4ODE3IDEuMzE1MDY4IDAuNzA1MzU1IDEuMTIzNzg2IDAuNDQyMzQxIDEuMTIzNzg2QzAuMTMxNTA3IDEuMTIzNzg2IC0wLjE1NTQxNyAxLjM4NjggLTAuMTU1NDE3IDEuNzQ1NDU1Qy0wLjE1NTQxNyAyLjIzNTYxNiAwLjM3MDYxIDIuNDM4ODU0IDAuODYwNzcyIDIuNDM4ODU0QzEuNjg1Njc5IDIuNDM4ODU0IDIuNzczNTk5IDEuODI5MTQxIDMuMDcyNDc4IDAuNjMzNjI0TDQuMTg0MzA5IC0zLjc4OTc4OFpNNC42NzQ0NzEgLTcuNDYwMDI1QzQuNjc0NDcxIC03Ljc1ODkwNCA0LjQyMzQxMiAtNy44NTQ1NDUgNC4yNzk5NSAtNy44NTQ1NDVDMy45NTcxNjEgLTcuODU0NTQ1IDMuNjgyMTkyIC03LjU0MzcxMSAzLjY4MjE5MiAtNy4yODA2OTdDMy42ODIxOTIgLTcuMTAxMzcgMy44MjU2NTQgLTYuODg2MTc3IDQuMDg4NjY3IC02Ljg4NjE3N0M0LjM2MzYzNiAtNi44ODYxNzcgNC42NzQ0NzEgLTcuMTQ5MTkxIDQuNjc0NDcxIC03LjQ2MDAyNVonIGlkPSdnMy0xMDYnLz4KPHBhdGggZD0nTTIuNDYyNzY1IC0zLjUwMjg2NEMyLjQ4NjY3NSAtMy41NzQ1OTUgMi43ODU1NTQgLTQuMTcyMzU0IDMuMjI3ODk1IC00LjU1NDkxOUMzLjUzODczIC00Ljg0MTg0MyAzLjk0NTIwNSAtNS4wMzMxMjYgNC40MTE0NTcgLTUuMDMzMTI2QzQuODg5NjY0IC01LjAzMzEyNiA1LjA1NzAzNiAtNC42NzQ0NzEgNS4wNTcwMzYgLTQuMTk2MjY0QzUuMDU3MDM2IC00LjEyNDUzMyA1LjA1NzAzNiAtMy44ODU0MyA0LjkxMzU3NCAtMy4zMjM1MzdMNC42MTQ2OTUgLTIuMDkyMTU0QzQuNTE5MDU0IC0xLjczMzQ5OSA0LjI5MTkwNSAtMC44NDg4MTcgNC4yNjc5OTUgLTAuNzE3MzFDNC4yMjAxNzQgLTAuNTM3OTgzIDQuMTQ4NDQzIC0wLjIyNzE0OCA0LjE0ODQ0MyAtMC4xNzkzMjhDNC4xNDg0NDMgLTAuMDExOTU1IDQuMjc5OTUgMC4xMTk1NTIgNC40NTkyNzggMC4xMTk1NTJDNC44MTc5MzMgMC4xMTk1NTIgNC44Nzc3MDkgLTAuMTU1NDE3IDQuOTg1MzA1IC0wLjU4NTgwM0w1LjcwMjYxNSAtMy40NDMwODhDNS43MjY1MjYgLTMuNTM4NzMgNi4zNDgxOTQgLTUuMDMzMTI2IDcuNjYzMjYzIC01LjAzMzEyNkM4LjE0MTQ2OSAtNS4wMzMxMjYgOC4zMDg4NDIgLTQuNjc0NDcxIDguMzA4ODQyIC00LjE5NjI2NEM4LjMwODg0MiAtMy41MjY3NzUgNy44NDI1OSAtMi4yMjM2NjEgNy41Nzk1NzcgLTEuNTA2MzUxQzcuNDcxOTggLTEuMjE5NDI3IDcuNDEyMjA0IC0xLjA2NDAxIDcuNDEyMjA0IC0wLjg0ODgxN0M3LjQxMjIwNCAtMC4zMTA4MzQgNy43ODI4MTQgMC4xMTk1NTIgOC4zNTY2NjMgMC4xMTk1NTJDOS40Njg0OTMgMC4xMTk1NTIgOS44ODY5MjQgLTEuNjM3ODU4IDkuODg2OTI0IC0xLjcwOTU4OUM5Ljg4NjkyNCAtMS43NjkzNjUgOS44MzkxMDMgLTEuODE3MTg2IDkuNzY3MzcyIC0xLjgxNzE4NkM5LjY1OTc3NiAtMS44MTcxODYgOS42NDc4MjEgLTEuNzgxMzIgOS41ODgwNDUgLTEuNTc4MDgyQzkuMzEzMDc2IC0wLjYyMTY2OSA4Ljg3MDczNSAtMC4xMTk1NTIgOC4zOTI1MjggLTAuMTE5NTUyQzguMjcyOTc2IC0wLjExOTU1MiA4LjA4MTY5NCAtMC4xMzE1MDcgOC4wODE2OTQgLTAuNTE0MDcyQzguMDgxNjk0IC0wLjgyNDkwNyA4LjIyNTE1NiAtMS4yMDc0NzIgOC4yNzI5NzYgLTEuMzM4OTc5QzguNDg4MTY5IC0xLjkxMjgyNyA5LjAyNjE1MiAtMy4zMjM1MzcgOS4wMjYxNTIgLTQuMDE2OTM2QzkuMDI2MTUyIC00LjczNDI0NyA4LjYwNzcyMSAtNS4yNzIyMjkgNy42OTkxMjggLTUuMjcyMjI5QzYuODk4MTMyIC01LjI3MjIyOSA2LjI1MjU1MyAtNC44MTc5MzMgNS43NzQzNDYgLTQuMTEyNTc4QzUuNzM4NDgxIC00Ljc1ODE1NyA1LjM0Mzk2IC01LjI3MjIyOSA0LjQ0NzMyMyAtNS4yNzIyMjlDMy4zODMzMTMgLTUuMjcyMjI5IDIuODIxNDIgLTQuNTE5MDU0IDIuNjA2MjI3IC00LjIyMDE3NEMyLjU3MDM2MSAtNC45MDE2MTkgMi4wODAxOTkgLTUuMjcyMjI5IDEuNTU0MTcyIC01LjI3MjIyOUMxLjIwNzQ3MiAtNS4yNzIyMjkgMC45MzI1MDMgLTUuMTA0ODU3IDAuNzA1MzU1IC00LjY1MDU2QzAuNDkwMTYyIC00LjIyMDE3NCAwLjMyMjc5IC0zLjQ5MDkwOSAwLjMyMjc5IC0zLjQ0MzA4OFMwLjM3MDYxIC0zLjMzNTQ5MiAwLjQ1NDI5NiAtMy4zMzU0OTJDMC41NDk5MzggLTMuMzM1NDkyIDAuNTYxODkzIC0zLjM0NzQ0NyAwLjYzMzYyNCAtMy42MjI0MTZDMC44MTI5NTEgLTQuMzI3NzcxIDEuMDQwMSAtNS4wMzMxMjYgMS41MTgzMDYgLTUuMDMzMTI2QzEuNzkzMjc1IC01LjAzMzEyNiAxLjg4ODkxNyAtNC44NDE4NDMgMS44ODg5MTcgLTQuNDgzMTg4QzEuODg4OTE3IC00LjIyMDE3NCAxLjc2OTM2NSAtMy43NTM5MjMgMS42ODU2NzkgLTMuMzgzMzEzTDEuMzUwOTM0IC0yLjA5MjE1NEMxLjMwMzExMyAtMS44NjUwMDYgMS4xNzE2MDYgLTEuMzI3MDI0IDEuMTExODMxIC0xLjExMTgzMUMxLjAyODE0NCAtMC44MDA5OTYgMC44OTY2MzggLTAuMjM5MTAzIDAuODk2NjM4IC0wLjE3OTMyOEMwLjg5NjYzOCAtMC4wMTE5NTUgMS4wMjgxNDQgMC4xMTk1NTIgMS4yMDc0NzIgMC4xMTk1NTJDMS4zNTA5MzQgMC4xMTk1NTIgMS41MTgzMDYgMC4wNDc4MjEgMS42MTM5NDggLTAuMTMxNTA3QzEuNjM3ODU4IC0wLjE5MTI4MyAxLjc0NTQ1NSAtMC42MDk3MTQgMS44MDUyMyAtMC44NDg4MTdMMi4wNjgyNDQgLTEuOTI0NzgyTDIuNDYyNzY1IC0zLjUwMjg2NFonIGlkPSdnMy0xMDknLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzQ5LjIxMzIxNycgeGxpbms6aHJlZj0nI2cwLTU2JyB5PSc3OS40NjgwOTMnLz4KPHVzZSB4PSc0OS4yMTMyMTcnIHhsaW5rOmhyZWY9JyNnMC02MicgeT0nOTAuMjI3ODUzJy8+Cjx1c2UgeD0nNDkuMjEzMjE3JyB4bGluazpocmVmPScjZzAtNjInIHk9JzkzLjgxNDQ0Jy8+Cjx1c2UgeD0nNDkuMjEzMjE3JyB4bGluazpocmVmPScjZzAtNjInIHk9Jzk3LjQwMTAyNycvPgo8dXNlIHg9JzQ5LjIxMzIxNycgeGxpbms6aHJlZj0nI2cwLTYyJyB5PScxMDAuOTg3NjE0Jy8+Cjx1c2UgeD0nNDkuMjEzMjE3JyB4bGluazpocmVmPScjZzAtNjAnIHk9JzEwNC41NzQyMDEnLz4KPHVzZSB4PSc0OS4yMTMyMTcnIHhsaW5rOmhyZWY9JyNnMC02MicgeT0nMTI2LjA5MzcyMycvPgo8dXNlIHg9JzQ5LjIxMzIxNycgeGxpbms6aHJlZj0nI2cwLTYyJyB5PScxMjkuNjgwMzEnLz4KPHVzZSB4PSc0OS4yMTMyMTcnIHhsaW5rOmhyZWY9JyNnMC02MicgeT0nMTMzLjI2Njg5NicvPgo8dXNlIHg9JzQ5LjIxMzIxNycgeGxpbms6aHJlZj0nI2cwLTYyJyB5PScxMzYuODUzNDgzJy8+Cjx1c2UgeD0nNDkuMjEzMjE3JyB4bGluazpocmVmPScjZzAtNTgnIHk9JzE0MC40NDAwNycvPgo8dXNlIHg9JzY0LjgyMTM3MycgeGxpbms6aHJlZj0nI2czLTEwMCcgeT0nODguNDY4MjAyJy8+Cjx1c2UgeD0nNzAuOTA0MDY2JyB4bGluazpocmVmPScjZzQtNDgnIHk9JzkwLjI2MTQ2NScvPgo8dXNlIHg9Jzc1LjEzODI0OScgeGxpbms6aHJlZj0nI2cyLTU5JyB5PSc5MC4yNjE0NjUnLz4KPHVzZSB4PSc3Ny40OTA1NzMnIHhsaW5rOmhyZWY9JyNnNC00OCcgeT0nOTAuMjYxNDY1Jy8+Cjx1c2UgeD0nODUuNTQzNzE3JyB4bGluazpocmVmPScjZzUtNjEnIHk9Jzg4LjQ2ODIwMicvPgo8dXNlIHg9Jzk3Ljk2OTE5OCcgeGxpbms6aHJlZj0nI2c1LTQ4JyB5PSc4OC40NjgyMDInLz4KPHVzZSB4PSc2NC44MjEzNzMnIHhsaW5rOmhyZWY9JyNnMy0xMDAnIHk9JzEyNS4yOTY2MDInLz4KPHVzZSB4PSc3MC45MDQwNjYnIHhsaW5rOmhyZWY9JyNnMi0xMDUnIHk9JzEyNy4wODk4NjUnLz4KPHVzZSB4PSc3My43ODcyMDYnIHhsaW5rOmhyZWY9JyNnMi01OScgeT0nMTI3LjA4OTg2NScvPgo8dXNlIHg9Jzc2LjEzOTUyOScgeGxpbms6aHJlZj0nI2cyLTEwNicgeT0nMTI3LjA4OTg2NScvPgo8dXNlIHg9JzgzLjg0MjUxNicgeGxpbms6aHJlZj0nI2c1LTYxJyB5PScxMjUuMjk2NjAyJy8+Cjx1c2UgeD0nOTYuMjY3OTk3JyB4bGluazpocmVmPScjZzUtMTA5JyB5PScxMjUuMjk2NjAyJy8+Cjx1c2UgeD0nMTA2LjAyMjk4JyB4bGluazpocmVmPScjZzUtMTA1JyB5PScxMjUuMjk2NjAyJy8+Cjx1c2UgeD0nMTA5LjI3NDY0MicgeGxpbms6aHJlZj0nI2c1LTExMCcgeT0nMTI1LjI5NjYwMicvPgo8dXNlIHg9JzExNy43NzA0NjInIHhsaW5rOmhyZWY9JyNnMC01NicgeT0nOTMuNjE1MTE1Jy8+Cjx1c2UgeD0nMTE3Ljc3MDQ2MicgeGxpbms6aHJlZj0nI2cwLTYyJyB5PScxMDQuMzc0ODc1Jy8+Cjx1c2UgeD0nMTE3Ljc3MDQ2MicgeGxpbms6aHJlZj0nI2cwLTYyJyB5PScxMDcuOTYxNDYyJy8+Cjx1c2UgeD0nMTE3Ljc3MDQ2MicgeGxpbms6aHJlZj0nI2cwLTYwJyB5PScxMTEuNTQ4MDQ5Jy8+Cjx1c2UgeD0nMTE3Ljc3MDQ2MicgeGxpbms6aHJlZj0nI2cwLTYyJyB5PScxMzMuMDY3NTcxJy8+Cjx1c2UgeD0nMTE3Ljc3MDQ2MicgeGxpbms6aHJlZj0nI2cwLTYyJyB5PScxMzYuNjU0MTU4Jy8+Cjx1c2UgeD0nMTE3Ljc3MDQ2MicgeGxpbms6aHJlZj0nI2cwLTU4JyB5PScxNDAuMjQwNzQ1Jy8+Cjx1c2UgeD0nMTMzLjM3ODYxOCcgeGxpbms6aHJlZj0nI2czLTEwMCcgeT0nMTAzLjU4OTExJy8+Cjx1c2UgeD0nMTM5LjQ2MTMxMScgeGxpbms6aHJlZj0nI2cyLTEwNScgeT0nMTA1LjM4MjM3MycvPgo8dXNlIHg9JzE0Mi4zNDQ0NTEnIHhsaW5rOmhyZWY9JyNnMS0wJyB5PScxMDUuMzgyMzczJy8+Cjx1c2UgeD0nMTQ4LjkzMDk1NycgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxMDUuMzgyMzczJy8+Cjx1c2UgeD0nMTUzLjE2NTE0JyB4bGluazpocmVmPScjZzItNTknIHk9JzEwNS4zODIzNzMnLz4KPHVzZSB4PScxNTUuNTE3NDY0JyB4bGluazpocmVmPScjZzItMTA2JyB5PScxMDUuMzgyMzczJy8+Cjx1c2UgeD0nMTU5LjQwMTQ4OScgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzEwNS4zODIzNzMnLz4KPHVzZSB4PScxNjUuOTg3OTk2JyB4bGluazpocmVmPScjZzQtNDknIHk9JzEwNS4zODIzNzMnLz4KPHVzZSB4PScxODAuNjgyOTQ3JyB4bGluazpocmVmPScjZzUtNDMnIHk9JzEwMy41ODkxMScvPgo8dXNlIHg9JzE5OS43NTAyMzknIHhsaW5rOmhyZWY9JyNnNS05OScgeT0nMTAzLjU4OTExJy8+Cjx1c2UgeD0nMjA0Ljk1Mjg5NycgeGxpbms6aHJlZj0nI2c1LTExMScgeT0nMTAzLjU4OTExJy8+Cjx1c2UgeD0nMjEwLjgwNTg4NycgeGxpbms6aHJlZj0nI2c1LTEwOScgeT0nMTAzLjU4OTExJy8+Cjx1c2UgeD0nMjIwLjU2MDg3MScgeGxpbms6aHJlZj0nI2c1LTExMicgeT0nMTAzLjU4OTExJy8+Cjx1c2UgeD0nMjI3LjA2NDE5MycgeGxpbms6aHJlZj0nI2c1LTk3JyB5PScxMDMuNTg5MTEnLz4KPHVzZSB4PScyMzIuOTE3MTgzJyB4bGluazpocmVmPScjZzUtMTE0JyB5PScxMDMuNTg5MTEnLz4KPHVzZSB4PScyMzcuNDY5NTA5JyB4bGluazpocmVmPScjZzUtOTcnIHk9JzEwMy41ODkxMScvPgo8dXNlIHg9JzI0My4zMjI0OTknIHhsaW5rOmhyZWY9JyNnNS0xMDUnIHk9JzEwMy41ODkxMScvPgo8dXNlIHg9JzI0Ni41NzQxNjEnIHhsaW5rOmhyZWY9JyNnNS0xMTUnIHk9JzEwMy41ODkxMScvPgo8dXNlIHg9JzI1MS4xOTE1MicgeGxpbms6aHJlZj0nI2c1LTExMScgeT0nMTAzLjU4OTExJy8+Cjx1c2UgeD0nMjU3LjA0NDUxJyB4bGluazpocmVmPScjZzUtMTEwJyB5PScxMDMuNTg5MTEnLz4KPHVzZSB4PScyNjUuNTQwMzMnIHhsaW5rOmhyZWY9JyNnMC0wJyB5PSc5My45MDUzNDcnLz4KPHVzZSB4PScyNzEuMDE5ODEyJyB4bGluazpocmVmPScjZzMtMTA5JyB5PScxMDMuNTg5MTEnLz4KPHVzZSB4PScyODEuMjU5MDc5JyB4bGluazpocmVmPScjZzItMTA1JyB5PSc5OS4yNTA2NzQnLz4KPHVzZSB4PScyODEuMjU5MDc5JyB4bGluazpocmVmPScjZzQtNDknIHk9JzEwNi41NDQ2MjYnLz4KPHVzZSB4PScyODUuOTkxMzk0JyB4bGluazpocmVmPScjZzMtNTknIHk9JzEwMy41ODkxMScvPgo8dXNlIHg9JzI5MS4yMzU1NTMnIHhsaW5rOmhyZWY9JyNnMy0xMDknIHk9JzEwMy41ODkxMScvPgo8dXNlIHg9JzMwMS40NzQ4MicgeGxpbms6aHJlZj0nI2cyLTEwNicgeT0nOTcuOTIxNDkxJy8+Cjx1c2UgeD0nMzAxLjQ3NDgyJyB4bGluazpocmVmPScjZzQtNTAnIHk9JzEwNi41MjAyODgnLz4KPHVzZSB4PSczMDYuMjA3MTM1JyB4bGluazpocmVmPScjZzAtMScgeT0nOTMuOTA1MzQ3Jy8+Cjx1c2UgeD0nMzEzLjY3OTExNScgeGxpbms6aHJlZj0nI2czLTU5JyB5PScxMDMuNTg5MTEnLz4KPHVzZSB4PScxMzMuMzc4NjE4JyB4bGluazpocmVmPScjZzMtMTAwJyB5PScxMTguNzEwMDUnLz4KPHVzZSB4PScxMzkuNDYxMzExJyB4bGluazpocmVmPScjZzItMTA1JyB5PScxMjAuNTAzMzEzJy8+Cjx1c2UgeD0nMTQyLjM0NDQ1MScgeGxpbms6aHJlZj0nI2cyLTU5JyB5PScxMjAuNTAzMzEzJy8+Cjx1c2UgeD0nMTQ0LjY5Njc3NScgeGxpbms6aHJlZj0nI2cyLTEwNicgeT0nMTIwLjUwMzMxMycvPgo8dXNlIHg9JzE0OC41ODA4JyB4bGluazpocmVmPScjZzEtMCcgeT0nMTIwLjUwMzMxMycvPgo8dXNlIHg9JzE1NS4xNjczMDYnIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nMTIwLjUwMzMxMycvPgo8dXNlIHg9JzE4MC42ODI5NDcnIHhsaW5rOmhyZWY9JyNnNS00MycgeT0nMTE4LjcxMDA1Jy8+Cjx1c2UgeD0nMTk5Ljc1MDIzOScgeGxpbms6aHJlZj0nI2c1LTEwNScgeT0nMTE4LjcxMDA1Jy8+Cjx1c2UgeD0nMjAzLjAwMTknIHhsaW5rOmhyZWY9JyNnNS0xMTAnIHk9JzExOC43MTAwNScvPgo8dXNlIHg9JzIwOS41MDUyMjInIHhsaW5rOmhyZWY9JyNnNS0xMTUnIHk9JzExOC43MTAwNScvPgo8dXNlIHg9JzIxNC4xMjI1ODEnIHhsaW5rOmhyZWY9JyNnNS0xMDEnIHk9JzExOC43MTAwNScvPgo8dXNlIHg9JzIxOS4zMjUyMzknIHhsaW5rOmhyZWY9JyNnNS0xMTQnIHk9JzExOC43MTAwNScvPgo8dXNlIHg9JzIyMy44Nzc1NjUnIHhsaW5rOmhyZWY9JyNnNS0xMTYnIHk9JzExOC43MTAwNScvPgo8dXNlIHg9JzIyOC40Mjk4OTEnIHhsaW5rOmhyZWY9JyNnNS0xMDUnIHk9JzExOC43MTAwNScvPgo8dXNlIHg9JzIzMS42ODE1NTInIHhsaW5rOmhyZWY9JyNnNS0xMTEnIHk9JzExOC43MTAwNScvPgo8dXNlIHg9JzIzNy41MzQ1NDInIHhsaW5rOmhyZWY9JyNnNS0xMTAnIHk9JzExOC43MTAwNScvPgo8dXNlIHg9JzI0Ni4wMzAzNjInIHhsaW5rOmhyZWY9JyNnMC0wJyB5PScxMDkuMDI2Mjg2Jy8+Cjx1c2UgeD0nMjUxLjUwOTg0NScgeGxpbms6aHJlZj0nI2czLTEwOScgeT0nMTE4LjcxMDA1Jy8+Cjx1c2UgeD0nMjYxLjc0OTExMicgeGxpbms6aHJlZj0nI2cyLTEwNicgeT0nMTEzLjA0MjQzJy8+Cjx1c2UgeD0nMjYxLjc0OTExMicgeGxpbms6aHJlZj0nI2c0LTUwJyB5PScxMjEuNjQxMjI3Jy8+Cjx1c2UgeD0nMjY2LjQ4MTQyNycgeGxpbms6aHJlZj0nI2czLTU5JyB5PScxMTguNzEwMDUnLz4KPHVzZSB4PScyNzEuNzI1NTg1JyB4bGluazpocmVmPScjZzMtMTA1JyB5PScxMTguNzEwMDUnLz4KPHVzZSB4PScyNzUuNzE5MDE4JyB4bGluazpocmVmPScjZzAtMScgeT0nMTA5LjAyNjI4NicvPgo8dXNlIHg9JzI4My4xOTA5OTgnIHhsaW5rOmhyZWY9JyNnMy01OScgeT0nMTE4LjcxMDA1Jy8+Cjx1c2UgeD0nMTMzLjM3ODYxOCcgeGxpbms6aHJlZj0nI2czLTEwMCcgeT0nMTMyLjY1Nzc3NicvPgo8dXNlIHg9JzEzOS40NjEzMTEnIHhsaW5rOmhyZWY9JyNnMi0xMDUnIHk9JzEzNC40NTEwMzknLz4KPHVzZSB4PScxNDIuMzQ0NDUxJyB4bGluazpocmVmPScjZzEtMCcgeT0nMTM0LjQ1MTAzOScvPgo8dXNlIHg9JzE0OC45MzA5NTcnIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nMTM0LjQ1MTAzOScvPgo8dXNlIHg9JzE1My4xNjUxNCcgeGxpbms6aHJlZj0nI2cyLTU5JyB5PScxMzQuNDUxMDM5Jy8+Cjx1c2UgeD0nMTU1LjUxNzQ2NCcgeGxpbms6aHJlZj0nI2cyLTEwNicgeT0nMTM0LjQ1MTAzOScvPgo8dXNlIHg9JzE4MC42ODI5NDcnIHhsaW5rOmhyZWY9JyNnNS00MycgeT0nMTMyLjY1Nzc3NicvPgo8dXNlIHg9JzE5OS43NTAyMzknIHhsaW5rOmhyZWY9JyNnNS0xMTUnIHk9JzEzMi42NTc3NzYnLz4KPHVzZSB4PScyMDQuMzY3NTk3JyB4bGluazpocmVmPScjZzUtMTE3JyB5PScxMzIuNjU3Nzc2Jy8+Cjx1c2UgeD0nMjEwLjg3MDkyJyB4bGluazpocmVmPScjZzUtMTEyJyB5PScxMzIuNjU3Nzc2Jy8+Cjx1c2UgeD0nMjE3LjM3NDI0MicgeGxpbms6aHJlZj0nI2c1LTExMicgeT0nMTMyLjY1Nzc3NicvPgo8dXNlIHg9JzIyMy44Nzc1NjUnIHhsaW5rOmhyZWY9JyNnNS0xMTQnIHk9JzEzMi42NTc3NzYnLz4KPHVzZSB4PScyMjguNDI5ODkxJyB4bGluazpocmVmPScjZzUtMTAxJyB5PScxMzIuNjU3Nzc2Jy8+Cjx1c2UgeD0nMjMzLjYzMjU0OScgeGxpbms6aHJlZj0nI2c1LTExNScgeT0nMTMyLjY1Nzc3NicvPgo8dXNlIHg9JzIzOC4yNDk5MDgnIHhsaW5rOmhyZWY9JyNnNS0xMTUnIHk9JzEzMi42NTc3NzYnLz4KPHVzZSB4PScyNDIuODY3MjY3JyB4bGluazpocmVmPScjZzUtMTA1JyB5PScxMzIuNjU3Nzc2Jy8+Cjx1c2UgeD0nMjQ2LjExODkyOCcgeGxpbms6aHJlZj0nI2c1LTExMScgeT0nMTMyLjY1Nzc3NicvPgo8dXNlIHg9JzI1MS45NzE5MTgnIHhsaW5rOmhyZWY9JyNnNS0xMTAnIHk9JzEzMi42NTc3NzYnLz4KPHVzZSB4PScyNjAuNDY3NzM4JyB4bGluazpocmVmPScjZzUtNDAnIHk9JzEzMi42NTc3NzYnLz4KPHVzZSB4PScyNjUuMDIwMDY0JyB4bGluazpocmVmPScjZzMtMTA5JyB5PScxMzIuNjU3Nzc2Jy8+Cjx1c2UgeD0nMjc1LjI1OTMzMScgeGxpbms6aHJlZj0nI2cyLTEwNScgeT0nMTI4LjMxOTM0Jy8+Cjx1c2UgeD0nMjc1LjI1OTMzMScgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxMzUuNjEzMjkyJy8+Cjx1c2UgeD0nMjc5Ljk5MTY0NicgeGxpbms6aHJlZj0nI2czLTU5JyB5PScxMzIuNjU3Nzc2Jy8+Cjx1c2UgeD0nMjg1LjIzNTgwNScgeGxpbms6aHJlZj0nI2czLTEwNicgeT0nMTMyLjY1Nzc3NicvPgo8dXNlIHg9JzI5MC43NTEzJyB4bGluazpocmVmPScjZzUtNDEnIHk9JzEzMi42NTc3NzYnLz4KPHVzZSB4PScyOTcuMjk2MTI0JyB4bGluazpocmVmPScjZzMtNTknIHk9JzEzMi42NTc3NzYnLz4KPHVzZSB4PScxMzMuMzc4NjE4JyB4bGluazpocmVmPScjZzMtMTAwJyB5PScxNDcuNzc4Njg1Jy8+Cjx1c2UgeD0nMTM5LjQ2MTMxMScgeGxpbms6aHJlZj0nI2cyLTEwNScgeT0nMTQ5LjU3MTk0OCcvPgo8dXNlIHg9JzE0Mi4zNDQ0NTEnIHhsaW5rOmhyZWY9JyNnMS0wJyB5PScxNDkuNTcxOTQ4Jy8+Cjx1c2UgeD0nMTQ4LjkzMDk1NycgeGxpbms6aHJlZj0nI2c0LTUwJyB5PScxNDkuNTcxOTQ4Jy8+Cjx1c2UgeD0nMTUzLjE2NTE0JyB4bGluazpocmVmPScjZzItNTknIHk9JzE0OS41NzE5NDgnLz4KPHVzZSB4PScxNTUuNTE3NDY0JyB4bGluazpocmVmPScjZzItMTA2JyB5PScxNDkuNTcxOTQ4Jy8+Cjx1c2UgeD0nMTU5LjQwMTQ4OScgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzE0OS41NzE5NDgnLz4KPHVzZSB4PScxNjUuOTg3OTk2JyB4bGluazpocmVmPScjZzQtNTAnIHk9JzE0OS41NzE5NDgnLz4KPHVzZSB4PScxODAuNjgyOTQ3JyB4bGluazpocmVmPScjZzUtNDMnIHk9JzE0Ny43Nzg2ODUnLz4KPHVzZSB4PScxOTkuNzUwMjM5JyB4bGluazpocmVmPScjZzUtMTEyJyB5PScxNDcuNzc4Njg1Jy8+Cjx1c2UgeD0nMjA2LjU3ODcyNycgeGxpbms6aHJlZj0nI2c1LTEwMScgeT0nMTQ3Ljc3ODY4NScvPgo8dXNlIHg9JzIxMS43ODEzODUnIHhsaW5rOmhyZWY9JyNnNS0xMTQnIHk9JzE0Ny43Nzg2ODUnLz4KPHVzZSB4PScyMTYuMzMzNzExJyB4bGluazpocmVmPScjZzUtMTA5JyB5PScxNDcuNzc4Njg1Jy8+Cjx1c2UgeD0nMjI1Ljc2MzUyOScgeGxpbms6aHJlZj0nI2c1LTExNycgeT0nMTQ3Ljc3ODY4NScvPgo8dXNlIHg9JzIzMi4yNjY4NTEnIHhsaW5rOmhyZWY9JyNnNS0xMTYnIHk9JzE0Ny43Nzg2ODUnLz4KPHVzZSB4PScyMzYuODE5MTc3JyB4bGluazpocmVmPScjZzUtOTcnIHk9JzE0Ny43Nzg2ODUnLz4KPHVzZSB4PScyNDIuNjcyMTY3JyB4bGluazpocmVmPScjZzUtMTE2JyB5PScxNDcuNzc4Njg1Jy8+Cjx1c2UgeD0nMjQ3LjIyNDQ5MycgeGxpbms6aHJlZj0nI2c1LTEwNScgeT0nMTQ3Ljc3ODY4NScvPgo8dXNlIHg9JzI1MC40NzYxNTQnIHhsaW5rOmhyZWY9JyNnNS0xMTEnIHk9JzE0Ny43Nzg2ODUnLz4KPHVzZSB4PScyNTYuMzI5MTQ0JyB4bGluazpocmVmPScjZzUtMTEwJyB5PScxNDcuNzc4Njg1Jy8+Cjx1c2UgeD0nMjY0LjgyNDk2NCcgeGxpbms6aHJlZj0nI2cwLTAnIHk9JzEzOC4wOTQ5MjInLz4KPHVzZSB4PScyNzAuMzA0NDQ3JyB4bGluazpocmVmPScjZzAtMCcgeT0nMTM4LjA5NDkyMicvPgo8dXNlIHg9JzI3NS43ODM5MjknIHhsaW5rOmhyZWY9JyNnMy0xMDknIHk9JzE0Ny43Nzg2ODUnLz4KPHVzZSB4PScyODYuMDIzMTk2JyB4bGluazpocmVmPScjZzItMTA1JyB5PScxNDIuODMwNTUxJy8+Cjx1c2UgeD0nMjg4LjkwNjMzNicgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzE0Mi44MzA1NTEnLz4KPHVzZSB4PScyOTUuNDkyODQzJyB4bGluazpocmVmPScjZzQtNDknIHk9JzE0Mi44MzA1NTEnLz4KPHVzZSB4PScyODYuMDIzMTk2JyB4bGluazpocmVmPScjZzQtNDknIHk9JzE1MC43MDk4NjInLz4KPHVzZSB4PSczMDAuMjI1MTU3JyB4bGluazpocmVmPScjZzMtNTknIHk9JzE0Ny43Nzg2ODUnLz4KPHVzZSB4PSczMDUuNDY5MzE2JyB4bGluazpocmVmPScjZzMtMTA5JyB5PScxNDcuNzc4Njg1Jy8+Cjx1c2UgeD0nMzE1LjcwODU4MycgeGxpbms6aHJlZj0nI2cyLTEwNScgeT0nMTQzLjQ0MDI0OCcvPgo8dXNlIHg9JzMxNS43MDg1ODMnIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nMTUwLjczNDInLz4KPHVzZSB4PSczMjAuNDQwODk4JyB4bGluazpocmVmPScjZzAtMScgeT0nMTM4LjA5NDkyMicvPgo8dXNlIHg9JzMyNy45MTI4NzgnIHhsaW5rOmhyZWY9JyNnMy01OScgeT0nMTQ3Ljc3ODY4NScvPgo8dXNlIHg9JzMzMy4xNTcwMzcnIHhsaW5rOmhyZWY9JyNnMC0wJyB5PScxMzguMDk0OTIyJy8+Cjx1c2UgeD0nMzM4LjYzNjUxOScgeGxpbms6aHJlZj0nI2czLTEwOScgeT0nMTQ3Ljc3ODY4NScvPgo8dXNlIHg9JzM0OC44NzU3ODYnIHhsaW5rOmhyZWY9JyNnMi0xMDYnIHk9JzE0Mi4xMTEwNjUnLz4KPHVzZSB4PSczNTIuNzU5ODExJyB4bGluazpocmVmPScjZzEtMCcgeT0nMTQyLjExMTA2NScvPgo8dXNlIHg9JzM1OS4zNDYzMTgnIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nMTQyLjExMTA2NScvPgo8dXNlIHg9JzM0OC44NzU3ODYnIHhsaW5rOmhyZWY9JyNnNC01MCcgeT0nMTUwLjcwOTg2MicvPgo8dXNlIHg9JzM2NC4wNzg2MzMnIHhsaW5rOmhyZWY9JyNnMy01OScgeT0nMTQ3Ljc3ODY4NScvPgo8dXNlIHg9JzM2OS4zMjI3OTInIHhsaW5rOmhyZWY9JyNnMy0xMDknIHk9JzE0Ny43Nzg2ODUnLz4KPHVzZSB4PSczNzkuNTYyMDU5JyB4bGluazpocmVmPScjZzItMTA2JyB5PScxNDIuMTExMDY1Jy8+Cjx1c2UgeD0nMzc5LjU2MjA1OScgeGxpbms6aHJlZj0nI2c0LTUwJyB5PScxNTAuNzA5ODYyJy8+Cjx1c2UgeD0nMzg0LjI5NDM3NCcgeGxpbms6aHJlZj0nI2cwLTEnIHk9JzEzOC4wOTQ5MjInLz4KPHVzZSB4PSczODkuNzczODU2JyB4bGluazpocmVmPScjZzAtMScgeT0nMTM4LjA5NDkyMicvPgo8dXNlIHg9JzQwMC4yMzQ2NTknIHhsaW5rOmhyZWY9JyNnMC01NycgeT0nOTMuNjE1MTE1Jy8+Cjx1c2UgeD0nNDAwLjIzNDY1OScgeGxpbms6aHJlZj0nI2cwLTYyJyB5PScxMDQuMzc0ODc1Jy8+Cjx1c2UgeD0nNDAwLjIzNDY1OScgeGxpbms6aHJlZj0nI2cwLTYyJyB5PScxMDcuOTYxNDYyJy8+Cjx1c2UgeD0nNDAwLjIzNDY1OScgeGxpbms6aHJlZj0nI2cwLTYxJyB5PScxMTEuNTQ4MDQ5Jy8+Cjx1c2UgeD0nNDAwLjIzNDY1OScgeGxpbms6aHJlZj0nI2cwLTYyJyB5PScxMzMuMDY3NTcxJy8+Cjx1c2UgeD0nNDAwLjIzNDY1OScgeGxpbms6aHJlZj0nI2cwLTYyJyB5PScxMzYuNjU0MTU4Jy8+Cjx1c2UgeD0nNDAwLjIzNDY1OScgeGxpbms6aHJlZj0nI2cwLTU5JyB5PScxNDAuMjQwNzQ1Jy8+CjwvZz4KPC9zdmc+)
Lemmes#
 la longueur du plus long préfixe de
la longueur du plus long préfixe de 
![\begin{eqnarray*}
M'(q, S) &=& \min_{d(q, S) \infegal k < l(q)} \acc{ M'(q[1..k], S) + \min( K(q, k, S), l(q) - k) }
\end{eqnarray*}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTkuMzI2NjhwdCcgdmVyc2lvbj0nMS4xJyB2aWV3Qm94PSc1OS43NzY2OTIgODIuMjkyMjQ5IDM0Ni42OTgxOTYgMTkuMzI2NjgnIHdpZHRoPSczNDYuNjk4MTk2cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTcuODc4NDU2IC0yLjc0OTY4OUM4LjA4MTY5NCAtMi43NDk2ODkgOC4yOTY4ODcgLTIuNzQ5Njg5IDguMjk2ODg3IC0yLjk4ODc5MlM4LjA4MTY5NCAtMy4yMjc4OTUgNy44Nzg0NTYgLTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzIgLTMuMjI3ODk1IDAuOTkyMjc5IC0zLjIyNzg5NSAwLjk5MjI3OSAtMi45ODg3OTJTMS4yMDc0NzIgLTIuNzQ5Njg5IDEuNDEwNzEgLTIuNzQ5Njg5SDcuODc4NDU2WicgaWQ9J2cyLTAnLz4KPHBhdGggZD0nTTMuMzgzMzEzIC03LjM3NjMzOUMzLjM4MzMxMyAtNy44NTQ1NDUgMy42OTQxNDcgLTguNjE5Njc2IDQuOTk3MjYgLTguNzAzMzYyQzUuMDU3MDM2IC04LjcxNTMxOCA1LjEwNDg1NyAtOC43NjMxMzggNS4xMDQ4NTcgLTguODM0ODY5QzUuMTA0ODU3IC04Ljk2NjM3NiA1LjAwOTIxNSAtOC45NjYzNzYgNC44Nzc3MDkgLTguOTY2Mzc2QzMuNjgyMTkyIC04Ljk2NjM3NiAyLjU5NDI3MSAtOC4zNTY2NjMgMi41ODIzMTYgLTcuNDcxOThWLTQuNzQ2MjAyQzIuNTgyMzE2IC00LjI3OTk1IDIuNTgyMzE2IC0zLjg5NzM4NSAyLjEwNDExIC0zLjUwMjg2NEMxLjY4NTY3OSAtMy4xNTYxNjQgMS4yMzEzODIgLTMuMTMyMjU0IDAuOTY4MzY5IC0zLjEyMDI5OUMwLjkwODU5MyAtMy4xMDgzNDQgMC44NjA3NzIgLTMuMDYwNTIzIDAuODYwNzcyIC0yLjk4ODc5MkMwLjg2MDc3MiAtMi44NjkyNCAwLjkzMjUwMyAtMi44NjkyNCAxLjA1MjA1NSAtMi44NTcyODVDMS44NDEwOTYgLTIuODA5NDY1IDIuNDE0OTQ0IC0yLjM3OTA3OCAyLjU0NjQ1MSAtMS43OTMyNzVDMi41ODIzMTYgLTEuNjYxNzY4IDIuNTgyMzE2IC0xLjYzNzg1OCAyLjU4MjMxNiAtMS4yMDc0NzJWMS4xNTk2NTFDMi41ODIzMTYgMS42NjE3NjggMi41ODIzMTYgMi4wNDQzMzQgMy4xNTYxNjQgMi40OTg2M0MzLjYyMjQxNiAyLjg1NzI4NSA0LjQxMTQ1NyAyLjk4ODc5MiA0Ljg3NzcwOSAyLjk4ODc5MkM1LjAwOTIxNSAyLjk4ODc5MiA1LjEwNDg1NyAyLjk4ODc5MiA1LjEwNDg1NyAyLjg1NzI4NUM1LjEwNDg1NyAyLjczNzczMyA1LjAzMzEyNiAyLjczNzczMyA0LjkxMzU3NCAyLjcyNTc3OEM0LjE2MDM5OSAyLjY3Nzk1OCAzLjU3NDU5NSAyLjI5NTM5MiAzLjQxOTE3OCAxLjY4NTY3OUMzLjM4MzMxMyAxLjU3ODA4MiAzLjM4MzMxMyAxLjU1NDE3MiAzLjM4MzMxMyAxLjEyMzc4NlYtMS4zODY4QzMuMzgzMzEzIC0xLjkzNjczNyAzLjI4NzY3MSAtMi4xMzk5NzUgMi45MDUxMDYgLTIuNTIyNTRDMi42NTQwNDcgLTIuNzczNTk5IDIuMzA3MzQ3IC0yLjg5MzE1MSAxLjk3MjYwMyAtMi45ODg3OTJDMi45NTI5MjcgLTMuMjYzNzYxIDMuMzgzMzEzIC0zLjgxMzY5OSAzLjM4MzMxMyAtNC41MDcwOThWLTcuMzc2MzM5WicgaWQ9J2cyLTEwMicvPgo8cGF0aCBkPSdNMi41ODIzMTYgMS4zOTg3NTVDMi41ODIzMTYgMS44NzY5NjEgMi4yNzE0ODIgMi42NDIwOTIgMC45NjgzNjkgMi43MjU3NzhDMC45MDg1OTMgMi43Mzc3MzMgMC44NjA3NzIgMi43ODU1NTQgMC44NjA3NzIgMi44NTcyODVDMC44NjA3NzIgMi45ODg3OTIgMC45OTIyNzkgMi45ODg3OTIgMS4wOTk4NzUgMi45ODg3OTJDMi4yNTk1MjcgMi45ODg3OTIgMy4zNzEzNTcgMi40MDI5ODkgMy4zODMzMTMgMS40OTQzOTZWLTEuMjMxMzgyQzMuMzgzMzEzIC0xLjY5NzYzNCAzLjM4MzMxMyAtMi4wODAxOTkgMy44NjE1MTkgLTIuNDc0NzJDNC4yNzk5NSAtMi44MjE0MiA0LjczNDI0NyAtMi44NDUzMyA0Ljk5NzI2IC0yLjg1NzI4NUM1LjA1NzAzNiAtMi44NjkyNCA1LjEwNDg1NyAtMi45MTcwNjEgNS4xMDQ4NTcgLTIuOTg4NzkyQzUuMTA0ODU3IC0zLjEwODM0NCA1LjAzMzEyNiAtMy4xMDgzNDQgNC45MTM1NzQgLTMuMTIwMjk5QzQuMTI0NTMzIC0zLjE2ODEyIDMuNTUwNjg1IC0zLjU5ODUwNiAzLjQxOTE3OCAtNC4xODQzMDlDMy4zODMzMTMgLTQuMzE1ODE2IDMuMzgzMzEzIC00LjMzOTcyNiAzLjM4MzMxMyAtNC43NzAxMTJWLTcuMTM3MjM1QzMuMzgzMzEzIC03LjYzOTM1MiAzLjM4MzMxMyAtOC4wMjE5MTggMi44MDk0NjUgLTguNDc2MjE0QzIuMzMxMjU4IC04Ljg0NjgyNCAxLjUwNjM1MSAtOC45NjYzNzYgMS4wOTk4NzUgLTguOTY2Mzc2QzAuOTkyMjc5IC04Ljk2NjM3NiAwLjg2MDc3MiAtOC45NjYzNzYgMC44NjA3NzIgLTguODM0ODY5QzAuODYwNzcyIC04LjcxNTMxOCAwLjkzMjUwMyAtOC43MTUzMTggMS4wNTIwNTUgLTguNzAzMzYyQzEuODA1MjMgLTguNjU1NTQyIDIuMzkxMDM0IC04LjI3Mjk3NiAyLjU0NjQ1MSAtNy42NjMyNjNDMi41ODIzMTYgLTcuNTU1NjY2IDIuNTgyMzE2IC03LjUzMTc1NiAyLjU4MjMxNiAtNy4xMDEzN1YtNC41OTA3ODVDMi41ODIzMTYgLTQuMDQwODQ3IDIuNjc3OTU4IC0zLjgzNzYwOSAzLjA2MDUyMyAtMy40NTUwNDRDMy4zMTE1ODIgLTMuMjAzOTg1IDMuNjU4MjgxIC0zLjA4NDQzMyAzLjk5MzAyNiAtMi45ODg3OTJDMy4wMTI3MDIgLTIuNzEzODIzIDIuNTgyMzE2IC0yLjE2Mzg4NSAyLjU4MjMxNiAtMS40NzA0ODZWMS4zOTg3NTVaJyBpZD0nZzItMTAzJy8+CjxwYXRoIGQ9J00yLjE5OTc1MSAtMC41NzM4NDhDMi4xOTk3NTEgLTAuOTIwNTQ4IDEuOTEyODI3IC0xLjE1OTY1MSAxLjYyNTkwMyAtMS4xNTk2NTFDMS4yNzkyMDMgLTEuMTU5NjUxIDEuMDQwMSAtMC44NzI3MjcgMS4wNDAxIC0wLjU4NTgwM0MxLjA0MDEgLTAuMjM5MTAzIDEuMzI3MDI0IDAgMS42MTM5NDggMEMxLjk2MDY0OCAwIDIuMTk5NzUxIC0wLjI4NjkyNCAyLjE5OTc1MSAtMC41NzM4NDhaJyBpZD0nZzQtNTgnLz4KPHBhdGggZD0nTTIuMzMxMjU4IDAuMDQ3ODIxQzIuMzMxMjU4IC0wLjY0NTU3OSAyLjEwNDExIC0xLjE1OTY1MSAxLjYxMzk0OCAtMS4xNTk2NTFDMS4yMzEzODIgLTEuMTU5NjUxIDEuMDQwMSAtMC44NDg4MTcgMS4wNDAxIC0wLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3IC0wLjA0NzgyMSAyLjAyMDQyMyAtMC4xNTU0MTdDMi4wNDQzMzQgLTAuMTc5MzI4IDIuMDU2Mjg5IC0wLjE3OTMyOCAyLjA2ODI0NCAtMC4xNzkzMjhDMi4wOTIxNTQgLTAuMTc5MzI4IDIuMDkyMTU0IC0wLjAxMTk1NSAyLjA5MjE1NCAwLjA0NzgyMUMyLjA5MjE1NCAwLjQ0MjM0MSAyLjAyMDQyMyAxLjIxOTQyNyAxLjMyNzAyNCAxLjk5NjUxM0MxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjQxMDcxIDIuMzA3MzQ3IDIuMzMxMjU4IDEuNDIyNjY1IDIuMzMxMjU4IDAuMDQ3ODIxWicgaWQ9J2c0LTU5Jy8+CjxwYXRoIGQ9J001Ljk3NzU4NCAtNC44Mjk4ODhDNS45NjU2MjkgLTQuODY1NzUzIDUuOTE3ODA4IC00Ljk2MTM5NSA1LjkxNzgwOCAtNC45OTcyNkM1LjkxNzgwOCAtNS4wMDkyMTUgNS45Mjk3NjMgLTUuMDIxMTcxIDYuMTMzMDAxIC01LjE3NjU4OEw3LjI5MjY1MyAtNi4wODUxODFDOC44OTQ2NDUgLTcuMzI4NTE4IDkuNDIwNjcyIC03Ljc0Njk0OSAxMC4yNDU1NzkgLTcuODE4NjhDMTAuMzI5MjY1IC03LjgzMDYzNSAxMC40NDg4MTcgLTcuODMwNjM1IDEwLjQ0ODgxNyAtOC4wMzM4NzNDMTAuNDQ4ODE3IC04LjEwNTYwNCAxMC40MTI5NTEgLTguMTY1MzggMTAuMzE3MzEgLTguMTY1MzhDMTAuMTg1ODAzIC04LjE2NTM4IDEwLjA0MjM0MSAtOC4xNDE0NjkgOS45MTA4MzQgLTguMTQxNDY5SDkuNDU2NTM4QzkuMDg1OTI4IC04LjE0MTQ2OSA4LjY5MTQwNyAtOC4xNjUzOCA4LjMzMjc1MiAtOC4xNjUzOEM4LjI0OTA2NiAtOC4xNjUzOCA4LjEwNTYwNCAtOC4xNjUzOCA4LjEwNTYwNCAtNy45NTAxODdDOC4xMDU2MDQgLTcuODMwNjM1IDguMTg5MjkgLTcuODE4NjggOC4yNjEwMjEgLTcuODE4NjhDOC4zOTI1MjggLTcuODA2NzI1IDguNTQ3OTQ1IC03Ljc1ODkwNCA4LjU0Nzk0NSAtNy41OTE1MzJDOC41NDc5NDUgLTcuMzUyNDI4IDguMTg5MjkgLTcuMDY1NTA0IDguMDkzNjQ5IC02Ljk5Mzc3M0wzLjQwNzIyMyAtMy4zNDc0NDdMNC4zOTk1MDIgLTcuMjkyNjUzQzQuNTA3MDk4IC03LjY5OTEyOCA0LjUzMTAwOSAtNy44MTg2OCA1LjM3OTgyNiAtNy44MTg2OEM1LjYwNjk3NCAtNy44MTg2OCA1LjcxNDU3IC03LjgxODY4IDUuNzE0NTcgLTguMDQ1ODI4QzUuNzE0NTcgLTguMTY1MzggNS41OTUwMTkgLTguMTY1MzggNS41MzUyNDMgLTguMTY1MzhDNS4zMjAwNSAtOC4xNjUzOCA1LjA2ODk5MSAtOC4xNDE0NjkgNC44NDE4NDMgLTguMTQxNDY5SDMuNDMxMTMzQzMuMjE1OTQgLTguMTQxNDY5IDIuOTUyOTI3IC04LjE2NTM4IDIuNzM3NzMzIC04LjE2NTM4QzIuNjQyMDkyIC04LjE2NTM4IDIuNTEwNTg1IC04LjE2NTM4IDIuNTEwNTg1IC03LjkzODIzMkMyLjUxMDU4NSAtNy44MTg2OCAyLjYxODE4MiAtNy44MTg2OCAyLjc5NzUwOSAtNy44MTg2OEMzLjUyNjc3NSAtNy44MTg2OCAzLjUyNjc3NSAtNy43MjMwMzkgMy41MjY3NzUgLTcuNTkxNTMyQzMuNTI2Nzc1IC03LjU2NzYyMSAzLjUyNjc3NSAtNy40OTU4OSAzLjQ3ODk1NCAtNy4zMTY1NjNMMS44NjUwMDYgLTAuODg0NjgyQzEuNzU3NDEgLTAuNDY2MjUyIDEuNzMzNDk5IC0wLjM0NjcgMC44OTY2MzggLTAuMzQ2N0MwLjY2OTQ4OSAtMC4zNDY3IDAuNTQ5OTM4IC0wLjM0NjcgMC41NDk5MzggLTAuMTMxNTA3QzAuNTQ5OTM4IDAgMC42NTc1MzQgMCAwLjcyOTI2NSAwQzAuOTU2NDEzIDAgMS4xOTU1MTcgLTAuMDIzOTEgMS40MjI2NjUgLTAuMDIzOTFIMi44MjE0MkMzLjA0ODU2OCAtMC4wMjM5MSAzLjI5OTYyNiAwIDMuNTI2Nzc1IDBDMy42MjI0MTYgMCAzLjc1MzkyMyAwIDMuNzUzOTIzIC0wLjIyNzE0OEMzLjc1MzkyMyAtMC4zNDY3IDMuNjQ2MzI2IC0wLjM0NjcgMy40NjY5OTkgLTAuMzQ2N0MyLjczNzczMyAtMC4zNDY3IDIuNzM3NzMzIC0wLjQ0MjM0MSAyLjczNzczMyAtMC41NjE4OTNDMi43Mzc3MzMgLTAuNjQ1NTc5IDIuODA5NDY1IC0wLjk0NDQ1OCAyLjg1NzI4NSAtMS4xMzU3NDFMMy4zMjM1MzcgLTIuOTg4NzkyTDUuMTQwNzIyIC00LjQxMTQ1N0M1LjQ4NzQyMiAtMy42NDYzMjYgNi4xMjEwNDYgLTIuMTE2MDY1IDYuNjExMjA4IC0wLjk0NDQ1OEM2LjY0NzA3MyAtMC44NzI3MjcgNi42NzA5ODQgLTAuODAwOTk2IDYuNjcwOTg0IC0wLjcxNzMxQzYuNjcwOTg0IC0wLjM1ODY1NSA2LjE5Mjc3NyAtMC4zNDY3IDYuMDg1MTgxIC0wLjM0NjdTNS44NTgwMzIgLTAuMzQ2NyA1Ljg1ODAzMiAtMC4xMTk1NTJDNS44NTgwMzIgMCA1Ljk4OTUzOSAwIDYuMDI1NDA1IDBDNi40NDM4MzYgMCA2Ljg4NjE3NyAtMC4wMjM5MSA3LjMwNDYwOCAtMC4wMjM5MUg3Ljg3ODQ1NkM4LjA1Nzc4MyAtMC4wMjM5MSA4LjI2MTAyMSAwIDguNDQwMzQ5IDBDOC41MTIwOCAwIDguNjQzNTg3IDAgOC42NDM1ODcgLTAuMjI3MTQ4QzguNjQzNTg3IC0wLjM0NjcgOC41MzU5OSAtMC4zNDY3IDguNDE2NDM4IC0wLjM0NjdDNy45NzQwOTcgLTAuMzU4NjU1IDcuODE4NjggLTAuNDU0Mjk2IDcuNjM5MzUyIC0wLjg4NDY4Mkw1Ljk3NzU4NCAtNC44Mjk4ODhaJyBpZD0nZzQtNzUnLz4KPHBhdGggZD0nTTEwLjg1NTI5MyAtNy4yOTI2NTNDMTAuOTYyODg5IC03LjY5OTEyOCAxMC45ODY4IC03LjgxODY4IDExLjgzNTYxNiAtNy44MTg2OEMxMi4wNjI3NjUgLTcuODE4NjggMTIuMTcwMzYxIC03LjgxODY4IDEyLjE3MDM2MSAtOC4wNDU4MjhDMTIuMTcwMzYxIC04LjE2NTM4IDEyLjA4NjY3NSAtOC4xNjUzOCAxMS44NTk1MjcgLTguMTY1MzhIMTAuNDI0OTA3QzEwLjEyNjAyNyAtOC4xNjUzOCAxMC4xMTQwNzIgLTguMTUzNDI1IDkuOTgyNTY1IC03Ljk2MjE0Mkw1LjYxODkyOSAtMS4wNjQwMUw0LjcyMjI5MSAtNy45MDIzNjZDNC42ODY0MjYgLTguMTY1MzggNC42NzQ0NzEgLTguMTY1MzggNC4zNjM2MzYgLTguMTY1MzhIMi44ODExOTZDMi42NTQwNDcgLTguMTY1MzggMi41NDY0NTEgLTguMTY1MzggMi41NDY0NTEgLTcuOTM4MjMyQzIuNTQ2NDUxIC03LjgxODY4IDIuNjU0MDQ3IC03LjgxODY4IDIuODMzMzc1IC03LjgxODY4QzMuNTYyNjQgLTcuODE4NjggMy41NjI2NCAtNy43MjMwMzkgMy41NjI2NCAtNy41OTE1MzJDMy41NjI2NCAtNy41Njc2MjEgMy41NjI2NCAtNy40OTU4OSAzLjUxNDgxOSAtNy4zMTY1NjNMMS45ODQ1NTggLTEuMjE5NDI3QzEuODQxMDk2IC0wLjY0NTU3OSAxLjU2NjEyNyAtMC4zODI1NjUgMC43NjUxMzEgLTAuMzQ2N0MwLjcyOTI2NSAtMC4zNDY3IDAuNTg1ODAzIC0wLjMzNDc0NSAwLjU4NTgwMyAtMC4xMzE1MDdDMC41ODU4MDMgMCAwLjY5MzQgMCAwLjc0MTIyIDBDMC45ODAzMjQgMCAxLjU5MDAzNyAtMC4wMjM5MSAxLjgyOTE0MSAtMC4wMjM5MUgyLjQwMjk4OUMyLjU3MDM2MSAtMC4wMjM5MSAyLjc3MzU5OSAwIDIuOTQwOTcxIDBDMy4wMjQ2NTggMCAzLjE1NjE2NCAwIDMuMTU2MTY0IC0wLjIyNzE0OEMzLjE1NjE2NCAtMC4zMzQ3NDUgMy4wMzY2MTMgLTAuMzQ2NyAyLjk4ODc5MiAtMC4zNDY3QzIuNTk0MjcxIC0wLjM1ODY1NSAyLjIxMTcwNiAtMC40MzAzODYgMi4yMTE3MDYgLTAuODYwNzcyQzIuMjExNzA2IC0wLjk4MDMyNCAyLjIxMTcwNiAtMC45OTIyNzkgMi4yNTk1MjcgLTEuMTU5NjUxTDMuOTA5MzQgLTcuNzQ2OTQ5SDMuOTIxMjk1TDQuOTEzNTc0IC0wLjMyMjc5QzQuOTQ5NDQgLTAuMDM1ODY2IDQuOTYxMzk1IDAgNS4wNjg5OTEgMEM1LjIwMDQ5OCAwIDUuMjYwMjc0IC0wLjA5NTY0MSA1LjMyMDA1IC0wLjIwMzIzOEwxMC4xMjYwMjcgLTcuODA2NzI1SDEwLjEzNzk4M0w4LjQwNDQ4MyAtMC44ODQ2ODJDOC4yOTY4ODcgLTAuNDY2MjUyIDguMjcyOTc2IC0wLjM0NjcgNy40MzYxMTUgLTAuMzQ2N0M3LjIwODk2NiAtMC4zNDY3IDcuMDg5NDE1IC0wLjM0NjcgNy4wODk0MTUgLTAuMTMxNTA3QzcuMDg5NDE1IDAgNy4xOTcwMTEgMCA3LjI2ODc0MiAwQzcuNDcxOTggMCA3LjcxMTA4MyAtMC4wMjM5MSA3LjkxNDMyMSAtMC4wMjM5MUg5LjMyNTAzMUM5LjUyODI2OSAtMC4wMjM5MSA5Ljc3OTMyOCAwIDkuOTgyNTY1IDBDMTAuMDc4MjA3IDAgMTAuMjA5NzE0IDAgMTAuMjA5NzE0IC0wLjIyNzE0OEMxMC4yMDk3MTQgLTAuMzQ2NyAxMC4xMDIxMTcgLTAuMzQ2NyA5LjkyMjc5IC0wLjM0NjdDOS4xOTM1MjQgLTAuMzQ2NyA5LjE5MzUyNCAtMC40NDIzNDEgOS4xOTM1MjQgLTAuNTYxODkzQzkuMTkzNTI0IC0wLjU3Mzg0OCA5LjE5MzUyNCAtMC42NTc1MzQgOS4yMTc0MzUgLTAuNzUzMTc2TDEwLjg1NTI5MyAtNy4yOTI2NTNaJyBpZD0nZzQtNzcnLz4KPHBhdGggZD0nTTcuNTkxNTMyIC04LjMwODg0MkM3LjU5MTUzMiAtOC40MTY0MzggNy41MDc4NDYgLTguNDE2NDM4IDcuNDgzOTM1IC04LjQxNjQzOEM3LjQzNjExNSAtOC40MTY0MzggNy40MjQxNTkgLTguNDA0NDgzIDcuMjgwNjk3IC04LjIyNTE1NkM3LjIwODk2NiAtOC4xNDE0NjkgNi43MTg4MDQgLTcuNTE5ODAxIDYuNzA2ODQ5IC03LjUwNzg0NkM2LjMxMjMyOSAtOC4yODQ5MzIgNS41MjMyODggLTguNDE2NDM4IDUuMDIxMTcxIC04LjQxNjQzOEMzLjUwMjg2NCAtOC40MTY0MzggMi4xMjgwMiAtNy4wMjk2MzkgMi4xMjgwMiAtNS42Nzg3MDVDMi4xMjgwMiAtNC43ODIwNjcgMi42NjYwMDIgLTQuMjU2MDQgMy4yNTE4MDYgLTQuMDUyODAyQzMuMzgzMzEzIC00LjAwNDk4MSA0LjA4ODY2NyAtMy44MTM2OTkgNC40NDczMjMgLTMuNzMwMDEyQzUuMDU3MDM2IC0zLjU2MjY0IDUuMjEyNDUzIC0zLjUxNDgxOSA1LjQ2MzUxMiAtMy4yNTE4MDZDNS41MTEzMzMgLTMuMTkyMDMgNS43NTA0MzYgLTIuOTE3MDYxIDUuNzUwNDM2IC0yLjM1NTE2OEM1Ljc1MDQzNiAtMS4yNDMzMzcgNC43MjIyOTEgLTAuMDk1NjQxIDMuNTI2Nzc1IC0wLjA5NTY0MUMyLjU0NjQ1MSAtMC4wOTU2NDEgMS40NTg1MzEgLTAuNTE0MDcyIDEuNDU4NTMxIC0xLjg1MzA1MUMxLjQ1ODUzMSAtMi4wODAxOTkgMS41MDYzNTEgLTIuMzY3MTIzIDEuNTQyMjE3IC0yLjQ4NjY3NUMxLjU0MjIxNyAtMi41MjI1NCAxLjU1NDE3MiAtMi41ODIzMTYgMS41NTQxNzIgLTIuNjA2MjI3QzEuNTU0MTcyIC0yLjY1NDA0NyAxLjUzMDI2MiAtMi43MTM4MjMgMS40MzQ2MiAtMi43MTM4MjNDMS4zMjcwMjQgLTIuNzEzODIzIDEuMzE1MDY4IC0yLjY4OTkxMyAxLjI2NzI0OCAtMi40ODY2NzVMMC42NTc1MzQgLTAuMDM1ODY2QzAuNjU3NTM0IC0wLjAyMzkxIDAuNjA5NzE0IDAuMTMxNTA3IDAuNjA5NzE0IDAuMTQzNDYyQzAuNjA5NzE0IDAuMjUxMDU5IDAuNzA1MzU1IDAuMjUxMDU5IDAuNzI5MjY1IDAuMjUxMDU5QzAuNzc3MDg2IDAuMjUxMDU5IDAuNzg5MDQxIDAuMjM5MTAzIDAuOTMyNTAzIDAuMDU5Nzc2TDEuNDgyNDQxIC0wLjY1NzUzNEMxLjc2OTM2NSAtMC4yMjcxNDggMi4zOTEwMzQgMC4yNTEwNTkgMy41MDI4NjQgMC4yNTEwNTlDNS4wNDUwODEgMC4yNTEwNTkgNi40NTU3OTEgLTEuMjQzMzM3IDYuNDU1NzkxIC0yLjczNzczM0M2LjQ1NTc5MSAtMy4yMzk4NTEgNi4zMzYyMzkgLTMuNjgyMTkyIDUuODgxOTQzIC00LjEyNDUzM0M1LjYzMDg4NCAtNC4zNzU1OTIgNS40MTU2OTEgLTQuNDM1MzY3IDQuMzE1ODE2IC00LjcyMjI5MUMzLjUxNDgxOSAtNC45Mzc0ODQgMy40MDcyMjMgLTQuOTczMzUgMy4xOTIwMyAtNS4xNjQ2MzNDMi45ODg3OTIgLTUuMzY3ODcgMi44MzMzNzUgLTUuNjU0Nzk1IDIuODMzMzc1IC02LjA2MTI3QzIuODMzMzc1IC03LjA2NTUwNCAzLjg0OTU2NCAtOC4wOTM2NDkgNC45ODUzMDUgLTguMDkzNjQ5QzYuMTU2OTEyIC04LjA5MzY0OSA2LjcwNjg0OSAtNy4zNzYzMzkgNi43MDY4NDkgLTYuMjQwNTk4QzYuNzA2ODQ5IC01LjkyOTc2MyA2LjY0NzA3MyAtNS42MDY5NzQgNi42NDcwNzMgLTUuNTU5MTUzQzYuNjQ3MDczIC01LjQ1MTU1NyA2Ljc0MjcxNSAtNS40NTE1NTcgNi43Nzg1OCAtNS40NTE1NTdDNi44ODYxNzcgLTUuNDUxNTU3IDYuODk4MTMyIC01LjQ4NzQyMiA2Ljk0NTk1MyAtNS42Nzg3MDVMNy41OTE1MzIgLTguMzA4ODQyWicgaWQ9J2c0LTgzJy8+CjxwYXRoIGQ9J00zLjM1OTQwMiAtNy45OTgwMDdDMy4zNzEzNTcgLTguMDQ1ODI4IDMuMzk1MjY4IC04LjExNzU1OSAzLjM5NTI2OCAtOC4xNzczMzVDMy4zOTUyNjggLTguMjk2ODg3IDMuMjc1NzE2IC04LjI5Njg4NyAzLjI1MTgwNiAtOC4yOTY4ODdDMy4yMzk4NTEgLTguMjk2ODg3IDIuODA5NDY1IC04LjI2MTAyMSAyLjU5NDI3MSAtOC4yMzcxMTFDMi4zOTEwMzQgLTguMjI1MTU2IDIuMjExNzA2IC04LjIwMTI0NSAxLjk5NjUxMyAtOC4xODkyOUMxLjcwOTU4OSAtOC4xNjUzOCAxLjYyNTkwMyAtOC4xNTM0MjUgMS42MjU5MDMgLTcuOTM4MjMyQzEuNjI1OTAzIC03LjgxODY4IDEuNzQ1NDU1IC03LjgxODY4IDEuODY1MDA2IC03LjgxODY4QzIuNDc0NzIgLTcuODE4NjggMi40NzQ3MiAtNy43MTEwODMgMi40NzQ3MiAtNy41OTE1MzJDMi40NzQ3MiAtNy41NDM3MTEgMi40NzQ3MiAtNy41MTk4MDEgMi40MTQ5NDQgLTcuMzA0NjA4TDAuNzA1MzU1IC0wLjQ2NjI1MkMwLjY1NzUzNCAtMC4yODY5MjQgMC42NTc1MzQgLTAuMjYzMDE0IDAuNjU3NTM0IC0wLjE5MTI4M0MwLjY1NzUzNCAwLjA3MTczMSAwLjg2MDc3MiAwLjExOTU1MiAwLjk4MDMyNCAwLjExOTU1MkMxLjMxNTA2OCAwLjExOTU1MiAxLjM4NjggLTAuMTQzNDYyIDEuNDgyNDQxIC0wLjUxNDA3MkwyLjA0NDMzNCAtMi43NDk2ODlDMi45MDUxMDYgLTIuNjU0MDQ3IDMuNDE5MTc4IC0yLjI5NTM5MiAzLjQxOTE3OCAtMS43MjE1NDRDMy40MTkxNzggLTEuNjQ5ODEzIDMuNDE5MTc4IC0xLjYwMTk5MyAzLjM4MzMxMyAtMS40MjI2NjVDMy4zMzU0OTIgLTEuMjQzMzM3IDMuMzM1NDkyIC0xLjA5OTg3NSAzLjMzNTQ5MiAtMS4wNDAxQzMuMzM1NDkyIC0wLjM0NjcgMy43ODk3ODggMC4xMTk1NTIgNC4zOTk1MDIgMC4xMTk1NTJDNC45NDk0NCAwLjExOTU1MiA1LjIzNjM2NCAtMC4zODI1NjUgNS4zMzIwMDUgLTAuNTQ5OTM4QzUuNTgzMDY0IC0wLjk5MjI3OSA1LjczODQ4MSAtMS42NjE3NjggNS43Mzg0ODEgLTEuNzA5NTg5QzUuNzM4NDgxIC0xLjc2OTM2NSA1LjY5MDY2IC0xLjgxNzE4NiA1LjYxODkyOSAtMS44MTcxODZDNS41MTEzMzMgLTEuODE3MTg2IDUuNDk5Mzc3IC0xLjc2OTM2NSA1LjQ1MTU1NyAtMS41NzgwODJDNS4yODQxODQgLTAuOTU2NDEzIDUuMDMzMTI2IC0wLjExOTU1MiA0LjQyMzQxMiAtMC4xMTk1NTJDNC4xODQzMDkgLTAuMTE5NTUyIDQuMDI4ODkyIC0wLjIzOTEwMyA0LjAyODg5MiAtMC42OTM0QzQuMDI4ODkyIC0wLjkyMDU0OCA0LjA3NjcxMiAtMS4xODM1NjIgNC4xMjQ1MzMgLTEuMzYyODg5QzQuMTcyMzU0IC0xLjU3ODA4MiA0LjE3MjM1NCAtMS41OTAwMzcgNC4xNzIzNTQgLTEuNzMzNDk5QzQuMTcyMzU0IC0yLjQzODg1NCAzLjUzODczIC0yLjgzMzM3NSAyLjQzODg1NCAtMi45NzY4MzdDMi44NjkyNCAtMy4yMzk4NTEgMy4yOTk2MjYgLTMuNzA2MTAyIDMuNDY2OTk5IC0zLjg4NTQzQzQuMTQ4NDQzIC00LjY1MDU2IDQuNjE0Njk1IC01LjAzMzEyNiA1LjE2NDYzMyAtNS4wMzMxMjZDNS40Mzk2MDEgLTUuMDMzMTI2IDUuNTExMzMzIC00Ljk2MTM5NSA1LjU5NTAxOSAtNC44ODk2NjRDNS4xNTI2NzcgLTQuODQxODQzIDQuOTg1MzA1IC00LjUzMTAwOSA0Ljk4NTMwNSAtNC4yOTE5MDVDNC45ODUzMDUgLTQuMDA0OTgxIDUuMjEyNDUzIC0zLjkwOTM0IDUuMzc5ODI2IC0zLjkwOTM0QzUuNzAyNjE1IC0zLjkwOTM0IDUuOTg5NTM5IC00LjE4NDMwOSA1Ljk4OTUzOSAtNC41NjY4NzRDNS45ODk1MzkgLTQuOTEzNTc0IDUuNzE0NTcgLTUuMjcyMjI5IDUuMTc2NTg4IC01LjI3MjIyOUM0LjUxOTA1NCAtNS4yNzIyMjkgMy45ODEwNzEgLTQuODA1OTc4IDMuMTMyMjU0IC0zLjg0OTU2NEMzLjAxMjcwMiAtMy43MDYxMDIgMi41NzAzNjEgLTMuMjUxODA2IDIuMTI4MDIgLTMuMDg0NDMzTDMuMzU5NDAyIC03Ljk5ODAwN1onIGlkPSdnNC0xMDcnLz4KPHBhdGggZD0nTTMuMDM2NjEzIC03Ljk5ODAwN0MzLjA0ODU2OCAtOC4wNDU4MjggMy4wNzI0NzggLTguMTE3NTU5IDMuMDcyNDc4IC04LjE3NzMzNUMzLjA3MjQ3OCAtOC4yOTY4ODcgMi45NTI5MjcgLTguMjk2ODg3IDIuOTI5MDE2IC04LjI5Njg4N0MyLjkxNzA2MSAtOC4yOTY4ODcgMi40ODY2NzUgLTguMjYxMDIxIDIuMjcxNDgyIC04LjIzNzExMUMyLjA2ODI0NCAtOC4yMjUxNTYgMS44ODg5MTcgLTguMjAxMjQ1IDEuNjczNzI0IC04LjE4OTI5QzEuMzg2OCAtOC4xNjUzOCAxLjMwMzExMyAtOC4xNTM0MjUgMS4zMDMxMTMgLTcuOTM4MjMyQzEuMzAzMTEzIC03LjgxODY4IDEuNDIyNjY1IC03LjgxODY4IDEuNTQyMjE3IC03LjgxODY4QzIuMTUxOTMgLTcuODE4NjggMi4xNTE5MyAtNy43MTEwODMgMi4xNTE5MyAtNy41OTE1MzJDMi4xNTE5MyAtNy41NDM3MTEgMi4xNTE5MyAtNy41MTk4MDEgMi4wOTIxNTQgLTcuMzA0NjA4TDAuNjA5NzE0IC0xLjM3NDg0NEMwLjU3Mzg0OCAtMS4yNDMzMzcgMC41NDk5MzggLTEuMTQ3Njk2IDAuNTQ5OTM4IC0wLjk1NjQxM0MwLjU0OTkzOCAtMC4zNTg2NTUgMC45OTIyNzkgMC4xMTk1NTIgMS42MDE5OTMgMC4xMTk1NTJDMS45OTY1MTMgMC4xMTk1NTIgMi4yNTk1MjcgLTAuMTQzNDYyIDIuNDUwODA5IC0wLjUxNDA3MkMyLjY1NDA0NyAtMC45MDg1OTMgMi44MjE0MiAtMS42NjE3NjggMi44MjE0MiAtMS43MDk1ODlDMi44MjE0MiAtMS43NjkzNjUgMi43NzM1OTkgLTEuODE3MTg2IDIuNzAxODY4IC0xLjgxNzE4NkMyLjU5NDI3MSAtMS44MTcxODYgMi41ODIzMTYgLTEuNzU3NDEgMi41MzQ0OTYgLTEuNTc4MDgyQzIuMzE5MzAzIC0wLjc1MzE3NiAyLjEwNDExIC0wLjExOTU1MiAxLjYyNTkwMyAtMC4xMTk1NTJDMS4yNjcyNDggLTAuMTE5NTUyIDEuMjY3MjQ4IC0wLjUwMjExNyAxLjI2NzI0OCAtMC42Njk0ODlDMS4yNjcyNDggLTAuNzE3MzEgMS4yNjcyNDggLTAuOTY4MzY5IDEuMzUwOTM0IC0xLjMwMzExM0wzLjAzNjYxMyAtNy45OTgwMDdaJyBpZD0nZzQtMTA4Jy8+CjxwYXRoIGQ9J001LjI3MjIyOSAtNS4xNTI2NzdDNS4yNzIyMjkgLTUuMjEyNDUzIDUuMjI0NDA4IC01LjI2MDI3NCA1LjE2NDYzMyAtNS4yNjAyNzRDNS4wNjg5OTEgLTUuMjYwMjc0IDQuNjAyNzQgLTQuODI5ODg4IDQuMzc1NTkyIC00LjQxMTQ1N0M0LjE2MDM5OSAtNC45NDk0NCAzLjc4OTc4OCAtNS4yNzIyMjkgMy4yNzU3MTYgLTUuMjcyMjI5QzEuOTI0NzgyIC01LjI3MjIyOSAwLjQ2NjI1MiAtMy41MjY3NzUgMC40NjYyNTIgLTEuNzU3NDFDMC40NjYyNTIgLTAuNTczODQ4IDEuMTU5NjUxIDAuMTE5NTUyIDEuOTcyNjAzIDAuMTE5NTUyQzIuNjA2MjI3IDAuMTE5NTUyIDMuMTMyMjU0IC0wLjM1ODY1NSAzLjM4MzMxMyAtMC42MzM2MjRMMy4zOTUyNjggLTAuNjIxNjY5TDIuOTQwOTcxIDEuMTcxNjA2TDIuODMzMzc1IDEuNjAxOTkzQzIuNzI1Nzc4IDEuOTYwNjQ4IDIuNTQ2NDUxIDEuOTYwNjQ4IDEuOTg0NTU4IDEuOTcyNjAzQzEuODUzMDUxIDEuOTcyNjAzIDEuNzMzNDk5IDEuOTcyNjAzIDEuNzMzNDk5IDIuMTk5NzUxQzEuNzMzNDk5IDIuMjgzNDM3IDEuODA1MjMgMi4zMTkzMDMgMS44ODg5MTcgMi4zMTkzMDNDMi4wNTYyODkgMi4zMTkzMDMgMi4yNzE0ODIgMi4yOTUzOTIgMi40Mzg4NTQgMi4yOTUzOTJIMy42NTgyODFDMy44Mzc2MDkgMi4yOTUzOTIgNC4wNDA4NDcgMi4zMTkzMDMgNC4yMjAxNzQgMi4zMTkzMDNDNC4yOTE5MDUgMi4zMTkzMDMgNC40MzUzNjcgMi4zMTkzMDMgNC40MzUzNjcgMi4wOTIxNTRDNC40MzUzNjcgMS45NzI2MDMgNC4zMzk3MjYgMS45NzI2MDMgNC4xNjAzOTkgMS45NzI2MDNDMy41OTg1MDYgMS45NzI2MDMgMy41NjI2NCAxLjg4ODkxNyAzLjU2MjY0IDEuNzkzMjc1QzMuNTYyNjQgMS43MzM0OTkgMy41NzQ1OTUgMS43MjE1NDQgMy42MTA0NjEgMS41NjYxMjdMNS4yNzIyMjkgLTUuMTUyNjc3Wk0zLjU4NjU1IC0xLjQyMjY2NUMzLjUyNjc3NSAtMS4yMTk0MjcgMy41MjY3NzUgLTEuMTk1NTE3IDMuMzU5NDAyIC0wLjk2ODM2OUMzLjA5NjM4OSAtMC42MzM2MjQgMi41NzAzNjEgLTAuMTE5NTUyIDIuMDA4NDY4IC0wLjExOTU1MkMxLjUxODMwNiAtMC4xMTk1NTIgMS4yNDMzMzcgLTAuNTYxODkzIDEuMjQzMzM3IC0xLjI2NzI0OEMxLjI0MzMzNyAtMS45MjQ3ODIgMS42MTM5NDggLTMuMjYzNzYxIDEuODQxMDk2IC0zLjc2NTg3OEMyLjI0NzU3MiAtNC42MDI3NCAyLjgwOTQ2NSAtNS4wMzMxMjYgMy4yNzU3MTYgLTUuMDMzMTI2QzQuMDY0NzU3IC01LjAzMzEyNiA0LjIyMDE3NCAtNC4wNTI4MDIgNC4yMjAxNzQgLTMuOTU3MTYxQzQuMjIwMTc0IC0zLjk0NTIwNSA0LjE4NDMwOSAtMy43ODk3ODggNC4xNzIzNTQgLTMuNzY1ODc4TDMuNTg2NTUgLTEuNDIyNjY1WicgaWQ9J2c0LTExMycvPgo8cGF0aCBkPSdNMi42NTQwNDcgMS45OTI1MjhDMi43MTc4MDggMS45OTI1MjggMi44MTM0NSAxLjk5MjUyOCAyLjgxMzQ1IDEuODk2ODg3QzIuODEzNDUgMS44NjUwMDYgMi44MDU0NzkgMS44NTcwMzYgMi43MDE4NjggMS43NTM0MjVDMS42MDk5NjMgMC43MjUyOCAxLjMzODk3OSAtMC43NTcxNjEgMS4zMzg5NzkgLTEuOTkyNTI4QzEuMzM4OTc5IC00LjI4NzkyIDIuMjg3NDIyIC01LjM2Mzg4NSAyLjY5Mzg5OCAtNS43MzA1MTFDMi44MDU0NzkgLTUuODM0MTIyIDIuODEzNDUgLTUuODQyMDkyIDIuODEzNDUgLTUuODgxOTQzUzIuNzgxNTY5IC01Ljk3NzU4NCAyLjcwMTg2OCAtNS45Nzc1ODRDMi41NzQzNDYgLTUuOTc3NTg0IDIuMTc1ODQxIC01LjU3MTEwOCAyLjExMjA4IC01LjQ5OTM3N0MxLjA0NDA4NSAtNC4zODM1NjIgMC44MjA5MjIgLTIuOTQ4OTQxIDAuODIwOTIyIC0xLjk5MjUyOEMwLjgyMDkyMiAtMC4yMDcyMjMgMS41NzAxMTIgMS4yMjczOTcgMi42NTQwNDcgMS45OTI1MjhaJyBpZD0nZzUtNDAnLz4KPHBhdGggZD0nTTIuNDYyNzY1IC0xLjk5MjUyOEMyLjQ2Mjc2NSAtMi43NDk2ODkgMi4zMzUyNDMgLTMuNjU4MjgxIDEuODQxMDk2IC00LjU5ODc1NUMxLjQ1MDU2IC01LjMzMjAwNSAwLjcyNTI4IC01Ljk3NzU4NCAwLjU4MTgxOCAtNS45Nzc1ODRDMC41MDIxMTcgLTUuOTc3NTg0IDAuNDc4MjA3IC01LjkyMTc5MyAwLjQ3ODIwNyAtNS44ODE5NDNDMC40NzgyMDcgLTUuODUwMDYyIDAuNDc4MjA3IC01LjgzNDEyMiAwLjU3Mzg0OCAtNS43Mzg0ODFDMS42ODk2NjQgLTQuNjc4NDU2IDEuOTQ0NzA3IC0zLjIxOTkyNSAxLjk0NDcwNyAtMS45OTI1MjhDMS45NDQ3MDcgMC4yOTQ4OTQgMC45OTYyNjQgMS4zNzg4MjkgMC41ODk3ODggMS43NDU0NTVDMC40ODYxNzcgMS44NDkwNjYgMC40NzgyMDcgMS44NTcwMzYgMC40NzgyMDcgMS44OTY4ODdTMC41MDIxMTcgMS45OTI1MjggMC41ODE4MTggMS45OTI1MjhDMC43MDkzNCAxLjk5MjUyOCAxLjEwNzg0NiAxLjU4NjA1MiAxLjE3MTYwNiAxLjUxNDMyMUMyLjIzOTYwMSAwLjM5ODUwNiAyLjQ2Mjc2NSAtMS4wMzYxMTUgMi40NjI3NjUgLTEuOTkyNTI4WicgaWQ9J2c1LTQxJy8+CjxwYXRoIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4NiAtMC41Mzc5ODMgMS44MTcxODYgLTIuOTc2ODM3QzEuODE3MTg2IC01LjI5NjEzOSAyLjM3OTA3OCAtNy4yOTI2NTMgMy43NjU4NzggLTguNzAzMzYyQzMuODg1NDMgLTguODEwOTU5IDMuODg1NDMgLTguODM0ODY5IDMuODg1NDMgLTguODcwNzM1QzMuODg1NDMgLTguOTQyNDY2IDMuODI1NjU0IC04Ljk2NjM3NiAzLjc3NzgzMyAtOC45NjYzNzZDMy42MjI0MTYgLTguOTY2Mzc2IDIuNjQyMDkyIC04LjEwNTYwNCAyLjA1NjI4OSAtNi45MzM5OThDMS40NDY1NzUgLTUuNzI2NTI2IDEuMTcxNjA2IC00LjQ0NzMyMyAxLjE3MTYwNiAtMi45NzY4MzdDMS4xNzE2MDYgLTEuOTEyODI3IDEuMzM4OTc5IC0wLjQ5MDE2MiAxLjk2MDY0OCAwLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJyBpZD0nZzYtNDAnLz4KPHBhdGggZD0nTTMuMzcxMzU3IC0yLjk3NjgzN0MzLjM3MTM1NyAtMy44ODU0MyAzLjI1MTgwNiAtNS4zNjc4NyAyLjU4MjMxNiAtNi43NTQ2N0MxLjg3Njk2MSAtOC4xODkyOSAwLjg5NjYzOCAtOC45NjYzNzYgMC43NjUxMzEgLTguOTY2Mzc2QzAuNzE3MzEgLTguOTY2Mzc2IDAuNjU3NTM0IC04Ljk0MjQ2NiAwLjY1NzUzNCAtOC44NzA3MzVDMC42NTc1MzQgLTguODM0ODY5IDAuNjU3NTM0IC04LjgxMDk1OSAwLjg2MDc3MiAtOC42MDc3MjFDMi4wNTYyODkgLTcuNDAwMjQ5IDIuNzI1Nzc4IC01LjQyNzY0NiAyLjcyNTc3OCAtMi45ODg3OTJDMi43MjU3NzggLTAuNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IDAuNzc3MDg2IDIuNzM3NzMzQzAuNjU3NTM0IDIuODQ1MzMgMC42NTc1MzQgMi44NjkyNCAwLjY1NzUzNCAyLjkwNTEwNkMwLjY1NzUzNCAyLjk3NjgzNyAwLjcxNzMxIDMuMDAwNzQ3IDAuNzY1MTMxIDMuMDAwNzQ3QzAuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IDAuOTY4MzY5QzMuMDk2Mzg5IC0wLjI1MTA1OSAzLjM3MTM1NyAtMS41NDIyMTcgMy4zNzEzNTcgLTIuOTc2ODM3WicgaWQ9J2c2LTQxJy8+CjxwYXRoIGQ9J000Ljc3MDExMiAtMi43NjE2NDRIOC4wNjk3MzhDOC4yMzcxMTEgLTIuNzYxNjQ0IDguNDUyMzA0IC0yLjc2MTY0NCA4LjQ1MjMwNCAtMi45NzY4MzdDOC40NTIzMDQgLTMuMjAzOTg1IDguMjQ5MDY2IC0zLjIwMzk4NSA4LjA2OTczOCAtMy4yMDM5ODVINC43NzAxMTJWLTYuNTAzNjExQzQuNzcwMTEyIC02LjY3MDk4NCA0Ljc3MDExMiAtNi44ODYxNzcgNC41NTQ5MTkgLTYuODg2MTc3QzQuMzI3NzcxIC02Ljg4NjE3NyA0LjMyNzc3MSAtNi42ODI5MzkgNC4zMjc3NzEgLTYuNTAzNjExVi0zLjIwMzk4NUgxLjAyODE0NEMwLjg2MDc3MiAtMy4yMDM5ODUgMC42NDU1NzkgLTMuMjAzOTg1IDAuNjQ1NTc5IC0yLjk4ODc5MkMwLjY0NTU3OSAtMi43NjE2NDQgMC44NDg4MTcgLTIuNzYxNjQ0IDEuMDI4MTQ0IC0yLjc2MTY0NEg0LjMyNzc3MVYwLjUzNzk4M0M0LjMyNzc3MSAwLjcwNTM1NSA0LjMyNzc3MSAwLjkyMDU0OCA0LjU0Mjk2NCAwLjkyMDU0OEM0Ljc3MDExMiAwLjkyMDU0OCA0Ljc3MDExMiAwLjcxNzMxIDQuNzcwMTEyIDAuNTM3OTgzVi0yLjc2MTY0NFonIGlkPSdnNi00MycvPgo8cGF0aCBkPSdNMy40NDMwODggLTcuNjYzMjYzQzMuNDQzMDg4IC03LjkzODIzMiAzLjQ0MzA4OCAtNy45NTAxODcgMy4yMDM5ODUgLTcuOTUwMTg3QzIuOTE3MDYxIC03LjYyNzM5NyAyLjMxOTMwMyAtNy4xODUwNTYgMS4wODc5MiAtNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5IC02LjgzODM1NiAxLjk2MDY0OCAtNi44MzgzNTYgMi42MTgxODIgLTcuMTQ5MTkxVi0wLjkyMDU0OEMyLjYxODE4MiAtMC40OTAxNjIgMi41ODIzMTYgLTAuMzQ2NyAxLjUzMDI2MiAtMC4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEgLTAuMDIzOTEgMi42NDIwOTIgLTAuMDIzOTEgMy4wMzY2MTMgLTAuMDIzOTFTNC41Nzg4MjkgLTAuMDIzOTEgNC45MDE2MTkgMFYtMC4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0IC0wLjM0NjcgMy40NDMwODggLTAuNDkwMTYyIDMuNDQzMDg4IC0wLjkyMDU0OFYtNy42NjMyNjNaJyBpZD0nZzYtNDknLz4KPHBhdGggZD0nTTguMDY5NzM4IC0zLjg3MzQ3NEM4LjIzNzExMSAtMy44NzM0NzQgOC40NTIzMDQgLTMuODczNDc0IDguNDUyMzA0IC00LjA4ODY2N0M4LjQ1MjMwNCAtNC4zMTU4MTYgOC4yNDkwNjYgLTQuMzE1ODE2IDguMDY5NzM4IC00LjMxNTgxNkgxLjAyODE0NEMwLjg2MDc3MiAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMzE1ODE2IDAuNjQ1NTc5IC00LjEwMDYyM0MwLjY0NTU3OSAtMy44NzM0NzQgMC44NDg4MTcgLTMuODczNDc0IDEuMDI4MTQ0IC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzggLTEuNjQ5ODEzQzguMjM3MTExIC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS42NDk4MTMgOC40NTIzMDQgLTEuODY1MDA2QzguNDUyMzA0IC0yLjA5MjE1NCA4LjI0OTA2NiAtMi4wOTIxNTQgOC4wNjk3MzggLTIuMDkyMTU0SDEuMDI4MTQ0QzAuODYwNzcyIC0yLjA5MjE1NCAwLjY0NTU3OSAtMi4wOTIxNTQgMC42NDU1NzkgLTEuODc2OTYxQzAuNjQ1NTc5IC0xLjY0OTgxMyAwLjg0ODgxNyAtMS42NDk4MTMgMS4wMjgxNDQgLTEuNjQ5ODEzSDguMDY5NzM4WicgaWQ9J2c2LTYxJy8+CjxwYXRoIGQ9J00yLjk4ODc5MiAyLjk4ODc5MlYyLjU0NjQ1MUgxLjgyOTE0MVYtOC41MjQwMzVIMi45ODg3OTJWLTguOTY2Mzc2SDEuMzg2OFYyLjk4ODc5MkgyLjk4ODc5MlonIGlkPSdnNi05MScvPgo8cGF0aCBkPSdNMS44NTMwNTEgLTguOTY2Mzc2SDAuMjUxMDU5Vi04LjUyNDAzNUgxLjQxMDcxVjIuNTQ2NDUxSDAuMjUxMDU5VjIuOTg4NzkySDEuODUzMDUxVi04Ljk2NjM3NlonIGlkPSdnNi05MycvPgo8cGF0aCBkPSdNMi4wODAxOTkgLTcuMzY0Mzg0QzIuMDgwMTk5IC03LjY3NTIxOCAxLjgyOTE0MSAtNy45NTAxODcgMS40OTQzOTYgLTcuOTUwMTg3QzEuMTgzNTYyIC03Ljk1MDE4NyAwLjkyMDU0OCAtNy42OTkxMjggMC45MjA1NDggLTcuMzc2MzM5QzAuOTIwNTQ4IC03LjAxNzY4NCAxLjIwNzQ3MiAtNi43OTA1MzUgMS40OTQzOTYgLTYuNzkwNTM1QzEuODY1MDA2IC02Ljc5MDUzNSAyLjA4MDE5OSAtNy4xMDEzNyAyLjA4MDE5OSAtNy4zNjQzODRaTTAuNDMwMzg2IC01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTcgLTQuNzk0MDIyIDEuMzAzMTEzIC00LjcyMjI5MSAxLjMwMzExMyAtNC4xMzY0ODhWLTAuODg0NjgyQzEuMzAzMTEzIC0wLjM0NjcgMS4xNzE2MDYgLTAuMzQ2NyAwLjM5NDUyMSAtMC4zNDY3VjBDMC43MjkyNjUgLTAuMDIzOTEgMS4zMDMxMTMgLTAuMDIzOTEgMS42NDk4MTMgLTAuMDIzOTFDMS43ODEzMiAtMC4wMjM5MSAyLjQ3NDcyIC0wLjAyMzkxIDIuODgxMTk2IDBWLTAuMzQ2N0MyLjEwNDExIC0wLjM0NjcgMi4wNTYyODkgLTAuNDA2NDc2IDIuMDU2Mjg5IC0wLjg3MjcyN1YtNS4yNzIyMjlMMC40MzAzODYgLTUuMTQwNzIyWicgaWQ9J2c2LTEwNScvPgo8cGF0aCBkPSdNOC41NzE4NTYgLTIuOTA1MTA2QzguNTcxODU2IC00LjAxNjkzNiA4LjU3MTg1NiAtNC4zNTE2ODEgOC4yOTY4ODcgLTQuNzM0MjQ3QzcuOTUwMTg3IC01LjIwMDQ5OCA3LjM4ODI5NCAtNS4yNzIyMjkgNi45ODE4MTggLTUuMjcyMjI5QzUuOTg5NTM5IC01LjI3MjIyOSA1LjQ4NzQyMiAtNC41NTQ5MTkgNS4yOTYxMzkgLTQuMDg4NjY3QzUuMTI4NzY3IC01LjAwOTIxNSA0LjQ4MzE4OCAtNS4yNzIyMjkgMy43MzAwMTIgLTUuMjcyMjI5QzIuNTcwMzYxIC01LjI3MjIyOSAyLjExNjA2NSAtNC4yNzk5NSAyLjAyMDQyMyAtNC4wNDA4NDdIMi4wMDg0NjhWLTUuMjcyMjI5TDAuMzgyNTY1IC01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTcgLTQuNzk0MDIyIDEuMjkxMTU4IC00LjcxMDMzNiAxLjI5MTE1OCAtNC4xMjQ1MzNWLTAuODg0NjgyQzEuMjkxMTU4IC0wLjM0NjcgMS4xNTk2NTEgLTAuMzQ2NyAwLjM4MjU2NSAtMC4zNDY3VjBDMC42OTM0IC0wLjAyMzkxIDEuMzM4OTc5IC0wLjAyMzkxIDEuNjczNzI0IC0wLjAyMzkxQzIuMDIwNDIzIC0wLjAyMzkxIDIuNjY2MDAyIC0wLjAyMzkxIDIuOTc2ODM3IDBWLTAuMzQ2N0MyLjIxMTcwNiAtMC4zNDY3IDIuMDY4MjQ0IC0wLjM0NjcgMi4wNjgyNDQgLTAuODg0NjgyVi0zLjEwODM0NEMyLjA2ODI0NCAtNC4zNjM2MzYgMi44OTMxNTEgLTUuMDMzMTI2IDMuNjM0MzcxIC01LjAzMzEyNlM0LjU0Mjk2NCAtNC40MjM0MTIgNC41NDI5NjQgLTMuNjk0MTQ3Vi0wLjg4NDY4MkM0LjU0Mjk2NCAtMC4zNDY3IDQuNDExNDU3IC0wLjM0NjcgMy42MzQzNzEgLTAuMzQ2N1YwQzMuOTQ1MjA1IC0wLjAyMzkxIDQuNTkwNzg1IC0wLjAyMzkxIDQuOTI1NTI5IC0wLjAyMzkxQzUuMjcyMjI5IC0wLjAyMzkxIDUuOTE3ODA4IC0wLjAyMzkxIDYuMjI4NjQzIDBWLTAuMzQ2N0M1LjQ2MzUxMiAtMC4zNDY3IDUuMzIwMDUgLTAuMzQ2NyA1LjMyMDA1IC0wLjg4NDY4MlYtMy4xMDgzNDRDNS4zMjAwNSAtNC4zNjM2MzYgNi4xNDQ5NTYgLTUuMDMzMTI2IDYuODg2MTc3IC01LjAzMzEyNlM3Ljc5NDc3IC00LjQyMzQxMiA3Ljc5NDc3IC0zLjY5NDE0N1YtMC44ODQ2ODJDNy43OTQ3NyAtMC4zNDY3IDcuNjYzMjYzIC0wLjM0NjcgNi44ODYxNzcgLTAuMzQ2N1YwQzcuMTk3MDExIC0wLjAyMzkxIDcuODQyNTkgLTAuMDIzOTEgOC4xNzczMzUgLTAuMDIzOTFDOC41MjQwMzUgLTAuMDIzOTEgOS4xNjk2MTQgLTAuMDIzOTEgOS40ODA0NDggMFYtMC4zNDY3QzguODgyNjkgLTAuMzQ2NyA4LjU4MzgxMSAtMC4zNDY3IDguNTcxODU2IC0wLjcwNTM1NVYtMi45MDUxMDZaJyBpZD0nZzYtMTA5Jy8+CjxwYXRoIGQ9J001LjMyMDA1IC0yLjkwNTEwNkM1LjMyMDA1IC00LjAxNjkzNiA1LjMyMDA1IC00LjM1MTY4MSA1LjA0NTA4MSAtNC43MzQyNDdDNC42OTgzODEgLTUuMjAwNDk4IDQuMTM2NDg4IC01LjI3MjIyOSAzLjczMDAxMiAtNS4yNzIyMjlDMi41NzAzNjEgLTUuMjcyMjI5IDIuMTE2MDY1IC00LjI3OTk1IDIuMDIwNDIzIC00LjA0MDg0N0gyLjAwODQ2OFYtNS4yNzIyMjlMMC4zODI1NjUgLTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE5NTUxNyAtNC43OTQwMjIgMS4yOTExNTggLTQuNzEwMzM2IDEuMjkxMTU4IC00LjEyNDUzM1YtMC44ODQ2ODJDMS4yOTExNTggLTAuMzQ2NyAxLjE1OTY1MSAtMC4zNDY3IDAuMzgyNTY1IC0wLjM0NjdWMEMwLjY5MzQgLTAuMDIzOTEgMS4zMzg5NzkgLTAuMDIzOTEgMS42NzM3MjQgLTAuMDIzOTFDMi4wMjA0MjMgLTAuMDIzOTEgMi42NjYwMDIgLTAuMDIzOTEgMi45NzY4MzcgMFYtMC4zNDY3QzIuMjExNzA2IC0wLjM0NjcgMi4wNjgyNDQgLTAuMzQ2NyAyLjA2ODI0NCAtMC44ODQ2ODJWLTMuMTA4MzQ0QzIuMDY4MjQ0IC00LjM2MzYzNiAyLjg5MzE1MSAtNS4wMzMxMjYgMy42MzQzNzEgLTUuMDMzMTI2UzQuNTQyOTY0IC00LjQyMzQxMiA0LjU0Mjk2NCAtMy42OTQxNDdWLTAuODg0NjgyQzQuNTQyOTY0IC0wLjM0NjcgNC40MTE0NTcgLTAuMzQ2NyAzLjYzNDM3MSAtMC4zNDY3VjBDMy45NDUyMDUgLTAuMDIzOTEgNC41OTA3ODUgLTAuMDIzOTEgNC45MjU1MjkgLTAuMDIzOTFDNS4yNzIyMjkgLTAuMDIzOTEgNS45MTc4MDggLTAuMDIzOTEgNi4yMjg2NDMgMFYtMC4zNDY3QzUuNjMwODg0IC0wLjM0NjcgNS4zMzIwMDUgLTAuMzQ2NyA1LjMyMDA1IC0wLjcwNTM1NVYtMi45MDUxMDZaJyBpZD0nZzYtMTEwJy8+CjxwYXRoIGQ9J00yLjExMjA4IC0zLjc3NzgzM0MyLjE1MTkzIC0zLjg4MTQ0NSAyLjE4MzgxMSAtMy45MzcyMzUgMi4xODM4MTEgLTQuMDE2OTM2QzIuMTgzODExIC00LjI3OTk1IDEuOTQ0NzA3IC00LjQ1NTI5MyAxLjcyMTU0NCAtNC40NTUyOTNDMS40MDI3NCAtNC40NTUyOTMgMS4zMTUwNjggLTQuMTc2MzM5IDEuMjgzMTg4IC00LjA2NDc1N0wwLjI3MDk4NCAtMC42Mjk2MzlDMC4yMzkxMDMgLTAuNTMzOTk4IDAuMjM5MTAzIC0wLjUxMDA4NyAwLjIzOTEwMyAtMC41MDIxMTdDMC4yMzkxMDMgLTAuNDMwMzg2IDAuMjg2OTI0IC0wLjQxNDQ0NiAwLjM2NjYyNSAtMC4zOTA1MzVDMC41MTAwODcgLTAuMzI2Nzc1IDAuNTI2MDI3IC0wLjMyNjc3NSAwLjU0MTk2OCAtMC4zMjY3NzVDMC41NjU4NzggLTAuMzI2Nzc1IDAuNjEzNjk5IC0wLjMyNjc3NSAwLjY2OTQ4OSAtMC40NjIyNjdMMi4xMTIwOCAtMy43Nzc4MzNaJyBpZD0nZzEtNDgnLz4KPHBhdGggZD0nTTEuNDkwNDExIC0wLjExOTU1MkMxLjQ5MDQxMSAwLjM5ODUwNiAxLjM3ODgyOSAwLjg1MjgwMiAwLjg4NDY4MiAxLjM0Njk0OUMwLjg1MjgwMiAxLjM3MDg1OSAwLjgzNjg2MiAxLjM4NjggMC44MzY4NjIgMS40MjY2NUMwLjgzNjg2MiAxLjQ5MDQxMSAwLjkwMDYyMyAxLjUzODIzMiAwLjk1NjQxMyAxLjUzODIzMkMxLjA1MjA1NSAxLjUzODIzMiAxLjcxMzU3NCAwLjkwODU5MyAxLjcxMzU3NCAtMC4wMjM5MUMxLjcxMzU3NCAtMC41MzM5OTggMS41MjIyOTEgLTAuODg0NjgyIDEuMTcxNjA2IC0wLjg4NDY4MkMwLjg5MjY1MyAtMC44ODQ2ODIgMC43MzMyNSAtMC42NjE1MTkgMC43MzMyNSAtMC40NDYzMjZDMC43MzMyNSAtMC4yMjMxNjMgMC44ODQ2ODIgMCAxLjE3OTU3NyAwQzEuMzcwODU5IDAgMS40OTA0MTEgLTAuMTExNTgyIDEuNDkwNDExIC0wLjExOTU1MlonIGlkPSdnMy01OScvPgo8cGF0aCBkPSdNNS43MDY2IC00LjExMjU3OEM1LjgwMjI0MiAtNC4xNjAzOTkgNS44NzM5NzMgLTQuMjA4MjE5IDUuODczOTczIC00LjMxMTgzMVM1Ljc5NDI3MSAtNC40OTUxNDMgNS42OTA2NiAtNC40OTUxNDNDNS42NjY3NSAtNC40OTUxNDMgNS42NTA4MDkgLTQuNDk1MTQzIDUuNTQ3MTk4IC00LjQzOTM1MkwwLjg2ODc0MiAtMi4xOTE3ODFDMC43NzMxMDEgLTIuMTQzOTYgMC43MDEzNyAtMi4wOTYxMzkgMC43MDEzNyAtMS45OTI1MjhTMC43NzMxMDEgLTEuODQxMDk2IDAuODY4NzQyIC0xLjc5MzI3NUw1LjU0NzE5OCAwLjQ1NDI5NkM1LjY1MDgwOSAwLjUxMDA4NyA1LjY2Njc1IDAuNTEwMDg3IDUuNjkwNjYgMC41MTAwODdDNS43OTQyNzEgMC41MTAwODcgNS44NzM5NzMgMC40MzAzODYgNS44NzM5NzMgMC4zMjY3NzVTNS44MDIyNDIgMC4xNzUzNDIgNS43MDY2IDAuMTI3NTIyTDEuMzA3MDk4IC0xLjk5MjUyOEw1LjcwNjYgLTQuMTEyNTc4WicgaWQ9J2czLTYwJy8+CjxwYXRoIGQ9J001LjM0Nzk0NSAtNS4zOTU3NjZDNS4zNTU5MTUgLTUuNDI3NjQ2IDUuMzcxODU2IC01LjQ3NTQ2NyA1LjM3MTg1NiAtNS41MTUzMThDNS4zNzE4NTYgLTUuNTcxMTA4IDUuMzI0MDM1IC01LjYxMDk1OSA1LjI2ODI0NCAtNS42MTA5NTlTNS4xOTY1MTMgLTUuNTk1MDE5IDUuMTA4ODQyIC01LjQ5OTM3N0M1LjAyMTE3MSAtNS4zOTU3NjYgNC44MTM5NDggLTUuMTQwNzIyIDQuNzI2Mjc2IC01LjA0NTA4MUM0LjQxNTQ0MiAtNS40OTkzNzcgMy45MTMzMjUgLTUuNjEwOTU5IDMuNTA2ODQ5IC01LjYxMDk1OUMyLjM5OTAwNCAtNS42MTA5NTkgMS40NTA1NiAtNC42Nzg0NTYgMS40NTA1NiAtMy43Njk4NjNDMS40NTA1NiAtMy4zMDc1OTcgMS42OTc2MzQgLTMuMDM2NjEzIDEuNzM3NDg0IC0yLjk4MDgyMkMyLjAwMDQ5OCAtMi43MDE4NjggMi4yMzE2MzEgLTIuNjM4MTA3IDIuODA1NDc5IC0yLjUwMjYxNUMzLjA4NDQzMyAtMi40MzA4ODQgMy4xMDAzNzQgLTIuNDMwODg0IDMuMzMxNTA3IC0yLjM3NTA5M1M0LjA3MjcyNyAtMi4xOTE3ODEgNC4wNzI3MjcgLTEuNTMwMjYyQzQuMDcyNzI3IC0wLjgzNjg2MiAzLjM4NzI5OCAtMC4wOTU2NDEgMi41NTA0MzYgLTAuMDk1NjQxQzIuMDMyMzc5IC0wLjA5NTY0MSAxLjA4MzkzNSAtMC4yNTUwNDQgMS4wODM5MzUgLTEuMjQzMzM3QzEuMDgzOTM1IC0xLjI2NzI0OCAxLjA4MzkzNSAtMS40MzQ2MiAxLjEzMTc1NiAtMS42MjU5MDNMMS4xMzk3MjYgLTEuNzA1NjA0QzEuMTM5NzI2IC0xLjgwMTI0NSAxLjA1MjA1NSAtMS44MDkyMTUgMS4wMjAxNzQgLTEuODA5MjE1QzAuOTE2NTYzIC0xLjgwOTIxNSAwLjkwODU5MyAtMS43NzczMzUgMC44Njg3NDIgLTEuNTk0MDIyTDAuNTQxOTY4IC0wLjI5NDg5NEMwLjUxMDA4NyAtMC4xNzUzNDIgMC40NTQyOTYgMC4wMzk4NTEgMC40NTQyOTYgMC4wNjM3NjFDMC40NTQyOTYgMC4xMjc1MjIgMC41MDIxMTcgMC4xNjczNzIgMC41NTc5MDggMC4xNjczNzJTMC42MjE2NjkgMC4xNTk0MDIgMC43MDkzNCAwLjA1NTc5MUwxLjA5MTkwNSAtMC4zOTA1MzVDMS4yNzUyMTggLTAuMTUxNDMyIDEuNzI5NTE0IDAuMTY3MzcyIDIuNTM0NDk2IDAuMTY3MzcyQzMuNjkwMTYyIDAuMTY3MzcyIDQuNjM4NjA1IC0wLjg3NjcxMiA0LjYzODYwNSAtMS44MzMxMjZDNC42Mzg2MDUgLTIuMTk5NzUxIDQuNTE5MDU0IC0yLjQ4NjY3NSA0LjMwMzg2MSAtMi43MDk4MzhDNC4wNjQ3NTcgLTIuOTcyODUyIDMuODAxNzQzIC0zLjAzNjYxMyAzLjQyNzE0OCAtMy4xMzIyNTRDMy4xOTYwMTUgLTMuMTg4MDQ1IDIuODg1MTgxIC0zLjI1OTc3NiAyLjcwMTg2OCAtMy4zMDc1OTdDMi40NjI3NjUgLTMuMzYzMzg3IDIuMDE2NDM4IC0zLjUyMjc5IDIuMDE2NDM4IC00LjA4MDY5N0MyLjAxNjQzOCAtNC43MDIzNjYgMi42ODU5MjggLTUuMzcxODU2IDMuNDk4ODc5IC01LjM3MTg1NkM0LjIxNjE4OSAtNS4zNzE4NTYgNC43MTAzMzYgLTQuOTk3MjYgNC43MTAzMzYgLTQuMTM2NDg4QzQuNzEwMzM2IC0zLjk0NTIwNSA0LjY3ODQ1NiAtMy43Nzc4MzMgNC42Nzg0NTYgLTMuNzQ1OTUzQzQuNjc4NDU2IC0zLjY1MDMxMSA0Ljc1MDE4NyAtMy42MzQzNzEgNC44MDU5NzggLTMuNjM0MzcxQzQuOTAxNjE5IC0zLjYzNDM3MSA0LjkwOTU4OSAtMy42NjYyNTIgNC45NDE0NjkgLTMuNzkzNzczTDUuMzQ3OTQ1IC01LjM5NTc2NlonIGlkPSdnMy04MycvPgo8cGF0aCBkPSdNNC4yODc5MiAtNS4yOTIxNTRDNC4yOTU4OSAtNS4zMDgwOTUgNC4zMTk4MDEgLTUuNDExNzA2IDQuMzE5ODAxIC01LjQxOTY3NkM0LjMxOTgwMSAtNS40NTk1MjcgNC4yODc5MiAtNS41MzEyNTggNC4xOTIyNzkgLTUuNTMxMjU4QzQuMTYwMzk5IC01LjUzMTI1OCAzLjkxMzMyNSAtNS41MDczNDcgMy43MzAwMTIgLTUuNDkxNDA3TDMuMjgzNjg2IC01LjQ1OTUyN0MzLjEwODM0NCAtNS40NDM1ODcgMy4wMjg2NDMgLTUuNDM1NjE2IDMuMDI4NjQzIC01LjI5MjE1NEMzLjAyODY0MyAtNS4xODA1NzMgMy4xNDAyMjQgLTUuMTgwNTczIDMuMjM1ODY2IC01LjE4MDU3M0MzLjYxODQzMSAtNS4xODA1NzMgMy42MTg0MzEgLTUuMTMyNzUyIDMuNjE4NDMxIC01LjA2MTAyMUMzLjYxODQzMSAtNS4wMTMyIDMuNTU0NjcgLTQuNzUwMTg3IDMuNTE0ODE5IC00LjU5MDc4NUwzLjEyNDI4NCAtMy4wMzY2MTNDMy4wNTI1NTMgLTMuMTcyMTA1IDIuODIxNDIgLTMuNTE0ODE5IDIuMzM1MjQzIC0zLjUxNDgxOUMxLjM4NjggLTMuNTE0ODE5IDAuMzQyNzE1IC0yLjQwNjk3NCAwLjM0MjcxNSAtMS4yMjczOTdDMC4zNDI3MTUgLTAuMzk4NTA2IDAuODc2NzEyIDAuMDc5NzAxIDEuNDkwNDExIDAuMDc5NzAxQzIuMDAwNDk4IDAuMDc5NzAxIDIuNDM4ODU0IC0wLjMyNjc3NSAyLjU4MjMxNiAtMC40ODYxNzdDMi43MjU3NzggMC4wNjM3NjEgMy4yNjc3NDYgMC4wNzk3MDEgMy4zNjMzODcgMC4wNzk3MDFDMy43MzAwMTIgMC4wNzk3MDEgMy45MTMzMjUgLTAuMjIzMTYzIDMuOTc3MDg2IC0wLjM1ODY1NUM0LjEzNjQ4OCAtMC42NDU1NzkgNC4yNDgwNyAtMS4xMDc4NDYgNC4yNDgwNyAtMS4xMzk3MjZDNC4yNDgwNyAtMS4xODc1NDcgNC4yMTYxODkgLTEuMjQzMzM3IDQuMTIwNTQ4IC0xLjI0MzMzN1M0LjAwODk2NiAtMS4xOTU1MTcgMy45NjExNDYgLTAuOTk2MjY0QzMuODQ5NTY0IC0wLjU1NzkwOCAzLjY5ODEzMiAtMC4xNDM0NjIgMy4zODcyOTggLTAuMTQzNDYyQzMuMjAzOTg1IC0wLjE0MzQ2MiAzLjEzMjI1NCAtMC4yOTQ4OTQgMy4xMzIyNTQgLTAuNTE4MDU3QzMuMTMyMjU0IC0wLjY2OTQ4OSAzLjE1NjE2NCAtMC43NTcxNjEgMy4xODAwNzUgLTAuODYwNzcyTDQuMjg3OTIgLTUuMjkyMTU0Wk0yLjU4MjMxNiAtMC44NjA3NzJDMi4xODM4MTEgLTAuMzEwODM0IDEuNzY5MzY1IC0wLjE0MzQ2MiAxLjUxNDMyMSAtMC4xNDM0NjJDMS4xNDc2OTYgLTAuMTQzNDYyIDAuOTY0Mzg0IC0wLjQ3ODIwNyAwLjk2NDM4NCAtMC44OTI2NTNDMC45NjQzODQgLTEuMjY3MjQ4IDEuMTc5NTc3IC0yLjEyMDA1IDEuMzU0OTE5IC0yLjQ3MDczNUMxLjU4NjA1MiAtMi45NTY5MTIgMS45NzY1ODggLTMuMjkxNjU2IDIuMzQzMjEzIC0zLjI5MTY1NkMyLjg2MTI3IC0zLjI5MTY1NiAzLjAxMjcwMiAtMi43MDk4MzggMy4wMTI3MDIgLTIuNjE0MTk3QzMuMDEyNzAyIC0yLjU4MjMxNiAyLjgxMzQ1IC0xLjgwMTI0NSAyLjc2NTYyOSAtMS41OTQwMjJDMi42NjIwMTcgLTEuMjE5NDI3IDIuNjYyMDE3IC0xLjIwMzQ4NyAyLjU4MjMxNiAtMC44NjA3NzJaJyBpZD0nZzMtMTAwJy8+CjxwYXRoIGQ9J00yLjMyNzI3MyAtNS4yOTIxNTRDMi4zMzUyNDMgLTUuMzA4MDk1IDIuMzU5MTUzIC01LjQxMTcwNiAyLjM1OTE1MyAtNS40MTk2NzZDMi4zNTkxNTMgLTUuNDU5NTI3IDIuMzI3MjczIC01LjUzMTI1OCAyLjIzMTYzMSAtNS41MzEyNThDMi4xOTk3NTEgLTUuNTMxMjU4IDEuOTUyNjc3IC01LjUwNzM0NyAxLjc2OTM2NSAtNS40OTE0MDdMMS4zMjMwMzkgLTUuNDU5NTI3QzEuMTQ3Njk2IC01LjQ0MzU4NyAxLjA2Nzk5NSAtNS40MzU2MTYgMS4wNjc5OTUgLTUuMjkyMTU0QzEuMDY3OTk1IC01LjE4MDU3MyAxLjE3OTU3NyAtNS4xODA1NzMgMS4yNzUyMTggLTUuMTgwNTczQzEuNjU3NzgzIC01LjE4MDU3MyAxLjY1Nzc4MyAtNS4xMzI3NTIgMS42NTc3ODMgLTUuMDYxMDIxQzEuNjU3NzgzIC01LjAzNzExMSAxLjY1Nzc4MyAtNS4wMjExNzEgMS42MTc5MzMgLTQuODc3NzA5TDAuNDg2MTc3IC0wLjM0MjcxNUMwLjQ1NDI5NiAtMC4yMjMxNjMgMC40NTQyOTYgLTAuMTc1MzQyIDAuNDU0Mjk2IC0wLjE2NzM3MkMwLjQ1NDI5NiAtMC4wMzE4OCAwLjU2NTg3OCAwLjA3OTcwMSAwLjcxNzMxIDAuMDc5NzAxQzAuOTg4Mjk0IDAuMDc5NzAxIDEuMDUyMDU1IC0wLjE3NTM0MiAxLjA4MzkzNSAtMC4yODY5MjRDMS4xNjM2MzYgLTAuNjIxNjY5IDEuMzcwODU5IC0xLjQ2NjUwMSAxLjQ1ODUzMSAtMS44MDEyNDVDMS44OTY4ODcgLTEuNzUzNDI1IDIuNDMwODg0IC0xLjYwMTk5MyAyLjQzMDg4NCAtMS4xNDc2OTZDMi40MzA4ODQgLTEuMTA3ODQ2IDIuNDMwODg0IC0xLjA2Nzk5NSAyLjQxNDk0NCAtMC45ODgyOTRDMi4zOTEwMzQgLTAuODg0NjgyIDIuMzc1MDkzIC0wLjc3MzEwMSAyLjM3NTA5MyAtMC43MzMyNUMyLjM3NTA5MyAtMC4yNjMwMTQgMi43MjU3NzggMC4wNzk3MDEgMy4xODgwNDUgMC4wNzk3MDFDMy41MjI3OSAwLjA3OTcwMSAzLjczMDAxMiAtMC4xNjczNzIgMy44MzM2MjQgLTAuMzE4ODA0QzQuMDI0OTA3IC0wLjYxMzY5OSA0LjE1MjQyOCAtMS4wOTE5MDUgNC4xNTI0MjggLTEuMTM5NzI2QzQuMTUyNDI4IC0xLjIxOTQyNyA0LjA4ODY2NyAtMS4yNDMzMzcgNC4wMzI4NzcgLTEuMjQzMzM3QzMuOTM3MjM1IC0xLjI0MzMzNyAzLjkyMTI5NSAtMS4xOTU1MTcgMy44ODk0MTUgLTEuMDUyMDU1QzMuNzg1ODAzIC0wLjY3NzQ2IDMuNTc4NTggLTAuMTQzNDYyIDMuMjAzOTg1IC0wLjE0MzQ2MkMyLjk5Njc2MiAtMC4xNDM0NjIgMi45NDg5NDEgLTAuMzE4ODA0IDIuOTQ4OTQxIC0wLjUzMzk5OEMyLjk0ODk0MSAtMC42Mzc2MDkgMi45NTY5MTIgLTAuNzMzMjUgMi45OTY3NjIgLTAuOTE2NTYzQzMuMDA0NzMyIC0wLjk0ODQ0MyAzLjAzNjYxMyAtMS4wNzU5NjUgMy4wMzY2MTMgLTEuMTYzNjM2QzMuMDM2NjEzIC0xLjgxNzE4NiAyLjIxNTY5MSAtMS45NjA2NDggMS44MDkyMTUgLTIuMDE2NDM4QzIuMTA0MTEgLTIuMTkxNzgxIDIuMzc1MDkzIC0yLjQ2Mjc2NSAyLjQ3MDczNSAtMi41NjYzNzZDMi45MDkwOTEgLTIuOTk2NzYyIDMuMjY3NzQ2IC0zLjI5MTY1NiAzLjY1MDMxMSAtMy4yOTE2NTZDMy43NTM5MjMgLTMuMjkxNjU2IDMuODQ5NTY0IC0zLjI2Nzc0NiAzLjkxMzMyNSAtMy4xODgwNDVDMy40ODI5MzkgLTMuMTMyMjU0IDMuNDgyOTM5IC0yLjc1NzY1OSAzLjQ4MjkzOSAtMi43NDk2ODlDMy40ODI5MzkgLTIuNTc0MzQ2IDMuNjE4NDMxIC0yLjQ1NDc5NSAzLjc5Mzc3MyAtMi40NTQ3OTVDNC4wMDg5NjYgLTIuNDU0Nzk1IDQuMjQ4MDcgLTIuNjMwMTM3IDQuMjQ4MDcgLTIuOTU2OTEyQzQuMjQ4MDcgLTMuMjI3ODk1IDQuMDU2Nzg3IC0zLjUxNDgxOSAzLjY1ODI4MSAtMy41MTQ4MTlDMy4xOTYwMTUgLTMuNTE0ODE5IDIuNzgxNTY5IC0zLjE2NDEzNCAyLjMyNzI3MyAtMi43MDk4MzhDMS44NjUwMDYgLTIuMjU1NTQyIDEuNjY1NzUzIC0yLjE2Nzg3IDEuNTM4MjMyIC0yLjExMjA4TDIuMzI3MjczIC01LjI5MjE1NFonIGlkPSdnMy0xMDcnLz4KPHBhdGggZD0nTTIuMDg4MTY5IC01LjI5MjE1NEMyLjA5NjEzOSAtNS4zMDgwOTUgMi4xMjAwNSAtNS40MTE3MDYgMi4xMjAwNSAtNS40MTk2NzZDMi4xMjAwNSAtNS40NTk1MjcgMi4wODgxNjkgLTUuNTMxMjU4IDEuOTkyNTI4IC01LjUzMTI1OEwxLjE4NzU0NyAtNS40Njc0OTdDMC44OTI2NTMgLTUuNDQzNTg3IDAuODI4ODkyIC01LjQzNTYxNiAwLjgyODg5MiAtNS4yOTIxNTRDMC44Mjg4OTIgLTUuMTgwNTczIDAuOTQwNDczIC01LjE4MDU3MyAxLjAzNjExNSAtNS4xODA1NzNDMS40MTg2OCAtNS4xODA1NzMgMS40MTg2OCAtNS4xMzI3NTIgMS40MTg2OCAtNS4wNjEwMjFDMS40MTg2OCAtNS4wMzcxMTEgMS40MTg2OCAtNS4wMjExNzEgMS4zNzg4MjkgLTQuODc3NzA5TDAuMzkwNTM1IC0wLjkyNDUzM0MwLjM1ODY1NSAtMC43OTcwMTEgMC4zNTg2NTUgLTAuNjc3NDYgMC4zNTg2NTUgLTAuNjY5NDg5QzAuMzU4NjU1IC0wLjE3NTM0MiAwLjc2NTEzMSAwLjA3OTcwMSAxLjE2MzYzNiAwLjA3OTcwMUMxLjUwNjM1MSAwLjA3OTcwMSAxLjY4OTY2NCAtMC4xOTEyODMgMS43NzczMzUgLTAuMzY2NjI1QzEuOTIwNzk3IC0wLjYyOTYzOSAyLjA0MDM0OSAtMS4wOTk4NzUgMi4wNDAzNDkgLTEuMTM5NzI2QzIuMDQwMzQ5IC0xLjE4NzU0NyAyLjAxNjQzOCAtMS4yNDMzMzcgMS45MTI4MjcgLTEuMjQzMzM3QzEuODQxMDk2IC0xLjI0MzMzNyAxLjgxNzE4NiAtMS4yMDM0ODcgMS44MTcxODYgLTEuMTk1NTE3QzEuODAxMjQ1IC0xLjE3MTYwNiAxLjc2MTM5NSAtMS4wMjgxNDQgMS43Mzc0ODQgLTAuOTQwNDczQzEuNjE3OTMzIC0wLjQ3ODIwNyAxLjQ2NjUwMSAtMC4xNDM0NjIgMS4xNzk1NzcgLTAuMTQzNDYyQzAuOTg4Mjk0IC0wLjE0MzQ2MiAwLjkzMjUwMyAtMC4zMjY3NzUgMC45MzI1MDMgLTAuNTE4MDU3QzAuOTMyNTAzIC0wLjY2OTQ4OSAwLjk1NjQxMyAtMC43NTcxNjEgMC45ODAzMjQgLTAuODYwNzcyTDIuMDg4MTY5IC01LjI5MjE1NFonIGlkPSdnMy0xMDgnLz4KPHBhdGggZD0nTTMuNzkzNzczIC0zLjI4MzY4NkMzLjgwMTc0MyAtMy4zMTU1NjcgMy44MDk3MTQgLTMuMzYzMzg3IDMuODA5NzE0IC0zLjQwMzIzOEMzLjgwOTcxNCAtMy40NTEwNTkgMy43Nzc4MzMgLTMuNTE0ODE5IDMuNzA2MTAyIC0zLjUxNDgxOUMzLjYxMDQ2MSAtMy41MTQ4MTkgMy4yODM2ODYgLTMuMjAzOTg1IDMuMTU2MTY0IC0yLjk4MDgyMkMzLjA2ODQ5MyAtMy4xNTYxNjQgMi44MjkzOSAtMy41MTQ4MTkgMi4zMzUyNDMgLTMuNTE0ODE5QzEuMzg2OCAtMy41MTQ4MTkgMC4zNDI3MTUgLTIuNDA2OTc0IDAuMzQyNzE1IC0xLjIyNzM5N0MwLjM0MjcxNSAtMC4zOTg1MDYgMC44NzY3MTIgMC4wNzk3MDEgMS40OTA0MTEgMC4wNzk3MDFDMS44ODg5MTcgMC4wNzk3MDEgMi4yMTU2OTEgLTAuMTUxNDMyIDIuNDU0Nzk1IC0wLjM1ODY1NUMyLjQ0NjgyNCAtMC4zMzQ3NDUgMi4xOTk3NTEgMC42Njk0ODkgMi4xNjc4NyAwLjgwNDk4MUMyLjA0ODMxOSAxLjI2NzI0OCAyLjA0ODMxOSAxLjI3NTIxOCAxLjU0NjIwMiAxLjI4MzE4OEMxLjQ1MDU2IDEuMjgzMTg4IDEuMzQ2OTQ5IDEuMjgzMTg4IDEuMzQ2OTQ5IDEuNDM0NjJDMS4zNDY5NDkgMS40ODI0NDEgMS4zODY4IDEuNTQ2MjAyIDEuNDY2NTAxIDEuNTQ2MjAyQzEuNTcwMTEyIDEuNTQ2MjAyIDEuNzUzNDI1IDEuNTMwMjYyIDEuODU3MDM2IDEuNTIyMjkxSDIuMjc5NDUyQzIuOTE3MDYxIDEuNTIyMjkxIDMuMDYwNTIzIDEuNTQ2MjAyIDMuMTI0Mjg0IDEuNTQ2MjAyQzMuMTU2MTY0IDEuNTQ2MjAyIDMuMjc1NzE2IDEuNTQ2MjAyIDMuMjc1NzE2IDEuMzk0NzdDMy4yNzU3MTYgMS4yODMxODggMy4xNjQxMzQgMS4yODMxODggMy4wNjg0OTMgMS4yODMxODhDMi42ODU5MjggMS4yODMxODggMi42ODU5MjggMS4yMzUzNjcgMi42ODU5MjggMS4xNjM2MzZDMi42ODU5MjggMS4xNTU2NjYgMi42ODU5MjggMS4xMTU4MTYgMi43MTc4MDggMC45OTYyNjRMMy43OTM3NzMgLTMuMjgzNjg2Wk0yLjYxNDE5NyAtMC45ODgyOTRDMi41ODIzMTYgLTAuODY4NzQyIDIuNTgyMzE2IC0wLjg0NDgzMiAyLjQ0NjgyNCAtMC42OTM0QzIuMDMyMzc5IC0wLjIwNzIyMyAxLjY4MTY5NCAtMC4xNDM0NjIgMS41MTQzMjEgLTAuMTQzNDYyQzEuMTQ3Njk2IC0wLjE0MzQ2MiAwLjk2NDM4NCAtMC40NzgyMDcgMC45NjQzODQgLTAuODkyNjUzQzAuOTY0Mzg0IC0xLjI2NzI0OCAxLjE3OTU3NyAtMi4xMjAwNSAxLjM1NDkxOSAtMi40NzA3MzVDMS41ODYwNTIgLTIuOTU2OTEyIDEuOTc2NTg4IC0zLjI5MTY1NiAyLjM0MzIxMyAtMy4yOTE2NTZDMi44NzcyMSAtMy4yOTE2NTYgMy4wMTI3MDIgLTIuNjY5OTg4IDMuMDEyNzAyIC0yLjYxNDE5N0MzLjAxMjcwMiAtMi41ODIzMTYgMi45OTY3NjIgLTIuNTI2NTI2IDIuOTg4NzkyIC0yLjQ4NjY3NUwyLjYxNDE5NyAtMC45ODgyOTRaJyBpZD0nZzMtMTEzJy8+CjxwYXRoIGQ9J001LjM3OTgyNiAtNC43MzQyNDdDNS40NzU0NjcgLTQuNzgyMDY3IDUuNTMxMjU4IC00LjgyMTkxOCA1LjUzMTI1OCAtNC45MDk1ODlTNS40NTk1MjcgLTUuMDY4OTkxIDUuMzcxODU2IC01LjA2ODk5MUM1LjMzMjAwNSAtNS4wNjg5OTEgNS4yNjAyNzQgLTUuMDM3MTExIDUuMjI4Mzk0IC01LjAyMTE3MUwwLjgyMDkyMiAtMi45NDA5NzFDMC42ODU0MyAtMi44NzcyMSAwLjY2MTUxOSAtMi44MjE0MiAwLjY2MTUxOSAtMi43NTc2NTlTMC42OTM0IC0yLjYzODEwNyAwLjgyMDkyMiAtMi41ODIzMTZMNS4yMjgzOTQgLTAuNTEwMDg3QzUuMzMyMDA1IC0wLjQ1NDI5NiA1LjM0Nzk0NSAtMC40NTQyOTYgNS4zNzE4NTYgLTAuNDU0Mjk2QzUuNDU5NTI3IC0wLjQ1NDI5NiA1LjUzMTI1OCAtMC41MjYwMjcgNS41MzEyNTggLTAuNjEzNjk5QzUuNTMxMjU4IC0wLjcxNzMxIDUuNDU5NTI3IC0wLjc0OTE5MSA1LjM3MTg1NiAtMC43ODkwNDFMMS4xOTU1MTcgLTIuNzU3NjU5TDUuMzc5ODI2IC00LjczNDI0N1pNNS4yMjgzOTQgMS4wMzYxMTVDNS4zMzIwMDUgMS4wOTE5MDUgNS4zNDc5NDUgMS4wOTE5MDUgNS4zNzE4NTYgMS4wOTE5MDVDNS40NTk1MjcgMS4wOTE5MDUgNS41MzEyNTggMS4wMjAxNzQgNS41MzEyNTggMC45MzI1MDNDNS41MzEyNTggMC44Mjg4OTIgNS40NTk1MjcgMC43OTcwMTEgNS4zNzE4NTYgMC43NTcxNjFMMC45NzIzNTQgLTEuMzE1MDY4QzAuODY4NzQyIC0xLjM3MDg1OSAwLjg1MjgwMiAtMS4zNzA4NTkgMC44MjA5MjIgLTEuMzcwODU5QzAuNzI1MjggLTEuMzcwODU5IDAuNjYxNTE5IC0xLjI5OTEyOCAwLjY2MTUxOSAtMS4yMTE0NTdDMC42NjE1MTkgLTEuMTQ3Njk2IDAuNjkzNCAtMS4wOTE5MDUgMC44MjA5MjIgLTEuMDM2MTE1TDUuMjI4Mzk0IDEuMDM2MTE1WicgaWQ9J2cwLTU0Jy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc1OS43NzY2OTInIHhsaW5rOmhyZWY9JyNnNC03NycgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nNzIuMzUwMjk5JyB4bGluazpocmVmPScjZzEtNDgnIHk9Jzg2LjcyMDEwMycvPgo8dXNlIHg9Jzc1LjE0NTM3NScgeGxpbms6aHJlZj0nI2c2LTQwJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PSc3OS42OTc3JyB4bGluazpocmVmPScjZzQtMTEzJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PSc4NS4zMTY4NTcnIHhsaW5rOmhyZWY9JyNnNC01OScgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nOTAuNTYxMDE2JyB4bGluazpocmVmPScjZzQtODMnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9Jzk4LjQ1NjMzOScgeGxpbms6aHJlZj0nI2c2LTQxJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScxMTIuOTcxMzAxJyB4bGluazpocmVmPScjZzYtNjEnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzE0OS4xMDQxODknIHhsaW5rOmhyZWY9JyNnNi0xMDknIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzE1OC44NTkxNzMnIHhsaW5rOmhyZWY9JyNnNi0xMDUnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzE2Mi4xMTA4MzQnIHhsaW5rOmhyZWY9JyNnNi0xMTAnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzEzMi4wMzg1OTInIHhsaW5rOmhyZWY9JyNnMy0xMDAnIHk9Jzk5LjYyNjQwMScvPgo8dXNlIHg9JzEzNi4zOTU5MScgeGxpbms6aHJlZj0nI2c1LTQwJyB5PSc5OS42MjY0MDEnLz4KPHVzZSB4PScxMzkuNjg5MTYzJyB4bGluazpocmVmPScjZzMtMTEzJyB5PSc5OS42MjY0MDEnLz4KPHVzZSB4PScxNDMuNzU1OTEzJyB4bGluazpocmVmPScjZzMtNTknIHk9Jzk5LjYyNjQwMScvPgo8dXNlIHg9JzE0Ni4xMDgyMzcnIHhsaW5rOmhyZWY9JyNnMy04MycgeT0nOTkuNjI2NDAxJy8+Cjx1c2UgeD0nMTUxLjcwMzk4MycgeGxpbms6aHJlZj0nI2c1LTQxJyB5PSc5OS42MjY0MDEnLz4KPHVzZSB4PScxNTQuOTk3MjM2JyB4bGluazpocmVmPScjZzAtNTQnIHk9Jzk5LjYyNjQwMScvPgo8dXNlIHg9JzE2MS4xOTYyMzQnIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9Jzk5LjYyNjQwMScvPgo8dXNlIHg9JzE2NS44MTc4NScgeGxpbms6aHJlZj0nI2czLTYwJyB5PSc5OS42MjY0MDEnLz4KPHVzZSB4PScxNzIuNDA0MzU2JyB4bGluazpocmVmPScjZzMtMTA4JyB5PSc5OS42MjY0MDEnLz4KPHVzZSB4PScxNzUuMDI2NDgyJyB4bGluazpocmVmPScjZzUtNDAnIHk9Jzk5LjYyNjQwMScvPgo8dXNlIHg9JzE3OC4zMTk3MzUnIHhsaW5rOmhyZWY9JyNnMy0xMTMnIHk9Jzk5LjYyNjQwMScvPgo8dXNlIHg9JzE4Mi4zODY0ODUnIHhsaW5rOmhyZWY9JyNnNS00MScgeT0nOTkuNjI2NDAxJy8+Cjx1c2UgeD0nMTg3LjY3MjIzNicgeGxpbms6aHJlZj0nI2cyLTEwMicgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMTkzLjY0OTgzNScgeGxpbms6aHJlZj0nI2c0LTc3JyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScyMDYuMjIzNDQyJyB4bGluazpocmVmPScjZzEtNDgnIHk9Jzg2LjcyMDEwMycvPgo8dXNlIHg9JzIwOS4wMTg1MTgnIHhsaW5rOmhyZWY9JyNnNi00MCcgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjEzLjU3MDg0NCcgeGxpbms6aHJlZj0nI2c0LTExMycgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjE5LjE5JyB4bGluazpocmVmPScjZzYtOTEnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzIyMi40NDE2NjInIHhsaW5rOmhyZWY9JyNnNi00OScgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjI4LjI5NDY1MicgeGxpbms6aHJlZj0nI2c0LTU4JyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScyMzEuNTQ2MzEzJyB4bGluazpocmVmPScjZzQtNTgnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzIzNC43OTc5NzQnIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzI0MS4yODc0NzgnIHhsaW5rOmhyZWY9JyNnNi05MycgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjQ0LjUzOTE0JyB4bGluazpocmVmPScjZzQtNTknIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzI0OS43ODMyOTknIHhsaW5rOmhyZWY9JyNnNC04MycgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjU3LjY3ODYyMicgeGxpbms6aHJlZj0nI2c2LTQxJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScyNjQuODg3NjExJyB4bGluazpocmVmPScjZzYtNDMnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzI3Ni42NDg5MjYnIHhsaW5rOmhyZWY9JyNnNi0xMDknIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzI4Ni40MDM5MScgeGxpbms6aHJlZj0nI2c2LTEwNScgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjg5LjY1NTU3MScgeGxpbms6aHJlZj0nI2c2LTExMCcgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjk2LjE1ODg5MycgeGxpbms6aHJlZj0nI2c2LTQwJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PSczMDAuNzExMjE5JyB4bGluazpocmVmPScjZzQtNzUnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzMxMS41Mjg4OTknIHhsaW5rOmhyZWY9JyNnNi00MCcgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMzE2LjA4MTIyNCcgeGxpbms6aHJlZj0nI2c0LTExMycgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMzIxLjcwMDM4MScgeGxpbms6aHJlZj0nI2c0LTU5JyB5PSc5MS42NTYyODknLz4KPHVzZSB4PSczMjYuOTQ0NTQnIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzMzMy40MzQwNDQnIHhsaW5rOmhyZWY9JyNnNC01OScgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMzM4LjY3ODIwMycgeGxpbms6aHJlZj0nI2c0LTgzJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PSczNDYuNTczNTI2JyB4bGluazpocmVmPScjZzYtNDEnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzM1MS4xMjU4NTInIHhsaW5rOmhyZWY9JyNnNC01OScgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMzU2LjM3MDAxJyB4bGluazpocmVmPScjZzQtMTA4JyB5PSc5MS42NTYyODknLz4KPHVzZSB4PSczNjAuMTE5ODE5JyB4bGluazpocmVmPScjZzYtNDAnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzM2NC42NzIxNDUnIHhsaW5rOmhyZWY9JyNnNC0xMTMnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzM3MC4yOTEzMDEnIHhsaW5rOmhyZWY9JyNnNi00MScgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMzc3LjUwMDI5JyB4bGluazpocmVmPScjZzItMCcgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMzg5LjQ1NTQ1MScgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMzk1Ljk0NDk1NScgeGxpbms6aHJlZj0nI2c2LTQxJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PSc0MDAuNDk3MjgxJyB4bGluazpocmVmPScjZzItMTAzJyB5PSc5MS42NTYyODknLz4KPC9nPgo8L3N2Zz4=)
Lemme L1 : M” et sous-ensemble
On suppose que la complétion est préfixe
pour la requête  et
et
 ce qui signifie
que la complétion est toujours affichée
avant la complétion si elles apparaissent ensemble.
Alors
ce qui signifie
que la complétion est toujours affichée
avant la complétion si elles apparaissent ensemble.
Alors  .
Plus spécifiquement, si on considère l’ensemble
.
Plus spécifiquement, si on considère l’ensemble
 (
( est la complétion
sans son préfixe ).
est la complétion
sans son préfixe ).

Lemme L1 : Rang k
On note  ,
,
 ,
,  avec
avec
 ,
,  ,
et
,
et  avec
avec  .
On suppose que les matrices
sont solution du problème d’optimisation
.
On suppose que les matrices
sont solution du problème d’optimisation
 .
On suppose que
.
On suppose que  .
Alors les les matrices
.
Alors les les matrices  et
et  sont de rang .
sont de rang .
Lemme L1 : inertie minimum
Soit  ,
,
 points de
points de  , le minimum de la quantité
, le minimum de la quantité
 :
:

est atteint pour  le barycentre des points
le barycentre des points  .
.
Lemme L2 : Projection
On note ,
, avec
, ,
et avec .
On suppose que les matrices
sont solution du problème d’optimisation
.
On considère que la matrice est un ensemble de
points dans dans un espace vectoriel de dimension .
La matrice  représente des projections de ces points
dans l’espace vectoriel engendré par les vecteurs colonnes
de la matrice
représente des projections de ces points
dans l’espace vectoriel engendré par les vecteurs colonnes
de la matrice  .
.
Lemme L2 : calcul de *M”(q, S)*
On suppose que  est la complétion la plus longue
de l’ensemble qui commence :
est la complétion la plus longue
de l’ensemble qui commence :
![\begin{eqnarray*}
k^* &=& \max\acc{ k | q[[1..k]] \prec q \text{ et } q \in S} \\
p(q, S) &=& q[[1..k^*]]
\end{eqnarray*}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMjguODkxNjU2cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMTI1LjYxNTE3MSA4Mi42ODk5MTMgMjEzLjAyODc2NCAyOC44OTE2NTYnIHdpZHRoPScyMTMuMDI4NzY0cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTQuNDQ3MzIzIC0yLjk3NjgzN0M2LjQzMTg4IC0zLjM0NzQ0NyA3LjQ0ODA3IC00LjA4ODY2NyA3Ljk3NDA5NyAtNS4wNTcwMzZDOC4yMTMyIC01LjUxMTMzMyA4LjI5Njg4NyAtNi4wNzMyMjUgOC4yOTY4ODcgLTYuMTgwODIyQzguMjk2ODg3IC02LjM2MDE0OSA4LjE2NTM4IC02LjQ0MzgzNiA4LjA1Nzc4MyAtNi40NDM4MzZDNy44NTQ1NDUgLTYuNDQzODM2IDcuODE4NjggLTYuMjUyNTUzIDcuNzk0NzcgLTYuMDk3MTM2QzcuNDQ4MDcgLTMuOTQ1MjA1IDUuMDMzMTI2IC0zLjIzOTg1MSAxLjMzODk3OSAtMy4yMTU5NEMxLjIxOTQyNyAtMy4yMTU5NCAwLjk5MjI3OSAtMy4yMTU5NCAwLjk5MjI3OSAtMi45NzY4MzdTMS4xNDc2OTYgLTIuNzM3NzMzIDEuNTkwMDM3IC0yLjczNzczM0MyLjgzMzM3NSAtMi43MjU3NzggNC4wNzY3MTIgLTIuNjQyMDkyIDUuMjcyMjI5IC0yLjI5NTM5MkM3LjUzMTc1NiAtMS42MjU5MDMgNy43MjMwMzkgLTAuMzM0NzQ1IDcuODA2NzI1IDAuMjE1MTkzQzcuODE4NjggMC4yODY5MjQgNy44NTQ1NDUgMC40NzgyMDcgOC4wNTc3ODMgMC40NzgyMDdDOC4xNjUzOCAwLjQ3ODIwNyA4LjI5Njg4NyAwLjQwNjQ3NiA4LjI5Njg4NyAwLjIxNTE5M0M4LjI5Njg4NyAwLjE0MzQ2MiA4LjIyNTE1NiAtMS4wNTIwNTUgNy4xMzcyMzUgLTEuOTAwODcyQzYuMzg0MDYgLTIuNDg2Njc1IDUuNDk5Mzc3IC0yLjc3MzU5OSA0LjQ0NzMyMyAtMi45NzY4MzdaJyBpZD0nZzEtMzAnLz4KPHBhdGggZD0nTTYuNTUxNDMyIC0yLjc0OTY4OUM2Ljc1NDY3IC0yLjc0OTY4OSA2Ljk2OTg2MyAtMi43NDk2ODkgNi45Njk4NjMgLTIuOTg4NzkyUzYuNzU0NjcgLTMuMjI3ODk1IDYuNTUxNDMyIC0zLjIyNzg5NUgxLjQ4MjQ0MUMxLjYyNTkwMyAtNC44Mjk4ODggMy4wMDA3NDcgLTUuOTc3NTg0IDQuNjg2NDI2IC01Ljk3NzU4NEg2LjU1MTQzMkM2Ljc1NDY3IC01Ljk3NzU4NCA2Ljk2OTg2MyAtNS45Nzc1ODQgNi45Njk4NjMgLTYuMjE2Njg3UzYuNzU0NjcgLTYuNDU1NzkxIDYuNTUxNDMyIC02LjQ1NTc5MUg0LjY2MjUxNkMyLjYxODE4MiAtNi40NTU3OTEgMC45OTIyNzkgLTQuOTAxNjE5IDAuOTkyMjc5IC0yLjk4ODc5MlMyLjYxODE4MiAwLjQ3ODIwNyA0LjY2MjUxNiAwLjQ3ODIwN0g2LjU1MTQzMkM2Ljc1NDY3IDAuNDc4MjA3IDYuOTY5ODYzIDAuNDc4MjA3IDYuOTY5ODYzIDAuMjM5MTAzUzYuNzU0NjcgMCA2LjU1MTQzMiAwSDQuNjg2NDI2QzMuMDAwNzQ3IDAgMS42MjU5MDMgLTEuMTQ3Njk2IDEuNDgyNDQxIC0yLjc0OTY4OUg2LjU1MTQzMlonIGlkPSdnMS01MCcvPgo8cGF0aCBkPSdNMy4zODMzMTMgLTcuMzc2MzM5QzMuMzgzMzEzIC03Ljg1NDU0NSAzLjY5NDE0NyAtOC42MTk2NzYgNC45OTcyNiAtOC43MDMzNjJDNS4wNTcwMzYgLTguNzE1MzE4IDUuMTA0ODU3IC04Ljc2MzEzOCA1LjEwNDg1NyAtOC44MzQ4NjlDNS4xMDQ4NTcgLTguOTY2Mzc2IDUuMDA5MjE1IC04Ljk2NjM3NiA0Ljg3NzcwOSAtOC45NjYzNzZDMy42ODIxOTIgLTguOTY2Mzc2IDIuNTk0MjcxIC04LjM1NjY2MyAyLjU4MjMxNiAtNy40NzE5OFYtNC43NDYyMDJDMi41ODIzMTYgLTQuMjc5OTUgMi41ODIzMTYgLTMuODk3Mzg1IDIuMTA0MTEgLTMuNTAyODY0QzEuNjg1Njc5IC0zLjE1NjE2NCAxLjIzMTM4MiAtMy4xMzIyNTQgMC45NjgzNjkgLTMuMTIwMjk5QzAuOTA4NTkzIC0zLjEwODM0NCAwLjg2MDc3MiAtMy4wNjA1MjMgMC44NjA3NzIgLTIuOTg4NzkyQzAuODYwNzcyIC0yLjg2OTI0IDAuOTMyNTAzIC0yLjg2OTI0IDEuMDUyMDU1IC0yLjg1NzI4NUMxLjg0MTA5NiAtMi44MDk0NjUgMi40MTQ5NDQgLTIuMzc5MDc4IDIuNTQ2NDUxIC0xLjc5MzI3NUMyLjU4MjMxNiAtMS42NjE3NjggMi41ODIzMTYgLTEuNjM3ODU4IDIuNTgyMzE2IC0xLjIwNzQ3MlYxLjE1OTY1MUMyLjU4MjMxNiAxLjY2MTc2OCAyLjU4MjMxNiAyLjA0NDMzNCAzLjE1NjE2NCAyLjQ5ODYzQzMuNjIyNDE2IDIuODU3Mjg1IDQuNDExNDU3IDIuOTg4NzkyIDQuODc3NzA5IDIuOTg4NzkyQzUuMDA5MjE1IDIuOTg4NzkyIDUuMTA0ODU3IDIuOTg4NzkyIDUuMTA0ODU3IDIuODU3Mjg1QzUuMTA0ODU3IDIuNzM3NzMzIDUuMDMzMTI2IDIuNzM3NzMzIDQuOTEzNTc0IDIuNzI1Nzc4QzQuMTYwMzk5IDIuNjc3OTU4IDMuNTc0NTk1IDIuMjk1MzkyIDMuNDE5MTc4IDEuNjg1Njc5QzMuMzgzMzEzIDEuNTc4MDgyIDMuMzgzMzEzIDEuNTU0MTcyIDMuMzgzMzEzIDEuMTIzNzg2Vi0xLjM4NjhDMy4zODMzMTMgLTEuOTM2NzM3IDMuMjg3NjcxIC0yLjEzOTk3NSAyLjkwNTEwNiAtMi41MjI1NEMyLjY1NDA0NyAtMi43NzM1OTkgMi4zMDczNDcgLTIuODkzMTUxIDEuOTcyNjAzIC0yLjk4ODc5MkMyLjk1MjkyNyAtMy4yNjM3NjEgMy4zODMzMTMgLTMuODEzNjk5IDMuMzgzMzEzIC00LjUwNzA5OFYtNy4zNzYzMzlaJyBpZD0nZzEtMTAyJy8+CjxwYXRoIGQ9J00yLjU4MjMxNiAxLjM5ODc1NUMyLjU4MjMxNiAxLjg3Njk2MSAyLjI3MTQ4MiAyLjY0MjA5MiAwLjk2ODM2OSAyLjcyNTc3OEMwLjkwODU5MyAyLjczNzczMyAwLjg2MDc3MiAyLjc4NTU1NCAwLjg2MDc3MiAyLjg1NzI4NUMwLjg2MDc3MiAyLjk4ODc5MiAwLjk5MjI3OSAyLjk4ODc5MiAxLjA5OTg3NSAyLjk4ODc5MkMyLjI1OTUyNyAyLjk4ODc5MiAzLjM3MTM1NyAyLjQwMjk4OSAzLjM4MzMxMyAxLjQ5NDM5NlYtMS4yMzEzODJDMy4zODMzMTMgLTEuNjk3NjM0IDMuMzgzMzEzIC0yLjA4MDE5OSAzLjg2MTUxOSAtMi40NzQ3MkM0LjI3OTk1IC0yLjgyMTQyIDQuNzM0MjQ3IC0yLjg0NTMzIDQuOTk3MjYgLTIuODU3Mjg1QzUuMDU3MDM2IC0yLjg2OTI0IDUuMTA0ODU3IC0yLjkxNzA2MSA1LjEwNDg1NyAtMi45ODg3OTJDNS4xMDQ4NTcgLTMuMTA4MzQ0IDUuMDMzMTI2IC0zLjEwODM0NCA0LjkxMzU3NCAtMy4xMjAyOTlDNC4xMjQ1MzMgLTMuMTY4MTIgMy41NTA2ODUgLTMuNTk4NTA2IDMuNDE5MTc4IC00LjE4NDMwOUMzLjM4MzMxMyAtNC4zMTU4MTYgMy4zODMzMTMgLTQuMzM5NzI2IDMuMzgzMzEzIC00Ljc3MDExMlYtNy4xMzcyMzVDMy4zODMzMTMgLTcuNjM5MzUyIDMuMzgzMzEzIC04LjAyMTkxOCAyLjgwOTQ2NSAtOC40NzYyMTRDMi4zMzEyNTggLTguODQ2ODI0IDEuNTA2MzUxIC04Ljk2NjM3NiAxLjA5OTg3NSAtOC45NjYzNzZDMC45OTIyNzkgLTguOTY2Mzc2IDAuODYwNzcyIC04Ljk2NjM3NiAwLjg2MDc3MiAtOC44MzQ4NjlDMC44NjA3NzIgLTguNzE1MzE4IDAuOTMyNTAzIC04LjcxNTMxOCAxLjA1MjA1NSAtOC43MDMzNjJDMS44MDUyMyAtOC42NTU1NDIgMi4zOTEwMzQgLTguMjcyOTc2IDIuNTQ2NDUxIC03LjY2MzI2M0MyLjU4MjMxNiAtNy41NTU2NjYgMi41ODIzMTYgLTcuNTMxNzU2IDIuNTgyMzE2IC03LjEwMTM3Vi00LjU5MDc4NUMyLjU4MjMxNiAtNC4wNDA4NDcgMi42Nzc5NTggLTMuODM3NjA5IDMuMDYwNTIzIC0zLjQ1NTA0NEMzLjMxMTU4MiAtMy4yMDM5ODUgMy42NTgyODEgLTMuMDg0NDMzIDMuOTkzMDI2IC0yLjk4ODc5MkMzLjAxMjcwMiAtMi43MTM4MjMgMi41ODIzMTYgLTIuMTYzODg1IDIuNTgyMzE2IC0xLjQ3MDQ4NlYxLjM5ODc1NVonIGlkPSdnMS0xMDMnLz4KPHBhdGggZD0nTTEuOTAwODcyIC04LjUzNTk5QzEuOTAwODcyIC04Ljc1MTE4MyAxLjkwMDg3MiAtOC45NjYzNzYgMS42NjE3NjggLTguOTY2Mzc2UzEuNDIyNjY1IC04Ljc1MTE4MyAxLjQyMjY2NSAtOC41MzU5OVYyLjU1ODQwNkMxLjQyMjY2NSAyLjc3MzU5OSAxLjQyMjY2NSAyLjk4ODc5MiAxLjY2MTc2OCAyLjk4ODc5MlMxLjkwMDg3MiAyLjc3MzU5OSAxLjkwMDg3MiAyLjU1ODQwNlYtOC41MzU5OVonIGlkPSdnMS0xMDYnLz4KPHBhdGggZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2IC0wLjUzNzk4MyAxLjgxNzE4NiAtMi45NzY4MzdDMS44MTcxODYgLTUuMjk2MTM5IDIuMzc5MDc4IC03LjI5MjY1MyAzLjc2NTg3OCAtOC43MDMzNjJDMy44ODU0MyAtOC44MTA5NTkgMy44ODU0MyAtOC44MzQ4NjkgMy44ODU0MyAtOC44NzA3MzVDMy44ODU0MyAtOC45NDI0NjYgMy44MjU2NTQgLTguOTY2Mzc2IDMuNzc3ODMzIC04Ljk2NjM3NkMzLjYyMjQxNiAtOC45NjYzNzYgMi42NDIwOTIgLTguMTA1NjA0IDIuMDU2Mjg5IC02LjkzMzk5OEMxLjQ0NjU3NSAtNS43MjY1MjYgMS4xNzE2MDYgLTQuNDQ3MzIzIDEuMTcxNjA2IC0yLjk3NjgzN0MxLjE3MTYwNiAtMS45MTI4MjcgMS4zMzg5NzkgLTAuNDkwMTYyIDEuOTYwNjQ4IDAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonIGlkPSdnMy00MCcvPgo8cGF0aCBkPSdNMy4zNzEzNTcgLTIuOTc2ODM3QzMuMzcxMzU3IC0zLjg4NTQzIDMuMjUxODA2IC01LjM2Nzg3IDIuNTgyMzE2IC02Ljc1NDY3QzEuODc2OTYxIC04LjE4OTI5IDAuODk2NjM4IC04Ljk2NjM3NiAwLjc2NTEzMSAtOC45NjYzNzZDMC43MTczMSAtOC45NjYzNzYgMC42NTc1MzQgLTguOTQyNDY2IDAuNjU3NTM0IC04Ljg3MDczNUMwLjY1NzUzNCAtOC44MzQ4NjkgMC42NTc1MzQgLTguODEwOTU5IDAuODYwNzcyIC04LjYwNzcyMUMyLjA1NjI4OSAtNy40MDAyNDkgMi43MjU3NzggLTUuNDI3NjQ2IDIuNzI1Nzc4IC0yLjk4ODc5MkMyLjcyNTc3OCAtMC42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgMC43NzcwODYgMi43Mzc3MzNDMC42NTc1MzQgMi44NDUzMyAwLjY1NzUzNCAyLjg2OTI0IDAuNjU3NTM0IDIuOTA1MTA2QzAuNjU3NTM0IDIuOTc2ODM3IDAuNzE3MzEgMy4wMDA3NDcgMC43NjUxMzEgMy4wMDA3NDdDMC45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgMC45NjgzNjlDMy4wOTYzODkgLTAuMjUxMDU5IDMuMzcxMzU3IC0xLjU0MjIxNyAzLjM3MTM1NyAtMi45NzY4MzdaJyBpZD0nZzMtNDEnLz4KPHBhdGggZD0nTTMuNDQzMDg4IC03LjY2MzI2M0MzLjQ0MzA4OCAtNy45MzgyMzIgMy40NDMwODggLTcuOTUwMTg3IDMuMjAzOTg1IC03Ljk1MDE4N0MyLjkxNzA2MSAtNy42MjczOTcgMi4zMTkzMDMgLTcuMTg1MDU2IDEuMDg3OTIgLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OSAtNi44MzgzNTYgMS45NjA2NDggLTYuODM4MzU2IDIuNjE4MTgyIC03LjE0OTE5MVYtMC45MjA1NDhDMi42MTgxODIgLTAuNDkwMTYyIDIuNTgyMzE2IC0wLjM0NjcgMS41MzAyNjIgLTAuMzQ2N0gxLjE1OTY1MVYwQzEuNDgyNDQxIC0wLjAyMzkxIDIuNjQyMDkyIC0wLjAyMzkxIDMuMDM2NjEzIC0wLjAyMzkxUzQuNTc4ODI5IC0wLjAyMzkxIDQuOTAxNjE5IDBWLTAuMzQ2N0g0LjUzMTAwOUMzLjQ3ODk1NCAtMC4zNDY3IDMuNDQzMDg4IC0wLjQ5MDE2MiAzLjQ0MzA4OCAtMC45MjA1NDhWLTcuNjYzMjYzWicgaWQ9J2czLTQ5Jy8+CjxwYXRoIGQ9J004LjA2OTczOCAtMy44NzM0NzRDOC4yMzcxMTEgLTMuODczNDc0IDguNDUyMzA0IC0zLjg3MzQ3NCA4LjQ1MjMwNCAtNC4wODg2NjdDOC40NTIzMDQgLTQuMzE1ODE2IDguMjQ5MDY2IC00LjMxNTgxNiA4LjA2OTczOCAtNC4zMTU4MTZIMS4wMjgxNDRDMC44NjA3NzIgLTQuMzE1ODE2IDAuNjQ1NTc5IC00LjMxNTgxNiAwLjY0NTU3OSAtNC4xMDA2MjNDMC42NDU1NzkgLTMuODczNDc0IDAuODQ4ODE3IC0zLjg3MzQ3NCAxLjAyODE0NCAtMy44NzM0NzRIOC4wNjk3MzhaTTguMDY5NzM4IC0xLjY0OTgxM0M4LjIzNzExMSAtMS42NDk4MTMgOC40NTIzMDQgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjg2NTAwNkM4LjQ1MjMwNCAtMi4wOTIxNTQgOC4yNDkwNjYgLTIuMDkyMTU0IDguMDY5NzM4IC0yLjA5MjE1NEgxLjAyODE0NEMwLjg2MDc3MiAtMi4wOTIxNTQgMC42NDU1NzkgLTIuMDkyMTU0IDAuNjQ1NTc5IC0xLjg3Njk2MUMwLjY0NTU3OSAtMS42NDk4MTMgMC44NDg4MTcgLTEuNjQ5ODEzIDEuMDI4MTQ0IC0xLjY0OTgxM0g4LjA2OTczOFonIGlkPSdnMy02MScvPgo8cGF0aCBkPSdNMi45ODg3OTIgMi45ODg3OTJWMi41NDY0NTFIMS44MjkxNDFWLTguNTI0MDM1SDIuOTg4NzkyVi04Ljk2NjM3NkgxLjM4NjhWMi45ODg3OTJIMi45ODg3OTJaJyBpZD0nZzMtOTEnLz4KPHBhdGggZD0nTTEuODUzMDUxIC04Ljk2NjM3NkgwLjI1MTA1OVYtOC41MjQwMzVIMS40MTA3MVYyLjU0NjQ1MUgwLjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJyBpZD0nZzMtOTMnLz4KPHBhdGggZD0nTTQuNjE0Njk1IC0zLjE5MjAzQzQuNjE0Njk1IC0zLjgzNzYwOSA0LjYxNDY5NSAtNC4zMTU4MTYgNC4wODg2NjcgLTQuNzgyMDY3QzMuNjcwMjM3IC01LjE2NDYzMyAzLjEzMjI1NCAtNS4zMzIwMDUgMi42MDYyMjcgLTUuMzMyMDA1QzEuNjI1OTAzIC01LjMzMjAwNSAwLjg3MjcyNyAtNC42ODY0MjYgMC44NzI3MjcgLTMuOTA5MzRDMC44NzI3MjcgLTMuNTYyNjQgMS4wOTk4NzUgLTMuMzk1MjY4IDEuMzc0ODQ0IC0zLjM5NTI2OEMxLjY2MTc2OCAtMy4zOTUyNjggMS44NjUwMDYgLTMuNTk4NTA2IDEuODY1MDA2IC0zLjg4NTQzQzEuODY1MDA2IC00LjM3NTU5MiAxLjQzNDYyIC00LjM3NTU5MiAxLjI1NTI5MyAtNC4zNzU1OTJDMS41MzAyNjIgLTQuODc3NzA5IDIuMTA0MTEgLTUuMDkyOTAyIDIuNTgyMzE2IC01LjA5MjkwMkMzLjEzMjI1NCAtNS4wOTI5MDIgMy44Mzc2MDkgLTQuNjM4NjA1IDMuODM3NjA5IC0zLjU2MjY0Vi0zLjA4NDQzM0MxLjQzNDYyIC0zLjA0ODU2OCAwLjUyNjAyNyAtMi4wNDQzMzQgMC41MjYwMjcgLTEuMTIzNzg2QzAuNTI2MDI3IC0wLjE3OTMyOCAxLjYyNTkwMyAwLjExOTU1MiAyLjM1NTE2OCAwLjExOTU1MkMzLjE0NDIwOSAwLjExOTU1MiAzLjY4MjE5MiAtMC4zNTg2NTUgMy45MDkzNCAtMC45MzI1MDNDMy45NTcxNjEgLTAuMzcwNjEgNC4zMjc3NzEgMC4wNTk3NzYgNC44NDE4NDMgMC4wNTk3NzZDNS4wOTI5MDIgMC4wNTk3NzYgNS43ODYzMDEgLTAuMTA3NTk3IDUuNzg2MzAxIC0xLjA2NDAxVi0xLjczMzQ5OUg1LjUyMzI4OFYtMS4wNjQwMUM1LjUyMzI4OCAtMC4zODI1NjUgNS4yMzYzNjQgLTAuMjg2OTI0IDUuMDY4OTkxIC0wLjI4NjkyNEM0LjYxNDY5NSAtMC4yODY5MjQgNC42MTQ2OTUgLTAuOTIwNTQ4IDQuNjE0Njk1IC0xLjA5OTg3NVYtMy4xOTIwM1pNMy44Mzc2MDkgLTEuNjg1Njc5QzMuODM3NjA5IC0wLjUxNDA3MiAyLjk2NDg4MiAtMC4xMTk1NTIgMi40NTA4MDkgLTAuMTE5NTUyQzEuODY1MDA2IC0wLjExOTU1MiAxLjM3NDg0NCAtMC41NDk5MzggMS4zNzQ4NDQgLTEuMTIzNzg2QzEuMzc0ODQ0IC0yLjcwMTg2OCAzLjQwNzIyMyAtMi44NDUzMyAzLjgzNzYwOSAtMi44NjkyNFYtMS42ODU2NzlaJyBpZD0nZzMtOTcnLz4KPHBhdGggZD0nTTQuNTc4ODI5IC0yLjc3MzU5OUM0Ljg0MTg0MyAtMi43NzM1OTkgNC44NjU3NTMgLTIuNzczNTk5IDQuODY1NzUzIC0zLjAwMDc0N0M0Ljg2NTc1MyAtNC4yMDgyMTkgNC4yMjAxNzQgLTUuMzMyMDA1IDIuNzczNTk5IC01LjMzMjAwNUMxLjQxMDcxIC01LjMzMjAwNSAwLjM1ODY1NSAtNC4xMDA2MjMgMC4zNTg2NTUgLTIuNjE4MTgyQzAuMzU4NjU1IC0xLjA0MDEgMS41NzgwODIgMC4xMTk1NTIgMi45MDUxMDYgMC4xMTk1NTJDNC4zMjc3NzEgMC4xMTk1NTIgNC44NjU3NTMgLTEuMTcxNjA2IDQuODY1NzUzIC0xLjQyMjY2NUM0Ljg2NTc1MyAtMS40OTQzOTYgNC44MDU5NzggLTEuNTQyMjE3IDQuNzM0MjQ3IC0xLjU0MjIxN0M0LjYzODYwNSAtMS41NDIyMTcgNC42MTQ2OTUgLTEuNDgyNDQxIDQuNTkwNzg1IC0xLjQyMjY2NUM0LjI3OTk1IC0wLjQxODQzMSAzLjQ3ODk1NCAtMC4xNDM0NjIgMi45NzY4MzcgLTAuMTQzNDYyUzEuMjY3MjQ4IC0wLjQ3ODIwNyAxLjI2NzI0OCAtMi41NDY0NTFWLTIuNzczNTk5SDQuNTc4ODI5Wk0xLjI3OTIwMyAtMy4wMDA3NDdDMS4zNzQ4NDQgLTQuODc3NzA5IDIuNDI2ODk5IC01LjA5MjkwMiAyLjc2MTY0NCAtNS4wOTI5MDJDNC4wNDA4NDcgLTUuMDkyOTAyIDQuMTEyNTc4IC0zLjQwNzIyMyA0LjEyNDUzMyAtMy4wMDA3NDdIMS4yNzkyMDNaJyBpZD0nZzMtMTAxJy8+CjxwYXRoIGQ9J004LjU3MTg1NiAtMi45MDUxMDZDOC41NzE4NTYgLTQuMDE2OTM2IDguNTcxODU2IC00LjM1MTY4MSA4LjI5Njg4NyAtNC43MzQyNDdDNy45NTAxODcgLTUuMjAwNDk4IDcuMzg4Mjk0IC01LjI3MjIyOSA2Ljk4MTgxOCAtNS4yNzIyMjlDNS45ODk1MzkgLTUuMjcyMjI5IDUuNDg3NDIyIC00LjU1NDkxOSA1LjI5NjEzOSAtNC4wODg2NjdDNS4xMjg3NjcgLTUuMDA5MjE1IDQuNDgzMTg4IC01LjI3MjIyOSAzLjczMDAxMiAtNS4yNzIyMjlDMi41NzAzNjEgLTUuMjcyMjI5IDIuMTE2MDY1IC00LjI3OTk1IDIuMDIwNDIzIC00LjA0MDg0N0gyLjAwODQ2OFYtNS4yNzIyMjlMMC4zODI1NjUgLTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE5NTUxNyAtNC43OTQwMjIgMS4yOTExNTggLTQuNzEwMzM2IDEuMjkxMTU4IC00LjEyNDUzM1YtMC44ODQ2ODJDMS4yOTExNTggLTAuMzQ2NyAxLjE1OTY1MSAtMC4zNDY3IDAuMzgyNTY1IC0wLjM0NjdWMEMwLjY5MzQgLTAuMDIzOTEgMS4zMzg5NzkgLTAuMDIzOTEgMS42NzM3MjQgLTAuMDIzOTFDMi4wMjA0MjMgLTAuMDIzOTEgMi42NjYwMDIgLTAuMDIzOTEgMi45NzY4MzcgMFYtMC4zNDY3QzIuMjExNzA2IC0wLjM0NjcgMi4wNjgyNDQgLTAuMzQ2NyAyLjA2ODI0NCAtMC44ODQ2ODJWLTMuMTA4MzQ0QzIuMDY4MjQ0IC00LjM2MzYzNiAyLjg5MzE1MSAtNS4wMzMxMjYgMy42MzQzNzEgLTUuMDMzMTI2UzQuNTQyOTY0IC00LjQyMzQxMiA0LjU0Mjk2NCAtMy42OTQxNDdWLTAuODg0NjgyQzQuNTQyOTY0IC0wLjM0NjcgNC40MTE0NTcgLTAuMzQ2NyAzLjYzNDM3MSAtMC4zNDY3VjBDMy45NDUyMDUgLTAuMDIzOTEgNC41OTA3ODUgLTAuMDIzOTEgNC45MjU1MjkgLTAuMDIzOTFDNS4yNzIyMjkgLTAuMDIzOTEgNS45MTc4MDggLTAuMDIzOTEgNi4yMjg2NDMgMFYtMC4zNDY3QzUuNDYzNTEyIC0wLjM0NjcgNS4zMjAwNSAtMC4zNDY3IDUuMzIwMDUgLTAuODg0NjgyVi0zLjEwODM0NEM1LjMyMDA1IC00LjM2MzYzNiA2LjE0NDk1NiAtNS4wMzMxMjYgNi44ODYxNzcgLTUuMDMzMTI2UzcuNzk0NzcgLTQuNDIzNDEyIDcuNzk0NzcgLTMuNjk0MTQ3Vi0wLjg4NDY4MkM3Ljc5NDc3IC0wLjM0NjcgNy42NjMyNjMgLTAuMzQ2NyA2Ljg4NjE3NyAtMC4zNDY3VjBDNy4xOTcwMTEgLTAuMDIzOTEgNy44NDI1OSAtMC4wMjM5MSA4LjE3NzMzNSAtMC4wMjM5MUM4LjUyNDAzNSAtMC4wMjM5MSA5LjE2OTYxNCAtMC4wMjM5MSA5LjQ4MDQ0OCAwVi0wLjM0NjdDOC44ODI2OSAtMC4zNDY3IDguNTgzODExIC0wLjM0NjcgOC41NzE4NTYgLTAuNzA1MzU1Vi0yLjkwNTEwNlonIGlkPSdnMy0xMDknLz4KPHBhdGggZD0nTTIuMDA4NDY4IC00LjgwNTk3OEgzLjY5NDE0N1YtNS4xNTI2NzdIMi4wMDg0NjhWLTcuMzUyNDI4SDEuNzQ1NDU1QzEuNzMzNDk5IC02LjIyODY0MyAxLjMwMzExMyAtNS4wODA5NDYgMC4yMTUxOTMgLTUuMDQ1MDgxVi00LjgwNTk3OEgxLjIzMTM4MlYtMS40ODI0NDFDMS4yMzEzODIgLTAuMTU1NDE3IDIuMTE2MDY1IDAuMTE5NTUyIDIuNzQ5Njg5IDAuMTE5NTUyQzMuNTAyODY0IDAuMTE5NTUyIDMuODk3Mzg1IC0wLjYyMTY2OSAzLjg5NzM4NSAtMS40ODI0NDFWLTIuMTYzODg1SDMuNjM0MzcxVi0xLjUwNjM1MUMzLjYzNDM3MSAtMC42NDU1NzkgMy4yODc2NzEgLTAuMTQzNDYyIDIuODIxNDIgLTAuMTQzNDYyQzIuMDA4NDY4IC0wLjE0MzQ2MiAyLjAwODQ2OCAtMS4yNTUyOTMgMi4wMDg0NjggLTEuNDU4NTMxVi00LjgwNTk3OFonIGlkPSdnMy0xMTYnLz4KPHBhdGggZD0nTTMuMzQ3NDQ3IC0yLjgyMTQyQzMuNjk0MTQ3IC0zLjI3NTcxNiA0LjE5NjI2NCAtMy45MjEyOTUgNC40MjM0MTIgLTQuMTcyMzU0QzQuOTEzNTc0IC00LjcyMjI5MSA1LjQ3NTQ2NyAtNC44MDU5NzggNS44NTgwMzIgLTQuODA1OTc4Vi01LjE1MjY3N0M1LjM0Mzk2IC01LjEyODc2NyA1LjMyMDA1IC01LjEyODc2NyA0Ljg1Mzc5OCAtNS4xMjg3NjdDNC4zOTk1MDIgLTUuMTI4NzY3IDQuMzc1NTkyIC01LjEyODc2NyAzLjc3NzgzMyAtNS4xNTI2NzdWLTQuODA1OTc4QzMuOTMzMjUgLTQuNzgyMDY3IDQuMTI0NTMzIC00LjcxMDMzNiA0LjEyNDUzMyAtNC40MzUzNjdDNC4xMjQ1MzMgLTQuMjMyMTMgNC4wMTY5MzYgLTQuMTAwNjIzIDMuOTQ1MjA1IC00LjAwNDk4MUwzLjE4MDA3NSAtMy4wMzY2MTNMMi4yNDc1NzIgLTQuMjY3OTk1QzIuMjExNzA2IC00LjMxNTgxNiAyLjEzOTk3NSAtNC40MjM0MTIgMi4xMzk5NzUgLTQuNTA3MDk4QzIuMTM5OTc1IC00LjU3ODgyOSAyLjE5OTc1MSAtNC43OTQwMjIgMi41NTg0MDYgLTQuODA1OTc4Vi01LjE1MjY3N0MyLjI1OTUyNyAtNS4xMjg3NjcgMS42NDk4MTMgLTUuMTI4NzY3IDEuMzI3MDI0IC01LjEyODc2N0MwLjkzMjUwMyAtNS4xMjg3NjcgMC45MDg1OTMgLTUuMTI4NzY3IDAuMTc5MzI4IC01LjE1MjY3N1YtNC44MDU5NzhDMC43ODkwNDEgLTQuODA1OTc4IDEuMDE2MTg5IC00Ljc4MjA2NyAxLjI2NzI0OCAtNC40NTkyNzhMMi42NjYwMDIgLTIuNjMwMTM3QzIuNjg5OTEzIC0yLjYwNjIyNyAyLjczNzczMyAtMi41MzQ0OTYgMi43Mzc3MzMgLTIuNDk4NjNTMS44MDUyMyAtMS4yOTExNTggMS42ODU2NzkgLTEuMTM1NzQxQzEuMTU5NjUxIC0wLjQ5MDE2MiAwLjYzMzYyNCAtMC4zNTg2NTUgMC4xMTk1NTIgLTAuMzQ2N1YwQzAuNTczODQ4IC0wLjAyMzkxIDAuNTk3NzU4IC0wLjAyMzkxIDEuMTExODMxIC0wLjAyMzkxQzEuNTY2MTI3IC0wLjAyMzkxIDEuNTkwMDM3IC0wLjAyMzkxIDIuMTg3Nzk2IDBWLTAuMzQ2N0MxLjkwMDg3MiAtMC4zODI1NjUgMS44NTMwNTEgLTAuNTYxODkzIDEuODUzMDUxIC0wLjcyOTI2NUMxLjg1MzA1MSAtMC45MjA1NDggMS45MzY3MzcgLTEuMDE2MTg5IDIuMDU2Mjg5IC0xLjE3MTYwNkMyLjIzNTYxNiAtMS40MjI2NjUgMi42MzAxMzcgLTEuOTEyODI3IDIuOTE3MDYxIC0yLjI4MzQzN0wzLjg5NzM4NSAtMS4wMDQyMzRDNC4xMDA2MjMgLTAuNzQxMjIgNC4xMDA2MjMgLTAuNzE3MzEgNC4xMDA2MjMgLTAuNjQ1NTc5QzQuMTAwNjIzIC0wLjU0OTkzOCA0LjAwNDk4MSAtMC4zNTg2NTUgMy42ODIxOTIgLTAuMzQ2N1YwQzMuOTkzMDI2IC0wLjAyMzkxIDQuNTc4ODI5IC0wLjAyMzkxIDQuOTEzNTc0IC0wLjAyMzkxQzUuMzA4MDk1IC0wLjAyMzkxIDUuMzMyMDA1IC0wLjAyMzkxIDYuMDQ5MzE1IDBWLTAuMzQ2N0M1LjQxNTY5MSAtMC4zNDY3IDUuMjAwNDk4IC0wLjM3MDYxIDQuOTEzNTc0IC0wLjc1MzE3NkwzLjM0NzQ0NyAtMi44MjE0MlonIGlkPSdnMy0xMjAnLz4KPHBhdGggZD0nTTIuMTk5NzUxIC0wLjU3Mzg0OEMyLjE5OTc1MSAtMC45MjA1NDggMS45MTI4MjcgLTEuMTU5NjUxIDEuNjI1OTAzIC0xLjE1OTY1MUMxLjI3OTIwMyAtMS4xNTk2NTEgMS4wNDAxIC0wLjg3MjcyNyAxLjA0MDEgLTAuNTg1ODAzQzEuMDQwMSAtMC4yMzkxMDMgMS4zMjcwMjQgMCAxLjYxMzk0OCAwQzEuOTYwNjQ4IDAgMi4xOTk3NTEgLTAuMjg2OTI0IDIuMTk5NzUxIC0wLjU3Mzg0OFonIGlkPSdnMi01OCcvPgo8cGF0aCBkPSdNMi4zMzEyNTggMC4wNDc4MjFDMi4zMzEyNTggLTAuNjQ1NTc5IDIuMTA0MTEgLTEuMTU5NjUxIDEuNjEzOTQ4IC0xLjE1OTY1MUMxLjIzMTM4MiAtMS4xNTk2NTEgMS4wNDAxIC0wLjg0ODgxNyAxLjA0MDEgLTAuNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjcgLTAuMDQ3ODIxIDIuMDIwNDIzIC0wLjE1NTQxN0MyLjA0NDMzNCAtMC4xNzkzMjggMi4wNTYyODkgLTAuMTc5MzI4IDIuMDY4MjQ0IC0wLjE3OTMyOEMyLjA5MjE1NCAtMC4xNzkzMjggMi4wOTIxNTQgLTAuMDExOTU1IDIuMDkyMTU0IDAuMDQ3ODIxQzIuMDkyMTU0IDAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggMC4wNDc4MjFaJyBpZD0nZzItNTknLz4KPHBhdGggZD0nTTcuNTkxNTMyIC04LjMwODg0MkM3LjU5MTUzMiAtOC40MTY0MzggNy41MDc4NDYgLTguNDE2NDM4IDcuNDgzOTM1IC04LjQxNjQzOEM3LjQzNjExNSAtOC40MTY0MzggNy40MjQxNTkgLTguNDA0NDgzIDcuMjgwNjk3IC04LjIyNTE1NkM3LjIwODk2NiAtOC4xNDE0NjkgNi43MTg4MDQgLTcuNTE5ODAxIDYuNzA2ODQ5IC03LjUwNzg0NkM2LjMxMjMyOSAtOC4yODQ5MzIgNS41MjMyODggLTguNDE2NDM4IDUuMDIxMTcxIC04LjQxNjQzOEMzLjUwMjg2NCAtOC40MTY0MzggMi4xMjgwMiAtNy4wMjk2MzkgMi4xMjgwMiAtNS42Nzg3MDVDMi4xMjgwMiAtNC43ODIwNjcgMi42NjYwMDIgLTQuMjU2MDQgMy4yNTE4MDYgLTQuMDUyODAyQzMuMzgzMzEzIC00LjAwNDk4MSA0LjA4ODY2NyAtMy44MTM2OTkgNC40NDczMjMgLTMuNzMwMDEyQzUuMDU3MDM2IC0zLjU2MjY0IDUuMjEyNDUzIC0zLjUxNDgxOSA1LjQ2MzUxMiAtMy4yNTE4MDZDNS41MTEzMzMgLTMuMTkyMDMgNS43NTA0MzYgLTIuOTE3MDYxIDUuNzUwNDM2IC0yLjM1NTE2OEM1Ljc1MDQzNiAtMS4yNDMzMzcgNC43MjIyOTEgLTAuMDk1NjQxIDMuNTI2Nzc1IC0wLjA5NTY0MUMyLjU0NjQ1MSAtMC4wOTU2NDEgMS40NTg1MzEgLTAuNTE0MDcyIDEuNDU4NTMxIC0xLjg1MzA1MUMxLjQ1ODUzMSAtMi4wODAxOTkgMS41MDYzNTEgLTIuMzY3MTIzIDEuNTQyMjE3IC0yLjQ4NjY3NUMxLjU0MjIxNyAtMi41MjI1NCAxLjU1NDE3MiAtMi41ODIzMTYgMS41NTQxNzIgLTIuNjA2MjI3QzEuNTU0MTcyIC0yLjY1NDA0NyAxLjUzMDI2MiAtMi43MTM4MjMgMS40MzQ2MiAtMi43MTM4MjNDMS4zMjcwMjQgLTIuNzEzODIzIDEuMzE1MDY4IC0yLjY4OTkxMyAxLjI2NzI0OCAtMi40ODY2NzVMMC42NTc1MzQgLTAuMDM1ODY2QzAuNjU3NTM0IC0wLjAyMzkxIDAuNjA5NzE0IDAuMTMxNTA3IDAuNjA5NzE0IDAuMTQzNDYyQzAuNjA5NzE0IDAuMjUxMDU5IDAuNzA1MzU1IDAuMjUxMDU5IDAuNzI5MjY1IDAuMjUxMDU5QzAuNzc3MDg2IDAuMjUxMDU5IDAuNzg5MDQxIDAuMjM5MTAzIDAuOTMyNTAzIDAuMDU5Nzc2TDEuNDgyNDQxIC0wLjY1NzUzNEMxLjc2OTM2NSAtMC4yMjcxNDggMi4zOTEwMzQgMC4yNTEwNTkgMy41MDI4NjQgMC4yNTEwNTlDNS4wNDUwODEgMC4yNTEwNTkgNi40NTU3OTEgLTEuMjQzMzM3IDYuNDU1NzkxIC0yLjczNzczM0M2LjQ1NTc5MSAtMy4yMzk4NTEgNi4zMzYyMzkgLTMuNjgyMTkyIDUuODgxOTQzIC00LjEyNDUzM0M1LjYzMDg4NCAtNC4zNzU1OTIgNS40MTU2OTEgLTQuNDM1MzY3IDQuMzE1ODE2IC00LjcyMjI5MUMzLjUxNDgxOSAtNC45Mzc0ODQgMy40MDcyMjMgLTQuOTczMzUgMy4xOTIwMyAtNS4xNjQ2MzNDMi45ODg3OTIgLTUuMzY3ODcgMi44MzMzNzUgLTUuNjU0Nzk1IDIuODMzMzc1IC02LjA2MTI3QzIuODMzMzc1IC03LjA2NTUwNCAzLjg0OTU2NCAtOC4wOTM2NDkgNC45ODUzMDUgLTguMDkzNjQ5QzYuMTU2OTEyIC04LjA5MzY0OSA2LjcwNjg0OSAtNy4zNzYzMzkgNi43MDY4NDkgLTYuMjQwNTk4QzYuNzA2ODQ5IC01LjkyOTc2MyA2LjY0NzA3MyAtNS42MDY5NzQgNi42NDcwNzMgLTUuNTU5MTUzQzYuNjQ3MDczIC01LjQ1MTU1NyA2Ljc0MjcxNSAtNS40NTE1NTcgNi43Nzg1OCAtNS40NTE1NTdDNi44ODYxNzcgLTUuNDUxNTU3IDYuODk4MTMyIC01LjQ4NzQyMiA2Ljk0NTk1MyAtNS42Nzg3MDVMNy41OTE1MzIgLTguMzA4ODQyWicgaWQ9J2cyLTgzJy8+CjxwYXRoIGQ9J00zLjM1OTQwMiAtNy45OTgwMDdDMy4zNzEzNTcgLTguMDQ1ODI4IDMuMzk1MjY4IC04LjExNzU1OSAzLjM5NTI2OCAtOC4xNzczMzVDMy4zOTUyNjggLTguMjk2ODg3IDMuMjc1NzE2IC04LjI5Njg4NyAzLjI1MTgwNiAtOC4yOTY4ODdDMy4yMzk4NTEgLTguMjk2ODg3IDIuODA5NDY1IC04LjI2MTAyMSAyLjU5NDI3MSAtOC4yMzcxMTFDMi4zOTEwMzQgLTguMjI1MTU2IDIuMjExNzA2IC04LjIwMTI0NSAxLjk5NjUxMyAtOC4xODkyOUMxLjcwOTU4OSAtOC4xNjUzOCAxLjYyNTkwMyAtOC4xNTM0MjUgMS42MjU5MDMgLTcuOTM4MjMyQzEuNjI1OTAzIC03LjgxODY4IDEuNzQ1NDU1IC03LjgxODY4IDEuODY1MDA2IC03LjgxODY4QzIuNDc0NzIgLTcuODE4NjggMi40NzQ3MiAtNy43MTEwODMgMi40NzQ3MiAtNy41OTE1MzJDMi40NzQ3MiAtNy41NDM3MTEgMi40NzQ3MiAtNy41MTk4MDEgMi40MTQ5NDQgLTcuMzA0NjA4TDAuNzA1MzU1IC0wLjQ2NjI1MkMwLjY1NzUzNCAtMC4yODY5MjQgMC42NTc1MzQgLTAuMjYzMDE0IDAuNjU3NTM0IC0wLjE5MTI4M0MwLjY1NzUzNCAwLjA3MTczMSAwLjg2MDc3MiAwLjExOTU1MiAwLjk4MDMyNCAwLjExOTU1MkMxLjMxNTA2OCAwLjExOTU1MiAxLjM4NjggLTAuMTQzNDYyIDEuNDgyNDQxIC0wLjUxNDA3MkwyLjA0NDMzNCAtMi43NDk2ODlDMi45MDUxMDYgLTIuNjU0MDQ3IDMuNDE5MTc4IC0yLjI5NTM5MiAzLjQxOTE3OCAtMS43MjE1NDRDMy40MTkxNzggLTEuNjQ5ODEzIDMuNDE5MTc4IC0xLjYwMTk5MyAzLjM4MzMxMyAtMS40MjI2NjVDMy4zMzU0OTIgLTEuMjQzMzM3IDMuMzM1NDkyIC0xLjA5OTg3NSAzLjMzNTQ5MiAtMS4wNDAxQzMuMzM1NDkyIC0wLjM0NjcgMy43ODk3ODggMC4xMTk1NTIgNC4zOTk1MDIgMC4xMTk1NTJDNC45NDk0NCAwLjExOTU1MiA1LjIzNjM2NCAtMC4zODI1NjUgNS4zMzIwMDUgLTAuNTQ5OTM4QzUuNTgzMDY0IC0wLjk5MjI3OSA1LjczODQ4MSAtMS42NjE3NjggNS43Mzg0ODEgLTEuNzA5NTg5QzUuNzM4NDgxIC0xLjc2OTM2NSA1LjY5MDY2IC0xLjgxNzE4NiA1LjYxODkyOSAtMS44MTcxODZDNS41MTEzMzMgLTEuODE3MTg2IDUuNDk5Mzc3IC0xLjc2OTM2NSA1LjQ1MTU1NyAtMS41NzgwODJDNS4yODQxODQgLTAuOTU2NDEzIDUuMDMzMTI2IC0wLjExOTU1MiA0LjQyMzQxMiAtMC4xMTk1NTJDNC4xODQzMDkgLTAuMTE5NTUyIDQuMDI4ODkyIC0wLjIzOTEwMyA0LjAyODg5MiAtMC42OTM0QzQuMDI4ODkyIC0wLjkyMDU0OCA0LjA3NjcxMiAtMS4xODM1NjIgNC4xMjQ1MzMgLTEuMzYyODg5QzQuMTcyMzU0IC0xLjU3ODA4MiA0LjE3MjM1NCAtMS41OTAwMzcgNC4xNzIzNTQgLTEuNzMzNDk5QzQuMTcyMzU0IC0yLjQzODg1NCAzLjUzODczIC0yLjgzMzM3NSAyLjQzODg1NCAtMi45NzY4MzdDMi44NjkyNCAtMy4yMzk4NTEgMy4yOTk2MjYgLTMuNzA2MTAyIDMuNDY2OTk5IC0zLjg4NTQzQzQuMTQ4NDQzIC00LjY1MDU2IDQuNjE0Njk1IC01LjAzMzEyNiA1LjE2NDYzMyAtNS4wMzMxMjZDNS40Mzk2MDEgLTUuMDMzMTI2IDUuNTExMzMzIC00Ljk2MTM5NSA1LjU5NTAxOSAtNC44ODk2NjRDNS4xNTI2NzcgLTQuODQxODQzIDQuOTg1MzA1IC00LjUzMTAwOSA0Ljk4NTMwNSAtNC4yOTE5MDVDNC45ODUzMDUgLTQuMDA0OTgxIDUuMjEyNDUzIC0zLjkwOTM0IDUuMzc5ODI2IC0zLjkwOTM0QzUuNzAyNjE1IC0zLjkwOTM0IDUuOTg5NTM5IC00LjE4NDMwOSA1Ljk4OTUzOSAtNC41NjY4NzRDNS45ODk1MzkgLTQuOTEzNTc0IDUuNzE0NTcgLTUuMjcyMjI5IDUuMTc2NTg4IC01LjI3MjIyOUM0LjUxOTA1NCAtNS4yNzIyMjkgMy45ODEwNzEgLTQuODA1OTc4IDMuMTMyMjU0IC0zLjg0OTU2NEMzLjAxMjcwMiAtMy43MDYxMDIgMi41NzAzNjEgLTMuMjUxODA2IDIuMTI4MDIgLTMuMDg0NDMzTDMuMzU5NDAyIC03Ljk5ODAwN1onIGlkPSdnMi0xMDcnLz4KPHBhdGggZD0nTTAuNTE0MDcyIDEuNTE4MzA2QzAuNDMwMzg2IDEuODc2OTYxIDAuMzgyNTY1IDEuOTcyNjAzIC0wLjEwNzU5NyAxLjk3MjYwM0MtMC4yNTEwNTkgMS45NzI2MDMgLTAuMzcwNjEgMS45NzI2MDMgLTAuMzcwNjEgMi4xOTk3NTFDLTAuMzcwNjEgMi4yMjM2NjEgLTAuMzU4NjU1IDIuMzE5MzAzIC0wLjIyNzE0OCAyLjMxOTMwM0MtMC4wNzE3MzEgMi4zMTkzMDMgMC4wOTU2NDEgMi4yOTUzOTIgMC4yNTEwNTkgMi4yOTUzOTJIMC43NjUxMzFDMS4wMTYxODkgMi4yOTUzOTIgMS42MjU5MDMgMi4zMTkzMDMgMS44NzY5NjEgMi4zMTkzMDNDMS45NDg2OTIgMi4zMTkzMDMgMi4wOTIxNTQgMi4zMTkzMDMgMi4wOTIxNTQgMi4xMDQxMUMyLjA5MjE1NCAxLjk3MjYwMyAyLjAwODQ2OCAxLjk3MjYwMyAxLjgwNTIzIDEuOTcyNjAzQzEuMjU1MjkzIDEuOTcyNjAzIDEuMjE5NDI3IDEuODg4OTE3IDEuMjE5NDI3IDEuNzkzMjc1QzEuMjE5NDI3IDEuNjQ5ODEzIDEuNzU3NDEgLTAuNDA2NDc2IDEuODI5MTQxIC0wLjY4MTQ0NUMxLjk2MDY0OCAtMC4zNDY3IDIuMjgzNDM3IDAuMTE5NTUyIDIuOTA1MTA2IDAuMTE5NTUyQzQuMjU2MDQgMC4xMTk1NTIgNS43MTQ1NyAtMS42Mzc4NTggNS43MTQ1NyAtMy4zOTUyNjhDNS43MTQ1NyAtNC40OTUxNDMgNS4wOTI5MDIgLTUuMjcyMjI5IDQuMTk2MjY0IC01LjI3MjIyOUMzLjQzMTEzMyAtNS4yNzIyMjkgMi43ODU1NTQgLTQuNTMxMDA5IDIuNjU0MDQ3IC00LjM2MzYzNkMyLjU1ODQwNiAtNC45NjEzOTUgMi4wOTIxNTQgLTUuMjcyMjI5IDEuNjEzOTQ4IC01LjI3MjIyOUMxLjI2NzI0OCAtNS4yNzIyMjkgMC45OTIyNzkgLTUuMTA0ODU3IDAuNzY1MTMxIC00LjY1MDU2QzAuNTQ5OTM4IC00LjIyMDE3NCAwLjM4MjU2NSAtMy40OTA5MDkgMC4zODI1NjUgLTMuNDQzMDg4UzAuNDMwMzg2IC0zLjMzNTQ5MiAwLjUxNDA3MiAtMy4zMzU0OTJDMC42MDk3MTQgLTMuMzM1NDkyIDAuNjIxNjY5IC0zLjM0NzQ0NyAwLjY5MzQgLTMuNjIyNDE2QzAuODcyNzI3IC00LjMyNzc3MSAxLjA5OTg3NSAtNS4wMzMxMjYgMS41NzgwODIgLTUuMDMzMTI2QzEuODUzMDUxIC01LjAzMzEyNiAxLjk0ODY5MiAtNC44NDE4NDMgMS45NDg2OTIgLTQuNDgzMTg4QzEuOTQ4NjkyIC00LjE5NjI2NCAxLjkxMjgyNyAtNC4wNzY3MTIgMS44NjUwMDYgLTMuODYxNTE5TDAuNTE0MDcyIDEuNTE4MzA2Wk0yLjU4MjMxNiAtMy43MzAwMTJDMi42NjYwMDIgLTQuMDY0NzU3IDMuMDAwNzQ3IC00LjQxMTQ1NyAzLjE5MjAzIC00LjU3ODgyOUMzLjMyMzUzNyAtNC42OTgzODEgMy43MTgwNTcgLTUuMDMzMTI2IDQuMTcyMzU0IC01LjAzMzEyNkM0LjY5ODM4MSAtNS4wMzMxMjYgNC45Mzc0ODQgLTQuNTA3MDk4IDQuOTM3NDg0IC0zLjg4NTQzQzQuOTM3NDg0IC0zLjMxMTU4MiA0LjYwMjc0IC0xLjk2MDY0OCA0LjMwMzg2MSAtMS4zMzg5NzlDNC4wMDQ5ODEgLTAuNjkzNCAzLjQ1NTA0NCAtMC4xMTk1NTIgMi45MDUxMDYgLTAuMTE5NTUyQzIuMDkyMTU0IC0wLjExOTU1MiAxLjk2MDY0OCAtMS4xNDc2OTYgMS45NjA2NDggLTEuMTk1NTE3QzEuOTYwNjQ4IC0xLjIzMTM4MiAxLjk4NDU1OCAtMS4zMjcwMjQgMS45OTY1MTMgLTEuMzg2OEwyLjU4MjMxNiAtMy43MzAwMTJaJyBpZD0nZzItMTEyJy8+CjxwYXRoIGQ9J001LjI3MjIyOSAtNS4xNTI2NzdDNS4yNzIyMjkgLTUuMjEyNDUzIDUuMjI0NDA4IC01LjI2MDI3NCA1LjE2NDYzMyAtNS4yNjAyNzRDNS4wNjg5OTEgLTUuMjYwMjc0IDQuNjAyNzQgLTQuODI5ODg4IDQuMzc1NTkyIC00LjQxMTQ1N0M0LjE2MDM5OSAtNC45NDk0NCAzLjc4OTc4OCAtNS4yNzIyMjkgMy4yNzU3MTYgLTUuMjcyMjI5QzEuOTI0NzgyIC01LjI3MjIyOSAwLjQ2NjI1MiAtMy41MjY3NzUgMC40NjYyNTIgLTEuNzU3NDFDMC40NjYyNTIgLTAuNTczODQ4IDEuMTU5NjUxIDAuMTE5NTUyIDEuOTcyNjAzIDAuMTE5NTUyQzIuNjA2MjI3IDAuMTE5NTUyIDMuMTMyMjU0IC0wLjM1ODY1NSAzLjM4MzMxMyAtMC42MzM2MjRMMy4zOTUyNjggLTAuNjIxNjY5TDIuOTQwOTcxIDEuMTcxNjA2TDIuODMzMzc1IDEuNjAxOTkzQzIuNzI1Nzc4IDEuOTYwNjQ4IDIuNTQ2NDUxIDEuOTYwNjQ4IDEuOTg0NTU4IDEuOTcyNjAzQzEuODUzMDUxIDEuOTcyNjAzIDEuNzMzNDk5IDEuOTcyNjAzIDEuNzMzNDk5IDIuMTk5NzUxQzEuNzMzNDk5IDIuMjgzNDM3IDEuODA1MjMgMi4zMTkzMDMgMS44ODg5MTcgMi4zMTkzMDNDMi4wNTYyODkgMi4zMTkzMDMgMi4yNzE0ODIgMi4yOTUzOTIgMi40Mzg4NTQgMi4yOTUzOTJIMy42NTgyODFDMy44Mzc2MDkgMi4yOTUzOTIgNC4wNDA4NDcgMi4zMTkzMDMgNC4yMjAxNzQgMi4zMTkzMDNDNC4yOTE5MDUgMi4zMTkzMDMgNC40MzUzNjcgMi4zMTkzMDMgNC40MzUzNjcgMi4wOTIxNTRDNC40MzUzNjcgMS45NzI2MDMgNC4zMzk3MjYgMS45NzI2MDMgNC4xNjAzOTkgMS45NzI2MDNDMy41OTg1MDYgMS45NzI2MDMgMy41NjI2NCAxLjg4ODkxNyAzLjU2MjY0IDEuNzkzMjc1QzMuNTYyNjQgMS43MzM0OTkgMy41NzQ1OTUgMS43MjE1NDQgMy42MTA0NjEgMS41NjYxMjdMNS4yNzIyMjkgLTUuMTUyNjc3Wk0zLjU4NjU1IC0xLjQyMjY2NUMzLjUyNjc3NSAtMS4yMTk0MjcgMy41MjY3NzUgLTEuMTk1NTE3IDMuMzU5NDAyIC0wLjk2ODM2OUMzLjA5NjM4OSAtMC42MzM2MjQgMi41NzAzNjEgLTAuMTE5NTUyIDIuMDA4NDY4IC0wLjExOTU1MkMxLjUxODMwNiAtMC4xMTk1NTIgMS4yNDMzMzcgLTAuNTYxODkzIDEuMjQzMzM3IC0xLjI2NzI0OEMxLjI0MzMzNyAtMS45MjQ3ODIgMS42MTM5NDggLTMuMjYzNzYxIDEuODQxMDk2IC0zLjc2NTg3OEMyLjI0NzU3MiAtNC42MDI3NCAyLjgwOTQ2NSAtNS4wMzMxMjYgMy4yNzU3MTYgLTUuMDMzMTI2QzQuMDY0NzU3IC01LjAzMzEyNiA0LjIyMDE3NCAtNC4wNTI4MDIgNC4yMjAxNzQgLTMuOTU3MTYxQzQuMjIwMTc0IC0zLjk0NTIwNSA0LjE4NDMwOSAtMy43ODk3ODggNC4xNzIzNTQgLTMuNzY1ODc4TDMuNTg2NTUgLTEuNDIyNjY1WicgaWQ9J2cyLTExMycvPgo8cGF0aCBkPSdNMy4yOTE2NTYgLTEuMDUyMDU1QzMuMzYzMzg3IC0xLjAwNDIzNCAzLjM4NzI5OCAtMS4wMDQyMzQgMy40MjcxNDggLTEuMDA0MjM0QzMuNTU0NjcgLTEuMDA0MjM0IDMuNjY2MjUyIC0xLjEwNzg0NiAzLjY2NjI1MiAtMS4yNTEzMDhDMy42NjYyNTIgLTEuNDAyNzQgMy41ODY1NSAtMS40MzQ2MiAzLjQ2Njk5OSAtMS40OTA0MTFDMi45MzMwMDEgLTEuNzM3NDg0IDIuNzQxNzE5IC0xLjgyNTE1NiAyLjM1MTE4MyAtMS45ODQ1NThMMy4yODM2ODYgLTIuNDA2OTc0QzMuMzQ3NDQ3IC0yLjQzMDg4NCAzLjQ5ODg3OSAtMi41MDI2MTUgMy41NjI2NCAtMi41MjY1MjZDMy42NDIzNDEgLTIuNTc0MzQ2IDMuNjY2MjUyIC0yLjY1NDA0NyAzLjY2NjI1MiAtMi43MjU3NzhDMy42NjYyNTIgLTIuODIxNDIgMy42MTg0MzEgLTIuOTcyODUyIDMuMzc5MzI4IC0yLjk3Mjg1MkwyLjIzMTYzMSAtMi4xOTE3ODFMMi4zNDMyMTMgLTMuMzcxMzU3QzIuMzU5MTUzIC0zLjUwNjg0OSAyLjM0MzIxMyAtMy43MDYxMDIgMi4xMTIwOCAtMy43MDYxMDJDMS45Njg2MTggLTMuNzA2MTAyIDEuODU3MDM2IC0zLjU4NjU1IDEuODgwOTQ2IC0zLjQ3NDk2OVYtMy4zNzkzMjhMMS45OTI1MjggLTIuMTkxNzgxTDAuOTMyNTAzIC0yLjkyNTAzMUMwLjg2MDc3MiAtMi45NzI4NTIgMC44MzY4NjIgLTIuOTcyODUyIDAuNzk3MDExIC0yLjk3Mjg1MkMwLjY2OTQ4OSAtMi45NzI4NTIgMC41NTc5MDggLTIuODY5MjQgMC41NTc5MDggLTIuNzI1Nzc4QzAuNTU3OTA4IC0yLjU3NDM0NiAwLjYzNzYwOSAtMi41NDI0NjYgMC43NTcxNjEgLTIuNDg2Njc1QzEuMjkxMTU4IC0yLjIzOTYwMSAxLjQ4MjQ0MSAtMi4xNTE5MyAxLjg3Mjk3NiAtMS45OTI1MjhMMC45NDA0NzMgLTEuNTcwMTEyQzAuODc2NzEyIC0xLjU0NjIwMiAwLjcyNTI4IC0xLjQ3NDQ3MSAwLjY2MTUxOSAtMS40NTA1NkMwLjU4MTgxOCAtMS40MDI3NCAwLjU1NzkwOCAtMS4zMjMwMzkgMC41NTc5MDggLTEuMjUxMzA4QzAuNTU3OTA4IC0xLjEwNzg0NiAwLjY2OTQ4OSAtMS4wMDQyMzQgMC43OTcwMTEgLTEuMDA0MjM0QzAuODYwNzcyIC0xLjAwNDIzNCAwLjg3NjcxMiAtMS4wMDQyMzQgMS4wNzU5NjUgLTEuMTQ3Njk2TDEuOTkyNTI4IC0xLjc4NTMwNUwxLjg3Mjk3NiAtMC41MDIxMTdDMS44NzI5NzYgLTAuMzQyNzE1IDIuMDA4NDY4IC0wLjI3MDk4NCAyLjExMjA4IC0wLjI3MDk4NFMyLjM1MTE4MyAtMC4zNDI3MTUgMi4zNTExODMgLTAuNTAyMTE3QzIuMzUxMTgzIC0wLjU4MTgxOCAyLjMxOTMwMyAtMC44MzY4NjIgMi4zMTEzMzMgLTAuOTMyNTAzQzIuMjc5NDUyIC0xLjIwMzQ4NyAyLjI1NTU0MiAtMS41MDYzNTEgMi4yMzE2MzEgLTEuNzg1MzA1TDMuMjkxNjU2IC0xLjA1MjA1NVonIGlkPSdnMC0zJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PScxNDguMTMxNzc3JyB4bGluazpocmVmPScjZzItMTA3JyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScxNTQuNjIxMjgxJyB4bGluazpocmVmPScjZzAtMycgeT0nODYuNzIwMTAzJy8+Cjx1c2UgeD0nMTY5LjMxNjIzNicgeGxpbms6aHJlZj0nI2czLTYxJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScxODguMzgzNTI4JyB4bGluazpocmVmPScjZzMtMTA5JyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScxOTguMTM4NTExJyB4bGluazpocmVmPScjZzMtOTcnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzIwMy45OTE1MDInIHhsaW5rOmhyZWY9JyNnMy0xMjAnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzIxMi4xNjIxNTYnIHhsaW5rOmhyZWY9JyNnMS0xMDInIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzIxOC4xMzk3NTUnIHhsaW5rOmhyZWY9JyNnMi0xMDcnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzIyNC42MjkyNTknIHhsaW5rOmhyZWY9JyNnMS0xMDYnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzIyNy45NTAxNDknIHhsaW5rOmhyZWY9JyNnMi0xMTMnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzIzMy41NjkzMDYnIHhsaW5rOmhyZWY9JyNnMy05MScgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjM2LjgyMDk2NycgeGxpbms6aHJlZj0nI2czLTkxJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScyNDAuMDcyNjI4JyB4bGluazpocmVmPScjZzMtNDknIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzI0NS45MjU2MTgnIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjQ5LjE3NzI4JyB4bGluazpocmVmPScjZzItNTgnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzI1Mi40Mjg5NDEnIHhsaW5rOmhyZWY9JyNnMi0xMDcnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzI1OC45MTg0NDUnIHhsaW5rOmhyZWY9JyNnMy05MycgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMjYyLjE3MDEwNicgeGxpbms6aHJlZj0nI2czLTkzJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PScyNjguNzQyNTk3JyB4bGluazpocmVmPScjZzEtMzAnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzI4MS4zNjE5MjMnIHhsaW5rOmhyZWY9JyNnMi0xMTMnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzI5MC44ODMwNzMnIHhsaW5rOmhyZWY9JyNnMy0xMDEnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzI5Ni4wODU3MzEnIHhsaW5rOmhyZWY9JyNnMy0xMTYnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzMwNC41NDAwNScgeGxpbms6aHJlZj0nI2cyLTExMycgeT0nOTEuNjU2Mjg5Jy8+Cjx1c2UgeD0nMzEzLjQ4MDAzNicgeGxpbms6aHJlZj0nI2cxLTUwJyB5PSc5MS42NTYyODknLz4KPHVzZSB4PSczMjQuNzcxMDA0JyB4bGluazpocmVmPScjZzItODMnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzMzMi42NjYzMjcnIHhsaW5rOmhyZWY9JyNnMS0xMDMnIHk9JzkxLjY1NjI4OScvPgo8dXNlIHg9JzEyNS42MTUxNzEnIHhsaW5rOmhyZWY9JyNnMi0xMTInIHk9JzEwOC41OTI3NzcnLz4KPHVzZSB4PScxMzEuNDkwMzE0JyB4bGluazpocmVmPScjZzMtNDAnIHk9JzEwOC41OTI3NzcnLz4KPHVzZSB4PScxMzYuMDQyNjM5JyB4bGluazpocmVmPScjZzItMTEzJyB5PScxMDguNTkyNzc3Jy8+Cjx1c2UgeD0nMTQxLjY2MTc5NicgeGxpbms6aHJlZj0nI2cyLTU5JyB5PScxMDguNTkyNzc3Jy8+Cjx1c2UgeD0nMTQ2LjkwNTk1NScgeGxpbms6aHJlZj0nI2cyLTgzJyB5PScxMDguNTkyNzc3Jy8+Cjx1c2UgeD0nMTU0LjgwMTI3OCcgeGxpbms6aHJlZj0nI2czLTQxJyB5PScxMDguNTkyNzc3Jy8+Cjx1c2UgeD0nMTY5LjMxNjIzNicgeGxpbms6aHJlZj0nI2czLTYxJyB5PScxMDguNTkyNzc3Jy8+Cjx1c2UgeD0nMTg4LjM4MzUyOCcgeGxpbms6aHJlZj0nI2cyLTExMycgeT0nMTA4LjU5Mjc3NycvPgo8dXNlIHg9JzE5NC4wMDI2ODQnIHhsaW5rOmhyZWY9JyNnMy05MScgeT0nMTA4LjU5Mjc3NycvPgo8dXNlIHg9JzE5Ny4yNTQzNDUnIHhsaW5rOmhyZWY9JyNnMy05MScgeT0nMTA4LjU5Mjc3NycvPgo8dXNlIHg9JzIwMC41MDYwMDcnIHhsaW5rOmhyZWY9JyNnMy00OScgeT0nMTA4LjU5Mjc3NycvPgo8dXNlIHg9JzIwNi4zNTg5OTcnIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nMTA4LjU5Mjc3NycvPgo8dXNlIHg9JzIwOS42MTA2NTgnIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nMTA4LjU5Mjc3NycvPgo8dXNlIHg9JzIxMi44NjIzMTknIHhsaW5rOmhyZWY9JyNnMi0xMDcnIHk9JzEwOC41OTI3NzcnLz4KPHVzZSB4PScyMTkuMzUxODIzJyB4bGluazpocmVmPScjZzAtMycgeT0nMTAzLjY1NjU5MScvPgo8dXNlIHg9JzIyNC4wODQxMzgnIHhsaW5rOmhyZWY9JyNnMy05MycgeT0nMTA4LjU5Mjc3NycvPgo8dXNlIHg9JzIyNy4zMzU3OTknIHhsaW5rOmhyZWY9JyNnMy05MycgeT0nMTA4LjU5Mjc3NycvPgo8L2c+Cjwvc3ZnPg==)
La métrique  vérifie la propriété suivante :
vérifie la propriété suivante :

Figures#
Figure F1 : Gradient conjugué
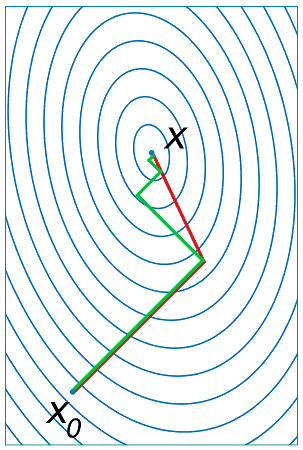
Gradient et gradient conjugué sur une ligne de niveau de la fonction  ,
le gradient est orthogonal aux lignes de niveaux de la fonction
,
le gradient est orthogonal aux lignes de niveaux de la fonction  ,
mais cette direction est rarement la bonne à moins que le point
,
mais cette direction est rarement la bonne à moins que le point
 se situe sur un des axes des ellipses,
le gradient conjugué agrège les derniers déplacements et propose une direction
de recherche plus plausible pour le minimum de la fonction.
Voir Conjugate Gradient Method.
se situe sur un des axes des ellipses,
le gradient conjugué agrège les derniers déplacements et propose une direction
de recherche plus plausible pour le minimum de la fonction.
Voir Conjugate Gradient Method.
Figure F1 : Modèle optimal pour la base de test
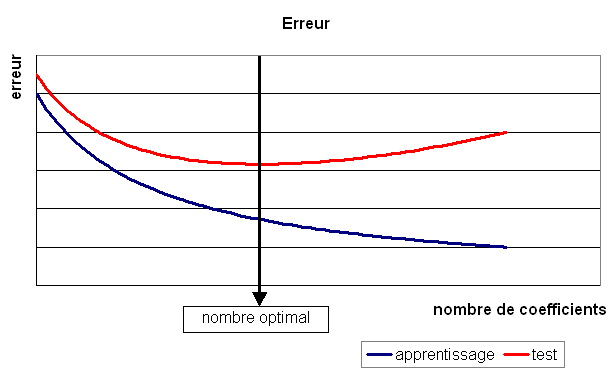
Figure F1 : Principe de la compression par un réseau diabolo

Figure F1 : Réseau de neurones adéquat pour la classification
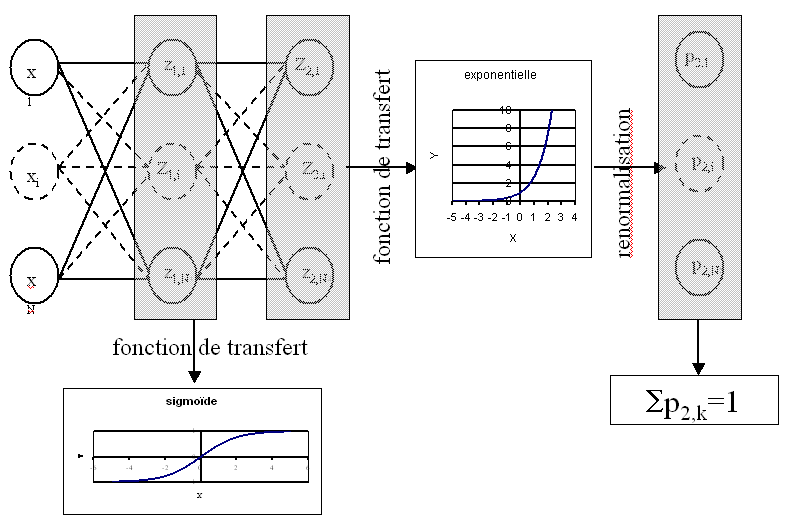
Figure F1 : neurone graphique

Le vecteur  joue le rôle des entrées.
joue le rôle des entrées.
 est appelé parfois le potentiel.
est appelé parfois le potentiel.
 .
.
 est appelée la sortie du neurone.
est appelée la fonction de transfert ou de seuil.
est appelée la sortie du neurone.
est appelée la fonction de transfert ou de seuil.
 .
.
Figure F2 : Exemple de minimal locaux
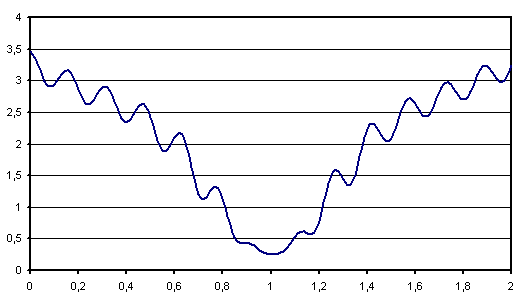
Figure F2 : Modèle du perceptron multi-couche (multi-layer perceptron, MLP)
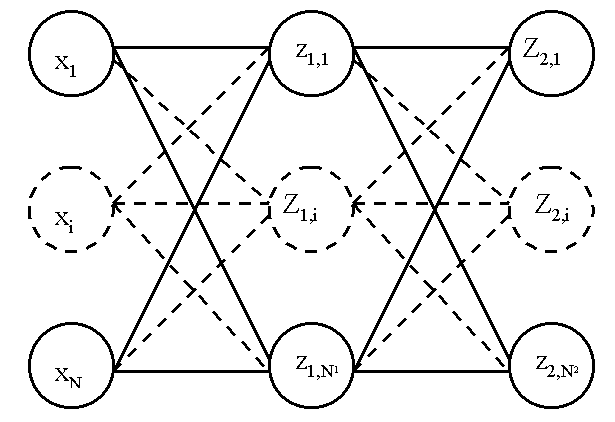
 : entrées
: entrées- nombre de neurones sur la couche
 ,
, 
 sortie du neurone , de la couche
sortie du neurone , de la couche  , par extension,
, par extension, 
 potentiel du neurone de la couche
potentiel du neurone de la couche  coefficient associé à l’entrée
coefficient associé à l’entrée  du neurone de la couche ,
du neurone de la couche , biais du neurone de la couche
biais du neurone de la couche  fonction de seuil du neurone de la couche
fonction de seuil du neurone de la couche
Figure F2 : Réseau de neurones pour lequel la sélection de connexions s’applique
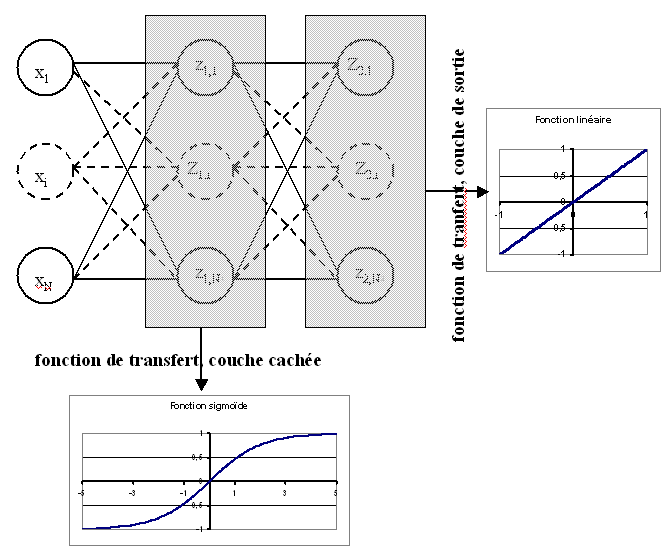
Figure F2 : Réseau diabolo : réduction d’une dimension

Ce réseau possède 3 entrées et 3 sorties
Minimiser l’erreur  revient à compresser un vecteur de dimension 3 en un vecteur de dimension 2.
Les coefficients de la
première couche du réseau de neurones permettent de compresser les données.
Les coefficients de la seconde couche permettent de les décompresser.
revient à compresser un vecteur de dimension 3 en un vecteur de dimension 2.
Les coefficients de la
première couche du réseau de neurones permettent de compresser les données.
Les coefficients de la seconde couche permettent de les décompresser.
Figure F3 : Courbe d’inertie pour l’ACP
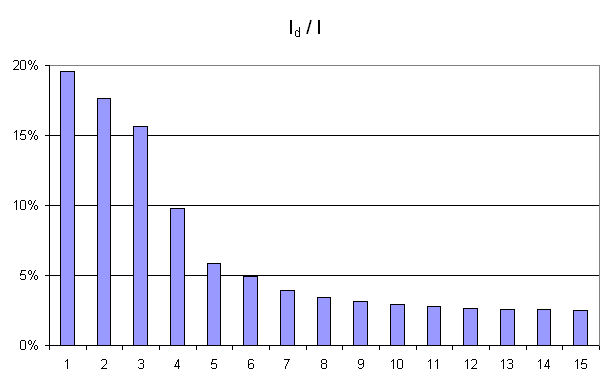
Courbe d’inertie : point d’inflexion pour  ,
l’expérience montre que généralement, seules les
projections sur un ou plusieurs des quatre premiers vecteurs propres
reflètera l’information contenue par le nuage de points.
,
l’expérience montre que généralement, seules les
projections sur un ou plusieurs des quatre premiers vecteurs propres
reflètera l’information contenue par le nuage de points.
Problèmes#
Problème P1 : Classification
Soit une variable aléatoire
et une variable aléatoire discrète  ,
l’objectif est d’approximer la fonction
,
l’objectif est d’approximer la fonction  .
Les données du problème sont
un échantillon de points :
.
Les données du problème sont
un échantillon de points :  avec
avec  et un modèle paramétré avec
et un modèle paramétré avec  :
:

avec  ,
,  est une fonction de paramètre
à valeur dans
est une fonction de paramètre
à valeur dans  et vérifiant la
contrainte :
et vérifiant la
contrainte :  .
.
Problème P1 : Factorisation de matrices positifs
Soit  , on cherche les matrices à coefficients positifs
, on cherche les matrices à coefficients positifs
 et
et  qui sont solution
du problème d’optimisation :
qui sont solution
du problème d’optimisation :

Problème P1 : Optimiser un système de complétion
On suppose que l’ensemble des complétions  est connu.
On souhaite ordonner cet ensemble pour obtenir l’ensemble ordonné
des complétions
est connu.
On souhaite ordonner cet ensemble pour obtenir l’ensemble ordonné
des complétions  qu’on considère comme une permutation
qu’on considère comme une permutation
 de l’ensemble de départ :
de l’ensemble de départ :  .
Ce système de complétion est destiné à un des utilisateurs qui forment des recherches ou requêtes
.
Ce système de complétion est destiné à un des utilisateurs qui forment des recherches ou requêtes
 .
.
 est la requête,
est la requête,  est la fréquence associée
à cette requête. On définit l’effort demandé aux utilisateurs
par ce système de complétion :
est la fréquence associée
à cette requête. On définit l’effort demandé aux utilisateurs
par ce système de complétion :

Déterminer le meilleur système de complétion revient à trouver
la permutation qui minimise  .
.
Problème P1 : Régression
Soient deux variables aléatoires et ,
l’objectif est d’approximer la fonction
.
Les données du problème sont
un échantillon de points
et un modèle paramétré avec :math:theta` :

avec ,
bruit blanc,
est une fonction de paramètre .
Problème P1 : analyse en composantes principales (ACP)
Soit  avec
avec  .
Soit
.
Soit  ,
,  où les vecteurs
où les vecteurs  sont les colonnes de et
sont les colonnes de et  .
On suppose également que les forment une base othonormée.
Par conséquent :
.
On suppose également que les forment une base othonormée.
Par conséquent :

 est l’ensemble des
vecteurs projetés sur le sous-espace vectoriel
engendré par les vecteurs .
Réaliser une analyse en composantes principales, c’est trouver le
meilleur plan de projection pour les vecteurs
, celui qui maximise l’inertie de ce nuage de points,
c’est donc trouver
est l’ensemble des
vecteurs projetés sur le sous-espace vectoriel
engendré par les vecteurs .
Réaliser une analyse en composantes principales, c’est trouver le
meilleur plan de projection pour les vecteurs
, celui qui maximise l’inertie de ce nuage de points,
c’est donc trouver  tel que :
tel que :
(1)#
Le terme  est l’inertie du nuage de points
projeté sur le sous-espace vectoriel défini par les
vecteurs colonnes de la matrice .
est l’inertie du nuage de points
projeté sur le sous-espace vectoriel défini par les
vecteurs colonnes de la matrice .
Problème P1 : estimateur du maximum de vraisemblance
Soit un vecteur  tel que :
tel que :

On cherche le vecteur  vérifiant :
vérifiant :

Problème P2 : Optimiser un système de complétion filtré
On suppose que l’ensemble des complétions est connu.
On souhaite ordonner cet ensemble pour obtenir l’ensemble ordonné
des complétions qu’on considère comme une permutation
de l’ensemble de départ : .
On utilise aussi une fonction qui filtre les suggestions montrées
à l’utilisateur, elle ne change pas l’ordre mais peut cacher certaines suggestions
si elles ne sont pas pertinentes.
Ce système de complétion est destiné à un des utilisateurs qui forment des recherches ou requêtes
.
est la requête, est la fréquence associée
à cette requête. On définit l’effort demandé aux utilisateurs
par ce système de complétion :

Déterminer le meilleur système de complétion revient à trouver
la permutation qui minimise  .
.
Problème P2 : Prédiction
Soit et ,
on cherche les matrices à coefficients positifs
qui sont solution
du problème d’optimisation :

Problème P2 : classification
Soit l’échantillon suivant :

 représente la probabilité que l’élément
appartiennent à la classe :
représente la probabilité que l’élément
appartiennent à la classe :

Le classifieur cherché est une fonction définie par :

Dont le vecteur de poids est égal à :

Propriétés#
Problème P1 : Classification
Soit une variable aléatoire
et une variable aléatoire discrète ,
l’objectif est d’approximer la fonction .
Les données du problème sont
un échantillon de points :
avec
et un modèle paramétré avec :
avec , est une fonction de paramètre
à valeur dans et vérifiant la
contrainte : .
Problème P1 : Factorisation de matrices positifs
Soit , on cherche les matrices à coefficients positifs
et qui sont solution
du problème d’optimisation :
Problème P1 : Optimiser un système de complétion
On suppose que l’ensemble des complétions est connu.
On souhaite ordonner cet ensemble pour obtenir l’ensemble ordonné
des complétions qu’on considère comme une permutation
de l’ensemble de départ : .
Ce système de complétion est destiné à un des utilisateurs qui forment des recherches ou requêtes
.
est la requête, est la fréquence associée
à cette requête. On définit l’effort demandé aux utilisateurs
par ce système de complétion :
Déterminer le meilleur système de complétion revient à trouver
la permutation qui minimise .
Problème P1 : Régression
Soient deux variables aléatoires et ,
l’objectif est d’approximer la fonction
.
Les données du problème sont
un échantillon de points
et un modèle paramétré avec :math:theta` :
avec ,
bruit blanc,
est une fonction de paramètre .
Problème P1 : analyse en composantes principales (ACP)
Soit avec .
Soit ,
où les vecteurs
sont les colonnes de et .
On suppose également que les forment une base othonormée.
Par conséquent :
est l’ensemble des
vecteurs projetés sur le sous-espace vectoriel
engendré par les vecteurs .
Réaliser une analyse en composantes principales, c’est trouver le
meilleur plan de projection pour les vecteurs
, celui qui maximise l’inertie de ce nuage de points,
c’est donc trouver tel que :
(1)#
Le terme est l’inertie du nuage de points
projeté sur le sous-espace vectoriel défini par les
vecteurs colonnes de la matrice .
Problème P1 : estimateur du maximum de vraisemblance
Soit un vecteur tel que :
On cherche le vecteur vérifiant :
Problème P2 : Optimiser un système de complétion filtré
On suppose que l’ensemble des complétions est connu.
On souhaite ordonner cet ensemble pour obtenir l’ensemble ordonné
des complétions qu’on considère comme une permutation
de l’ensemble de départ : .
On utilise aussi une fonction qui filtre les suggestions montrées
à l’utilisateur, elle ne change pas l’ordre mais peut cacher certaines suggestions
si elles ne sont pas pertinentes.
Ce système de complétion est destiné à un des utilisateurs qui forment des recherches ou requêtes
.
est la requête, est la fréquence associée
à cette requête. On définit l’effort demandé aux utilisateurs
par ce système de complétion :
Déterminer le meilleur système de complétion revient à trouver
la permutation qui minimise .
Problème P2 : Prédiction
Soit et ,
on cherche les matrices à coefficients positifs
qui sont solution
du problème d’optimisation :
Problème P2 : classification
Soit l’échantillon suivant :
représente la probabilité que l’élément
appartiennent à la classe :
Le classifieur cherché est une fonction définie par :
Dont le vecteur de poids est égal à :
Tables#
Théorèmes#
Théorème T1 : Aire sous la courbe (AUC)
On utilise les notations de la définition de la Courbe ROC.
L’aire sous la courbe ROC est égale à  .
.
Théorème T1 : La factorisation de matrice est équivalente à une analyse en composantes principales
On note ,
, avec
, ,
et avec .
On suppose que les matrices
sont solution du problème d’optimisation
.
On considère que la matrice est un ensemble de
points dans dans un espace vectoriel de dimension .
On suppose  .
La matrice
.
La matrice  définit un hyperplan identique à celui défini
par les vecteurs propres associés aux
plus grande valeurs propres de la matrice
définit un hyperplan identique à celui défini
par les vecteurs propres associés aux
plus grande valeurs propres de la matrice
 où
où  est la transposée de .
est la transposée de .
Théorème T1 : M”, ordre et sous-ensemble
Soit une requête de l’ensemble de complétion
ordonnées selon  .
Si cet ordre vérifie :
.
Si cet ordre vérifie :
(1)#![\forall k, \; \sigma(q[1..k]) \infegal \sigma(q[1..k+1])](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTEuOTU1MTY4cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMTU3LjAxNjczMiA4My44ODUzNjYgMTUyLjIxODEgMTEuOTU1MTY4JyB3aWR0aD0nMTUyLjIxODFwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNOC4wNjk3MzggLTcuMTAxMzdDOC4yMTMyIC03LjE3MzEwMSA4LjI5Njg4NyAtNy4yMzI4NzcgOC4yOTY4ODcgLTcuMzY0Mzg0UzguMTg5MjkgLTcuNjAzNDg3IDguMDU3NzgzIC03LjYwMzQ4N0M3Ljk5ODAwNyAtNy42MDM0ODcgNy44OTA0MTEgLTcuNTU1NjY2IDcuODQyNTkgLTcuNTMxNzU2TDEuMjMxMzgyIC00LjQxMTQ1N0MxLjAyODE0NCAtNC4zMTU4MTYgMC45OTIyNzkgLTQuMjMyMTMgMC45OTIyNzkgLTQuMTM2NDg4UzEuMDQwMSAtMy45NTcxNjEgMS4yMzEzODIgLTMuODczNDc0TDcuODQyNTkgLTAuNzY1MTMxQzcuOTk4MDA3IC0wLjY4MTQ0NSA4LjAyMTkxOCAtMC42ODE0NDUgOC4wNTc3ODMgLTAuNjgxNDQ1QzguMTg5MjkgLTAuNjgxNDQ1IDguMjk2ODg3IC0wLjc4OTA0MSA4LjI5Njg4NyAtMC45MjA1NDhDOC4yOTY4ODcgLTEuMDc1OTY1IDguMTg5MjkgLTEuMTIzNzg2IDguMDU3NzgzIC0xLjE4MzU2MkwxLjc5MzI3NSAtNC4xMzY0ODhMOC4wNjk3MzggLTcuMTAxMzdaTTcuODQyNTkgMS41NTQxNzJDNy45OTgwMDcgMS42Mzc4NTggOC4wMjE5MTggMS42Mzc4NTggOC4wNTc3ODMgMS42Mzc4NThDOC4xODkyOSAxLjYzNzg1OCA4LjI5Njg4NyAxLjUzMDI2MiA4LjI5Njg4NyAxLjM5ODc1NUM4LjI5Njg4NyAxLjI0MzMzNyA4LjE4OTI5IDEuMTk1NTE3IDguMDU3NzgzIDEuMTM1NzQxTDEuNDU4NTMxIC0xLjk3MjYwM0MxLjMwMzExMyAtMi4wNTYyODkgMS4yNzkyMDMgLTIuMDU2Mjg5IDEuMjMxMzgyIC0yLjA1NjI4OUMxLjA4NzkyIC0yLjA1NjI4OSAwLjk5MjI3OSAtMS45NDg2OTIgMC45OTIyNzkgLTEuODE3MTg2QzAuOTkyMjc5IC0xLjcyMTU0NCAxLjA0MDEgLTEuNjM3ODU4IDEuMjMxMzgyIC0xLjU1NDE3Mkw3Ljg0MjU5IDEuNTU0MTcyWicgaWQ9J2cwLTU0Jy8+CjxwYXRoIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4NiAtMC41Mzc5ODMgMS44MTcxODYgLTIuOTc2ODM3QzEuODE3MTg2IC01LjI5NjEzOSAyLjM3OTA3OCAtNy4yOTI2NTMgMy43NjU4NzggLTguNzAzMzYyQzMuODg1NDMgLTguODEwOTU5IDMuODg1NDMgLTguODM0ODY5IDMuODg1NDMgLTguODcwNzM1QzMuODg1NDMgLTguOTQyNDY2IDMuODI1NjU0IC04Ljk2NjM3NiAzLjc3NzgzMyAtOC45NjYzNzZDMy42MjI0MTYgLTguOTY2Mzc2IDIuNjQyMDkyIC04LjEwNTYwNCAyLjA1NjI4OSAtNi45MzM5OThDMS40NDY1NzUgLTUuNzI2NTI2IDEuMTcxNjA2IC00LjQ0NzMyMyAxLjE3MTYwNiAtMi45NzY4MzdDMS4xNzE2MDYgLTEuOTEyODI3IDEuMzM4OTc5IC0wLjQ5MDE2MiAxLjk2MDY0OCAwLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJyBpZD0nZzMtNDAnLz4KPHBhdGggZD0nTTMuMzcxMzU3IC0yLjk3NjgzN0MzLjM3MTM1NyAtMy44ODU0MyAzLjI1MTgwNiAtNS4zNjc4NyAyLjU4MjMxNiAtNi43NTQ2N0MxLjg3Njk2MSAtOC4xODkyOSAwLjg5NjYzOCAtOC45NjYzNzYgMC43NjUxMzEgLTguOTY2Mzc2QzAuNzE3MzEgLTguOTY2Mzc2IDAuNjU3NTM0IC04Ljk0MjQ2NiAwLjY1NzUzNCAtOC44NzA3MzVDMC42NTc1MzQgLTguODM0ODY5IDAuNjU3NTM0IC04LjgxMDk1OSAwLjg2MDc3MiAtOC42MDc3MjFDMi4wNTYyODkgLTcuNDAwMjQ5IDIuNzI1Nzc4IC01LjQyNzY0NiAyLjcyNTc3OCAtMi45ODg3OTJDMi43MjU3NzggLTAuNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IDAuNzc3MDg2IDIuNzM3NzMzQzAuNjU3NTM0IDIuODQ1MzMgMC42NTc1MzQgMi44NjkyNCAwLjY1NzUzNCAyLjkwNTEwNkMwLjY1NzUzNCAyLjk3NjgzNyAwLjcxNzMxIDMuMDAwNzQ3IDAuNzY1MTMxIDMuMDAwNzQ3QzAuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IDAuOTY4MzY5QzMuMDk2Mzg5IC0wLjI1MTA1OSAzLjM3MTM1NyAtMS41NDIyMTcgMy4zNzEzNTcgLTIuOTc2ODM3WicgaWQ9J2czLTQxJy8+CjxwYXRoIGQ9J000Ljc3MDExMiAtMi43NjE2NDRIOC4wNjk3MzhDOC4yMzcxMTEgLTIuNzYxNjQ0IDguNDUyMzA0IC0yLjc2MTY0NCA4LjQ1MjMwNCAtMi45NzY4MzdDOC40NTIzMDQgLTMuMjAzOTg1IDguMjQ5MDY2IC0zLjIwMzk4NSA4LjA2OTczOCAtMy4yMDM5ODVINC43NzAxMTJWLTYuNTAzNjExQzQuNzcwMTEyIC02LjY3MDk4NCA0Ljc3MDExMiAtNi44ODYxNzcgNC41NTQ5MTkgLTYuODg2MTc3QzQuMzI3NzcxIC02Ljg4NjE3NyA0LjMyNzc3MSAtNi42ODI5MzkgNC4zMjc3NzEgLTYuNTAzNjExVi0zLjIwMzk4NUgxLjAyODE0NEMwLjg2MDc3MiAtMy4yMDM5ODUgMC42NDU1NzkgLTMuMjAzOTg1IDAuNjQ1NTc5IC0yLjk4ODc5MkMwLjY0NTU3OSAtMi43NjE2NDQgMC44NDg4MTcgLTIuNzYxNjQ0IDEuMDI4MTQ0IC0yLjc2MTY0NEg0LjMyNzc3MVYwLjUzNzk4M0M0LjMyNzc3MSAwLjcwNTM1NSA0LjMyNzc3MSAwLjkyMDU0OCA0LjU0Mjk2NCAwLjkyMDU0OEM0Ljc3MDExMiAwLjkyMDU0OCA0Ljc3MDExMiAwLjcxNzMxIDQuNzcwMTEyIDAuNTM3OTgzVi0yLjc2MTY0NFonIGlkPSdnMy00MycvPgo8cGF0aCBkPSdNMy40NDMwODggLTcuNjYzMjYzQzMuNDQzMDg4IC03LjkzODIzMiAzLjQ0MzA4OCAtNy45NTAxODcgMy4yMDM5ODUgLTcuOTUwMTg3QzIuOTE3MDYxIC03LjYyNzM5NyAyLjMxOTMwMyAtNy4xODUwNTYgMS4wODc5MiAtNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5IC02LjgzODM1NiAxLjk2MDY0OCAtNi44MzgzNTYgMi42MTgxODIgLTcuMTQ5MTkxVi0wLjkyMDU0OEMyLjYxODE4MiAtMC40OTAxNjIgMi41ODIzMTYgLTAuMzQ2NyAxLjUzMDI2MiAtMC4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEgLTAuMDIzOTEgMi42NDIwOTIgLTAuMDIzOTEgMy4wMzY2MTMgLTAuMDIzOTFTNC41Nzg4MjkgLTAuMDIzOTEgNC45MDE2MTkgMFYtMC4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0IC0wLjM0NjcgMy40NDMwODggLTAuNDkwMTYyIDMuNDQzMDg4IC0wLjkyMDU0OFYtNy42NjMyNjNaJyBpZD0nZzMtNDknLz4KPHBhdGggZD0nTTIuOTg4NzkyIDIuOTg4NzkyVjIuNTQ2NDUxSDEuODI5MTQxVi04LjUyNDAzNUgyLjk4ODc5MlYtOC45NjYzNzZIMS4zODY4VjIuOTg4NzkySDIuOTg4NzkyWicgaWQ9J2czLTkxJy8+CjxwYXRoIGQ9J00xLjg1MzA1MSAtOC45NjYzNzZIMC4yNTEwNTlWLTguNTI0MDM1SDEuNDEwNzFWMi41NDY0NTFIMC4yNTEwNTlWMi45ODg3OTJIMS44NTMwNTFWLTguOTY2Mzc2WicgaWQ9J2czLTkzJy8+CjxwYXRoIGQ9J002LjU4NzI5OCAtNy44NDI1OUM2LjY0NzA3MyAtNy45NzQwOTcgNi42NDcwNzMgLTcuOTk4MDA3IDYuNjQ3MDczIC04LjA1Nzc4M0M2LjY0NzA3MyAtOC4xNzczMzUgNi41NTE0MzIgLTguMjk2ODg3IDYuNDA3OTcgLTguMjk2ODg3QzYuMjUyNTUzIC04LjI5Njg4NyA2LjE4MDgyMiAtOC4xNTM0MjUgNi4xMzMwMDEgLTguMDIxOTE4TDUuMTQwNzIyIC01LjM5MTc4MUgxLjUwNjM1MUwwLjUxNDA3MiAtOC4wMjE5MThDMC40NTQyOTYgLTguMTg5MjkgMC4zOTQ1MjEgLTguMjk2ODg3IDAuMjM5MTAzIC04LjI5Njg4N0MwLjExOTU1MiAtOC4yOTY4ODcgMCAtOC4xNzczMzUgMCAtOC4wNTc3ODNDMCAtOC4wMzM4NzMgMCAtOC4wMDk5NjMgMC4wNzE3MzEgLTcuODQyNTlMMy4wNDg1NjggLTAuMDExOTU1QzMuMTA4MzQ0IDAuMTU1NDE3IDMuMTY4MTIgMC4yNjMwMTQgMy4zMjM1MzcgMC4yNjMwMTRDMy40OTA5MDkgMC4yNjMwMTQgMy41Mzg3MyAwLjEzMTUwNyAzLjU4NjU1IDAuMDExOTU1TDYuNTg3Mjk4IC03Ljg0MjU5Wk0xLjY5NzYzNCAtNC45MTM1NzRINC45NDk0NEwzLjMyMzUzNyAtMC42NTc1MzRMMS42OTc2MzQgLTQuOTEzNTc0WicgaWQ9J2cxLTU2Jy8+CjxwYXRoIGQ9J002LjA3MzIyNSAtNC41MDcwOThDNi4yMjg2NDMgLTQuNTA3MDk4IDYuNjIzMTYzIC00LjUwNzA5OCA2LjYyMzE2MyAtNC44ODk2NjRDNi42MjMxNjMgLTUuMTUyNjc3IDYuMzk2MDE1IC01LjE1MjY3NyA2LjE4MDgyMiAtNS4xNTI2NzdIMy41Mzg3M0MxLjc0NTQ1NSAtNS4xNTI2NzcgMC40NTQyOTYgLTMuMTU2MTY0IDAuNDU0Mjk2IC0xLjc0NTQ1NUMwLjQ1NDI5NiAtMC43MjkyNjUgMS4xMTE4MzEgMC4xMTk1NTIgMi4xODc3OTYgMC4xMTk1NTJDMy41OTg1MDYgMC4xMTk1NTIgNS4xNDA3MjIgLTEuMzk4NzU1IDUuMTQwNzIyIC0zLjE5MjAzQzUuMTQwNzIyIC0zLjY1ODI4MSA1LjAzMzEyNiAtNC4xMTI1NzggNC43NDYyMDIgLTQuNTA3MDk4SDYuMDczMjI1Wk0yLjE5OTc1MSAtMC4xMTk1NTJDMS41OTAwMzcgLTAuMTE5NTUyIDEuMTQ3Njk2IC0wLjU4NTgwMyAxLjE0NzY5NiAtMS40MTA3MUMxLjE0NzY5NiAtMi4xMjgwMiAxLjU3ODA4MiAtNC41MDcwOTggMy4zMzU0OTIgLTQuNTA3MDk4QzMuODQ5NTY0IC00LjUwNzA5OCA0LjQyMzQxMiAtNC4yNTYwNCA0LjQyMzQxMiAtMy4zMzU0OTJDNC40MjM0MTIgLTIuOTE3MDYxIDQuMjMyMTMgLTEuOTEyODI3IDMuODEzNjk5IC0xLjIxOTQyN0MzLjM4MzMxMyAtMC41MTQwNzIgMi43Mzc3MzMgLTAuMTE5NTUyIDIuMTk5NzUxIC0wLjExOTU1MlonIGlkPSdnMi0yNycvPgo8cGF0aCBkPSdNMi4xOTk3NTEgLTAuNTczODQ4QzIuMTk5NzUxIC0wLjkyMDU0OCAxLjkxMjgyNyAtMS4xNTk2NTEgMS42MjU5MDMgLTEuMTU5NjUxQzEuMjc5MjAzIC0xLjE1OTY1MSAxLjA0MDEgLTAuODcyNzI3IDEuMDQwMSAtMC41ODU4MDNDMS4wNDAxIC0wLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MSAtMC4yODY5MjQgMi4xOTk3NTEgLTAuNTczODQ4WicgaWQ9J2cyLTU4Jy8+CjxwYXRoIGQ9J00yLjMzMTI1OCAwLjA0NzgyMUMyLjMzMTI1OCAtMC42NDU1NzkgMi4xMDQxMSAtMS4xNTk2NTEgMS42MTM5NDggLTEuMTU5NjUxQzEuMjMxMzgyIC0xLjE1OTY1MSAxLjA0MDEgLTAuODQ4ODE3IDEuMDQwMSAtMC41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNyAtMC4wNDc4MjEgMi4wMjA0MjMgLTAuMTU1NDE3QzIuMDQ0MzM0IC0wLjE3OTMyOCAyLjA1NjI4OSAtMC4xNzkzMjggMi4wNjgyNDQgLTAuMTc5MzI4QzIuMDkyMTU0IC0wLjE3OTMyOCAyLjA5MjE1NCAtMC4wMTE5NTUgMi4wOTIxNTQgMC4wNDc4MjFDMi4wOTIxNTQgMC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAwLjA0NzgyMVonIGlkPSdnMi01OScvPgo8cGF0aCBkPSdNMy4zNTk0MDIgLTcuOTk4MDA3QzMuMzcxMzU3IC04LjA0NTgyOCAzLjM5NTI2OCAtOC4xMTc1NTkgMy4zOTUyNjggLTguMTc3MzM1QzMuMzk1MjY4IC04LjI5Njg4NyAzLjI3NTcxNiAtOC4yOTY4ODcgMy4yNTE4MDYgLTguMjk2ODg3QzMuMjM5ODUxIC04LjI5Njg4NyAyLjgwOTQ2NSAtOC4yNjEwMjEgMi41OTQyNzEgLTguMjM3MTExQzIuMzkxMDM0IC04LjIyNTE1NiAyLjIxMTcwNiAtOC4yMDEyNDUgMS45OTY1MTMgLTguMTg5MjlDMS43MDk1ODkgLTguMTY1MzggMS42MjU5MDMgLTguMTUzNDI1IDEuNjI1OTAzIC03LjkzODIzMkMxLjYyNTkwMyAtNy44MTg2OCAxLjc0NTQ1NSAtNy44MTg2OCAxLjg2NTAwNiAtNy44MTg2OEMyLjQ3NDcyIC03LjgxODY4IDIuNDc0NzIgLTcuNzExMDgzIDIuNDc0NzIgLTcuNTkxNTMyQzIuNDc0NzIgLTcuNTQzNzExIDIuNDc0NzIgLTcuNTE5ODAxIDIuNDE0OTQ0IC03LjMwNDYwOEwwLjcwNTM1NSAtMC40NjYyNTJDMC42NTc1MzQgLTAuMjg2OTI0IDAuNjU3NTM0IC0wLjI2MzAxNCAwLjY1NzUzNCAtMC4xOTEyODNDMC42NTc1MzQgMC4wNzE3MzEgMC44NjA3NzIgMC4xMTk1NTIgMC45ODAzMjQgMC4xMTk1NTJDMS4zMTUwNjggMC4xMTk1NTIgMS4zODY4IC0wLjE0MzQ2MiAxLjQ4MjQ0MSAtMC41MTQwNzJMMi4wNDQzMzQgLTIuNzQ5Njg5QzIuOTA1MTA2IC0yLjY1NDA0NyAzLjQxOTE3OCAtMi4yOTUzOTIgMy40MTkxNzggLTEuNzIxNTQ0QzMuNDE5MTc4IC0xLjY0OTgxMyAzLjQxOTE3OCAtMS42MDE5OTMgMy4zODMzMTMgLTEuNDIyNjY1QzMuMzM1NDkyIC0xLjI0MzMzNyAzLjMzNTQ5MiAtMS4wOTk4NzUgMy4zMzU0OTIgLTEuMDQwMUMzLjMzNTQ5MiAtMC4zNDY3IDMuNzg5Nzg4IDAuMTE5NTUyIDQuMzk5NTAyIDAuMTE5NTUyQzQuOTQ5NDQgMC4xMTk1NTIgNS4yMzYzNjQgLTAuMzgyNTY1IDUuMzMyMDA1IC0wLjU0OTkzOEM1LjU4MzA2NCAtMC45OTIyNzkgNS43Mzg0ODEgLTEuNjYxNzY4IDUuNzM4NDgxIC0xLjcwOTU4OUM1LjczODQ4MSAtMS43NjkzNjUgNS42OTA2NiAtMS44MTcxODYgNS42MTg5MjkgLTEuODE3MTg2QzUuNTExMzMzIC0xLjgxNzE4NiA1LjQ5OTM3NyAtMS43NjkzNjUgNS40NTE1NTcgLTEuNTc4MDgyQzUuMjg0MTg0IC0wLjk1NjQxMyA1LjAzMzEyNiAtMC4xMTk1NTIgNC40MjM0MTIgLTAuMTE5NTUyQzQuMTg0MzA5IC0wLjExOTU1MiA0LjAyODg5MiAtMC4yMzkxMDMgNC4wMjg4OTIgLTAuNjkzNEM0LjAyODg5MiAtMC45MjA1NDggNC4wNzY3MTIgLTEuMTgzNTYyIDQuMTI0NTMzIC0xLjM2Mjg4OUM0LjE3MjM1NCAtMS41NzgwODIgNC4xNzIzNTQgLTEuNTkwMDM3IDQuMTcyMzU0IC0xLjczMzQ5OUM0LjE3MjM1NCAtMi40Mzg4NTQgMy41Mzg3MyAtMi44MzMzNzUgMi40Mzg4NTQgLTIuOTc2ODM3QzIuODY5MjQgLTMuMjM5ODUxIDMuMjk5NjI2IC0zLjcwNjEwMiAzLjQ2Njk5OSAtMy44ODU0M0M0LjE0ODQ0MyAtNC42NTA1NiA0LjYxNDY5NSAtNS4wMzMxMjYgNS4xNjQ2MzMgLTUuMDMzMTI2QzUuNDM5NjAxIC01LjAzMzEyNiA1LjUxMTMzMyAtNC45NjEzOTUgNS41OTUwMTkgLTQuODg5NjY0QzUuMTUyNjc3IC00Ljg0MTg0MyA0Ljk4NTMwNSAtNC41MzEwMDkgNC45ODUzMDUgLTQuMjkxOTA1QzQuOTg1MzA1IC00LjAwNDk4MSA1LjIxMjQ1MyAtMy45MDkzNCA1LjM3OTgyNiAtMy45MDkzNEM1LjcwMjYxNSAtMy45MDkzNCA1Ljk4OTUzOSAtNC4xODQzMDkgNS45ODk1MzkgLTQuNTY2ODc0QzUuOTg5NTM5IC00LjkxMzU3NCA1LjcxNDU3IC01LjI3MjIyOSA1LjE3NjU4OCAtNS4yNzIyMjlDNC41MTkwNTQgLTUuMjcyMjI5IDMuOTgxMDcxIC00LjgwNTk3OCAzLjEzMjI1NCAtMy44NDk1NjRDMy4wMTI3MDIgLTMuNzA2MTAyIDIuNTcwMzYxIC0zLjI1MTgwNiAyLjEyODAyIC0zLjA4NDQzM0wzLjM1OTQwMiAtNy45OTgwMDdaJyBpZD0nZzItMTA3Jy8+CjxwYXRoIGQ9J001LjI3MjIyOSAtNS4xNTI2NzdDNS4yNzIyMjkgLTUuMjEyNDUzIDUuMjI0NDA4IC01LjI2MDI3NCA1LjE2NDYzMyAtNS4yNjAyNzRDNS4wNjg5OTEgLTUuMjYwMjc0IDQuNjAyNzQgLTQuODI5ODg4IDQuMzc1NTkyIC00LjQxMTQ1N0M0LjE2MDM5OSAtNC45NDk0NCAzLjc4OTc4OCAtNS4yNzIyMjkgMy4yNzU3MTYgLTUuMjcyMjI5QzEuOTI0NzgyIC01LjI3MjIyOSAwLjQ2NjI1MiAtMy41MjY3NzUgMC40NjYyNTIgLTEuNzU3NDFDMC40NjYyNTIgLTAuNTczODQ4IDEuMTU5NjUxIDAuMTE5NTUyIDEuOTcyNjAzIDAuMTE5NTUyQzIuNjA2MjI3IDAuMTE5NTUyIDMuMTMyMjU0IC0wLjM1ODY1NSAzLjM4MzMxMyAtMC42MzM2MjRMMy4zOTUyNjggLTAuNjIxNjY5TDIuOTQwOTcxIDEuMTcxNjA2TDIuODMzMzc1IDEuNjAxOTkzQzIuNzI1Nzc4IDEuOTYwNjQ4IDIuNTQ2NDUxIDEuOTYwNjQ4IDEuOTg0NTU4IDEuOTcyNjAzQzEuODUzMDUxIDEuOTcyNjAzIDEuNzMzNDk5IDEuOTcyNjAzIDEuNzMzNDk5IDIuMTk5NzUxQzEuNzMzNDk5IDIuMjgzNDM3IDEuODA1MjMgMi4zMTkzMDMgMS44ODg5MTcgMi4zMTkzMDNDMi4wNTYyODkgMi4zMTkzMDMgMi4yNzE0ODIgMi4yOTUzOTIgMi40Mzg4NTQgMi4yOTUzOTJIMy42NTgyODFDMy44Mzc2MDkgMi4yOTUzOTIgNC4wNDA4NDcgMi4zMTkzMDMgNC4yMjAxNzQgMi4zMTkzMDNDNC4yOTE5MDUgMi4zMTkzMDMgNC40MzUzNjcgMi4zMTkzMDMgNC40MzUzNjcgMi4wOTIxNTRDNC40MzUzNjcgMS45NzI2MDMgNC4zMzk3MjYgMS45NzI2MDMgNC4xNjAzOTkgMS45NzI2MDNDMy41OTg1MDYgMS45NzI2MDMgMy41NjI2NCAxLjg4ODkxNyAzLjU2MjY0IDEuNzkzMjc1QzMuNTYyNjQgMS43MzM0OTkgMy41NzQ1OTUgMS43MjE1NDQgMy42MTA0NjEgMS41NjYxMjdMNS4yNzIyMjkgLTUuMTUyNjc3Wk0zLjU4NjU1IC0xLjQyMjY2NUMzLjUyNjc3NSAtMS4yMTk0MjcgMy41MjY3NzUgLTEuMTk1NTE3IDMuMzU5NDAyIC0wLjk2ODM2OUMzLjA5NjM4OSAtMC42MzM2MjQgMi41NzAzNjEgLTAuMTE5NTUyIDIuMDA4NDY4IC0wLjExOTU1MkMxLjUxODMwNiAtMC4xMTk1NTIgMS4yNDMzMzcgLTAuNTYxODkzIDEuMjQzMzM3IC0xLjI2NzI0OEMxLjI0MzMzNyAtMS45MjQ3ODIgMS42MTM5NDggLTMuMjYzNzYxIDEuODQxMDk2IC0zLjc2NTg3OEMyLjI0NzU3MiAtNC42MDI3NCAyLjgwOTQ2NSAtNS4wMzMxMjYgMy4yNzU3MTYgLTUuMDMzMTI2QzQuMDY0NzU3IC01LjAzMzEyNiA0LjIyMDE3NCAtNC4wNTI4MDIgNC4yMjAxNzQgLTMuOTU3MTYxQzQuMjIwMTc0IC0zLjk0NTIwNSA0LjE4NDMwOSAtMy43ODk3ODggNC4xNzIzNTQgLTMuNzY1ODc4TDMuNTg2NTUgLTEuNDIyNjY1WicgaWQ9J2cyLTExMycvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMTU3LjAxNjczMicgeGxpbms6aHJlZj0nI2cxLTU2JyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScxNjMuNjU4NTEzJyB4bGluazpocmVmPScjZzItMTA3JyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScxNzAuMTQ4MDE3JyB4bGluazpocmVmPScjZzItNTknIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzE3OC43MTMwMDUnIHhsaW5rOmhyZWY9JyNnMi0yNycgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMTg1Ljc5NTQwOScgeGxpbms6aHJlZj0nI2czLTQwJyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScxOTAuMzQ3NzM1JyB4bGluazpocmVmPScjZzItMTEzJyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScxOTUuOTY2ODkxJyB4bGluazpocmVmPScjZzMtOTEnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzE5OS4yMTg1NTInIHhsaW5rOmhyZWY9JyNnMy00OScgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMjA1LjA3MTU0MycgeGxpbms6aHJlZj0nI2cyLTU4JyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScyMDguMzIzMjA0JyB4bGluazpocmVmPScjZzItNTgnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzIxMS41NzQ4NjUnIHhsaW5rOmhyZWY9JyNnMi0xMDcnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzIxOC4wNjQzNjknIHhsaW5rOmhyZWY9JyNnMy05MycgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMjIxLjMxNjAzJyB4bGluazpocmVmPScjZzMtNDEnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzIyOS4xODkxODYnIHhsaW5rOmhyZWY9JyNnMC01NCcgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMjQxLjgwODUxMicgeGxpbms6aHJlZj0nI2cyLTI3JyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScyNDguODkwOTE2JyB4bGluazpocmVmPScjZzMtNDAnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzI1My40NDMyNDInIHhsaW5rOmhyZWY9JyNnMi0xMTMnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzI1OS4wNjIzOTgnIHhsaW5rOmhyZWY9JyNnMy05MScgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMjYyLjMxNDA1OScgeGxpbms6aHJlZj0nI2czLTQ5JyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScyNjguMTY3MDUnIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMjcxLjQxODcxMScgeGxpbms6aHJlZj0nI2cyLTU4JyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScyNzQuNjcwMzcyJyB4bGluazpocmVmPScjZzItMTA3JyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScyODMuODE2NTQnIHhsaW5rOmhyZWY9JyNnMy00MycgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMjk1LjU3Nzg1NScgeGxpbms6aHJlZj0nI2czLTQ5JyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PSczMDEuNDMwODQ1JyB4bGluazpocmVmPScjZzMtOTMnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzMwNC42ODI1MDYnIHhsaW5rOmhyZWY9JyNnMy00MScgeT0nOTIuODUxNzQyJy8+CjwvZz4KPC9zdmc+)
On note l’ensemble ![S'(q[1..k]) = \acc{ q[k+1..len(q)] \in S }](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTEuOTU1MTY4cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU2Ljc4NzA0OSAxNzcuMjQ0OTE5IDExLjk1NTE2OCcgd2lkdGg9JzE3Ny4yNDQ5MTlwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNNi41NTE0MzIgLTIuNzQ5Njg5QzYuNzU0NjcgLTIuNzQ5Njg5IDYuOTY5ODYzIC0yLjc0OTY4OSA2Ljk2OTg2MyAtMi45ODg3OTJTNi43NTQ2NyAtMy4yMjc4OTUgNi41NTE0MzIgLTMuMjI3ODk1SDEuNDgyNDQxQzEuNjI1OTAzIC00LjgyOTg4OCAzLjAwMDc0NyAtNS45Nzc1ODQgNC42ODY0MjYgLTUuOTc3NTg0SDYuNTUxNDMyQzYuNzU0NjcgLTUuOTc3NTg0IDYuOTY5ODYzIC01Ljk3NzU4NCA2Ljk2OTg2MyAtNi4yMTY2ODdTNi43NTQ2NyAtNi40NTU3OTEgNi41NTE0MzIgLTYuNDU1NzkxSDQuNjYyNTE2QzIuNjE4MTgyIC02LjQ1NTc5MSAwLjk5MjI3OSAtNC45MDE2MTkgMC45OTIyNzkgLTIuOTg4NzkyUzIuNjE4MTgyIDAuNDc4MjA3IDQuNjYyNTE2IDAuNDc4MjA3SDYuNTUxNDMyQzYuNzU0NjcgMC40NzgyMDcgNi45Njk4NjMgMC40NzgyMDcgNi45Njk4NjMgMC4yMzkxMDNTNi43NTQ2NyAwIDYuNTUxNDMyIDBINC42ODY0MjZDMy4wMDA3NDcgMCAxLjYyNTkwMyAtMS4xNDc2OTYgMS40ODI0NDEgLTIuNzQ5Njg5SDYuNTUxNDMyWicgaWQ9J2cxLTUwJy8+CjxwYXRoIGQ9J00zLjM4MzMxMyAtNy4zNzYzMzlDMy4zODMzMTMgLTcuODU0NTQ1IDMuNjk0MTQ3IC04LjYxOTY3NiA0Ljk5NzI2IC04LjcwMzM2MkM1LjA1NzAzNiAtOC43MTUzMTggNS4xMDQ4NTcgLTguNzYzMTM4IDUuMTA0ODU3IC04LjgzNDg2OUM1LjEwNDg1NyAtOC45NjYzNzYgNS4wMDkyMTUgLTguOTY2Mzc2IDQuODc3NzA5IC04Ljk2NjM3NkMzLjY4MjE5MiAtOC45NjYzNzYgMi41OTQyNzEgLTguMzU2NjYzIDIuNTgyMzE2IC03LjQ3MTk4Vi00Ljc0NjIwMkMyLjU4MjMxNiAtNC4yNzk5NSAyLjU4MjMxNiAtMy44OTczODUgMi4xMDQxMSAtMy41MDI4NjRDMS42ODU2NzkgLTMuMTU2MTY0IDEuMjMxMzgyIC0zLjEzMjI1NCAwLjk2ODM2OSAtMy4xMjAyOTlDMC45MDg1OTMgLTMuMTA4MzQ0IDAuODYwNzcyIC0zLjA2MDUyMyAwLjg2MDc3MiAtMi45ODg3OTJDMC44NjA3NzIgLTIuODY5MjQgMC45MzI1MDMgLTIuODY5MjQgMS4wNTIwNTUgLTIuODU3Mjg1QzEuODQxMDk2IC0yLjgwOTQ2NSAyLjQxNDk0NCAtMi4zNzkwNzggMi41NDY0NTEgLTEuNzkzMjc1QzIuNTgyMzE2IC0xLjY2MTc2OCAyLjU4MjMxNiAtMS42Mzc4NTggMi41ODIzMTYgLTEuMjA3NDcyVjEuMTU5NjUxQzIuNTgyMzE2IDEuNjYxNzY4IDIuNTgyMzE2IDIuMDQ0MzM0IDMuMTU2MTY0IDIuNDk4NjNDMy42MjI0MTYgMi44NTcyODUgNC40MTE0NTcgMi45ODg3OTIgNC44Nzc3MDkgMi45ODg3OTJDNS4wMDkyMTUgMi45ODg3OTIgNS4xMDQ4NTcgMi45ODg3OTIgNS4xMDQ4NTcgMi44NTcyODVDNS4xMDQ4NTcgMi43Mzc3MzMgNS4wMzMxMjYgMi43Mzc3MzMgNC45MTM1NzQgMi43MjU3NzhDNC4xNjAzOTkgMi42Nzc5NTggMy41NzQ1OTUgMi4yOTUzOTIgMy40MTkxNzggMS42ODU2NzlDMy4zODMzMTMgMS41NzgwODIgMy4zODMzMTMgMS41NTQxNzIgMy4zODMzMTMgMS4xMjM3ODZWLTEuMzg2OEMzLjM4MzMxMyAtMS45MzY3MzcgMy4yODc2NzEgLTIuMTM5OTc1IDIuOTA1MTA2IC0yLjUyMjU0QzIuNjU0MDQ3IC0yLjc3MzU5OSAyLjMwNzM0NyAtMi44OTMxNTEgMS45NzI2MDMgLTIuOTg4NzkyQzIuOTUyOTI3IC0zLjI2Mzc2MSAzLjM4MzMxMyAtMy44MTM2OTkgMy4zODMzMTMgLTQuNTA3MDk4Vi03LjM3NjMzOVonIGlkPSdnMS0xMDInLz4KPHBhdGggZD0nTTIuNTgyMzE2IDEuMzk4NzU1QzIuNTgyMzE2IDEuODc2OTYxIDIuMjcxNDgyIDIuNjQyMDkyIDAuOTY4MzY5IDIuNzI1Nzc4QzAuOTA4NTkzIDIuNzM3NzMzIDAuODYwNzcyIDIuNzg1NTU0IDAuODYwNzcyIDIuODU3Mjg1QzAuODYwNzcyIDIuOTg4NzkyIDAuOTkyMjc5IDIuOTg4NzkyIDEuMDk5ODc1IDIuOTg4NzkyQzIuMjU5NTI3IDIuOTg4NzkyIDMuMzcxMzU3IDIuNDAyOTg5IDMuMzgzMzEzIDEuNDk0Mzk2Vi0xLjIzMTM4MkMzLjM4MzMxMyAtMS42OTc2MzQgMy4zODMzMTMgLTIuMDgwMTk5IDMuODYxNTE5IC0yLjQ3NDcyQzQuMjc5OTUgLTIuODIxNDIgNC43MzQyNDcgLTIuODQ1MzMgNC45OTcyNiAtMi44NTcyODVDNS4wNTcwMzYgLTIuODY5MjQgNS4xMDQ4NTcgLTIuOTE3MDYxIDUuMTA0ODU3IC0yLjk4ODc5MkM1LjEwNDg1NyAtMy4xMDgzNDQgNS4wMzMxMjYgLTMuMTA4MzQ0IDQuOTEzNTc0IC0zLjEyMDI5OUM0LjEyNDUzMyAtMy4xNjgxMiAzLjU1MDY4NSAtMy41OTg1MDYgMy40MTkxNzggLTQuMTg0MzA5QzMuMzgzMzEzIC00LjMxNTgxNiAzLjM4MzMxMyAtNC4zMzk3MjYgMy4zODMzMTMgLTQuNzcwMTEyVi03LjEzNzIzNUMzLjM4MzMxMyAtNy42MzkzNTIgMy4zODMzMTMgLTguMDIxOTE4IDIuODA5NDY1IC04LjQ3NjIxNEMyLjMzMTI1OCAtOC44NDY4MjQgMS41MDYzNTEgLTguOTY2Mzc2IDEuMDk5ODc1IC04Ljk2NjM3NkMwLjk5MjI3OSAtOC45NjYzNzYgMC44NjA3NzIgLTguOTY2Mzc2IDAuODYwNzcyIC04LjgzNDg2OUMwLjg2MDc3MiAtOC43MTUzMTggMC45MzI1MDMgLTguNzE1MzE4IDEuMDUyMDU1IC04LjcwMzM2MkMxLjgwNTIzIC04LjY1NTU0MiAyLjM5MTAzNCAtOC4yNzI5NzYgMi41NDY0NTEgLTcuNjYzMjYzQzIuNTgyMzE2IC03LjU1NTY2NiAyLjU4MjMxNiAtNy41MzE3NTYgMi41ODIzMTYgLTcuMTAxMzdWLTQuNTkwNzg1QzIuNTgyMzE2IC00LjA0MDg0NyAyLjY3Nzk1OCAtMy44Mzc2MDkgMy4wNjA1MjMgLTMuNDU1MDQ0QzMuMzExNTgyIC0zLjIwMzk4NSAzLjY1ODI4MSAtMy4wODQ0MzMgMy45OTMwMjYgLTIuOTg4NzkyQzMuMDEyNzAyIC0yLjcxMzgyMyAyLjU4MjMxNiAtMi4xNjM4ODUgMi41ODIzMTYgLTEuNDcwNDg2VjEuMzk4NzU1WicgaWQ9J2cxLTEwMycvPgo8cGF0aCBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYgLTAuNTM3OTgzIDEuODE3MTg2IC0yLjk3NjgzN0MxLjgxNzE4NiAtNS4yOTYxMzkgMi4zNzkwNzggLTcuMjkyNjUzIDMuNzY1ODc4IC04LjcwMzM2MkMzLjg4NTQzIC04LjgxMDk1OSAzLjg4NTQzIC04LjgzNDg2OSAzLjg4NTQzIC04Ljg3MDczNUMzLjg4NTQzIC04Ljk0MjQ2NiAzLjgyNTY1NCAtOC45NjYzNzYgMy43Nzc4MzMgLTguOTY2Mzc2QzMuNjIyNDE2IC04Ljk2NjM3NiAyLjY0MjA5MiAtOC4xMDU2MDQgMi4wNTYyODkgLTYuOTMzOTk4QzEuNDQ2NTc1IC01LjcyNjUyNiAxLjE3MTYwNiAtNC40NDczMjMgMS4xNzE2MDYgLTIuOTc2ODM3QzEuMTcxNjA2IC0xLjkxMjgyNyAxLjMzODk3OSAtMC40OTAxNjIgMS45NjA2NDggMC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicgaWQ9J2czLTQwJy8+CjxwYXRoIGQ9J00zLjM3MTM1NyAtMi45NzY4MzdDMy4zNzEzNTcgLTMuODg1NDMgMy4yNTE4MDYgLTUuMzY3ODcgMi41ODIzMTYgLTYuNzU0NjdDMS44NzY5NjEgLTguMTg5MjkgMC44OTY2MzggLTguOTY2Mzc2IDAuNzY1MTMxIC04Ljk2NjM3NkMwLjcxNzMxIC04Ljk2NjM3NiAwLjY1NzUzNCAtOC45NDI0NjYgMC42NTc1MzQgLTguODcwNzM1QzAuNjU3NTM0IC04LjgzNDg2OSAwLjY1NzUzNCAtOC44MTA5NTkgMC44NjA3NzIgLTguNjA3NzIxQzIuMDU2Mjg5IC03LjQwMDI0OSAyLjcyNTc3OCAtNS40Mjc2NDYgMi43MjU3NzggLTIuOTg4NzkyQzIuNzI1Nzc4IC0wLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAwLjc3NzA4NiAyLjczNzczM0MwLjY1NzUzNCAyLjg0NTMzIDAuNjU3NTM0IDIuODY5MjQgMC42NTc1MzQgMi45MDUxMDZDMC42NTc1MzQgMi45NzY4MzcgMC43MTczMSAzLjAwMDc0NyAwLjc2NTEzMSAzLjAwMDc0N0MwLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAwLjk2ODM2OUMzLjA5NjM4OSAtMC4yNTEwNTkgMy4zNzEzNTcgLTEuNTQyMjE3IDMuMzcxMzU3IC0yLjk3NjgzN1onIGlkPSdnMy00MScvPgo8cGF0aCBkPSdNNC43NzAxMTIgLTIuNzYxNjQ0SDguMDY5NzM4QzguMjM3MTExIC0yLjc2MTY0NCA4LjQ1MjMwNCAtMi43NjE2NDQgOC40NTIzMDQgLTIuOTc2ODM3QzguNDUyMzA0IC0zLjIwMzk4NSA4LjI0OTA2NiAtMy4yMDM5ODUgOC4wNjk3MzggLTMuMjAzOTg1SDQuNzcwMTEyVi02LjUwMzYxMUM0Ljc3MDExMiAtNi42NzA5ODQgNC43NzAxMTIgLTYuODg2MTc3IDQuNTU0OTE5IC02Ljg4NjE3N0M0LjMyNzc3MSAtNi44ODYxNzcgNC4zMjc3NzEgLTYuNjgyOTM5IDQuMzI3NzcxIC02LjUwMzYxMVYtMy4yMDM5ODVIMS4wMjgxNDRDMC44NjA3NzIgLTMuMjAzOTg1IDAuNjQ1NTc5IC0zLjIwMzk4NSAwLjY0NTU3OSAtMi45ODg3OTJDMC42NDU1NzkgLTIuNzYxNjQ0IDAuODQ4ODE3IC0yLjc2MTY0NCAxLjAyODE0NCAtMi43NjE2NDRINC4zMjc3NzFWMC41Mzc5ODNDNC4zMjc3NzEgMC43MDUzNTUgNC4zMjc3NzEgMC45MjA1NDggNC41NDI5NjQgMC45MjA1NDhDNC43NzAxMTIgMC45MjA1NDggNC43NzAxMTIgMC43MTczMSA0Ljc3MDExMiAwLjUzNzk4M1YtMi43NjE2NDRaJyBpZD0nZzMtNDMnLz4KPHBhdGggZD0nTTMuNDQzMDg4IC03LjY2MzI2M0MzLjQ0MzA4OCAtNy45MzgyMzIgMy40NDMwODggLTcuOTUwMTg3IDMuMjAzOTg1IC03Ljk1MDE4N0MyLjkxNzA2MSAtNy42MjczOTcgMi4zMTkzMDMgLTcuMTg1MDU2IDEuMDg3OTIgLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OSAtNi44MzgzNTYgMS45NjA2NDggLTYuODM4MzU2IDIuNjE4MTgyIC03LjE0OTE5MVYtMC45MjA1NDhDMi42MTgxODIgLTAuNDkwMTYyIDIuNTgyMzE2IC0wLjM0NjcgMS41MzAyNjIgLTAuMzQ2N0gxLjE1OTY1MVYwQzEuNDgyNDQxIC0wLjAyMzkxIDIuNjQyMDkyIC0wLjAyMzkxIDMuMDM2NjEzIC0wLjAyMzkxUzQuNTc4ODI5IC0wLjAyMzkxIDQuOTAxNjE5IDBWLTAuMzQ2N0g0LjUzMTAwOUMzLjQ3ODk1NCAtMC4zNDY3IDMuNDQzMDg4IC0wLjQ5MDE2MiAzLjQ0MzA4OCAtMC45MjA1NDhWLTcuNjYzMjYzWicgaWQ9J2czLTQ5Jy8+CjxwYXRoIGQ9J004LjA2OTczOCAtMy44NzM0NzRDOC4yMzcxMTEgLTMuODczNDc0IDguNDUyMzA0IC0zLjg3MzQ3NCA4LjQ1MjMwNCAtNC4wODg2NjdDOC40NTIzMDQgLTQuMzE1ODE2IDguMjQ5MDY2IC00LjMxNTgxNiA4LjA2OTczOCAtNC4zMTU4MTZIMS4wMjgxNDRDMC44NjA3NzIgLTQuMzE1ODE2IDAuNjQ1NTc5IC00LjMxNTgxNiAwLjY0NTU3OSAtNC4xMDA2MjNDMC42NDU1NzkgLTMuODczNDc0IDAuODQ4ODE3IC0zLjg3MzQ3NCAxLjAyODE0NCAtMy44NzM0NzRIOC4wNjk3MzhaTTguMDY5NzM4IC0xLjY0OTgxM0M4LjIzNzExMSAtMS42NDk4MTMgOC40NTIzMDQgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjg2NTAwNkM4LjQ1MjMwNCAtMi4wOTIxNTQgOC4yNDkwNjYgLTIuMDkyMTU0IDguMDY5NzM4IC0yLjA5MjE1NEgxLjAyODE0NEMwLjg2MDc3MiAtMi4wOTIxNTQgMC42NDU1NzkgLTIuMDkyMTU0IDAuNjQ1NTc5IC0xLjg3Njk2MUMwLjY0NTU3OSAtMS42NDk4MTMgMC44NDg4MTcgLTEuNjQ5ODEzIDEuMDI4MTQ0IC0xLjY0OTgxM0g4LjA2OTczOFonIGlkPSdnMy02MScvPgo8cGF0aCBkPSdNMi45ODg3OTIgMi45ODg3OTJWMi41NDY0NTFIMS44MjkxNDFWLTguNTI0MDM1SDIuOTg4NzkyVi04Ljk2NjM3NkgxLjM4NjhWMi45ODg3OTJIMi45ODg3OTJaJyBpZD0nZzMtOTEnLz4KPHBhdGggZD0nTTEuODUzMDUxIC04Ljk2NjM3NkgwLjI1MTA1OVYtOC41MjQwMzVIMS40MTA3MVYyLjU0NjQ1MUgwLjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJyBpZD0nZzMtOTMnLz4KPHBhdGggZD0nTTIuMTk5NzUxIC0wLjU3Mzg0OEMyLjE5OTc1MSAtMC45MjA1NDggMS45MTI4MjcgLTEuMTU5NjUxIDEuNjI1OTAzIC0xLjE1OTY1MUMxLjI3OTIwMyAtMS4xNTk2NTEgMS4wNDAxIC0wLjg3MjcyNyAxLjA0MDEgLTAuNTg1ODAzQzEuMDQwMSAtMC4yMzkxMDMgMS4zMjcwMjQgMCAxLjYxMzk0OCAwQzEuOTYwNjQ4IDAgMi4xOTk3NTEgLTAuMjg2OTI0IDIuMTk5NzUxIC0wLjU3Mzg0OFonIGlkPSdnMi01OCcvPgo8cGF0aCBkPSdNNy41OTE1MzIgLTguMzA4ODQyQzcuNTkxNTMyIC04LjQxNjQzOCA3LjUwNzg0NiAtOC40MTY0MzggNy40ODM5MzUgLTguNDE2NDM4QzcuNDM2MTE1IC04LjQxNjQzOCA3LjQyNDE1OSAtOC40MDQ0ODMgNy4yODA2OTcgLTguMjI1MTU2QzcuMjA4OTY2IC04LjE0MTQ2OSA2LjcxODgwNCAtNy41MTk4MDEgNi43MDY4NDkgLTcuNTA3ODQ2QzYuMzEyMzI5IC04LjI4NDkzMiA1LjUyMzI4OCAtOC40MTY0MzggNS4wMjExNzEgLTguNDE2NDM4QzMuNTAyODY0IC04LjQxNjQzOCAyLjEyODAyIC03LjAyOTYzOSAyLjEyODAyIC01LjY3ODcwNUMyLjEyODAyIC00Ljc4MjA2NyAyLjY2NjAwMiAtNC4yNTYwNCAzLjI1MTgwNiAtNC4wNTI4MDJDMy4zODMzMTMgLTQuMDA0OTgxIDQuMDg4NjY3IC0zLjgxMzY5OSA0LjQ0NzMyMyAtMy43MzAwMTJDNS4wNTcwMzYgLTMuNTYyNjQgNS4yMTI0NTMgLTMuNTE0ODE5IDUuNDYzNTEyIC0zLjI1MTgwNkM1LjUxMTMzMyAtMy4xOTIwMyA1Ljc1MDQzNiAtMi45MTcwNjEgNS43NTA0MzYgLTIuMzU1MTY4QzUuNzUwNDM2IC0xLjI0MzMzNyA0LjcyMjI5MSAtMC4wOTU2NDEgMy41MjY3NzUgLTAuMDk1NjQxQzIuNTQ2NDUxIC0wLjA5NTY0MSAxLjQ1ODUzMSAtMC41MTQwNzIgMS40NTg1MzEgLTEuODUzMDUxQzEuNDU4NTMxIC0yLjA4MDE5OSAxLjUwNjM1MSAtMi4zNjcxMjMgMS41NDIyMTcgLTIuNDg2Njc1QzEuNTQyMjE3IC0yLjUyMjU0IDEuNTU0MTcyIC0yLjU4MjMxNiAxLjU1NDE3MiAtMi42MDYyMjdDMS41NTQxNzIgLTIuNjU0MDQ3IDEuNTMwMjYyIC0yLjcxMzgyMyAxLjQzNDYyIC0yLjcxMzgyM0MxLjMyNzAyNCAtMi43MTM4MjMgMS4zMTUwNjggLTIuNjg5OTEzIDEuMjY3MjQ4IC0yLjQ4NjY3NUwwLjY1NzUzNCAtMC4wMzU4NjZDMC42NTc1MzQgLTAuMDIzOTEgMC42MDk3MTQgMC4xMzE1MDcgMC42MDk3MTQgMC4xNDM0NjJDMC42MDk3MTQgMC4yNTEwNTkgMC43MDUzNTUgMC4yNTEwNTkgMC43MjkyNjUgMC4yNTEwNTlDMC43NzcwODYgMC4yNTEwNTkgMC43ODkwNDEgMC4yMzkxMDMgMC45MzI1MDMgMC4wNTk3NzZMMS40ODI0NDEgLTAuNjU3NTM0QzEuNzY5MzY1IC0wLjIyNzE0OCAyLjM5MTAzNCAwLjI1MTA1OSAzLjUwMjg2NCAwLjI1MTA1OUM1LjA0NTA4MSAwLjI1MTA1OSA2LjQ1NTc5MSAtMS4yNDMzMzcgNi40NTU3OTEgLTIuNzM3NzMzQzYuNDU1NzkxIC0zLjIzOTg1MSA2LjMzNjIzOSAtMy42ODIxOTIgNS44ODE5NDMgLTQuMTI0NTMzQzUuNjMwODg0IC00LjM3NTU5MiA1LjQxNTY5MSAtNC40MzUzNjcgNC4zMTU4MTYgLTQuNzIyMjkxQzMuNTE0ODE5IC00LjkzNzQ4NCAzLjQwNzIyMyAtNC45NzMzNSAzLjE5MjAzIC01LjE2NDYzM0MyLjk4ODc5MiAtNS4zNjc4NyAyLjgzMzM3NSAtNS42NTQ3OTUgMi44MzMzNzUgLTYuMDYxMjdDMi44MzMzNzUgLTcuMDY1NTA0IDMuODQ5NTY0IC04LjA5MzY0OSA0Ljk4NTMwNSAtOC4wOTM2NDlDNi4xNTY5MTIgLTguMDkzNjQ5IDYuNzA2ODQ5IC03LjM3NjMzOSA2LjcwNjg0OSAtNi4yNDA1OThDNi43MDY4NDkgLTUuOTI5NzYzIDYuNjQ3MDczIC01LjYwNjk3NCA2LjY0NzA3MyAtNS41NTkxNTNDNi42NDcwNzMgLTUuNDUxNTU3IDYuNzQyNzE1IC01LjQ1MTU1NyA2Ljc3ODU4IC01LjQ1MTU1N0M2Ljg4NjE3NyAtNS40NTE1NTcgNi44OTgxMzIgLTUuNDg3NDIyIDYuOTQ1OTUzIC01LjY3ODcwNUw3LjU5MTUzMiAtOC4zMDg4NDJaJyBpZD0nZzItODMnLz4KPHBhdGggZD0nTTIuMTM5OTc1IC0yLjc3MzU5OUMyLjQ2Mjc2NSAtMi43NzM1OTkgMy4yNzU3MTYgLTIuNzk3NTA5IDMuODQ5NTY0IC0zLjAxMjcwMkM0Ljc1ODE1NyAtMy4zNTk0MDIgNC44NDE4NDMgLTQuMDUyODAyIDQuODQxODQzIC00LjI2Nzk5NUM0Ljg0MTg0MyAtNC43OTQwMjIgNC4zODc1NDcgLTUuMjcyMjI5IDMuNTk4NTA2IC01LjI3MjIyOUMyLjM0MzIxMyAtNS4yNzIyMjkgMC41Mzc5ODMgLTQuMTM2NDg4IDAuNTM3OTgzIC0yLjAwODQ2OEMwLjUzNzk4MyAtMC43NTMxNzYgMS4yNTUyOTMgMC4xMTk1NTIgMi4zNDMyMTMgMC4xMTk1NTJDMy45NjkxMTYgMC4xMTk1NTIgNC45OTcyNiAtMS4xNDc2OTYgNC45OTcyNiAtMS4zMDMxMTNDNC45OTcyNiAtMS4zNzQ4NDQgNC45MjU1MjkgLTEuNDM0NjIgNC44Nzc3MDkgLTEuNDM0NjJDNC44NDE4NDMgLTEuNDM0NjIgNC44Mjk4ODggLTEuNDIyNjY1IDQuNzIyMjkxIC0xLjMxNTA2OEMzLjk1NzE2MSAtMC4yOTg4NzkgMi44MjE0MiAtMC4xMTk1NTIgMi4zNjcxMjMgLTAuMTE5NTUyQzEuNjg1Njc5IC0wLjExOTU1MiAxLjMyNzAyNCAtMC42NTc1MzQgMS4zMjcwMjQgLTEuNTQyMjE3QzEuMzI3MDI0IC0xLjcwOTU4OSAxLjMyNzAyNCAtMi4wMDg0NjggMS41MDYzNTEgLTIuNzczNTk5SDIuMTM5OTc1Wk0xLjU2NjEyNyAtMy4wMTI3MDJDMi4wODAxOTkgLTQuODUzNzk4IDMuMjE1OTQgLTUuMDMzMTI2IDMuNTk4NTA2IC01LjAzMzEyNkM0LjEyNDUzMyAtNS4wMzMxMjYgNC40ODMxODggLTQuNzIyMjkxIDQuNDgzMTg4IC00LjI2Nzk5NUM0LjQ4MzE4OCAtMy4wMTI3MDIgMi41NzAzNjEgLTMuMDEyNzAyIDIuMDY4MjQ0IC0zLjAxMjcwMkgxLjU2NjEyN1onIGlkPSdnMi0xMDEnLz4KPHBhdGggZD0nTTMuMzU5NDAyIC03Ljk5ODAwN0MzLjM3MTM1NyAtOC4wNDU4MjggMy4zOTUyNjggLTguMTE3NTU5IDMuMzk1MjY4IC04LjE3NzMzNUMzLjM5NTI2OCAtOC4yOTY4ODcgMy4yNzU3MTYgLTguMjk2ODg3IDMuMjUxODA2IC04LjI5Njg4N0MzLjIzOTg1MSAtOC4yOTY4ODcgMi44MDk0NjUgLTguMjYxMDIxIDIuNTk0MjcxIC04LjIzNzExMUMyLjM5MTAzNCAtOC4yMjUxNTYgMi4yMTE3MDYgLTguMjAxMjQ1IDEuOTk2NTEzIC04LjE4OTI5QzEuNzA5NTg5IC04LjE2NTM4IDEuNjI1OTAzIC04LjE1MzQyNSAxLjYyNTkwMyAtNy45MzgyMzJDMS42MjU5MDMgLTcuODE4NjggMS43NDU0NTUgLTcuODE4NjggMS44NjUwMDYgLTcuODE4NjhDMi40NzQ3MiAtNy44MTg2OCAyLjQ3NDcyIC03LjcxMTA4MyAyLjQ3NDcyIC03LjU5MTUzMkMyLjQ3NDcyIC03LjU0MzcxMSAyLjQ3NDcyIC03LjUxOTgwMSAyLjQxNDk0NCAtNy4zMDQ2MDhMMC43MDUzNTUgLTAuNDY2MjUyQzAuNjU3NTM0IC0wLjI4NjkyNCAwLjY1NzUzNCAtMC4yNjMwMTQgMC42NTc1MzQgLTAuMTkxMjgzQzAuNjU3NTM0IDAuMDcxNzMxIDAuODYwNzcyIDAuMTE5NTUyIDAuOTgwMzI0IDAuMTE5NTUyQzEuMzE1MDY4IDAuMTE5NTUyIDEuMzg2OCAtMC4xNDM0NjIgMS40ODI0NDEgLTAuNTE0MDcyTDIuMDQ0MzM0IC0yLjc0OTY4OUMyLjkwNTEwNiAtMi42NTQwNDcgMy40MTkxNzggLTIuMjk1MzkyIDMuNDE5MTc4IC0xLjcyMTU0NEMzLjQxOTE3OCAtMS42NDk4MTMgMy40MTkxNzggLTEuNjAxOTkzIDMuMzgzMzEzIC0xLjQyMjY2NUMzLjMzNTQ5MiAtMS4yNDMzMzcgMy4zMzU0OTIgLTEuMDk5ODc1IDMuMzM1NDkyIC0xLjA0MDFDMy4zMzU0OTIgLTAuMzQ2NyAzLjc4OTc4OCAwLjExOTU1MiA0LjM5OTUwMiAwLjExOTU1MkM0Ljk0OTQ0IDAuMTE5NTUyIDUuMjM2MzY0IC0wLjM4MjU2NSA1LjMzMjAwNSAtMC41NDk5MzhDNS41ODMwNjQgLTAuOTkyMjc5IDUuNzM4NDgxIC0xLjY2MTc2OCA1LjczODQ4MSAtMS43MDk1ODlDNS43Mzg0ODEgLTEuNzY5MzY1IDUuNjkwNjYgLTEuODE3MTg2IDUuNjE4OTI5IC0xLjgxNzE4NkM1LjUxMTMzMyAtMS44MTcxODYgNS40OTkzNzcgLTEuNzY5MzY1IDUuNDUxNTU3IC0xLjU3ODA4MkM1LjI4NDE4NCAtMC45NTY0MTMgNS4wMzMxMjYgLTAuMTE5NTUyIDQuNDIzNDEyIC0wLjExOTU1MkM0LjE4NDMwOSAtMC4xMTk1NTIgNC4wMjg4OTIgLTAuMjM5MTAzIDQuMDI4ODkyIC0wLjY5MzRDNC4wMjg4OTIgLTAuOTIwNTQ4IDQuMDc2NzEyIC0xLjE4MzU2MiA0LjEyNDUzMyAtMS4zNjI4ODlDNC4xNzIzNTQgLTEuNTc4MDgyIDQuMTcyMzU0IC0xLjU5MDAzNyA0LjE3MjM1NCAtMS43MzM0OTlDNC4xNzIzNTQgLTIuNDM4ODU0IDMuNTM4NzMgLTIuODMzMzc1IDIuNDM4ODU0IC0yLjk3NjgzN0MyLjg2OTI0IC0zLjIzOTg1MSAzLjI5OTYyNiAtMy43MDYxMDIgMy40NjY5OTkgLTMuODg1NDNDNC4xNDg0NDMgLTQuNjUwNTYgNC42MTQ2OTUgLTUuMDMzMTI2IDUuMTY0NjMzIC01LjAzMzEyNkM1LjQzOTYwMSAtNS4wMzMxMjYgNS41MTEzMzMgLTQuOTYxMzk1IDUuNTk1MDE5IC00Ljg4OTY2NEM1LjE1MjY3NyAtNC44NDE4NDMgNC45ODUzMDUgLTQuNTMxMDA5IDQuOTg1MzA1IC00LjI5MTkwNUM0Ljk4NTMwNSAtNC4wMDQ5ODEgNS4yMTI0NTMgLTMuOTA5MzQgNS4zNzk4MjYgLTMuOTA5MzRDNS43MDI2MTUgLTMuOTA5MzQgNS45ODk1MzkgLTQuMTg0MzA5IDUuOTg5NTM5IC00LjU2Njg3NEM1Ljk4OTUzOSAtNC45MTM1NzQgNS43MTQ1NyAtNS4yNzIyMjkgNS4xNzY1ODggLTUuMjcyMjI5QzQuNTE5MDU0IC01LjI3MjIyOSAzLjk4MTA3MSAtNC44MDU5NzggMy4xMzIyNTQgLTMuODQ5NTY0QzMuMDEyNzAyIC0zLjcwNjEwMiAyLjU3MDM2MSAtMy4yNTE4MDYgMi4xMjgwMiAtMy4wODQ0MzNMMy4zNTk0MDIgLTcuOTk4MDA3WicgaWQ9J2cyLTEwNycvPgo8cGF0aCBkPSdNMy4wMzY2MTMgLTcuOTk4MDA3QzMuMDQ4NTY4IC04LjA0NTgyOCAzLjA3MjQ3OCAtOC4xMTc1NTkgMy4wNzI0NzggLTguMTc3MzM1QzMuMDcyNDc4IC04LjI5Njg4NyAyLjk1MjkyNyAtOC4yOTY4ODcgMi45MjkwMTYgLTguMjk2ODg3QzIuOTE3MDYxIC04LjI5Njg4NyAyLjQ4NjY3NSAtOC4yNjEwMjEgMi4yNzE0ODIgLTguMjM3MTExQzIuMDY4MjQ0IC04LjIyNTE1NiAxLjg4ODkxNyAtOC4yMDEyNDUgMS42NzM3MjQgLTguMTg5MjlDMS4zODY4IC04LjE2NTM4IDEuMzAzMTEzIC04LjE1MzQyNSAxLjMwMzExMyAtNy45MzgyMzJDMS4zMDMxMTMgLTcuODE4NjggMS40MjI2NjUgLTcuODE4NjggMS41NDIyMTcgLTcuODE4NjhDMi4xNTE5MyAtNy44MTg2OCAyLjE1MTkzIC03LjcxMTA4MyAyLjE1MTkzIC03LjU5MTUzMkMyLjE1MTkzIC03LjU0MzcxMSAyLjE1MTkzIC03LjUxOTgwMSAyLjA5MjE1NCAtNy4zMDQ2MDhMMC42MDk3MTQgLTEuMzc0ODQ0QzAuNTczODQ4IC0xLjI0MzMzNyAwLjU0OTkzOCAtMS4xNDc2OTYgMC41NDk5MzggLTAuOTU2NDEzQzAuNTQ5OTM4IC0wLjM1ODY1NSAwLjk5MjI3OSAwLjExOTU1MiAxLjYwMTk5MyAwLjExOTU1MkMxLjk5NjUxMyAwLjExOTU1MiAyLjI1OTUyNyAtMC4xNDM0NjIgMi40NTA4MDkgLTAuNTE0MDcyQzIuNjU0MDQ3IC0wLjkwODU5MyAyLjgyMTQyIC0xLjY2MTc2OCAyLjgyMTQyIC0xLjcwOTU4OUMyLjgyMTQyIC0xLjc2OTM2NSAyLjc3MzU5OSAtMS44MTcxODYgMi43MDE4NjggLTEuODE3MTg2QzIuNTk0MjcxIC0xLjgxNzE4NiAyLjU4MjMxNiAtMS43NTc0MSAyLjUzNDQ5NiAtMS41NzgwODJDMi4zMTkzMDMgLTAuNzUzMTc2IDIuMTA0MTEgLTAuMTE5NTUyIDEuNjI1OTAzIC0wLjExOTU1MkMxLjI2NzI0OCAtMC4xMTk1NTIgMS4yNjcyNDggLTAuNTAyMTE3IDEuMjY3MjQ4IC0wLjY2OTQ4OUMxLjI2NzI0OCAtMC43MTczMSAxLjI2NzI0OCAtMC45NjgzNjkgMS4zNTA5MzQgLTEuMzAzMTEzTDMuMDM2NjEzIC03Ljk5ODAwN1onIGlkPSdnMi0xMDgnLz4KPHBhdGggZD0nTTIuNDYyNzY1IC0zLjUwMjg2NEMyLjQ4NjY3NSAtMy41NzQ1OTUgMi43ODU1NTQgLTQuMTcyMzU0IDMuMjI3ODk1IC00LjU1NDkxOUMzLjUzODczIC00Ljg0MTg0MyAzLjk0NTIwNSAtNS4wMzMxMjYgNC40MTE0NTcgLTUuMDMzMTI2QzQuODg5NjY0IC01LjAzMzEyNiA1LjA1NzAzNiAtNC42NzQ0NzEgNS4wNTcwMzYgLTQuMTk2MjY0QzUuMDU3MDM2IC0zLjUxNDgxOSA0LjU2Njg3NCAtMi4xNTE5MyA0LjMyNzc3MSAtMS41MDYzNTFDNC4yMjAxNzQgLTEuMjE5NDI3IDQuMTYwMzk5IC0xLjA2NDAxIDQuMTYwMzk5IC0wLjg0ODgxN0M0LjE2MDM5OSAtMC4zMTA4MzQgNC41MzEwMDkgMC4xMTk1NTIgNS4xMDQ4NTcgMC4xMTk1NTJDNi4yMTY2ODcgMC4xMTk1NTIgNi42MzUxMTggLTEuNjM3ODU4IDYuNjM1MTE4IC0xLjcwOTU4OUM2LjYzNTExOCAtMS43NjkzNjUgNi41ODcyOTggLTEuODE3MTg2IDYuNTE1NTY3IC0xLjgxNzE4NkM2LjQwNzk3IC0xLjgxNzE4NiA2LjM5NjAxNSAtMS43ODEzMiA2LjMzNjIzOSAtMS41NzgwODJDNi4wNjEyNyAtMC41OTc3NTggNS42MDY5NzQgLTAuMTE5NTUyIDUuMTQwNzIyIC0wLjExOTU1MkM1LjAyMTE3MSAtMC4xMTk1NTIgNC44Mjk4ODggLTAuMTMxNTA3IDQuODI5ODg4IC0wLjUxNDA3MkM0LjgyOTg4OCAtMC44MTI5NTEgNC45NjEzOTUgLTEuMTcxNjA2IDUuMDMzMTI2IC0xLjMzODk3OUM1LjI3MjIyOSAtMS45OTY1MTMgNS43NzQzNDYgLTMuMzM1NDkyIDUuNzc0MzQ2IC00LjAxNjkzNkM1Ljc3NDM0NiAtNC43MzQyNDcgNS4zNTU5MTUgLTUuMjcyMjI5IDQuNDQ3MzIzIC01LjI3MjIyOUMzLjM4MzMxMyAtNS4yNzIyMjkgMi44MjE0MiAtNC41MTkwNTQgMi42MDYyMjcgLTQuMjIwMTc0QzIuNTcwMzYxIC00LjkwMTYxOSAyLjA4MDE5OSAtNS4yNzIyMjkgMS41NTQxNzIgLTUuMjcyMjI5QzEuMTcxNjA2IC01LjI3MjIyOSAwLjkwODU5MyAtNS4wNDUwODEgMC43MDUzNTUgLTQuNjM4NjA1QzAuNDkwMTYyIC00LjIwODIxOSAwLjMyMjc5IC0zLjQ5MDkwOSAwLjMyMjc5IC0zLjQ0MzA4OFMwLjM3MDYxIC0zLjMzNTQ5MiAwLjQ1NDI5NiAtMy4zMzU0OTJDMC41NDk5MzggLTMuMzM1NDkyIDAuNTYxODkzIC0zLjM0NzQ0NyAwLjYzMzYyNCAtMy42MjI0MTZDMC44MjQ5MDcgLTQuMzUxNjgxIDEuMDQwMSAtNS4wMzMxMjYgMS41MTgzMDYgLTUuMDMzMTI2QzEuNzkzMjc1IC01LjAzMzEyNiAxLjg4ODkxNyAtNC44NDE4NDMgMS44ODg5MTcgLTQuNDgzMTg4QzEuODg4OTE3IC00LjIyMDE3NCAxLjc2OTM2NSAtMy43NTM5MjMgMS42ODU2NzkgLTMuMzgzMzEzTDEuMzUwOTM0IC0yLjA5MjE1NEMxLjMwMzExMyAtMS44NjUwMDYgMS4xNzE2MDYgLTEuMzI3MDI0IDEuMTExODMxIC0xLjExMTgzMUMxLjAyODE0NCAtMC44MDA5OTYgMC44OTY2MzggLTAuMjM5MTAzIDAuODk2NjM4IC0wLjE3OTMyOEMwLjg5NjYzOCAtMC4wMTE5NTUgMS4wMjgxNDQgMC4xMTk1NTIgMS4yMDc0NzIgMC4xMTk1NTJDMS4zNTA5MzQgMC4xMTk1NTIgMS41MTgzMDYgMC4wNDc4MjEgMS42MTM5NDggLTAuMTMxNTA3QzEuNjM3ODU4IC0wLjE5MTI4MyAxLjc0NTQ1NSAtMC42MDk3MTQgMS44MDUyMyAtMC44NDg4MTdMMi4wNjgyNDQgLTEuOTI0NzgyTDIuNDYyNzY1IC0zLjUwMjg2NFonIGlkPSdnMi0xMTAnLz4KPHBhdGggZD0nTTUuMjcyMjI5IC01LjE1MjY3N0M1LjI3MjIyOSAtNS4yMTI0NTMgNS4yMjQ0MDggLTUuMjYwMjc0IDUuMTY0NjMzIC01LjI2MDI3NEM1LjA2ODk5MSAtNS4yNjAyNzQgNC42MDI3NCAtNC44Mjk4ODggNC4zNzU1OTIgLTQuNDExNDU3QzQuMTYwMzk5IC00Ljk0OTQ0IDMuNzg5Nzg4IC01LjI3MjIyOSAzLjI3NTcxNiAtNS4yNzIyMjlDMS45MjQ3ODIgLTUuMjcyMjI5IDAuNDY2MjUyIC0zLjUyNjc3NSAwLjQ2NjI1MiAtMS43NTc0MUMwLjQ2NjI1MiAtMC41NzM4NDggMS4xNTk2NTEgMC4xMTk1NTIgMS45NzI2MDMgMC4xMTk1NTJDMi42MDYyMjcgMC4xMTk1NTIgMy4xMzIyNTQgLTAuMzU4NjU1IDMuMzgzMzEzIC0wLjYzMzYyNEwzLjM5NTI2OCAtMC42MjE2NjlMMi45NDA5NzEgMS4xNzE2MDZMMi44MzMzNzUgMS42MDE5OTNDMi43MjU3NzggMS45NjA2NDggMi41NDY0NTEgMS45NjA2NDggMS45ODQ1NTggMS45NzI2MDNDMS44NTMwNTEgMS45NzI2MDMgMS43MzM0OTkgMS45NzI2MDMgMS43MzM0OTkgMi4xOTk3NTFDMS43MzM0OTkgMi4yODM0MzcgMS44MDUyMyAyLjMxOTMwMyAxLjg4ODkxNyAyLjMxOTMwM0MyLjA1NjI4OSAyLjMxOTMwMyAyLjI3MTQ4MiAyLjI5NTM5MiAyLjQzODg1NCAyLjI5NTM5MkgzLjY1ODI4MUMzLjgzNzYwOSAyLjI5NTM5MiA0LjA0MDg0NyAyLjMxOTMwMyA0LjIyMDE3NCAyLjMxOTMwM0M0LjI5MTkwNSAyLjMxOTMwMyA0LjQzNTM2NyAyLjMxOTMwMyA0LjQzNTM2NyAyLjA5MjE1NEM0LjQzNTM2NyAxLjk3MjYwMyA0LjMzOTcyNiAxLjk3MjYwMyA0LjE2MDM5OSAxLjk3MjYwM0MzLjU5ODUwNiAxLjk3MjYwMyAzLjU2MjY0IDEuODg4OTE3IDMuNTYyNjQgMS43OTMyNzVDMy41NjI2NCAxLjczMzQ5OSAzLjU3NDU5NSAxLjcyMTU0NCAzLjYxMDQ2MSAxLjU2NjEyN0w1LjI3MjIyOSAtNS4xNTI2NzdaTTMuNTg2NTUgLTEuNDIyNjY1QzMuNTI2Nzc1IC0xLjIxOTQyNyAzLjUyNjc3NSAtMS4xOTU1MTcgMy4zNTk0MDIgLTAuOTY4MzY5QzMuMDk2Mzg5IC0wLjYzMzYyNCAyLjU3MDM2MSAtMC4xMTk1NTIgMi4wMDg0NjggLTAuMTE5NTUyQzEuNTE4MzA2IC0wLjExOTU1MiAxLjI0MzMzNyAtMC41NjE4OTMgMS4yNDMzMzcgLTEuMjY3MjQ4QzEuMjQzMzM3IC0xLjkyNDc4MiAxLjYxMzk0OCAtMy4yNjM3NjEgMS44NDEwOTYgLTMuNzY1ODc4QzIuMjQ3NTcyIC00LjYwMjc0IDIuODA5NDY1IC01LjAzMzEyNiAzLjI3NTcxNiAtNS4wMzMxMjZDNC4wNjQ3NTcgLTUuMDMzMTI2IDQuMjIwMTc0IC00LjA1MjgwMiA0LjIyMDE3NCAtMy45NTcxNjFDNC4yMjAxNzQgLTMuOTQ1MjA1IDQuMTg0MzA5IC0zLjc4OTc4OCA0LjE3MjM1NCAtMy43NjU4NzhMMy41ODY1NSAtMS40MjI2NjVaJyBpZD0nZzItMTEzJy8+CjxwYXRoIGQ9J00yLjExMjA4IC0zLjc3NzgzM0MyLjE1MTkzIC0zLjg4MTQ0NSAyLjE4MzgxMSAtMy45MzcyMzUgMi4xODM4MTEgLTQuMDE2OTM2QzIuMTgzODExIC00LjI3OTk1IDEuOTQ0NzA3IC00LjQ1NTI5MyAxLjcyMTU0NCAtNC40NTUyOTNDMS40MDI3NCAtNC40NTUyOTMgMS4zMTUwNjggLTQuMTc2MzM5IDEuMjgzMTg4IC00LjA2NDc1N0wwLjI3MDk4NCAtMC42Mjk2MzlDMC4yMzkxMDMgLTAuNTMzOTk4IDAuMjM5MTAzIC0wLjUxMDA4NyAwLjIzOTEwMyAtMC41MDIxMTdDMC4yMzkxMDMgLTAuNDMwMzg2IDAuMjg2OTI0IC0wLjQxNDQ0NiAwLjM2NjYyNSAtMC4zOTA1MzVDMC41MTAwODcgLTAuMzI2Nzc1IDAuNTI2MDI3IC0wLjMyNjc3NSAwLjU0MTk2OCAtMC4zMjY3NzVDMC41NjU4NzggLTAuMzI2Nzc1IDAuNjEzNjk5IC0wLjMyNjc3NSAwLjY2OTQ4OSAtMC40NjIyNjdMMi4xMTIwOCAtMy43Nzc4MzNaJyBpZD0nZzAtNDgnLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzM4Ljg1NDI5NicgeGxpbms6aHJlZj0nI2cyLTgzJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc0Ni43NDk2MTknIHhsaW5rOmhyZWY9JyNnMC00OCcgeT0nNjEuNDE0OTg4Jy8+Cjx1c2UgeD0nNDkuNTQ0Njk1JyB4bGluazpocmVmPScjZzMtNDAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzU0LjA5NzAyMScgeGxpbms6aHJlZj0nI2cyLTExMycgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNTkuNzE2MTc3JyB4bGluazpocmVmPScjZzMtOTEnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzYyLjk2NzgzOScgeGxpbms6aHJlZj0nI2czLTQ5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc2OC44MjA4MjknIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNzIuMDcyNDknIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNzUuMzI0MTUxJyB4bGluazpocmVmPScjZzItMTA3JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc4MS44MTM2NTUnIHhsaW5rOmhyZWY9JyNnMy05MycgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nODUuMDY1MzE3JyB4bGluazpocmVmPScjZzMtNDEnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzkyLjkzODQ3MicgeGxpbms6aHJlZj0nI2czLTYxJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMDUuMzYzOTUzJyB4bGluazpocmVmPScjZzEtMTAyJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMTEuMzQxNTUyJyB4bGluazpocmVmPScjZzItMTEzJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMTYuOTYwNzA4JyB4bGluazpocmVmPScjZzMtOTEnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEyMC4yMTIzNycgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTI5LjM1ODUzNycgeGxpbms6aHJlZj0nI2czLTQzJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxNDEuMTE5ODUyJyB4bGluazpocmVmPScjZzMtNDknIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE0Ni45NzI4NDInIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTUwLjIyNDUwNCcgeGxpbms6aHJlZj0nI2cyLTU4JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxNTMuNDc2MTY1JyB4bGluazpocmVmPScjZzItMTA4JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxNTcuMjI1OTczJyB4bGluazpocmVmPScjZzItMTAxJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxNjIuNjUxNDE0JyB4bGluazpocmVmPScjZzItMTEwJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxNjkuNjM5MDE5JyB4bGluazpocmVmPScjZzMtNDAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE3NC4xOTEzNDUnIHhsaW5rOmhyZWY9JyNnMi0xMTMnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE3OS44MTA1MDEnIHhsaW5rOmhyZWY9JyNnMy00MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTg0LjM2MjgyNycgeGxpbms6aHJlZj0nI2czLTkzJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxOTAuOTM1MzE4JyB4bGluazpocmVmPScjZzEtNTAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzIwMi4yMjYyODYnIHhsaW5rOmhyZWY9JyNnMi04MycgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMjEwLjEyMTYwOScgeGxpbms6aHJlZj0nI2cxLTEwMycgeT0nNjUuNzUzNDI1Jy8+CjwvZz4KPC9zdmc+) :
:
alors :
![\forall k, \; M'(q[1..k], S) = M'(q[k+1..l(q)], S'(q[1..k]) + M'(q[1..k], S)](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTIuMzUyODMycHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNjguNzIwMTg5IDgzLjQ4NzcwMiAzMjguODExMTg5IDEyLjM1MjgzMicgd2lkdGg9JzMyOC44MTExODlwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYgLTAuNTM3OTgzIDEuODE3MTg2IC0yLjk3NjgzN0MxLjgxNzE4NiAtNS4yOTYxMzkgMi4zNzkwNzggLTcuMjkyNjUzIDMuNzY1ODc4IC04LjcwMzM2MkMzLjg4NTQzIC04LjgxMDk1OSAzLjg4NTQzIC04LjgzNDg2OSAzLjg4NTQzIC04Ljg3MDczNUMzLjg4NTQzIC04Ljk0MjQ2NiAzLjgyNTY1NCAtOC45NjYzNzYgMy43Nzc4MzMgLTguOTY2Mzc2QzMuNjIyNDE2IC04Ljk2NjM3NiAyLjY0MjA5MiAtOC4xMDU2MDQgMi4wNTYyODkgLTYuOTMzOTk4QzEuNDQ2NTc1IC01LjcyNjUyNiAxLjE3MTYwNiAtNC40NDczMjMgMS4xNzE2MDYgLTIuOTc2ODM3QzEuMTcxNjA2IC0xLjkxMjgyNyAxLjMzODk3OSAtMC40OTAxNjIgMS45NjA2NDggMC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicgaWQ9J2czLTQwJy8+CjxwYXRoIGQ9J00zLjM3MTM1NyAtMi45NzY4MzdDMy4zNzEzNTcgLTMuODg1NDMgMy4yNTE4MDYgLTUuMzY3ODcgMi41ODIzMTYgLTYuNzU0NjdDMS44NzY5NjEgLTguMTg5MjkgMC44OTY2MzggLTguOTY2Mzc2IDAuNzY1MTMxIC04Ljk2NjM3NkMwLjcxNzMxIC04Ljk2NjM3NiAwLjY1NzUzNCAtOC45NDI0NjYgMC42NTc1MzQgLTguODcwNzM1QzAuNjU3NTM0IC04LjgzNDg2OSAwLjY1NzUzNCAtOC44MTA5NTkgMC44NjA3NzIgLTguNjA3NzIxQzIuMDU2Mjg5IC03LjQwMDI0OSAyLjcyNTc3OCAtNS40Mjc2NDYgMi43MjU3NzggLTIuOTg4NzkyQzIuNzI1Nzc4IC0wLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAwLjc3NzA4NiAyLjczNzczM0MwLjY1NzUzNCAyLjg0NTMzIDAuNjU3NTM0IDIuODY5MjQgMC42NTc1MzQgMi45MDUxMDZDMC42NTc1MzQgMi45NzY4MzcgMC43MTczMSAzLjAwMDc0NyAwLjc2NTEzMSAzLjAwMDc0N0MwLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAwLjk2ODM2OUMzLjA5NjM4OSAtMC4yNTEwNTkgMy4zNzEzNTcgLTEuNTQyMjE3IDMuMzcxMzU3IC0yLjk3NjgzN1onIGlkPSdnMy00MScvPgo8cGF0aCBkPSdNNC43NzAxMTIgLTIuNzYxNjQ0SDguMDY5NzM4QzguMjM3MTExIC0yLjc2MTY0NCA4LjQ1MjMwNCAtMi43NjE2NDQgOC40NTIzMDQgLTIuOTc2ODM3QzguNDUyMzA0IC0zLjIwMzk4NSA4LjI0OTA2NiAtMy4yMDM5ODUgOC4wNjk3MzggLTMuMjAzOTg1SDQuNzcwMTEyVi02LjUwMzYxMUM0Ljc3MDExMiAtNi42NzA5ODQgNC43NzAxMTIgLTYuODg2MTc3IDQuNTU0OTE5IC02Ljg4NjE3N0M0LjMyNzc3MSAtNi44ODYxNzcgNC4zMjc3NzEgLTYuNjgyOTM5IDQuMzI3NzcxIC02LjUwMzYxMVYtMy4yMDM5ODVIMS4wMjgxNDRDMC44NjA3NzIgLTMuMjAzOTg1IDAuNjQ1NTc5IC0zLjIwMzk4NSAwLjY0NTU3OSAtMi45ODg3OTJDMC42NDU1NzkgLTIuNzYxNjQ0IDAuODQ4ODE3IC0yLjc2MTY0NCAxLjAyODE0NCAtMi43NjE2NDRINC4zMjc3NzFWMC41Mzc5ODNDNC4zMjc3NzEgMC43MDUzNTUgNC4zMjc3NzEgMC45MjA1NDggNC41NDI5NjQgMC45MjA1NDhDNC43NzAxMTIgMC45MjA1NDggNC43NzAxMTIgMC43MTczMSA0Ljc3MDExMiAwLjUzNzk4M1YtMi43NjE2NDRaJyBpZD0nZzMtNDMnLz4KPHBhdGggZD0nTTMuNDQzMDg4IC03LjY2MzI2M0MzLjQ0MzA4OCAtNy45MzgyMzIgMy40NDMwODggLTcuOTUwMTg3IDMuMjAzOTg1IC03Ljk1MDE4N0MyLjkxNzA2MSAtNy42MjczOTcgMi4zMTkzMDMgLTcuMTg1MDU2IDEuMDg3OTIgLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OSAtNi44MzgzNTYgMS45NjA2NDggLTYuODM4MzU2IDIuNjE4MTgyIC03LjE0OTE5MVYtMC45MjA1NDhDMi42MTgxODIgLTAuNDkwMTYyIDIuNTgyMzE2IC0wLjM0NjcgMS41MzAyNjIgLTAuMzQ2N0gxLjE1OTY1MVYwQzEuNDgyNDQxIC0wLjAyMzkxIDIuNjQyMDkyIC0wLjAyMzkxIDMuMDM2NjEzIC0wLjAyMzkxUzQuNTc4ODI5IC0wLjAyMzkxIDQuOTAxNjE5IDBWLTAuMzQ2N0g0LjUzMTAwOUMzLjQ3ODk1NCAtMC4zNDY3IDMuNDQzMDg4IC0wLjQ5MDE2MiAzLjQ0MzA4OCAtMC45MjA1NDhWLTcuNjYzMjYzWicgaWQ9J2czLTQ5Jy8+CjxwYXRoIGQ9J004LjA2OTczOCAtMy44NzM0NzRDOC4yMzcxMTEgLTMuODczNDc0IDguNDUyMzA0IC0zLjg3MzQ3NCA4LjQ1MjMwNCAtNC4wODg2NjdDOC40NTIzMDQgLTQuMzE1ODE2IDguMjQ5MDY2IC00LjMxNTgxNiA4LjA2OTczOCAtNC4zMTU4MTZIMS4wMjgxNDRDMC44NjA3NzIgLTQuMzE1ODE2IDAuNjQ1NTc5IC00LjMxNTgxNiAwLjY0NTU3OSAtNC4xMDA2MjNDMC42NDU1NzkgLTMuODczNDc0IDAuODQ4ODE3IC0zLjg3MzQ3NCAxLjAyODE0NCAtMy44NzM0NzRIOC4wNjk3MzhaTTguMDY5NzM4IC0xLjY0OTgxM0M4LjIzNzExMSAtMS42NDk4MTMgOC40NTIzMDQgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjg2NTAwNkM4LjQ1MjMwNCAtMi4wOTIxNTQgOC4yNDkwNjYgLTIuMDkyMTU0IDguMDY5NzM4IC0yLjA5MjE1NEgxLjAyODE0NEMwLjg2MDc3MiAtMi4wOTIxNTQgMC42NDU1NzkgLTIuMDkyMTU0IDAuNjQ1NTc5IC0xLjg3Njk2MUMwLjY0NTU3OSAtMS42NDk4MTMgMC44NDg4MTcgLTEuNjQ5ODEzIDEuMDI4MTQ0IC0xLjY0OTgxM0g4LjA2OTczOFonIGlkPSdnMy02MScvPgo8cGF0aCBkPSdNMi45ODg3OTIgMi45ODg3OTJWMi41NDY0NTFIMS44MjkxNDFWLTguNTI0MDM1SDIuOTg4NzkyVi04Ljk2NjM3NkgxLjM4NjhWMi45ODg3OTJIMi45ODg3OTJaJyBpZD0nZzMtOTEnLz4KPHBhdGggZD0nTTEuODUzMDUxIC04Ljk2NjM3NkgwLjI1MTA1OVYtOC41MjQwMzVIMS40MTA3MVYyLjU0NjQ1MUgwLjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJyBpZD0nZzMtOTMnLz4KPHBhdGggZD0nTTYuNTg3Mjk4IC03Ljg0MjU5QzYuNjQ3MDczIC03Ljk3NDA5NyA2LjY0NzA3MyAtNy45OTgwMDcgNi42NDcwNzMgLTguMDU3NzgzQzYuNjQ3MDczIC04LjE3NzMzNSA2LjU1MTQzMiAtOC4yOTY4ODcgNi40MDc5NyAtOC4yOTY4ODdDNi4yNTI1NTMgLTguMjk2ODg3IDYuMTgwODIyIC04LjE1MzQyNSA2LjEzMzAwMSAtOC4wMjE5MThMNS4xNDA3MjIgLTUuMzkxNzgxSDEuNTA2MzUxTDAuNTE0MDcyIC04LjAyMTkxOEMwLjQ1NDI5NiAtOC4xODkyOSAwLjM5NDUyMSAtOC4yOTY4ODcgMC4yMzkxMDMgLTguMjk2ODg3QzAuMTE5NTUyIC04LjI5Njg4NyAwIC04LjE3NzMzNSAwIC04LjA1Nzc4M0MwIC04LjAzMzg3MyAwIC04LjAwOTk2MyAwLjA3MTczMSAtNy44NDI1OUwzLjA0ODU2OCAtMC4wMTE5NTVDMy4xMDgzNDQgMC4xNTU0MTcgMy4xNjgxMiAwLjI2MzAxNCAzLjMyMzUzNyAwLjI2MzAxNEMzLjQ5MDkwOSAwLjI2MzAxNCAzLjUzODczIDAuMTMxNTA3IDMuNTg2NTUgMC4wMTE5NTVMNi41ODcyOTggLTcuODQyNTlaTTEuNjk3NjM0IC00LjkxMzU3NEg0Ljk0OTQ0TDMuMzIzNTM3IC0wLjY1NzUzNEwxLjY5NzYzNCAtNC45MTM1NzRaJyBpZD0nZzEtNTYnLz4KPHBhdGggZD0nTTIuMTEyMDggLTMuNzc3ODMzQzIuMTUxOTMgLTMuODgxNDQ1IDIuMTgzODExIC0zLjkzNzIzNSAyLjE4MzgxMSAtNC4wMTY5MzZDMi4xODM4MTEgLTQuMjc5OTUgMS45NDQ3MDcgLTQuNDU1MjkzIDEuNzIxNTQ0IC00LjQ1NTI5M0MxLjQwMjc0IC00LjQ1NTI5MyAxLjMxNTA2OCAtNC4xNzYzMzkgMS4yODMxODggLTQuMDY0NzU3TDAuMjcwOTg0IC0wLjYyOTYzOUMwLjIzOTEwMyAtMC41MzM5OTggMC4yMzkxMDMgLTAuNTEwMDg3IDAuMjM5MTAzIC0wLjUwMjExN0MwLjIzOTEwMyAtMC40MzAzODYgMC4yODY5MjQgLTAuNDE0NDQ2IDAuMzY2NjI1IC0wLjM5MDUzNUMwLjUxMDA4NyAtMC4zMjY3NzUgMC41MjYwMjcgLTAuMzI2Nzc1IDAuNTQxOTY4IC0wLjMyNjc3NUMwLjU2NTg3OCAtMC4zMjY3NzUgMC42MTM2OTkgLTAuMzI2Nzc1IDAuNjY5NDg5IC0wLjQ2MjI2N0wyLjExMjA4IC0zLjc3NzgzM1onIGlkPSdnMC00OCcvPgo8cGF0aCBkPSdNMi4xOTk3NTEgLTAuNTczODQ4QzIuMTk5NzUxIC0wLjkyMDU0OCAxLjkxMjgyNyAtMS4xNTk2NTEgMS42MjU5MDMgLTEuMTU5NjUxQzEuMjc5MjAzIC0xLjE1OTY1MSAxLjA0MDEgLTAuODcyNzI3IDEuMDQwMSAtMC41ODU4MDNDMS4wNDAxIC0wLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MSAtMC4yODY5MjQgMi4xOTk3NTEgLTAuNTczODQ4WicgaWQ9J2cyLTU4Jy8+CjxwYXRoIGQ9J00yLjMzMTI1OCAwLjA0NzgyMUMyLjMzMTI1OCAtMC42NDU1NzkgMi4xMDQxMSAtMS4xNTk2NTEgMS42MTM5NDggLTEuMTU5NjUxQzEuMjMxMzgyIC0xLjE1OTY1MSAxLjA0MDEgLTAuODQ4ODE3IDEuMDQwMSAtMC41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNyAtMC4wNDc4MjEgMi4wMjA0MjMgLTAuMTU1NDE3QzIuMDQ0MzM0IC0wLjE3OTMyOCAyLjA1NjI4OSAtMC4xNzkzMjggMi4wNjgyNDQgLTAuMTc5MzI4QzIuMDkyMTU0IC0wLjE3OTMyOCAyLjA5MjE1NCAtMC4wMTE5NTUgMi4wOTIxNTQgMC4wNDc4MjFDMi4wOTIxNTQgMC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAwLjA0NzgyMVonIGlkPSdnMi01OScvPgo8cGF0aCBkPSdNMTAuODU1MjkzIC03LjI5MjY1M0MxMC45NjI4ODkgLTcuNjk5MTI4IDEwLjk4NjggLTcuODE4NjggMTEuODM1NjE2IC03LjgxODY4QzEyLjA2Mjc2NSAtNy44MTg2OCAxMi4xNzAzNjEgLTcuODE4NjggMTIuMTcwMzYxIC04LjA0NTgyOEMxMi4xNzAzNjEgLTguMTY1MzggMTIuMDg2Njc1IC04LjE2NTM4IDExLjg1OTUyNyAtOC4xNjUzOEgxMC40MjQ5MDdDMTAuMTI2MDI3IC04LjE2NTM4IDEwLjExNDA3MiAtOC4xNTM0MjUgOS45ODI1NjUgLTcuOTYyMTQyTDUuNjE4OTI5IC0xLjA2NDAxTDQuNzIyMjkxIC03LjkwMjM2NkM0LjY4NjQyNiAtOC4xNjUzOCA0LjY3NDQ3MSAtOC4xNjUzOCA0LjM2MzYzNiAtOC4xNjUzOEgyLjg4MTE5NkMyLjY1NDA0NyAtOC4xNjUzOCAyLjU0NjQ1MSAtOC4xNjUzOCAyLjU0NjQ1MSAtNy45MzgyMzJDMi41NDY0NTEgLTcuODE4NjggMi42NTQwNDcgLTcuODE4NjggMi44MzMzNzUgLTcuODE4NjhDMy41NjI2NCAtNy44MTg2OCAzLjU2MjY0IC03LjcyMzAzOSAzLjU2MjY0IC03LjU5MTUzMkMzLjU2MjY0IC03LjU2NzYyMSAzLjU2MjY0IC03LjQ5NTg5IDMuNTE0ODE5IC03LjMxNjU2M0wxLjk4NDU1OCAtMS4yMTk0MjdDMS44NDEwOTYgLTAuNjQ1NTc5IDEuNTY2MTI3IC0wLjM4MjU2NSAwLjc2NTEzMSAtMC4zNDY3QzAuNzI5MjY1IC0wLjM0NjcgMC41ODU4MDMgLTAuMzM0NzQ1IDAuNTg1ODAzIC0wLjEzMTUwN0MwLjU4NTgwMyAwIDAuNjkzNCAwIDAuNzQxMjIgMEMwLjk4MDMyNCAwIDEuNTkwMDM3IC0wLjAyMzkxIDEuODI5MTQxIC0wLjAyMzkxSDIuNDAyOTg5QzIuNTcwMzYxIC0wLjAyMzkxIDIuNzczNTk5IDAgMi45NDA5NzEgMEMzLjAyNDY1OCAwIDMuMTU2MTY0IDAgMy4xNTYxNjQgLTAuMjI3MTQ4QzMuMTU2MTY0IC0wLjMzNDc0NSAzLjAzNjYxMyAtMC4zNDY3IDIuOTg4NzkyIC0wLjM0NjdDMi41OTQyNzEgLTAuMzU4NjU1IDIuMjExNzA2IC0wLjQzMDM4NiAyLjIxMTcwNiAtMC44NjA3NzJDMi4yMTE3MDYgLTAuOTgwMzI0IDIuMjExNzA2IC0wLjk5MjI3OSAyLjI1OTUyNyAtMS4xNTk2NTFMMy45MDkzNCAtNy43NDY5NDlIMy45MjEyOTVMNC45MTM1NzQgLTAuMzIyNzlDNC45NDk0NCAtMC4wMzU4NjYgNC45NjEzOTUgMCA1LjA2ODk5MSAwQzUuMjAwNDk4IDAgNS4yNjAyNzQgLTAuMDk1NjQxIDUuMzIwMDUgLTAuMjAzMjM4TDEwLjEyNjAyNyAtNy44MDY3MjVIMTAuMTM3OTgzTDguNDA0NDgzIC0wLjg4NDY4MkM4LjI5Njg4NyAtMC40NjYyNTIgOC4yNzI5NzYgLTAuMzQ2NyA3LjQzNjExNSAtMC4zNDY3QzcuMjA4OTY2IC0wLjM0NjcgNy4wODk0MTUgLTAuMzQ2NyA3LjA4OTQxNSAtMC4xMzE1MDdDNy4wODk0MTUgMCA3LjE5NzAxMSAwIDcuMjY4NzQyIDBDNy40NzE5OCAwIDcuNzExMDgzIC0wLjAyMzkxIDcuOTE0MzIxIC0wLjAyMzkxSDkuMzI1MDMxQzkuNTI4MjY5IC0wLjAyMzkxIDkuNzc5MzI4IDAgOS45ODI1NjUgMEMxMC4wNzgyMDcgMCAxMC4yMDk3MTQgMCAxMC4yMDk3MTQgLTAuMjI3MTQ4QzEwLjIwOTcxNCAtMC4zNDY3IDEwLjEwMjExNyAtMC4zNDY3IDkuOTIyNzkgLTAuMzQ2N0M5LjE5MzUyNCAtMC4zNDY3IDkuMTkzNTI0IC0wLjQ0MjM0MSA5LjE5MzUyNCAtMC41NjE4OTNDOS4xOTM1MjQgLTAuNTczODQ4IDkuMTkzNTI0IC0wLjY1NzUzNCA5LjIxNzQzNSAtMC43NTMxNzZMMTAuODU1MjkzIC03LjI5MjY1M1onIGlkPSdnMi03NycvPgo8cGF0aCBkPSdNNy41OTE1MzIgLTguMzA4ODQyQzcuNTkxNTMyIC04LjQxNjQzOCA3LjUwNzg0NiAtOC40MTY0MzggNy40ODM5MzUgLTguNDE2NDM4QzcuNDM2MTE1IC04LjQxNjQzOCA3LjQyNDE1OSAtOC40MDQ0ODMgNy4yODA2OTcgLTguMjI1MTU2QzcuMjA4OTY2IC04LjE0MTQ2OSA2LjcxODgwNCAtNy41MTk4MDEgNi43MDY4NDkgLTcuNTA3ODQ2QzYuMzEyMzI5IC04LjI4NDkzMiA1LjUyMzI4OCAtOC40MTY0MzggNS4wMjExNzEgLTguNDE2NDM4QzMuNTAyODY0IC04LjQxNjQzOCAyLjEyODAyIC03LjAyOTYzOSAyLjEyODAyIC01LjY3ODcwNUMyLjEyODAyIC00Ljc4MjA2NyAyLjY2NjAwMiAtNC4yNTYwNCAzLjI1MTgwNiAtNC4wNTI4MDJDMy4zODMzMTMgLTQuMDA0OTgxIDQuMDg4NjY3IC0zLjgxMzY5OSA0LjQ0NzMyMyAtMy43MzAwMTJDNS4wNTcwMzYgLTMuNTYyNjQgNS4yMTI0NTMgLTMuNTE0ODE5IDUuNDYzNTEyIC0zLjI1MTgwNkM1LjUxMTMzMyAtMy4xOTIwMyA1Ljc1MDQzNiAtMi45MTcwNjEgNS43NTA0MzYgLTIuMzU1MTY4QzUuNzUwNDM2IC0xLjI0MzMzNyA0LjcyMjI5MSAtMC4wOTU2NDEgMy41MjY3NzUgLTAuMDk1NjQxQzIuNTQ2NDUxIC0wLjA5NTY0MSAxLjQ1ODUzMSAtMC41MTQwNzIgMS40NTg1MzEgLTEuODUzMDUxQzEuNDU4NTMxIC0yLjA4MDE5OSAxLjUwNjM1MSAtMi4zNjcxMjMgMS41NDIyMTcgLTIuNDg2Njc1QzEuNTQyMjE3IC0yLjUyMjU0IDEuNTU0MTcyIC0yLjU4MjMxNiAxLjU1NDE3MiAtMi42MDYyMjdDMS41NTQxNzIgLTIuNjU0MDQ3IDEuNTMwMjYyIC0yLjcxMzgyMyAxLjQzNDYyIC0yLjcxMzgyM0MxLjMyNzAyNCAtMi43MTM4MjMgMS4zMTUwNjggLTIuNjg5OTEzIDEuMjY3MjQ4IC0yLjQ4NjY3NUwwLjY1NzUzNCAtMC4wMzU4NjZDMC42NTc1MzQgLTAuMDIzOTEgMC42MDk3MTQgMC4xMzE1MDcgMC42MDk3MTQgMC4xNDM0NjJDMC42MDk3MTQgMC4yNTEwNTkgMC43MDUzNTUgMC4yNTEwNTkgMC43MjkyNjUgMC4yNTEwNTlDMC43NzcwODYgMC4yNTEwNTkgMC43ODkwNDEgMC4yMzkxMDMgMC45MzI1MDMgMC4wNTk3NzZMMS40ODI0NDEgLTAuNjU3NTM0QzEuNzY5MzY1IC0wLjIyNzE0OCAyLjM5MTAzNCAwLjI1MTA1OSAzLjUwMjg2NCAwLjI1MTA1OUM1LjA0NTA4MSAwLjI1MTA1OSA2LjQ1NTc5MSAtMS4yNDMzMzcgNi40NTU3OTEgLTIuNzM3NzMzQzYuNDU1NzkxIC0zLjIzOTg1MSA2LjMzNjIzOSAtMy42ODIxOTIgNS44ODE5NDMgLTQuMTI0NTMzQzUuNjMwODg0IC00LjM3NTU5MiA1LjQxNTY5MSAtNC40MzUzNjcgNC4zMTU4MTYgLTQuNzIyMjkxQzMuNTE0ODE5IC00LjkzNzQ4NCAzLjQwNzIyMyAtNC45NzMzNSAzLjE5MjAzIC01LjE2NDYzM0MyLjk4ODc5MiAtNS4zNjc4NyAyLjgzMzM3NSAtNS42NTQ3OTUgMi44MzMzNzUgLTYuMDYxMjdDMi44MzMzNzUgLTcuMDY1NTA0IDMuODQ5NTY0IC04LjA5MzY0OSA0Ljk4NTMwNSAtOC4wOTM2NDlDNi4xNTY5MTIgLTguMDkzNjQ5IDYuNzA2ODQ5IC03LjM3NjMzOSA2LjcwNjg0OSAtNi4yNDA1OThDNi43MDY4NDkgLTUuOTI5NzYzIDYuNjQ3MDczIC01LjYwNjk3NCA2LjY0NzA3MyAtNS41NTkxNTNDNi42NDcwNzMgLTUuNDUxNTU3IDYuNzQyNzE1IC01LjQ1MTU1NyA2Ljc3ODU4IC01LjQ1MTU1N0M2Ljg4NjE3NyAtNS40NTE1NTcgNi44OTgxMzIgLTUuNDg3NDIyIDYuOTQ1OTUzIC01LjY3ODcwNUw3LjU5MTUzMiAtOC4zMDg4NDJaJyBpZD0nZzItODMnLz4KPHBhdGggZD0nTTMuMzU5NDAyIC03Ljk5ODAwN0MzLjM3MTM1NyAtOC4wNDU4MjggMy4zOTUyNjggLTguMTE3NTU5IDMuMzk1MjY4IC04LjE3NzMzNUMzLjM5NTI2OCAtOC4yOTY4ODcgMy4yNzU3MTYgLTguMjk2ODg3IDMuMjUxODA2IC04LjI5Njg4N0MzLjIzOTg1MSAtOC4yOTY4ODcgMi44MDk0NjUgLTguMjYxMDIxIDIuNTk0MjcxIC04LjIzNzExMUMyLjM5MTAzNCAtOC4yMjUxNTYgMi4yMTE3MDYgLTguMjAxMjQ1IDEuOTk2NTEzIC04LjE4OTI5QzEuNzA5NTg5IC04LjE2NTM4IDEuNjI1OTAzIC04LjE1MzQyNSAxLjYyNTkwMyAtNy45MzgyMzJDMS42MjU5MDMgLTcuODE4NjggMS43NDU0NTUgLTcuODE4NjggMS44NjUwMDYgLTcuODE4NjhDMi40NzQ3MiAtNy44MTg2OCAyLjQ3NDcyIC03LjcxMTA4MyAyLjQ3NDcyIC03LjU5MTUzMkMyLjQ3NDcyIC03LjU0MzcxMSAyLjQ3NDcyIC03LjUxOTgwMSAyLjQxNDk0NCAtNy4zMDQ2MDhMMC43MDUzNTUgLTAuNDY2MjUyQzAuNjU3NTM0IC0wLjI4NjkyNCAwLjY1NzUzNCAtMC4yNjMwMTQgMC42NTc1MzQgLTAuMTkxMjgzQzAuNjU3NTM0IDAuMDcxNzMxIDAuODYwNzcyIDAuMTE5NTUyIDAuOTgwMzI0IDAuMTE5NTUyQzEuMzE1MDY4IDAuMTE5NTUyIDEuMzg2OCAtMC4xNDM0NjIgMS40ODI0NDEgLTAuNTE0MDcyTDIuMDQ0MzM0IC0yLjc0OTY4OUMyLjkwNTEwNiAtMi42NTQwNDcgMy40MTkxNzggLTIuMjk1MzkyIDMuNDE5MTc4IC0xLjcyMTU0NEMzLjQxOTE3OCAtMS42NDk4MTMgMy40MTkxNzggLTEuNjAxOTkzIDMuMzgzMzEzIC0xLjQyMjY2NUMzLjMzNTQ5MiAtMS4yNDMzMzcgMy4zMzU0OTIgLTEuMDk5ODc1IDMuMzM1NDkyIC0xLjA0MDFDMy4zMzU0OTIgLTAuMzQ2NyAzLjc4OTc4OCAwLjExOTU1MiA0LjM5OTUwMiAwLjExOTU1MkM0Ljk0OTQ0IDAuMTE5NTUyIDUuMjM2MzY0IC0wLjM4MjU2NSA1LjMzMjAwNSAtMC41NDk5MzhDNS41ODMwNjQgLTAuOTkyMjc5IDUuNzM4NDgxIC0xLjY2MTc2OCA1LjczODQ4MSAtMS43MDk1ODlDNS43Mzg0ODEgLTEuNzY5MzY1IDUuNjkwNjYgLTEuODE3MTg2IDUuNjE4OTI5IC0xLjgxNzE4NkM1LjUxMTMzMyAtMS44MTcxODYgNS40OTkzNzcgLTEuNzY5MzY1IDUuNDUxNTU3IC0xLjU3ODA4MkM1LjI4NDE4NCAtMC45NTY0MTMgNS4wMzMxMjYgLTAuMTE5NTUyIDQuNDIzNDEyIC0wLjExOTU1MkM0LjE4NDMwOSAtMC4xMTk1NTIgNC4wMjg4OTIgLTAuMjM5MTAzIDQuMDI4ODkyIC0wLjY5MzRDNC4wMjg4OTIgLTAuOTIwNTQ4IDQuMDc2NzEyIC0xLjE4MzU2MiA0LjEyNDUzMyAtMS4zNjI4ODlDNC4xNzIzNTQgLTEuNTc4MDgyIDQuMTcyMzU0IC0xLjU5MDAzNyA0LjE3MjM1NCAtMS43MzM0OTlDNC4xNzIzNTQgLTIuNDM4ODU0IDMuNTM4NzMgLTIuODMzMzc1IDIuNDM4ODU0IC0yLjk3NjgzN0MyLjg2OTI0IC0zLjIzOTg1MSAzLjI5OTYyNiAtMy43MDYxMDIgMy40NjY5OTkgLTMuODg1NDNDNC4xNDg0NDMgLTQuNjUwNTYgNC42MTQ2OTUgLTUuMDMzMTI2IDUuMTY0NjMzIC01LjAzMzEyNkM1LjQzOTYwMSAtNS4wMzMxMjYgNS41MTEzMzMgLTQuOTYxMzk1IDUuNTk1MDE5IC00Ljg4OTY2NEM1LjE1MjY3NyAtNC44NDE4NDMgNC45ODUzMDUgLTQuNTMxMDA5IDQuOTg1MzA1IC00LjI5MTkwNUM0Ljk4NTMwNSAtNC4wMDQ5ODEgNS4yMTI0NTMgLTMuOTA5MzQgNS4zNzk4MjYgLTMuOTA5MzRDNS43MDI2MTUgLTMuOTA5MzQgNS45ODk1MzkgLTQuMTg0MzA5IDUuOTg5NTM5IC00LjU2Njg3NEM1Ljk4OTUzOSAtNC45MTM1NzQgNS43MTQ1NyAtNS4yNzIyMjkgNS4xNzY1ODggLTUuMjcyMjI5QzQuNTE5MDU0IC01LjI3MjIyOSAzLjk4MTA3MSAtNC44MDU5NzggMy4xMzIyNTQgLTMuODQ5NTY0QzMuMDEyNzAyIC0zLjcwNjEwMiAyLjU3MDM2MSAtMy4yNTE4MDYgMi4xMjgwMiAtMy4wODQ0MzNMMy4zNTk0MDIgLTcuOTk4MDA3WicgaWQ9J2cyLTEwNycvPgo8cGF0aCBkPSdNMy4wMzY2MTMgLTcuOTk4MDA3QzMuMDQ4NTY4IC04LjA0NTgyOCAzLjA3MjQ3OCAtOC4xMTc1NTkgMy4wNzI0NzggLTguMTc3MzM1QzMuMDcyNDc4IC04LjI5Njg4NyAyLjk1MjkyNyAtOC4yOTY4ODcgMi45MjkwMTYgLTguMjk2ODg3QzIuOTE3MDYxIC04LjI5Njg4NyAyLjQ4NjY3NSAtOC4yNjEwMjEgMi4yNzE0ODIgLTguMjM3MTExQzIuMDY4MjQ0IC04LjIyNTE1NiAxLjg4ODkxNyAtOC4yMDEyNDUgMS42NzM3MjQgLTguMTg5MjlDMS4zODY4IC04LjE2NTM4IDEuMzAzMTEzIC04LjE1MzQyNSAxLjMwMzExMyAtNy45MzgyMzJDMS4zMDMxMTMgLTcuODE4NjggMS40MjI2NjUgLTcuODE4NjggMS41NDIyMTcgLTcuODE4NjhDMi4xNTE5MyAtNy44MTg2OCAyLjE1MTkzIC03LjcxMTA4MyAyLjE1MTkzIC03LjU5MTUzMkMyLjE1MTkzIC03LjU0MzcxMSAyLjE1MTkzIC03LjUxOTgwMSAyLjA5MjE1NCAtNy4zMDQ2MDhMMC42MDk3MTQgLTEuMzc0ODQ0QzAuNTczODQ4IC0xLjI0MzMzNyAwLjU0OTkzOCAtMS4xNDc2OTYgMC41NDk5MzggLTAuOTU2NDEzQzAuNTQ5OTM4IC0wLjM1ODY1NSAwLjk5MjI3OSAwLjExOTU1MiAxLjYwMTk5MyAwLjExOTU1MkMxLjk5NjUxMyAwLjExOTU1MiAyLjI1OTUyNyAtMC4xNDM0NjIgMi40NTA4MDkgLTAuNTE0MDcyQzIuNjU0MDQ3IC0wLjkwODU5MyAyLjgyMTQyIC0xLjY2MTc2OCAyLjgyMTQyIC0xLjcwOTU4OUMyLjgyMTQyIC0xLjc2OTM2NSAyLjc3MzU5OSAtMS44MTcxODYgMi43MDE4NjggLTEuODE3MTg2QzIuNTk0MjcxIC0xLjgxNzE4NiAyLjU4MjMxNiAtMS43NTc0MSAyLjUzNDQ5NiAtMS41NzgwODJDMi4zMTkzMDMgLTAuNzUzMTc2IDIuMTA0MTEgLTAuMTE5NTUyIDEuNjI1OTAzIC0wLjExOTU1MkMxLjI2NzI0OCAtMC4xMTk1NTIgMS4yNjcyNDggLTAuNTAyMTE3IDEuMjY3MjQ4IC0wLjY2OTQ4OUMxLjI2NzI0OCAtMC43MTczMSAxLjI2NzI0OCAtMC45NjgzNjkgMS4zNTA5MzQgLTEuMzAzMTEzTDMuMDM2NjEzIC03Ljk5ODAwN1onIGlkPSdnMi0xMDgnLz4KPHBhdGggZD0nTTUuMjcyMjI5IC01LjE1MjY3N0M1LjI3MjIyOSAtNS4yMTI0NTMgNS4yMjQ0MDggLTUuMjYwMjc0IDUuMTY0NjMzIC01LjI2MDI3NEM1LjA2ODk5MSAtNS4yNjAyNzQgNC42MDI3NCAtNC44Mjk4ODggNC4zNzU1OTIgLTQuNDExNDU3QzQuMTYwMzk5IC00Ljk0OTQ0IDMuNzg5Nzg4IC01LjI3MjIyOSAzLjI3NTcxNiAtNS4yNzIyMjlDMS45MjQ3ODIgLTUuMjcyMjI5IDAuNDY2MjUyIC0zLjUyNjc3NSAwLjQ2NjI1MiAtMS43NTc0MUMwLjQ2NjI1MiAtMC41NzM4NDggMS4xNTk2NTEgMC4xMTk1NTIgMS45NzI2MDMgMC4xMTk1NTJDMi42MDYyMjcgMC4xMTk1NTIgMy4xMzIyNTQgLTAuMzU4NjU1IDMuMzgzMzEzIC0wLjYzMzYyNEwzLjM5NTI2OCAtMC42MjE2NjlMMi45NDA5NzEgMS4xNzE2MDZMMi44MzMzNzUgMS42MDE5OTNDMi43MjU3NzggMS45NjA2NDggMi41NDY0NTEgMS45NjA2NDggMS45ODQ1NTggMS45NzI2MDNDMS44NTMwNTEgMS45NzI2MDMgMS43MzM0OTkgMS45NzI2MDMgMS43MzM0OTkgMi4xOTk3NTFDMS43MzM0OTkgMi4yODM0MzcgMS44MDUyMyAyLjMxOTMwMyAxLjg4ODkxNyAyLjMxOTMwM0MyLjA1NjI4OSAyLjMxOTMwMyAyLjI3MTQ4MiAyLjI5NTM5MiAyLjQzODg1NCAyLjI5NTM5MkgzLjY1ODI4MUMzLjgzNzYwOSAyLjI5NTM5MiA0LjA0MDg0NyAyLjMxOTMwMyA0LjIyMDE3NCAyLjMxOTMwM0M0LjI5MTkwNSAyLjMxOTMwMyA0LjQzNTM2NyAyLjMxOTMwMyA0LjQzNTM2NyAyLjA5MjE1NEM0LjQzNTM2NyAxLjk3MjYwMyA0LjMzOTcyNiAxLjk3MjYwMyA0LjE2MDM5OSAxLjk3MjYwM0MzLjU5ODUwNiAxLjk3MjYwMyAzLjU2MjY0IDEuODg4OTE3IDMuNTYyNjQgMS43OTMyNzVDMy41NjI2NCAxLjczMzQ5OSAzLjU3NDU5NSAxLjcyMTU0NCAzLjYxMDQ2MSAxLjU2NjEyN0w1LjI3MjIyOSAtNS4xNTI2NzdaTTMuNTg2NTUgLTEuNDIyNjY1QzMuNTI2Nzc1IC0xLjIxOTQyNyAzLjUyNjc3NSAtMS4xOTU1MTcgMy4zNTk0MDIgLTAuOTY4MzY5QzMuMDk2Mzg5IC0wLjYzMzYyNCAyLjU3MDM2MSAtMC4xMTk1NTIgMi4wMDg0NjggLTAuMTE5NTUyQzEuNTE4MzA2IC0wLjExOTU1MiAxLjI0MzMzNyAtMC41NjE4OTMgMS4yNDMzMzcgLTEuMjY3MjQ4QzEuMjQzMzM3IC0xLjkyNDc4MiAxLjYxMzk0OCAtMy4yNjM3NjEgMS44NDEwOTYgLTMuNzY1ODc4QzIuMjQ3NTcyIC00LjYwMjc0IDIuODA5NDY1IC01LjAzMzEyNiAzLjI3NTcxNiAtNS4wMzMxMjZDNC4wNjQ3NTcgLTUuMDMzMTI2IDQuMjIwMTc0IC00LjA1MjgwMiA0LjIyMDE3NCAtMy45NTcxNjFDNC4yMjAxNzQgLTMuOTQ1MjA1IDQuMTg0MzA5IC0zLjc4OTc4OCA0LjE3MjM1NCAtMy43NjU4NzhMMy41ODY1NSAtMS40MjI2NjVaJyBpZD0nZzItMTEzJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc2OC43MjAxODknIHhsaW5rOmhyZWY9JyNnMS01NicgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nNzUuMzYxOTcnIHhsaW5rOmhyZWY9JyNnMi0xMDcnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzgxLjg1MTQ3NCcgeGxpbms6aHJlZj0nI2cyLTU5JyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PSc5MC40MTY0NjInIHhsaW5rOmhyZWY9JyNnMi03NycgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMTAyLjk5MDA2OScgeGxpbms6aHJlZj0nI2cwLTQ4JyB5PSc4Ny45MTU1NTYnLz4KPHVzZSB4PScxMDUuNzg1MTQ1JyB4bGluazpocmVmPScjZzMtNDAnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzExMC4zMzc0NycgeGxpbms6aHJlZj0nI2cyLTExMycgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMTE1Ljk1NjYyNycgeGxpbms6aHJlZj0nI2czLTkxJyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScxMTkuMjA4Mjg4JyB4bGluazpocmVmPScjZzMtNDknIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzEyNS4wNjEyNzgnIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMTI4LjMxMjk0JyB4bGluazpocmVmPScjZzItNTgnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzEzMS41NjQ2MDEnIHhsaW5rOmhyZWY9JyNnMi0xMDcnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzEzOC4wNTQxMDUnIHhsaW5rOmhyZWY9JyNnMy05MycgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMTQxLjMwNTc2NicgeGxpbms6aHJlZj0nI2cyLTU5JyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScxNDYuNTQ5OTI1JyB4bGluazpocmVmPScjZzItODMnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzE1NC40NDUyNDgnIHhsaW5rOmhyZWY9JyNnMy00MScgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMTYyLjMxODQwMycgeGxpbms6aHJlZj0nI2czLTYxJyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScxNzQuNzQzODg0JyB4bGluazpocmVmPScjZzItNzcnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzE4Ny4zMTc0OTEnIHhsaW5rOmhyZWY9JyNnMC00OCcgeT0nODcuOTE1NTU2Jy8+Cjx1c2UgeD0nMTkwLjExMjU2NycgeGxpbms6aHJlZj0nI2czLTQwJyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScxOTQuNjY0ODkzJyB4bGluazpocmVmPScjZzItMTEzJyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScyMDAuMjg0MDQ5JyB4bGluazpocmVmPScjZzMtOTEnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzIwMy41MzU3MScgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMjEyLjY4MTg3OCcgeGxpbms6aHJlZj0nI2czLTQzJyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScyMjQuNDQzMTkzJyB4bGluazpocmVmPScjZzMtNDknIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzIzMC4yOTYxODMnIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMjMzLjU0Nzg0NCcgeGxpbms6aHJlZj0nI2cyLTU4JyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScyMzYuNzk5NTA2JyB4bGluazpocmVmPScjZzItMTA4JyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScyNDAuNTQ5MzE0JyB4bGluazpocmVmPScjZzMtNDAnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzI0NS4xMDE2NCcgeGxpbms6aHJlZj0nI2cyLTExMycgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMjUwLjcyMDc5NicgeGxpbms6aHJlZj0nI2czLTQxJyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScyNTUuMjczMTIyJyB4bGluazpocmVmPScjZzMtOTMnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzI1OC41MjQ3ODMnIHhsaW5rOmhyZWY9JyNnMi01OScgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMjYzLjc2ODk0MicgeGxpbms6aHJlZj0nI2cyLTgzJyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScyNzEuNjY0MjY1JyB4bGluazpocmVmPScjZzAtNDgnIHk9Jzg3LjkxNTU1NicvPgo8dXNlIHg9JzI3NC40NTkzNDEnIHhsaW5rOmhyZWY9JyNnMy00MCcgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMjc5LjAxMTY2NycgeGxpbms6aHJlZj0nI2cyLTExMycgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMjg0LjYzMDgyMycgeGxpbms6aHJlZj0nI2czLTkxJyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PScyODcuODgyNDg0JyB4bGluazpocmVmPScjZzMtNDknIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzI5My43MzU0NzUnIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMjk2Ljk4NzEzNicgeGxpbms6aHJlZj0nI2cyLTU4JyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PSczMDAuMjM4Nzk3JyB4bGluazpocmVmPScjZzItMTA3JyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PSczMDYuNzI4MzAxJyB4bGluazpocmVmPScjZzMtOTMnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzMwOS45Nzk5NjMnIHhsaW5rOmhyZWY9JyNnMy00MScgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMzE3LjE4ODk1MicgeGxpbms6aHJlZj0nI2czLTQzJyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PSczMjguOTUwMjY3JyB4bGluazpocmVmPScjZzItNzcnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzM0MS41MjM4NzQnIHhsaW5rOmhyZWY9JyNnMC00OCcgeT0nODcuOTE1NTU2Jy8+Cjx1c2UgeD0nMzQ0LjMxODk1JyB4bGluazpocmVmPScjZzMtNDAnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzM0OC44NzEyNzUnIHhsaW5rOmhyZWY9JyNnMi0xMTMnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzM1NC40OTA0MzInIHhsaW5rOmhyZWY9JyNnMy05MScgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMzU3Ljc0MjA5MycgeGxpbms6aHJlZj0nI2czLTQ5JyB5PSc5Mi44NTE3NDInLz4KPHVzZSB4PSczNjMuNTk1MDgzJyB4bGluazpocmVmPScjZzItNTgnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzM2Ni44NDY3NDQnIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMzcwLjA5ODQwNicgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMzc2LjU4NzkxJyB4bGluazpocmVmPScjZzMtOTMnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzM3OS44Mzk1NzEnIHhsaW5rOmhyZWY9JyNnMi01OScgeT0nOTIuODUxNzQyJy8+Cjx1c2UgeD0nMzg1LjA4MzczJyB4bGluazpocmVmPScjZzItODMnIHk9JzkyLjg1MTc0MicvPgo8dXNlIHg9JzM5Mi45NzkwNTMnIHhsaW5rOmhyZWY9JyNnMy00MScgeT0nOTIuODUxNzQyJy8+CjwvZz4KPC9zdmc+)
Théorème T1 : Régression linéaire après Gram-Schmidt
Soit une matrice  avec
avec
 . Et un vecteur
. Et un vecteur  .
D’après l”algorithme de Gram-Schmidt,
il existe deux matrices telles que
.
D’après l”algorithme de Gram-Schmidt,
il existe deux matrices telles que
 ou
ou  .
.
 et
et  .
La matrice T est triangulaire supérieure
et vérifie
.
La matrice T est triangulaire supérieure
et vérifie  (
( est la matrice identité). Alors
est la matrice identité). Alors
 .
.
 est la solution du problème d’optimisation
est la solution du problème d’optimisation
 .
.
Théorème T1 : [Farago1993]_ 1
Les notations sont celles de l’algorithme précédent.
Il retourne le plus proche voisin  de
de
 inclus dans
inclus dans  .
Autrement dit,
.
Autrement dit,  .
.
Théorème T1 : convergence de la méthode de Newton
Soit une fonction continue  de classe
de classe  .
On suppose les hypothèses suivantes vérifiées :
.
On suppose les hypothèses suivantes vérifiées :
H1 :
 est un singleton
est un singletonH2 :
![\forall\varepsilon>0, \; \underset{\left| W-W^{\ast}\right|
>\varepsilon}{\inf}\left[ \left( W-W^{\ast}\right) ^{\prime}.\nabla
g\left( W\right) \right] >0](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMjAuMjAyMDI5cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU1LjUxNDAzNiAyMjEuODg5MzM1IDIwLjIwMjAyOScgd2lkdGg9JzIyMS44ODkzMzVwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNMi40MTQ5NDQgMTMuODU2MDRINC43MTAzMzZWMTMuMzc3ODMzSDIuODkzMTUxVjBINC43MTAzMzZWLTAuNDc4MjA3SDIuNDE0OTQ0VjEzLjg1NjA0WicgaWQ9J2cwLTInLz4KPHBhdGggZD0nTTIuNTU4NDA2IDEzLjg1NjA0Vi0wLjQ3ODIwN0gwLjI2MzAxNFYwSDIuMDgwMTk5VjEzLjM3NzgzM0gwLjI2MzAxNFYxMy44NTYwNEgyLjU1ODQwNlonIGlkPSdnMC0zJy8+CjxwYXRoIGQ9J00xLjY2MTc2OCAtMi43MjU3NzhDMi4wNDQzMzQgLTIuNTcwMzYxIDIuNDUwODA5IC0yLjU3MDM2MSAyLjY3Nzk1OCAtMi41NzAzNjFDMi45ODg3OTIgLTIuNTcwMzYxIDMuNjEwNDYxIC0yLjU3MDM2MSAzLjYxMDQ2MSAtMi45MTcwNjFDMy42MTA0NjEgLTMuMTMyMjU0IDMuMzgzMzEzIC0zLjIxNTk0IDIuNzczNTk5IC0zLjIxNTk0QzIuNDc0NzIgLTMuMjE1OTQgMi4xMTYwNjUgLTMuMTgwMDc1IDEuNjk3NjM0IC0zLjAwMDc0N0MxLjMyNzAyNCAtMy4xODAwNzUgMS4xODM1NjIgLTMuNDU1MDQ0IDEuMTgzNTYyIC0zLjcxODA1N0MxLjE4MzU2MiAtNC40NTkyNzggMi4zNTUxNjggLTQuODg5NjY0IDMuNDE5MTc4IC00Ljg4OTY2NEMzLjYyMjQxNiAtNC44ODk2NjQgNC4wNTI4MDIgLTQuODg5NjY0IDQuNTU0OTE5IC00LjUxOTA1NEM0LjYyNjY1IC00LjQ3MTIzMyA0LjY2MjUxNiAtNC40MzUzNjcgNC43NDYyMDIgLTQuNDM1MzY3QzQuODg5NjY0IC00LjQzNTM2NyA1LjA0NTA4MSAtNC41OTA3ODUgNS4wNDUwODEgLTQuNzM0MjQ3QzUuMDQ1MDgxIC00Ljk0OTQ0IDQuMzUxNjgxIC01LjQwMzczNiAzLjUyNjc3NSAtNS40MDM3MzZDMi4xODc3OTYgLTUuNDAzNzM2IDAuOTIwNTQ4IC00LjYwMjc0IDAuOTIwNTQ4IC0zLjcxODA1N0MwLjkyMDU0OCAtMy4yNzU3MTYgMS4yMDc0NzIgLTMuMDAwNzQ3IDEuNDEwNzEgLTIuODU3Mjg1QzAuNzE3MzEgLTIuNDYyNzY1IDAuMzEwODM0IC0xLjgxNzE4NiAwLjMxMDgzNCAtMS4yMzEzODJDMC4zMTA4MzQgLTAuNDA2NDc2IDEuMDUyMDU1IDAuMjUxMDU5IDIuMTk5NzUxIDAuMjUxMDU5QzMuNzc3ODMzIDAuMjUxMDU5IDQuNDExNDU3IC0wLjgwMDk5NiA0LjQxMTQ1NyAtMC45NjgzNjlDNC40MTE0NTcgLTEuMDI4MTQ0IDQuMzYzNjM2IC0xLjA3NTk2NSA0LjMwMzg2MSAtMS4wNzU5NjVTNC4yMjAxNzQgLTEuMDQwMSA0LjE3MjM1NCAtMC45NjgzNjlDNC4wNDA4NDcgLTAuNzQxMjIgMy43MzAwMTIgLTAuMjYzMDE0IDIuMzA3MzQ3IC0wLjI2MzAxNEMxLjU2NjEyNyAtMC4yNjMwMTQgMC41ODU4MDMgLTAuNDU0Mjk2IDAuNTg1ODAzIC0xLjMwMzExM0MwLjU4NTgwMyAtMS43MDk1ODkgMC44ODQ2ODIgLTIuMzE5MzAzIDEuNjYxNzY4IC0yLjcyNTc3OFpNMi4wMzIzNzkgLTIuODY5MjRDMi4zNTUxNjggLTIuOTc2ODM3IDIuNjY2MDAyIC0yLjk3NjgzNyAyLjc0OTY4OSAtMi45NzY4MzdDMy4wODQ0MzMgLTIuOTc2ODM3IDMuMTQ0MjA5IC0yLjk1MjkyNyAzLjMzNTQ5MiAtMi45MDUxMDZDMy4xMzIyNTQgLTIuODA5NDY1IDMuMTA4MzQ0IC0yLjgwOTQ2NSAyLjY3Nzk1OCAtMi44MDk0NjVDMi40NjI3NjUgLTIuODA5NDY1IDIuMjcxNDgyIC0yLjgwOTQ2NSAyLjAzMjM3OSAtMi44NjkyNFonIGlkPSdnNS0zNCcvPgo8cGF0aCBkPSdNMi4xOTk3NTEgLTAuNTczODQ4QzIuMTk5NzUxIC0wLjkyMDU0OCAxLjkxMjgyNyAtMS4xNTk2NTEgMS42MjU5MDMgLTEuMTU5NjUxQzEuMjc5MjAzIC0xLjE1OTY1MSAxLjA0MDEgLTAuODcyNzI3IDEuMDQwMSAtMC41ODU4MDNDMS4wNDAxIC0wLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MSAtMC4yODY5MjQgMi4xOTk3NTEgLTAuNTczODQ4WicgaWQ9J2c1LTU4Jy8+CjxwYXRoIGQ9J00yLjMzMTI1OCAwLjA0NzgyMUMyLjMzMTI1OCAtMC42NDU1NzkgMi4xMDQxMSAtMS4xNTk2NTEgMS42MTM5NDggLTEuMTU5NjUxQzEuMjMxMzgyIC0xLjE1OTY1MSAxLjA0MDEgLTAuODQ4ODE3IDEuMDQwMSAtMC41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNyAtMC4wNDc4MjEgMi4wMjA0MjMgLTAuMTU1NDE3QzIuMDQ0MzM0IC0wLjE3OTMyOCAyLjA1NjI4OSAtMC4xNzkzMjggMi4wNjgyNDQgLTAuMTc5MzI4QzIuMDkyMTU0IC0wLjE3OTMyOCAyLjA5MjE1NCAtMC4wMTE5NTUgMi4wOTIxNTQgMC4wNDc4MjFDMi4wOTIxNTQgMC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAwLjA0NzgyMVonIGlkPSdnNS01OScvPgo8cGF0aCBkPSdNNy44Nzg0NTYgLTIuNzI1Nzc4QzguMTA1NjA0IC0yLjgzMzM3NSA4LjExNzU1OSAtMi45MDUxMDYgOC4xMTc1NTkgLTIuOTg4NzkyQzguMTE3NTU5IC0zLjA2MDUyMyA4LjA5MzY0OSAtMy4xNDQyMDkgNy44Nzg0NTYgLTMuMjM5ODUxTDEuNDEwNzEgLTYuMjE2Njg3QzEuMjU1MjkzIC02LjI4ODQxOCAxLjIzMTM4MiAtNi4zMDAzNzQgMS4yMDc0NzIgLTYuMzAwMzc0QzEuMDY0MDEgLTYuMzAwMzc0IDAuOTgwMzI0IC02LjE4MDgyMiAwLjk4MDMyNCAtNi4wODUxODFDMC45ODAzMjQgLTUuOTQxNzE5IDEuMDc1OTY1IC01Ljg5Mzg5OCAxLjIzMTM4MiAtNS44MjIxNjdMNy4zNzYzMzkgLTIuOTg4NzkyTDEuMjE5NDI3IC0wLjE0MzQ2MkMwLjk4MDMyNCAtMC4wMzU4NjYgMC45ODAzMjQgMC4wNDc4MjEgMC45ODAzMjQgMC4xMTk1NTJDMC45ODAzMjQgMC4yMTUxOTMgMS4wNjQwMSAwLjMzNDc0NSAxLjIwNzQ3MiAwLjMzNDc0NUMxLjIzMTM4MiAwLjMzNDc0NSAxLjI0MzMzNyAwLjMyMjc5IDEuNDEwNzEgMC4yNTEwNTlMNy44Nzg0NTYgLTIuNzI1Nzc4WicgaWQ9J2c1LTYyJy8+CjxwYXRoIGQ9J00xMC43OTU1MTcgLTYuODM4MzU2QzExLjA3MDQ4NiAtNy4zMDQ2MDggMTEuMzMzNDk5IC03Ljc0Njk0OSAxMi4wNTA4MDkgLTcuODE4NjhDMTIuMTU4NDA2IC03LjgzMDYzNSAxMi4yNjYwMDIgLTcuODQyNTkgMTIuMjY2MDAyIC04LjAzMzg3M0MxMi4yNjYwMDIgLTguMTY1MzggMTIuMTU4NDA2IC04LjE2NTM4IDEyLjEyMjU0IC04LjE2NTM4QzEyLjA5ODYzIC04LjE2NTM4IDEyLjAxNDk0NCAtOC4xNDE0NjkgMTEuMjI1OTAzIC04LjE0MTQ2OUMxMC44NjcyNDggLTguMTQxNDY5IDEwLjQ5NjYzOCAtOC4xNjUzOCAxMC4xNDk5MzggLTguMTY1MzhDMTAuMDc4MjA3IC04LjE2NTM4IDkuOTM0NzQ1IC04LjE2NTM4IDkuOTM0NzQ1IC03LjkzODIzMkM5LjkzNDc0NSAtNy44MzA2MzUgMTAuMDMwMzg2IC03LjgxODY4IDEwLjEwMjExNyAtNy44MTg2OEMxMC4zNDEyMiAtNy44MDY3MjUgMTAuNzIzNzg2IC03LjczNDk5NCAxMC43MjM3ODYgLTcuMzY0Mzg0QzEwLjcyMzc4NiAtNy4yMDg5NjYgMTAuNjc1OTY1IC03LjEyNTI4IDEwLjU1NjQxMyAtNi45MjIwNDJMNy4yOTI2NTMgLTEuMjA3NDcyTDYuODYyMjY3IC03LjQzNjExNUM2Ljg2MjI2NyAtNy41Nzk1NzcgNi45OTM3NzMgLTcuODA2NzI1IDcuNjYzMjYzIC03LjgxODY4QzcuODE4NjggLTcuODE4NjggNy45MzgyMzIgLTcuODE4NjggNy45MzgyMzIgLTguMDQ1ODI4QzcuOTM4MjMyIC04LjE2NTM4IDcuODE4NjggLTguMTY1MzggNy43NTg5MDQgLTguMTY1MzhDNy4zNDA0NzMgLTguMTY1MzggNi44OTgxMzIgLTguMTQxNDY5IDYuNDY3NzQ2IC04LjE0MTQ2OUg1Ljg0NjA3N0M1LjY2Njc1IC04LjE0MTQ2OSA1LjQ1MTU1NyAtOC4xNjUzOCA1LjI3MjIyOSAtOC4xNjUzOEM1LjIwMDQ5OCAtOC4xNjUzOCA1LjA1NzAzNiAtOC4xNjUzOCA1LjA1NzAzNiAtNy45MzgyMzJDNS4wNTcwMzYgLTcuODE4NjggNS4xNDA3MjIgLTcuODE4NjggNS4zNDM5NiAtNy44MTg2OEM1Ljg5Mzg5OCAtNy44MTg2OCA1Ljg5Mzg5OCAtNy44MDY3MjUgNS45NDE3MTkgLTcuMDc3NDZMNS45Nzc1ODQgLTYuNjQ3MDczTDIuODgxMTk2IC0xLjIwNzQ3MkwyLjQzODg1NCAtNy4zNzYzMzlDMi40Mzg4NTQgLTcuNTA3ODQ2IDIuNDM4ODU0IC03LjgwNjcyNSAzLjI1MTgwNiAtNy44MTg2OEMzLjM4MzMxMyAtNy44MTg2OCAzLjUxNDgxOSAtNy44MTg2OCAzLjUxNDgxOSAtOC4wMzM4NzNDMy41MTQ4MTkgLTguMTY1MzggMy40MDcyMjMgLTguMTY1MzggMy4zMzU0OTIgLTguMTY1MzhDMi45MTcwNjEgLTguMTY1MzggMi40NzQ3MiAtOC4xNDE0NjkgMi4wNDQzMzQgLTguMTQxNDY5SDEuNDIyNjY1QzEuMjQzMzM3IC04LjE0MTQ2OSAxLjAyODE0NCAtOC4xNjUzOCAwLjg0ODgxNyAtOC4xNjUzOEMwLjc3NzA4NiAtOC4xNjUzOCAwLjYzMzYyNCAtOC4xNjUzOCAwLjYzMzYyNCAtNy45MzgyMzJDMC42MzM2MjQgLTcuODE4NjggMC43MjkyNjUgLTcuODE4NjggMC44OTY2MzggLTcuODE4NjhDMS40NTg1MzEgLTcuODE4NjggMS40NzA0ODYgLTcuNzQ2OTQ5IDEuNDk0Mzk2IC03LjM2NDM4NEwyLjAyMDQyMyAtMC4wMjM5MUMyLjAzMjM3OSAwLjE3OTMyOCAyLjA0NDMzNCAwLjI1MTA1OSAyLjE4Nzc5NiAwLjI1MTA1OUMyLjMwNzM0NyAwLjI1MTA1OSAyLjMzMTI1OCAwLjIwMzIzOCAyLjQzODg1NCAwLjAyMzkxTDYuMDAxNDk0IC02LjIwNDczMkw2LjQ0MzgzNiAtMC4wMjM5MUM2LjQ1NTc5MSAwLjE3OTMyOCA2LjQ2Nzc0NiAwLjI1MTA1OSA2LjYxMTIwOCAwLjI1MTA1OUM2LjczMDc2IDAuMjUxMDU5IDYuNzY2NjI1IDAuMTkxMjgzIDYuODYyMjY3IDAuMDIzOTFMMTAuNzk1NTE3IC02LjgzODM1NlonIGlkPSdnNS04NycvPgo8cGF0aCBkPSdNNC4wNDA4NDcgLTEuNTE4MzA2QzMuOTkzMDI2IC0xLjMyNzAyNCAzLjk2OTExNiAtMS4yNzkyMDMgMy44MTM2OTkgLTEuMDk5ODc1QzMuMzIzNTM3IC0wLjQ2NjI1MiAyLjgyMTQyIC0wLjIzOTEwMyAyLjQ1MDgwOSAtMC4yMzkxMDNDMi4wNTYyODkgLTAuMjM5MTAzIDEuNjg1Njc5IC0wLjU0OTkzOCAxLjY4NTY3OSAtMS4zNzQ4NDRDMS42ODU2NzkgLTIuMDA4NDY4IDIuMDQ0MzM0IC0zLjM0NzQ0NyAyLjMwNzM0NyAtMy44ODU0M0MyLjY1NDA0NyAtNC41NTQ5MTkgMy4xOTIwMyAtNS4wMzMxMjYgMy42OTQxNDcgLTUuMDMzMTI2QzQuNDgzMTg4IC01LjAzMzEyNiA0LjYzODYwNSAtNC4wNTI4MDIgNC42Mzg2MDUgLTMuOTgxMDcxTDQuNjAyNzQgLTMuODEzNjk5TDQuMDQwODQ3IC0xLjUxODMwNlpNNC43ODIwNjcgLTQuNDgzMTg4QzQuNjI2NjUgLTQuODI5ODg4IDQuMjkxOTA1IC01LjI3MjIyOSAzLjY5NDE0NyAtNS4yNzIyMjlDMi4zOTEwMzQgLTUuMjcyMjI5IDAuOTA4NTkzIC0zLjYzNDM3MSAwLjkwODU5MyAtMS44NTMwNTFDMC45MDg1OTMgLTAuNjA5NzE0IDEuNjYxNzY4IDAgMi40MjY4OTkgMEMzLjA2MDUyMyAwIDMuNjIyNDE2IC0wLjUwMjExNyAzLjgzNzYwOSAtMC43NDEyMkwzLjU3NDU5NSAwLjMzNDc0NUMzLjQwNzIyMyAwLjk5MjI3OSAzLjMzNTQ5MiAxLjI5MTE1OCAyLjkwNTEwNiAxLjcwOTU4OUMyLjQxNDk0NCAyLjE5OTc1MSAxLjk2MDY0OCAyLjE5OTc1MSAxLjY5NzYzNCAyLjE5OTc1MUMxLjMzODk3OSAyLjE5OTc1MSAxLjA0MDEgMi4xNzU4NDEgMC43NDEyMiAyLjA4MDE5OUMxLjEyMzc4NiAxLjk3MjYwMyAxLjIxOTQyNyAxLjYzNzg1OCAxLjIxOTQyNyAxLjUwNjM1MUMxLjIxOTQyNyAxLjMxNTA2OCAxLjA3NTk2NSAxLjEyMzc4NiAwLjgxMjk1MSAxLjEyMzc4NkMwLjUyNjAyNyAxLjEyMzc4NiAwLjIxNTE5MyAxLjM2Mjg4OSAwLjIxNTE5MyAxLjc1NzQxQzAuMjE1MTkzIDIuMjQ3NTcyIDAuNzA1MzU1IDIuNDM4ODU0IDEuNzIxNTQ0IDIuNDM4ODU0QzMuMjYzNzYxIDIuNDM4ODU0IDQuMDY0NzU3IDEuNDQ2NTc1IDQuMjIwMTc0IDAuODAwOTk2TDUuNTQ3MTk4IC00LjU1NDkxOUM1LjU4MzA2NCAtNC42OTgzODEgNS41ODMwNjQgLTQuNzIyMjkxIDUuNTgzMDY0IC00Ljc0NjIwMkM1LjU4MzA2NCAtNC45MTM1NzQgNS40NTE1NTcgLTUuMDQ1MDgxIDUuMjcyMjI5IC01LjA0NTA4MUM0Ljk4NTMwNSAtNS4wNDUwODEgNC44MTc5MzMgLTQuODA1OTc4IDQuNzgyMDY3IC00LjQ4MzE4OFonIGlkPSdnNS0xMDMnLz4KPHBhdGggZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2IC0wLjUzNzk4MyAxLjgxNzE4NiAtMi45NzY4MzdDMS44MTcxODYgLTUuMjk2MTM5IDIuMzc5MDc4IC03LjI5MjY1MyAzLjc2NTg3OCAtOC43MDMzNjJDMy44ODU0MyAtOC44MTA5NTkgMy44ODU0MyAtOC44MzQ4NjkgMy44ODU0MyAtOC44NzA3MzVDMy44ODU0MyAtOC45NDI0NjYgMy44MjU2NTQgLTguOTY2Mzc2IDMuNzc3ODMzIC04Ljk2NjM3NkMzLjYyMjQxNiAtOC45NjYzNzYgMi42NDIwOTIgLTguMTA1NjA0IDIuMDU2Mjg5IC02LjkzMzk5OEMxLjQ0NjU3NSAtNS43MjY1MjYgMS4xNzE2MDYgLTQuNDQ3MzIzIDEuMTcxNjA2IC0yLjk3NjgzN0MxLjE3MTYwNiAtMS45MTI4MjcgMS4zMzg5NzkgLTAuNDkwMTYyIDEuOTYwNjQ4IDAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonIGlkPSdnNi00MCcvPgo8cGF0aCBkPSdNMy4zNzEzNTcgLTIuOTc2ODM3QzMuMzcxMzU3IC0zLjg4NTQzIDMuMjUxODA2IC01LjM2Nzg3IDIuNTgyMzE2IC02Ljc1NDY3QzEuODc2OTYxIC04LjE4OTI5IDAuODk2NjM4IC04Ljk2NjM3NiAwLjc2NTEzMSAtOC45NjYzNzZDMC43MTczMSAtOC45NjYzNzYgMC42NTc1MzQgLTguOTQyNDY2IDAuNjU3NTM0IC04Ljg3MDczNUMwLjY1NzUzNCAtOC44MzQ4NjkgMC42NTc1MzQgLTguODEwOTU5IDAuODYwNzcyIC04LjYwNzcyMUMyLjA1NjI4OSAtNy40MDAyNDkgMi43MjU3NzggLTUuNDI3NjQ2IDIuNzI1Nzc4IC0yLjk4ODc5MkMyLjcyNTc3OCAtMC42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgMC43NzcwODYgMi43Mzc3MzNDMC42NTc1MzQgMi44NDUzMyAwLjY1NzUzNCAyLjg2OTI0IDAuNjU3NTM0IDIuOTA1MTA2QzAuNjU3NTM0IDIuOTc2ODM3IDAuNzE3MzEgMy4wMDA3NDcgMC43NjUxMzEgMy4wMDA3NDdDMC45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgMC45NjgzNjlDMy4wOTYzODkgLTAuMjUxMDU5IDMuMzcxMzU3IC0xLjU0MjIxNyAzLjM3MTM1NyAtMi45NzY4MzdaJyBpZD0nZzYtNDEnLz4KPHBhdGggZD0nTTUuMzU1OTE1IC0zLjgyNTY1NEM1LjM1NTkxNSAtNC44MTc5MzMgNS4yOTYxMzkgLTUuNzg2MzAxIDQuODY1NzUzIC02LjY5NDg5NEM0LjM3NTU5MiAtNy42ODcxNzMgMy41MTQ4MTkgLTcuOTUwMTg3IDIuOTI5MDE2IC03Ljk1MDE4N0MyLjIzNTYxNiAtNy45NTAxODcgMS4zODY4IC03LjYwMzQ4NyAwLjk0NDQ1OCAtNi42MTEyMDhDMC42MDk3MTQgLTUuODU4MDMyIDAuNDkwMTYyIC01LjExNjgxMiAwLjQ5MDE2MiAtMy44MjU2NTRDMC40OTAxNjIgLTIuNjY2MDAyIDAuNTczODQ4IC0xLjc5MzI3NSAxLjAwNDIzNCAtMC45NDQ0NThDMS40NzA0ODYgLTAuMDM1ODY2IDIuMjk1MzkyIDAuMjUxMDU5IDIuOTE3MDYxIDAuMjUxMDU5QzMuOTU3MTYxIDAuMjUxMDU5IDQuNTU0OTE5IC0wLjM3MDYxIDQuOTAxNjE5IC0xLjA2NDAxQzUuMzMyMDA1IC0xLjk2MDY0OCA1LjM1NTkxNSAtMy4xMzIyNTQgNS4zNTU5MTUgLTMuODI1NjU0Wk0yLjkxNzA2MSAwLjAxMTk1NUMyLjUzNDQ5NiAwLjAxMTk1NSAxLjc1NzQxIC0wLjIwMzIzOCAxLjUzMDI2MiAtMS41MDYzNTFDMS4zOTg3NTUgLTIuMjIzNjYxIDEuMzk4NzU1IC0zLjEzMjI1NCAxLjM5ODc1NSAtMy45NjkxMTZDMS4zOTg3NTUgLTQuOTQ5NDQgMS4zOTg3NTUgLTUuODM0MTIyIDEuNTkwMDM3IC02LjUzOTQ3N0MxLjc5MzI3NSAtNy4zNDA0NzMgMi40MDI5ODkgLTcuNzExMDgzIDIuOTE3MDYxIC03LjcxMTA4M0MzLjM3MTM1NyAtNy43MTEwODMgNC4wNjQ3NTcgLTcuNDM2MTE1IDQuMjkxOTA1IC02LjQwNzk3QzQuNDQ3MzIzIC01LjcyNjUyNiA0LjQ0NzMyMyAtNC43ODIwNjcgNC40NDczMjMgLTMuOTY5MTE2QzQuNDQ3MzIzIC0zLjE2ODEyIDQuNDQ3MzIzIC0yLjI1OTUyNyA0LjMxNTgxNiAtMS41MzAyNjJDNC4wODg2NjcgLTAuMjE1MTkzIDMuMzM1NDkyIDAuMDExOTU1IDIuOTE3MDYxIDAuMDExOTU1WicgaWQ9J2c2LTQ4Jy8+CjxwYXRoIGQ9J00yLjA1NjI4OSAtNC44MDU5NzhIMy40MDcyMjNWLTUuMTUyNjc3SDIuMDMyMzc5Vi02LjU1MTQzMkMyLjAzMjM3OSAtNy42MjczOTcgMi41ODIzMTYgLTguMTc3MzM1IDMuMDcyNDc4IC04LjE3NzMzNUMzLjE2ODEyIC04LjE3NzMzNSAzLjM0NzQ0NyAtOC4xNTM0MjUgMy40OTA5MDkgLTguMDgxNjk0QzMuNDQzMDg4IC04LjA2OTczOCAzLjE0NDIwOSAtNy45NjIxNDIgMy4xNDQyMDkgLTcuNjE1NDQyQzMuMTQ0MjA5IC03LjM0MDQ3MyAzLjMzNTQ5MiAtNy4xNDkxOTEgMy42MTA0NjEgLTcuMTQ5MTkxQzMuODk3Mzg1IC03LjE0OTE5MSA0LjA4ODY2NyAtNy4zNDA0NzMgNC4wODg2NjcgLTcuNjI3Mzk3QzQuMDg4NjY3IC04LjA2OTczOCAzLjY1ODI4MSAtOC40MTY0MzggMy4wODQ0MzMgLTguNDE2NDM4QzIuMjQ3NTcyIC04LjQxNjQzOCAxLjMwMzExMyAtNy43NzA4NTkgMS4zMDMxMTMgLTYuNTUxNDMyVi01LjE1MjY3N0gwLjM3MDYxVi00LjgwNTk3OEgxLjMwMzExM1YtMC44ODQ2ODJDMS4zMDMxMTMgLTAuMzQ2NyAxLjE3MTYwNiAtMC4zNDY3IDAuMzk0NTIxIC0wLjM0NjdWMEMwLjcyOTI2NSAtMC4wMjM5MSAxLjM4NjggLTAuMDIzOTEgMS43NDU0NTUgLTAuMDIzOTFDMi4wNjgyNDQgLTAuMDIzOTEgMi45MTcwNjEgLTAuMDIzOTEgMy4xOTIwMyAwVi0wLjM0NjdIMi45NTI5MjdDMi4wODAxOTkgLTAuMzQ2NyAyLjA1NjI4OSAtMC40NzgyMDcgMi4wNTYyODkgLTAuOTA4NTkzVi00LjgwNTk3OFonIGlkPSdnNi0xMDInLz4KPHBhdGggZD0nTTIuMDgwMTk5IC03LjM2NDM4NEMyLjA4MDE5OSAtNy42NzUyMTggMS44MjkxNDEgLTcuOTUwMTg3IDEuNDk0Mzk2IC03Ljk1MDE4N0MxLjE4MzU2MiAtNy45NTAxODcgMC45MjA1NDggLTcuNjk5MTI4IDAuOTIwNTQ4IC03LjM3NjMzOUMwLjkyMDU0OCAtNy4wMTc2ODQgMS4yMDc0NzIgLTYuNzkwNTM1IDEuNDk0Mzk2IC02Ljc5MDUzNUMxLjg2NTAwNiAtNi43OTA1MzUgMi4wODAxOTkgLTcuMTAxMzcgMi4wODAxOTkgLTcuMzY0Mzg0Wk0wLjQzMDM4NiAtNS4xNDA3MjJWLTQuNzk0MDIyQzEuMTk1NTE3IC00Ljc5NDAyMiAxLjMwMzExMyAtNC43MjIyOTEgMS4zMDMxMTMgLTQuMTM2NDg4Vi0wLjg4NDY4MkMxLjMwMzExMyAtMC4zNDY3IDEuMTcxNjA2IC0wLjM0NjcgMC4zOTQ1MjEgLTAuMzQ2N1YwQzAuNzI5MjY1IC0wLjAyMzkxIDEuMzAzMTEzIC0wLjAyMzkxIDEuNjQ5ODEzIC0wLjAyMzkxQzEuNzgxMzIgLTAuMDIzOTEgMi40NzQ3MiAtMC4wMjM5MSAyLjg4MTE5NiAwVi0wLjM0NjdDMi4xMDQxMSAtMC4zNDY3IDIuMDU2Mjg5IC0wLjQwNjQ3NiAyLjA1NjI4OSAtMC44NzI3MjdWLTUuMjcyMjI5TDAuNDMwMzg2IC01LjE0MDcyMlonIGlkPSdnNi0xMDUnLz4KPHBhdGggZD0nTTUuMzIwMDUgLTIuOTA1MTA2QzUuMzIwMDUgLTQuMDE2OTM2IDUuMzIwMDUgLTQuMzUxNjgxIDUuMDQ1MDgxIC00LjczNDI0N0M0LjY5ODM4MSAtNS4yMDA0OTggNC4xMzY0ODggLTUuMjcyMjI5IDMuNzMwMDEyIC01LjI3MjIyOUMyLjU3MDM2MSAtNS4yNzIyMjkgMi4xMTYwNjUgLTQuMjc5OTUgMi4wMjA0MjMgLTQuMDQwODQ3SDIuMDA4NDY4Vi01LjI3MjIyOUwwLjM4MjU2NSAtNS4xNDA3MjJWLTQuNzk0MDIyQzEuMTk1NTE3IC00Ljc5NDAyMiAxLjI5MTE1OCAtNC43MTAzMzYgMS4yOTExNTggLTQuMTI0NTMzVi0wLjg4NDY4MkMxLjI5MTE1OCAtMC4zNDY3IDEuMTU5NjUxIC0wLjM0NjcgMC4zODI1NjUgLTAuMzQ2N1YwQzAuNjkzNCAtMC4wMjM5MSAxLjMzODk3OSAtMC4wMjM5MSAxLjY3MzcyNCAtMC4wMjM5MUMyLjAyMDQyMyAtMC4wMjM5MSAyLjY2NjAwMiAtMC4wMjM5MSAyLjk3NjgzNyAwVi0wLjM0NjdDMi4yMTE3MDYgLTAuMzQ2NyAyLjA2ODI0NCAtMC4zNDY3IDIuMDY4MjQ0IC0wLjg4NDY4MlYtMy4xMDgzNDRDMi4wNjgyNDQgLTQuMzYzNjM2IDIuODkzMTUxIC01LjAzMzEyNiAzLjYzNDM3MSAtNS4wMzMxMjZTNC41NDI5NjQgLTQuNDIzNDEyIDQuNTQyOTY0IC0zLjY5NDE0N1YtMC44ODQ2ODJDNC41NDI5NjQgLTAuMzQ2NyA0LjQxMTQ1NyAtMC4zNDY3IDMuNjM0MzcxIC0wLjM0NjdWMEMzLjk0NTIwNSAtMC4wMjM5MSA0LjU5MDc4NSAtMC4wMjM5MSA0LjkyNTUyOSAtMC4wMjM5MUM1LjI3MjIyOSAtMC4wMjM5MSA1LjkxNzgwOCAtMC4wMjM5MSA2LjIyODY0MyAwVi0wLjM0NjdDNS42MzA4ODQgLTAuMzQ2NyA1LjMzMjAwNSAtMC4zNDY3IDUuMzIwMDUgLTAuNzA1MzU1Vi0yLjkwNTEwNlonIGlkPSdnNi0xMTAnLz4KPHBhdGggZD0nTTUuNTcxMTA4IC0xLjgwOTIxNUM1LjY5ODYzIC0xLjgwOTIxNSA1Ljg3Mzk3MyAtMS44MDkyMTUgNS44NzM5NzMgLTEuOTkyNTI4UzUuNjk4NjMgLTIuMTc1ODQxIDUuNTcxMTA4IC0yLjE3NTg0MUgxLjAwNDIzNEMwLjg3NjcxMiAtMi4xNzU4NDEgMC43MDEzNyAtMi4xNzU4NDEgMC43MDEzNyAtMS45OTI1MjhTMC44NzY3MTIgLTEuODA5MjE1IDEuMDA0MjM0IC0xLjgwOTIxNUg1LjU3MTEwOFonIGlkPSdnMi0wJy8+CjxwYXRoIGQ9J00zLjI5MTY1NiAtMS4wNTIwNTVDMy4zNjMzODcgLTEuMDA0MjM0IDMuMzg3Mjk4IC0xLjAwNDIzNCAzLjQyNzE0OCAtMS4wMDQyMzRDMy41NTQ2NyAtMS4wMDQyMzQgMy42NjYyNTIgLTEuMTA3ODQ2IDMuNjY2MjUyIC0xLjI1MTMwOEMzLjY2NjI1MiAtMS40MDI3NCAzLjU4NjU1IC0xLjQzNDYyIDMuNDY2OTk5IC0xLjQ5MDQxMUMyLjkzMzAwMSAtMS43Mzc0ODQgMi43NDE3MTkgLTEuODI1MTU2IDIuMzUxMTgzIC0xLjk4NDU1OEwzLjI4MzY4NiAtMi40MDY5NzRDMy4zNDc0NDcgLTIuNDMwODg0IDMuNDk4ODc5IC0yLjUwMjYxNSAzLjU2MjY0IC0yLjUyNjUyNkMzLjY0MjM0MSAtMi41NzQzNDYgMy42NjYyNTIgLTIuNjU0MDQ3IDMuNjY2MjUyIC0yLjcyNTc3OEMzLjY2NjI1MiAtMi44MjE0MiAzLjYxODQzMSAtMi45NzI4NTIgMy4zNzkzMjggLTIuOTcyODUyTDIuMjMxNjMxIC0yLjE5MTc4MUwyLjM0MzIxMyAtMy4zNzEzNTdDMi4zNTkxNTMgLTMuNTA2ODQ5IDIuMzQzMjEzIC0zLjcwNjEwMiAyLjExMjA4IC0zLjcwNjEwMkMxLjk2ODYxOCAtMy43MDYxMDIgMS44NTcwMzYgLTMuNTg2NTUgMS44ODA5NDYgLTMuNDc0OTY5Vi0zLjM3OTMyOEwxLjk5MjUyOCAtMi4xOTE3ODFMMC45MzI1MDMgLTIuOTI1MDMxQzAuODYwNzcyIC0yLjk3Mjg1MiAwLjgzNjg2MiAtMi45NzI4NTIgMC43OTcwMTEgLTIuOTcyODUyQzAuNjY5NDg5IC0yLjk3Mjg1MiAwLjU1NzkwOCAtMi44NjkyNCAwLjU1NzkwOCAtMi43MjU3NzhDMC41NTc5MDggLTIuNTc0MzQ2IDAuNjM3NjA5IC0yLjU0MjQ2NiAwLjc1NzE2MSAtMi40ODY2NzVDMS4yOTExNTggLTIuMjM5NjAxIDEuNDgyNDQxIC0yLjE1MTkzIDEuODcyOTc2IC0xLjk5MjUyOEwwLjk0MDQ3MyAtMS41NzAxMTJDMC44NzY3MTIgLTEuNTQ2MjAyIDAuNzI1MjggLTEuNDc0NDcxIDAuNjYxNTE5IC0xLjQ1MDU2QzAuNTgxODE4IC0xLjQwMjc0IDAuNTU3OTA4IC0xLjMyMzAzOSAwLjU1NzkwOCAtMS4yNTEzMDhDMC41NTc5MDggLTEuMTA3ODQ2IDAuNjY5NDg5IC0xLjAwNDIzNCAwLjc5NzAxMSAtMS4wMDQyMzRDMC44NjA3NzIgLTEuMDA0MjM0IDAuODc2NzEyIC0xLjAwNDIzNCAxLjA3NTk2NSAtMS4xNDc2OTZMMS45OTI1MjggLTEuNzg1MzA1TDEuODcyOTc2IC0wLjUwMjExN0MxLjg3Mjk3NiAtMC4zNDI3MTUgMi4wMDg0NjggLTAuMjcwOTg0IDIuMTEyMDggLTAuMjcwOTg0UzIuMzUxMTgzIC0wLjM0MjcxNSAyLjM1MTE4MyAtMC41MDIxMTdDMi4zNTExODMgLTAuNTgxODE4IDIuMzE5MzAzIC0wLjgzNjg2MiAyLjMxMTMzMyAtMC45MzI1MDNDMi4yNzk0NTIgLTEuMjAzNDg3IDIuMjU1NTQyIC0xLjUwNjM1MSAyLjIzMTYzMSAtMS43ODUzMDVMMy4yOTE2NTYgLTEuMDUyMDU1WicgaWQ9J2cyLTMnLz4KPHBhdGggZD0nTTIuMTEyMDggLTMuNzc3ODMzQzIuMTUxOTMgLTMuODgxNDQ1IDIuMTgzODExIC0zLjkzNzIzNSAyLjE4MzgxMSAtNC4wMTY5MzZDMi4xODM4MTEgLTQuMjc5OTUgMS45NDQ3MDcgLTQuNDU1MjkzIDEuNzIxNTQ0IC00LjQ1NTI5M0MxLjQwMjc0IC00LjQ1NTI5MyAxLjMxNTA2OCAtNC4xNzYzMzkgMS4yODMxODggLTQuMDY0NzU3TDAuMjcwOTg0IC0wLjYyOTYzOUMwLjIzOTEwMyAtMC41MzM5OTggMC4yMzkxMDMgLTAuNTEwMDg3IDAuMjM5MTAzIC0wLjUwMjExN0MwLjIzOTEwMyAtMC40MzAzODYgMC4yODY5MjQgLTAuNDE0NDQ2IDAuMzY2NjI1IC0wLjM5MDUzNUMwLjUxMDA4NyAtMC4zMjY3NzUgMC41MjYwMjcgLTAuMzI2Nzc1IDAuNTQxOTY4IC0wLjMyNjc3NUMwLjU2NTg3OCAtMC4zMjY3NzUgMC42MTM2OTkgLTAuMzI2Nzc1IDAuNjY5NDg5IC0wLjQ2MjI2N0wyLjExMjA4IC0zLjc3NzgzM1onIGlkPSdnMi00OCcvPgo8cGF0aCBkPSdNMS4zNTQ5MTkgLTUuNjc0NzJDMS4zNTQ5MTkgLTUuODAyMjQyIDEuMzU0OTE5IC01Ljk3NzU4NCAxLjE3MTYwNiAtNS45Nzc1ODRTMC45ODgyOTQgLTUuODAyMjQyIDAuOTg4Mjk0IC01LjY3NDcyVjEuNjg5NjY0QzAuOTg4Mjk0IDEuODE3MTg2IDAuOTg4Mjk0IDEuOTkyNTI4IDEuMTcxNjA2IDEuOTkyNTI4UzEuMzU0OTE5IDEuODE3MTg2IDEuMzU0OTE5IDEuNjg5NjY0Vi01LjY3NDcyWicgaWQ9J2cyLTEwNicvPgo8cGF0aCBkPSdNNy44Nzg0NTYgLTIuNzQ5Njg5QzguMDgxNjk0IC0yLjc0OTY4OSA4LjI5Njg4NyAtMi43NDk2ODkgOC4yOTY4ODcgLTIuOTg4NzkyUzguMDgxNjk0IC0zLjIyNzg5NSA3Ljg3ODQ1NiAtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3MiAtMy4yMjc4OTUgMC45OTIyNzkgLTMuMjI3ODk1IDAuOTkyMjc5IC0yLjk4ODc5MlMxLjIwNzQ3MiAtMi43NDk2ODkgMS40MTA3MSAtMi43NDk2ODlINy44Nzg0NTZaJyBpZD0nZzMtMCcvPgo8cGF0aCBkPSdNNi41ODcyOTggLTcuODQyNTlDNi42NDcwNzMgLTcuOTc0MDk3IDYuNjQ3MDczIC03Ljk5ODAwNyA2LjY0NzA3MyAtOC4wNTc3ODNDNi42NDcwNzMgLTguMTc3MzM1IDYuNTUxNDMyIC04LjI5Njg4NyA2LjQwNzk3IC04LjI5Njg4N0M2LjI1MjU1MyAtOC4yOTY4ODcgNi4xODA4MjIgLTguMTUzNDI1IDYuMTMzMDAxIC04LjAyMTkxOEw1LjE0MDcyMiAtNS4zOTE3ODFIMS41MDYzNTFMMC41MTQwNzIgLTguMDIxOTE4QzAuNDU0Mjk2IC04LjE4OTI5IDAuMzk0NTIxIC04LjI5Njg4NyAwLjIzOTEwMyAtOC4yOTY4ODdDMC4xMTk1NTIgLTguMjk2ODg3IDAgLTguMTc3MzM1IDAgLTguMDU3NzgzQzAgLTguMDMzODczIDAgLTguMDA5OTYzIDAuMDcxNzMxIC03Ljg0MjU5TDMuMDQ4NTY4IC0wLjAxMTk1NUMzLjEwODM0NCAwLjE1NTQxNyAzLjE2ODEyIDAuMjYzMDE0IDMuMzIzNTM3IDAuMjYzMDE0QzMuNDkwOTA5IDAuMjYzMDE0IDMuNTM4NzMgMC4xMzE1MDcgMy41ODY1NSAwLjAxMTk1NUw2LjU4NzI5OCAtNy44NDI1OVpNMS42OTc2MzQgLTQuOTEzNTc0SDQuOTQ5NDRMMy4zMjM1MzcgLTAuNjU3NTM0TDEuNjk3NjM0IC00LjkxMzU3NFonIGlkPSdnMy01NicvPgo8cGF0aCBkPSdNOS4zMjUwMzEgLTcuOTAyMzY2QzkuMzQ4OTQxIC03LjkzODIzMiA5LjM4NDgwNyAtOC4wMjE5MTggOS4zODQ4MDcgLTguMDY5NzM4QzkuMzg0ODA3IC04LjE1MzQyNSA5LjM3Mjg1MiAtOC4xNjUzOCA5LjA5Nzg4MyAtOC4xNjUzOEgwLjg0ODgxN0MwLjU3Mzg0OCAtOC4xNjUzOCAwLjU2MTg5MyAtOC4xNTM0MjUgMC41NjE4OTMgLTguMDY5NzM4QzAuNTYxODkzIC04LjAyMTkxOCAwLjU5Nzc1OCAtNy45MzgyMzIgMC42MjE2NjkgLTcuOTAyMzY2TDQuNjUwNTYgMC4xNjczNzJDNC43MzQyNDcgMC4zMjI3OSA0Ljc3MDExMiAwLjM5NDUyMSA0Ljk3MzM1IDAuMzk0NTIxUzUuMjEyNDUzIDAuMzIyNzkgNS4yOTYxMzkgMC4xNjczNzJMOS4zMjUwMzEgLTcuOTAyMzY2Wk0yLjA0NDMzNCAtNy4zMDQ2MDhIOC42MDc3MjFMNS4zMzIwMDUgLTAuNzI5MjY1TDIuMDQ0MzM0IC03LjMwNDYwOFonIGlkPSdnMy0xMTQnLz4KPHBhdGggZD0nTTEuMTYzNjM2IC0xLjc4NTMwNUMxLjQ0MjU5IC0xLjY2NTc1MyAxLjY4MTY5NCAtMS42NjU3NTMgMS44OTY4ODcgLTEuNjY1NzUzQzIuMTQzOTYgLTEuNjY1NzUzIDIuNTkwMjg2IC0xLjY2NTc1MyAyLjU5MDI4NiAtMS45NTI2NzdDMi41OTAyODYgLTIuMTU5OSAyLjI4NzQyMiAtMi4xOTE3ODEgMS45NzY1ODggLTIuMTkxNzgxQzEuNTYyMTQyIC0yLjE5MTc4MSAxLjM0Njk0OSAtMi4xMDQxMSAxLjE3OTU3NyAtMi4wMzIzNzlDMS4wNjc5OTUgLTIuMDg4MTY5IDAuODY4NzQyIC0yLjIzOTYwMSAwLjg2ODc0MiAtMi40NjI3NjVDMC44Njg3NDIgLTIuODg1MTgxIDEuNjA5OTYzIC0zLjE4MDA3NSAyLjQwNjk3NCAtMy4xODAwNzVDMi42NTQwNDcgLTMuMTgwMDc1IDIuOTAxMTIxIC0zLjE0MDIyNCAzLjE4ODA0NSAtMi45NTY5MTJDMy4yNjc3NDYgLTIuOTAxMTIxIDMuMjgzNjg2IC0yLjg4NTE4MSAzLjM0NzQ0NyAtMi44ODUxODFDMy40NTkwMjkgLTIuODg1MTgxIDMuNTg2NTUgLTMuMDA0NzMyIDMuNTg2NTUgLTMuMTI0Mjg0QzMuNTg2NTUgLTMuMjkxNjU2IDMuMjgzNjg2IC0zLjQxOTE3OCAzLjE3MjEwNSAtMy40NjY5OTlDMi44NTMzIC0zLjYwMjQ5MSAyLjYwNjIyNyAtMy42MDI0OTEgMi40ODY2NzUgLTMuNjAyNDkxQzEuNTM4MjMyIC0zLjYwMjQ5MSAwLjYyMTY2OSAtMy4wNjg0OTMgMC42MjE2NjkgLTIuNDU0Nzk1QzAuNjIxNjY5IC0yLjE1OTkgMC44NDQ4MzIgLTEuOTY4NjE4IDAuOTI0NTMzIC0xLjkxMjgyN0MwLjM2NjYyNSAtMS41NTQxNzIgMC4yMzExMzMgLTEuMTIzNzg2IDAuMjMxMTMzIC0wLjg2MDc3MkMwLjIzMTEzMyAtMC4zMTg4MDQgMC43NDEyMiAwLjE2NzM3MiAxLjYyNTkwMyAwLjE2NzM3MkMyLjc4MTU2OSAwLjE2NzM3MiAzLjIwMzk4NSAtMC41NTc5MDggMy4yMDM5ODUgLTAuNjY5NDg5QzMuMjAzOTg1IC0wLjcyNTI4IDMuMTcyMTA1IC0wLjc4MTA3MSAzLjEwMDM3NCAtMC43ODEwNzFDMy4wNDQ1ODMgLTAuNzgxMDcxIDMuMDIwNjcyIC0wLjc0OTE5MSAyLjk4ODc5MiAtMC43MDEzN0MyLjg2OTI0IC0wLjUxMDA4NyAyLjcwMTg2OCAtMC4yNTUwNDQgMS43MTM1NzQgLTAuMjU1MDQ0QzEuNTA2MzUxIC0wLjI1NTA0NCAwLjQ4NjE3NyAtMC4yNTUwNDQgMC40ODYxNzcgLTAuOTA4NTkzQzAuNDg2MTc3IC0xLjE0NzY5NiAwLjY2OTQ4OSAtMS41MTQzMjEgMS4xNjM2MzYgLTEuNzg1MzA1Wk0yLjMwMzM2MiAtMS45Mjg3NjdDMi4xODM4MTEgLTEuODg4OTE3IDIuMTY3ODcgLTEuODg4OTE3IDEuODk2ODg3IC0xLjg4ODkxN0MxLjgwOTIxNSAtMS44ODg5MTcgMS42NDE4NDMgLTEuODg4OTE3IDEuNTIyMjkxIC0xLjkxMjgyN0MxLjcxMzU3NCAtMS45NjA2NDggMS44ODg5MTcgLTEuOTY4NjE4IDEuOTYwNjQ4IC0xLjk2ODYxOEMyLjEwNDExIC0xLjk2ODYxOCAyLjE5OTc1MSAtMS45NTI2NzcgMi4zMDMzNjIgLTEuOTM2NzM3Vi0xLjkyODc2N1onIGlkPSdnNC0zNCcvPgo8cGF0aCBkPSdNNS43MDY2IC0xLjc5MzI3NUM1LjgwMjI0MiAtMS44NDEwOTYgNS44NzM5NzMgLTEuODg4OTE3IDUuODczOTczIC0xLjk5MjUyOFM1LjgwMjI0MiAtMi4xNDM5NiA1LjcwNjYgLTIuMTkxNzgxTDEuMDI4MTQ0IC00LjQzOTM1MkMwLjkyNDUzMyAtNC40OTUxNDMgMC45MDg1OTMgLTQuNDk1MTQzIDAuODg0NjgyIC00LjQ5NTE0M0MwLjc4MTA3MSAtNC40OTUxNDMgMC43MDEzNyAtNC40MTU0NDIgMC43MDEzNyAtNC4zMTE4MzFTMC43NzMxMDEgLTQuMTYwMzk5IDAuODY4NzQyIC00LjExMjU3OEw1LjI2ODI0NCAtMS45OTI1MjhMMC44Njg3NDIgMC4xMjc1MjJDMC43NzMxMDEgMC4xNzUzNDIgMC43MDEzNyAwLjIyMzE2MyAwLjcwMTM3IDAuMzI2Nzc1UzAuNzgxMDcxIDAuNTEwMDg3IDAuODg0NjgyIDAuNTEwMDg3QzAuOTA4NTkzIDAuNTEwMDg3IDAuOTI0NTMzIDAuNTEwMDg3IDEuMDI4MTQ0IDAuNDU0Mjk2TDUuNzA2NiAtMS43OTMyNzVaJyBpZD0nZzQtNjInLz4KPHBhdGggZD0nTTcuNzg2OCAtNC40ODcxNzNDOC4xNDU0NTUgLTUuMDg0OTMyIDguNDE2NDM4IC01LjE1NjY2MyA4LjY3OTQ1MiAtNS4xODA1NzNDOC43NTExODMgLTUuMTg4NTQzIDguODQ2ODI0IC01LjE5NjUxMyA4Ljg0NjgyNCAtNS4zMzIwMDVDOC44NDY4MjQgLTUuMzg3Nzk2IDguNzk5MDA0IC01LjQ0MzU4NyA4LjczNTI0MyAtNS40NDM1ODdDOC41OTk3NTEgLTUuNDQzNTg3IDguNzI3MjczIC01LjQxOTY3NiA4LjA5NzYzNCAtNS40MTk2NzZDNy41NzE2MDYgLTUuNDE5Njc2IDcuMzQwNDczIC01LjQ0MzU4NyA3LjMwMDYyMyAtNS40NDM1ODdDNy4xNzMxMDEgLTUuNDQzNTg3IDcuMTQ5MTkxIC01LjM1NTkxNSA3LjE0OTE5MSAtNS4yOTIxNTRDNy4xNDkxOTEgLTUuMTg4NTQzIDcuMjYwNzcyIC01LjE4MDU3MyA3LjI4NDY4MiAtNS4xODA1NzNDNy41MDc4NDYgLTUuMTcyNjAzIDcuNzA3MDk4IC01LjA5MjkwMiA3LjcwNzA5OCAtNC44OTM2NDlDNy43MDcwOTggLTQuNzkwMDM3IDcuNjI3Mzk3IC00LjY1NDU0NSA3LjU4NzU0NyAtNC41OTA3ODVMNS4zNzk4MjYgLTAuODc2NzEyTDUuMDA1MjMgLTQuODM3ODU4QzQuOTk3MjYgLTQuODUzNzk4IDQuOTg5MjkgLTQuOTA5NTg5IDQuOTg5MjkgLTQuOTMzNDk5QzQuOTg5MjkgLTUuMDUzMDUxIDUuMTQwNzIyIC01LjE4MDU3MyA1LjUzMTI1OCAtNS4xODA1NzNDNS42NTA4MDkgLTUuMTgwNTczIDUuNzQ2NDUxIC01LjE4MDU3MyA1Ljc0NjQ1MSAtNS4zMzIwMDVDNS43NDY0NTEgLTUuMzk1NzY2IDUuNjk4NjMgLTUuNDQzNTg3IDUuNjE4OTI5IC01LjQ0MzU4N1M1LjI0NDMzNCAtNS40Mjc2NDYgNS4xNjQ2MzMgLTUuNDE5Njc2SDQuNjg2NDI2QzMuOTc3MDg2IC01LjQxOTY3NiAzLjg4OTQxNSAtNS40NDM1ODcgMy44MjU2NTQgLTUuNDQzNTg3QzMuNzkzNzczIC01LjQ0MzU4NyAzLjY2NjI1MiAtNS40NDM1ODcgMy42NjYyNTIgLTUuMjkyMTU0QzMuNjY2MjUyIC01LjE4MDU3MyAzLjc2OTg2MyAtNS4xODA1NzMgMy44ODk0MTUgLTUuMTgwNTczQzQuMjI0MTU5IC01LjE4MDU3MyA0LjI0ODA3IC01LjExNjgxMiA0LjI2NDAxIC01LjAwNTIzQzQuMjY0MDEgLTQuOTg5MjkgNC4zMTE4MzEgLTQuNTI3MDI0IDQuMzExODMxIC00LjUwMzExM1M0LjMxMTgzMSAtNC40MzkzNTIgNC4yNTYwNCAtNC4zNTE2ODFMMi4xODM4MTEgLTAuODc2NzEyTDEuODA5MjE1IC00Ljc5ODAwN0MxLjgwOTIxNSAtNC44Mzc4NTggMS44MDEyNDUgLTQuOTAxNjE5IDEuODAxMjQ1IC00Ljk0MTQ2OUMxLjgwMTI0NSAtNS4wMDUyMyAxLjg2NTAwNiAtNS4xODA1NzMgMi4zNTExODMgLTUuMTgwNTczQzIuNDM4ODU0IC01LjE4MDU3MyAyLjU1MDQzNiAtNS4xODA1NzMgMi41NTA0MzYgLTUuMzMyMDA1QzIuNTUwNDM2IC01LjM5NTc2NiAyLjQ5NDY0NSAtNS40NDM1ODcgMi40MjI5MTQgLTUuNDQzNTg3QzIuMzQzMjEzIC01LjQ0MzU4NyAyLjA0ODMxOSAtNS40Mjc2NDYgMS45Njg2MTggLTUuNDE5Njc2SDEuNDkwNDExQzAuNzU3MTYxIC01LjQxOTY3NiAwLjcyNTI4IC01LjQ0MzU4NyAwLjYyOTYzOSAtNS40NDM1ODdDMC41MDIxMTcgLTUuNDQzNTg3IDAuNDc4MjA3IC01LjM1NTkxNSAwLjQ3ODIwNyAtNS4yOTIxNTRDMC40NzgyMDcgLTUuMTgwNTczIDAuNTg5Nzg4IC01LjE4MDU3MyAwLjY3NzQ2IC01LjE4MDU3M0MxLjA1MjA1NSAtNS4xODA1NzMgMS4wNjAwMjUgLTUuMTI0NzgyIDEuMDc1OTY1IC00LjkyNTUyOUwxLjUzODIzMiAtMC4wNjM3NjFDMS41NTQxNzIgMC4wODc2NzEgMS41NjIxNDIgMC4xNjczNzIgMS42OTc2MzQgMC4xNjczNzJDMS43NjEzOTUgMC4xNjczNzIgMS44NDEwOTYgMC4xNDM0NjIgMS45Mjg3NjcgMEw0LjM1MTY4MSAtNC4wODA2OTdMNC43MzQyNDcgLTAuMDU1NzkxQzQuNzUwMTg3IDAuMDg3NjcxIDQuNzU4MTU3IDAuMTY3MzcyIDQuODg1Njc5IDAuMTY3MzcyQzUuMDIxMTcxIDAuMTY3MzcyIDUuMDY4OTkxIDAuMDc5NzAxIDUuMTE2ODEyIDBMNy43ODY4IC00LjQ4NzE3M1onIGlkPSdnNC04NycvPgo8cGF0aCBkPSdNMi43Nzk1NzcgLTAuODQyODM5QzIuOTM0OTk0IC0wLjczNTI0MyAyLjk0Njk0OSAtMC43MzUyNDMgMi45ODg3OTIgLTAuNzM1MjQzQzMuMDkwNDExIC0wLjczNTI0MyAzLjE4NjA1MiAtMC44MjQ5MDcgMy4xODYwNTIgLTAuOTQ0NDU4UzMuMDk2Mzg5IC0xLjA5OTg3NSAzLjA0ODU2OCAtMS4xMjM3ODZDMi43NDM3MTEgLTEuMjQ5MzE1IDIuNDM4ODU0IC0xLjM3NDg0NCAyLjEyODAyIC0xLjQ4ODQxOEMyLjczNzczMyAtMS43Mzk0NzcgMi45MDUxMDYgLTEuNzk5MjUzIDMuMDEyNzAyIC0xLjg0NzA3M0MzLjEwMjM2NiAtMS44ODg5MTcgMy4xODYwNTIgLTEuOTE4ODA0IDMuMTg2MDUyIC0yLjAzODM1NlMzLjA5MDQxMSAtMi4yNDc1NzIgMi45ODg3OTIgLTIuMjQ3NTcyQzIuOTQwOTcxIC0yLjI0NzU3MiAyLjkwNTEwNiAtMi4yMjM2NjEgMi44NTcyODUgLTIuMTkzNzczTDIuMDA4NDY4IC0xLjY1NTc5MUMyLjAxNDQ0NiAtMS43Mzk0NzcgMi4wMzgzNTYgLTEuOTQ4NjkyIDIuMDQ0MzM0IC0yLjAyMDQyM0MyLjA1NjI4OSAtMi4xMzk5NzUgMi4xMDQxMSAtMi40OTg2MyAyLjEwNDExIC0yLjYwMDI0OVMyLjAxNDQ0NiAtMi43Nzk1NzcgMS45MDY4NDkgLTIuNzc5NTc3QzEuODA1MjMgLTIuNzc5NTc3IDEuNzA5NTg5IC0yLjcwMTg2OCAxLjcwOTU4OSAtMi42MDAyNDlDMS43MDk1ODkgLTIuNTg4Mjk0IDEuNzYzMzg3IC0yLjA1MDMxMSAxLjc2OTM2NSAtMi4wMjY0MDFDMS43NzUzNDIgLTEuOTYwNjQ4IDEuNzk5MjUzIC0xLjczMzQ5OSAxLjgwNTIzIC0xLjY1NTc5MUwwLjk1NjQxMyAtMi4xOTM3NzNDMC45MDg1OTMgLTIuMjIzNjYxIDAuODcyNzI3IC0yLjI0NzU3MiAwLjgyNDkwNyAtMi4yNDc1NzJDMC43MjMyODggLTIuMjQ3NTcyIDAuNjI3NjQ2IC0yLjE1NzkwOCAwLjYyNzY0NiAtMi4wMzgzNTZTMC43MTczMSAtMS44ODI5MzkgMC43NjUxMzEgLTEuODU5MDI5QzEuMDY5OTg4IC0xLjczMzQ5OSAxLjM3NDg0NCAtMS42MDc5NyAxLjY4NTY3OSAtMS40OTQzOTZDMS4wNzU5NjUgLTEuMjQzMzM3IDAuOTA4NTkzIC0xLjE4MzU2MiAwLjgwMDk5NiAtMS4xMzU3NDFDMC43MTEzMzMgLTEuMDkzODk4IDAuNjI3NjQ2IC0xLjA2NDAxIDAuNjI3NjQ2IC0wLjk0NDQ1OFMwLjcyMzI4OCAtMC43MzUyNDMgMC44MjQ5MDcgLTAuNzM1MjQzQzAuODcyNzI3IC0wLjczNTI0MyAwLjk3NDM0NiAtMC44MDA5OTYgMS4wNDYwNzcgLTAuODQ4ODE3QzEuMTI5NzYzIC0wLjg5NjYzOCAxLjMzMzAwMSAtMS4wMjgxNDQgMS40MTA3MSAtMS4wODE5NDNDMS42MDc5NyAtMS4yMDc0NzIgMS42Nzk3MDEgLTEuMjU1MjkzIDEuODA1MjMgLTEuMzI3MDI0QzEuNzk5MjUzIC0xLjI0MzMzNyAxLjc3NTM0MiAtMS4wMzQxMjIgMS43NjkzNjUgLTAuOTYyMzkxTDEuNzA5NTg5IC0wLjM4MjU2NUMxLjcwOTU4OSAtMC4yODA5NDYgMS44MDUyMyAtMC4yMDMyMzggMS45MDY4NDkgLTAuMjAzMjM4QzIuMDE0NDQ2IC0wLjIwMzIzOCAyLjEwNDExIC0wLjI4MDk0NiAyLjEwNDExIC0wLjM4MjU2NUMyLjEwNDExIC0wLjM4ODU0MyAyLjA1MDMxMSAtMC45MjY1MjYgMi4wNDQzMzQgLTAuOTU2NDEzQzIuMDM4MzU2IC0xLjAyMjE2NyAyLjAxNDQ0NiAtMS4yNDkzMTUgMi4wMDg0NjggLTEuMzI3MDI0TDIuNzc5NTc3IC0wLjg0MjgzOVonIGlkPSdnMS0zJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSczOC44NTQyOTYnIHhsaW5rOmhyZWY9JyNnMy01NicgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNDUuNDk2MDc3JyB4bGluazpocmVmPScjZzUtMzQnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzU0LjI5NDkyOScgeGxpbms6aHJlZj0nI2c1LTYyJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc2Ni43MjA0MScgeGxpbms6aHJlZj0nI2c2LTQ4JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc3Mi41NzM0JyB4bGluazpocmVmPScjZzUtNTknIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9Jzk2LjI3Mzk5OCcgeGxpbms6aHJlZj0nI2c2LTEwNScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nOTkuNTI1NjU5JyB4bGluazpocmVmPScjZzYtMTEwJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMDYuMDI4OTgxJyB4bGluazpocmVmPScjZzYtMTAyJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc4MS4xMzgzODknIHhsaW5rOmhyZWY9JyNnMi0xMDYnIHk9JzczLjcyMzUzNycvPgo8dXNlIHg9JzgzLjQ5MDcxMicgeGxpbms6aHJlZj0nI2c0LTg3JyB5PSc3My43MjM1MzcnLz4KPHVzZSB4PSc5Mi42NTY0NzUnIHhsaW5rOmhyZWY9JyNnMi0wJyB5PSc3My43MjM1MzcnLz4KPHVzZSB4PSc5OS4yNDI5ODInIHhsaW5rOmhyZWY9JyNnNC04NycgeT0nNzMuNzIzNTM3Jy8+Cjx1c2UgeD0nMTA4LjQwODc0NCcgeGxpbms6aHJlZj0nI2cxLTMnIHk9JzcxLjQ1NDI3NScvPgo8dXNlIHg9JzExMi43MjU4NjgnIHhsaW5rOmhyZWY9JyNnMi0xMDYnIHk9JzczLjcyMzUzNycvPgo8dXNlIHg9JzExNS4wNzgxOTInIHhsaW5rOmhyZWY9JyNnNC02MicgeT0nNzMuNzIzNTM3Jy8+Cjx1c2UgeD0nMTIxLjY2NDY5OScgeGxpbms6aHJlZj0nI2c0LTM0JyB5PSc3My43MjM1MzcnLz4KPHVzZSB4PScxMjcuNTY3NTgxJyB4bGluazpocmVmPScjZzAtMicgeT0nNTYuMDY5NjYxJy8+Cjx1c2UgeD0nMTMyLjU0ODkxNicgeGxpbms6aHJlZj0nI2c2LTQwJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMzcuMTAxMjQyJyB4bGluazpocmVmPScjZzUtODcnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE1Mi40MzUyNDYnIHhsaW5rOmhyZWY9JyNnMy0wJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxNjQuMzkwNDA2JyB4bGluazpocmVmPScjZzUtODcnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE3Ny4wNjc3NDYnIHhsaW5rOmhyZWY9JyNnMi0zJyB5PSc2MS40MTQ5ODgnLz4KPHVzZSB4PScxODEuODAwMDYxJyB4bGluazpocmVmPScjZzYtNDEnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE4Ni4zNTIzNTcnIHhsaW5rOmhyZWY9JyNnMi00OCcgeT0nNTkuOTQxODknLz4KPHVzZSB4PScxOTEuMTM5OTMnIHhsaW5rOmhyZWY9JyNnNS01OCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTk0LjM5MTU5MScgeGxpbms6aHJlZj0nI2czLTExNCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMjA0LjM1NDI2MicgeGxpbms6aHJlZj0nI2c1LTEwMycgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMjEyLjM4MTAxNicgeGxpbms6aHJlZj0nI2c2LTQwJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScyMTYuOTMzMzQxJyB4bGluazpocmVmPScjZzUtODcnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzIyOS42MTA2ODInIHhsaW5rOmhyZWY9JyNnNi00MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMjM0LjE2Mjk5NicgeGxpbms6aHJlZj0nI2cwLTMnIHk9JzU2LjA2OTY2MScvPgo8dXNlIHg9JzI0Mi40NjUxNjEnIHhsaW5rOmhyZWY9JyNnNS02MicgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMjU0Ljg5MDY0MScgeGxpbms6aHJlZj0nI2c2LTQ4JyB5PSc2NS43NTM0MjUnLz4KPC9nPgo8L3N2Zz4=)
H3 :
 tels que
tels que 
H4 : la suite
 vérifie,
vérifie,
 et
et  ,
,

Alors la suite  construite de la manière suivante
construite de la manière suivante
 ,
,  :
:
 vérifie
vérifie  .
.
Théorème T1 : convergence des k-means
Quelque soit l’initialisation choisie, la suite  construite par l’algorithme des k-means
converge.
construite par l’algorithme des k-means
converge.
Théorème T1 : convexité des classes formées par une régression logistique
On définit l’application  qui associe la plus grande coordonnée
qui associe la plus grande coordonnée
 .
A est une matrice
.
A est une matrice  ,
B est un vecteur de
,
B est un vecteur de  ,
c est le nombre de parties.
L’application f définit une partition convexe
de l’espace vectoriel .
,
c est le nombre de parties.
L’application f définit une partition convexe
de l’espace vectoriel .
Théorème T1 : densité des réseaux de neurones (Cybenko1989)
[Cybenko1989]
Soit  l’espace des réseaux de neurones à
entrées et sorties, possédant une couche cachée dont la
fonction de seuil est une fonction sigmoïde
l’espace des réseaux de neurones à
entrées et sorties, possédant une couche cachée dont la
fonction de seuil est une fonction sigmoïde
 ,
une couche de sortie dont la fonction de seuil est linéaire
Soit
,
une couche de sortie dont la fonction de seuil est linéaire
Soit  l’ensemble des fonctions continues de
l’ensemble des fonctions continues de
 avec
compact muni de la norme
Alors est dense dans .
avec
compact muni de la norme
Alors est dense dans .
Théorème T1 : distance d’édition
Soit et les fonctions définies respectivement par
(1) et (2), alors :
est une distance sur
Théorème T1 : loi asymptotique des coefficients
Soit un réseau de neurone défini par perceptron
composé de :
une couche d’entrées
une couche cachée dont les fonctions de transfert sont sigmoïdes
une couche de sortie dont les fonctions de transfert sont linéaires
Ce réseau sert de modèle pour la fonction
dans le problème de régression
avec un échantillon  ,
les résidus sont supposés normaux.
La suite
,
les résidus sont supposés normaux.
La suite  définie par (2) vérifie :
définie par (2) vérifie :

Et le vecteur aléatoire  vérifie :
vérifie :

Où la matrice  est définie par (2).
est définie par (2).
end{xtheorem}
Théorème T1 : résolution de l’ACP
Les notations utilisées sont celles du problème de l”ACP. Dans ce cas :
(2)#
De plus est l’espace vectoriel engendré par les
vecteurs propres de la matrice
 associées aux
valeurs propres de plus grand module.
associées aux
valeurs propres de plus grand module.
Théorème T1 : résolution du problème du maximum de vraisemblance
La solution du problème du maximum de vraisemblance est le vecteur :

Théorème T1 : simulation d’une loi quelconque
Soit  une fonction de répartition de densité
vérifiant
une fonction de répartition de densité
vérifiant  , soit
, soit  une variable
aléatoire uniformément distribuée sur alors
une variable
aléatoire uniformément distribuée sur alors
 est variable aléatoire de densité .
est variable aléatoire de densité .
Théorème T2 : Borne supérieure de l’erreur produite par k-means++
On définit l’inertie par
 .
Si
.
Si  définit l’inertie optimale alors
définit l’inertie optimale alors
 .
.
Théorème T2 : [Farago1993]_ 2
Les notations sont celles du même algorithme.
On définit une mesure sur l’ensemble ,
 désigne la boule de centre
et de rayon
désigne la boule de centre
et de rayon  ,
,
 une variable aléatoire, de plus :
une variable aléatoire, de plus :

On suppose qu’il existe  et une fonction
et une fonction  tels que :
tels que :

La convergence doit être uniforme et presque sûre.
On note également  le nombre de calculs de
dissimilarité effectués par l’algorithme
où est le nombre d’élément de ,
désigne toujours le nombre de pivots, alors :
le nombre de calculs de
dissimilarité effectués par l’algorithme
où est le nombre d’élément de ,
désigne toujours le nombre de pivots, alors :

Théorème T2 : rétropropagation
Cet algorithme s’applique à un réseau de neurones vérifiant la définition du perceptron.
Il s’agit de calculer sa dérivée par rapport aux poids. Il se déduit des formules
(3), (4), (5) et (7)
et suppose que l’algorithme de propagation a été préalablement exécuté.
On note  ,
,  et
et
 .
.
Initialisation


Récurrence






Terminaison




Théorème T2 : simulation d’une loi de Poisson
On définit une suite infinie  de loi
exponentielle de paramètre
de loi
exponentielle de paramètre  . On définit ensuite
la série de variables aléatoires
. On définit ensuite
la série de variables aléatoires  et enfin
et enfin  .
Alors la variable aléatoire
.
Alors la variable aléatoire  suit une loi
de Poisson de paramètre .
suit une loi
de Poisson de paramètre .
Théorème T2 : sélection d’architecture
Les notations utilisées sont celles du théorème
loi asymptotique des coefficients.
est un réseau de neurones
de paramètres . On définit la constante  ,
en général
,
en général  puisque
puisque
 si
si  .
.
Initialisation
Une architecture est choisie pour le réseau de neurones incluant un nombre M de paramètres.
Apprentissage
Le réseau de neurones est appris. On calcule les nombre et matrice
 et .
La base d’apprentissage contient exemples.
et .
La base d’apprentissage contient exemples.
Test
in 

Sélection


 est supprimée ou le poids
est supprimée ou le poids  est maintenue à zéro.
est maintenue à zéro.
Théorème T3 : somme de loi exponentielle iid
Soit  variables aléatoires indépendantes
et identiquement distribuées de loi
variables aléatoires indépendantes
et identiquement distribuées de loi  alors la
somme
alors la
somme  suit une loi
suit une loi  .
.